Pracownia Kleju AWS to interfejs graficzny, który ułatwia tworzenie, uruchamianie i monitorowanie zadań wyodrębniania, przekształcania i ładowania (ETL) w Klej AWS. Pozwala wizualnie komponować przepływy pracy transformacji danych za pomocą węzłów reprezentujących różne etapy obsługi danych, które później są automatycznie konwertowane na kod do uruchomienia.
Pracownia Kleju AWS niedawno wydany 10 dodatkowych przekształceń wizualnych, aby umożliwić tworzenie bardziej zaawansowanych zadań w sposób wizualny bez umiejętności kodowania. W tym poście omawiamy potencjalne przypadki użycia, które odzwierciedlają typowe potrzeby ETL.
Nowe przekształcenia, które zostaną zademonstrowane w tym poście, to: Concatenate, Split String, Array To Columns, Add Current Timestamp, Pivot Rows To Columns, Unpivot Columns To Rows, Lookup, Explode Array or Map Into Columns, Derived Column i Autobalance Processing .
Omówienie rozwiązania
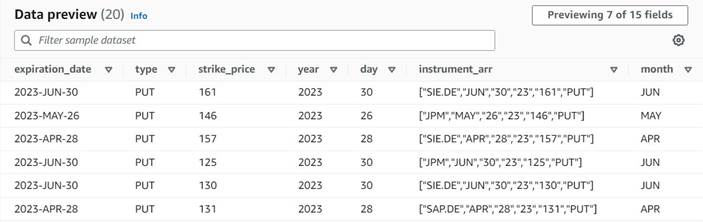
W tym przypadku mamy kilka plików JSON z operacjami opcji na akcje. Chcemy dokonać pewnych przekształceń przed zapisaniem danych, aby ułatwić ich analizę, a także chcemy utworzyć osobne podsumowanie zbioru danych.
W tym zbiorze danych każdy wiersz reprezentuje transakcję kontraktów opcyjnych. Opcje to instrumenty finansowe, które dają prawo – ale nie obowiązek – kupna lub sprzedaży akcji po ustalonej cenie (tzw Cena wykonania) przed określoną datą wygaśnięcia.
Dane wejściowe
Dane są zgodne z następującym schematem:
- order_id – Unikalny identyfikator
- symbol – Kod na ogół oparty na kilku literach identyfikujący korporację, która emituje bazowe akcje
- instrument – Nazwa, która identyfikuje konkretną kupowaną lub sprzedawaną opcję
- waluta – Kod waluty ISO, w którym wyrażona jest cena
- Cena – Kwota, która została zapłacona za zakup każdego kontraktu opcyjnego (na większości giełd jeden kontrakt pozwala na kupno lub sprzedaż 100 akcji)
- wymiana – Kod centrum wymiany lub miejsca, w którym opcja była przedmiotem obrotu
- sprzedany – Lista liczby kontraktów, które zostały przydzielone do realizacji zlecenia sprzedaży, gdy jest to transakcja sprzedaży
- kupiony – Lista liczby kontraktów, które zostały przydzielone do realizacji zlecenia kupna, gdy jest to transakcja kupna
Poniżej znajduje się próbka danych syntetycznych wygenerowanych dla tego posta:
wymagania ETL
Dane te mają szereg unikalnych cech, często spotykanych w starszych systemach, które utrudniają korzystanie z nich.
Oto wymagania ETL:
- Nazwa instrumentu zawiera cenne informacje, które mają być zrozumiałe dla ludzi; chcemy znormalizować to do oddzielnych kolumn dla łatwiejszej analizy.
- Atrybuty
boughtisoldwzajemnie się wykluczają; możemy skonsolidować je w jedną kolumnę z numerami kontraktów i mieć inną kolumnę wskazującą, czy kontrakty zostały kupione czy sprzedane w tej kolejności. - Chcemy zachować informacje o poszczególnych alokacjach kontraktów, ale jako pojedyncze wiersze, zamiast zmuszać użytkowników do radzenia sobie z tablicą liczb. Moglibyśmy zsumować liczby, ale stracilibyśmy informacje o tym, jak zlecenie zostało zrealizowane (wskazujące na płynność rynku). Zamiast tego zdecydowaliśmy się zdenormalizować tabelę, aby każdy wiersz miał jedną liczbę kontraktów, dzieląc zamówienia z wieloma liczbami na osobne wiersze. W skompresowanym formacie kolumnowym dodatkowy rozmiar zestawu danych związany z tym powtórzeniem jest często mały po zastosowaniu kompresji, dlatego dopuszczalne jest ułatwienie wykonywania zapytań dotyczących zestawu danych.
- Chcemy wygenerować zbiorczą tabelę wolumenu dla każdego typu opcji (call i put) dla każdej akcji. Zapewnia to wskazanie nastrojów rynkowych dla każdej akcji i ogólnie rynku (chciwość vs. strach).
- Aby umożliwić ogólne podsumowania transakcji, chcemy podać dla każdej operacji sumę całkowitą i ustandaryzować walutę na dolary amerykańskie, korzystając z przybliżonego odniesienia do konwersji.
- Chcemy dodać datę, kiedy te przemiany miały miejsce. Może to być przydatne, na przykład, aby mieć odniesienie do tego, kiedy dokonano przeliczenia waluty.
W oparciu o te wymagania zadanie wygeneruje dwa wyniki:
- Plik CSV z podsumowaniem liczby kontraktów dla każdego symbolu i typu
- Tabela katalogowa do przechowywania historii zamówienia, po wykonaniu wskazanych przekształceń
Wymagania wstępne
Będziesz potrzebować własnego wiadra S3, aby śledzić ten przypadek użycia. Aby utworzyć nowy zasobnik, zobacz Tworzenie wiadra.
