In 2021 i 2020, powiedzieliśmy Ci o nowych funkcjach w Amazonka Przesunięcie ku czerwieni które ułatwiają, przyspieszają i zmniejszają koszty analizowania wszystkich danych oraz znajdowania bogatych i zaawansowanych spostrzeżeń. Z przyjemnością informujemy, że w 2022 roku zespół Amazon Redshift ciężko pracował. Pracowaliśmy wstecz od wymagań klientów i ogłosiliśmy wiele nowych funkcji, aby ułatwić, przyspieszyć i obniżyć koszty analizy wszystkich danych. W tym poście omówiono niektóre z tych nowych funkcji.
W AWS, w zakresie danych i analiz, naszą strategią jest zapewnienie Ci nowoczesna architektura danych który pomaga uwolnić się od silosów danych; mieć specjalnie opracowane usługi w zakresie danych, analiz, uczenia maszynowego (ML) i sztucznej inteligencji, aby używać właściwego narzędzia do właściwego zadania; oraz mieć otwarte, zarządzane, bezpieczne iw pełni zarządzane usługi, dzięki którym analizy będą dostępne dla wszystkich. W nowoczesnej architekturze danych AWS, Amazon Redshift jako magazyn danych w chmurze pozostaje kluczowym elementem, umożliwiając przeprowadzanie złożonych analiz SQL w skali i wydajności na terabajtach do petabajtów ustrukturyzowanych i nieustrukturyzowanych danych oraz szeroko udostępnianie spostrzeżeń za pośrednictwem popularnej analizy biznesowej ( BI) i narzędzi analitycznych. Nadal pracujemy wstecz w stosunku do wymagań klientów, aw 2022 r. wprowadziliśmy ponad 40 funkcji w Amazon Redshift, aby pomóc klientom w ich najważniejszych przypadkach użycia hurtowni danych, w tym:
- Analityka samoobsługowa
- Łatwe pozyskiwanie danych
- Udostępnianie danych i współpraca
- Nauka o danych i uczenie maszynowe
- Bezpieczne i niezawodne analizy
- Najlepsza analiza wydajności cenowej
