Eksperci przy stole: Semiconductor Engineering zasiedli, aby porozmawiać o ścieżce rozwoju pamięci w coraz bardziej heterogenicznych systemach z Frankiem Ferro, dyrektorem grupy ds. zarządzania produktami w firmie Kadencja; Steven Woo, kolega i wybitny wynalazca w Rambus; Jongsin Yun, technolog pamięci w EDA firmy Siemens; Randy White, menedżer programu rozwiązań pamięciowych w firmie Celownik; oraz Frank Schirrmeister, wiceprezes ds. rozwiązań i rozwoju biznesu w firmie tętnica. Poniżej znajdują się fragmenty tej rozmowy. Można znaleźć część pierwszą tej dyskusji tutaj.
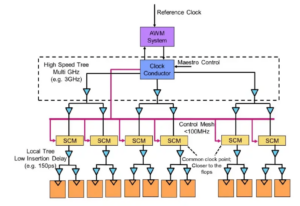
![[Od lewej]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; i Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[Od lewej]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; i Frank Schirrmeister, Arteris
SE: Kiedy zmagamy się z zapotrzebowaniem na sztuczną inteligencję/uczenie się i zasilanie, jakie konfiguracje należy ponownie przemyśleć? Czy zobaczymy odejście od architektury Von Neumanna?
Zabiegać: Jeśli chodzi o architektury systemów, w branży zachodzi rozłam. Tradycyjne aplikacje będące dominującymi końmi pociągowymi, które uruchamiamy w chmurze na serwerach opartych na architekturze x86, nie odchodzą w niepamięć. Istnieją dziesiątki lat oprogramowania, które tworzono i rozwijano, a które będzie dobrze działać w oparciu o tę architekturę. Natomiast AI/ML to nowa klasa. Ludzie ponownie przemyśleli architektury i zbudowali procesory bardzo specyficzne dla domeny. Widzimy, że około dwie trzecie energii jest zużywane na samo przenoszenie danych między procesorem a urządzeniem HBM, podczas gdy tylko około jedna trzecia jest zużywana na faktyczny dostęp do bitów w rdzeniach DRAM. Przenoszenie danych jest obecnie znacznie trudniejsze i droższe. Nie pozbędziemy się pamięci. Potrzebujemy tego, ponieważ zbiory danych są coraz większe. Pytanie brzmi więc: „Jaki jest właściwy sposób na przyszłość?” Odbyło się wiele dyskusji na temat układania w stosy. Gdybyśmy wzięli tę pamięć i umieścili ją bezpośrednio na procesorze, zapewniłoby to dwie rzeczy. Po pierwsze, przepustowość jest obecnie ograniczona przez brzeg lub obwód chipa. To tam idą wejścia/wyjścia. Ale jeśli umieścisz go bezpośrednio na procesorze, możesz teraz wykorzystać cały obszar chipa do rozproszonych połączeń wzajemnych i uzyskać większą przepustowość samej pamięci, która może być przesyłana bezpośrednio do procesor. Łącza stają się znacznie krótsze, a wydajność energetyczna prawdopodobnie wzrasta od 5 do 6 razy. Po drugie, ilość przepustowości, jaką można uzyskać dzięki większym obszarom połączeń z pamięcią, również wzrasta o kilka liczb całkowitych. Połączenie tych dwóch rzeczy może zapewnić większą przepustowość i zwiększyć efektywność energetyczną. Branża ewoluuje w zależności od potrzeb i z pewnością jest to jeden ze sposobów, w jaki w przyszłości systemy pamięci zaczną ewoluować, stając się bardziej energooszczędne i zapewniające większą przepustowość.
