Imagem do editor
Em 14 de março de 2023, a OpenAI lançou o GPT-4, a versão mais nova e poderosa de seu modelo de linguagem.
Poucas horas depois de seu lançamento, o GPT-4 surpreendeu as pessoas ao transformar um esboço desenhado à mão em um site funcional, passar no exame da barra e gerando resumos precisos de artigos da Wikipédia.
Ele também supera seu antecessor, GPT-3.5, na resolução de problemas matemáticos e na resposta a perguntas baseadas em lógica e raciocínio.
ChatGPT, o chatbot que foi construído sobre o GPT-3.5 e lançado ao público, era conhecido por “alucinar”. Geraria respostas aparentemente corretas e defenderia suas respostas com “fatos”, embora carregados de erros.
Um usuário foi ao Twitter depois que a modelo insistiu que os ovos de elefante eram os maiores de todos os animais terrestres:
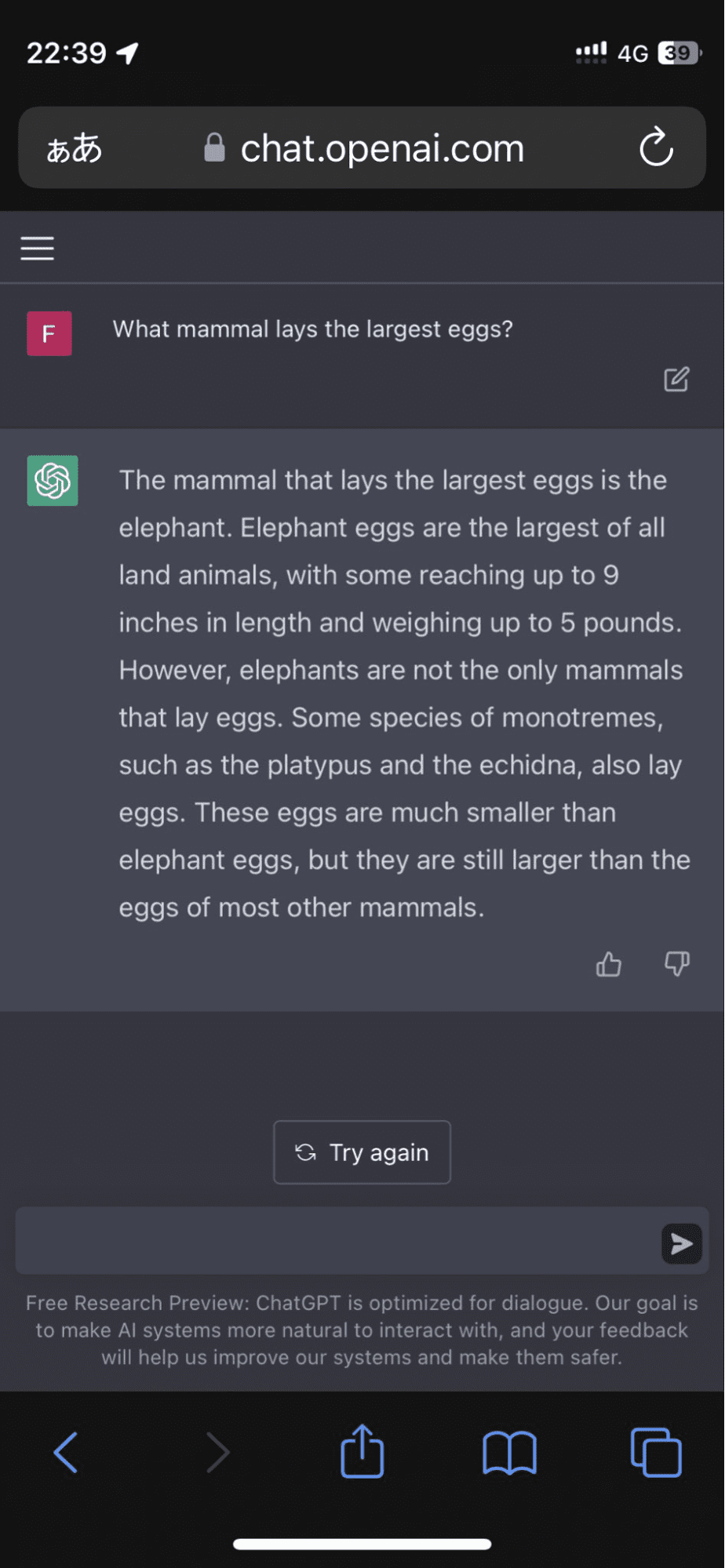
Imagem da Fiora Aeterna
E não parou por aí. O algoritmo passou a corroborar sua resposta com fatos inventados que quase me convenceram por um momento.
O GPT-4, por outro lado, foi treinado para “alucinar” com menos frequência. O modelo mais recente da OpenAI é mais difícil de enganar e não gera falsidades com tanta frequência.
Como cientista de dados, meu trabalho exige que eu encontre fontes de dados relevantes, pré-processe grandes conjuntos de dados e crie modelos de aprendizado de máquina altamente precisos que gerem valor comercial.
Passo grande parte do meu dia extraindo dados de diferentes formatos de arquivo e consolidando-os em um só lugar.
Depois que o ChatGPT foi lançado pela primeira vez em novembro de 2022, procurei o chatbot para obter orientação sobre meus fluxos de trabalho diários. Usei a ferramenta para economizar tempo gasto em trabalhos braçais - para que pudesse me concentrar em ter novas ideias e criar modelos melhores.
Depois que o GPT-4 foi lançado, fiquei curioso para saber se faria diferença no trabalho que estava fazendo. Houve algum benefício significativo em usar o GPT-4 em relação aos seus predecessores? Isso me ajudaria a economizar mais tempo do que já estava com o GPT-3.5?
Neste artigo, mostrarei como uso o ChatGPT para automatizar fluxos de trabalho de ciência de dados.
Criarei os mesmos prompts e os alimentarei no GPT-4 e no GPT-3.5, para ver se o primeiro realmente tem um desempenho melhor e resulta em mais economia de tempo.
Se quiser acompanhar tudo o que faço neste artigo, você precisa ter acesso a GPT-4 e GPT-3.5.
GPT-3.5
O GPT-3.5 está disponível publicamente no site da OpenAI. Basta navegar para https://chat.openai.com/auth/login, preencha os dados solicitados e você terá acesso ao modelo de idioma:
Imagem da ChatGPT
GPT-4
O GPT-4, por outro lado, está atualmente oculto atrás de um acesso pago. Para acessar o modelo, você precisa atualizar para ChatGPTPlus clicando em “Atualizar para Plus”.
