A importância dos data warehouses e análises realizadas em plataformas de data warehouse tem aumentado constantemente ao longo dos anos, com muitas empresas passando a confiar nesses sistemas como missão crítica para tomada de decisões operacionais de curto prazo e planejamento estratégico de longo prazo. Tradicionalmente, os data warehouses são atualizados em ciclos de lote, por exemplo, mensalmente, semanalmente ou diariamente, para que as empresas possam obter vários insights deles.
Muitas organizações estão percebendo que a ingestão de dados quase em tempo real, juntamente com análises avançadas, abre novas oportunidades. Por exemplo, uma instituição financeira pode prever se uma transação com cartão de crédito é fraudulenta executando um programa de detecção de anomalias em modo quase em tempo real, em vez de em lote.
Neste post, mostramos como Amazon RedShift pode fornecer ingestão de streaming e previsões de machine learning (ML) em uma única plataforma.
O Amazon Redshift é um data warehouse em nuvem rápido, escalável, seguro e totalmente gerenciado que torna simples e econômica a análise de todos os seus dados usando SQL padrão.
Amazon RedshiftML torna mais fácil para analistas de dados e desenvolvedores de banco de dados criar, treinar e aplicar modelos de ML usando comandos SQL familiares em data warehouses do Amazon Redshift.
Estamos animados para lançar Ingestão de streaming do Amazon Redshift para Fluxos de dados do Amazon Kinesis e Amazon Managed Streaming para Apache Kafka (Amazon MSK), que permite ingerir dados diretamente de um Kinesis data stream ou tópico Kafka sem precisar preparar os dados em Serviço de armazenamento simples da Amazon (Amazônia S3). A ingestão de streaming do Amazon Redshift permite que você obtenha baixa latência na ordem de segundos enquanto ingere centenas de megabytes de dados em seu data warehouse.
Esta postagem demonstra como o Amazon Redshift, o data warehouse na nuvem, permite que você crie previsões de ML quase em tempo real usando a ingestão de streaming do Amazon Redshift e os recursos do Redshift ML com linguagem SQL familiar.
Visão geral da solução
Seguindo as etapas descritas nesta postagem, você poderá configurar um aplicativo de streamer produtor em um Amazon Elastic Compute Nuvem (Amazon EC2) instância que simula transações de cartão de crédito e envia dados para o Kinesis Data Streams em tempo real. Você configura uma visualização materializada de ingestão de streaming do Amazon Redshift no Amazon Redshift, onde os dados de streaming são recebidos. Você treina e constrói um modelo Redshift ML para gerar inferências em tempo real em relação aos dados de streaming.
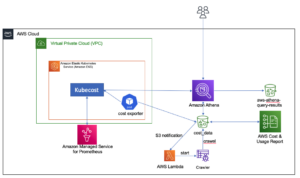
O diagrama a seguir ilustra a arquitetura e o fluxo do processo.
O processo passo a passo é o seguinte:
- A instância do EC2 simula um aplicativo de transação de cartão de crédito, que insere transações de cartão de crédito no Kinesis data stream.
- O fluxo de dados armazena os dados de entrada da transação de cartão de crédito.
- Uma visualização materializada do Amazon Redshift Streaming Ingestion é criada sobre o fluxo de dados, que ingere automaticamente os dados de streaming no Amazon Redshift.
- Você cria, treina e implanta um modelo de ML usando o Redshift ML. O modelo Redshift ML é treinado usando dados transacionais históricos.
- Você transforma os dados de streaming e gera previsões de ML.
- Você pode alertar os clientes ou atualizar o aplicativo para reduzir o risco.
Este passo a passo usa dados de streaming de transação de cartão de crédito. Os dados da transação do cartão de crédito são fictícios e são baseados em um simulador. O conjunto de dados do cliente também é fictício e é gerado com algumas funções de dados aleatórios.
Pré-requisitos
- Crie um cluster Amazon Redshift.
- Configure o cluster para usar o Redshift ML.
- Crie an Gerenciamento de acesso e identidade da AWS (IAM) usuário.
- Atualize a função do IAM anexada ao cluster Redshift para incluir permissões para acessar o Kinesis data stream. Para obter mais informações sobre a política necessária, consulte Introdução ao processamento de streaming.
- Criar uma instância EC5.4 m2xlarge. Testamos o aplicativo Producer com a instância m5.4xlarge, mas você pode usar outro tipo de instância. Ao criar a instância, use o amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 AMI.
