Zdjęcie autora
Podczas pracy z danymi i różnymi zmiennymi przypisanie jednej zmiennej lub wartości jako większej od drugiej jest łatwe. Możemy założyć, że określona zmienna lub punkt danych miały większy wpływ na wynik, ale czy jesteśmy pewni, że inne zmienne mają taki sam wpływ?
W statystyce stopa bazowa może być postrzegana jako prawdopodobieństwa klas, które są bezwarunkowe w stosunku do „dowodów charakterystycznych”. Możesz zobaczyć stopę bazową jako swoje wcześniejsze założenie dotyczące prawdopodobieństwa.
Stawki bazowe są ważnymi narzędziami w badaniach. Na przykład, jeśli jesteśmy firmą farmaceutyczną i jesteśmy w trakcie opracowywania i wysyłania nowej szczepionki, chcemy przyjrzeć się powodzeniu leczenia. Jeśli mamy 4000 osób, które są chętne na to szczepienie, a nasza stawka podstawowa to 1/25.
Oznacza to, że z 160 osób tylko 4000 osób zostanie skutecznie wyleczonych. W świecie farmaceutycznym jest to bardzo niski wskaźnik sukcesu. W ten sposób można wykorzystać stawki podstawowe do poprawy badań i dokładności oraz zapewnienia, że produkt będzie działał dobrze.
Jeśli podzielimy słowa, da nam to lepsze zrozumienie. Błąd oznacza błędne przekonanie lub błędne rozumowanie. Jeśli teraz połączymy to z naszą powyższą definicją stopy bazowej.
Błąd stopy bazowej, znany również jako błąd stopy bazowej i zaniedbanie stopy bazowej, polega na prawdopodobieństwie oceny konkretnej sytuacji bez uwzględnienia wszystkich istotnych danych.
Błąd stopy bazowej zawiera informacje o stopie bazowej, a także inne istotne informacje. Może to wynikać z różnych przyczyn, takich jak niedokładne zbadanie i przeanalizowanie danych we właściwy sposób lub nieumiejętność faworyzowania określonej części danych.
Błąd stopy bazowej opisuje tendencję kogoś do lekceważenia istniejących informacji o stopie bazowej, naciskania i opowiadania się za nowymi informacjami. Jest to sprzeczne z podstawowymi zasadami rozumowania opartego na dowodach.
Zazwyczaj słyszysz o tym, co dzieje się w branży finansowej. Na przykład inwestorzy będą opierać swoją taktykę kupowania lub udostępniania na irracjonalnych informacjach, co prowadzi do wahań na rynku – pomimo znajomości stopy bazowej.
Więc teraz mamy lepsze zrozumienie stopy bazowej i mitu stopy bazowej. Jakie jest jego znaczenie i wpływ w Data Science?
Mówiliśmy o „prawdopodobieństwach klas” i „biorąc pod uwagę wszystkie istotne dane”. Jeśli jesteś naukowcem danych lub inżynierem uczenia maszynowego lub stawiasz pierwsze kroki w drzwiach – będziesz wiedział, jak ważne są prawdopodobieństwa i odpowiednie dane do generowania dokładnych danych wyjściowych, procesu uczenia się modelu uczenia maszynowego i tworzenia modeli o wysokiej wydajności.
Aby analizować i przewidywać dane lub aby model uczenia maszynowego generował dokładne dane wyjściowe — musisz wziąć pod uwagę każdy bit danych. Gdy przeglądasz swoje dane po raz pierwszy, możesz uznać niektóre części za istotne, a inne za nieistotne. Jednak jest to twoja ocena i nie jest jeszcze oparta na faktach, dopóki nie zostanie przeprowadzona właściwa analiza.
Jak wspomniano powyżej, początkowa stawka podstawowa pomaga zapewnić dokładność i tworzyć modele o wysokiej wydajności. Jak więc możemy to zrobić w Data Science?