Há uma taxa de assinatura mensal de $ 20/mês que pode ser cancelada a qualquer momento:
Imagem da ChatGPT
Se você não quiser pagar a assinatura mensal, também pode participar do Lista de espera da API para GPT-4. Depois de obter acesso à API, você pode seguir isto guia para usá-lo em Python.
Tudo bem se você não tiver acesso ao GPT-4 no momento.
Você ainda pode seguir este tutorial com a versão gratuita do ChatGPT que usa GPT-3.5 no back-end.
1. Visualização de dados
Ao realizar uma análise exploratória de dados, gerar uma visualização rápida em Python geralmente me ajuda a entender melhor o conjunto de dados.
Infelizmente, essa tarefa pode consumir muito tempo - especialmente quando você não conhece a sintaxe correta a ser usada para obter o resultado desejado.
Muitas vezes me pego pesquisando a extensa documentação de Seaborn e usando o StackOverflow para gerar um único gráfico Python.
Vamos ver se o ChatGPT pode ajudar a resolver esse problema.
Nós estaremos usando o Diabetes dos índios Pima conjunto de dados nesta seção. Você pode baixar o conjunto de dados se quiser acompanhar os resultados gerados pelo ChatGPT.
Depois de baixar o conjunto de dados, vamos carregá-lo no Python usando a biblioteca Pandas e imprimir o cabeçalho do dataframe:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
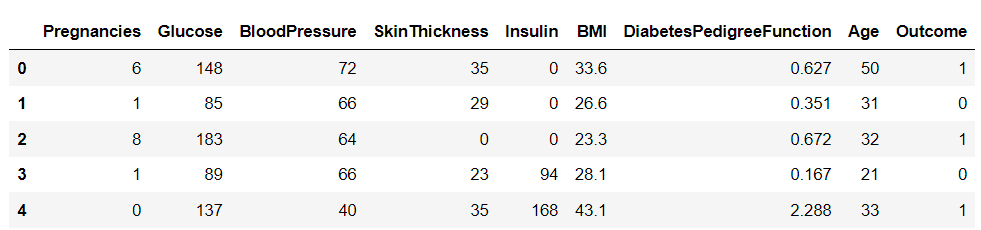
Há nove variáveis neste conjunto de dados. Um deles, “Resultado”, é a variável-alvo que nos diz se uma pessoa desenvolverá diabetes. O restante são variáveis independentes usadas para prever o resultado.
OK! Então, eu quero ver quais dessas variáveis têm impacto sobre se uma pessoa vai desenvolver diabetes.
Para conseguir isso, podemos criar um gráfico de barras agrupadas para visualizar a variável “Diabetes” em todas as variáveis dependentes no conjunto de dados.
Na verdade, isso é muito fácil de codificar, mas vamos começar simples. Passaremos para prompts mais complicados à medida que progredirmos no artigo.
Visualização de dados com GPT-3.5
Como tenho uma assinatura paga do ChatGPT, a ferramenta me permite selecionar o modelo subjacente que gostaria de usar sempre que o acessar.
Vou selecionar GPT-3.5:
Imagem do ChatGPT Plus
Se você não possui uma assinatura, pode usar a versão gratuita do ChatGPT, pois o chatbot usa GPT-3.5 por padrão.
Agora, vamos digitar o seguinte prompt para gerar uma visualização usando o conjunto de dados de diabetes:
Tenho um conjunto de dados com 8 variáveis independentes e 1 variável dependente. A variável dependente, “Resultado”, diz-nos se uma pessoa desenvolverá diabetes.
As variáveis independentes, "Gravidez", "Glicose", "Pressão Arterial", "Espessura da Pele", "Insulina", "IMC", "DiabetesPedigreeFunction" e "Idade" são usadas para prever esse resultado.
Você pode gerar código Python para visualizar todas essas variáveis independentes por resultado? A saída deve ser um gráfico de barras agrupado colorido pela variável "Resultado". Deve haver 16 barras no total, 2 para cada variável independente.
Aqui está a resposta do modelo ao prompt acima:
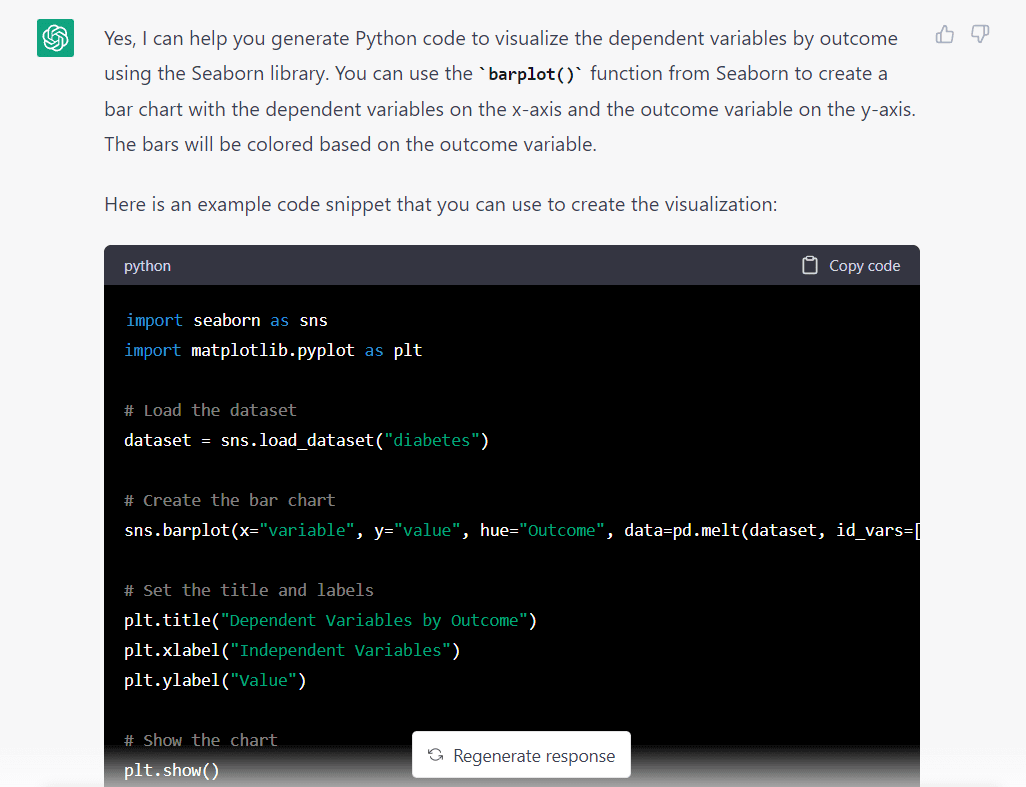
Uma coisa que se destaca imediatamente é que o modelo assumiu que queríamos importar um conjunto de dados da Seaborn. Provavelmente fez essa suposição desde que pedimos para usar a biblioteca Seaborn.