- Para garantir que o Python3 esteja instalado na instância do EC2, execute o seguinte comando para verificar sua versão do Python (observe que o script de extração de dados funciona apenas no Python 3):
- Instale os seguintes pacotes dependentes para executar o programa simulador:
- Configure o Amazon EC2 usando as variáveis como as credenciais da AWS geradas para o usuário IAM criado na etapa 3 acima. A captura de tela a seguir mostra um exemplo usando aws configurar.

Configurar Kinesis Data Streams
O Amazon Kinesis Data Streams é um serviço de streaming de dados em tempo real altamente escalável e durável. Ele pode capturar continuamente gigabytes de dados por segundo de centenas de milhares de fontes, como fluxos de cliques de sites, fluxos de eventos de banco de dados, transações financeiras, feeds de mídia social, logs de TI e eventos de rastreamento de localização. Os dados coletados estão disponíveis em milissegundos para permitir casos de uso de análise em tempo real, como painéis em tempo real, detecção de anomalias em tempo real, preços dinâmicos e muito mais. Usamos o Kinesis Data Streams porque é uma solução sem servidor que pode ser dimensionada com base no uso.
Criar um stream de dados do Kinesis
Primeiro, você precisa criar um Kinesis data stream para receber os dados de streaming:
- No console do Amazon Kinesis, escolha Fluxos de dados no painel de navegação.
- Escolha Criar fluxo de dados.
- Escolha Nome do fluxo de dados, entrar
cust-payment-txn-stream. - Escolha Modo de capacidade, selecione Sob demanda.

- Para o restante das opções, escolha as opções padrão e siga as instruções para concluir a configuração.
- Capture o ARN para o fluxo de dados criado para usar na próxima seção ao definir sua política IAM.

Configurar permissões
Para que um aplicativo de streaming grave no Kinesis Data Streams, o aplicativo precisa ter acesso ao Kinesis. Você pode usar a seguinte declaração de política para conceder ao processo do simulador que você configurou na próxima seção acesso ao fluxo de dados. Use o ARN do fluxo de dados que você salvou na etapa anterior.
Configurar o produtor de stream
Antes de podermos consumir dados de streaming no Amazon Redshift, precisamos de uma fonte de dados de streaming que grave dados no Kinesis data stream. Esta postagem usa um gerador de dados personalizado e o SDK da AWS para Python (Boto3) para publicar os dados no fluxo de dados. Para obter instruções de configuração, consulte Simulador de produtor. Este processo de simulador publica dados de streaming no fluxo de dados criado na etapa anterior (cust-payment-txn-stream).
Configurar o consumidor de stream
Esta seção fala sobre como configurar o consumidor de stream (a exibição de ingestão de streaming do Amazon Redshift).
O Amazon Redshift Streaming Ingestion fornece ingestão de baixa latência e alta velocidade de dados de streaming do Kinesis Data Streams em uma visualização materializada do Amazon Redshift. Você pode configurar seu cluster do Amazon Redshift para habilitar a ingestão de streaming e criar uma visualização materializada com atualização automática, usando instruções SQL, conforme descrito em Criando visualizações materializadas no Amazon Redshift. O processo automático de atualização de visualização materializada ingerirá dados de streaming em centenas de megabytes de dados por segundo do Kinesis Data Streams para o Amazon Redshift. Isso resulta em acesso rápido a dados externos que são atualizados rapidamente.
Depois de criar a visualização materializada, você pode acessar seus dados do fluxo de dados usando SQL e simplificar seus pipelines de dados criando visualizações materializadas diretamente no fluxo.
Conclua as etapas a seguir para configurar uma visualização materializada de streaming do Amazon Redshift:
- No console do IAM, escolha as políticas no painel de navegação.
- Escolha Criar política.
- Crie uma nova política IAM chamada
KinesisStreamPolicy. Para a definição da política de streaming, consulte Introdução ao processamento de streaming. - No painel de navegação, escolha Setores.
- Escolha Criar função.
- Selecionar Serviço AWS e escolha Redshift e Redshift personalizáveis.