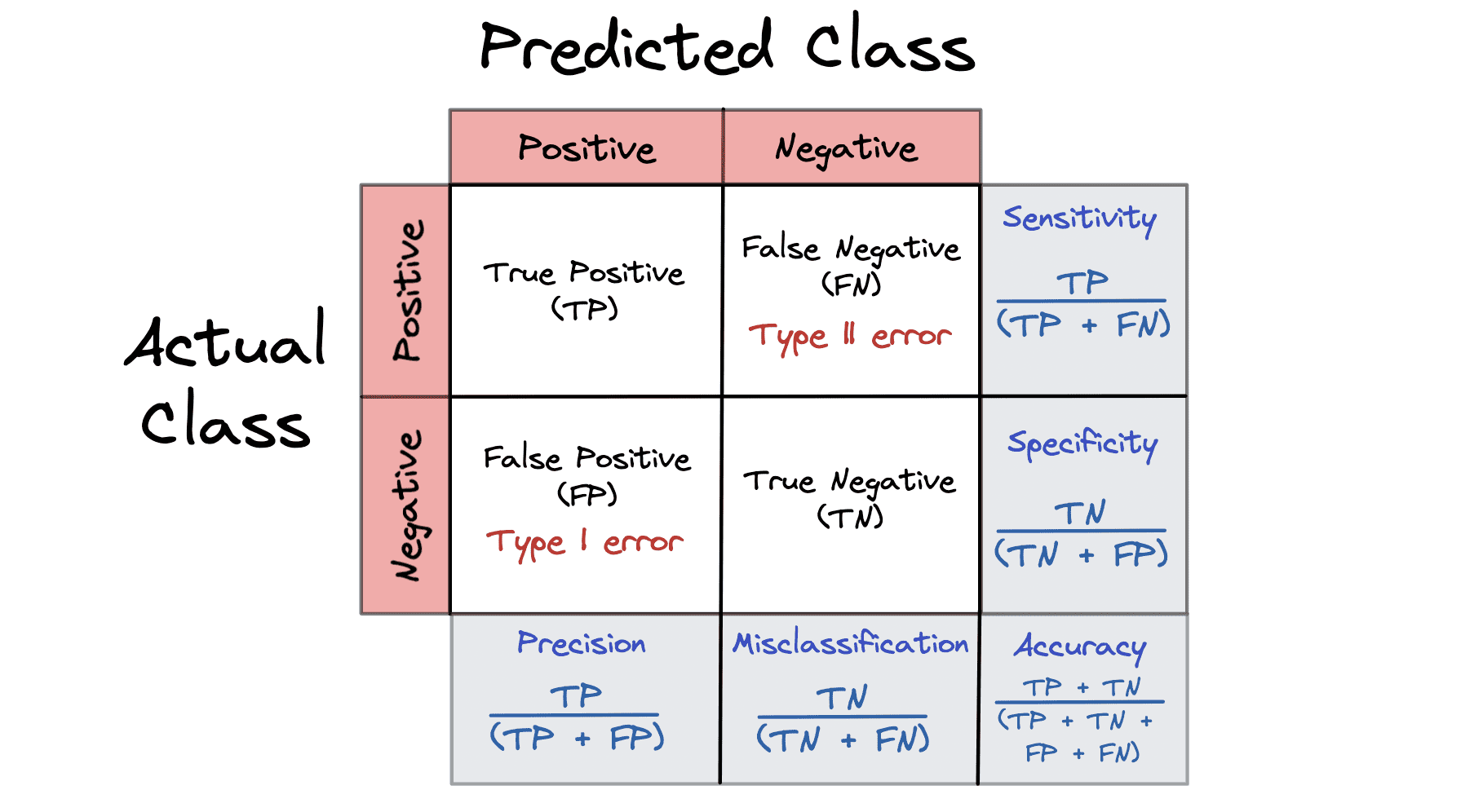
Macierz zamieszania
Matryca zamieszania to pomiar wydajności, który zapewnia podsumowanie wyników przewidywania problemu klasyfikacji. Wszystkie macierze zamieszania są oparte na wyniku: Prawda, Fałsz, Pozytywny i Negatywny.
