Wprowadzenie
Wyobraź sobie, że stoisz w słabo oświetlonej bibliotece i próbujesz rozszyfrować skomplikowany dokument, jednocześnie żonglując dziesiątkami innych tekstów. Tak wyglądał świat Transformers, zanim gazeta „Attention is All You Need” ujawniła swoje rewolucyjne światło reflektorów – mechanizm uwagi.
Spis treści
Ograniczenia RNN
Tradycyjne modele sekwencyjne, np Powtarzające się sieci neuronowe (RNN), przetwarzał język słowo po słowie, co prowadzi do kilku ograniczeń:
- Zależność krótkiego zasięgu: RNN miały trudności ze zrozumieniem powiązań między odległymi słowami, często błędnie interpretując znaczenie zdań takich jak „człowiek, który wczoraj odwiedził zoo”, w których podmiot i czasownik są bardzo od siebie oddalone.
- Ograniczona równoległość: Sekwencyjne przetwarzanie informacji jest z natury powolne, co uniemożliwia efektywne szkolenie i wykorzystanie zasobów obliczeniowych, zwłaszcza w przypadku długich sekwencji.
- Skoncentruj się na kontekście lokalnym: RNN biorą pod uwagę przede wszystkim bezpośrednich sąsiadów, potencjalnie pomijając kluczowe informacje z innych części zdania.
Ograniczenia te utrudniały Transformersom wykonywanie złożonych zadań, takich jak tłumaczenie maszynowe i rozumienie języka naturalnego. Potem przyszedł mechanizm uwagi, rewolucyjny reflektor, który oświetla ukryte połączenia między słowami, zmieniając nasze rozumienie przetwarzania języka. Ale co dokładnie rozwiązała uwaga i jak zmieniła grę w Transformers?
Skoncentrujmy się na trzech kluczowych obszarach:
Zależność dalekiego zasięgu
- Problem: Tradycyjne modelki często natrafiały na zdania typu „kobieta, która mieszkała na wzgórzu, widziała wczoraj w nocy spadającą gwiazdę”. Ze względu na odległość mieli trudności z połączeniem „kobiety” i „spadającej gwiazdy”, co prowadziło do błędnych interpretacji.
- Mechanizm uwagi: Wyobraź sobie model świecący jasnym promieniem na zdanie, łączący „kobietę” bezpośrednio z „spadającą gwiazdą” i rozumiejący zdanie jako całość. Ta zdolność do uchwycenia relacji niezależnie od odległości jest kluczowa w przypadku zadań takich jak tłumaczenie maszynowe i podsumowania.
Przeczytaj także: Przegląd pamięci krótkotrwałej (LSTM)
Moc przetwarzania równoległego
- Problem: Tradycyjne modele przetwarzały informacje sekwencyjnie, jak czytanie książki strona po stronie. Było to powolne i nieefektywne, szczególnie w przypadku długich tekstów.
- Mechanizm uwagi: Wyobraź sobie, że wiele reflektorów skanuje bibliotekę jednocześnie, analizując równolegle różne części tekstu. Znacząco przyspiesza to pracę modelu, pozwalając mu efektywnie obsługiwać ogromne ilości danych. Ta moc przetwarzania równoległego jest niezbędna do uczenia złożonych modeli i tworzenia prognoz w czasie rzeczywistym.
Globalna świadomość kontekstu
- Problem: Tradycyjne modele często skupiały się na pojedynczych słowach, pomijając szerszy kontekst zdania. Prowadziło to do nieporozumień w przypadkach takich jak sarkazm lub podwójne znaczenie.
- Mechanizm uwagi: Wyobraź sobie, że światło reflektorów pada na całą bibliotekę, przyglądając się każdej książce i rozumiejąc, w jaki sposób są ze sobą powiązane. Ta globalna świadomość kontekstu pozwala modelowi uwzględnić cały tekst podczas interpretacji każdego słowa, co prowadzi do bogatszego i bardziej zniuansowanego zrozumienia.
Ujednoznacznienie słów polisemicznych
- Problem: Słowa takie jak „bank” czy „jabłko” mogą być rzeczownikami, czasownikami, a nawet firmami, tworząc niejasności, z którymi borykały się tradycyjne modele.