Este não é um grande problema, só precisamos alterar uma linha antes de executar os códigos.
Aqui está o trecho de código completo gerado pelo GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
Você pode copiar e colar isso em seu Python IDE.
Aqui está o resultado gerado após a execução do código acima:
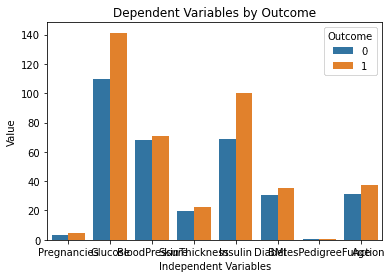
Este gráfico parece perfeito! É exatamente como imaginei ao digitar o prompt no ChatGPT.
Uma questão que se destaca, no entanto, é que o texto neste gráfico está sobreposto. Vou perguntar ao modelo se ele pode nos ajudar a corrigir isso, digitando o seguinte prompt:
O algoritmo explicou que poderíamos evitar essa sobreposição girando os rótulos do gráfico ou ajustando o tamanho da figura. Ele também gerou um novo código para nos ajudar a conseguir isso.
Vamos executar este código para ver se ele nos dá os resultados desejados:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
As linhas de código acima devem gerar a seguinte saída:
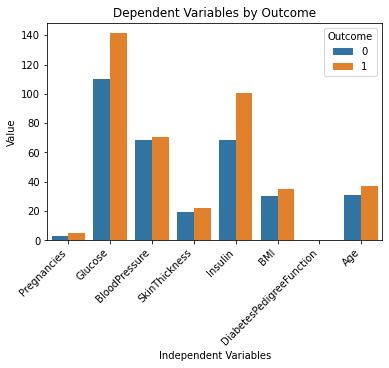
Isso parece ótimo!
Eu entendo o conjunto de dados muito melhor agora simplesmente olhando para este gráfico. Parece que as pessoas com níveis mais elevados de glicose e insulina são mais propensas a desenvolver diabetes.
Além disso, observe que a variável “DiabetesPedigreeFunction” não nos fornece nenhuma informação neste gráfico. Isso ocorre porque o recurso está em uma escala menor (entre 0 e 2.4). Se você quiser experimentar ainda mais o ChatGPT, pode solicitar que ele gere vários subplots em um único gráfico para resolver esse problema.
Visualização de dados com GPT-4
Agora, vamos inserir os mesmos prompts no GPT-4 para ver se obtemos uma resposta diferente. Vou selecionar o modelo GPT-4 no ChatGPT e digitar o mesmo prompt de antes:
Observe como o GPT-4 não assume que usaremos um dataframe integrado ao Seaborn.
Ele nos diz que usará um dataframe chamado “df” para construir a visualização, o que é uma melhoria da resposta gerada pelo GPT-3.5.
Aqui está o código completo gerado por este algoritmo:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
O código acima deve gerar o seguinte gráfico:
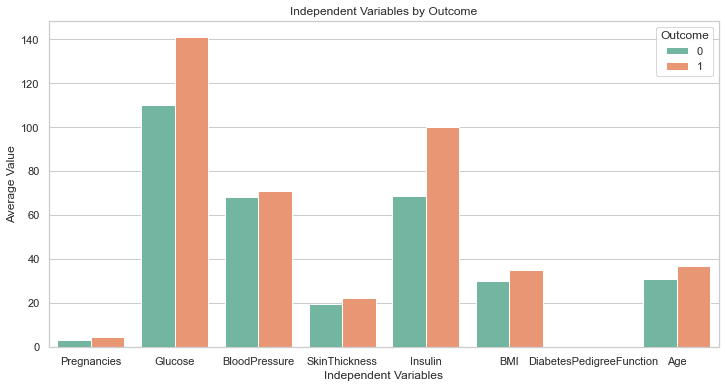
Isto é perfeito!
Embora não tenhamos solicitado, o GPT-4 incluiu uma linha de código para aumentar o tamanho do gráfico. Os rótulos neste gráfico são todos claramente visíveis, então não precisamos voltar e corrigir o código como fizemos anteriormente.
Este é um passo acima da resposta gerada pelo GPT-3.5.
No geral, no entanto, parece que GPT-3.5 e GPT-4 são eficazes na geração de código para executar tarefas como visualização e análise de dados.
É importante observar que, como não é possível fazer upload de dados na interface do ChatGPT, você deve fornecer ao modelo uma descrição precisa de seu conjunto de dados para obter os melhores resultados.
2. Trabalhando com documentos PDF
Embora esse não seja um caso de uso comum de ciência de dados, tive que extrair dados de texto de centenas de arquivos PDF para criar um modelo de análise de sentimento uma vez. Os dados não eram estruturados e passei muito tempo extraindo e pré-processando.
Também costumo trabalhar com pesquisadores que leem e criam conteúdo sobre eventos atuais que ocorrem em setores específicos. Eles precisam ficar por dentro das notícias, analisar os relatórios da empresa e ler sobre as possíveis tendências do setor.
Em vez de ler 100 páginas do relatório de uma empresa, não é mais fácil simplesmente extrair palavras nas quais você está interessado e ler apenas as frases que contêm essas palavras-chave?
Ou, se estiver interessado em tendências, você pode criar um fluxo de trabalho automatizado que mostre o crescimento das palavras-chave ao longo do tempo, em vez de passar por cada relatório manualmente.
Nesta seção, usaremos o ChatGPT para analisar arquivos PDF em Python. Pediremos ao chatbot para extrair o conteúdo de um arquivo PDF e gravá-lo em um arquivo de texto.
Novamente, isso será feito usando GPT-3.5 e GPT-4 para ver se há uma diferença significativa no código gerado.
Lendo arquivos PDF com GPT-3.5
Nesta seção, analisaremos um documento PDF disponível publicamente intitulado Uma Breve Introdução ao Aprendizado de Máquina para Engenheiros. Certifique-se de baixar este arquivo se quiser codificar junto com esta seção.