- Crie uma nova função chamada
redshift-streaming-rolee anexe a políticaKinesisStreamPolicy. - Crie um esquema externo para mapear para o Kinesis Data Streams:
Agora você pode criar uma visualização materializada para consumir os dados do stream. Você pode usar o tipo de dados SUPER para armazenar a carga como está, no formato JSON, ou usar as funções JSON do Amazon Redshift para analisar os dados JSON em colunas individuais. Para este post, usamos o segundo método porque o esquema está bem definido.
- Crie a visualização materializada de ingestão de streaming
cust_payment_tx_stream. Ao especificar AUTO REFRESH YES no código a seguir, você pode habilitar a atualização automática da exibição de ingestão de streaming, o que economiza tempo ao evitar a criação de pipelines de dados:
Observe que json_extract_path_text tem uma limitação de comprimento de 64 KB. Além disso, from_varbye filtra registros maiores que 65 KB.
- Atualize os dados.
A visualização materializada de streaming do Amazon Redshift é atualizada automaticamente pelo Amazon Redshift para você. Dessa forma, você não precisa se preocupar com a desatualização dos dados. Com a atualização automática da visualização materializada, os dados são carregados automaticamente no Amazon Redshift assim que ficam disponíveis no stream. Se você optar por executar manualmente esta operação, use o seguinte comando:
- Agora vamos consultar a visualização materializada de streaming para ver os dados de exemplo:

- Vamos verificar quantos registros estão na exibição de streaming agora:

Agora você concluiu a configuração da exibição de ingestão de streaming do Amazon Redshift, que é continuamente atualizada com dados de transações de cartão de crédito recebidos. Em minha configuração, vejo que cerca de 67,000 registros foram inseridos na exibição de streaming no momento em que executei minha consulta de contagem selecionada. Este número pode ser diferente para você.
Redshift ML
Com o Redshift ML, você pode trazer um modelo de ML pré-treinado ou criar um nativamente. Para mais informações, consulte Usar machine learning no Amazon Redshift.
Nesta postagem, treinamos e construímos um modelo de ML usando um conjunto de dados históricos. Os dados contêm um tx_fraud campo que sinaliza uma transação histórica como fraudulenta ou não. Construímos um modelo de ML supervisionado usando o Redshift Auto ML, que aprende com esse conjunto de dados e prevê as transações recebidas quando elas são executadas por meio das funções de previsão.
Nas seções a seguir, mostramos como configurar o conjunto de dados históricos e os dados do cliente.
Carregar o conjunto de dados históricos
A tabela histórica tem mais campos do que a fonte de dados de streaming. Esses campos contêm os gastos mais recentes do cliente e a pontuação de risco do terminal, como o número de transações fraudulentas computadas pela transformação de dados de streaming. Também existem variáveis categóricas, como transações de fim de semana ou transações noturnas.
Para carregar os dados históricos, execute os comandos usando o Editor de consultas do Amazon Redshift.
Crie a tabela de histórico de transações com o seguinte código. O DDL também pode ser encontrado em GitHub.
Vamos verificar quantas transações foram carregadas:
Confira a tendência mensal de transações fraudulentas e não fraudulentas:
Criar e carregar dados do cliente
Agora criamos a tabela de clientes e carregamos os dados, que contém o e-mail e o telefone do cliente. O código a seguir cria a tabela, carrega os dados e faz uma amostra da tabela. A tabela DDL está disponível em GitHub.
Nossos dados de teste têm cerca de 5,000 clientes. A captura de tela a seguir mostra dados de amostra do cliente.

Construir um modelo de ML
Nossa tabela histórica de transações de cartão tem 6 meses de dados, que agora usamos para treinar e testar o modelo de ML.
O modelo usa os seguintes campos como entrada:
Nós temos tx_fraud como saída.
Dividimos esses dados em conjuntos de dados de treinamento e teste. As transações de 2022/04/01 a 2022/07/31 são para o conjunto de treinamento. As transações de 2022/08/01 a 2022/09/30 são usadas para o conjunto de teste.
Vamos criar o modelo de ML usando o SQL familiar instrução CREATE MODEL. Usamos uma forma básica do comando Redshift ML. O seguinte método usa Piloto automático do Amazon SageMaker, que executa a preparação de dados, engenharia de recursos, seleção de modelo e treinamento automaticamente para você. Forneça o nome do seu bucket S3 que contém o código.