Generuj dane syntetyczne
Aby śledzić ten post (lub samodzielnie eksperymentować z tego rodzaju danymi), możesz wygenerować ten zestaw danych w sposób syntetyczny. Poniższy skrypt Pythona można uruchomić w środowisku Pythona z zainstalowanym Boto3 i dostępem do niego Usługa Amazon Simple Storage (Amazonka S3).
Aby wygenerować dane, wykonaj następujące kroki:
- W AWS Glue Studio utwórz nowe zadanie z opcją Edytor skryptów powłoki Pythona.
- Podaj nazwę pracy i na Szczegóły pracy wybierz a odpowiednia rola i nazwę skryptu Pythona.
- W Szczegóły pracy sekcja, rozwiń Zaawansowane właściwości i przewiń w dół do Parametry zadania.
- Wprowadź parametr o nazwie
--bucketi przypisz jako wartość nazwę zasobnika, w którym chcesz przechowywać przykładowe dane. - Wprowadź następujący skrypt do edytora powłoki AWS Glue:
- Uruchom zadanie i poczekaj, aż na karcie Uruchomienia zostanie wyświetlone jako zakończone pomyślnie (powinno to zająć tylko kilka sekund).
Każde uruchomienie wygeneruje plik JSON z 1,000 wierszy w określonym zasobniku i prefiksie transformsblog/inputdata/. Możesz uruchomić zadanie wiele razy, jeśli chcesz przetestować więcej plików wejściowych.
Każdy wiersz danych syntetycznych to wiersz danych reprezentujący obiekt JSON, taki jak ten:
Utwórz zadanie wizualne AWS Glue
Aby utworzyć zadanie wizualne AWS Glue, wykonaj następujące kroki:
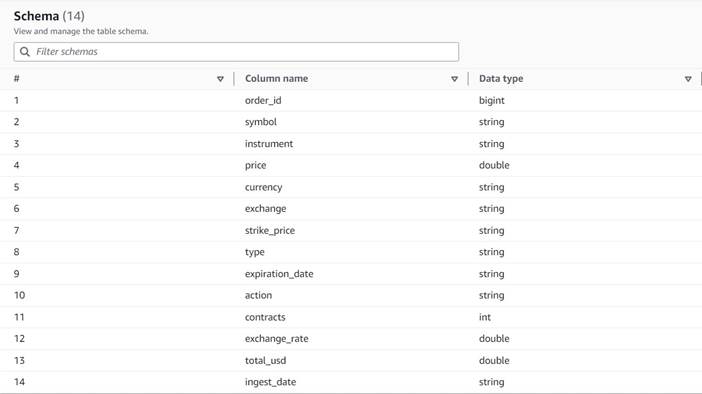
- Przejdź do AWS Glue Studio i utwórz zadanie za pomocą opcji Wizualne z pustym płótnem.
- Edytuj
Untitled jobnadać mu nazwę i przypisać rola odpowiednia dla kleju AWS na Szczegóły pracy patka. - Dodaj źródło danych S3 (możesz je nazwać
JSON files source) i wprowadź adres URL S3, pod którym przechowywane są pliki (np.s3://<your bucket name>/transformsblog/inputdata/), a następnie wybierz JSON jako format danych. - Wybierz Wywnioskować schemat więc ustawia schemat wyjściowy na podstawie danych.
Z tego węzła źródłowego będziesz nadal łączyć transformacje. Podczas dodawania każdej transformacji upewnij się, że wybrany węzeł jest ostatnim dodanym, aby został przypisany jako element nadrzędny, chyba że w instrukcjach wskazano inaczej.
Jeśli nie wybrałeś odpowiedniego rodzica, zawsze możesz edytować rodzica, zaznaczając go i wybierając innego rodzica w okienku konfiguracji.
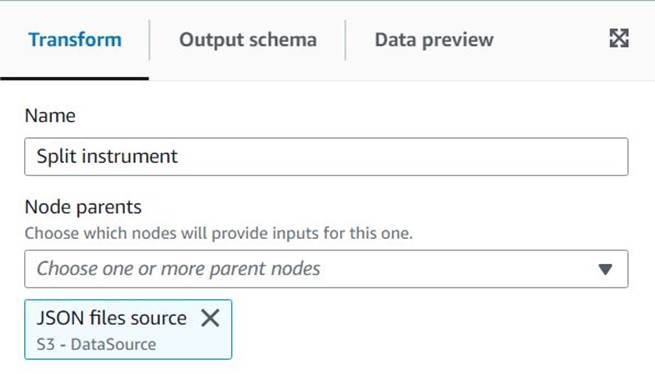
Dla każdego dodanego węzła nadasz mu określoną nazwę (aby cel węzła był pokazany na wykresie) i konfigurację na Przekształcać patka.
Za każdym razem, gdy transformacja zmienia schemat (na przykład dodaje nową kolumnę), schemat wyjściowy musi zostać zaktualizowany, aby był widoczny dla dalszych transformacji. Możesz ręcznie edytować schemat wyjściowy, ale bardziej praktyczne i bezpieczniejsze jest zrobienie tego za pomocą podglądu danych.
Dodatkowo w ten sposób możesz sprawdzić, czy transformacja działa zgodnie z oczekiwaniami. W tym celu otwórz plik Podgląd danych kartę z wybraną transformacją i rozpocznij sesję podglądu. Po sprawdzeniu, czy przekształcone dane wyglądają zgodnie z oczekiwaniami, przejdź do Schemat wyjściowy kartę i wybierz Użyj schematu podglądu danych automatycznej aktualizacji schematu.
Podczas dodawania nowych rodzajów przekształceń podgląd może wyświetlać komunikat o brakującej zależności. Kiedy tak się stanie, wybierz Zakończ sesję i rozpocznij nowy, więc podgląd wybiera nowy rodzaj węzła.
Wyodrębnij informacje o instrumencie
Zacznijmy od zajęcia się informacjami o nazwie instrumentu, aby znormalizować je do kolumn, które będą łatwiej dostępne w wynikowej tabeli wyjściowej.