- Mechanizm uwagi: Wyobraź sobie, że model rzuca światło na wszystkie wystąpienia słowa „bank” w zdaniu, a następnie analizuje otaczający go kontekst i powiązania z innymi słowami. Biorąc pod uwagę strukturę gramatyczną, pobliskie rzeczowniki, a nawet zdania przeszłe, mechanizm uwagi może wydedukować zamierzone znaczenie. Ta umiejętność ujednoznaczniania słów polisemicznych jest kluczowa w przypadku zadań takich jak tłumaczenie maszynowe, podsumowywanie tekstu i systemy dialogowe.
Te cztery aspekty – zależność dalekiego zasięgu, moc przetwarzania równoległego, świadomość kontekstu globalnego i ujednoznacznienie – ukazują transformacyjną moc mechanizmów uwagi. Dzięki nim Transformers znalazł się na czele przetwarzania języka naturalnego, umożliwiając im radzenie sobie ze złożonymi zadaniami z niezwykłą dokładnością i wydajnością.
W miarę ewolucji NLP, a w szczególności LLM, mechanizmy uwagi będą niewątpliwie odgrywać jeszcze bardziej krytyczną rolę. Stanowią pomost pomiędzy liniową sekwencją słów a bogatym gobelinem ludzkiego języka i ostatecznie są kluczem do uwolnienia prawdziwego potencjału tych językowych cudów. W tym artykule szczegółowo opisano różne typy mechanizmów uwagi i ich funkcje.
1. Samouważność: gwiazda przewodnia transformatora
Wyobraź sobie, że żonglujesz wieloma książkami i podczas pisania streszczenia musisz odwołać się do konkretnych fragmentów każdej z nich. Samouważność lub uwaga skalowanego produktu punktowego działa jak inteligentny asystent, pomagając modelom zrobić to samo z danymi sekwencyjnymi, takimi jak zdania lub szeregi czasowe. Pozwala każdemu elementowi sekwencji zająć się każdym innym elementem, skutecznie wychwytując zależności dalekiego zasięgu i złożone relacje.
Oto bliższe spojrzenie na jego podstawowe aspekty techniczne:
Reprezentacja wektorowa
