Kliknij, aby dowiedzieć się więcej o autorze Kendalla Clarka.
Upoważnienie IT do dostarczania wartości biznesowej nigdy nie było silniejsze. W rzeczywistości, 76% kadry kierowniczej uważają, że IT musi być aktywnym partnerem w tworzeniu strategii biznesowej. Zwinność jest tutaj kluczem do sukcesu. Jednak większości przedsiębiorstw przeszkadzają strategie dotyczące danych, które pozostawiają zespoły w martwym punkcie, gdy pojawiają się zmiany rynkowe lub pojawiają się nowe wyzwania.
Weźmy na przykład ustrukturyzowane systemy zarządzania danymi. Ta opcja sprawdzała się dobrze, gdy sam krajobraz danych przedsiębiorstwa miał głównie strukturę. Ale świat jest teraz inny, a krajobraz danych korporacyjnych jest obecnie zdominowany przez hybrydowe, zróżnicowane i zmieniające się dane. Pojawienie się Internetu Rzeczy (IoT), wzrost wolumenu nieustrukturyzowanych danych, rosnące znaczenie zewnętrznych źródeł danych oraz trend w kierunku hybrydowych środowisk wielochmurowych stanowią przeszkody w spełnieniu każdego nowego żądania danych. The stara strategia danych, skupione wokół relacyjnych systemów danych, jest zasadniczo zepsute. Jak więc przedsiębiorstwa mogą przejść od reaktywnej do responsywnej strategii dotyczącej danych?
Enterprise Data Fabrics: droga do przodu
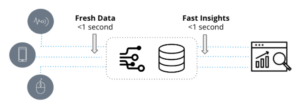
Dzisiejsze organizacje chcą zbudować struktura danych do wspierania wspólnych, wielofunkcyjnych projektów i produktów oraz do unikania reaktywnych przepływów pracy dzięki odpornej cyfrowej podstawie – bez konieczności wymiany i wymiany. Sieci danych splatają dane z wewnętrznych silosów danych i zewnętrznych źródeł oraz tworzą sieć informacji do zasilania aplikacji, sztucznej inteligencji i analiz. Po prostu obsługują pełen zakres wyzwań związanych z danymi w dzisiejszym złożonym, połączonym przedsiębiorstwie.
W przeciwieństwie do starszych, statycznych technik integracji danych, kluczowe zasady dotyczące sieci szkieletowych danych polegają na tym, że mogą one:
- Odpowiedz na nieoczekiwane pytania i dostosuj się do nowych wymagań
- Nadaj znaczenie danym, co prowadzi do lepszego wglądu
- Włącz zapytania w silosach danych i źródłach zewnętrznych, niezależnie od struktury danych
- Zmodernizuj istniejące systemy tak, aby nie było konieczności ich wymiany
- Połącz dane w warstwie obliczeniowej, a nie w warstwie przechowywania, aby silosy danych można było łączyć bez tworzenia dodatkowych silosów
Sieci danych obsługują również międzyfunkcyjne połączenia danych, które są kluczowe dla tworzenia i obrony przewagi konkurencyjnej oraz umożliwiają współpracę w całym przedsiębiorstwie i z partnerami zewnętrznymi. Weźmy jako przykład wyzwania związane z innowacjami w łańcuchu dostaw. Konwencjonalne systemy danych w łańcuchu dostaw to wyścig sztafetowy, działający z liniowym przełączaniem i silosowymi połączeniami peer-to-peer między systemami. Widzieliśmy przewidywalne wyniki, gdy uderzył COVID-19 i załamały się globalne łańcuchy dostaw. Pewne obciążenie, a nawet częściowe załamanie było nieuniknione, ale konsekwencje pogłębiały nieodpowiednie strategie dotyczące danych, które traktowały łańcuch dostaw jako sztywny system. W rzeczywistości łańcuch dostaw to złożona sieć podmiotów, które muszą być w pełni zsynchronizowane, aby dostosować się do potrzeb.
Dzięki cyfrowej sieci dostaw opartej na strukturze danych przedsiębiorstwa mogą odpowiadać na złożone pytania, na które wcześniej były ślepe, takie jak „pokaż mi wszystkie partie surowców i powiązanych dostawców zaangażowanych w produkcję wyrobów gotowych z serii 123”. Lub „jak KWS dla produktu A porównuje te dwa regiony?” Lub „którzy producenci dostarczyli surowce objęte skargą klienta?”
