
Zdjęcie utworzone za pomocą DALL-E3
Sztuczna inteligencja to całkowita rewolucja w świecie technologii.
Jego zdolność do naśladowania ludzkiej inteligencji i wykonywania zadań, które kiedyś uważano za domenę wyłącznie ludzką, wciąż zadziwia większość z nas.
Jednak niezależnie od tego, jak dobry był ten późny postęp w zakresie sztucznej inteligencji, zawsze jest miejsce na ulepszenia.
I właśnie w tym miejscu rozpoczyna się szybka inżynieria!
Wejdź w to pole, które może znacząco zwiększyć produktywność modeli AI.
Odkryjmy to wszystko razem!
Szybka inżynieria to szybko rozwijająca się dziedzina sztucznej inteligencji, która koncentruje się na poprawie wydajności i skuteczności modeli językowych. Wszystko polega na tworzeniu doskonałych podpowiedzi, które poprowadzą modele AI w celu uzyskania pożądanych wyników.
Pomyśl o tym, jak o tym, jak dać komuś lepsze instrukcje, aby upewnić się, że rozumie i poprawnie wykonuje zadanie.
Dlaczego szybka inżynieria ma znaczenie
- Zwiększona produktywność: Dzięki zastosowaniu podpowiedzi wysokiej jakości modele sztucznej inteligencji mogą generować dokładniejsze i trafniejsze odpowiedzi. Oznacza to mniej czasu spędzonego na poprawkach, a więcej na wykorzystaniu możliwości sztucznej inteligencji.
- Efektywność kosztowa: Szkolenie modeli sztucznej inteligencji wymaga dużych zasobów. Szybka inżynieria może zmniejszyć potrzebę ponownego szkolenia poprzez optymalizację wydajności modelu za pomocą lepszych podpowiedzi.
- Wszechstronność: Dobrze opracowany monit może sprawić, że modele sztucznej inteligencji będą bardziej wszechstronne, umożliwiając im radzenie sobie z szerszym zakresem zadań i wyzwań.
Zanim zagłębimy się w najbardziej zaawansowane techniki, przypomnijmy sobie dwie najbardziej przydatne (i podstawowe) techniki szybkiej inżynierii.
Myślenie sekwencyjne z „Pomyślmy krok po kroku”
Dziś wiadomo, że dokładność modeli LLM znacznie wzrasta po dodaniu sekwencji słów „Pomyślmy krok po kroku”.
Dlaczego… możesz zapytać?
Dzieje się tak dlatego, że zmuszamy model do podzielenia dowolnego zadania na wiele kroków, upewniając się w ten sposób, że model ma wystarczająco dużo czasu na przetworzenie każdego z nich.
Na przykład mógłbym rzucić wyzwanie GPT3.5, wyświetlając następujący monit:
Jeśli Jan ma 5 gruszek, zjada 2, kupuje jeszcze 5, a następnie daje 3 swojemu przyjacielowi, ile ma gruszek?
Modelka od razu udzieli mi odpowiedzi. Jeśli jednak dodam na koniec „Pomyślmy krok po kroku”, zmuszam model do wygenerowania procesu myślenia składającego się z wielu kroków.
Podpowiedź kilku strzałów
Podczas gdy podpowiadanie zerowe odnosi się do proszenia modelu o wykonanie zadania bez podawania kontekstu lub wcześniejszej wiedzy, technika podpowiadania z kilkoma strzałami oznacza, że przedstawiamy LLM kilka przykładów oczekiwanych przez nas wyników wraz z pewnym konkretnym pytaniem.
Na przykład, jeśli chcemy wymyślić model, który definiuje dowolny termin za pomocą poetyckiego tonu, może to być dość trudne do wyjaśnienia. Prawidłowy?
Jednakże moglibyśmy użyć poniższych podpowiedzi składających się z kilku strzałów, aby skierować model w pożądanym kierunku.
Twoim zadaniem jest udzielenie odpowiedzi w spójnym stylu zgodnym z poniższym stylem.
: Naucz mnie o odporności.
: Odporność jest jak drzewo, które ugina się pod wpływem wiatru, ale nigdy się nie łamie.
To umiejętność podniesienia się z przeciwności losu i dalszego podążania do przodu.
: Twoje dane tutaj.
Jeśli jeszcze tego nie wypróbowałeś, możesz rzucić wyzwanie GPT.
Jednakże, ponieważ jestem pewien, że większość z Was zna już te podstawowe techniki, spróbuję rzucić Wam wyzwanie, przedstawiając kilka zaawansowanych technik.