Każdy element (słowo, punkt danych) przekształcany jest w wielowymiarowy wektor, kodujący jego zawartość informacyjną. Ta przestrzeń wektorowa służy jako podstawa interakcji między elementami.
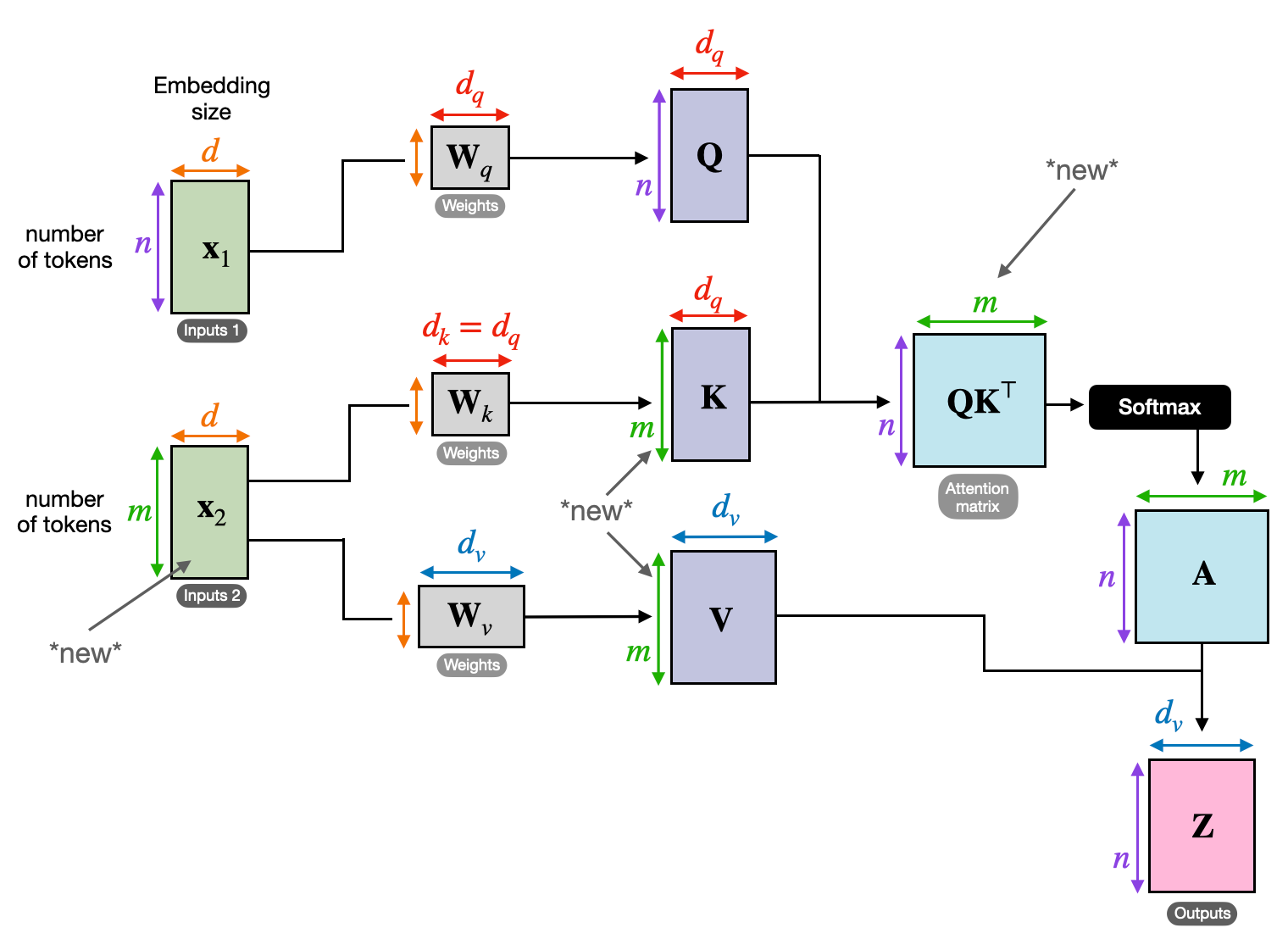
Transformacja QKV
Zdefiniowano trzy kluczowe macierze:
- Zapytanie (Q): Reprezentuje „pytanie”, które każdy element stawia innym. Q wychwytuje potrzeby informacyjne bieżącego elementu i kieruje wyszukiwaniem odpowiednich informacji w sekwencji.
- Klucz (K): Przechowuje „klucz” do informacji o każdym elemencie. K koduje istotę treści każdego elementu, umożliwiając innym elementom identyfikację potencjalnego znaczenia w oparciu o własne potrzeby.
- Wartość (V): Przechowuje rzeczywistą treść, którą każdy element chce udostępnić. V zawiera szczegółowe informacje, do których inne elementy mogą uzyskać dostęp i które mogą wykorzystać na podstawie ich wyników uwagi.
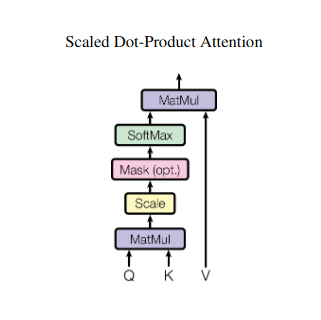
Obliczanie wyniku uwagi
Zgodność pomiędzy każdą parą elementów jest mierzona za pomocą iloczynu skalarnego pomiędzy ich odpowiednimi wektorami Q i K. Wyższe wyniki wskazują na silniejsze potencjalne powiązanie między elementami.
Skalowane wagi uwagi
Aby zapewnić względne znaczenie, te wyniki zgodności są normalizowane za pomocą funkcji softmax. Powoduje to wagi uwagi w zakresie od 0 do 1, reprezentujące ważoną ważność każdego elementu dla kontekstu bieżącego elementu.
Ważona agregacja kontekstu
Wagi uwagi są stosowane do macierzy V, zasadniczo podkreślając ważne informacje z każdego elementu w oparciu o ich znaczenie dla bieżącego elementu. Ta ważona suma tworzy kontekstową reprezentację bieżącego elementu, obejmującą spostrzeżenia zebrane ze wszystkich innych elementów w sekwencji.
Ulepszona reprezentacja elementów
Dzięki wzbogaconej reprezentacji element ma teraz głębsze zrozumienie własnej treści, a także swoich relacji z innymi elementami w sekwencji. Ta przekształcona reprezentacja stanowi podstawę do późniejszego przetwarzania w modelu.