Zanurzmy się głębiej i omówmy nowe funkcje Amazon Redshift w tych obszarach.
Analityka samoobsługowa
Klienci wciąż mówią nam, że dane i analizy stają się wszechobecne, a wszyscy w ich organizacji potrzebują analiz. ogłosiliśmy Bezserwerowe Amazon Redshift (w wersji zapoznawczej) w 2021 r., aby ułatwić uruchamianie i skalowanie analiz w kilka sekund bez konieczności udostępniania i zarządzania infrastrukturą hurtowni danych. W lipcu 2022 roku ogłosiliśmy ogólna dostępność Redshift Serverlessi od tego czasu tysiące klientów, w tym Peloton, Broadridge Financials i NextGen Healthcare, używało go do szybkiego i łatwego analizowania swoich danych. Amazon Redshift Serverless automatycznie przydziela i inteligentnie skaluje pojemność magazynu danych, aby zapewnić wysoką wydajność wszystkich analiz, a Ty płacisz tylko za moc obliczeniową używaną przez czas trwania obciążeń na zasadzie sekundowej. Od GA dodaliśmy funkcje, takie jak tagowanie zasobów, uproszczone monitorowanie i dostępność w dodatkowych regionach AWS w celu dalszego uproszczenia rozliczeń i rozszerzenia zasięgu na większą liczbę regionów na całym świecie.
W 2021 roku uruchomiliśmy Amazon Redshift Query Editor V2, które jest bezpłatnym narzędziem internetowym dla analityków danych, analityków danych i programistów do eksploracji, analizy i współpracy nad danymi w hurtowniach danych i jeziorach danych Amazon Redshift. W 2022 Query Editor V2 otrzymał dodatkowe ulepszenia takie jak wsparcie notebooka dla lepszej współpracy przy tworzeniu, organizowaniu i dodawaniu adnotacji do zapytań; dostęp użytkownika przez poświadczenia dostawcy tożsamości (IdP). dla pojedynczego logowania; oraz możliwość uruchamiania wielu zapytań jednocześnie w celu zwiększenia produktywności programistów.
