Środowisko wykonawcze Amazon EMR dla Apache Spark to zoptymalizowane pod kątem wydajności środowisko uruchomieniowe dla Apache Spark, które jest w 100% kompatybilne z interfejsem API Open Source Apache Spark. Z Amazon EMR wersji 6.9.0, środowisko uruchomieniowe EMR dla Apache Spark obsługuje równoważną wersję Spark 3.3.0.
Dzięki Amazon EMR 6.9.0 możesz teraz uruchamiać aplikacje Apache Spark 3.x szybciej i taniej, bez konieczności wprowadzania jakichkolwiek zmian w aplikacjach. W naszych testach porównawczych wydajności, wywodzących się z testów wydajności TPC-DS w skali 3 TB, stwierdziliśmy, że środowisko wykonawcze EMR dla Apache Spark 3.3.0 zapewnia średnio 3.5-krotnie (przy użyciu całkowitego czasu działania) poprawę wydajności w porównaniu z Open Source Apache Spark 3.3.0. XNUMX.
W tym poście analizujemy wyniki naszych testów porównawczych z uruchomioną aplikacją TPC-DS Apache Spark o otwartym kodzie źródłowym a następnie na Amazon EMR 6.9, który jest dostarczany ze zoptymalizowanym środowiskiem uruchomieniowym Spark, które jest kompatybilne z Open Source Spark. Przechodzimy przez szczegółową analizę kosztów i na koniec przedstawiamy instrukcje krok po kroku, jak przeprowadzić test porównawczy.
Zaobserwowane wyniki
Aby ocenić poprawę wydajności, wykorzystaliśmy narzędzie do testowania wydajności Spark o otwartym kodzie źródłowym, które pochodzi z zestawu narzędzi do testowania wydajności TPC-DS. Przeprowadziliśmy testy na klastrze EMR c5d.9xlarge z siedmioma węzłami (sześć węzłów rdzeniowych i jeden węzeł podstawowy) ze środowiskiem wykonawczym EMR dla Apache Spark oraz na drugim samozarządzanym klastrze z siedmioma węzłami na Elastyczna chmura obliczeniowa Amazon (Amazon EC2) z równoważną wersją Spark typu open source. Przeprowadziliśmy oba testy z danymi w Usługa Amazon Simple Storage (Amazonka S3).
Dynamiczna alokacja zasobów (DRA) to świetna funkcja do wykorzystania w przypadku różnych obciążeń. Jednak w przypadku testu porównawczego, w którym porównujemy dwie platformy wyłącznie pod względem wydajności, a wolumeny danych testowych nie zmieniają się (w naszym przypadku 3 TB), uważamy, że najlepiej jest unikać zmienności, aby przeprowadzić porównanie jabłek z jabłkami. W naszych testach zarówno w Open Source Spark, jak i Amazon EMR wyłączyliśmy DRA podczas uruchamiania aplikacji do testów porównawczych.
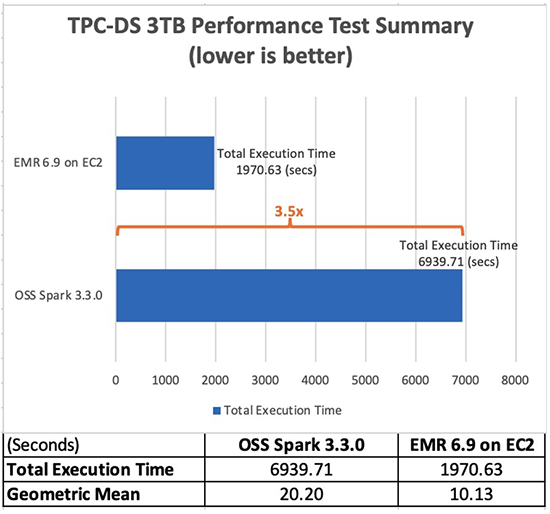
W poniższej tabeli przedstawiono łączny czas wykonywania zadań dla wszystkich zapytań (w sekundach) w zestawie danych zapytań o pojemności 3 TB między usługą Amazon EMR w wersji 6.9.0 a platformą Spark typu open source w wersji 3.3.0. Zaobserwowaliśmy, że nasze testy TPC-DS wykazały, że całkowity czas wykonywania zadania na Amazon EMR na Amazon EC2 był 3.5 razy szybszy niż przy użyciu klastra Spark typu open source o tej samej konfiguracji.