Żelazo: Kiedy około 2016 roku zacząłem pracować nad HBM, niektórzy z bardziej zaawansowanych klientów pytali, czy można go układać w stosy. Od dłuższego czasu zastanawiali się, jak ułożyć pamięć DRAM na wierzchu, ponieważ istnieją wyraźne zalety. Z warstwy fizycznej PHY staje się w zasadzie znikome, co pozwala zaoszczędzić dużo energii i wydajności. Ale teraz masz procesor o mocy kilku 100 W i dodatkowo pamięć. Pamięć nie jest w stanie wytrzymać ciepła. To prawdopodobnie najsłabsze ogniwo w łańcuchu cieplnym, co stwarza kolejne wyzwanie. Są korzyści, ale nadal muszą wymyślić, jak sobie poradzić z termiką. Obecnie istnieje większa zachęta do rozwijania tego typu architektury, ponieważ naprawdę pozwala to ogólnie zaoszczędzić na wydajności i mocy, a także poprawić wydajność obliczeniową. Istnieją jednak pewne wyzwania związane z projektowaniem fizycznym, z którymi należy się uporać. Jak mówił Steve, widzimy pojawiające się wszelkiego rodzaju architektury. Całkowicie zgadzam się, że architektury GPU/CPU nigdzie się nie wybierają, nadal będą dominować. Jednocześnie każda firma na świecie próbuje wymyślić lepszą pułapkę na myszy do wykorzystania sztucznej inteligencji. Widzimy wbudowaną pamięć SRAM i kombinacje pamięci o dużej przepustowości. Obecnie LPDDR dość mocno podnosi głowę, jeśli chodzi o wykorzystanie LPDDR w centrum danych ze względu na moc. Widzieliśmy nawet użycie GDDR w niektórych aplikacjach wnioskowania AI, a także we wszystkich starych systemach pamięci. Teraz próbują zmieścić jak najwięcej pamięci DDR5 na powierzchni. Widziałem każdą architekturę, jaką możesz wymyślić, niezależnie od tego, czy jest to DDR, HBM, GDDR czy inna. To zależy od rdzenia procesora pod względem ogólnej wartości dodanej, a następnie w jaki sposób można przebić się przez konkretną architekturę. System pamięci, który jest z nim zgodny, dzięki czemu możesz kształtować swój procesor i architekturę pamięci, w zależności od tego, co jest dostępne.
Oraz: Kolejną kwestią jest brak zmienności. Jeśli na przykład sztuczna inteligencja musi poradzić sobie z przerwami w zasilaniu pomiędzy uruchomieniem sztucznej inteligencji opartej na IoT, potrzebujemy dużo wyłączania i włączania zasilania, a wszystkie informacje potrzebne do szkolenia sztucznej inteligencji muszą się ciągle zmieniać. Jeśli mamy jakieś rozwiązania, w których możemy przechowywać te ciężary w chipie, dzięki czemu nie musimy ciągle poruszać się tam i z powrotem, aby uzyskać tę samą wagę, oznacza to duże oszczędności energii, szczególnie w przypadku sztucznej inteligencji opartej na IoT. Będzie inne rozwiązanie, które zaspokoi zapotrzebowanie na energię.
Schirmeister: Z punktu widzenia NoC fascynujące jest to, że trzeba zoptymalizować te ścieżki od procesora przechodzącego przez NoC, uzyskując dostęp do interfejsu pamięci z kontrolerem potencjalnie przechodzącym przez UCIe w celu przekazania chipletu do innego chipletu, który następnie ma wbudowaną pamięć To. To nie tak, że architektury Von Neumanna są martwe. Ale obecnie istnieje wiele odmian, w zależności od obciążenia, które chcesz obliczyć. Należy je rozpatrywać w kontekście pamięci, a pamięć jest tylko jednym z aspektów. Skąd pobierasz dane z lokalizacji danych i jak są one rozmieszczone w tej pamięci DRAM? Pracujemy nad wszystkimi tymi elementami, takimi jak analiza wydajności pamięci, a następnie optymalizacja architektury systemu. Pobudza to wiele innowacji w nowych architekturach, o czym nigdy nie pomyślałem, gdy na uniwersytecie uczyłem się o Von Neumannie. Na drugim końcu znajdują się rzeczy takie jak siatki. Obecnie istnieje o wiele więcej architektur, które należy wziąć pod uwagę, a ich wybór zależy od przepustowości pamięci, możliwości obliczeniowych itd. i nie rośnie w tym samym tempie.