Eu chamo o modelo de ML como Cust_cc_txn_fd, e a função de previsão como fn_customer_cc_fd. A cláusula FROM mostra as colunas de entrada da tabela histórica public.cust_payment_tx_history. O parâmetro de destino é definido como tx_fraud, que é a variável de destino que estamos tentando prever. IAM_Role está definido como padrão porque o cluster está configurado com esta função; caso contrário, você deve fornecer o ARN da função IAM do cluster do Amazon Redshift. eu defino o max_runtime para 3,600 segundos, que é o tempo que damos ao SageMaker para concluir o processo. O Redshift ML implanta o melhor modelo identificado nesse período de tempo.
Dependendo da complexidade do modelo e da quantidade de dados, pode levar algum tempo para que o modelo esteja disponível. Se você achar que sua seleção de modelo não está completa, aumente o valor para max_runtime. Você pode definir um valor máximo de 9999.
O comando CREATE MODEL é executado de forma assíncrona, o que significa que é executado em segundo plano. Você pode usar o MOSTRAR MODELO comando para ver o status do modelo. Quando o status é exibido como Pronto, significa que o modelo foi treinado e implantado.
As capturas de tela a seguir mostram nossa saída.



Na saída, vejo que o modelo foi reconhecido corretamente como BinaryClassification, e F1 foi selecionado como o objetivo. o Pontuação F1 é uma métrica que considera tanto precisão e recall. Ele retorna um valor entre 1 (precisão e recuperação perfeitas) e 0 (menor pontuação possível). No meu caso, é 0.91. Quanto maior o valor, melhor o desempenho do modelo.
Vamos testar esse modelo com o conjunto de dados de teste. Execute o seguinte comando, que recupera previsões de amostra:

Vemos que alguns valores são correspondentes e outros não. Vamos comparar as previsões com a verdade básica:

Validamos que o modelo está funcionando e a pontuação da F1 é boa. Vamos passar para a geração de previsões sobre dados de streaming.
Prever transações fraudulentas
Como o modelo Redshift ML está pronto para uso, podemos usá-lo para executar as previsões contra a ingestão de dados de streaming. O conjunto de dados históricos tem mais campos do que temos na fonte de dados de streaming, mas eles são apenas métricas recentes e de frequência em torno do risco do cliente e do terminal para uma transação fraudulenta.
Podemos aplicar as transformações sobre os dados de streaming com muita facilidade incorporando o SQL dentro das visualizações. Crie o primeira vista, que agrega dados de streaming no nível do cliente. Em seguida, crie o segunda vista, que agrega dados de streaming no nível do terminal, e o terceira visão, que combina dados transacionais de entrada com dados agregados de cliente e terminal e chama a função de previsão em um só lugar. O código para a terceira visualização é o seguinte:
Execute uma instrução SELECT na exibição:
À medida que você executa a instrução SELECT repetidamente, as últimas transações de cartão de crédito passam por transformações e previsões de ML quase em tempo real.
Isso demonstra o poder do Amazon Redshift — com comandos SQL fáceis de usar, você pode transformar dados de streaming aplicando funções de janela complexas e aplicar um modelo de ML para prever transações fraudulentas em uma única etapa, sem criar pipelines de dados complexos ou criar e gerenciar infraestrutura adicional.
Expanda a solução
Como os fluxos de dados e as previsões de ML são feitos quase em tempo real, você pode criar processos de negócios para alertar seu cliente usando Serviço de notificação simples da Amazon (Amazon SNS), ou você pode bloquear a conta do cartão de crédito do cliente em um sistema operacional.
Esta postagem não aborda os detalhes dessas operações, mas se você estiver interessado em aprender mais sobre a criação de soluções orientadas a eventos usando o Amazon Redshift, consulte o seguinte Repositório GitHub.
limpar
Para evitar cobranças futuras, exclua os recursos que foram criados como parte desta postagem.
Conclusão
Nesta postagem, demonstramos como configurar um fluxo de dados do Kinesis, configurar um produtor e publicar dados em fluxos e, em seguida, criar uma exibição de ingestão de streaming do Amazon Redshift e consultar os dados no Amazon Redshift. Depois que os dados estavam no cluster do Amazon Redshift, demonstramos como treinar um modelo de ML e criar uma função de previsão e aplicá-la aos dados de streaming para gerar previsões quase em tempo real.
Se você tiver algum comentário ou dúvida, por favor, deixe-os nos comentários.