Ten wieloetapowy proces umożliwia samouważności:
- Przechwytuj zależności dalekiego zasięgu: Relacje między odległymi elementami stają się łatwo widoczne, nawet jeśli są oddzielone wieloma elementami pośrednimi.
- Modeluj złożone interakcje: Ujawniają subtelne zależności i korelacje w obrębie sekwencji, co prowadzi do bogatszego zrozumienia struktury i dynamiki danych.
- Kontekstualizuj każdy element: Model analizuje każdy element nie osobno, ale w szerszym kontekście sekwencji, co prowadzi do dokładniejszych i bardziej zróżnicowanych przewidywań lub reprezentacji.
Samouważność zrewolucjonizowała sposób, w jaki modele przetwarzają dane sekwencyjne, otwierając nowe możliwości w różnych dziedzinach, takich jak tłumaczenie maszynowe, generowanie języka naturalnego, prognozowanie szeregów czasowych i nie tylko. Jego zdolność do odkrywania ukrytych relacji w sekwencjach stanowi potężne narzędzie do odkrywania spostrzeżeń i osiągania doskonałej wydajności w szerokim zakresie zadań.
2. Uwaga wielogłowa: patrzenie przez różne soczewki
Samouważność zapewnia całościowy pogląd, ale czasami kluczowe jest skupienie się na konkretnych aspektach danych. Tutaj właśnie pojawia się uwaga wielogłowa. Wyobraź sobie, że masz wielu asystentów, każdy wyposażony w inny obiektyw:
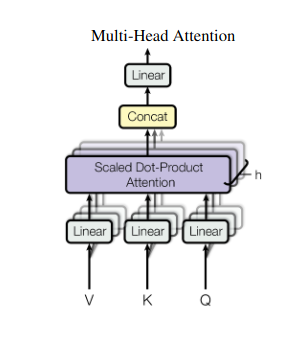
- Wiele „głow” są tworzone, z których każdy dotyczy sekwencji wejściowej poprzez własne macierze Q, K i V.
- Każdy szef uczy się koncentrować na różnych aspektach danych, takich jak zależności dalekiego zasięgu, relacje syntaktyczne lub lokalne interakcje słów.
- Dane wyjściowe z każdej głowicy są następnie łączone i rzutowane na ostateczną reprezentację, która oddaje wieloaspektowy charakter danych wejściowych.
Dzięki temu model może jednocześnie uwzględniać różne perspektywy, co prowadzi do bogatszego i bardziej zniuansowanego zrozumienia danych.
3. Wzajemna uwaga: budowanie mostów pomiędzy sekwencjami
Zdolność rozumienia powiązań pomiędzy różnymi informacjami jest kluczowa dla wielu zadań NLP. Wyobraź sobie, że piszesz recenzję książki – nie tylko streszczasz tekst słowo po słowie, ale raczej wyciągasz wnioski i powiązania między rozdziałami. Wchodzić uwaga krzyżowa, potężny mechanizm, który buduje mosty między sekwencjami, umożliwiając modelom wykorzystanie informacji z dwóch różnych źródeł.
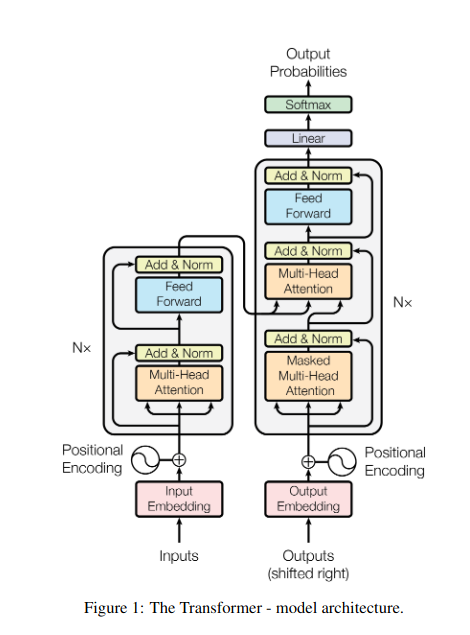
- W architekturach kodera-dekodera, takich jak Transformers, koder przetwarza sekwencję wejściową (książkę) i generuje ukrytą reprezentację.
- Połączenia dekoder wykorzystuje uwagę krzyżową, aby zwrócić uwagę na ukrytą reprezentację kodera na każdym etapie generowania sekwencji wyjściowej (przegląd).
