W dzisiejszej erze cyfrowej dane stanowią podstawę sukcesu każdej organizacji. Jednym z najczęściej używanych formatów wymiany danych jest XML. Analizowanie plików XML jest kluczowe z kilku powodów. Po pierwsze, pliki XML są wykorzystywane w wielu branżach, w tym w finansach, służbie zdrowia i rządzie. Analizowanie plików XML może pomóc organizacjom uzyskać wgląd w ich dane, umożliwiając im podejmowanie lepszych decyzji i usprawnianie działań. Analizowanie plików XML może również pomóc w integracji danych, ponieważ wiele aplikacji i systemów używa XML jako standardowego formatu danych. Analizując pliki XML, organizacje mogą łatwo integrować dane z różnych źródeł i zapewnić spójność w swoich systemach. Jednak pliki XML zawierają częściowo ustrukturyzowane, silnie zagnieżdżone dane, co utrudnia dostęp do informacji i ich analizę, szczególnie jeśli plik jest duży i zawiera złożony, wysoce zagnieżdżony schemat.
Pliki XML dobrze nadają się do zastosowań, ale mogą nie być optymalne w przypadku silników analitycznych. Aby zwiększyć wydajność zapytań i umożliwić łatwy dostęp w dalszych silnikach analitycznych, takich jak Amazonka Atena, bardzo ważne jest wstępne przetworzenie plików XML do formatu kolumnowego, takiego jak Parquet. Ta transformacja pozwala na poprawę wydajności i użyteczności w przepływach pracy analitycznych. W tym poście pokazujemy, jak przetwarzać dane XML za pomocą Klej AWS i Atena.
Omówienie rozwiązania
Badamy dwie różne techniki, które mogą usprawnić przepływ pracy podczas przetwarzania plików XML:
- Technika 1: Użyj robota AWS Glue i edytora wizualnego AWS Glue – Możesz użyć interfejsu użytkownika AWS Glue w połączeniu z przeszukiwaczem, aby zdefiniować strukturę tabeli dla plików XML. Takie podejście zapewnia przyjazny interfejs użytkownika i jest szczególnie odpowiednie dla osób, które preferują graficzne podejście do zarządzania swoimi danymi.
- Technika 2: Użyj dynamicznych ramek AWS Glue z wywnioskowanymi i ustalonymi schematami – Przeszukiwacz ma ograniczenia, jeśli chodzi o przetwarzanie pojedynczego wiersza w plikach XML większych niż 1 MB. Aby pokonać to ograniczenie, do skonstruowania kleju AWS używamy notatnika AWS Glue
DynamicFrames, wykorzystując zarówno wywnioskowane, jak i ustalone schematy. Metoda ta zapewnia wydajną obsługę plików XML zawierających wiersze o rozmiarze przekraczającym 1 MB.
W obu podejściach naszym ostatecznym celem jest konwersja plików XML do formatu Apache Parquet, dzięki czemu będą one łatwo dostępne do wysyłania zapytań za pomocą Atheny. Dzięki tym technikom możesz zwiększyć szybkość przetwarzania i dostępność danych XML, umożliwiając łatwe uzyskiwanie cennych spostrzeżeń.
Wymagania wstępne
Przed rozpoczęciem tego samouczka należy spełnić następujące wymagania wstępne (dotyczą obu technik):
- Pobierz pliki XML technika1.xml i technika2.xml.
- Prześlij pliki do pliku Usługa Amazon Simple Storage Łyżka (Amazon S3). Możesz przesłać je do tego samego segmentu S3 w różnych folderach lub do różnych segmentów S3.
- Tworzenie AWS Zarządzanie tożsamością i dostępem (IAM) dla zadania ETL lub notatnika zgodnie z instrukcją Skonfiguruj uprawnienia IAM dla AWS Glue Studio.
- Dodaj wbudowaną politykę do swojej roli za pomocą iam: PassRole akcja:
- Dodaj politykę uprawnień do roli z dostępem do segmentu S3.
Teraz, gdy mamy już za sobą wymagania wstępne, przejdźmy do wdrożenia pierwszej techniki.
Technika 1: Użyj robota AWS Glue i edytora wizualnego
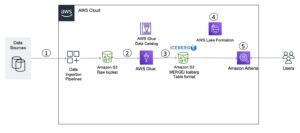
Poniższy diagram ilustruje prostą architekturę, której można użyć do wdrożenia rozwiązania.
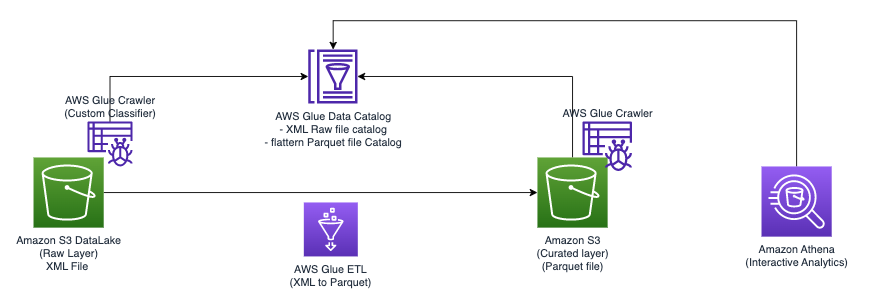
Aby analizować pliki XML przechowywane w Amazon S3 przy użyciu AWS Glue i Athena, wykonujemy następujące kroki wysokiego poziomu:
- Utwórz przeszukiwacz AWS Glue, aby wyodrębnić metadane XML i utworzyć tabelę w katalogu danych kleju AWS.
- Przetwarzaj i przekształcaj dane XML do formatu (np. Parquet) odpowiedniego dla Atheny za pomocą zadania AWS Glue wyodrębniania, przekształcania i ładowania (ETL).