Przyspieszenie na zapytanie w Amazon EMR 6.9 ze środowiskiem uruchomieniowym EMR dla Apache Spark i bez niego zostało zilustrowane na poniższym wykresie. Oś pozioma przedstawia każde zapytanie w teście porównawczym 3 TB. Oś pionowa pokazuje przyspieszenie każdego zapytania ze względu na środowisko wykonawcze EMR. Znaczący wzrost wydajności jest ponad 10 razy szybszy w przypadku zapytań TPC-DS 24b, 72, 95 i 96.

Analiza kosztów
Poprawa wydajności środowiska uruchomieniowego EMR dla Apache Spark bezpośrednio przekłada się na niższe koszty. Udało nam się uzyskać 67% oszczędności kosztów, uruchamiając aplikację porównawczą na Amazon EMR w porównaniu z kosztami poniesionymi na uruchomienie tej samej aplikacji na Open Source Spark na Amazon EC2 przy tej samej wielkości klastra ze względu na skrócenie godzin Amazon EMR i Amazon Wykorzystanie EC2. Ceny Amazon EMR dotyczą aplikacji EMR działających w klastrach EMR z instancjami EC2. Cena Amazon EMR jest dodawana do bazowych cen obliczeniowych i magazynowych, takich jak cena instancji EC2 i Sklep Amazon Elastic Block (Amazon EBS) koszt (w przypadku dołączania woluminów EBS). Ogólnie rzecz biorąc, szacowany koszt porównawczy w regionie wschodnich Stanów Zjednoczonych (Północna Wirginia) wynosi 27.01 USD za uruchomienie dla open-source Spark na Amazon EC2 i 8.82 USD za uruchomienie dla Amazon EMR.
| Praca porównawcza | Czas pracy (godziny) | Szacowany koszt | Całkowita instancja EC2 | Razem vCPU | Całkowita pamięć (GiB) | Urządzenie root (Amazon EBS) |
|
Open-source Spark na Amazon EC2 (1 węzły podstawowe i 6 rdzeni) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR na Amazon EC2 (1 węzły podstawowe i 6 rdzeni) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Zestawienie kosztów
Poniżej znajduje się zestawienie kosztów zadania open source Spark on Amazon EC2 (27.01 USD):
- Całkowity koszt Amazon EC2 – (7 * 1.728 USD * 2.23) = (liczba wystąpień * c5d.9xduża stawka godzinowa * czas wykonywania zadania w godzinach) = 26.97 USD
- Koszt Amazon EBS – (0.1 USD/730 * 20 * 7 * 2.23) = (Amazon EBS za GB-godzinową stawkę * rozmiar głównego EBS * liczba instancji * czas wykonywania zadania w godzinie) = 0.042 USD
Poniżej znajduje się zestawienie kosztów zadania Amazon EMR na Amazon EC2 (8.82 USD):
- Całkowity koszt Amazon EMR – (7 * 0.27 USD * 0.63) = ((liczba węzłów podstawowych + liczba węzłów głównych)* c5d.9xlarge Cena Amazon EMR * czas wykonywania zadania w godzinie) = 1.19 USD
- Całkowity koszt Amazon EC2 – (7 * 1.728 USD * 0.63) = ((liczba węzłów podstawowych + liczba węzłów podstawowych)* cena instancji c5d.9xlarge * czas wykonywania zadania w godzinach) = 7.62 USD
- Koszt Amazon EBS – (0.1 USD/730 * 20 GiB * 7 * 0.63) = (Amazon EBS za GB-godzinową stawkę * rozmiar EBS * liczba instancji * czas wykonywania zadania w godzinie) = 0.012 USD
Skonfiguruj testy porównawcze OSS Spark
W poniższych sekcjach przedstawiamy krótki zarys kroków związanych z konfigurowaniem testów porównawczych. Szczegółowe instrukcje wraz z przykładami można znaleźć w GitHub repo.
