Vivemos na era dos dados e insights em tempo real, impulsionados por aplicativos de streaming de dados de baixa latência. Hoje, todos esperam uma experiência personalizada em qualquer aplicação, e as organizações estão constantemente inovando para aumentar a velocidade de operação dos negócios e tomada de decisões. O volume de dados urgentes produzidos está aumentando rapidamente, com diferentes formatos de dados sendo introduzidos em novos negócios e casos de uso de clientes. Portanto, é fundamental que as organizações adotem uma infraestrutura de streaming de dados de baixa latência, escalável e confiável para fornecer aplicativos de negócios em tempo real e melhores experiências aos clientes.
Esta é a primeira postagem de uma série de blogs que oferece padrões de arquitetura comuns na construção de infraestruturas de streaming de dados em tempo real usando o Kinesis Data Streams para uma ampla variedade de casos de uso. Seu objetivo é fornecer uma estrutura para criar aplicativos de streaming de baixa latência na nuvem AWS usando Fluxos de dados do Amazon Kinesis e Serviços de análise de dados desenvolvidos especificamente pela AWS.
Nesta postagem, revisaremos os padrões de arquitetura comuns de dois casos de uso: análise de dados de série temporal e microsserviços orientados a eventos. Na postagem subsequente de nossa série, exploraremos os padrões de arquitetura na construção de pipelines de streaming para painéis de BI em tempo real, agente de contact center, dados contábeis, recomendação personalizada em tempo real, análise de log, dados de IoT, captura de dados de alteração e dados reais. dados de marketing em tempo real. Todos esses padrões de arquitetura são integrados ao Amazon Kinesis Data Streams.
Streaming em tempo real com Kinesis Data Streams
O Amazon Kinesis Data Streams é um serviço de streaming de dados sem servidor e nativo da nuvem que facilita a captura, o processamento e o armazenamento de dados em tempo real em qualquer escala. Com o Kinesis Data Streams, você pode coletar e processar centenas de gigabytes de dados por segundo de centenas de milhares de fontes, permitindo escrever facilmente aplicativos que processam informações em tempo real. Os dados coletados ficam disponíveis em milissegundos para permitir casos de uso de análise em tempo real, como painéis em tempo real, detecção de anomalias em tempo real e preços dinâmicos. Por padrão, os dados no Kinesis Data Stream são armazenados por 24 horas com a opção de aumentar a retenção de dados para 365 dias. Se os clientes quiserem processar os mesmos dados em tempo real com vários aplicativos, eles poderão usar o recurso Enhanced Fan-Out (EFO). Antes desse recurso, cada aplicativo que consumia dados do stream compartilhava a saída de 2 MB/segundo/fragmento. Ao configurar os consumidores de fluxo para usar distribuição aprimorada, cada consumidor de dados recebe um canal dedicado de 2 MB/segundo de taxa de transferência de leitura por fragmento para reduzir ainda mais a latência na recuperação de dados.
Para alta disponibilidade e durabilidade, o Kinesis Data Streams alcança alta durabilidade ao replicar de forma síncrona os dados transmitidos em três zonas de disponibilidade em uma região da AWS e oferece a opção de reter dados por até 365 dias. Para segurança, o Kinesis Data Streams fornece criptografia no lado do servidor para que você possa atender a requisitos rígidos de gerenciamento de dados, criptografando seus dados em repouso e endpoints de interface da Amazon Virtual Private Cloud (VPC) para manter privado o tráfego entre sua Amazon VPC e o Kinesis Data Streams.
Kinesis Data Streams tem integrações nativas com outros serviços da AWS, como Cola AWS e Amazon Event Bridge para criar aplicativos de streaming em tempo real na AWS. Consulte Integrações do Amazon Kinesis Data Streams para obter detalhes adicionais.
Arquitetura moderna de streaming de dados com Kinesis Data Streams
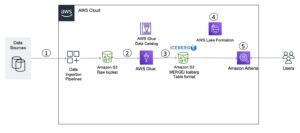
Uma arquitetura moderna de streaming de dados com Kinesis Data Streams pode ser projetada como uma pilha de cinco camadas lógicas; cada camada é composta por vários componentes específicos que atendem a requisitos específicos, conforme ilustrado no diagrama a seguir:
A arquitetura consiste nos seguintes componentes principais:
- Fontes de streaming – Sua fonte de dados de streaming inclui fontes de dados como dados de clickstream, sensores, mídias sociais, dispositivos de Internet das Coisas (IoT), arquivos de log gerados usando seus aplicativos da Web e móveis e dispositivos móveis que geram dados semiestruturados e não estruturados como fluxos contínuos em alta velocidade.