- Macierz Q dekodera współdziała z matrycami K i V kodera, umożliwiając mu skupienie się na odpowiednich fragmentach książki podczas pisania każdego zdania recenzji.
Mechanizm ten jest nieoceniony w przypadku zadań takich jak tłumaczenie maszynowe, podsumowywanie i odpowiadanie na pytania, gdzie niezbędne jest zrozumienie relacji między sekwencjami wejściowymi i wyjściowymi.
4. Uwaga przyczynowa: zachowanie upływu czasu
Wyobraź sobie, że przewidujesz następne słowo w zdaniu, nie patrząc przed siebie. Tradycyjne mechanizmy uwagi borykają się z zadaniami wymagającymi zachowania czasowego porządku informacji, takimi jak generowanie tekstu i prognozowanie szeregów czasowych. Chętnie „wyglądają” w sekwencji, co prowadzi do niedokładnych przewidywań. Uwaga przyczynowa rozwiązuje to ograniczenie, zapewniając, że przewidywania zależą wyłącznie od wcześniej przetworzonych informacji.
Oto jak to działa
- Mechanizm maskujący: Na wagi uwagi nakładana jest specyficzna maska, która skutecznie blokuje modelowi dostęp do przyszłych elementów sekwencji. Na przykład, prognozując drugie słowo w „kobieta, która…”, model może wziąć pod uwagę tylko „the”, a nie „kto” lub kolejne słowa.
- Przetwarzanie autoregresyjne: Informacje przepływają liniowo, a reprezentacja każdego elementu zbudowana jest wyłącznie z elementów występujących przed nim. Model przetwarza sekwencję słowo po słowie, generując prognozy na podstawie ustalonego do tego momentu kontekstu.
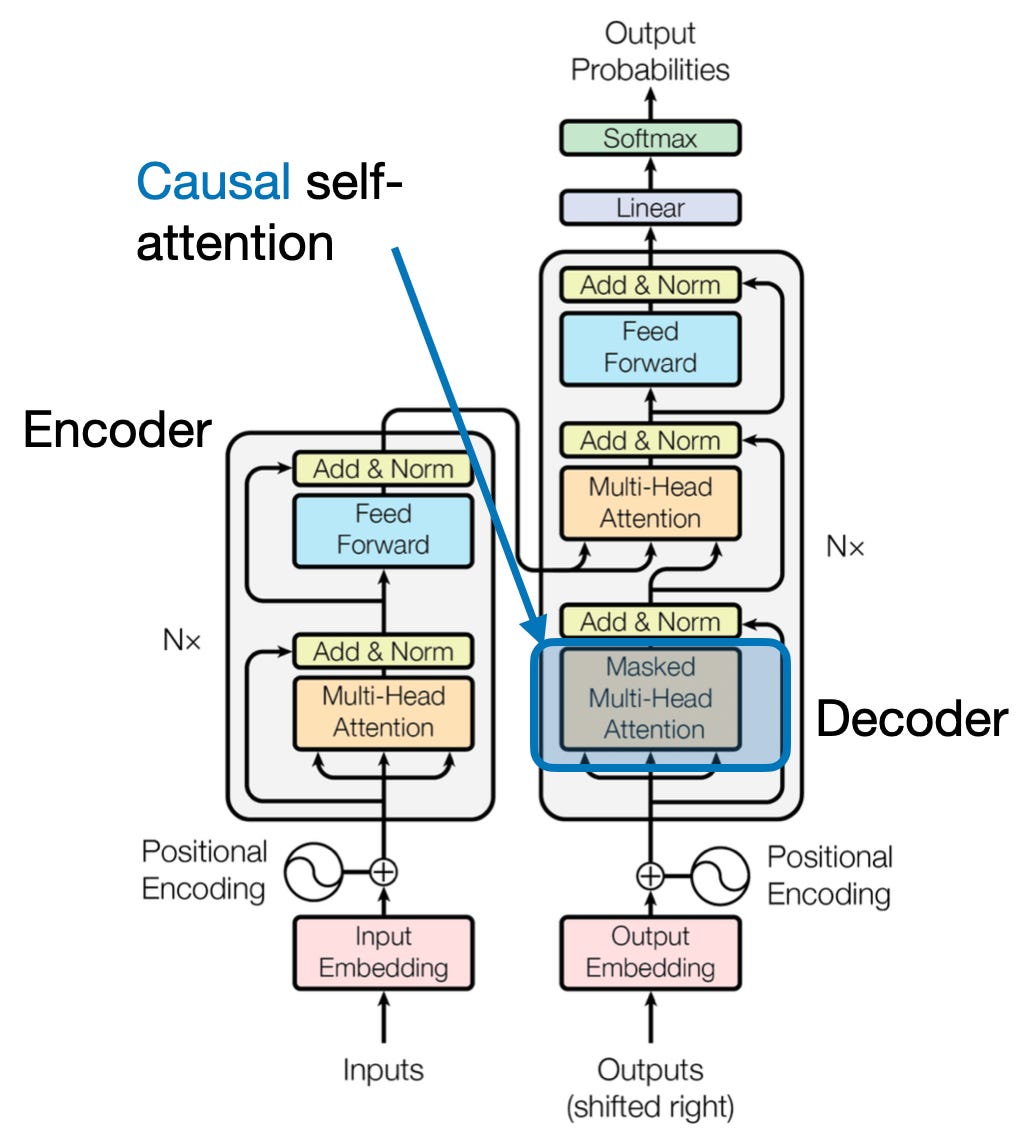
Uwaga przyczynowa ma kluczowe znaczenie w przypadku zadań takich jak generowanie tekstu i prognozowanie szeregów czasowych, gdzie utrzymanie porządku czasowego danych ma kluczowe znaczenie dla dokładnych przewidywań.
5. Uwaga globalna a lokalna: znalezienie równowagi