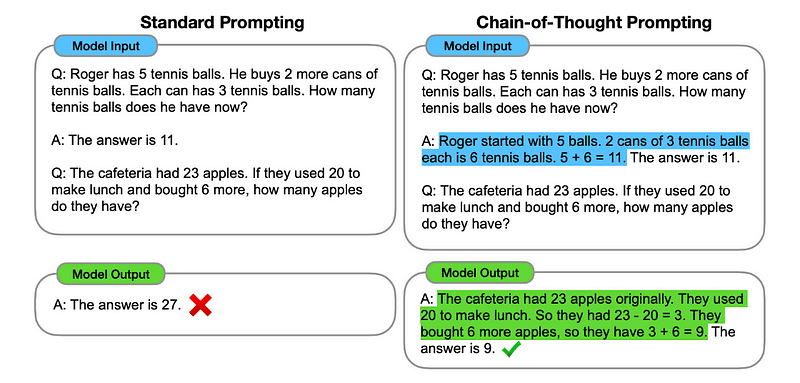
1. Podpowiadanie w łańcuchu myślowym (CoT).
Wprowadzony przez Google w 2022 roku, metoda ta polega na poinstruowaniu modelu, aby przed udzieleniem ostatecznej odpowiedzi przeszedł kilka etapów rozumowania.
Brzmi znajomo, prawda? Jeśli tak, masz całkowitą rację.
To jakby połączyć myślenie sekwencyjne i podpowiadanie o kilku strzałach.
W jaki sposób?
Zasadniczo monit CoT kieruje LLM do sekwencyjnego przetwarzania informacji. Oznacza to, że pokazujemy, jak rozwiązać pierwszy problem za pomocą wieloetapowego rozumowania, a następnie wysyłamy do modelu nasze prawdziwe zadanie, oczekując, że będzie on emulował porównywalny ciąg myślowy podczas odpowiadania na rzeczywiste zapytanie, które chcemy rozwiązać.
Zdjęcie zaczerpnięte z papier.
Zatem, wzorując się na pierwszym przykładzie, moglibyśmy podpowiedzieć pierwszy problem i sekwencyjne wyjaśnienie, jak go rozwiązać. Następnie możemy przesłać nasze uwagi i zobaczyć, jak dzieje się magia!
Jeśli Jan ma 5 gruszek, zjada 2, kupuje jeszcze 5, a następnie daje 3 swojemu przyjacielowi, ile ma gruszek? Pomyślmy krok po kroku.
Przejdźmy krok po kroku. Jan zaczyna z 5 gruszkami. Zjada 2 gruszki, więc zostaje mu 5–2 = 3 gruszki. Następnie kupuje jeszcze 5 gruszek. Zatem ma teraz 3 + 5 = 8 gruszek. Na koniec daje przyjacielowi 3 gruszki. Zatem zostało mu 8–3 = 5 gruszek. Zatem po wszystkich tych krokach Jan ma 5 gruszek.
Twój wkład tutaj.
Jednak większość z Was z pewnością myśli… Czy za każdym razem, gdy chcę o coś zapytać na ChatGPT, muszę wymyślać sekwencyjny sposób rozwiązania dowolnego problemu?
Cóż… nie jesteś pierwszy! A to prowadzi nas do…
2. Automatyczny łańcuch myślowy (Auto-CoT)
W 2022, Zhang i współpracownicy wprowadzili metodę pozwalającą uniknąć tego ręcznego procesu. Istnieją dwa główne powody, dla których należy unikać wykonywania zadań ręcznych:
- To może być nudne.
- Może przynieść złe rezultaty – na przykład, gdy nasz proces umysłowy jest nieprawidłowy.
Zasugerowali użycie LLM w połączeniu z podpowiedzią „Pomyślmy krok po kroku”, aby sekwencyjnie tworzyć łańcuchy rozumowania dla każdej demonstracji.
Oznacza to pytanie do ChatGPT, jak rozwiązać dowolny problem po kolei, a następnie użycie tego samego przykładu do przeszkolenia go, jak rozwiązać każdy inny problem.
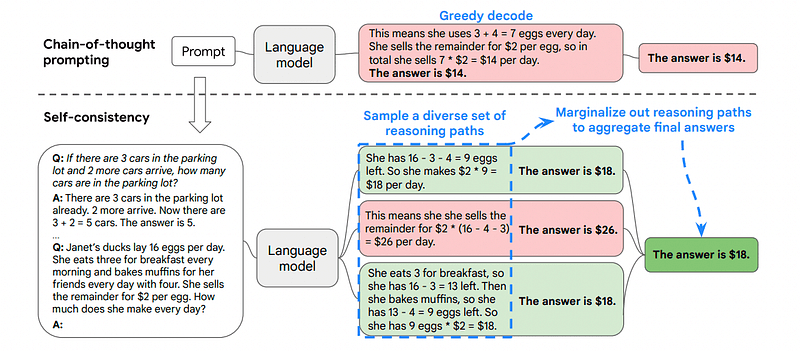
3. Samokonsekwencja
Spójność własna to kolejna interesująca technika podpowiedzi, której celem jest ulepszenie łańcucha myślowego podpowiadającego w przypadku bardziej złożonych problemów z rozumowaniem.