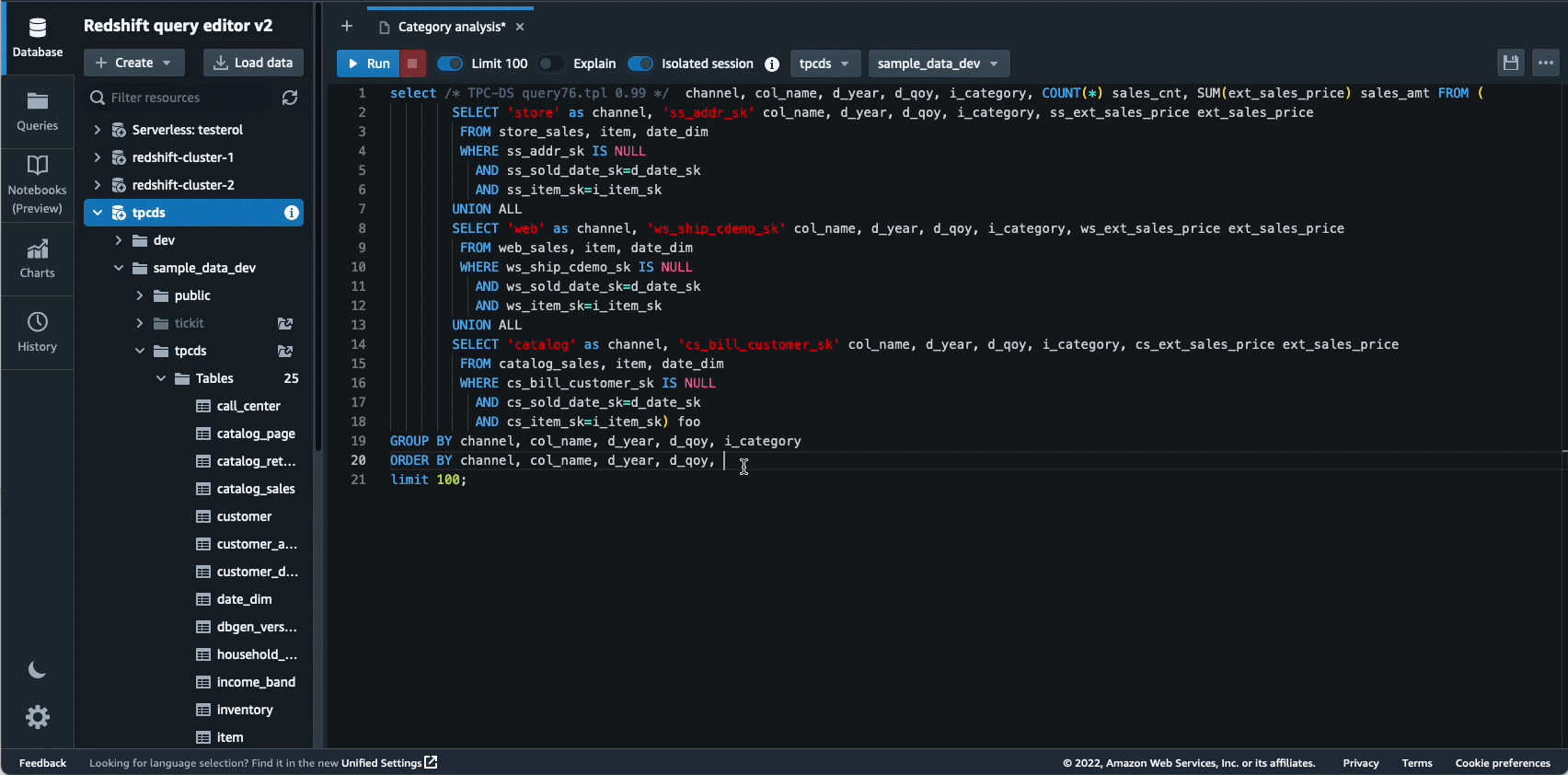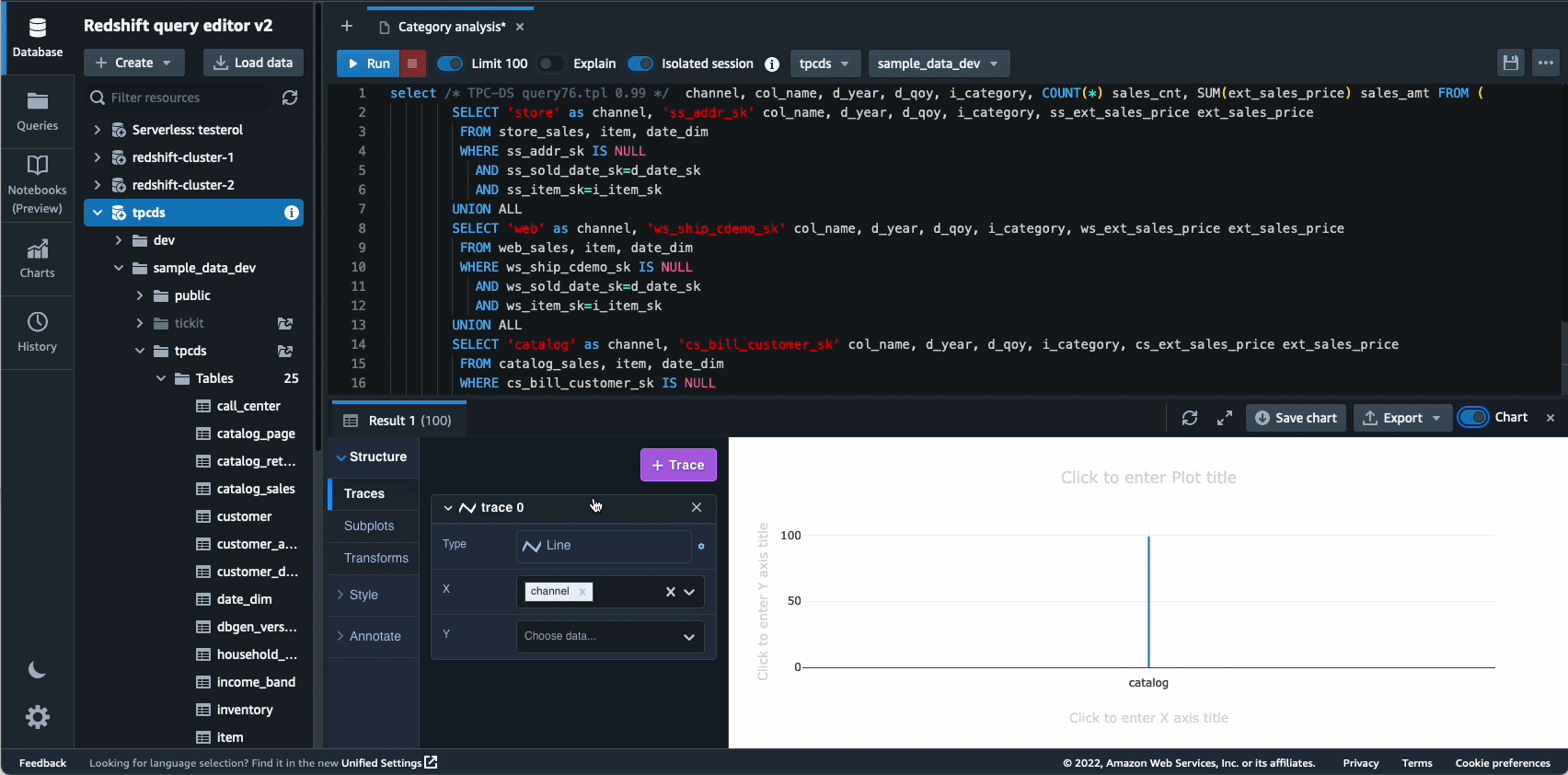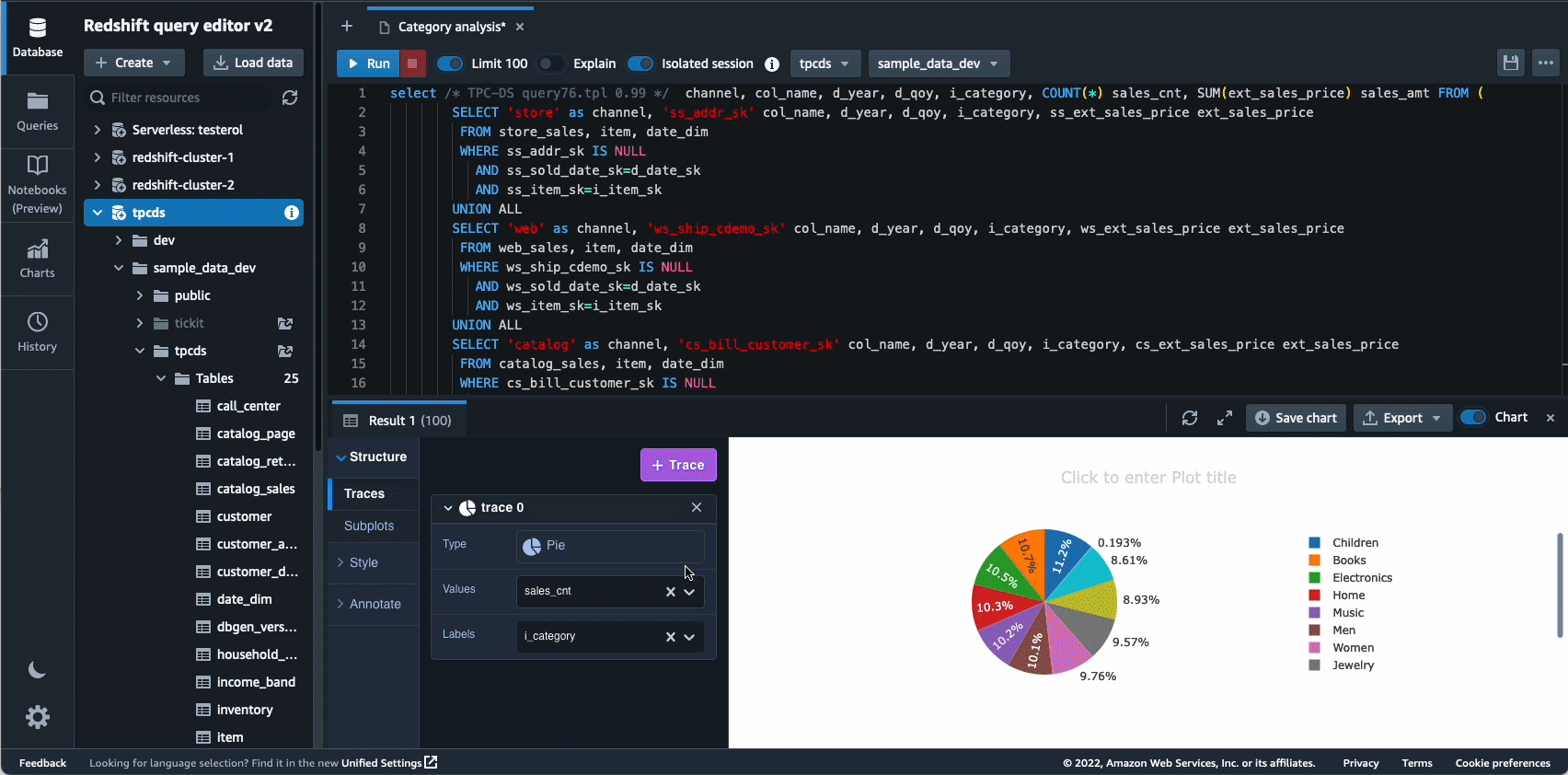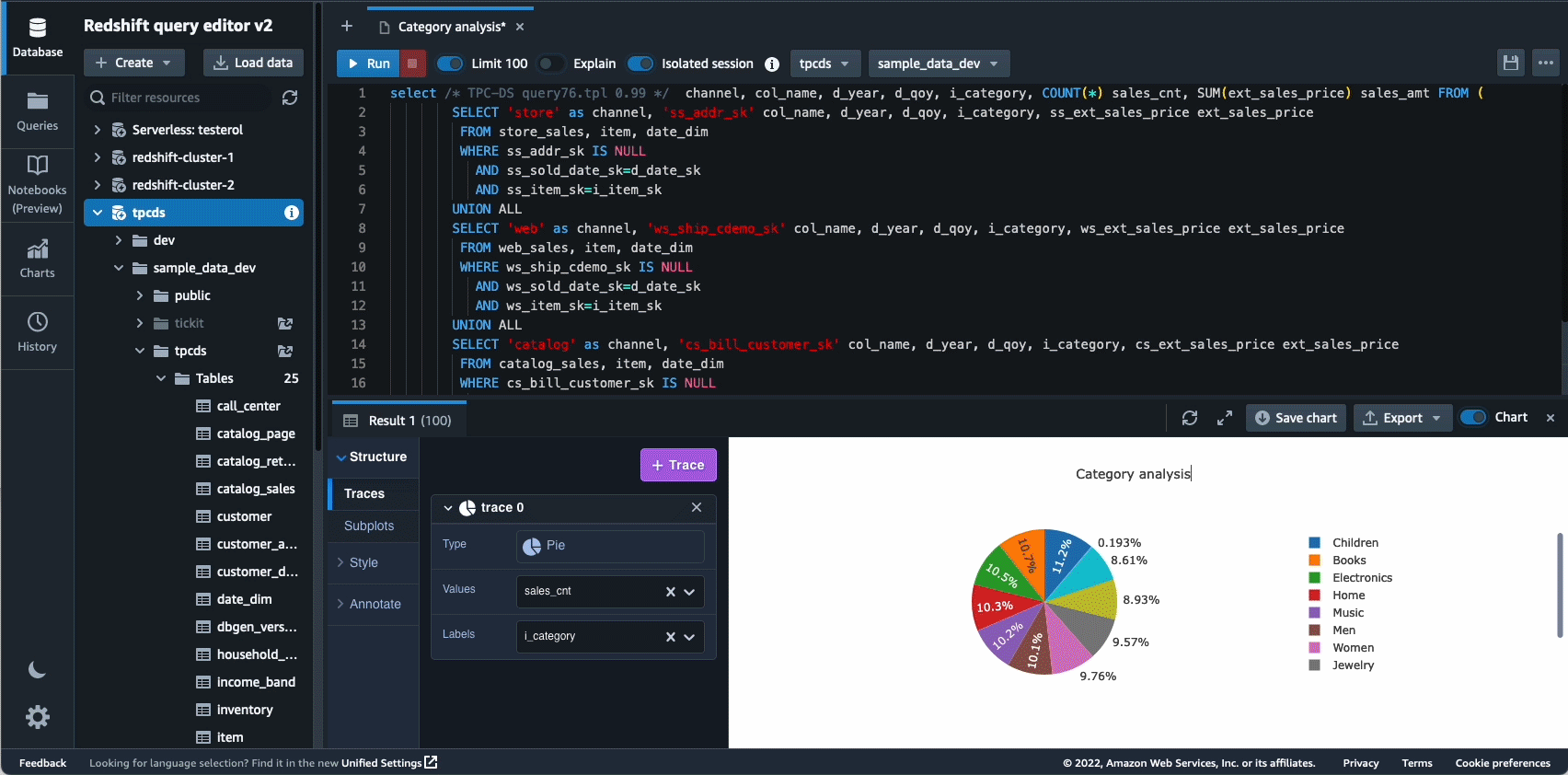
Autonomia to kolejny obszar, w którym aktywnie pracujemy nad wykorzystaniem optymalizacji opartych na ML i zapewnieniem klientom samouczącej się i samooptymalizującej hurtowni danych. W 2022 roku ogłosiliśmy ogólną dostępność Zautomatyzowane widoki zmaterializowane (AutoMV) w celu poprawy wydajności zapytań (zmniejszenia całkowitego czasu wykonywania) bez żadnego wysiłku ze strony użytkownika poprzez automatyczne tworzenie i utrzymywanie zmaterializowanych widoków. AutoMV w połączeniu z automatycznym odświeżaniem, odświeżaniem przyrostowym i automatycznym przepisywaniem zapytań dla widoków zmaterializowanych sprawiło, że widoki zmaterializowane nie wymagają konserwacji, zapewniając automatycznie wyższą wydajność. Ponadto automatyczna optymalizacja stołu (ATO) możliwość optymalizacji schematu i automatyczne zarządzanie obciążeniem Funkcja (auto WLM) do optymalizacji obciążenia została dodatkowo ulepszona w celu uzyskania lepszej wydajności zapytań.
Łatwe pozyskiwanie danych
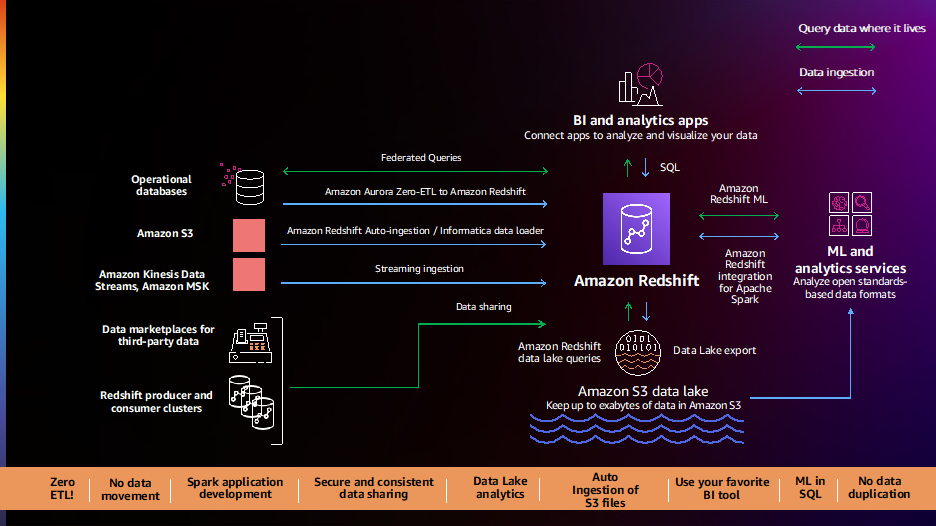
Klienci mówią nam, że ich dane są rozproszone w wielu źródłach danych, takich jak transakcyjne bazy danych, hurtownie danych, jeziora danych i systemy dużych zbiorów danych. Chcą mieć możliwość elastycznego integrowania tych danych z potokami danych bez kodu/niskiego kodu, bez ETL lub analizowania tych danych na miejscu bez ich przenoszenia. Klienci mówią nam, że ich obecne potoki danych są złożone, ręczne, sztywne i powolne, co skutkuje niekompletnymi, niespójnymi i nieaktualnymi widokami danych, co ogranicza wgląd. Klienci prosili nas o lepszą drogę naprzód, a my z przyjemnością ogłaszamy szereg nowych możliwości upraszczania i automatyzacji potoków danych.