- Ingestão de fluxo – A camada de ingestão de fluxo é responsável por ingerir dados na camada de armazenamento de fluxo. Ele fornece a capacidade de coletar dados de dezenas de milhares de fontes de dados e ingeri-los em tempo real. Você pode usar o SDK do Kinesis para ingestão de dados de streaming por meio de APIs, o Biblioteca do Produtor Kinesis para construir produtores de streaming de alto desempenho e longa duração, ou um Agente Kinesis para coletar um conjunto de arquivos e ingeri-los no Kinesis Data Streams. Além disso, você pode usar muitas integrações pré-construídas, como Serviço de migração de banco de dados AWS (AWS DMS), Amazon DynamoDB e Núcleo da AWS IoT para ingerir dados sem código. Você também pode ingerir dados de plataformas de terceiros, como Apache Spark e Apache Kafka Connect
- Armazenamento de fluxo – O Kinesis Data Streams oferece dois modos de suporte à taxa de transferência de dados: sob demanda e provisionado. O modo sob demanda, agora a opção padrão, pode ser dimensionado de forma elástica para absorver taxas de transferência variáveis, para que os clientes não precisem se preocupar com o gerenciamento de capacidade e pagar pela taxa de transferência de dados. O modo sob demanda aumenta automaticamente 2x a capacidade do stream em relação ao máximo histórico de ingestão de dados para fornecer capacidade suficiente para picos inesperados na ingestão de dados. Alternativamente, os clientes que desejam controle granular sobre os recursos de fluxo podem usar o modo Provisionado e aumentar e diminuir proativamente o número de Shards para atender aos seus requisitos de rendimento. Além disso, o Kinesis Data Streams pode armazenar dados de streaming por até 24 horas por padrão, mas pode estender até 7 dias ou 365 dias, dependendo dos casos de uso. Vários aplicativos podem consumir o mesmo fluxo.
- Processamento de fluxo – A camada de processamento de fluxo é responsável por transformar os dados em um estado consumível por meio de validação, limpeza, normalização, transformação e enriquecimento de dados. Os registros de streaming são lidos na ordem em que são produzidos, permitindo análises em tempo real, construção de aplicativos orientados a eventos ou ETL de streaming (extração, transformação e carregamento). Você pode usar Serviço gerenciado da Amazon para Apache Flink para processamento complexo de dados de fluxo, AWS Lambda para processamento de dados de fluxo sem estado, e Cola AWS & Amazon EMR para computação quase em tempo real. Você também pode criar aplicativos de consumidor personalizados com Biblioteca do Consumidor Kinesis, que cuidará de muitas tarefas complexas associadas à computação distribuída.
- Destino - A camada de destino é como um destino criado especificamente, dependendo do seu caso de uso. Você pode transmitir dados diretamente para Amazon RedShift para armazenamento de dados e Amazon EventBridge para criar aplicativos orientados a eventos. Você também pode usar Mangueira de incêndio de dados do Amazon Kinesis para integração de streaming, onde você pode processar light stream com AWS Lambda e, em seguida, entregar streaming processado em destinos como Amazon S3 data lake, OpenSearch Service para análise operacional, um data warehouse Redshift, bancos de dados No-SQL como Amazon DynamoDB e bancos de dados relacionais como Amazon RDS para consumir fluxos em tempo real em aplicativos de negócios. O destino pode ser um aplicativo orientado a eventos para painéis em tempo real, decisões automáticas baseadas em dados de streaming processados, alterações em tempo real e muito mais.
Arquitetura analítica em tempo real para séries temporais
Os dados de série temporal são uma sequência de pontos de dados registrados durante um intervalo de tempo para medir eventos que mudam ao longo do tempo. Exemplos são preços de ações ao longo do tempo, fluxos de cliques em páginas da web e registros de dispositivos ao longo do tempo. Os clientes podem usar dados de séries temporais para monitorar mudanças ao longo do tempo, para que possam detectar anomalias, identificar padrões e analisar como determinadas variáveis são influenciadas ao longo do tempo. Os dados de série temporal são normalmente gerados a partir de múltiplas fontes em grandes volumes e precisam ser coletados de maneira econômica e quase em tempo real.