Łączenie udanej struktury danych zaczyna się od zrozumienia jej materiałów
W przeciwieństwie do innych podejść, struktury danych łączą ze sobą istniejące systemy i aplikacje do zarządzania danymi. Nic więc dziwnego, że struktury danych są szybko postrzegane jako kolejny krok naprzód w dojrzewaniu przestrzeni integracji danych. Dzieje się tak, ponieważ sieci szkieletowe danych mogą:
1. Odkryj ukryte znaczenie: Sieci danych zmieniają status quo, dostarczając znaczenie, a nie tylko dane, w całym przedsiębiorstwie. To znaczenie jest splecione z wielu źródeł: danych i metadanych, źródeł wewnętrznych i zewnętrznych oraz systemów chmurowych i lokalnych. Znaczenie jest rejestrowane w ramach i przez rozszerzalne modele danych oparte na grafach wiedzy, przy czym cały kontekst każdego zasobu danych jest w pełni obecny i dostępny w formie zrozumiałej dla maszyny. Dzięki sieci szkieletowej danych ludzie i algorytmy mogą podejmować lepsze decyzje, jednocześnie zmniejszając prawdopodobieństwo i ryzyko niewłaściwego wykorzystania lub błędnej interpretacji danych.
2. Odpowiedz na trudne pytania: Sieci danych dostarczają odpowiedzi za pośrednictwem zaawansowanych funkcji zapytań, wyszukiwania i uczenia się. Zamiast statycznej jednostki opartej na przenoszeniu lub kopiowaniu danych, platforma Data Fabric zapewnia dynamiczną „możliwą do przeszukiwania” warstwę danych, która gromadzi odpowiedzi z różnych silosy danych. Poprzednie strategie integracji danych polegały na tworzeniu nowego modelu danych do obsługi każdego nowego przypadku użycia, a następnie przenoszeniu lub kopiowaniu danych w celu wypełnienia tego modelu danych. W przypadku sieci szkieletowej modele danych są wielokrotnego użytku, więc gdy pojawią się nieoczekiwane pytania, zespołom łatwo jest dostosować się do potrzeb biznesowych.
3. Wspieraj wielofunkcyjne projekty zarządzania danymi: Sieci danych łączą istniejące systemy zarządzania danymi, wzbogacając wszystkie połączone aplikacje. Zastępują starsze systemy, które gromadziły lub katalogowały zasoby przedsiębiorstwa, ale nie umożliwiały wykorzystania danych. Poprzednie rozwiązania również zawiodły częściowo ze względu na niezdolność do obsługi hybrydowych, zróżnicowanych i zmieniających się danych, ale także z powodu sprzeciwu organizacyjnego. Sieci danych są jednak budowane z myślą o współpracy, wykorzystywaniu i łączeniu istniejących zasobów oraz napędzaniu nowej generacji wielofunkcyjnych projektów zarządzania danymi.
Modernizacja istniejących inwestycji
Większość z nas pamięta, jak kiedyś jeziora danych dawały obietnicę scentralizowania zasobów danych przedsiębiorstwa. Jednak wiele jezior danych nie spełnia swoich oczekiwań właśnie dlatego, że kolokują dane w warstwie przechowywania, zamiast łączyć je w warstwie obliczeniowej. Wykorzystują dane na podstawie ich lokalizacji, a nie na podstawie ich znaczenia biznesowego. Cała przesłanka stojąca za strukturą danych polega na tym, że fizyczna kolokacja danych sama w sobie nie zapewnia połączenia danych ani nie zapewnia znaczenia ani kontekstu. Starsze generacje systemów integracji opartych na pamięci masowej, takie jak hurtownie danych, są w rzeczywistości jeszcze mniej wydajne niż jeziora danych, ponieważ na początku łatwo zarządzają danymi strukturalnymi, pozostawiając częściowo ustrukturyzowane i nieustrukturyzowane silosy danych całkowicie nieadresowane i odłączone. Firmy szybko zwróciły się ku katalogom danych, aby spróbować poradzić sobie z oszałamiającą różnorodnością swoich krajobrazów danych, ale przekonały się, że samo katalogowanie nie prowadzi do połączonego przedsiębiorstwa.