- dodaj Podzielony ciąg węzeł i nazwij go
Split instrument, co spowoduje tokenizację kolumny instrumentu za pomocą wyrażenia regularnego zawierającego białe znaki:s+(w tym przypadku przydałaby się pojedyncza przestrzeń, ale ten sposób jest bardziej elastyczny i wyraźniejszy wizualnie). - Chcemy zachować oryginalne informacje o instrumencie bez zmian, więc wprowadź nową nazwę kolumny dla podzielonej tablicy:
instrument_arr.
- Dodaj Tablica do kolumn węzeł i nazwij go
Instrument columnsaby przekonwertować właśnie utworzoną kolumnę tablicy na nowe pola, z wyjątkiemsymbol, dla którego mamy już kolumnę. - Wybierz kolumnę
instrument_arr, pomiń pierwszy token i powiedz mu, aby wyodrębnił kolumny wyjściowemonth, day, year, strike_price, typeza pomocą indeksów2, 3, 4, 5, 6(spacje po przecinkach służą czytelności, nie mają wpływu na konfigurację).
Wyodrębniony rok jest wyrażony tylko dwiema cyframi; zróbmy przerwę i załóżmy, że to jest w tym stuleciu, jeśli użyją tylko dwóch cyfr.
- dodaj Pochodna kolumna węzeł i nazwij go
Four digits year. - Wchodzę
yearjako kolumnę pochodną, aby ją przesłoniła, i wprowadź następujące wyrażenie SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Dla wygody budujemy expiration_date pole, które użytkownik może mieć jako odniesienie do ostatniej daty, w której opcja może zostać wykonana.
- dodaj Połącz kolumny węzeł i nazwij go
Build expiration date. - Nazwij nową kolumnę
expiration_date, wybierz kolumnyyear,month,day(w tej kolejności) i myślnik jako odstępnik.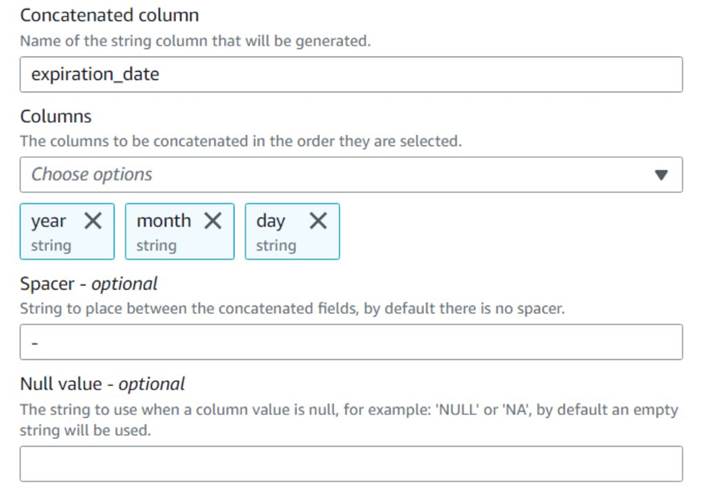
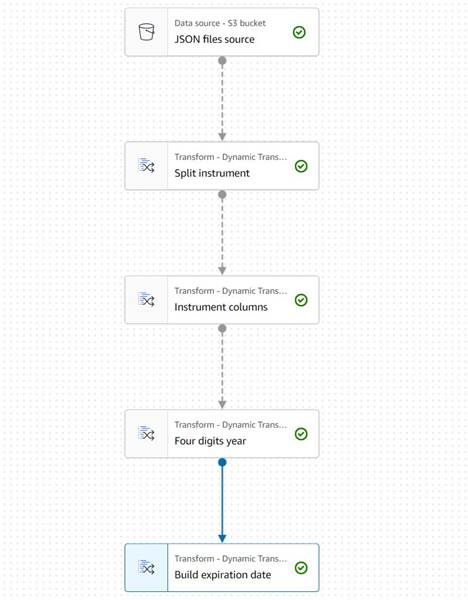
Dotychczasowy diagram powinien wyglądać jak w poniższym przykładzie.
Dotychczasowy podgląd danych nowych kolumn powinien wyglądać jak na poniższym zrzucie ekranu.
Normalizuj liczbę kontraktów
Każdy z wierszy w danych wskazuje liczbę kontraktów każdej opcji, które zostały kupione lub sprzedane oraz partie, na których zlecenia zostały zrealizowane. Nie tracąc informacji o poszczególnych partiach, chcemy mieć każdą kwotę w osobnym wierszu z pojedynczą wartością kwoty, podczas gdy reszta informacji jest replikowana w każdym produkowanym wierszu.
Najpierw połączmy kwoty w jedną kolumnę.
- Dodaj Odwróć kolumny w wiersze węzeł i nazwij go
Unpivot actions. - Wybierz kolumny
boughtisoldaby odwrócić i przechowywać nazwy i wartości w kolumnach o nazwieactionicontracts, Odpowiednio.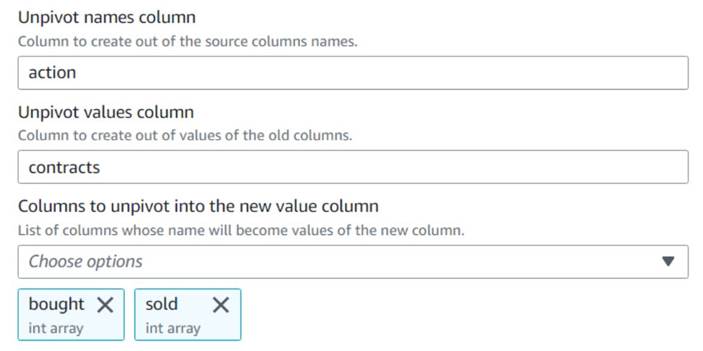
Zauważ w podglądzie, że nowa kolumnacontractsjest nadal tablicą liczb po tym przekształceniu.