Normalmente, existem três objetivos principais que os clientes desejam alcançar no processamento de dados de série temporal:
- Obtenha insights em tempo real sobre o desempenho do sistema e detecte anomalias
- Entenda o comportamento do usuário final para rastrear tendências e consultar/criar visualizações a partir desses insights
- Tenha uma solução de armazenamento durável para ingerir e armazenar dados arquivados e acessados com frequência.
Com o Kinesis Data Streams, os clientes podem capturar continuamente terabytes de dados de séries temporais de milhares de fontes para limpeza, enriquecimento, armazenamento, análise e visualização.
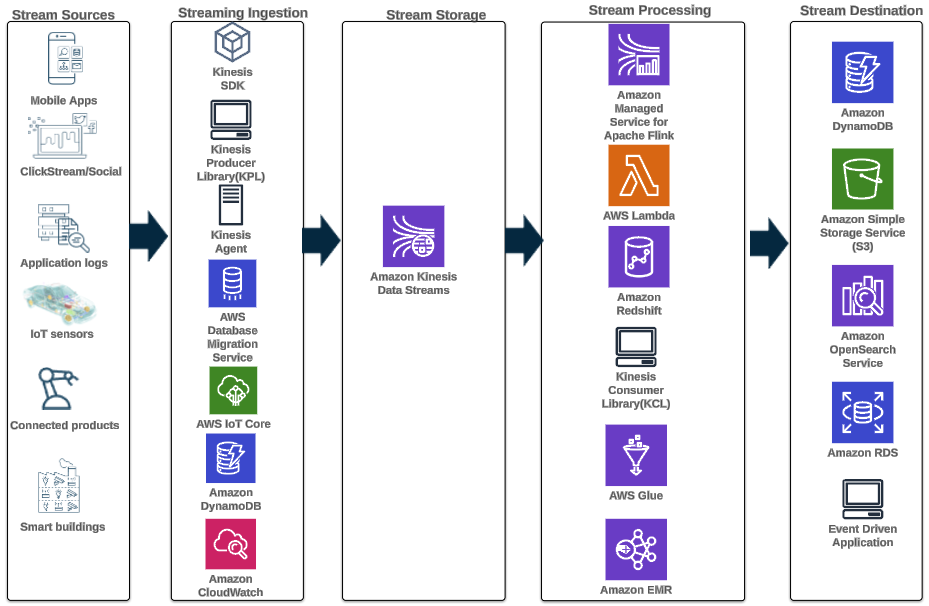
O padrão de arquitetura a seguir ilustra como a análise em tempo real pode ser obtida para dados de série temporal com o Kinesis Data Streams:
As etapas do fluxo de trabalho são as seguintes:
- Ingestão e armazenamento de dados – O Kinesis Data Streams pode capturar e armazenar continuamente terabytes de dados de milhares de fontes.
- Processamento de fluxo – Um aplicativo criado com Serviço gerenciado da Amazon para Apache Flink pode ler os registros do fluxo de dados para detectar e limpar quaisquer erros nos dados da série temporal e enriquecer os dados com metadados específicos para otimizar a análise operacional. Usar um fluxo de dados intermediário oferece a vantagem de usar os dados da série temporal em outros processos e soluções ao mesmo tempo. Uma função Lambda é então invocada com esses eventos e pode realizar cálculos de séries temporais na memória.
- Destinos – Após a limpeza e o enriquecimento, os dados da série temporal processados podem ser transmitidos para Fluxo de tempo da Amazon banco de dados para painéis e análises em tempo real ou armazenado em bancos de dados como DynamoDB para consulta do usuário final. Os dados brutos podem ser transmitidos para o Amazon S3 para arquivamento.
- Visualização e obtenção de insights – Os clientes podem consultar, visualizar e criar alertas usando Serviço gerenciado da Amazon para Grafana. Grafana oferece suporte a fontes de dados que são back-ends de armazenamento para dados de série temporal. Para acessar seus dados do Timestream, você precisa instalar o plugin Timestream para Grafana. Os usuários finais podem consultar dados da tabela do DynamoDB com Gateway de API da Amazon atuando como procurador.