Sobre os autores
 Bhanu Pittampally é um arquiteto de soluções especialista em análise baseado em Dallas. Ele é especialista na construção de soluções analíticas. Sua formação é em data warehouses — arquitetura, desenvolvimento e administração. Ele está no campo de dados e análises há mais de 15 anos.
Bhanu Pittampally é um arquiteto de soluções especialista em análise baseado em Dallas. Ele é especialista na construção de soluções analíticas. Sua formação é em data warehouses — arquitetura, desenvolvimento e administração. Ele está no campo de dados e análises há mais de 15 anos.
 Praveen Kadipiconda é Arquiteto de Soluções Especialista em Análise Sênior na AWS baseado em Dallas. Ele ajuda os clientes a criar soluções analíticas eficientes, de alto desempenho e escaláveis. Ele trabalhou com a construção de bancos de dados e soluções de data warehouse por mais de 15 anos.
Praveen Kadipiconda é Arquiteto de Soluções Especialista em Análise Sênior na AWS baseado em Dallas. Ele ajuda os clientes a criar soluções analíticas eficientes, de alto desempenho e escaláveis. Ele trabalhou com a construção de bancos de dados e soluções de data warehouse por mais de 15 anos.
 Ritesh Kumar Sinha é um arquiteto de soluções especialista em análise baseado em San Francisco. Ele ajudou os clientes a criar armazenamento de dados escalável e soluções de big data por mais de 16 anos. Ele adora projetar e construir soluções eficientes de ponta a ponta na AWS. Em seu tempo livre, ele adora ler, caminhar e praticar ioga.
Ritesh Kumar Sinha é um arquiteto de soluções especialista em análise baseado em San Francisco. Ele ajudou os clientes a criar armazenamento de dados escalável e soluções de big data por mais de 16 anos. Ele adora projetar e construir soluções eficientes de ponta a ponta na AWS. Em seu tempo livre, ele adora ler, caminhar e praticar ioga.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/near-real-time-fraud-detection-using-amazon-redshift-streaming-ingestion-with-amazon-kinesis-data-streams-and-amazon-redshift-ml/
- 000
- 000 clientes
- 1
- 10
- 100
- 11
- 15 anos
- 67
- 7
- 9
- a
- Capaz
- Sobre
- acima
- Acesso
- Conta
- Alcançar
- Açao Social
- Adicional
- administração
- avançado
- Depois de
- contra
- Alertar
- Todos os Produtos
- permite
- Amazon
- Amazon EC2
- Amazon Kinesis
- quantidade
- Analistas
- Analítico
- analítica
- analisar
- e
- detecção de anomalia
- apache
- Aplicação
- Aplicar
- Aplicando
- arquitetura
- por aí
- anexar
- auto
- Automático
- automaticamente
- disponível
- evitando
- AWS
- fundo
- baseado
- basic
- Porque
- torna-se
- MELHOR
- Melhor
- entre
- Grande
- Big Data
- trazer
- construir
- Prédio
- negócio
- processos de negócios
- negócios
- chamada
- chamado
- chamadas
- capturar
- cartão
- casas
- casos
- personagem
- acusações
- verificar
- Escolha
- Cidades
- Na nuvem
- Agrupar
- código
- colunas
- combina
- vinda
- comentários
- comparar
- completar
- completando
- integrações
- complexidade
- Computar
- considera
- cônsul
- consumir
- consumidor
- contém
- relação custo-benefício
- poderia
- crio
- criado
- cria
- Criar
- Credenciais
- crédito
- cartão de crédito
- cliente
- dados do cliente
- Clientes
- ciclos
- diariamente
- Dallas
- dados,
- Preparação de dados
- data warehouse
- armazéns de dados
- banco de dados
- bases de dados
- conjuntos de dados
- Data
- Tomada de Decisão
- Padrão
- definição
- entregar
- demonstraram
- dependente
- implantar
- implantado
- implanta
- descrito
- Design
- detalhes
- Detecção
- desenvolvedores
- Desenvolvimento
- diferente
- diretamente
- Não faz
- fazer
- não
- Dow
- dinâmico
- facilmente
- fácil de usar
- efeito
- eficiente
- permitir
- permite
- end-to-end
- Engenharia
- Entrar