- Dodaj Rozbij tablicę lub mapuj na wiersze rząd o nazwie
Explode contracts. - Wybierz
contractskolumna i wprowadźcontractsjako nową kolumnę, aby ją zastąpić (nie musimy zachowywać oryginalnej tablicy).
Podgląd pokazuje teraz, że każdy wiersz ma jeden contracts kwotę, a pozostałe pola są takie same.
Oznacza to również, że order_id nie jest już unikalnym kluczem. W przypadku własnych przypadków użycia musisz zdecydować, jak modelować swoje dane i czy chcesz denormalizować, czy nie.
Poniższy zrzut ekranu jest przykładem tego, jak wyglądają nowe kolumny po dotychczasowych przekształceniach.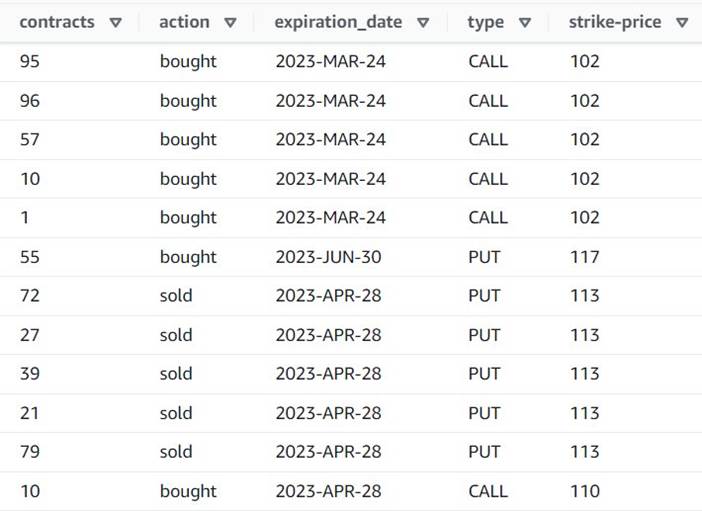
Utwórz tabelę podsumowującą
Teraz tworzysz tabelę podsumowującą z liczbą kontraktów będących w obrocie dla każdego typu i każdego symbolu giełdowego.
Załóżmy dla celów ilustracyjnych, że przetwarzane pliki należą do jednego dnia, więc to podsumowanie daje użytkownikom biznesowym informacje o tym, jakie jest zainteresowanie rynku i nastroje w tym dniu.
- dodaj Wybierz Pola node i wybierz następujące kolumny do zachowania dla podsumowania:
symbol,type,contracts.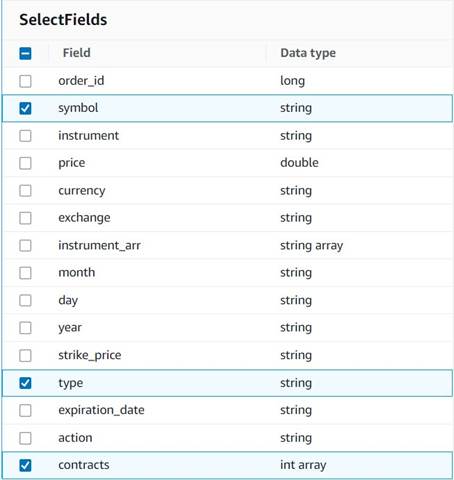
- dodaj Przestaw wiersze na kolumny węzeł i nazwij go
Pivot summary. - Agregat na
contractskolumna za pomocąsumi wybierz konwersjętypeKolumna.
Normalnie przechowujesz go w jakiejś zewnętrznej bazie danych lub pliku w celach informacyjnych; w tym przykładzie zapisujemy go jako plik CSV na Amazon S3.
- Dodaj Przetwarzanie automatycznego równoważenia węzeł i nazwij go
Single output file. - Chociaż ten typ transformacji jest zwykle używany do optymalizacji równoległości, tutaj używamy go, aby zredukować dane wyjściowe do pojedynczego pliku. Dlatego wejdź
1w konfiguracji ilości partycji.
- Dodaj cel S3 i nazwij go
CSV Contract summary. - Wybierz CSV jako format danych i wprowadź ścieżkę S3, w której rola stanowiska może przechowywać pliki.
Ostatnia część zadania powinna teraz wyglądać jak w poniższym przykładzie.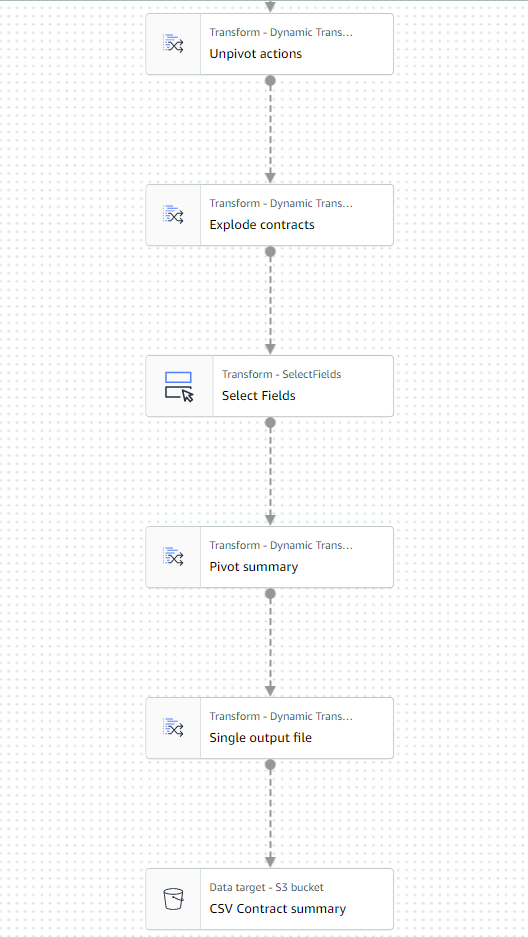
- Zapisz i uruchom zadanie. Użyj Działa kartę, aby sprawdzić, czy zakończyło się pomyślnie.