Integracja Amazon Aurora zero-ETL z Amazon Redshift (wersja zapoznawcza) umożliwia przeprowadzanie analiz w czasie zbliżonym do rzeczywistego i uczenie maszynowe na petabajtach danych transakcyjnych. Oferuje rozwiązanie bez kodu do tworzenia danych transakcyjnych z wielu Amazonka Aurora baz danych dostępnych w hurtowniach danych Amazon Redshift w ciągu kilku sekund od ich zapisania do Aurory, eliminując potrzebę budowania i utrzymywania złożonych potoków danych. Dzięki tej funkcji klienci Aurory mogą również uzyskać dostęp do funkcji Amazon Redshift, takich jak złożona analiza SQL, wbudowana ML, udostępnianie danych i federacyjny dostęp do wielu magazynów danych i jezior danych. Ta funkcja jest teraz dostępna w wersji zapoznawczej dla Wersja zgodna z Amazon Aurora MySQL wersja 3 (z kompatybilnością z MySQL 8.0) i możesz poprosić o dostęp do podglądu.
Amazon Redshift jest teraz obsługiwany automatyczne kopiowanie z Amazon S3 (wersja zapoznawcza), aby uprościć ładowanie danych z Usługa Amazon Simple Storage (Amazon S3) w Amazon Redshift. Możesz teraz skonfigurować reguły ciągłego pozyskiwania plików (zadania kopiowania), aby śledzić ścieżki Amazon S3 i automatycznie ładować nowe pliki bez potrzeby stosowania dodatkowych narzędzi lub niestandardowych rozwiązań. Zadania kopiowania można monitorować za pomocą tabel systemowych, które automatycznie śledzą wcześniej załadowane pliki i wykluczają je z procesu pozyskiwania, aby zapobiec powielaniu danych. Ta funkcja jest teraz dostępna w wersji zapoznawczej; możesz wypróbować tę funkcję, tworząc nowy klaster przy użyciu ścieżki podglądu.