Consulte Processamento quase em tempo real com Amazon Kinesis, Amazon Timestream e Grafana apresentando um pipeline de streaming sem servidor para processar e armazenar dados de IoT de telemetria de dispositivos em um armazenamento de dados otimizado para séries temporais, como o Amazon Timestream.
Enriquecimento e reprodução de dados em tempo real para microsserviços de fornecimento de eventos
Microsserviços são uma abordagem arquitetônica e organizacional para desenvolvimento de software onde o software é composto de pequenos serviços independentes que se comunicam por meio de APIs bem definidas. Ao construir microsserviços orientados a eventos, os clientes desejam alcançar 1. alta escalabilidade para lidar com o volume de eventos recebidos e 2. confiabilidade no processamento de eventos e manter a funcionalidade do sistema diante de falhas.
Os clientes utilizam padrões de arquitetura de microsserviços para acelerar a inovação e o tempo de lançamento de novos recursos no mercado, porque isso torna os aplicativos mais fáceis de escalar e mais rápidos de desenvolver. No entanto, é um desafio enriquecer e reproduzir os dados em uma chamada de rede para outro microsserviço porque isso pode afetar a confiabilidade do aplicativo e dificultar a depuração e o rastreamento de erros. Para resolver esse problema, o fornecimento de eventos é um padrão de design eficaz que centraliza registros históricos de todas as mudanças de estado para enriquecimento e reprodução, e separa as cargas de trabalho de leitura e gravação. Os clientes podem usar o Kinesis Data Streams como armazenamento de eventos centralizado para microsserviços de fornecimento de eventos, porque o KDS pode 1/ lidar com gigabytes de taxa de transferência de dados por segundo por stream e transmitir os dados em milissegundos, para atender aos requisitos de alta escalabilidade e quase em tempo real latência, 2/ integração com Flink e S3 para enriquecimento e obtenção de dados enquanto está completamente desacoplado dos microsserviços, e 3/ permite nova tentativa e leitura assíncrona posteriormente, porque o KDS retém o registro de dados por um padrão de 24 horas e, opcionalmente, até 365 dias.
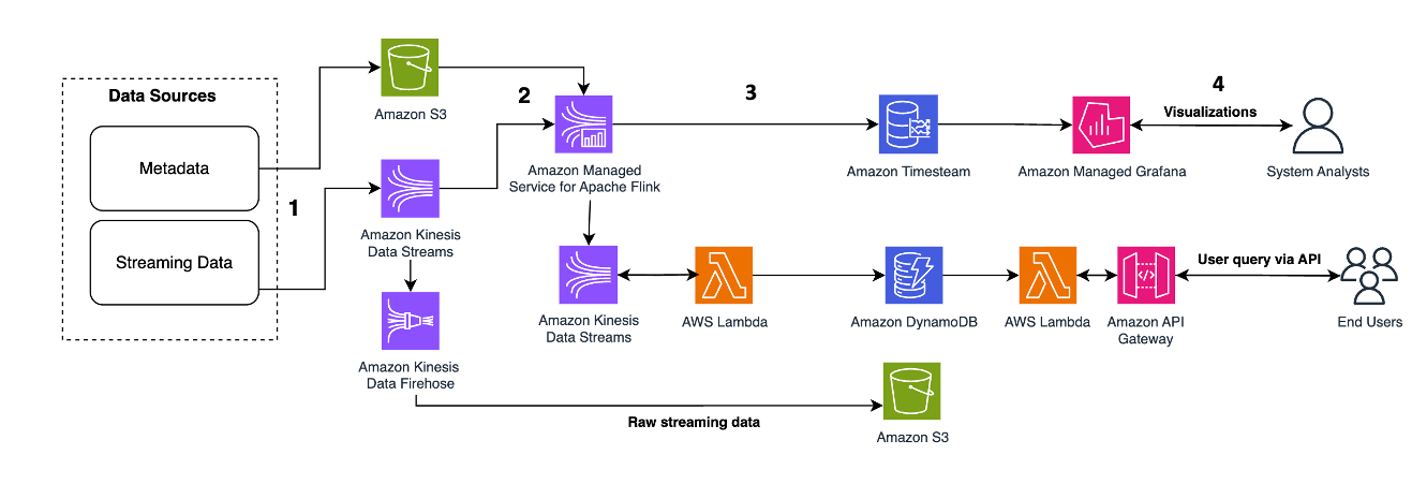
O padrão de arquitetura a seguir é uma ilustração genérica de como o Kinesis Data Streams pode ser usado para microsserviços de fornecimento de eventos:
As etapas do fluxo de trabalho são as seguintes:
- Ingestão e armazenamento de dados – Você pode agregar a entrada dos seus microsserviços ao Kinesis Data Streams para armazenamento.