Znajdziesz plik w tej ścieżce, który jest CSV, mimo że nie ma tego rozszerzenia. Prawdopodobnie będziesz musiał dodać rozszerzenie po pobraniu, aby je otworzyć.
W narzędziu, które może odczytać plik CSV, podsumowanie powinno wyglądać podobnie do poniższego przykładu.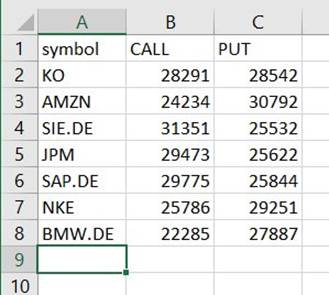
Wyczyść kolumny tymczasowe
Przygotowując się do zapisania zamówień w tabeli historycznej do przyszłej analizy, wyczyśćmy kilka tymczasowych kolumn utworzonych po drodze.
- dodaj Upuść pola węzeł z
Explode contractswęzeł wybrany jako jego rodzic (rozgałęziamy potok danych, aby wygenerować osobne wyjście). - Wybierz pola do usunięcia:
instrument_arr,month,day,year.
Resztę chcemy zachować, aby została zapisana w tabeli historycznej, którą utworzymy później.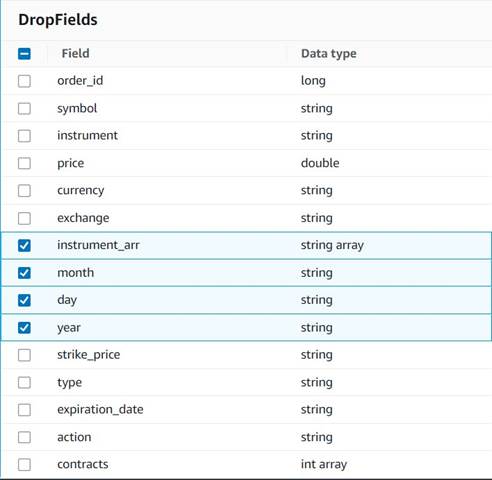
Standaryzacja waluty
Te syntetyczne dane zawierają fikcyjne operacje na dwóch walutach, ale w prawdziwym systemie można by dostać waluty z rynków na całym świecie. Przydatne jest ujednolicenie obsługiwanych walut w jedną walutę referencyjną, aby można je było łatwo porównywać i agregować na potrzeby raportów i analiz.
Używamy pliki Amazonka Atena symulować tabelę z przybliżonymi przeliczeniami walut, która jest okresowo aktualizowana (tutaj zakładamy, że przetwarzamy zamówienia na tyle terminowo, że przeliczenie jest rozsądnym przedstawicielem do celów porównawczych).
- Otwórz konsolę Athena w tym samym regionie, w którym używasz kleju AWS.
- Uruchom następujące zapytanie, aby utworzyć tabelę, ustawiając lokalizację S3, w której role Athena i AWS Glue mogą odczytywać i zapisywać. Możesz także chcieć przechowywać tabelę w innej bazie danych niż
default(jeśli to zrobisz, odpowiednio zaktualizuj kwalifikowaną nazwę tabeli w podanych przykładach). - Wpisz kilka przykładowych konwersji do tabeli:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Powinieneś być teraz w stanie wyświetlić tabelę z następującym zapytaniem:
SELECT * FROM default.exchange_rates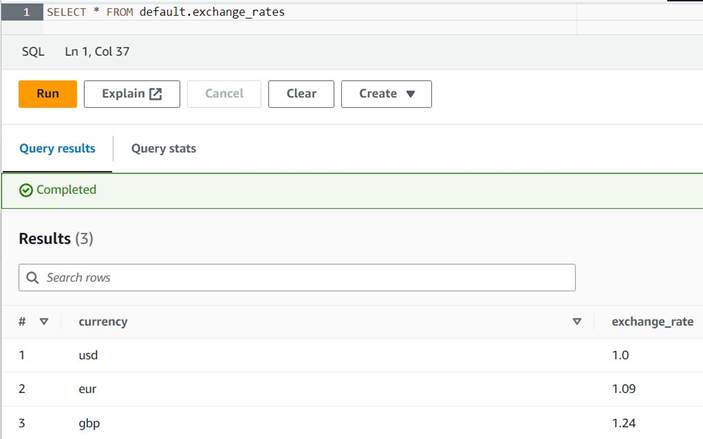
- Wracając do zadania wizualnego AWS Glue, dodaj a Lookup węzeł (jako dziecko
Drop Fields) i nazwij toExchange rate. - Wprowadź kwalifikowaną nazwę tabeli, którą właśnie utworzyłeś, używając
currencyjako klucz i wybierzexchange_ratepole do wykorzystania.