Jaka jest więc główna różnica?
Główną ideą Self-Consistency jest świadomość, że możemy wytrenować model na złym przykładzie. Wyobraź sobie, że rozwiązuję poprzedni problem za pomocą złego procesu myślowego:
Jeśli Jan ma 5 gruszek, zjada 2, kupuje jeszcze 5, a następnie daje 3 swojemu przyjacielowi, ile ma gruszek? Pomyślmy krok po kroku.
Zacznij od 5 gruszek. Jan zjada 2 gruszki. Następnie daje przyjacielowi 3 gruszki. Działania te można łączyć: 2 (zjedzone) + 3 (dane) = w sumie dotkniętych jest 5 gruszek. Teraz odejmij całkowitą liczbę dotkniętych gruszek od początkowych 5 gruszek: 5 (początkowe) – 5 (dotknięte) = pozostało 0 gruszek.
Wtedy każde inne zadanie, które wyślę modelowi, będzie błędne.
Właśnie dlatego samospójność polega na próbkowaniu różnych ścieżek rozumowania, z których każda zawiera ciąg myślowy, a następnie pozwalaniu LLM wybrać najlepszą i najbardziej spójną ścieżkę rozwiązania problemu.
Zdjęcie zaczerpnięte z papier
W tym przypadku, ponownie wzorując się na pierwszym przykładzie, możemy pokazać modelowi różne sposoby rozwiązania problemu.
Jeśli Jan ma 5 gruszek, zjada 2, kupuje jeszcze 5, a następnie daje 3 swojemu przyjacielowi, ile ma gruszek?
Zacznij od 5 gruszek. Jan zjada 2 gruszki, zostawiając mu 5–2 = 3 gruszki. Kupuje jeszcze 5 gruszek, co daje w sumie 3 + 5 = 8 gruszek. Na koniec daje przyjacielowi 3 gruszki, więc zostało mu 8–3 = 5 gruszek.
Jeśli Jan ma 5 gruszek, zjada 2, kupuje jeszcze 5, a następnie daje 3 swojemu przyjacielowi, ile ma gruszek?
Zacznij od 5 gruszek. Następnie kupuje jeszcze 5 gruszek. John zjada teraz 2 gruszki. Akcje te można łączyć: 2 (zjedzone) + 5 (kupione) = w sumie 7 gruszek. Odejmij gruszkę, którą Jon zjadł od całkowitej ilości gruszek 7 (całkowita ilość) – 2 (zjedzone) = zostało 5 gruszek.
Twój wkład tutaj.
I tu pojawia się ostatnia technika.
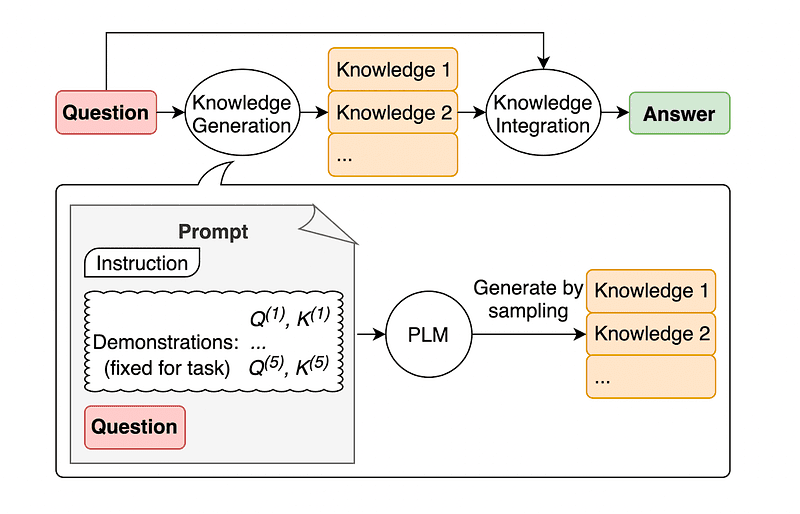
4. Podpowiadanie o wiedzy ogólnej
Powszechną praktyką szybkiego projektowania jest uzupełnianie zapytania o dodatkową wiedzę przed wysłaniem ostatecznego wywołania API do GPT-3 lub GPT-4.