Chociaż technologie te obiecywały zakończenie silosów danych, prawda jest taka, że są one nieuniknione i istnieją z bardzo dobrych powodów. Pozwalają na lokalną kontrolę i zarządzanie, gdy jest to ważne dla określonej części firmy, ponieważ niektóre dane muszą być przechowywane oddzielnie od innych danych, aby zachować zgodność z przepisami prawnymi lub po prostu ze starszych powodów biznesowych. Konwencjonalna integracja danych skupiona na eliminacji
silosów poprzez mastering, migrację, konsolidację lub zarządzanie. Jednak sieci światłowodowe oferują praktyczną alternatywę. Zamiast działać przeciwko silosom danych, struktura danych wykorzystuje je bez konieczności tworzenia dalszych kopii danych. Zamiast zastępować przestarzałe technologie, struktura danych działa równolegle z istniejącymi inwestycjami i poprawia ich użyteczność. Wynika to z faktu, że sieć szkieletowa danych jest projektem architektonicznym, który działa w warstwie obliczeniowej i koncentruje się na łączeniu danych w dowolnym miejscu, a tym samym faktycznie ulepsza istniejące fizycznie skonsolidowane zasoby do przechowywania danych, takie jak jeziora danych, katalogi danych, hurtownie, MDM i inne.
Grafy wiedzy: brakujący ścieg do udanej sieci szkieletowej danych
Grafy wiedzy są w stanie przedstawić pełną różnorodność i złożoność danych przedsiębiorstwa, ponieważ służą jako uniwersalny format znaczenia, niezależnie od struktury źródła danych, lokalizacji lub formatu. Graf wiedzy zastępuje obecny pracochłonny proces integracji danych przedsiębiorstwa, który zwykle obejmuje ekstrakcję, tłumaczenie, modelowanie, mapowanie, a następnie przeniesienie danych między różnymi aplikacjami. Niestandardowy kod wymagany do modelowania i mapowania szybko staje się nieporęczny na dużą skalę, spowalniając tempo innowacji i wglądu.
Grafy wiedzy są integralną częścią efektywnej struktury danych, ponieważ tworzą sieć wiedzy wielokrotnego użytku i łatwo reprezentują dane o różnych strukturach i obsługują wiele schematów. Tworząc możliwe do zapytania i wielokrotnego użytku semantyczne rozumienie danych korporacyjnych i zewnętrznych, grafy wiedzy służą jako rdzeń struktury danych: wzbogacają i przyspieszają istniejące inwestycje oraz zapewniają krytyczny dostęp do wglądu biznesowego.
Podobnie jak zwykła struktura, która dopasowuje się do wszystkiego, co otacza, struktura danych przedsiębiorstwa nakłada się na istniejące zasoby danych i łączy się z nimi za pośrednictwem poszczególnych wątków oraz splata te źródła w ujednoliconą warstwę. W ten sposób sieci szkieletowe danych faktycznie zwiększają wartość biznesową istniejących inwestycji.
- dostęp
- aktywny
- Dodatkowy
- Korzyść
- AI
- Algorytmy
- analityka
- aplikacje
- mobilne i webowe
- na około
- kapitał
- Aktywa
- budować
- biznes
- zmiana
- Chmura
- kod
- współpraca
- Firmy
- Mieszanka
- obliczać
- połączenia
- konsolidacja
- COVID-19
- Tworzenie
- Aktualny
- dane
- integracja danych
- zarządzanie danymi
- przechowywanie danych
- strategia danych
- hurtownia danych
- dostarczanie
- Wnętrze
- cyfrowy
- Różnorodność
- jazdy
- Efektywne
- Enterprise
- ekstrakcja
- tkanina
- Nasz formularz
- format
- Naprzód
- pełny
- Globalne
- dobry
- zarządzanie
- tutaj
- W jaki sposób
- HTTPS
- Hybrydowy
- Informacja
- Innowacja
- integralny
- integracja
- Internet
- Internet przedmiotów
- Inwestycje
- zaangażowany
- Internet przedmiotów
- IT
- Klawisz
- wiedza
- duży
- prowadzić
- UCZYĆ SIĘ
- nauka
- Regulamin
- Dźwignia
- miejscowy
- lokalizacja
- i konserwacjami
- rynek
- materiały
- model
- modelowanie
- sieć
- oferta
- operacyjny
- Option
- Inne
- Pozostałe
- partnerem
- Ludzie
- Platforma
- power
- teraźniejszość
- Produkt
- Produkcja
- Produkty
- projektowanie
- Wyścig
- Surowy
- Rzeczywistość
- Przyczyny
- Regulacja
- Efekt
- Ryzyko
- Skala
- Szukaj
- przesunięcie
- Spowolnienie
- So
- Rozwiązania
- Typ przestrzeni
- Rynek
- przechowywanie
- Strategia
- sukces
- udany
- dostawcy
- Dostawa
- łańcuch dostaw
- Dostarczać łańcuchy
- wsparcie
- system
- systemy
- Technologies
- Tłumaczenie
- odkryć
- uniwersalny
- us
- użyteczność
- wartość
- Tom
- Magazyn
- Splot
- w ciągu
- działa
- świat