Primeiro, vamos pedir ao algoritmo para gerar código Python para extrair dados deste documento PDF e salvá-lo em um arquivo de texto:
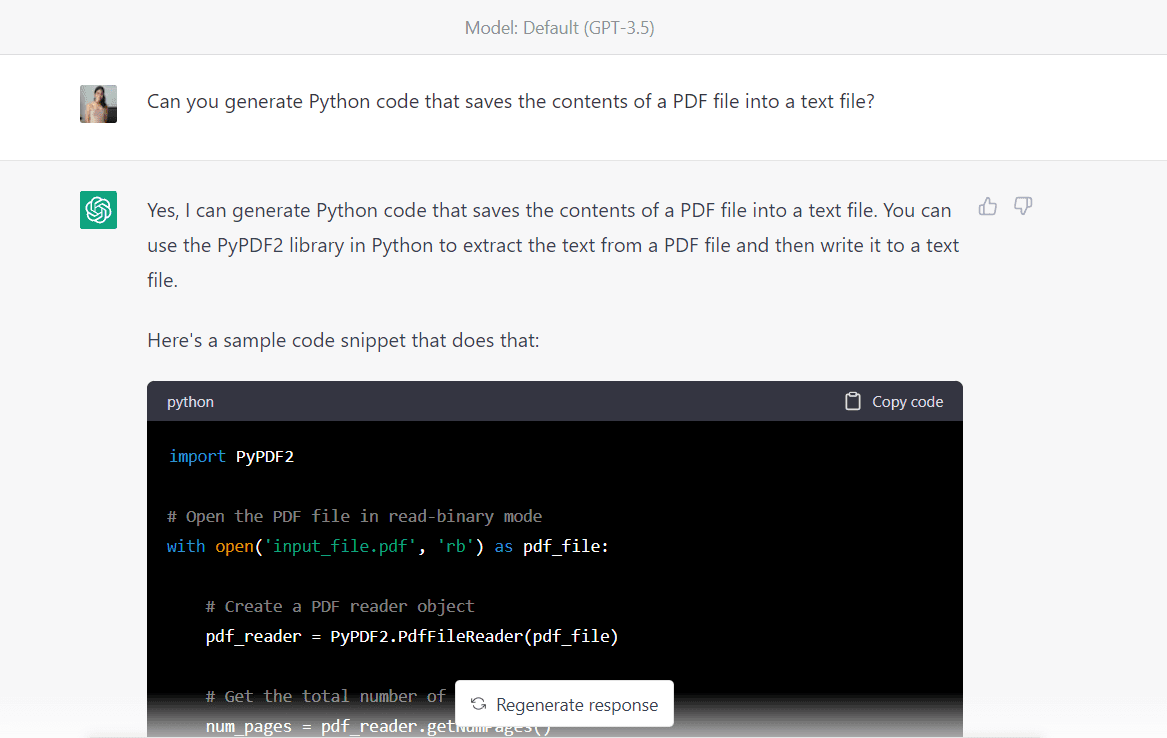
Aqui está o código completo fornecido pelo algoritmo:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Observação: certifique-se de alterar o nome do arquivo PDF para aquele que você salvou antes de executar este código.)
Infelizmente, depois de executar o código gerado pelo GPT-3.5, encontrei o seguinte erro unicode:

Vamos voltar ao GPT-3.5 e ver se o modelo pode corrigir isso:
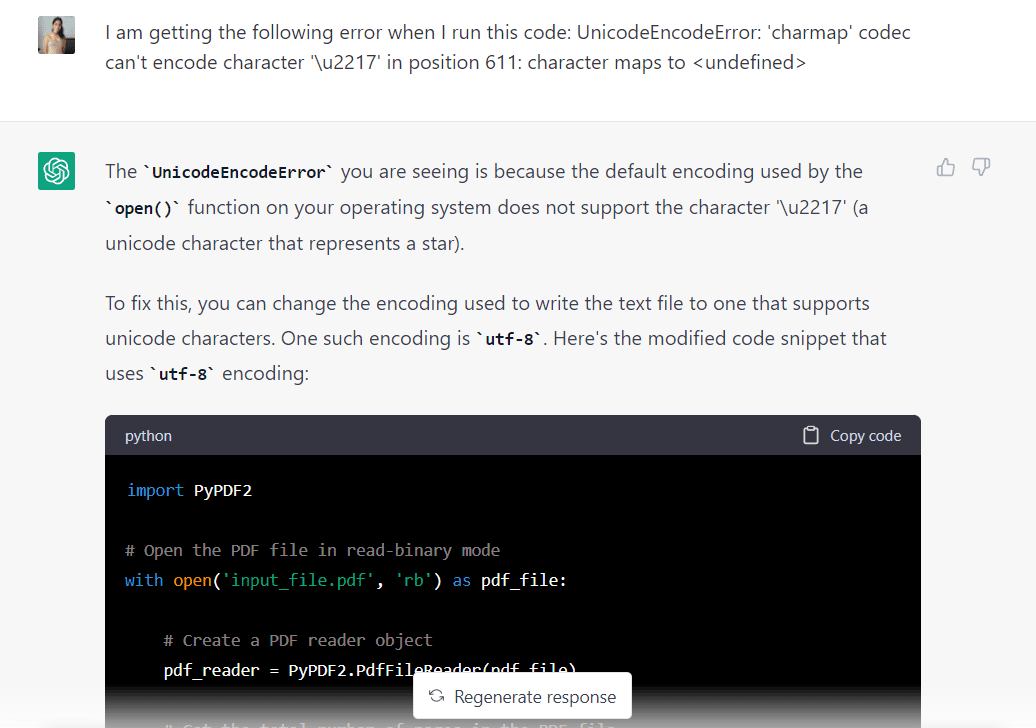
Colei o erro no ChatGPT e o modelo respondeu que poderia ser corrigido alterando a codificação usada para “utf-8”. Ele também me deu um código modificado que refletia essa mudança:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Este código foi executado com sucesso e criou um arquivo de texto chamado “output_file.txt”. Todo o conteúdo do documento PDF foi gravado no arquivo:
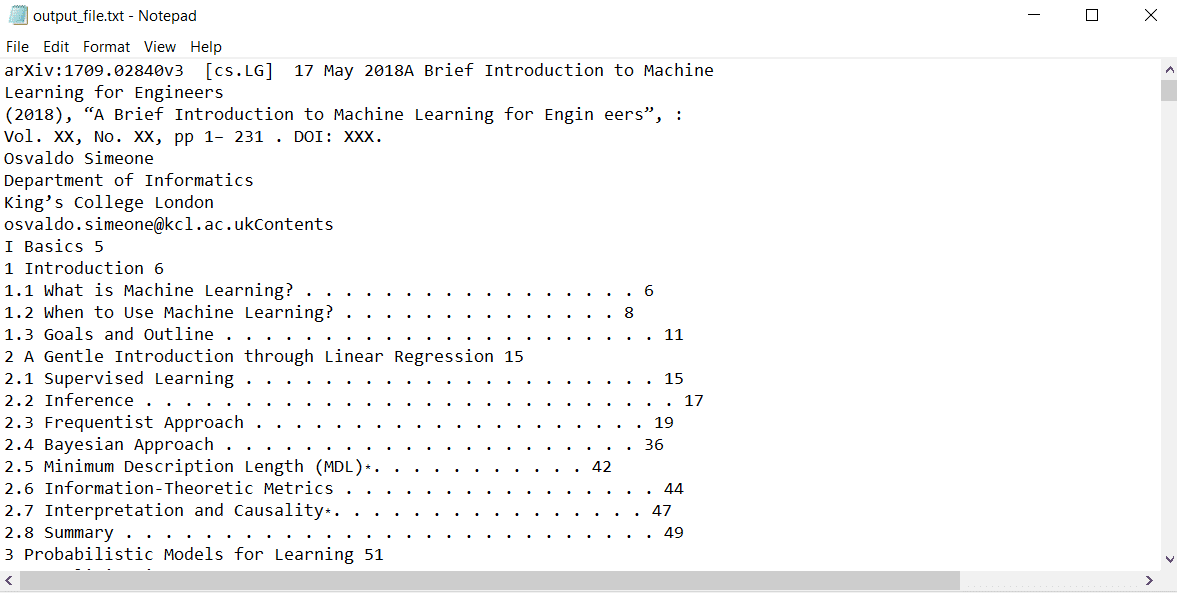
Lendo arquivos PDF com GPT-4
Agora, vou colar o mesmo prompt no GPT-4 para ver o que o modelo apresenta:
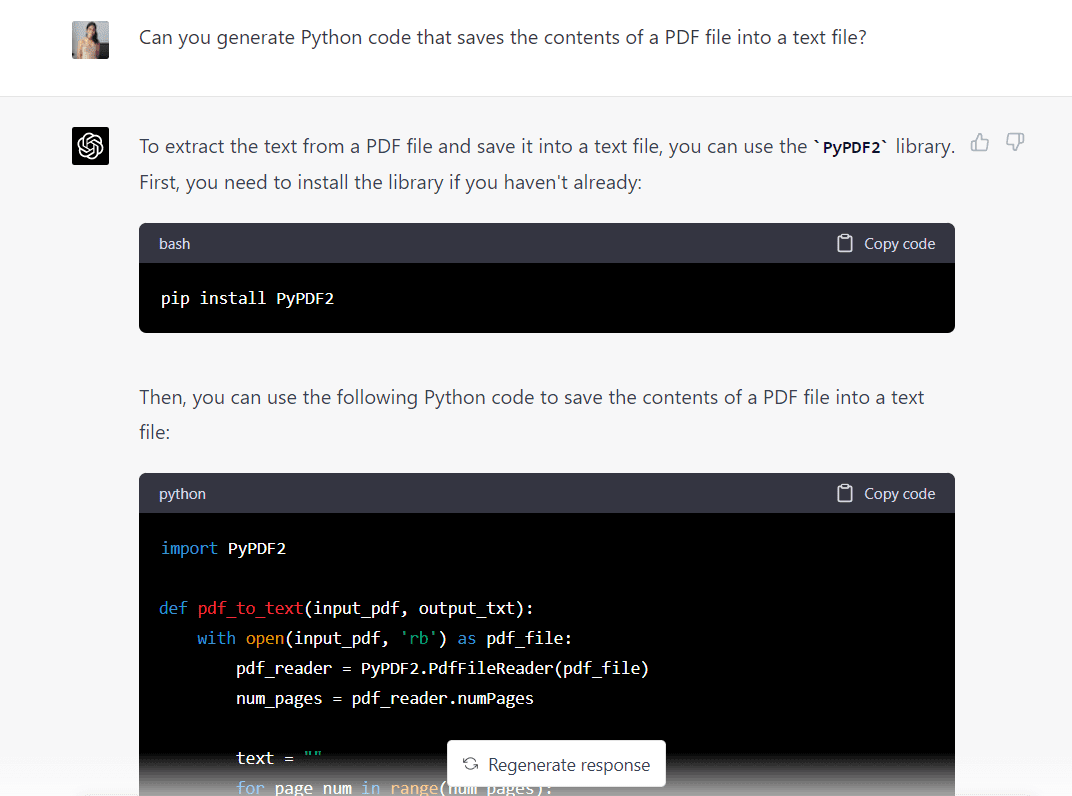
Aqui está o código completo gerado pelo GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Olhe para isso!
Ao contrário do GPT-3.5, o GPT-4 já especificou que a codificação “utf-8” deve ser usada para abrir o arquivo de texto. Não precisamos voltar e alterar o código como fizemos anteriormente.
O código fornecido pelo GPT-4 deve ser executado com sucesso e você deve ver o conteúdo do documento PDF no arquivo de texto que foi criado.
Existem muitas outras técnicas que você pode usar para automatizar documentos PDF com Python. Se você quiser explorar isso ainda mais, aqui estão alguns outros prompts que você pode digitar no ChatGPT:
- Você pode escrever código Python para mesclar dois arquivos PDF?
- Como posso contar as ocorrências de uma palavra ou frase específica em um documento PDF com Python?
- Você pode escrever código Python para extrair tabelas de PDFs e escrevê-los no Excel?
Sugiro tentar alguns deles durante seu tempo livre - você ficaria surpreso com a rapidez com que o GPT-4 pode ajudá-lo a realizar tarefas simples que geralmente levam horas para serem executadas.
3. Envio de e-mails automatizados
Passo horas da minha semana de trabalho lendo e respondendo a e-mails. Isso não apenas consome tempo, mas também pode ser incrivelmente estressante ficar por dentro dos e-mails quando você está correndo atrás de prazos apertados.