Zgodnie z Jiacheng Liu and Co, zawsze możemy dodać trochę wiedzy do każdego żądania, aby LLM lepiej wiedziało o pytaniu.
Zdjęcie zaczerpnięte z papier.
Na przykład, gdy zapytasz ChatGPT, czy część golfistów próbuje uzyskać wyższą liczbę punktów niż inni, potwierdzi to. Jednak główny cel golfa jest zupełnie odwrotny. Dlatego możemy dodać wcześniejszą wiedzę, mówiąc: „Gracz z niższym wynikiem wygrywa”.

Więc... co jest zabawnego, jeśli mówimy modelowi dokładnie odpowiedź?
W tym przypadku technika ta służy do poprawy sposobu, w jaki LLM wchodzi z nami w interakcję.
Zamiast więc pobierać dodatkowy kontekst z zewnętrznej bazy danych, autorzy artykułu zalecają, aby LLM tworzyło własną wiedzę. Ta samodzielnie wygenerowana wiedza jest następnie włączana do podpowiedzi, aby wzmocnić zdroworozsądkowe rozumowanie i zapewnić lepsze wyniki.
W ten sposób można ulepszyć LLM bez zwiększania zbioru danych szkoleniowych!
Szybka inżynieria stała się kluczową techniką zwiększania możliwości LLM. Powtarzając i ulepszając podpowiedzi, możemy komunikować się z modelami sztucznej inteligencji w bardziej bezpośredni sposób, a tym samym uzyskiwać dokładniejsze i kontekstowo odpowiednie wyniki, oszczędzając zarówno czas, jak i zasoby.
Zarówno dla entuzjastów technologii, analityków danych, jak i twórców treści zrozumienie i opanowanie szybkiej inżynierii może być cennym atutem w wykorzystaniu pełnego potencjału sztucznej inteligencji.
Łącząc starannie zaprojektowane podpowiedzi z bardziej zaawansowanymi technikami, posiadanie zestawu umiejętności szybkiego projektowania niewątpliwie zapewni Ci przewagę w nadchodzących latach.
Józefa Ferrera jest inżynierem analitykiem z Barcelony. Ukończył inżynierię fizyki i obecnie pracuje w dziedzinie Data Science stosowanej do mobilności ludzi. Jest twórcą treści w niepełnym wymiarze godzin, koncentrującym się na analizie danych i technologii. Możesz skontaktować się z nim na LinkedIn, Twitter or Średni.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- zdolność
- O nas
- precyzja
- dokładny
- działania
- rzeczywisty
- Dodaj
- dodanie
- Dodatkowy
- zaawansowany
- Po
- ponownie
- AI
- Modele AI
- Cele
- wyrównany
- zarówno
- Wszystkie kategorie
- Pozwalać
- wzdłuż
- już
- zawsze
- am
- ilość
- an
- analityka
- i
- Inne
- odpowiedź
- każdy
- api
- stosowany
- SĄ
- AS
- zapytać
- pytanie
- kapitał
- Autorzy
- automatycznie
- uniknąć
- świadomy
- z dala
- z powrotem
- Łazienka
- Barcelona
- podstawowy
- BE
- bo
- być
- zanim
- jest
- BEST
- Ulepsz Swój
- grzbiet
- podnieść
- Nudny
- obie
- kupiony
- Odbić się
- przerwa
- przerwy
- Przynosi
- szerszy
- ale
- Kupuje
- by
- wezwanie
- CAN
- możliwości
- ostrożnie
- walizka
- łańcuch
- więzy
- wyzwanie
- wyzwania
- ChatGPT
- Dodaj
- koledzy
- połączony
- łączenie
- jak
- byliśmy spójni, od początku
- przyjście
- wspólny
- komunikować
- porównywalny
- kompletny
- kompleks
- za
- zgodny
- skontaktuj się
- zawartość
- twórcy treści
- kontekst
- Korekty
- prawidłowo
- mógłby
- stworzony
- twórca
- twórcy
- Obecnie
- dane
- nauka danych
- Baza danych
- Definiuje
- dostarczanie
- zaprojektowany
- życzenia
- różnica
- różne
- kierować
- kierunek
- odkryj
- nurkowanie
- do
- robi
- domena
- domeny
- na dół
- każdy
- krawędź
- skuteczność