Mechanizmy uwagi stoją przed kluczowym kompromisem: przechwytywanie zależności dalekiego zasięgu zamiast utrzymywania wydajnych obliczeń. Przejawia się to w dwóch podstawowych podejściach: globalna uwaga i lokalna uwaga. Wyobraź sobie, że czytasz całą książkę, zamiast skupiać się na konkretnym rozdziale. Uwaga globalna przetwarza całą sekwencję na raz, podczas gdy uwaga lokalna skupia się na mniejszym oknie:
- Globalna uwaga przechwytuje zależności dalekiego zasięgu i ogólny kontekst, ale w przypadku długich sekwencji może być kosztowne obliczeniowo.
- Lokalna uwaga jest bardziej efektywny, ale może ominąć odległe relacje.
Wybór między uwagą globalną a lokalną zależy od kilku czynników:
- Wymagania zadania: Zadania takie jak tłumaczenie maszynowe wymagają uchwycenia odległych relacji, co sprzyja uwadze globalnej, podczas gdy analiza nastrojów może sprzyjać skupieniu uwagi lokalnej.
- Długość sekwencji: Dłuższe sekwencje sprawiają, że uwaga globalna jest kosztowna obliczeniowo, co wymaga podejścia lokalnego lub hybrydowego.
- Pojemność modelu: Ograniczenia zasobów mogą wymagać uwagi lokalnej nawet w przypadku zadań wymagających kontekstu globalnego.
Aby osiągnąć optymalną równowagę, modele mogą wykorzystywać:
- Przełączanie dynamiczne: wykorzystaj uwagę globalną dla kluczowych elementów i uwagę lokalną dla innych, dostosowując się do ważności i odległości.
- Podejścia hybrydowe: połącz oba mechanizmy w ramach tej samej warstwy, wykorzystując ich mocne strony.
Przeczytaj także: Analiza typów sieci neuronowych w głębokim uczeniu się
Wnioski
Ostatecznie idealne podejście opiera się na spektrum uwagi globalnej i lokalnej. Zrozumienie tych kompromisów i przyjęcie odpowiednich strategii umożliwia modelom efektywne wykorzystanie odpowiednich informacji w różnych skalach, co prowadzi do bogatszego i dokładniejszego zrozumienia sekwencji.
Referencje
- Raszczka, S. (2023). „Zrozumienie i kodowanie samouwagi, uwagi wielogłowej, uwagi krzyżowej i uwagi przyczynowej w LLM”.
- Vaswani, A. i in. (2017). „Wszystko, czego potrzebujesz, to uwaga”.
- Radford, A. i in. (2019). „Modele językowe to osoby uczące się wielozadaniowo bez nadzoru”.