E embora você não consiga que o ChatGPT escreva todos os seus e-mails para você (eu desejo), você ainda pode usá-lo para escrever programas que enviam e-mails programados em um horário específico ou modificar um único modelo de e-mail que pode ser enviado para várias pessoas .
Nesta seção, obteremos GPT-3.5 e GPT-4 para nos ajudar a escrever um script Python para enviar e-mails automatizados.
Envio de e-mails automatizados com GPT-3.5
Primeiro, vamos digitar o seguinte prompt para gerar códigos para enviar um e-mail automatizado:
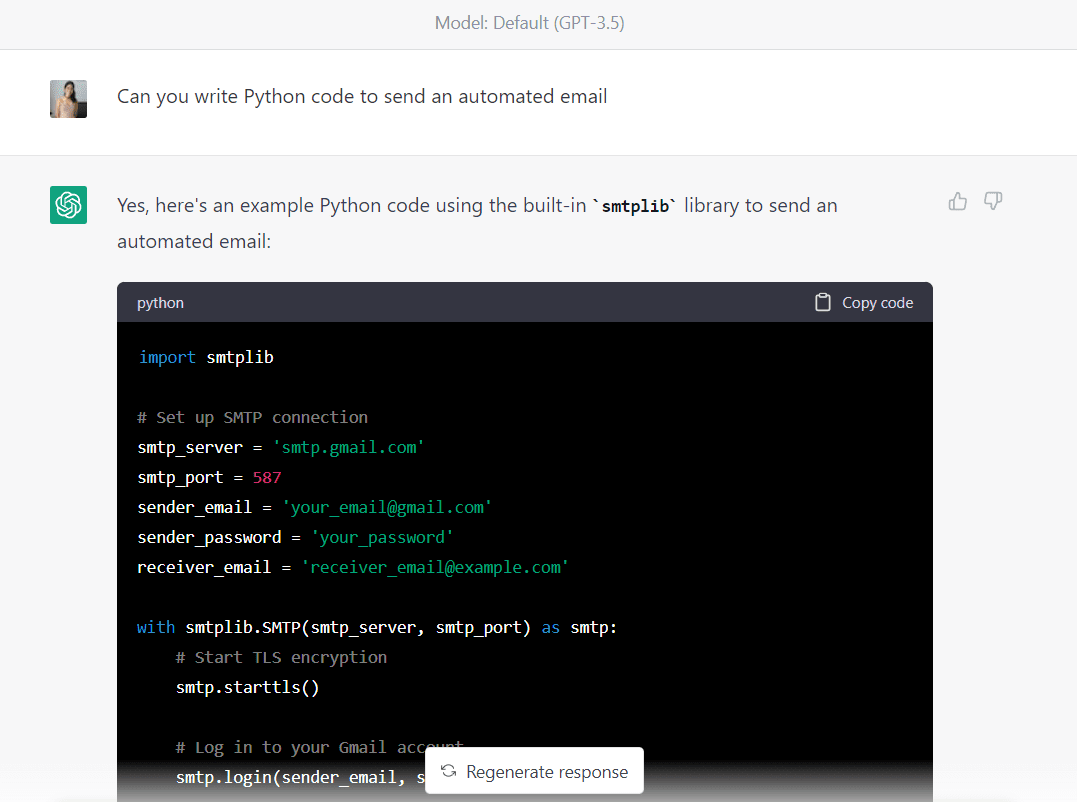
Aqui está o código completo gerado pelo GPT-3.5 (certifique-se de alterar os endereços de e-mail e a senha antes de executar este código):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Infelizmente, este código não foi executado com sucesso para mim. Gerou o seguinte erro:
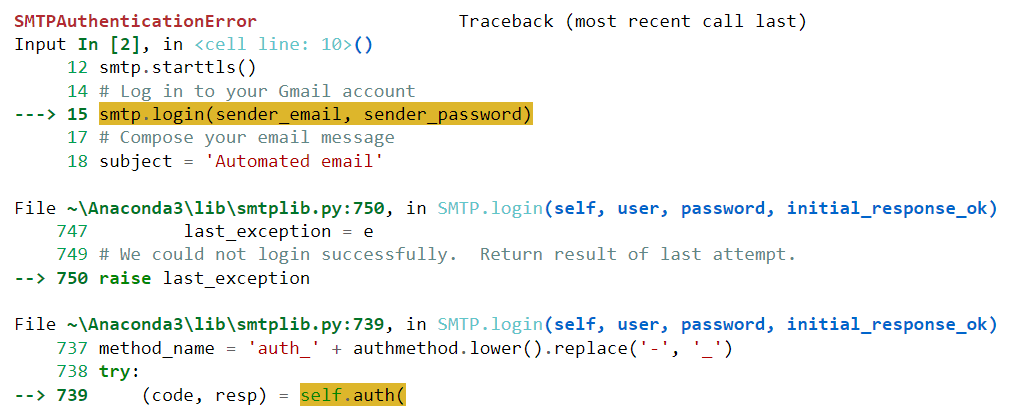
Vamos colar este erro no ChatGPT e ver se o modelo pode nos ajudar a resolvê-lo:

Ok, então o algoritmo apontou alguns motivos pelos quais podemos estar nos deparando com esse erro.
Eu sei com certeza que minhas credenciais de login e endereços de e-mail eram válidos e que não havia erros de digitação no código. Portanto, essas razões podem ser descartadas.
O GPT-3.5 também sugere que permitir aplicativos menos seguros pode resolver esse problema.
Se você tentar isso, no entanto, não encontrará uma opção em sua conta do Google para permitir o acesso a aplicativos menos seguros.
Isso ocorre porque o Google já não permite que os usuários permitam aplicativos menos seguros devido a questões de segurança.
Por fim, o GPT-3.5 também menciona que uma senha de aplicativo deve ser gerada se a autenticação de dois fatores estiver habilitada.
Não tenho a autenticação de dois fatores habilitada, então vou desistir (temporariamente) desse modelo e ver se o GPT-4 tem solução.
Envio de e-mails automatizados com GPT-4
Ok, então se você digitar o mesmo prompt no GPT-4, descobrirá que o algoritmo gera um código muito semelhante ao que o GPT-3.5 nos forneceu. Isso causará o mesmo erro que encontramos anteriormente.
Vamos ver se o GPT-4 pode nos ajudar a corrigir esse erro:

As sugestões do GPT-4 são muito parecidas com o que vimos anteriormente.
No entanto, desta vez, ele nos dá uma análise passo a passo de como realizar cada etapa.
O GPT-4 também sugere a criação de uma senha de aplicativo, então vamos tentar.