- Processamento de fluxo - Funções com estado do Apache Flink simplifica a construção de aplicativos distribuídos orientados a eventos com estado. Ele pode receber os eventos de um fluxo de dados de entrada do Kinesis e rotear o fluxo resultante para um fluxo de dados de saída. Você pode criar um cluster de funções com estado com Apache Flink com base na lógica de negócios do seu aplicativo.
- Instantâneo de estado no Amazon S3 – Você pode armazenar o snapshot do estado no Amazon S3 para rastreamento.
- Fluxos de saída – Os fluxos de saída podem ser consumidos por meio de funções remotas Lambda por meio do protocolo HTTP/gRPC por meio do API Gateway.
- Funções remotas Lambda – As funções Lambda podem atuar como microsserviços para vários aplicativos e lógicas de negócios para atender aplicativos de negócios e aplicativos móveis.
Para saber como outros clientes criaram seus microsserviços baseados em eventos com o Kinesis Data Streams, consulte o seguinte:
Principais considerações e práticas recomendadas
A seguir estão considerações e práticas recomendadas a serem lembradas:
- A descoberta de dados deve ser o primeiro passo na construção de aplicativos modernos de streaming de dados. Você deve definir o valor comercial e, em seguida, identificar suas fontes de dados de streaming e personas de usuário para alcançar os resultados comerciais desejados.
- Escolha sua ferramenta de ingestão de dados de streaming com base na sua fonte de dados dinâmica. Por exemplo, você pode usar o SDK do Kinesis para ingestão de dados de streaming por meio de APIs, o Biblioteca do Produtor Kinesis para construir produtores de streaming de alto desempenho e longa duração, um Agente Kinesis para coletar um conjunto de arquivos e ingeri-los no Kinesis Data Streams, AWS DMS para casos de uso de streaming de CDC e Núcleo da AWS IoT para ingerir dados de dispositivos IoT no Kinesis Data Streams. Você pode ingerir dados de streaming diretamente no Amazon Redshift para criar aplicativos de streaming de baixa latência. Você também pode usar bibliotecas de terceiros, como Apache Spark e Apache Kafka, para ingerir dados de streaming no Kinesis Data Streams.
- Você precisa escolher seus serviços de processamento de dados de streaming com base em seu caso de uso específico e nos requisitos de negócios. Por exemplo, você pode usar o Amazon Kinesis Managed Service para Apache Flink para casos de uso de streaming avançado com vários destinos de streaming e processamento complexo de stream com estado ou se quiser monitorar métricas de negócios em tempo real (como a cada hora). Lambda é bom para processamento baseado em eventos e sem estado. Você pode usar Amazon EMR para streaming de processamento de dados para usar suas estruturas de big data de código aberto favoritas. O AWS Glue é bom para processamento de dados de streaming quase em tempo real para casos de uso como streaming de ETL.
- O modo sob demanda do Kinesis Data Streams cobra por uso e aumenta automaticamente a capacidade dos recursos, por isso é ideal para cargas de trabalho de streaming com picos e manutenção sem usar as mãos. O modo provisionado cobra por capacidade e requer gerenciamento proativo de capacidade, por isso é bom para cargas de trabalho de streaming previsíveis.
- Você pode usar o Calculadora compartilhada Kinesis para calcular o número de fragmentos necessários para o modo provisionado. Você não precisa se preocupar com fragmentos no modo sob demanda.
- Ao conceder permissões, você decide quem receberá quais permissões para quais recursos do Kinesis Data Streams. Você habilita ações específicas que deseja permitir nesses recursos. Portanto, você deve conceder apenas as permissões necessárias para executar uma tarefa. Você também pode criptografar os dados em repouso usando uma chave gerenciada pelo cliente (CMK) KMS.