Związane z
Jestem miłośnikiem danych i uwielbiam wydobywać i rozumieć ukryte wzorce w danych. Chcę się uczyć i rozwijać w dziedzinie uczenia maszynowego i data science.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- zdolność
- dostęp
- precyzja
- dokładny
- Osiągać
- osiągnięcia
- w poprzek
- Dzieje Apostolskie
- rzeczywisty
- Adresy
- Przyjęcie
- przed
- AL
- Wszystkie kategorie
- Pozwalać
- pozwala
- am
- Dwuznaczność
- kwoty
- an
- analiza
- ćwiczenie
- Analizując
- i
- sekretarka
- osobno
- pozorny
- stosowany
- podejście
- awanse
- SĄ
- obszary
- artykuł
- AS
- aspekty
- Asystent
- asystenci
- At
- uczęszczać
- uczestniczyć
- Uwaga
- świadomość
- Bilans
- na podstawie
- podstawa
- BE
- Belka
- stają się
- zanim
- pomiędzy
- Poza
- bloking
- książka
- Książki
- obie
- BRIDGE
- mosty
- Jasny
- szerszy
- przyniósł
- Budowanie
- Buduje
- wybudowany
- ale
- by
- oprawa ołowiana witrażu
- CAN
- zdobyć
- przechwytuje
- Przechwytywanie
- Etui
- zmiana
- Rozdział
- rozdziały
- wybór
- bliższy
- Kodowanie
- połączyć
- byliśmy spójni, od początku
- Firmy
- zgodność
- kompleks
- obliczenia
- obliczeniowy
- Skontaktuj się
- Podłączanie
- połączenia
- Rozważać
- wobec
- Ograniczenia
- zawiera
- zawartość
- kontekst
- kontynuować
- rdzeń
- korelacje
- stworzony
- tworzy
- Tworzenie
- krytyczny
- istotny
- Aktualny
- dane
- nauka danych
- Odszyfrować
- głęboko
- głębiej
- zdefiniowane
- zagłębia się
- zależeć
- zależność
- Zależności
- Zależność
- zależy
- szczegółowe
- Dialog
- ZROBIŁ
- różne
- bezpośrednio
- dystans
- Odległy
- odrębny
- inny
- do
- dokument
- DOT
- Podwójna
- dziesiątki
- dramatycznie
- rysować
- z powodu
- dynamika
- E i T
- każdy
- faktycznie
- efektywność
- wydajny
- skutecznie
- element
- Elementy
- uprawniającej
- Umożliwia
- umożliwiając
- kodowanie
- Wzbogacony
- zapewnić
- zapewnienie
- Wchodzę
- Cały
- całość
- wyposażony
- szczególnie
- istota
- niezbędny
- istotnie
- ustanowiony
- Parzyste
- Każdy
- ewoluuje
- dokładnie
- drogi
- Wykorzystać
- wyciąg
- Twarz
- Czynniki
- daleko
- faworyzować
- pole
- Łąka
- finał
- pływ
- Przepływy
- Skupiać
- koncentruje
- koncentruje
- skupienie
- W razie zamówieenia projektu
- czoło
- formularze
- Fundacja
- cztery
- Framework
- od
- funkcjonować
- funkcjonalności
- przyszłość
- gra
- generuje
- generujący
- generacja
- Globalne
- kontekst globalny
- chwycić
- Rosnąć
- Przewodniki
- przewodnictwo
- uchwyt
- Have
- mający
- głowa
- pomoc
- Ukryty
- Wysoki
- wyższy
- podświetlanie
- posiada
- holistyczne
- W jaki sposób
- HTTPS
- człowiek
- Hybrydowy
- i
- idealny
- zidentyfikować
- if
- obraz
- Natychmiastowy
- znaczenie
- ważny
- in
- niedokładny
- włączenie
- wskazać
- indywidualny
- niewydajny
- Informacja
- właściwie
- wkład
- spostrzeżenia
- przykład
- Inteligentny
- zamierzony
- wzajemne oddziaływanie
- Interakcje
- współdziała
- interweniować
- najnowszych
- nieoceniony
- izolacja
- IT
- JEGO
- jpg
- właśnie
- Klawisz
- Kluczowe obszary
- język
- Nazwisko
- warstwa
- prowadzący
- UCZYĆ SIĘ
- Ucz się i rozwijaj
- uczniowie
- nauka
- Doprowadziło
- Obiektyw
- obiektywy
- Dźwignia
- lewarowanie
- Biblioteka
- leży
- lekki
- lubić