Do naszych testów porównawczych OSS Spark używamy narzędzia open source Flintrock aby uruchomić naszą platformę opartą na Amazon EC2 Apache Spark grupa. Flintrock zapewnia szybki sposób na uruchomienie klastra Apache Spark na Amazon EC2 za pomocą wiersza poleceń.
Wymagania wstępne
Wykonaj następujące wymagane kroki:
- Mieć Pythona 3.7.x lub nowszego.
- Miej Pip3 22.2.2 lub nowszy.
- Dodaj katalog bin języka Python do ścieżki środowiska. Plik binarny Flintrock zostanie zainstalowany w tej ścieżce.
- run
aws configureskonfigurować swój Interfejs wiersza poleceń AWS (AWS CLI), aby wskazywała konto porównawcze. Odnosić się do Szybka konfiguracja z konfiguracją aws po instrukcje. - Mieć para kluczy z restrykcyjnymi uprawnieniami do plików, aby uzyskać dostęp do głównego węzła OSS Spark.
- W razie potrzeby utwórz nowy zasobnik S3 na swoim koncie testowym.
- Skopiuj dane źródłowe TPC-DS jako dane wejściowe do zasobnika S3.
- Zbuduj aplikację porównawczą, wykonując czynności opisane w Kroki, aby zbudować aplikację do asemblera z testem porównawczym. Alternatywnie możesz pobrać gotowy plik Spark-Benchmark-Assembly-3.3.0.jar jeśli potrzebujesz aplikacji opartej na platformie Spark 3.3.0.
Wdróż klaster Spark i uruchom zadanie testu porównawczego
Wykonaj następujące kroki:
- Zainstaluj narzędzie Flintrock za pomocą pip, jak pokazano na Kroki konfiguracji testu porównawczego OSS Spark.
- Uruchom polecenie flintrock configure, które wyświetli domyślny plik konfiguracyjny.
- Zmodyfikuj domyślne
config.yamlplik w zależności od potrzeb. Ewentualnie skopiuj i wklej plik plik config.yaml zawartość do domyślnego pliku konfiguracyjnego. Następnie zapisz plik w miejscu, w którym się znajdował. - Na koniec uruchom 7-węzłowy klaster Spark na Amazon EC2 za pośrednictwem Flintrock.
Powinno to utworzyć klaster Spark z jednym węzłem podstawowym i sześcioma węzłami procesu roboczego. Jeśli zobaczysz komunikaty o błędach, dokładnie sprawdź wartości pliku konfiguracyjnego, zwłaszcza wersje Spark i Hadoop oraz atrybuty download-source i AMI.
Klaster OSS Spark nie jest dostarczany z menedżerem zasobów YARN. Aby go włączyć, musimy skonfigurować klaster.
- Pobierz przędza-strona.xml i włącz przędzę.sh pliki z repozytorium GitHub.
- Zastąpić z adresem IP głównego węzła w twoim klastrze Flintrock.
Możesz pobrać adres IP z konsoli Amazon EC2.
- Przekaż pliki do wszystkich węzłów klastra Spark.
- Uruchom skrypt enable-yarn.
- Włącz obsługę Snappy w Hadoop (zadanie testu porównawczego odczytuje skompresowane dane Snappy).
- Pobierz plik JAR aplikacji narzędziowej testu porównawczego Spark-Benchmark-Assembly-3.3.0.jar do komputera lokalnego.
- Skopiuj ten plik do klastra.
- Zaloguj się do węzła podstawowego i uruchom YARN.