- Você pode atualizar o período de retenção por meio do console do Kinesis Data Streams ou usando o AumentarStreamRetentionPeriod e os votos de DecreaseStreamRetentionPeriod operações com base em seus casos de uso específicos.
- O Kinesis Data Streams oferece suporte refragmentação. A API recomendada para esta função é AtualizarShardCount, que permite modificar o número de fragmentos em seu stream para se adaptar às mudanças na taxa de fluxo de dados através do stream. As APIs de reestilhaçamento (dividir e mesclar) normalmente são usadas para lidar com fragmentos ativos.
Conclusão
Esta postagem demonstrou vários padrões de arquitetura para a criação de aplicativos de streaming de baixa latência com o Kinesis Data Streams. Você pode criar seus próprios aplicativos de vaporização de baixa latência com o Kinesis Data Streams usando as informações desta postagem.
Para padrões arquitetônicos detalhados, consulte os seguintes recursos:
Se você deseja construir uma visão e estratégia de dados, confira o Tudo baseado em dados da AWS (D2E).
Sobre os autores
 Raghavarao Sodabatina é arquiteto de soluções principal na AWS, com foco em análise de dados, IA/ML e segurança na nuvem. Ele se envolve com os clientes para criar soluções inovadoras que abordem os problemas de negócios dos clientes e para acelerar a adoção dos serviços da AWS. Nas horas vagas, Raghavarao gosta de passar tempo com a família, ler livros e assistir filmes.
Raghavarao Sodabatina é arquiteto de soluções principal na AWS, com foco em análise de dados, IA/ML e segurança na nuvem. Ele se envolve com os clientes para criar soluções inovadoras que abordem os problemas de negócios dos clientes e para acelerar a adoção dos serviços da AWS. Nas horas vagas, Raghavarao gosta de passar tempo com a família, ler livros e assistir filmes.
 Pendure Zuo é gerente sênior de produtos da equipe Amazon Kinesis Data Streams na Amazon Web Services. Ele é apaixonado pelo desenvolvimento de experiências de produtos intuitivas que resolvem problemas complexos do cliente e permitem que os clientes alcancem suas metas de negócios.
Pendure Zuo é gerente sênior de produtos da equipe Amazon Kinesis Data Streams na Amazon Web Services. Ele é apaixonado pelo desenvolvimento de experiências de produtos intuitivas que resolvem problemas complexos do cliente e permitem que os clientes alcancem suas metas de negócios.
 Shwetha Radhakrishnan é arquiteto de soluções para AWS com foco em análise de dados. Ela tem desenvolvido soluções que impulsionam a adoção da nuvem e ajudam as organizações a tomar decisões baseadas em dados no setor público. Fora do trabalho, ela adora dançar, passar tempo com amigos e familiares e viajar.
Shwetha Radhakrishnan é arquiteto de soluções para AWS com foco em análise de dados. Ela tem desenvolvido soluções que impulsionam a adoção da nuvem e ajudam as organizações a tomar decisões baseadas em dados no setor público. Fora do trabalho, ela adora dançar, passar tempo com amigos e familiares e viajar.
 Brittany Ly é arquiteto de soluções na AWS. Ela está focada em ajudar clientes corporativos em sua jornada de adoção e modernização da nuvem e tem interesse na área de segurança e análise. Fora do trabalho, ela adora ficar com o cachorro e jogar pickleball.