Macierz nieporozumień przedstawia przewidywania naszego modelu podczas fazy testowania. Wyniki fałszywie ujemne i fałszywie dodatnie w macierzy zamieszania to przykłady błędnej stopy bazowej.
- True Positive (TP) – Twój model przewidywał wynik dodatni i jest dodatni
- True Negative (TN) – Twój model przewidywał ujemne i jest ujemne
- False Positive (FP) – Twój model przewidywał wynik dodatni i jest ujemny
- False Negative (FN) – Twój model przewidywał wynik ujemny i jest dodatni
Macierz nieporozumień może obliczyć 5 różnych wskaźników, które pomogą nam zmierzyć ważność naszego modelu:
- Błędna klasyfikacja = FP + FN / TP + TN + FP + FN
- Precyzja = TP / TP + FP
- Dokładność = TP + TN / TP + TN + FP + FN
- Swoistość = TN / TN + FP
- Czułość czyli Recall = TP / TP + FN
Aby lepiej zrozumieć macierz nieporozumień, lepiej spojrzeć na wizualizację:
Zdjęcie autora
Czytając ten artykuł, prawdopodobnie możesz pomyśleć o różnych przyczynach błędnej stopy bazowej, takich jak nieuwzględnienie wszystkich istotnych danych, błąd ludzki lub brak precyzji.
Chociaż wszystkie one są prawdziwe i zwiększają przyczynę błędu stopy bazowej. Wszystkie dotyczą największego problemu, jakim jest ignorowanie informacji o stawce podstawowej. Informacje o stawce podstawowej są często ignorowane, ponieważ są uważane za nieistotne, jednak informacje o stopie podstawowej mogą zaoszczędzić ludziom dużo czasu i pieniędzy. Korzystanie z dostępnych informacji o stopie bazowej pozwala na dokładniejsze określanie prawdopodobieństwa wystąpienia danego zdarzenia.
Korzystanie z informacji o stawce podstawowej pomoże uniknąć błędnej stopy procentowej.
Świadomość błędów, takich jak opinie, automatyczne procesy itp. – pozwoli Ci walczyć z błędem stopy bazowej i zredukować potencjalne błędy. Kiedy mierzysz prawdopodobieństwo wystąpienia określonego zdarzenia, metody bayesowskie mogą pomóc w zmniejszeniu błędu stopy bazowej.
Stawka podstawowa jest ważna w nauce o danych, ponieważ zapewnia podstawową wiedzę na temat oceny badania lub projektu oraz dostrajania modelu — zapewniając ogólny wzrost dokładności i wydajności.
Jeśli chcesz obejrzeć film o błędnych stawkach bazowych w medycynie, obejrzyj ten film: Paradoks testów medycznych
Nisza Arja jest analitykiem danych, niezależnym pisarzem technicznym i menedżerem ds. społeczności w KDnuggets. Jest szczególnie zainteresowana udzielaniem porad dotyczących kariery w Data Science lub samouczkami i wiedzą opartą na teorii wokół Data Science. Chciałaby również zbadać różne sposoby, w jakie sztuczna inteligencja jest / może korzystnie wpłynąć na długowieczność ludzkiego życia. Chętnie się uczy, stara się poszerzyć swoją wiedzę techniczną i umiejętności pisania, jednocześnie pomagając innym.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-base-rate-fallacy-and-its-impact-on-data-science
- :ma
- :Jest
- :nie
- $W GÓRĘ
- a
- O nas
- powyżej
- precyzja
- dokładny
- Rada
- przed
- Wszystkie kategorie
- pozwala
- również
- an
- analizować