Ponieważ nazwa pola jest taka sama zarówno w danych, jak iw tabeli przeglądowej, możemy po prostu wprowadzić nazwęcurrencyi nie trzeba definiować mapowania.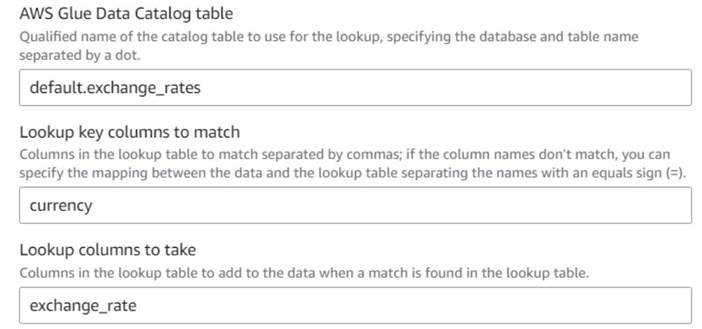
W chwili pisania tego tekstu transformacja wyszukiwania nie jest obsługiwana w podglądzie danych i wyświetla błąd informujący, że tabela nie istnieje. Służy to tylko do podglądu danych i nie uniemożliwia prawidłowego działania zadania. Kilka pozostałych kroków wpisu nie wymaga aktualizacji schematu. Jeśli chcesz uruchomić podgląd danych na innych węzłach, możesz tymczasowo usunąć węzeł wyszukiwania, a następnie umieścić go z powrotem. - dodaj Pochodna kolumna węzeł i nazwij go
Total in usd. - Nazwij kolumnę pochodną
total_usdi użyj następującego wyrażenia SQL:round(contracts * price * exchange_rate, 2)
- dodaj Dodaj aktualny znacznik czasu węzeł i nazwij kolumnę
ingest_date. - Użyj formatu
%Y-%m-%ddla Twojej sygnatury czasowej (dla celów demonstracyjnych używamy tylko daty; możesz ją uściślić, jeśli chcesz).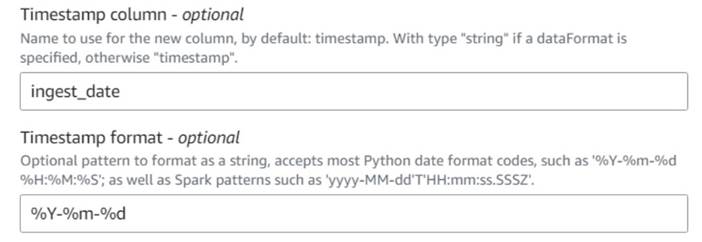
Zapisz tabelę zamówień historycznych
Aby zapisać tabelę zamówień historycznych, wykonaj następujące kroki:
- Dodaj węzeł docelowy S3 i nadaj mu nazwę
Orders table. - Skonfiguruj format Parquet z szybką kompresją i podaj docelową ścieżkę S3, w której będą przechowywane wyniki (oddzielone od podsumowania).
- Wybierz Utwórz tabelę w Data Catalog i przy kolejnych uruchomieniach, aktualizuj schemat i dodawaj nowe partycje.
- Wprowadź docelową bazę danych i nazwę nowej tabeli, na przykład:
option_orders.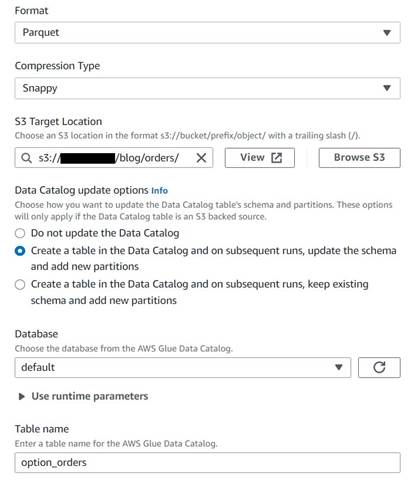
Ostatnia część diagramu powinna teraz wyglądać podobnie do poniższego, z dwoma rozgałęzieniami dla dwóch oddzielnych wyjść.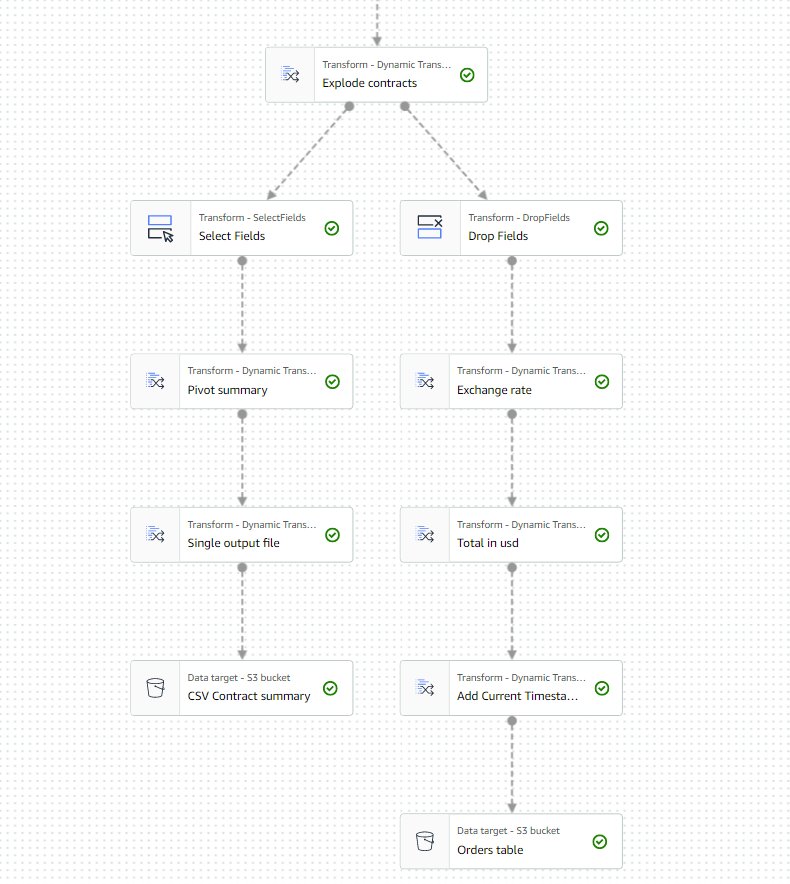
Po pomyślnym uruchomieniu zadania możesz użyć narzędzia, takiego jak Athena, do przejrzenia danych wygenerowanych przez zadanie, wysyłając zapytanie do nowej tabeli. Możesz znaleźć stół na liście Athena i wybrać Podgląd tabeli lub po prostu uruchom zapytanie SELECT (aktualizując nazwę tabeli do nazwy i katalogu, którego użyłeś):
SELECT * FROM default.option_orders limit 10
Zawartość tabeli powinna wyglądać podobnie do poniższego zrzutu ekranu.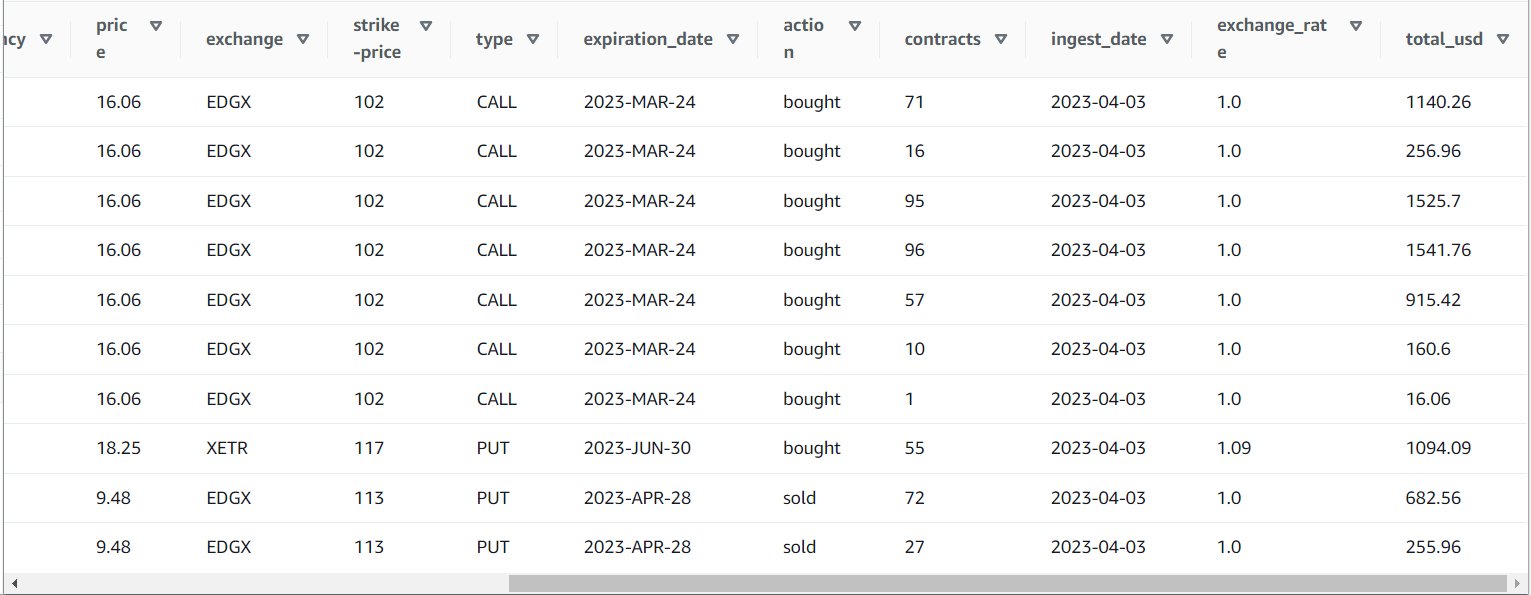
Sprzątać
Jeśli nie chcesz zachować tego przykładu, usuń dwa utworzone zadania, dwie tabele w Athenie i ścieżki S3, w których były przechowywane pliki wejściowe i wyjściowe.
Wnioski
W tym poście pokazaliśmy, jak nowe transformacje w AWS Glue Studio mogą pomóc w bardziej zaawansowanych transformacjach przy minimalnej konfiguracji. Oznacza to, że możesz zaimplementować więcej przypadków użycia ETL bez konieczności pisania i utrzymywania jakiegokolwiek kodu. Nowe transformacje są już dostępne w AWS Glue Studio, więc możesz ich używać już dziś w swoich zadaniach wizualnych.
O autorze
![]() Gonzalo herreros jest starszym architektem Big Data w zespole AWS Glue.