- Prześlij zadanie testu porównawczego w klastrze Spark typu open source, jak pokazano w Prześlij zadanie wzorcowe.
Podsumuj wyniki
Pobierz plik z wynikami testu z wyjściowego zasobnika S3 s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Zastępować $YOUR_S3_BUCKET z nazwą zasobnika S3.) Możesz użyć konsoli Amazon S3 i przejść do wyjściowej lokalizacji S3 lub użyć AWS CLI.
Aplikacja testu porównawczego platformy Spark tworzy folder sygnatury czasowej i zapisuje plik podsumowania w prefiksie Summary.csv. Twoja sygnatura czasowa i nazwa pliku będą się różnić od tych pokazanych w poprzednim przykładzie.
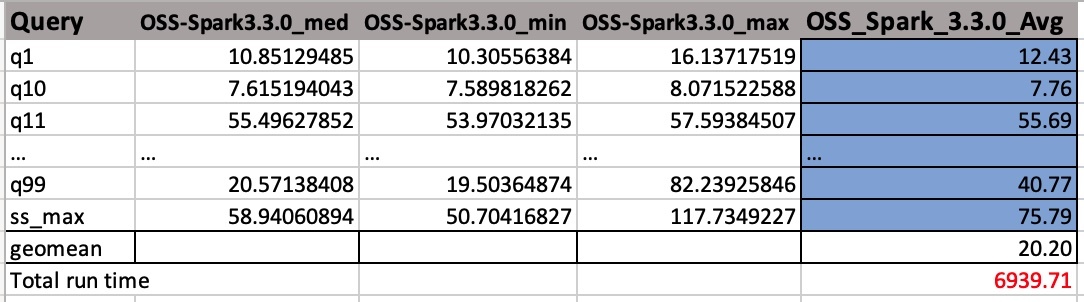
Wyjściowe pliki CSV mają cztery kolumny bez nazw nagłówków. Oni są:
- Nazwa zapytania
- Mediana czasu
- Minimalny czas
- Maksymalny czas
Poniższy zrzut ekranu przedstawia przykładowe dane wyjściowe. Ręcznie dodaliśmy nazwy kolumn. Sposób obliczania średniej geometrycznej i całkowitego czasu wykonywania zadania opiera się na średnich arytmetycznych. Najpierw bierzemy średnią z wartości med, min i max za pomocą wzoru ŚREDNIA(B2:D2). Następnie bierzemy średnią geometryczną kolumny Avg za pomocą wzoru GEOMETRIA (E2:E105).
Skonfiguruj testy porównawcze Amazon EMR
Aby uzyskać szczegółowe instrukcje, zobacz Kroki konfiguracji EMR Benchmarking.
Wymagania wstępne
Wykonaj następujące wymagane kroki:
- run
aws configureaby skonfigurować powłokę AWS CLI tak, aby wskazywała konto testowe. Odnosić się do Szybka konfiguracja z konfiguracją aws po instrukcje. - Prześlij aplikację testową do Amazon S3.
Wdróż klaster EMR i uruchom zadanie testu porównawczego
Wykonaj następujące kroki:
- Uruchom Amazon EMR w powłoce AWS CLI za pomocą wiersza poleceń, jak pokazano na Wdróż EMR Cluster i uruchom zadanie porównawcze.
- Skonfiguruj Amazon EMR z jednym węzłem podstawowym (c5d.9xlarge) i sześcioma głównymi (c5d.9xlarge). Odnosić się do tworzenie klastra aby zapoznać się ze szczegółowym opisem opcji AWS CLI.
- Zapisz identyfikator klastra z odpowiedzi. Potrzebujesz tego w następnym kroku.
- Prześlij zadanie porównawcze w Amazon EMR, używając kroków dodawania w AWS CLI.
Podsumuj wyniki
Podsumuj wyniki z zasobnika wyjściowego s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT w taki sam sposób, jak zrobiliśmy to dla wyników OSS i porównaj.