White: Istnieje trend obejmujący obliczenia zdezagregowane lub obliczenia rozproszone, co oznacza, że architekt musi mieć do dyspozycji więcej narzędzi. Hierarchia pamięci została rozszerzona. Uwzględniono semantykę, a także pamięć CXL i różne pamięci hybrydowe, które są dostępne w wersji flash i DRAM. Równoległa aplikacja dla centrum danych to motoryzacja. W przemyśle motoryzacyjnym ten czujnik zawsze był obliczany za pomocą ECU (elektronicznych jednostek sterujących). Fascynuje mnie ewolucja do centrum danych. Przejdźmy szybko do przodu i dzisiaj mamy rozproszone węzły obliczeniowe zwane kontrolerami domeny. To jest to samo. Próbuje zwrócić uwagę na to, że być może moc nie jest tak duża, ponieważ skala komputerów nie jest tak duża, ale opóźnienia z pewnością mają duże znaczenie w motoryzacji. ADAS wymaga bardzo dużej przepustowości, a Ty masz różne kompromisy. A potem masz więcej czujników mechanicznych, ale podobne ograniczenia w centrum danych. Masz chłodnię, która nie musi mieć małych opóźnień, a także inne aplikacje o dużej przepustowości. Fascynujące jest obserwowanie, jak bardzo ewoluowały narzędzia i możliwości architekta. Branża wykonała naprawdę dobrą robotę, reagując, a my wszyscy zapewniamy różne rozwiązania, które trafiają na rynek.
SE: Jak ewoluowały narzędzia do projektowania pamięci?
Schirmeister: Kiedy zaczynałem od kilku pierwszych chipów w latach 90., najczęściej używanym narzędziem systemowym był Excel. Od tego czasu zawsze miałem nadzieję, że w pewnym momencie może się zepsuć ze względu na rzeczy, które robimy na poziomie systemu, pamięci, analizy przepustowości i tak dalej. To miało duży wpływ na moje zespoły. W tamtym czasie był to bardzo zaawansowany sprzęt. Ale według Randy’ego obecnie pewne złożone rzeczy należy symulować z poziomem wierności, który wcześniej nie był możliwy bez obliczeń. Dla przykładu, założenie pewnego opóźnienia dostępu do pamięci DRAM może prowadzić do złych decyzji dotyczących architektury i potencjalnie nieprawidłowego zaprojektowania architektur transportu danych na chipie. Druga strona jest również prawdziwa. Jeśli zawsze zakładasz najgorszy przypadek, przeprojektujesz architekturę. Posiadanie narzędzi do analizy pamięci DRAM i wydajności oraz posiadanie odpowiednich modeli kontrolerów pozwala architektowi symulować to wszystko, co jest fascynującym środowiskiem. Z lat 90. pokładałem nadzieję, że Excel w pewnym momencie przełamie się jako narzędzie na poziomie systemu może faktycznie się spełnić, ponieważ niektórych dynamicznych efektów nie da się już wykonać w Excelu, ponieważ trzeba je zasymulować — zwłaszcza gdy dodasz interfejs typu die-to-die z charakterystyką PHY, a następnie warstwę łączy cechy takie jak sprawdzanie, czy wszystko się zgadza i potencjalne ponowne przesyłanie danych. Brak przeprowadzenia tych symulacji spowoduje, że architektura będzie nieoptymalna.
Żelazo: Pierwszym krokiem w większości przeprowadzanych przez nas ocen jest udostępnienie im stanowiska do testowania pamięci, aby mogli zacząć przyglądać się wydajności DRAM. To ogromny krok, nawet jeśli chodzi o tak proste czynności, jak uruchomienie lokalnych narzędzi do symulacji pamięci DRAM, a potem przejście do pełnowymiarowych symulacji. Widzimy, że coraz więcej klientów prosi o tego typu symulację. Bardzo ważnym pierwszym krokiem w każdej ocenie jest upewnienie się, że wydajność pamięci DRAM wynosi ponad 90 lat.