- ograniczenie
- Ograniczenia
- miejscowy
- długo
- dłużej
- Popatrz
- miłość
- maszyna
- uczenie maszynowe
- tłumaczenie maszynowe
- utrzymanie
- robić
- Dokonywanie
- mężczyzna
- wiele
- maska
- Matrix
- Maksymalna szerokość
- znaczenie
- znaczenia
- mierzona
- mechanizm
- Mechanizmy
- Pamięć
- może
- tęsknić
- brakujący
- model
- modele
- jeszcze
- bardziej wydajny
- wieloaspektowy
- wielokrotność
- Naturalny
- Język naturalny
- Generowanie języka naturalnego
- Przetwarzanie języka naturalnego
- Zrozumienie naturalnego języka
- Natura
- Potrzebować
- potrzeba
- wymagania
- sąsiedzi
- sieci
- Nerwowy
- sieci neuronowe
- Nowości
- Następny
- noc
- nlp
- rzeczowniki
- już dziś
- niuansowany
- of
- często
- on
- pewnego razu
- tylko
- Optymalny
- or
- zamówienie
- Inne
- Pozostałe
- ludzkiej,
- na zewnątrz
- wydajność
- Wyjścia
- ogólny
- przegląd
- własny
- strona
- đôi
- Papier
- Parallel
- strony
- fragmenty
- Przeszłość
- wzory
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- perspektywy
- sztuk
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- punkt
- stwarza
- posiada
- możliwości
- silny
- potencjał
- potencjalnie
- power
- mocny
- przewidywanie
- Przewidywania
- konserwowanie
- zapobieganie
- poprzednio
- głównie
- pierwotny
- wygląda tak
- obrobiony
- procesów
- przetwarzanie
- Moc przetwarzania
- Produkt
- Przewiduje
- napędzany
- zapewnia
- pytanie
- zasięg
- nośny
- raczej
- Czytaj
- łatwo
- Czytający
- w czasie rzeczywistym
- odniesienie
- Bez względu
- Relacje
- względny
- mających znaczenie
- znakomity
- reprezentacja
- reprezentowanie
- reprezentuje
- wymagać
- rozwiązać
- Zasób
- Zasoby
- osób
- Efekt
- przeglądu
- rewolucyjny
- zrewolucjonizował
- Bogaty
- Rola
- s
- taki sam
- Sarkazm
- zobaczył
- waga
- skanowanie
- nauka
- wynik
- wyniki
- Szukaj
- druga
- widzenie
- wyrok
- sentyment
- Sekwencja
- Serie
- służy
- kilka
- Share
- świecący
- strzelanie
- Short
- prezentacja
- jednocześnie
- powolny
- mniejszy
- Wyłącznie
- ROZWIĄZANIA
- czasami
- Źródła
- Typ przestrzeni
- specyficzny
- swoiście
- Widmo
- prędkości
- reflektor
- stojący
- Gwiazda
- Ewolucja krok po kroku
- sklep
- strategie
- silne strony
- silniejszy
- Struktura
- Walka
- Walka
- przedmiot
- kolejny
- taki
- odpowiedni
- suma
- streszczać
- PODSUMOWANIE
- przełożony
- otaczający
- systemy
- sprzęt
- biorąc
- gobelin
- zadania
- Techniczny
- semestr
- XNUMX
- generowanie tekstu
- że
- Połączenia
- świat
- ich
- Im
- następnie
- Te
- one
- to
- trzy
- Przez
- czas
- Szereg czasowy
- do
- narzędzie
- tradycyjny
- Trening
- transformacyjny
- przekształcony
- transformator
- Transformatory
- transformatorowy
- Tłumaczenie
- prawdziwy
- drugiej
- typy
- Ostatecznie
- zrozumieć
- zrozumienie
- niewątpliwie
- odblokowywanie
- demaskować
- odsłonięty
- posługiwać się
- zastosowania
- za pomocą
- różnorodny
- Naprawiono
- Przeciw
- Zobacz i wysłuchaj
- odwiedził
- istotny
- vs
- chcieć
- chce
- była
- DOBRZE
- Co
- jeśli chodzi o komunikację i motywację
- Podczas
- KIM
- cały
- szeroki
- Szeroki zasięg
- będzie
- okno
- w
- w ciągu
- bez
- kobieta
- słowo
- słowa
- Praca
- świat
- pisanie
- wczoraj
- ty
- zefirnet
- ZOO