Sprzątać
Aby uniknąć naliczania przyszłych opłat, usuń utworzone zasoby, postępując zgodnie z instrukcjami w pliku Sekcja czyszczenia repozytorium GitHub.
- Zatrzymaj klastry EMR i OSS Spark. Możesz je również usunąć, jeśli nie chcesz zachować ich treści. Możesz usunąć te zasoby, uruchamiając skrypt cleanup-benchmark-env.sh z terminala w twoim środowisku porównawczym.
- Jeśli użyłeś Chmura AWS9 jako IDE do budowania pliku JAR aplikacji wzorcowej Kroki, aby zbudować aplikację do asemblera z testem porównawczym, możesz również chcieć usunąć środowisko.
Wnioski
Możesz uruchamiać obciążenia Apache Spark 3.5 razy (w oparciu o całkowity czas pracy) szybciej i po niższych kosztach bez wprowadzania jakichkolwiek zmian w aplikacjach, korzystając z Amazon EMR 6.9.0.
Aby być na bieżąco, zasubskrybuj blog Big Data RSS aby dowiedzieć się więcej o środowisku wykonawczym EMR dla Apache Spark, najlepszych praktykach konfiguracyjnych i poradach dotyczących dostrajania.
Aby zapoznać się z wcześniejszymi testami porównawczymi, zobacz Uruchamiaj obciążenia Apache Spark 3.0 1.7 razy szybciej dzięki środowisku wykonawczemu Amazon EMR dla Apache Spark. Należy zauważyć, że poprzedni wynik testu porównawczego wynoszący 1.7-krotność wydajności był oparty na średniej geometrycznej. Na podstawie średniej geometrycznej wydajność w Amazon EMR 6.9 była dwa razy szybsza.
O autorach
 Sekar Srinivasan jest starszym specjalistą ds. architekta rozwiązań w AWS, skoncentrowanym na Big Data i Analytics. Sekar ma ponad 20-letnie doświadczenie w pracy z danymi. Jego pasją jest pomaganie klientom w budowaniu skalowalnych rozwiązań modernizujących ich architekturę i generowaniu insightów z ich danych. W wolnym czasie lubi pracować nad projektami non-profit, zwłaszcza tymi, które skupiają się na edukacji dzieci upośledzonych.
Sekar Srinivasan jest starszym specjalistą ds. architekta rozwiązań w AWS, skoncentrowanym na Big Data i Analytics. Sekar ma ponad 20-letnie doświadczenie w pracy z danymi. Jego pasją jest pomaganie klientom w budowaniu skalowalnych rozwiązań modernizujących ich architekturę i generowaniu insightów z ich danych. W wolnym czasie lubi pracować nad projektami non-profit, zwłaszcza tymi, które skupiają się na edukacji dzieci upośledzonych.
 Prabu Ravichandrana jest starszym architektem danych w Amazon Web Services i koncentruje się na analityce, architekturze i implementacji Data Lake. Pomaga klientom projektować i budować skalowalne i solidne rozwiązania z wykorzystaniem usług AWS. W wolnym czasie Prabu lubi podróżować i spędzać czas z rodziną.