Zabiegać: Jednym z powodów wzrostu liczby narzędzi do symulacji pełnego systemu jest to, że pamięci DRAM stały się znacznie bardziej skomplikowane. Obecnie bardzo trudno jest sprostać niektórym z tych złożonych zadań, korzystając z prostych narzędzi, takich jak Excel. Jeśli spojrzeć na arkusz danych DRAM z lat 90., arkusze te liczyły około 40 stron. Teraz mają setki stron. To tylko mówi o złożoności urządzenia, które jest potrzebne do uzyskania dużej przepustowości. Można to połączyć z faktem, że pamięć jest czynnikiem wpływającym na koszty systemu, a także przepustowość i opóźnienia związane z wydajnością procesora. Jest to również duży sterownik mocy, więc teraz musisz symulować na znacznie bardziej szczegółowym poziomie. Jeśli chodzi o przepływ narzędzi, architekci systemów rozumieją, że pamięć jest ogromnym czynnikiem napędzającym. Dlatego narzędzia muszą być bardziej wyrafinowane i muszą bardzo dobrze łączyć się z innymi narzędziami, aby architekt systemu miał najlepszy globalny obraz tego, co się dzieje — szczególnie tego, jak pamięć wpływa na system.
Oraz: W miarę jak wkraczamy w erę sztucznej inteligencji, używanych jest wiele systemów wielordzeniowych, ale nie wiemy, które dane trafiają gdzie. Działa również bardziej równolegle do chipa. Rozmiar pamięci jest znacznie większy. Jeśli użyjemy sztucznej inteligencji typu ChatGPT, wówczas obsługa danych w modelach wymaga około 350 MB danych, co stanowi ogromną ilość danych jak na wagę, a rzeczywiste dane wejściowe/wyjściowe są znacznie większe. Ten wzrost ilości wymaganych danych oznacza, że istnieje wiele efektów probabilistycznych, których wcześniej nie widzieliśmy. Wykrycie wszystkich błędów związanych z tak dużą ilością pamięci jest niezwykle trudnym testem. ECC jest używane wszędzie, nawet w pamięci SRAM, która tradycyjnie nie korzystała z ECC, ale teraz jest bardzo powszechna w największych systemach. Testowanie tego wszystkiego jest bardzo trudne i musi być wspierane przez rozwiązania EDA, aby przetestować wszystkie te różne warunki.
SE: Z jakimi wyzwaniami na co dzień mierzą się zespoły inżynierów?
White: Każdego dnia znajdziesz mnie w laboratorium. Podwijam rękawy i mam brudne ręce, szturcham przewody, lutuję i tak dalej. Dużo myślę o walidacji po krzemie. Rozmawialiśmy o wczesnych symulacjach i narzędziach wbudowanych w matrycę — BiST i tym podobnych. Ostatecznie, przed wysyłką, chcemy przeprowadzić jakąś formę walidacji systemu lub testów na poziomie urządzenia. Rozmawialiśmy o tym, jak pokonać ścianę pamięci. Wspólnie lokalizujemy pamięć, HBM i tym podobne. Jeśli spojrzymy na ewolucję technologii pakowania, zaczynaliśmy od opakowań ołowianych. Nie były zbyt dobre pod względem integralności sygnału. Kilkadziesiąt lat później przeszliśmy na zoptymalizowaną integralność sygnału, taką jak macierze kulkowe (BGA). Nie mieliśmy do tego dostępu, co oznaczało, że nie można było tego przetestować. Wpadliśmy więc na pomysł zwany przekładkami urządzeń — przekładkami BGA — i to pozwoliło nam umieścić specjalne urządzenie kierujące sygnały. Następnie moglibyśmy podłączyć go do sprzętu testowego. Przejdźmy szybko do dnia dzisiejszego, a teraz mamy HBM i chiplety. Jak umieścić urządzenie pomiędzy silikonowymi przekładkami? Nie możemy i na tym polega walka. To wyzwanie, które nie pozwala mi zasnąć w nocy. Jak przeprowadzamy analizę awarii w terenie u klienta OEM lub systemu, gdzie nie uzyskuje on wydajności na poziomie 90%. W łączu jest więcej błędów, nie można ich poprawnie zainicjować, a szkolenie nie działa. Czy jest to problem ze integralnością systemu?