Gonzalo herreros jest starszym architektem Big Data w zespole AWS Glue.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Zdolny
- O nas
- do przyjęcia
- dostęp
- odpowiednio
- Dodaj
- w dodatku
- dodanie
- zaawansowany
- Po
- Wszystkie kategorie
- przydzielony
- przydziały
- dopuszczać
- pozwala
- wzdłuż
- już
- również
- zawsze
- Amazonka
- ilość
- kwoty
- an
- analiza
- w czasie rzeczywistym sprawiają,
- i
- Inne
- każdy
- stosowany
- przybliżony
- kwiecień
- SĄ
- argument
- Szyk
- AS
- przydzielony
- At
- atrybuty
- automatycznie
- dostępny
- AWS
- Klej AWS
- z powrotem
- na podstawie
- BE
- zanim
- jest
- Duży
- Big Data
- pusty
- BMW
- obie
- kupiony
- gałęzie
- budować
- biznes
- ale
- kupować
- by
- wezwanie
- CAN
- walizka
- Etui
- katalog
- Centrum
- Wiek
- Zmiany
- Charakterystyka
- ZOBACZ
- dziecko
- Dodaj
- Wybierając
- jaśniejsze
- kod
- Kodowanie
- Kolumna
- kolumny
- wspólny
- w porównaniu
- porównanie
- kompletny
- Zakończony
- systemu
- Konsola
- konsolidować
- zawiera
- zawartość
- umowa
- umowy
- wygoda
- Konwersja
- konwersje
- konwertować
- przeliczone
- KORPORACJA
- mógłby
- Stwórz
- stworzony
- Tworzenie
- waluty
- Waluta
- Aktualny
- DZIEŃ
- dane
- Baza danych
- Data
- Daty
- data i godzina
- dzień
- sprawa
- czynienia
- zdecydować
- Domyślnie
- zdefiniowane
- wykazać
- Zależność
- Pochodny
- Mimo
- detale
- różne
- cyfry
- dyskutować
- do
- Nie
- robi
- dolarów
- nie
- Podwójna
- na dół
- Spadek
- porzucone
- każdy
- łatwiej
- z łatwością
- łatwo
- redaktor
- umożliwiać
- dość
- Wchodzę
- Środowisko
- błąd
- Eter (ETH)
- EUR
- przykład
- przykłady
- Z wyjątkiem
- wymiana
- Wymiana
- Ekskluzywny
- istnieć
- Rozszerzać
- spodziewany
- eksperyment
- wygaśnięcie
- wyrażone
- rozbudowa
- zewnętrzny
- dodatkowy
- wyciąg
- daleko
- strach
- kilka
- powieściowy
- pole
- Łąka
- filet
- Akta
- wypełniać
- wypełniony
- budżetowy
- Instrumenty finansowe
- Znajdź
- i terminów, a
- ustalony
- elastyczne
- obserwuj
- następujący
- następujący sposób
- W razie zamówieenia projektu
- format
- znaleziono
- od
- przyszłość
- GBP
- Ogólne
- ogólnie
- Generować
- wygenerowane
- otrzymać
- Dać
- daje
- Go
- wykres
- Chciwość
- Prowadzenie
- dzieje
- Have
- mający
- pomoc
- tutaj
- historyczny
- historia
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- Ludzie
- i
- identyfikuje
- zidentyfikować
- if
- Rezultat
- wdrożenia
- importować
- in
- indeksy
- wskazany
- wskazuje
- wskazując,
- wskazanie
- indywidualny
- Informacja
- wkład
- przykład
- zamiast
- instrukcje
- instrument
- instrumenty
- odsetki
- Interfejs
- najnowszych
- ISO
- IT
- JEGO
- Praca
- Oferty pracy
- jpg
- json
- właśnie
- Trzymać
- Klawisz
- Uprzejmy
- Nazwisko
- później
- lubić
- LIMIT
- Linia
- Płynność
- Lista
- załadować
- lokalizacja
- dłużej
- Popatrz
- wygląda jak
- WYGLĄD
- wyszukiwania
- stracić
- utraty
- zrobiony
- utrzymać