Prabu Ravichandrana jest starszym architektem danych w Amazon Web Services i koncentruje się na analityce, architekturze i implementacji Data Lake. Pomaga klientom projektować i budować skalowalne i solidne rozwiązania z wykorzystaniem usług AWS. W wolnym czasie Prabu lubi podróżować i spędzać czas z rodziną.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 roku
- 7
- 9
- a
- Zdolny
- O nas
- powyżej
- dostęp
- Konto
- w dodatku
- adres
- Rada
- Wszystkie kategorie
- przydział
- Amazonka
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- i
- Apache
- Apache Spark
- api
- Zastosowanie
- aplikacje
- architektura
- atrybuty
- średni
- AVG
- AWS
- Oś
- na podstawie
- uwierzyć
- Benchmark
- BEST
- Najlepsze praktyki
- pomiędzy
- Duży
- Big Data
- Blokować
- awaria
- budować
- Budowanie
- walizka
- zmiana
- Zmiany
- Opłaty
- Wykres
- Grupa
- Kolumna
- kolumny
- jak
- porównać
- porównanie
- zgodny
- obliczać
- systemu
- Konsola
- zawartość
- rdzeń
- Koszty:
- oszczędności
- Koszty:
- Stwórz
- stworzony
- tworzy
- Klientów
- dane
- Jezioro danych
- Data
- Domyślnie
- Pochodny
- opis
- szczegółowe
- urządzenie
- ZROBIŁ
- różne
- bezpośrednio
- niepełnosprawny
- Nie
- nie
- pobieranie
- każdy
- Wschód
- ebs
- Edukacja
- umożliwiać
- Środowisko
- Równoważny
- błąd
- szczególnie
- szacunkowa
- Eter (ETH)
- oceniać
- przykład
- przykłady
- Ćwiczenie
- doświadczenie
- członków Twojej rodziny
- szybciej
- Cecha
- filet
- Akta
- W końcu
- i terminów, a
- koncentruje
- skoncentrowany
- następujący
- formuła
- znaleziono
- Darmowy
- od
- przyszłość
- Zyski
- generujący
- GitHub
- wspaniały
- Hadoop
- pomoc
- pomaga
- Poziomy
- GODZINY
- Jednak
- HTML
- HTTPS
- realizacja
- poprawa
- ulepszenia
- in
- wkład
- spostrzeżenia
- przykład
- instrukcje
- zaangażowany
- IP
- Adres IP
- IT
- Praca
- Trzymać
- jezioro
- uruchomić
- UCZYĆ SIĘ
- Linia
- miejscowy
- lokalizacja
- maszyna
- Dokonywanie
- kierownik
- sposób
- ręcznie
- max
- znaczy
- Pamięć
- wiadomości
- jeszcze
- Nazwa
- Nazwy
- Nawigacja
- Potrzebować
- potrzebne
- wymagania
- Nowości
- Następny
- węzeł
- węzły
- niedochodowy
- dostojnik
- numer
- ONE
- open source
- zoptymalizowane
- Opcje
- zamówienie
- Oss
- zarys
- ogólny
- namiętny
- Przeszłość
- ścieżka
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uprawnienia
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- Pops
- Post
- praktyki
- Cena
- Cennik
- wycena
- pierwotny
- prywatny
- projektowanie
- zapewniać
- pod warunkiem,
- zapewnia
- czysto
- Python
- Szybki
- Kurs
- zrealizować
- Zredukowany
- region
- zwolnić
- obsługi produkcji rolnej, która zastąpiła
- Zasób
- Zasoby
- odpowiedź
- Restrykcyjne
- dalsze
- Efekt
- krzepki
- korzeń
- run
- bieganie
- taki sam
- Zapisz
- Oszczędności
- skalowalny
- Skala
- druga
- sekund
- Sekcja
- działy
- senior
- Usługi
- ustawienie
- ustawienie
- Powłoka
- powinien
- pokazane
- Targi
- Prosty
- SIX
- Rozmiar
- Rozwiązania
- Źródło
- Iskra
- specjalista
- Spędzanie
- początek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- subskrybuj
- taki
- PODSUMOWANIE
- wsparcie
- podpory
- stół
- Brać
- terminal
- test
- Testy
- Połączenia
- ich
- Przez
- czas
- czasy
- znak czasu
- do
- narzędzie
- Zestaw narzędzi
- Kwota produktów:
- tłumaczyć
- Podróżowanie
- zasadniczy
- mający mniejsze prawa
- us
- Stosowanie
- posługiwać się
- użyteczność
- Wartości
- wersja
- przez
- virginia
- kłęby
- sieć
- usługi internetowe
- który
- Podczas
- będzie
- bez
- Praca
- pracownik
- pracujący
- X
- XML
- jamla
- lat
- Twój
- zefirnet