Brittany Ly é arquiteto de soluções na AWS. Ela está focada em ajudar clientes corporativos em sua jornada de adoção e modernização da nuvem e tem interesse na área de segurança e análise. Fora do trabalho, ela adora ficar com o cachorro e jogar pickleball.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 100
- 24
- 7
- a
- habilidade
- Sobre
- acelerar
- Acesso
- acessadas
- Alcançar
- alcançado
- Alcança
- alcançar
- em
- Aja
- atuação
- ações
- adaptar
- Adição
- Adicional
- Adicionalmente
- endereço
- Adoção
- avançado
- Vantagem
- Depois de
- idade
- Agente
- agregar
- AI / ML
- visa
- alertas
- Todos os Produtos
- permitir
- Permitindo
- permite
- tb
- Amazon
- Amazon Kinesis
- Fluxo de tempo da Amazon
- Amazon Web Services
- an
- análise
- analítica
- analisar
- e
- detecção de anomalia
- Outro
- qualquer
- apache
- Apache Kafka
- Apache Spark
- api
- APIs
- Aplicação
- aplicações
- abordagem
- Aplicativos
- arquitetônico
- arquitetura
- SOMOS
- AS
- associado
- At
- Automático
- automaticamente
- disponibilidade
- disponível
- AWS
- Cola AWS
- AWS Lambda
- baseado
- BE
- Porque
- sido
- comportamento
- ser
- MELHOR
- melhores práticas
- Melhor
- entre
- Grande
- Big Data
- Blog
- Livros
- ambos
- construir
- Prédio
- construído
- negócio
- Aplicações de Negócio
- negócios
- mas a
- by
- calcular
- chamada
- CAN
- Capacidade
- capturar
- Cuidado
- casas
- casos
- CDC
- Centralização de
- centralizada
- certo
- desafiante
- alterar
- Alterações
- acusações
- verificar
- escolha
- Escolha
- limpar
- Limpeza
- Na nuvem
- adoção de nuvem
- Cloud Security
- Agrupar
- coletar
- Coleta
- comum
- comunicar
- completamente
- integrações
- componentes
- composta
- Computar
- computação
- preocupado
- configurando
- Considerações
- consiste
- cônsul
- constantemente
- consumir
- consumida
- consumidor
- Consumidores
- Contacto
- contact center
- contínuo
- continuamente
- ao controle
- crio
- criado
- crítico
- cliente
- Clientes
- personalizado
- Dançando
- painéis
- dados,
- análise de dados
- Análise de Dados
- enriquecimento de dados
- lago data
- gestão de dados
- Os pontos de dados
- informática
- data warehouse
- orientado por dados
- banco de dados
- bases de dados
- dias
- decidir
- decisão
- Tomada de Decisão
- decisões
- desacoplado
- dedicado
- Padrão
- definir
- entregar
- demonstraram
- Dependendo
- Design
- projetado
- desejado
- destino
- destinos
- detalhado
- detalhes
- descobrir
- Detecção
- desenvolver
- em desenvolvimento
- Desenvolvimento
- dispositivo
- Dispositivos/Instrumentos
- diferente
- difícil
- diretamente
- descoberta
- distribuído
- computação distribuída
- do
- Cachorro
- não
- down
- distância
- dirigido
- durabilidade
- dinâmico
- cada
- mais fácil
- facilmente
- fácil
- Eficaz
- abraços
- permitir
- criptografia
- endpoints
- envolve
- aprimorada
- enriquecer
- Empreendimento
- clientes corporativos
- erros
- Éter (ETH)
- Evento
- eventos
- Cada
- todos
- exemplo
- exemplos
- espera
- vasta experiência
- Experiências
- explorar
- estender
- extrato
- Rosto
- falhas
- família
- Moda
- mais rápido
- Favorito
- Característica
- Funcionalidades
- campo
- Arquivos
- Primeiro nome
- cinco
- fluxo
- Foco
- focado
- focando
- seguinte
- segue
- Escolha
- Quadro
- enquadramentos
- freqüentemente
- amigos
- da
- função
- funcionalidade
- funções
- mais distante
- Ganho
- porta de entrada
- gerar
- gerado
- obtendo
- GitHub
- dá
- Objetivos
- Bom estado, com sinais de uso
- conceder
- concessão
- manipular
- Aguentar
- he
- ajudar
- ajuda
- sua experiência
- Alta
- alta performance
- sua
- histórico
- HOT
- hora
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Contudo
- HTML
- http
- HTTPS
- Centenas
- identificar
- if
- ilustra
- Impacto
- in
- Em outra
- inclui
- Entrada
- Crescimento
- aumentando
- de treinadores em Entrevista Motivacional
- influenciado
- INFORMAÇÕES
- Infraestrutura
- infra-estrutura
- inovando
- Inovação
- inovadores
- entrada
- insights
- instalar
- integrar
- integrado
- integração
- integrações
- interesse
- Interface
- Internet
- internet das coisas
- para dentro
- introduzido
- intuitivo
- invocado
- iot
- Dispositivo IoT
- IT
- ESTÁ
- viagem
- jpg
- Kafka
- Guarda
- Chave
- Streams de dados Kinesis
- lago
- Latência
- mais tarde
- camada
- camadas
- APRENDER
- Ledger
- bibliotecas
- Biblioteca
- leve
- como
- vida
- carregar
- log
- lógica
- lógico
- ama
- a manter
- manutenção
- fazer
- FAZ
- Fazendo
- gerenciados
- de grupos
- Gerente
- muitos
- Marketing
- máximo
- medição
- Mídia
- Conheça
- Memória
- ir
- metadados
- Métrica
- microsserviços
- Coração
- migração
- milissegundos
- mente
- Móvel Esteira
- Aplicações móveis
- dispositivos móveis
- aplicativos móveis
- Moda
- EQUIPAMENTOS
- modernização
- modos
- modificar
- Monitore
- mais
- Filmes
- múltiplo
- devo
- nativo
- Perto
- você merece...