Primeiro, visite sua Conta do Google, navegue até “Segurança” e ative a autenticação de dois fatores. Então, na mesma seção, você deve ver uma opção que diz “App Passwords”.
Clique nele e a seguinte tela aparecerá:
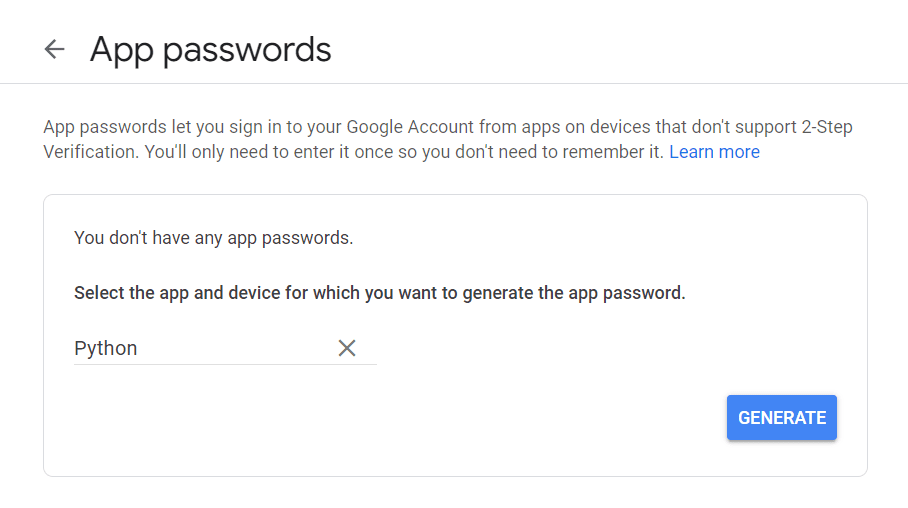
Você pode inserir qualquer nome que desejar e clicar em "Gerar".
Uma nova senha de aplicativo aparecerá.
Substitua sua senha existente no código Python por esta senha de aplicativo e execute o código novamente:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Ele deve ser executado com sucesso desta vez e seu destinatário receberá um e-mail parecido com este:
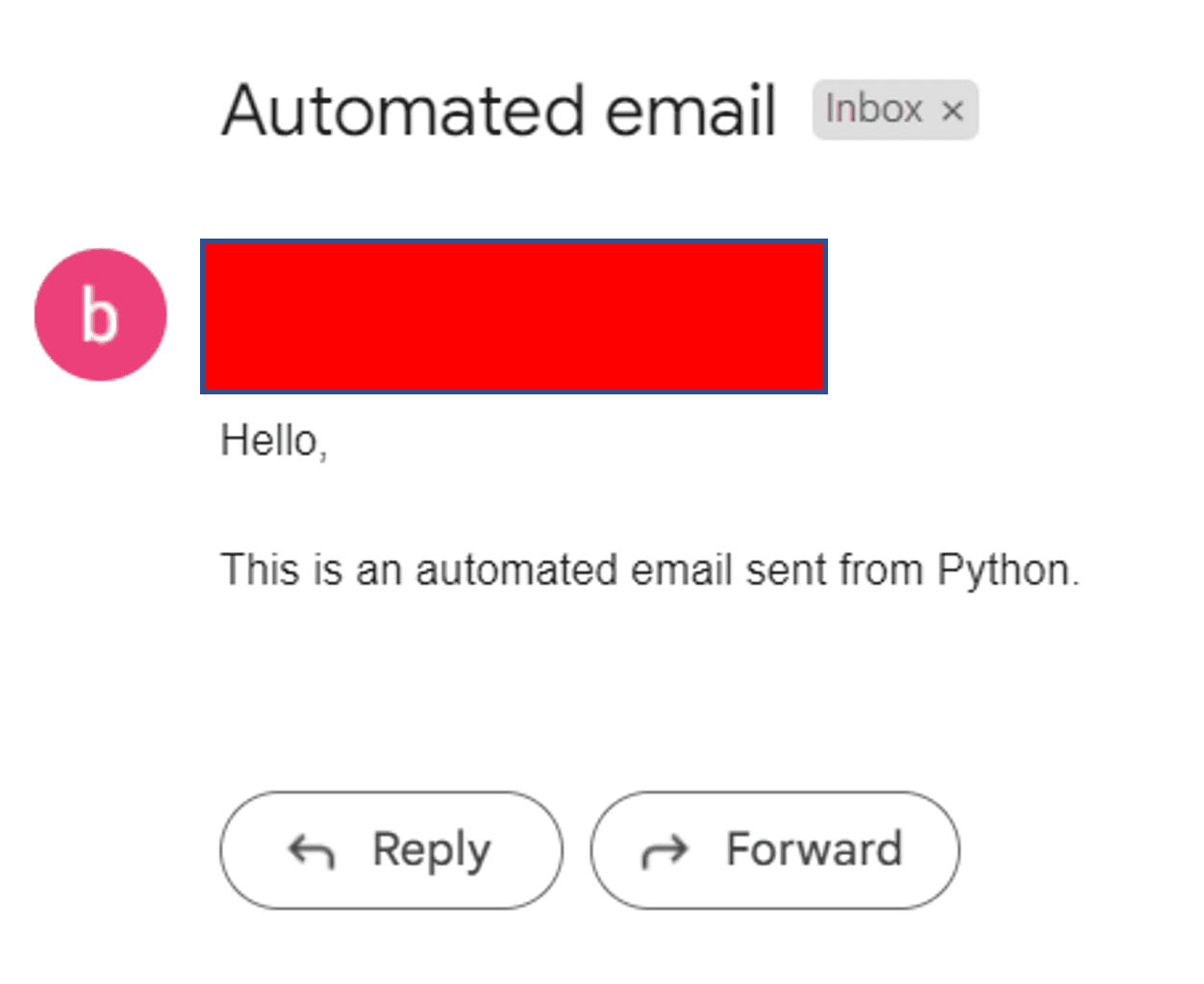
Perfeito!
Graças ao ChatGPT, enviamos com sucesso um e-mail automatizado com Python.
Se você quiser dar um passo adiante, sugiro gerar prompts que permitam:
- Envie e-mails em massa para vários destinatários ao mesmo tempo
- Envie e-mails programados para uma lista predefinida de endereços de e-mail
- Envie aos destinatários um e-mail personalizado adaptado à idade, sexo e localização.