- efektywność
- wyłonił
- inżynier
- Inżynieria
- wzmacniać
- wzmocnienie
- dość
- zapewnić
- Miłośnicy
- dokładnie
- przykład
- przykłady
- wykonać
- oczekując
- Wyjaśniać
- wyjaśnienie
- znajomy
- kilka
- pole
- finał
- W końcu
- i terminów, a
- koncentruje
- koncentruje
- następujący
- W razie zamówieenia projektu
- zmuszając
- Naprzód
- przyjaciel
- od
- pełny
- zabawny
- Ogólne
- Generować
- otrzymać
- Dać
- dany
- daje
- Go
- cel
- golf
- dobry
- poprowadzi
- Ciężko
- Wykorzystywanie
- Have
- mający
- he
- tutaj
- wysokiej jakości
- wyższy
- go
- jego
- W jaki sposób
- How To
- Jednak
- HTTPS
- człowiek
- ludzka inteligencja
- i
- pomysł
- if
- obraz
- podnieść
- ulepszony
- poprawa
- poprawy
- in
- wzrastający
- Informacja
- początkowy
- wkład
- przykład
- instrukcje
- zintegrowany
- Inteligencja
- współdziała
- ciekawy
- najnowszych
- wprowadzono
- dotyczy
- IT
- JEGO
- John
- Jon
- właśnie
- Knuggety
- Trzymać
- kopać
- Kicks
- Wiedzieć
- wiedza
- wie
- język
- Nazwisko
- Późno
- Wyprowadzenia
- Skakać
- nauka
- pozostawiając
- lewo
- mniej
- niech
- najmu
- lewarowanie
- lubić
- niższy
- magia
- Główny
- robić
- Dokonywanie
- sposób
- podręcznik
- wiele
- Mastering
- Materia
- me
- znaczy
- psychika
- połączenie
- metoda
- może
- mobilność
- model
- modele
- jeszcze
- większość
- przeniesienie
- wielokrotność
- musi
- Potrzebować
- nigdy
- Nie
- już dziś
- uzyskać
- of
- on
- pewnego razu
- naprzeciwko
- optymalizacji
- or
- Inne
- Pozostałe
- ludzkiej,
- na zewnątrz
- wydajność
- Wyjścia
- zewnętrzne
- własny
- Papier
- część
- ścieżka
- doskonały
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- Fizyka
- kluczowy
- plato
- Analiza danych Platona
- PlatoDane
- gracz
- punkt
- potencjał
- praktyka
- precyzyjnie
- teraźniejszość
- bardzo
- poprzedni
- Problem
- problemy
- wygląda tak
- produkować
- wydajność
- zapewniać
- że
- ciągnięcie
- pytanie
- całkiem
- zasięg
- raczej
- real
- Przyczyny
- polecić
- zmniejszyć
- odnosi
- zażądać
- sprężystość
- zasobochłonne
- Zasoby
- odpowiadanie
- odpowiedź
- Odpowiedzi
- Efekt
- przekwalifikowanie
- Rewolucja
- prawo
- Pokój
- s
- taki sam
- oszczędność
- nauka
- Nauka i technika
- Naukowcy
- wynik
- widzieć
- wysłać
- wysyłanie
- Sekwencja
- zestaw
- kilka
- pokazać
- znacznie
- umiejętność
- So
- Wyłącznie
- ROZWIĄZANIA
- Rozwiązywanie
- kilka
- Ktoś
- coś
- specyficzny
- spędził
- etapy
- początek
- rozpocznie
- sterować
- Ewolucja krok po kroku
- Cel
- Nadal
- styl
- pewnie
- sprzęt
- Zadania
- Zadanie
- zadania
- tech
- technika
- Techniki
- Technologia
- mówi
- semestr
- niż
- że
- Połączenia
- Im
- następnie
- Tam.
- w związku z tym
- Te
- one
- myśleć
- Myślący
- to
- myśl
- Przez
- A zatem
- czas
- do
- TON
- Kwota produktów:
- CAŁKOWICIE
- Pociąg
- Trening
- drzewo
- wypróbowany
- próbować
- stara
- drugiej
- ostateczny
- dla
- przejść
- zrozumieć
- zrozumienie
- niewątpliwie
- us
- posługiwać się
- używany
- za pomocą
- UPRAWOMOCNIĆ
- Cenny
- różnorodny
- wszechstronny
- początku.
- chcieć
- Droga..
- sposoby
- we
- znane
- były
- jeśli chodzi o komunikację i motywację
- który
- dlaczego
- będzie
- wiatr
- w
- w ciągu
- bez
- słowo
- pracujący
- świat
- Źle
- lat
- jeszcze
- Wydajność
- ty
- Twój
- zefirnet