Klienci wciąż mówią nam, że potrzebują natychmiastowych analiz w czasie rzeczywistym, a my z przyjemnością ogłaszamy ogólna dostępność obsługi przetwarzania strumieniowego w Amazon Redshift dla Strumienie danych Amazon Kinesis i Przesyłanie strumieniowe zarządzane przez Amazon dla Apache Kafka (Amazon MSK). Ta funkcja eliminuje potrzebę umieszczania danych przesyłanych strumieniowo w Amazon S3 przed pobraniem ich do Amazon Redshift, umożliwiając osiągnięcie niskich opóźnień, mierzonych w sekundach, przy jednoczesnym przetwarzaniu setek megabajtów danych przesyłanych strumieniowo na sekundę do magazynów danych. Możesz używać SQL w ramach Amazon Redshift, aby łączyć się i bezpośrednio pobierać dane z wielu strumieni danych Kinesis lub tematów MSK, tworzyć automatycznie odświeżane zmaterializowane widoki przesyłania strumieniowego z transformacjami na górze strumieni, aby uzyskać bezpośredni dostęp do danych przesyłanych strumieniowo oraz łączyć dane w czasie rzeczywistym z danymi historycznymi dane dla lepszego wglądu. Na przykład firma Adobe zintegrowała przetwarzanie strumieniowe Amazon Redshift jako część swojej platformy Adobe Experience Platform do pozyskiwania i analizowania w czasie rzeczywistym strumienia kliknięć i sesji w sieci i aplikacjach dla różnych aplikacji, takich jak CRM i aplikacje obsługi klienta.
Klienci powiedzieli nam, że chcą prostej, gotowej do użycia integracji między narzędziami Amazon Redshift, BI i ETL (wyodrębnianie, przekształcanie i ładowanie) oraz aplikacjami biznesowymi, takimi jak Salesforce i Marketo. Z przyjemnością informujemy o ogólnej dostępności Ładowarka danych Informatica dla Amazon Redshift, która umożliwia korzystanie z programu Informatica Data Loader do szybkiego ładowania dużych ilości danych do Amazon Redshift za darmo. Możesz po prostu wybrać opcję Informatica Data Loader na konsoli Amazon Redshift. Będąc w Informatica Data Loader, możesz połączyć się ze źródłami takimi jak Salesforce lub Marketo, wybrać Amazon Redshift jako cel i rozpocząć ładowanie danych.
Udostępnianie danych i współpraca
Klienci wciąż mówią nam, że chcą analizować wszystkie swoje dane własne i zewnętrzne oraz udostępniać bogate wglądy oparte na danych swoim klientom, partnerom i dostawcom. W 2021 roku uruchomiliśmy nowe funkcje, takie jak Udostępnianie danych i Integracja z AWS Data Exchange, aby ułatwić Ci analizowanie wszystkich danych i udostępnianie ich w organizacjach i poza nimi.
Świetnym przykładem klienta korzystającego z udostępniania danych jest Orion. Orion dostarcza rozwiązania danych w czasie rzeczywistym jako usługi (DaaS) dla klientów z branży usług finansowych, takich jak dostawcy zarządzania majątkiem, zarządzania aktywami i zarządzania inwestycjami. Mają ponad 2,500 źródeł danych, które są głównie bazami danych SQL Server znajdującymi się zarówno lokalnie, jak i w AWS. Dane są przesyłane strumieniowo za pomocą łączników Kafka do Amazon Redshift. Mają klaster producentów, który otrzymuje wszystkie te dane, a następnie wykorzystuje udostępnianie danych do udostępniania danych w czasie rzeczywistym w celu współpracy. Jest to architektura wielu dzierżawców, która obsługuje wielu klientów. Biorąc pod uwagę wrażliwość ich danych, udostępnianie danych jest sposobem na zapewnienie izolacji obciążeń między klastrami, a także bezpieczne udostępnianie tych danych użytkownikom końcowym.
W 2022 r. nadal inwestowaliśmy w ten obszar, aby poprawić wydajność, zarządzanie i produktywność programistów dzięki nowym funkcjom ułatwiającym, prostszym i szybszym udostępnianie danych i współpracę nad nimi.
Ponieważ klienci budują konfiguracje udostępniania danych na dużą skalę, prosili o uproszczenie zarządzania i bezpieczeństwa udostępnianych danych, a my dodajemy scentralizowana kontrola dostępu z AWS Lake Formation dla udostępniania danych Amazon Redshift, aby umożliwić udostępnianie danych w czasie rzeczywistym w wielu hurtowniach danych Amazon Redshift. Dzięki tej funkcji Amazon Redshift obsługuje teraz uproszczone zarządzanie udziałami danych Amazon Redshift za pomocą Formacja AWS Lake jako pojedynczy panel do centralnego zarządzania danymi lub uprawnieniami do współdzielonych danych. Możesz przeglądać, modyfikować i kontrolować uprawnienia, w tym zabezpieczenia na poziomie wierszy i kolumn w tabelach i widokach w udziałach danych Amazon Redshift, korzystając z interfejsów API Lake Formation i Konsola zarządzania AWSi umożliwiać wykrywanie i wykorzystywanie udziałów danych Amazon Redshift przez inne hurtownie danych Amazon Redshift.
Nauka o danych i uczenie maszynowe
Klienci wciąż mówią nam, że chcą, aby ich dane i systemy analityczne pomagały im odpowiadać na szeroki zakres pytań, od tego, co dzieje się w ich biznesie (analiza opisowa), po dlaczego tak się dzieje (analiza diagnostyczna) i co będzie się działo w przyszłości (analizy predykcyjne). Amazon Redshift zapewnia takie funkcje, jak złożona analiza SQL, analiza jeziora danych i Amazon Redshift ML aby klienci mogli analizować swoje dane i odkrywać przydatne informacje. Przesunięcie ku czerwieni ML integruje Amazon Redshift z Amazon Sage Maker, w pełni zarządzana usługa uczenia maszynowego, umożliwiająca tworzenie, trenowanie i wdrażanie modeli uczenia maszynowego przy użyciu znanych poleceń SQL.