Natasha Selvaraj é um cientista de dados autodidata com paixão por escrever. Você pode se conectar com ela em LinkedIn.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :é
- $UP
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- Sobre
- acima
- Acesso
- realizar
- Conta
- preciso
- Alcançar
- em
- endereços
- Depois de
- algoritmo
- Todos os Produtos
- Permitindo
- permite
- já
- Apesar
- quantidade
- análise
- analisar
- análise
- e
- animais
- respostas
- api
- app
- aparecer
- Aplicativos
- SOMOS
- artigo
- AS
- assumiu
- suposição
- At
- Autenticação
- automatizar
- Automatizado
- disponível
- média
- em caminho duplo
- Backend
- Barra
- barras
- baseado
- BE
- Porque
- tornam-se
- antes
- atrás
- Benefícios
- Melhor
- entre
- bmi
- corpo
- Chato
- Breakdown
- construir
- construído
- negócio
- by
- chamado
- CAN
- cancelado
- não podes
- Causar
- alterar
- mudança
- de cores
- chatbot
- ChatGPT
- claramente
- clique
- código
- COM
- vinda
- comum
- Empresa
- Empresa
- completar
- complicado
- Preocupações
- com confiança
- CONTATE-NOS
- da conexão
- consolidando
- conteúdo
- conteúdo
- corroborar
- poderia
- crio
- criado
- Criar
- Credenciais
- curioso
- Atual
- Atualmente
- personalizar
- personalizado
- diariamente
- dados,
- análise de dados
- ciência de dados
- cientista de dados
- Visualização de dados
- conjuntos de dados
- dia
- Padrão
- dependente
- descrição
- detalhes
- desenvolver
- Diabetes
- DID
- diferença
- diferente
- documento
- documentação
- INSTITUCIONAIS
- Não faz
- fazer
- não
- download
- distância
- durante
- cada
- Mais cedo
- mais fácil
- Eficaz
- Ovos
- ou
- elefante
- e-mails
- permitir
- habilitado
- criptografia
- Entrar
- erro
- erros
- especialmente
- Éter (ETH)
- eventos
- Cada
- tudo
- exatamente
- Excel
- executar
- existente
- experimentar
- explicado
- Análise exploratória de dados
- explorar
- extenso
- extrato
- Característica
- taxa
- poucos
- Figura
- Envie o
- Arquivos
- preencher
- Encontre
- Primeiro nome
- Fixar
- fixado
- Foco
- seguir
- seguinte
- Escolha
- Antigo
- Gratuito
- freqüentemente
- da
- funcional
- mais distante
- Gênero
- gerar
- gerado
- gera
- gerando
- ter
- OFERTE
- dá
- gmail
- Go
- vai
- Growth
- orientações
- guia
- mão
- Ter
- cabeça
- ajudar
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- oculto
- superior
- altamente
- Horizontal
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- enorme
- Centenas
- i
- idéias
- imediatamente
- Impacto
- importar
- importante
- melhoria
- in
- incluído
- Crescimento
- incrivelmente
- de treinadores em Entrevista Motivacional
- indústrias
- indústria
- INFORMAÇÕES
- em vez disso
- interessado
- Interface
- Introdução
- emitem
- IT
- ESTÁ
- Trabalho
- juntar
- KDnuggetsGenericName
- Saber
- Rótulos
- Terreno
- língua
- grande
- maior
- mais recente
- lançamento
- lançado
- aprendizagem
- Permite
- níveis
- Biblioteca
- como
- Provável
- Line
- linhas
- Lista
- carregar
- localização
- olhou
- procurando
- OLHARES
- lote
- máquina
- aprendizado de máquina
- moldadas
- fazer
- manualmente
- muitos
- Março
- matemática
- matplotlib
- menções
- ir
- mensagem
- poder
- Moda
- modelo
- modelos
- modificada
- modificar
- momento
- mensal
- assinatura mensal
- mais
- a maioria
- mover
- múltiplo
- nome
- Navegar
- você merece...
- Novo
- novo aplicativo
- Recentes
- notícias
- notório
- Novembro
- número
- objeto
- of
- OK
- on
- ONE
- aberto
- OpenAI
- ótimo
- Opção
- Outros
- Resultado
- Supera o desempenho
- saída
- página
- pago
- pandas
- paixão
- Senha
- senhas
- Pagar
- Pessoas
- realizar
- realização
- pessoa
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- mais
- potencial
- poderoso
- antecessor
- predizer
- bastante
- evitar
- anteriormente
- Impressão
- provavelmente
- Problema
- problemas
- Programas
- Progresso
- fornecer
- fornecido
- público
- publicamente
- Python
- Frequentes
- Links
- rapidamente
- Leia
- Leitor
- Leitura
- razões
- receber
- destinatários
- refletida
- liberado
- relevante
- remanescente
- Denunciar
- Relatórios
- requeridos
- exige
- pesquisadores
- responder
- resposta
- resultar
- Resultados
- Execute
- corrida
- mesmo
- Salvar
- Poupança
- diz
- Escala
- programado
- Ciência
- Cientista
- Peneira
- seaborn
- pesquisar
- Seção
- seguro
- segurança
- envio
- sentimento
- conjunto
- rede de apoio social
- mostrar
- periodo
- semelhante
- simples
- simplesmente
- desde
- solteiro
- Tamanho
- menor
- So
- solução
- RESOLVER
- Resolvendo
- alguns
- Fontes
- específico
- especificada
- gastar
- gasto
- fica
- começo
- ficar
- Passo
- Ainda
- Dê um basta
- sujeito
- tudo incluso
- entraram com sucesso
- Sugere
- adequado
- admirado
- sintaxe
- adaptados
- Tire
- tomar
- Target
- Tarefa
- tarefas
- técnicas
- conta
- modelo
- que
- A
- deles
- Eles
- Lá.
- Este
- coisa
- Através da
- tempo
- demorado
- Título
- intitulado
- TLS
- para
- ferramenta
- topo
- Total
- treinado
- Tendências
- Passando
- tutorial
- subjacente
- compreender
- unicode
- atualização
- us
- usar
- Utilizador
- usuários
- geralmente
- valor
- versão
- visível
- Visite a
- visualização
- W
- querido
- Site
- O Quê
- se
- qual
- QUEM
- Wikipedia
- precisarão
- com
- dentro
- Word
- palavras
- Atividades:
- de gestão de documentos
- fluxos de trabalho
- trabalhar
- seria
- escrever
- escrita
- escrito
- investimentos
- zefirnet