Schirmeister: Czy nie wolałbyś robić tego w domu, za pomocą wirtualnego interfejsu, niż chodzić do laboratorium? Czy odpowiedzią nie jest więcej analiz wbudowanych w chip? Dzięki chipletom integrujemy wszystko jeszcze bardziej. Umieszczenie tam lutownicy tak naprawdę nie wchodzi w grę, więc musi istnieć sposób na analizę na chipie. Mamy ten sam problem z NoC. Ludzie patrzą na NoC, wysyłasz dane, a potem ich nie ma. Potrzebujemy danych analitycznych, które można tam umieścić, aby ludzie mogli przeprowadzać debugowanie, a to rozciąga się na poziom produkcyjny, aby w końcu można było pracować z domu i robić wszystko w oparciu o analitykę chipów.
Żelazo: Zwłaszcza w przypadku pamięci o dużej przepustowości fizycznie nie można się tam dostać. Kiedy udzielamy licencji na PHY, mamy również produkt, który jest z tym zgodny, dzięki czemu możesz przyjrzeć się każdemu z tych 1,024 bitów. Możesz rozpocząć odczytywanie i zapisywanie pamięci DRAM z poziomu narzędzia, dzięki czemu nie musisz się tam fizycznie wchodzić. Podoba mi się pomysł z interposerem. Podczas testowania wyciągamy niektóre piny z przekładki, czego nie można zrobić w systemie. Dostanie się do tych systemów 3D to naprawdę wyzwanie. Nawet z punktu widzenia przepływu narzędzi do projektowania wydaje się, że większość firm wykonuje swój własny, indywidualny przepływ wielu z tych narzędzi 2.5D. Zaczynamy opracowywać bardziej ustandaryzowany sposób budowania systemu 2.5D, począwszy od integralności sygnału, mocy, aż po cały przepływ.
White: Mam nadzieję, że w miarę upływu czasu uda nam się utrzymać ten sam poziom dokładności. Należę do grupy ds. zgodności współczynników kształtu UCIe. Zastanawiam się, jak scharakteryzować znaną dobrą kość, złotą kość. Ostatecznie zajmie to znacznie więcej czasu, ale znajdziemy złoty środek między wydajnością i dokładnością potrzebnych testów, a wbudowaną elastycznością.
Schirmeister: Jeśli przyjrzę się chipletom i ich adopcji w bardziej otwartym środowisku produkcyjnym, testowanie jest jednym z większych wyzwań na drodze do zapewnienia ich prawidłowego działania. Jeśli jestem dużą firmą i kontroluję wszystkie jej strony, mogę odpowiednio ograniczyć wszystko, tak aby testowanie i tak dalej stało się wykonalne. Jeśli chcę przejść do sloganu UCIe, że UCI jest tylko jedna litera od PCI i wyobrażam sobie przyszłość, w której montaż UCIe będzie, z perspektywy produkcyjnej, przypominał dzisiejsze gniazda PCI w komputerze PC, to aspekty testowania są naprawdę wyzywający. Musimy znaleźć rozwiązanie. Jest mnóstwo pracy.
Powiązane artykuły
Przyszłość pamięci (Część 1 powyżej można zaokrąglić)
Od prób rozwiązania problemów związanych z temperaturą i zasilaniem po rolę CXL i UCIe, przyszłość niesie ze sobą wiele możliwości dla pamięci.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://semiengineering.com/rethinking-memory/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 2016
- 3d
- 40
- a
- O nas
- powyżej
- dostęp
- Dostęp
- precyzja
- rzeczywisty
- faktycznie
- ADA
- Dodaj
- adres
- Przyjęcie
- zaawansowany
- Korzyść
- Zalety
- ponownie
- AI
- Trening AI
- AI / ML
- Wszystkie kategorie
- dozwolony
- pozwala