Klienci prosili nas również o lepszą integrację między Amazon Redshift i Apache Spark, więc z radością ogłaszamy Integracja Amazon Redshift dla Apache Spark aby hurtownie danych były łatwo dostępne dla aplikacji opartych na platformie Spark. Teraz programiści korzystający z usług analitycznych AWS i usług ML, takich jak Amazon EMR, Klej AWS, a SageMaker może bez wysiłku tworzyć aplikacje Apache Spark, które odczytują i zapisują w swoich magazynach danych Amazon Redshift. Amazon EMR i AWS Glue pakują złącze Redshift-Spark, dzięki czemu możesz łatwo łączyć się z hurtownią danych z aplikacji opartych na Spark. Możesz użyć kilku funkcji wypychania w dół dla operacji, takich jak sortowanie, agregowanie, ograniczanie, łączenie i funkcje skalarne, dzięki czemu tylko odpowiednie dane są przenoszone z magazynu danych Amazon Redshift do zużywającej aplikacji Spark. Możesz także zwiększyć bezpieczeństwo swoich aplikacji, używając AWS Zarządzanie tożsamością i dostępem (IAM), aby połączyć się z Amazon Redshift.
Bezpieczne i niezawodne analizy
Klienci wciąż mówią nam, że ich hurtownie danych to systemy o znaczeniu krytycznym, które wymagają wysokiej dostępności, niezawodności i bezpieczeństwa. W 2022 roku wprowadziliśmy szereg nowych funkcji w tym obszarze.
Amazon Redshift jest teraz obsługiwany Wdrożenia z wieloma AZ (w wersji zapoznawczej) dla klastrów opartych na instancjach RA3, co umożliwia prowadzenie hurtowni danych w wielu strefach dostępności AWS jednocześnie i ciągłą pracę w nieprzewidzianych scenariuszach awarii obejmujących całą strefę dostępności. Obsługa Multi-AZ jest już dostępna dla Redshift Serverless. Wdrożenie Amazon Redshift Multi-AZ umożliwia odzyskiwanie w przypadku awarii strefy dostępności bez interwencji użytkownika. Hurtownia danych Amazon Redshift Multi-AZ jest dostępna jako pojedyncza hurtownia danych z jednym punktem końcowym i pomaga zmaksymalizować wydajność poprzez automatyczną dystrybucję przetwarzania obciążenia w wielu strefach dostępności. Żadne zmiany w aplikacji nie są potrzebne do utrzymania ciągłości biznesowej podczas nieprzewidzianych przestojów.
W 2022 r. wprowadziliśmy funkcje, takie jak kontrola dostępu oparta na rolach, zabezpieczenia na poziomie wierszy i maskowanie danych (w wersji zapoznawczej), aby ułatwić zarządzanie dostępem i decydowanie, kto ma dostęp do danych, w tym zaciemnianie informacji umożliwiających identyfikację osób (PII) ), jak numery kart kredytowych.
Możesz użyć kontrola dostępu oparta na rolach (RBAC) do kontrolowania dostępu użytkownika końcowego do danych na poziomie ogólnym lub szczegółowym w oparciu o rolę i uprawnienia użytkownika końcowego. Za pomocą RBAC możesz utworzyć rolę przy użyciu języka SQL, udzielić kolekcji szczegółowych uprawnień do roli, a następnie przypisać tę rolę użytkownikom końcowym. Rolom można nadawać uprawnienia na poziomie obiektu, kolumny i systemu. Ponadto RBAC wprowadza gotowe role systemowe dla administratorów baz danych, operatorów, administratorów zabezpieczeń lub role niestandardowe.
Zabezpieczenia na poziomie wiersza (RLS) upraszcza projektowanie i wdrażanie szczegółowego dostępu do wierszy w tabelach. Dzięki RLS możesz ograniczyć dostęp do podzbioru wierszy w tabeli na podstawie roli lub uprawnień użytkownika w SQL.
Obsługa Amazon Redshift dla dynamiczne maskowanie danych (DDM), która jest teraz dostępna w wersji zapoznawczej, pozwala uprościć ochronę danych osobowych, takich jak numery ubezpieczenia społecznego, numery kart kredytowych i numery telefonów w hurtowni danych Amazon Redshift. Dzięki dynamicznemu maskowaniu danych kontrolujesz dostęp do swoich danych za pomocą prostych zasad maskowania opartych na języku SQL, które określają, w jaki sposób Amazon Redshift zwraca użytkownikowi poufne dane w czasie zapytania. Możesz tworzyć zasady maskowania, aby definiować spójne, zachowujące format i nieodwracalne wartości maskowanych danych. Zasady maskowania można zastosować do określonej kolumny lub listy kolumn w tabeli. Ponadto masz swobodę wyboru sposobu wyświetlania zamaskowanych danych. Na przykład możesz całkowicie ukryć dane, zastąpić częściowe wartości rzeczywiste symbolami wieloznacznymi lub zdefiniować własny sposób maskowania danych za pomocą wyrażeń SQL, Pythona lub AWS Lambda funkcje zdefiniowane przez użytkownika. Ponadto można zastosować zasady maskowania warunkowego oparte na innych kolumnach, które selektywnie chronią dane kolumn w tabeli na podstawie wartości w jednej lub kilku różnych kolumnach.
Ogłosiliśmy również ulepszenia do rejestrowanie audytu, natywna integracja z Usługa Active Directory Microsoft Azurei wsparcie dla domyślne role uprawnień w dodatkowych regionach, aby jeszcze bardziej uprościć zarządzanie bezpieczeństwem.
Najlepsza analiza wydajności cenowej
Klienci wciąż mówią nam, że potrzebują szybkich i ekonomicznych hurtowni danych, które zapewniają wysoką wydajność w dowolnej skali przy jednoczesnym utrzymaniu niskich kosztów. Od dnia 1 od Uruchomienie Amazon Redshift w 2012 roku, przyjęliśmy podejście oparte na danych i wykorzystaliśmy telemetrię floty do zbudowania usługi hurtowni danych w chmurze, która zapewnia najlepszą wydajność cenową w dowolnej skali. Przez lata ewoluowaliśmy Architektura Amazon Redshift i uruchomił funkcje, takie jak Pamięć zarządzana z przesunięciem ku czerwieni (RMS) do rozdzielenia pamięci masowej i obliczeniowej, Widmo przesunięcia ku czerwieni Amazonki dla zapytań do data lake, automatyczna optymalizacja stołu do optymalizacji schematu fizycznego, automatyczne zarządzanie obciążeniem nadawać priorytety obciążeniom i przydzielać odpowiednie moce obliczeniowe i pamięć, zmiana rozmiaru klastra skalować moc obliczeniową i pamięć masową w pionie oraz skalowanie współbieżności do dynamicznego skalowania obliczeń w górę lub w dół. Nasz testy wydajności nadal demonstrować wiodącą pozycję Amazon Redshift w zakresie wydajności cenowej.