- necessário
- Cria
- rede
- Novo
- Novos Recursos
- agora
- número
- of
- oferecer
- Oferece
- on
- Sob demanda
- só
- aberto
- open source
- operação
- operacional
- Operações
- Otimize
- otimizado
- Opção
- or
- ordem
- organizacional
- organizações
- Outros
- A Nossa
- Fora
- resultados
- saída
- lado de fora
- Acima de
- próprio
- parte
- apaixonado
- padrão
- padrões
- Pagar
- para
- realizar
- atuação
- permissões
- Personalizado
- tubo
- oleoduto
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- plug-in
- pontos
- Publique
- práticas
- Previsível
- Valores
- preços
- primário
- Diretor
- Prévio
- privado
- Proactive
- Problema
- problemas
- processo
- processado
- processos
- em processamento
- Produzido
- produtor
- Produtores
- Produto
- gerente de produto
- Agenda
- protocolo
- fornecer
- fornece
- procuração
- público
- alcance
- rapidamente
- Taxa
- Cru
- dados não tratados
- Leia
- Leitura
- reais
- em tempo real
- dados em tempo real
- receber
- recebe
- Recomendação
- Recomenda
- registro
- gravado
- registros
- reduzir
- referir
- região
- confiabilidade
- confiável
- remoto
- requeridos
- requerimento
- Requisitos
- exige
- recurso
- Recursos
- responsável
- DESCANSO
- resultando
- reter
- Retém
- retenção
- rever
- Rota
- mesmo
- AMPLIAR
- escalável
- Escala
- Escalas
- Segundo
- setor
- segurança
- senior
- sensor
- Seqüência
- Série
- servir
- Serverless
- serviço
- Serviços
- conjunto
- compartilhado
- ela
- rede de apoio social
- apresentando
- simplifica
- pequeno
- Instantâneo
- So
- Redes Sociais
- meios de comunicação social
- Software
- desenvolvimento de software
- solução
- Soluções
- RESOLVER
- fonte
- Fontes
- Faísca
- específico
- velocidade
- gastar
- Passar
- picos
- divisão
- pilha
- Estado
- Passo
- Passos
- estoque
- armazenamento
- loja
- armazenadas
- Estratégia
- transmitir canais
- fluídas
- de streaming
- córregos
- rigoroso
- subseqüente
- tal
- suficiente
- ajuda
- suportes
- .
- mesa
- Tire
- Tarefa
- tarefas
- Profissionais
- dezenas
- que
- A
- as informações
- O Estado
- deles
- Eles
- então
- Lá.
- assim sendo
- Este
- deles
- coisas
- De terceiros
- isto
- aqueles
- milhares
- três
- Através da
- Taxa de transferência
- tempo
- Séries temporais
- sensível ao tempo
- para
- hoje
- ferramenta
- traçar
- pista
- Rastreamento
- tráfego
- Transformar
- Transformação
- transformando
- Viagens
- Tendências
- dois
- tipicamente
- Inesperado
- sobre
- Uso
- usar
- caso de uso
- usava
- Utilizador
- utilização
- utilizar
- validação
- valor
- variável
- vário
- Velocidade
- via
- Virtual
- visão
- visualização
- visualizar
- volume
- volumes
- queremos
- Armazém
- Armazenagem
- assistindo
- we
- web
- serviços web
- bem definido
- O Quê
- quando
- qual
- enquanto
- QUEM
- Largo
- Ampla variedade
- precisarão
- de
- dentro
- Atividades:
- de gestão de documentos
- preocupar-se
- escrever
- Você
- investimentos
- zefirnet
- zonas