- analiza
- Analizując
- i
- SĄ
- na około
- artykuł
- sztuczny
- sztuczna inteligencja
- AS
- założenie
- At
- automatycznie
- dostępny
- baza
- na podstawie
- Bayesian
- BE
- wiara
- korzyści
- Ulepsz Swój
- stronniczość
- Najwyższa
- Bit
- poszerzać
- Zakup
- by
- obliczać
- CAN
- Kariera
- Spowodować
- Przyczyny
- pewien
- ZOBACZ
- Klasy
- klasyfikacja
- zwalczania
- połączyć
- społeczność
- sukcesy firma
- zamieszanie
- Rozważać
- wynagrodzenie
- za
- dane
- nauka danych
- naukowiec danych
- Mimo
- rozwijanie
- różne
- Drzwi
- podczas
- inżynier
- zapewnić
- błąd
- Błędy
- itp
- wydarzenie
- Każdy
- dowód
- Badanie
- przykład
- przykłady
- Przede wszystkim system został opracowany
- odkryj
- Faktyczny
- wadliwy
- pole
- budżetowy
- i terminów, a
- pierwszy raz
- fluktuacja
- Stopa
- W razie zamówieenia projektu
- wolny zawód
- fundamentalny
- miejsce
- Dać
- dany
- Goes
- będzie
- większy
- poprowadzi
- Wydarzenie
- Have
- mający
- słyszeć
- pomoc
- pomoc
- pomaga
- wysoka wydajność
- W jaki sposób
- How To
- Jednak
- HTTPS
- człowiek
- Niewiedza
- Rezultat
- ważny
- podnieść
- in
- Zwiększać
- przemysł
- Informacja
- początkowy
- Inteligencja
- zainteresowany
- najnowszych
- Inwestorzy
- problem
- IT
- JEGO
- Knuggety
- Zapalony
- Wiedzieć
- wiedza
- znany
- Brak
- Wyprowadzenia
- uczeń
- nauka
- życie
- lubić
- długowieczność
- Popatrz
- Partia
- niski
- maszyna
- uczenie maszynowe
- robić
- Dokonywanie
- kierownik
- rynek
- Matrix
- Może..
- znaczy
- zmierzyć
- zmierzenie
- medyczny
- wzmiankowany
- metody
- Metryka
- może
- model
- modele
- pieniądze
- jeszcze
- Potrzebować
- ujemny
- Nowości
- już dziś
- of
- on
- ONE
- tylko
- Opinie
- or
- Inne
- Pozostałe
- ludzkiej,
- Wynik
- wydajność
- ogólny
- część
- szczególnie
- strony
- Ludzie
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- Przemysł farmaceutyczny
- faza
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- pozytywny
- potencjał
- precyzyjny
- Detaliczność
- Przewiduje
- przepowiednia
- Przewidywania
- Wcześniejszy
- prawdopodobieństwo
- prawdopodobnie
- Problem
- wygląda tak
- procesów
- produkować
- Produkt
- projekt
- właściwy
- prawidłowo
- zapewnia
- że
- Naciskać
- Kurs
- ceny
- Przyczyny
- zmniejszyć
- mających znaczenie
- reprezentuje
- Badania naukowe
- Efekt
- reguły
- s
- Zapisz
- skanowanie
- nauka
- Naukowiec
- poszukuje
- dzielenie
- sytuacja
- umiejętności
- So
- kilka
- Ktoś
- specyficzny
- dzielić
- statystyka
- Badanie
- sukces
- Z powodzeniem
- taki
- PODSUMOWANIE
- taktyka
- Brać
- biorąc
- tech
- Techniczny
- test
- Testowanie
- niż
- że
- Połączenia
- ich
- Te
- to
- całkowicie
- Przez
- czas
- do
- narzędzia
- leczenie
- prawdziwy
- tutoriale
- zazwyczaj
- bezwarunkowy
- zrozumieć
- zrozumienie
- us
- używany
- wartość
- różnorodność
- różnorodny
- Wideo
- Oglądaj
- sposoby
- we
- DOBRZE
- Co
- Co to jest
- czy
- który
- Podczas
- KIM
- będzie
- skłonny
- Życzenia
- w
- słowa
- pracujący
- świat
- by
- pisarz
- pisanie
- ty
- Twój
- zefirnet