- również
- zawsze
- ilość
- an
- analiza
- analityka
- i
- Inne
- odpowiedź
- każdy
- więcej
- nigdzie
- Zastosowanie
- aplikacje
- odpowiednio
- architekci
- architektura
- SĄ
- POWIERZCHNIA
- na około
- ułożone
- Szyk
- AS
- pytanie
- aspekt
- aspekty
- Montaż
- założyć
- At
- Próby
- motoryzacyjny
- dostępny
- z dala
- z powrotem
- Łazienka
- piłka
- przepustowość
- bar
- na podstawie
- Gruntownie
- podstawa
- BE
- bo
- stają się
- staje się
- być
- zanim
- jest
- Korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Duży
- większe
- Bit
- przerwa
- przynieść
- budować
- wybudowany
- biznes
- rozwój biznesu
- ale
- by
- Kadencja
- nazywa
- oprawa ołowiana witrażu
- CAN
- Może uzyskać
- możliwości
- walizka
- Centrum
- pewien
- na pewno
- łańcuch
- wyzwanie
- wyzwania
- wyzwanie
- Charakterystyka
- charakteryzować
- kontrola
- żeton
- Frytki
- klasa
- jasny
- Chmura
- zimno
- Chłodnia
- kombinacje
- jak
- przyjście
- wspólny
- Firmy
- sukcesy firma
- kompleks
- kompleksowość
- spełnienie
- skomplikowane
- obliczać
- komputery
- computing
- pojęcie
- Warunki
- Skontaktuj się
- za
- Ograniczenia
- kontekst
- kontrast
- kontrola
- kontroler
- Rozmowa
- rdzeń
- skorygowania
- Koszty:
- mógłby
- Para
- CPU
- tworzy
- klient
- Klientów
- dane
- Centrum danych
- zbiory danych
- dzień
- dzień do dnia
- Dni
- martwy
- sprawa
- lat
- Decyzje
- Zdecydowanie
- wymagania
- W zależności
- zależy
- Wnętrze
- projektowanie
- szczegółowe
- oprogramowania
- urządzenie
- Umierać
- różne
- trudny
- bezpośrednio
- Dyrektor
- dyskusja
- sprzedaż
- Wybitny
- dystrybuowane
- przetwarzanie rozproszone
- do
- robi
- Nie
- robi
- domena
- dominujący
- zrobić
- nie
- na dół
- napędzany
- kierowca
- podczas
- dynamiczny
- Wcześnie
- ruchomości
- efektywność
- wydajny
- Elektroniczny
- zakończenia
- energia
- Inżynieria
- Cały
- Środowisko
- sprzęt
- Era
- Błędy
- szczególnie
- Eter (ETH)
- ewaluację
- oceny
- Parzyste
- ostatecznie
- Każdy
- wszystko
- wszędzie
- ewolucja
- ewoluuje
- ewoluowały
- ewoluuje
- przykład
- przewyższać
- rozszerzony
- drogi
- rozciąga się
- skrajny
- niezwykle
- Oczy
- Twarz
- fakt
- czynnik
- Brak
- fascynujący
- FAST
- wykonalny
- facet
- wierność
- pole
- Postać
- W końcu
- Znajdź
- i terminów, a
- Migać
- Elastyczność
- Trzepnięcie
- pływ
- następujący sposób
- Ślad stopy
- W razie zamówieenia projektu
- Nasz formularz
- naprzód
- Naprzód
- znaleziono
- szczery
- od
- pełny
- dalej
- przyszłość
- otrzymać
- miejsce
- Dać
- dany
- Globalne
- Go
- Goes
- będzie
- Złoty
- poszedł
- dobry
- dobra praca
- got
- Krata
- Zarządzanie
- Rozwój
- miał
- Prowadzenie
- siła robocza
- Zaoszczędzić
- Have
- mający
- głowa
- pomoc
- hierarchia
- Wysoki
- posiada
- Strona główna
- nadzieję
- W jaki sposób
- How To
- HTML
- HTTPS
- olbrzymi
- Setki
- Hybrydowy
- i
- pomysł
- if
- obraz
- wpływ
- wpływ
- ważny
- podnieść
- in
- Motywacja
- włączony
- niepoprawnie
- Zwiększać
- coraz bardziej
- indywidualny
- przemysł
- Informacja
- Innowacja
- wewnątrz
- integrować
- integralność
- interkonekty
- Interfejs
- najnowszych
- z udziałem
- problem
- problemy
- IT
- JEGO
- samo
- Praca
- właśnie
- Wiedzieć