W 2022 roku dodaliśmy nowe funkcje, takie jak ogólna dostępność skalowanie współbieżności dla operacji zapisu takie jak COPY, INSERT, UPDATE i DELETE, aby obsługiwać praktycznie nieograniczoną liczbę jednoczesnych użytkowników i zapytań. Wprowadziliśmy również ulepszenia wydajności przetwarzania danych opartych na łańcuchach poprzez skanowanie wektorowe lekkich, wydajnych procesorowo kolumn łańcuchowych zakodowanych w słowniku, co pozwala silnikowi bazy danych działać bezpośrednio na skompresowanych danych.
Dodaliśmy również obsługę operatorów SQL, takich jak MERGE (jeden operator dla wkładek lub aktualizacji); POŁĄCZENIE_BY (dla zapytań hierarchicznych); GRUPOWANIE ZESTAWÓW, ROLLUP i CUBE (dla raportowania wielowymiarowego); i zwiększono rozmiar danych typu SUPER do 16 MB, aby ułatwić migrację ze starszych hurtowni danych do Amazon Redshift.
Wnioski
Nasi klienci wciąż mówią nam, że dane i analizy pozostają dla nich najwyższym priorytetem, a potrzeba efektywnego kosztowo wydobywania większej wartości biznesowej z ich danych w tych czasach jest bardziej wyraźna niż kiedykolwiek wcześniej. Amazon Redshift jako hurtownia danych w chmurze umożliwia przeprowadzanie złożonych analiz SQL ze skalą i wydajnością na terabajtach do petabajtów ustrukturyzowanych i nieustrukturyzowanych danych oraz udostępnianie spostrzeżeń za pośrednictwem popularnych narzędzi BI i analitycznych.
Chociaż w 40 r. wprowadziliśmy ponad 2022 funkcji, a tempo innowacji wciąż przyspiesza, to wciąż jest pierwszy dzień i czekamy na informacje od Ciebie, w jaki sposób te funkcje pomogą Ci odblokować większą wartość dla Twoich organizacji. Zapraszamy do wypróbowania tych nowych funkcji i skontaktowania się z nami za pośrednictwem zespołu konta AWS, jeśli masz dalsze uwagi.
O autorze
 Manana Goela jest Product Go-To-Market Leader dla AWS Analytics Services, w tym Amazon Redshift w AWS. Ma ponad 25-letnie doświadczenie i jest dobrze zorientowany w bazach danych, hurtowniach danych, analizie biznesowej i analityce. Manan posiada tytuł MBA uzyskany na Duke University oraz tytuł licencjata w dziedzinie inżynierii elektroniki i komunikacji.
Manana Goela jest Product Go-To-Market Leader dla AWS Analytics Services, w tym Amazon Redshift w AWS. Ma ponad 25-letnie doświadczenie i jest dobrze zorientowany w bazach danych, hurtowniach danych, analizie biznesowej i analityce. Manan posiada tytuł MBA uzyskany na Duke University oraz tytuł licencjata w dziedzinie inżynierii elektroniki i komunikacji.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- zdolność
- O nas
- przyśpieszyć
- dostęp
- Dostęp do danych
- dostęp
- dostępny
- Konto
- Osiągać
- w poprzek
- aktywny
- aktywnie
- w dodatku
- dodatek
- Dodatkowy
- do tego
- Adobe
- Wszystkie kategorie
- pozwala
- już
- Amazonka
- Amazon EMR
- analitycy
- analityka
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- Ogłosić
- ogłosił
- Inne
- odpowiedź
- Apache
- Apache Spark
- Pszczoła
- Zastosowanie
- aplikacje
- Aplikuj
- podejście
- architektura
- POWIERZCHNIA
- obszary
- sztuczny
- sztuczna inteligencja
- kapitał
- zarządzanie aktywami
- Audyt
- jutrzenka
- autor
- samochód
- zautomatyzować
- automatycznie
- automatycznie
- dostępność
- dostępny
- AWS
- Klej AWS
- Lazur
- na podstawie
- podstawa
- staje
- zanim
- jest
- BEST
- Ulepsz Swój
- pomiędzy
- Duży
- Big Data
- billing
- przerwa
- szeroki
- Broadridge
- budować
- Budowanie
- wbudowany
- biznes
- Aplikacje biznesowe
- ciągłości działania
- business intelligence
- możliwości
- Pojemność
- karta
- walizka
- Etui
- Zmiany
- znaków
- Dodaj
- Wybierając
- klientów
- Chmura
- Grupa
- współpracować
- współpraca
- kolekcja
- Kolumna
- kolumny
- połączyć
- połączony
- komentarze
- Komunikacja
- zgodność
- całkowicie
- kompleks
- składnik
- obliczać
- równoległy
- Skontaktuj się
- zgodny
- Konsola
- spożywane
- kontynuować
- nadal
- ciągły
- ciągły
- kontrola
- opłacalne
- Koszty:
- obejmuje
- Stwórz
- Tworzenie
- Listy uwierzytelniające
- kredyt
- Karta kredytowa
- Kredyty
- CRM
- Aktualny
- zwyczaj
- klient
- Obsługa klienta
- Klientów
- dostosowane
- dane
- Wymiana danych
- Jezioro danych
- analiza danych
- udostępnianie danych
- hurtownia danych
- magazyn danych
- sterowane danymi
- Baza danych
- Bazy danych
- dzień
- głębiej
- dostarczyć
- wykazać
- rozwijać
- Wdrożenie
- Wnętrze
- Ustalać
- Deweloper
- deweloperzy
- różne
- bezpośrednio
- odkryj
- odkryty
- dyskutować
- dystrybuowane
- rozdzielczy
- Książę
- uniwersytet książęcy
- podczas
- dynamiczny
- łatwiej
- z łatwością