- Éter (ETH)
- Evento
- eventos
- exemplo
- animado
- externo
- Extração
- f1
- familiar
- RÁPIDO
- Característica
- Funcionalidades
- retornos
- campo
- Campos
- filtros
- financeiro
- Encontre
- bandeiras
- fluxo
- seguir
- seguinte
- segue
- formulário
- formato
- encontrado
- QUADRO
- Francisco
- fraude
- detecção de fraude
- Gratuito
- Frequência
- da
- totalmente
- função
- funções
- futuro
- gerar
- gerado
- gerando
- gerador
- ter
- OFERTE
- Go
- Bom estado, com sinais de uso
- conceder
- Solo
- Grupo
- ter
- ajudou
- ajuda
- superior
- Destaques
- histórico
- história
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- Centenas
- IAM
- identificado
- Identidade
- importância
- in
- incluir
- Entrada
- Crescimento
- aumentando
- Individual
- INFORMAÇÕES
- Infraestrutura
- entrada
- Inserções
- insights
- instalar
- instância
- Instituto
- instruções
- interessado
- IT
- juntar
- json
- Kafka
- Streams de dados Kinesis
- língua
- Maior
- Latência
- mais recente
- lançamento
- aprendizagem
- Deixar
- Comprimento
- Nível
- LIMITE
- limitação
- carregar
- cargas
- longo prazo
- Baixo
- máquina
- aprendizado de máquina
- moldadas
- fazer
- FAZ
- gerenciados
- gestão
- manualmente
- muitos
- mapa,
- massivamente
- correspondente
- matplotlib
- max
- significa
- Mídia
- método
- métrico
- Métrica
- Mitigar
- ML
- Moda
- modelo
- modelos
- mensal
- mês
- mais
- a maioria
- mover
- nome
- Navegação
- você merece...
- Cria
- Novo
- Próximo
- notificação
- número
- numpy
- objetivo
- ONE
- abre
- operação
- operacional
- Operações
- oportunidades
- Opções
- ordem
- organizações
- Outros
- delineado
- pacotes
- pandas
- pão
- parâmetro
- parte
- perfeita
- realizar
- atuação
- executa
- permissões
- telefone
- Lugar
- planejamento
- plataforma
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- políticas
- Privacidade
- possível
- Publique
- poder
- Precisão
- predizer
- predição
- Previsões
- Previsões
- anterior
- preços
- processo
- processos
- produtor
- Agenda
- fornecer
- fornece
- público
- publicar
- Python
- Frequentes
- rapidamente
- acaso
- Leitura
- pronto
- reais
- em tempo real
- dados em tempo real
- percebendo
- receber
- recebido
- recentemente
- reconhecido
- registros
- REPETIDAMENTE
- substituir
- requeridos
- recurso
- Recursos
- DESCANSO
- Resultados
- Retorna
- Risco
- Tipo
- Execute
- corrida
- sábio
- San
- San Francisco
- escalável
- Escala
- screenshots
- Sdk
- seaborn
- Segundo
- segundo
- Seção
- seções
- seguro
- selecionado
- doadores,
- Serverless
- serviço
- conjunto
- contexto
- Configurações
- instalação
- assistência técnica de curto e longo prazo
- mostrar
- Shows
- simples
- simplificar
- simulador
- So
- Redes Sociais
- meios de comunicação social
- solução
- Soluções
- alguns
- fonte
- Fontes
- especialista
- especializada
- gastar
- divisão
- SQL
- Etapa
- padrão
- começado
- Estado
- Declaração
- declarações
- Status
- Passo
- Passos
- armazenamento
- loja
- lojas
- Estratégico
- transmitir canais
- de streaming
- Serviço de transmissão
- córregos
- tal
- super
- .
- sistemas
- mesa
- Tire
- toma
- negociações
- Target
- terminal
- teste
- A
- Terceiro
- milhares
- Através da
- tempo
- timestamp
- para
- topo
- tópico
- tradicionalmente
- Trem
- treinado
- Training
- transação
- transacional
- Transações
- Transformar
- transformações
- transformando
- Trend
- Atualizar
- Atualizada
- Uso
- usar
- Utilizador
- validado
- valor
- Valores
- vário
- Verdade
- versão
- Ver
- visualizações
- caminhada
- Passo a passo
- Armazém
- Armazenagem
- Site
- fim de semana
- semanal
- O Quê
- qual
- enquanto
- Wikipedia
- precisarão
- sem
- trabalhou
- trabalhar
- trabalho
- escrever
- anos
- Ioga
- investimentos
- zefirnet