- znany
- laboratorium
- duży
- większe
- największym
- Utajenie
- później
- warstwa
- prowadzić
- nauka
- list
- poziom
- Licencja
- lubić
- Ograniczony
- LINK
- linki
- miejscowy
- Popatrz
- poszukuje
- Partia
- dużo
- niski
- utrzymać
- robić
- Dokonywanie
- i konserwacjami
- kierownik
- produkcja
- wiele
- rynek
- Maksymalna szerokość
- może
- me
- znaczy
- Oznaczało
- mechaniczny
- średni
- wspomnienia
- Pamięć
- może
- modele
- jeszcze
- większość
- ruch
- przeniósł
- ruch
- przeniesienie
- dużo
- my
- Potrzebować
- wymagania
- nigdy
- Nowości
- noc
- węzły
- już dziś
- numer
- of
- poza
- Stary
- on
- ONE
- tylko
- koncepcja
- Szanse
- Optymalizacja
- zoptymalizowane
- optymalizacji
- Option
- Opcje
- or
- zamówienie
- Inne
- Pozostałe
- na zewnątrz
- ogólny
- Przezwyciężać
- własny
- Pakiety
- opakowania
- stron
- Parallel
- część
- szczególny
- przechodzić
- ścieżka
- ścieżki
- PC
- Ludzie
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- perspektywa
- fizyczny
- Fizycznie
- kołki
- planeta
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- możliwy
- potencjalnie
- power
- prezydent
- poprzednio
- prawdopodobnie
- Problem
- Procesor
- Procesory
- Produkt
- zarządzanie produktem
- Produkcja
- Program
- właściwy
- prawidłowo
- zapewniać
- położyć
- pytanie
- całkiem
- wychowywanie
- Kurs
- raczej
- Czytający
- naprawdę
- związane z
- polegać
- wymagany
- Wymaga
- rozwiązać
- odpowiadanie
- dalsze
- Pozbyć się
- prawo
- Rosnąć
- role
- Rolka
- run
- bieganie
- taki sam
- Zapisz
- Oszczędności
- powiedzenie
- Skala
- druga
- widzieć
- widzenie
- wydaje
- widziany
- semantyka
- Semiconductor
- wysłać
- czujnik
- czujniki
- serwery
- kilka
- pościel
- przesunięcie
- statek
- bok
- Strony
- Siemens
- Signal
- Sygnały
- Krzem
- podobny
- Prosty
- symulacja
- symulacje
- ponieważ
- pojedynczy
- Rozmiar
- automatach
- So
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- wyrafinowany
- Mówi
- specjalny
- spędził
- Wyciskać
- stos
- ułożone w stos
- układanie w stosy
- standaryzowany
- punkt widzenia
- początek
- rozpoczęty
- Startowy
- Ewolucja krok po kroku
- Steve
- steven
- Nadal
- przechowywanie
- sklep
- Walka
- taki
- Utrzymany
- pewnie
- system
- systemy
- stół
- Brać
- Mówić
- Zespoły
- technolog
- Technologia
- REGULAMIN
- test
- Testowanie
- Testy
- niż
- że
- Połączenia
- Przyszłość
- ich
- Im
- następnie
- Tam.
- termiczny
- Te
- one
- rzecz
- rzeczy
- myśleć
- Trzeci
- to
- tych
- myśl
- Przez
- czas
- do
- już dziś
- razem
- narzędzie
- narzędzia
- Top
- CAŁKOWICIE
- kompromisy
- tradycyjny
- tradycyjnie
- Trening
- transportu
- Trend
- prawdziwy
- stara
- drugiej
- dwie trzecie
- rodzaj
- zrozumieć
- jednostek
- uniwersytet
- us
- posługiwać się
- używany
- za pomocą
- uprawomocnienie
- wartość
- wariacje
- różnorodny
- początku.
- wice
- Wiceprezes
- Zobacz i wysłuchaj
- Wirtualny
- z
- chodzący
- Ściana
- chcieć
- była
- Droga..
- we
- waga
- DOBRZE
- były
- Co
- cokolwiek
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- biały
- cały
- dlaczego
- będzie
- w
- bez
- zalecać się
- Praca
- Praca w domu
- pracujący
- najgorszy
- pisanie
- ty
- Twój
- zefirnet