- redaktor
- wysiłek
- Elektronika
- eliminuje
- eliminując
- umożliwiać
- Umożliwia
- umożliwiając
- Punkt końcowy
- silnik
- Inżynieria
- Eter (ETH)
- wszyscy
- ewoluowały
- przykład
- wymiana
- podniecony
- Rozszerzać
- doświadczenie
- odkryj
- wyrażeń
- wyciąg
- Brak
- znajomy
- FAST
- szybciej
- Cecha
- Korzyści
- filet
- Akta
- budżetowy
- usługi finansowe
- finansowy
- Znajdź
- FLOTA
- Elastyczność
- formacja
- Naprzód
- Darmowy
- od
- w pełni
- Funkcje
- dalej
- przyszłość
- Ogólne
- otrzymać
- gif
- Dać
- dany
- daje
- Dający
- szkło
- Idź do sklepu
- zarządzanie
- przyznać
- udzielony
- wspaniały
- zdarzyć
- Zaoszczędzić
- Ciężko
- mający
- opieki zdrowotnej
- przesłuchanie
- pomoc
- pomaga
- Ukryj
- Wysoki
- historyczny
- posiada
- W jaki sposób
- How To
- HTML
- HTTPS
- Setki
- IAM
- tożsamość
- realizacja
- podnieść
- ulepszony
- ulepszenia
- in
- Włącznie z
- wzrosła
- przemysł
- Informacja
- Infrastruktura
- Innowacja
- Wkłady
- spostrzeżenia
- integrować
- zintegrowany
- Integruje się
- integracja
- Inteligencja
- interwencja
- wprowadzono
- Przedstawia
- Inwestuj
- inwestycja
- zapraszać
- izolacja
- IT
- Praca
- Oferty pracy
- przystąpić
- lipiec
- kafka
- Trzymać
- konserwacja
- Klawisz
- Strumienie danych kinezy
- jezioro
- na dużą skalę
- Utajenie
- uruchomić
- uruchomiona
- lider
- Przywództwo
- nauka
- Dziedzictwo
- poziom
- lekki
- LIMIT
- Lista
- relacja na żywo
- dane na żywo
- załadować
- ładowarka
- załadunek
- Popatrz
- niski
- maszyna
- uczenie maszynowe
- zrobiony
- utrzymać
- konserwacja
- robić
- Dokonywanie
- zarządzanie
- zarządzane
- i konserwacjami
- podręcznik
- Marketo
- maska
- Maksymalizuj
- Pamięć
- migrować
- ML
- modele
- Nowoczesne technologie
- modyfikować
- monitorowane
- monitorowanie
- jeszcze
- przeniesienie
- wielokrotność
- MySQL
- rodzimy
- Potrzebować
- potrzebne
- wymagania
- Nowości
- Nowe funkcje
- numer
- z naszej
- Oferty
- ONE
- koncepcja
- działać
- działanie
- operacje
- operator
- operatorzy
- optymalizacja
- Option
- organizacja
- organizacji
- Inne
- Awarie
- zewnętrzne
- własny
- Pokój
- pakiet
- chleb
- część
- wzmacniacz
- Przeszłość
- Zapłacić
- peleton
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uprawnienia
- Osobiście
- telefon
- fizyczny
- pii
- Miejsce
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- zadowolony
- polityka
- polityka
- Popularny
- Post
- mocny
- Analityka predykcyjna
- zapobiec
- Podgląd
- poprzednio
- Cena
- głównie
- Priorytet
- priorytet
- wygląda tak
- przetwarzanie
- producent
- Produkt
- wydajność
- ochrony
- zapewniać
- dostawca
- dostawców
- zapewnia
- zaopatrzenie
- Python
- pytania
- szybko
- zasięg
- dosięgnąć
- Czytaj
- real
- w czasie rzeczywistym
- dane w czasie rzeczywistym
- otrzymuje
- Recover
- zmniejszyć
- regiony
- niezawodność
- rzetelny
- szczątki
- obsługi produkcji rolnej, która zastąpiła
- raport
- Raportowanie
- wymagania
- ograniczać
- wynikły
- powraca
- przeglądu
- przepisanie
- Bogaty
- sztywny
- Rola
- role
- zwiń
- reguły
- run
- bieganie
- sagemaker
- sprzedawca
- Skala
- waga
- skalowaniem
- scenariusze
- nauka
- Naukowcy
- druga
- sekund
- bezpieczne
- bezpiecznie
- bezpieczeństwo
- wrażliwy
- Wrażliwość
- Bezserwerowe
- służy
- usługa
- Usługi
- Sesja
- zestaw
- Zestawy
- kilka
- Share
- shared
- dzielenie
- pokazać
- Prosty
- uproszczony
- upraszczać
- po prostu
- jednocześnie
- ponieważ
- pojedynczy
- Siedzący
- Rozmiar
- powolny
- So
- Obserwuj Nas
- rozwiązanie
- Rozwiązania
- kilka
- Źródła
- Iskra
- specyficzny
- SQL
- STAGE
- przechowywanie
- sklep
- Strategia
- strumieniowo
- Streaming
- Strumienie
- zbudowany
- dane ustrukturyzowane i nieustrukturyzowane
- taki
- Wspaniały
- dostawcy
- wsparcie
- podpory
- system
- systemy
- stół
- cel
- zespół
- Połączenia
- Przyszłość
- ich
- innych firm
- tysiące
- Przez
- czas
- czasy
- do
- narzędzie
- narzędzia
- Top
- tematy
- Kwota produktów:
- Kontakt
- śledzić
- Pociąg
- transakcyjny
- Przekształcać
- przemiany
- wszechobecny
- nieprzewidziany
- uniwersytet
- nieograniczone
- odblokować
- Aktualizacja
- Nowości
- us
- posługiwać się
- Użytkownik
- Użytkownicy
- Wykorzystując
- wartość
- Wartości
- różnorodny
- wersja
- Zobacz i wysłuchaj
- widoki
- prawie
- Magazyn
- Magazynowanie
- Bogactwo
- zarządzanie majątkiem
- sieć
- Web-based
- Co
- Co to jest
- który
- Podczas
- KIM
- szeroki
- Szeroki zasięg
- szeroko
- będzie
- w ciągu
- bez
- Praca
- pracował
- pracujący
- na calym swiecie
- napisać
- napisany
- rok
- lat
- Twój
- zefirnet
- Strefy