- robić
- WYKONUJE
- ręcznie
- mapa
- mapowanie
- rynek
- sentyment rynkowy
- rynki
- Może..
- znaczy
- Łączyć
- wiadomość
- może
- minimum
- brakujący
- model
- monitor
- jeszcze
- większość
- wielokrotność
- wzajemnie
- Nazwa
- O imieniu
- Nazwy
- Potrzebować
- wymagania
- Nowości
- Nie
- węzeł
- węzły
- normalnie
- już dziś
- numer
- z naszej
- przedmiot
- of
- często
- on
- ONE
- tylko
- koncepcja
- działanie
- operacje
- Optymalizacja
- Option
- Opcje
- or
- zamówienie
- Zlecenia
- oryginalny
- Inne
- Inaczej
- wydajność
- koniec
- ogólny
- Zastąp
- własny
- płatny
- chleb
- parametr
- część
- ścieżka
- Wybiera
- rurociąg
- Pivot
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- Post
- potencjał
- Praktyczny
- precyzyjny
- zapobiec
- Podgląd
- Cena
- prawdopodobnie
- wygląda tak
- przetwarzanie
- produkować
- Wytworzony
- zapewniać
- pod warunkiem,
- zapewnia
- zakup
- cel
- cele
- położyć
- Python
- wykwalifikowany
- podnieść
- przypadkowy
- Czytaj
- real
- rozsądny
- zmniejszyć
- odzwierciedlić
- region
- pozostały
- usunąć
- replikowane
- Raportowanie
- reprezentować
- przedstawiciel
- reprezentowanie
- reprezentuje
- wymagać
- wymagania
- Wymaga
- odpowiednio
- REST
- wynikły
- Efekt
- przeglądu
- Rola
- role
- RZĄD
- run
- bieganie
- bezpieczniej
- taki sam
- SAP
- Zapisz
- oszczędność
- przewijać
- sekund
- wybrany
- wybierając
- sprzedać
- senior
- sentyment
- oddzielny
- Sesja
- Zestawy
- ustawienie
- Akcje
- Powłoka
- powinien
- pokazać
- Targi
- podobny
- Prosty
- pojedynczy
- Rozmiar
- umiejętności
- mały
- So
- dotychczas
- sprzedany
- kilka
- coś
- Źródło
- Typ przestrzeni
- obowiązuje
- specyficzny
- określony
- dzielić
- Arkusz kalkulacyjny
- SQL
- początek
- Cel
- Nadal
- stany magazynowe
- przechowywanie
- sklep
- przechowywany
- sznur
- studio
- kolejny
- Z powodzeniem
- odpowiedni
- PODSUMOWANIE
- Utrzymany
- symbol
- syntetyczny
- dane syntetyczne
- syntetycznie
- system
- systemy
- stół
- Brać
- cel
- zespół
- powiedzieć
- tymczasowy
- dziesięć
- test
- niż
- że
- Połączenia
- Wykres
- Informacje
- świat
- Im
- następnie
- w związku z tym
- Te
- one
- to
- tych
- czas
- czasy
- znak czasu
- do
- już dziś
- żeton
- tokenizować
- wziął
- narzędzie
- Kwota produktów:
- handel
- w obrocie
- Przekształcać
- Transformacja
- przemiany
- przekształcony
- drugiej
- rodzaj
- dla
- zasadniczy
- zrozumieć
- wyjątkowy
- aż do
- Aktualizacja
- zaktualizowane
- aktualizowanie
- URL
- us
- Dolary amerykańskie
- USD
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- Cenny
- Cenne informacje
- wartość
- Wartości
- Miejsce
- zweryfikowana
- zweryfikować
- Zobacz i wysłuchaj
- widoczny
- Tom
- vs
- czekać
- chcieć
- była
- Droga..
- we
- były
- Co
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- będzie
- w
- bez
- przepływów pracy
- pracujący
- świat
- by
- napisać
- pisanie
- rok
- ty
- Twój
- zefirnet











