Source: https://www.quantamagazine.org/machines-beat-humans-on-a-reading-test-but-do-they-understand-20191017/
I recently started a new newsletter focus on AI education and already has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Machine reading comprehension(MRC) is an emergent discipline in the field of deep learning. From a conceptual standpoint, MRC focuses on deep learning models that can answer intelligent questions about specific text documents. For humans, reading comprehension is a native cognitive skill developed since the early days of school or even before. At we are reading a text, we are instinctively extracting the key ideas that will allow us to answer future questions about that subject. In the case of artificial intelligence(AI) models, that skill is still largely underdeveloped.
The first widely adopted generation of natural language understanding(NLU) techniques has focused mostly on detecting the intentions and concepts associated with a specific sentence. We can think about these models as a first tier of knowledge to enable reading comprehension. However, full machine reading comprehension needs additional building blocks that can extrapolate and correlate questions to specific sections of a text and build knowledge from specific sections of a document.
One of the biggest challenges in the MRC domain is that most models are based on supervised training with datasets that contain not only the documents but potential questions and answers. As you can imagine, this approach is not only very difficult to scale but practically impossible to implement in some domains in which the data is simply not available. Recently, researchers from Microsoft proposed an interesting approach to deal with this challenge in MRC algorithms.
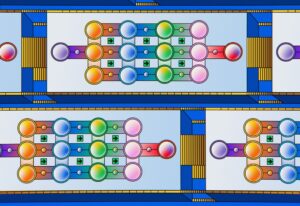
In a paper titled “Two-Stage Synthesis Networks for Transfer Learning in Machine Comprehension”, Microsoft’s Research introduced a technique called two stage synthesis networks or SynNet that applies transfer learning to reduce the effort to train a MRC model. SynNet can be seen as a two phase approach to build knowledge related to a specific text. In the first phase, SynNet learns a general pattern of identifying potential “interestingness” in a text document. These are key knowledge points, named entities, or semantic concepts that are usually answers that people may ask for. Then, in the second stage, the model learns to form natural language questions around these potential answers, within the context of the article.
The fascinating thing about SynNet is that, once trained, a model can be applied to a new domain, read the documents in the new domain and then generate pseudo questions and answers against these documents. Then, it forms the necessary training data to train an MRC system for that new domain, which could be a new disease, an employee handbook of a new company, or a new product manual.
Many people erroneously associate MRC technique with the more developed field of machine translation. In the case of MRC models such as SynNet, the challenge is that they need to synthesize both questions and answers for a document. While the question is a syntactically fluent natural language sentence, the answer is mostly a salient semantic concept in the paragraph, such as a named entity, an action, or a number. Since the answer has a different linguistic structure than the question, it may be more appropriate to view answers and questions as two different types of data. SynNet materializes in that theory by decomposing the process of generating question-answer pairs into two fundamental steps: The answer generation conditioned on the paragraph and the question generation conditioned on the paragraph and the answer.

Image Credit: Microsoft Research
You can think about SynNet as a teacher that is very good at generating questions from documents based on its experience. As it learn about the relevant questions in one domain, it can apply the same patterns to documents in a new domain. Microsoft researchers have applied the principles of SynNet to different MRC models including the recently published ReasoNet which have shown a lot of promise towards making machine reading comprehension a reality in the near future.
Original. Reposted with permission.
Related:
Source: https://www.kdnuggets.com/2021/04/microsoft-research-trains-neural-networks-understand-read.html- Action
- Additional
- AI
- algorithms
- around
- article
- Biggest
- build
- Building
- challenge
- cognitive
- company
- credit
- data
- deal
- deep learning
- Disease
- documents
- domains
- Early
- Education
- etc
- First
- Focus
- form
- full
- future
- General
- good
- HTTPS
- Humans
- image
- Including
- IT
- Key
- knowledge
- language
- LEARN
- learning
- machine learning
- machine translation
- Making
- medium
- Microsoft
- Microsoft Research
- model
- Natural Language
- Near
- networks
- Neural
- neural networks
- new product
- news
- Newsletter
- nlu
- Paper
- Pattern
- People
- Product
- projects
- Reading
- Reality
- reduce
- research
- Scale
- School
- Stage
- started
- system
- teacher
- Training
- trains
- Translation
- us
- View
- within