- Skonfiguruj i uruchom zadanie AWS Glue za pomocą konsoli AWS Glue lub Interfejs wiersza poleceń AWS (interfejs wiersza poleceń AWS).
- Wykorzystaj przetworzone dane (w formacie Parquet) z tabelami Athena, umożliwiając zapytania SQL.
- Skorzystaj z przyjaznego interfejsu użytkownika w Athenie, aby analizować dane XML za pomocą zapytań SQL na temat danych przechowywanych w Amazon S3.
Architektura ta jest skalowalnym, ekonomicznym rozwiązaniem do analizy danych XML na Amazon S3 przy użyciu AWS Glue i Athena. Możesz analizować duże zbiory danych bez skomplikowanego zarządzania infrastrukturą.
Do wyodrębniania metadanych plików XML używamy robota AWS Glue. Możesz wybrać domyślny klasyfikator AWS Glue do ogólnej klasyfikacji XML. Automatycznie wykrywa strukturę i schemat danych XML, co jest przydatne w przypadku popularnych formatów.
W tym rozwiązaniu używamy również niestandardowego klasyfikatora XML. Został zaprojektowany dla określonych schematów lub formatów XML, umożliwiając precyzyjną ekstrakcję metadanych. Jest to idealne rozwiązanie w przypadku niestandardowych formatów XML lub gdy potrzebujesz szczegółowej kontroli nad klasyfikacją. Niestandardowy klasyfikator zapewnia wyodrębnienie tylko niezbędnych metadanych, upraszczając dalsze zadania przetwarzania i analizy. Takie podejście optymalizuje wykorzystanie plików XML.
Poniższy zrzut ekranu przedstawia przykład pliku XML ze znacznikami.
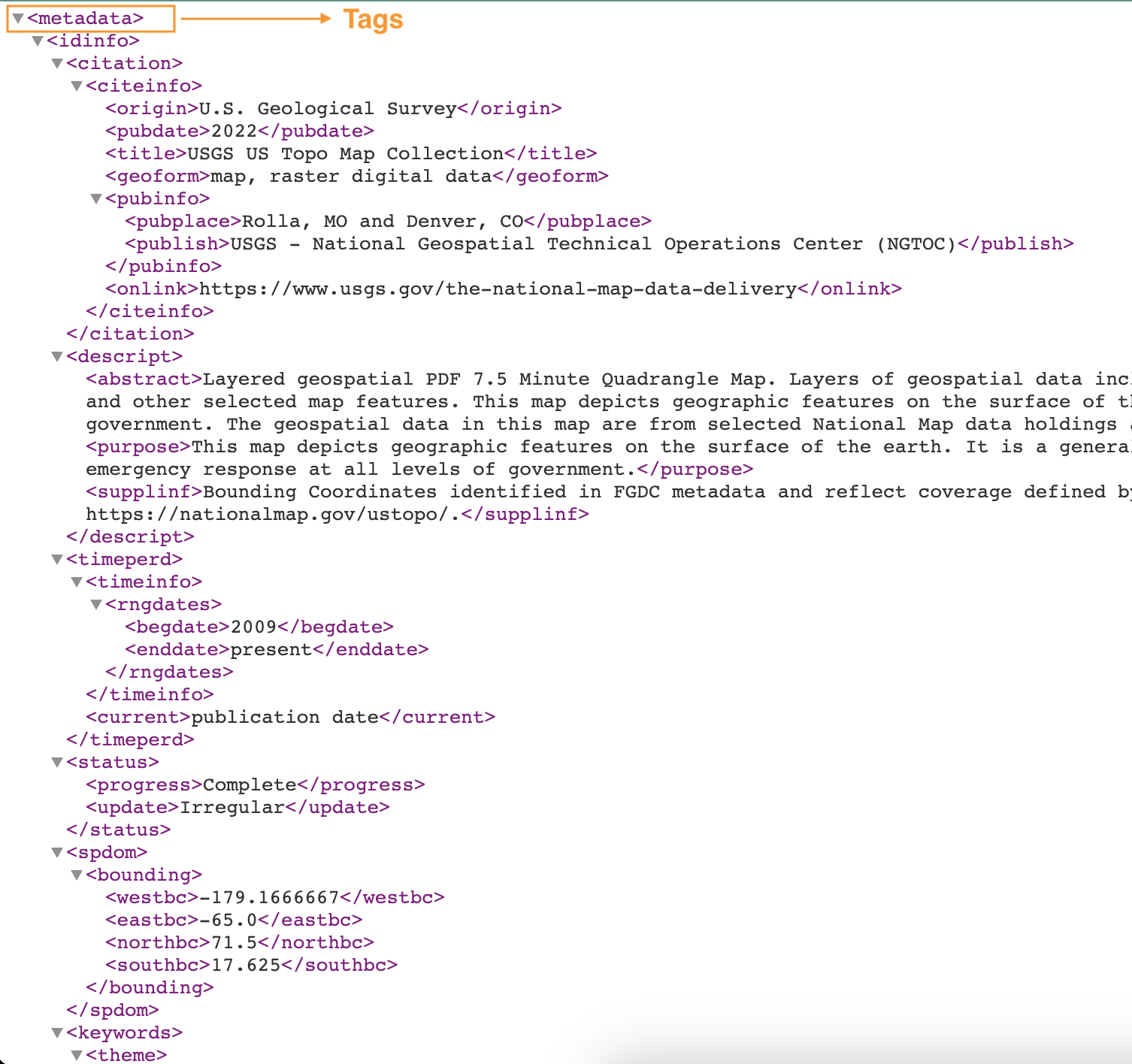
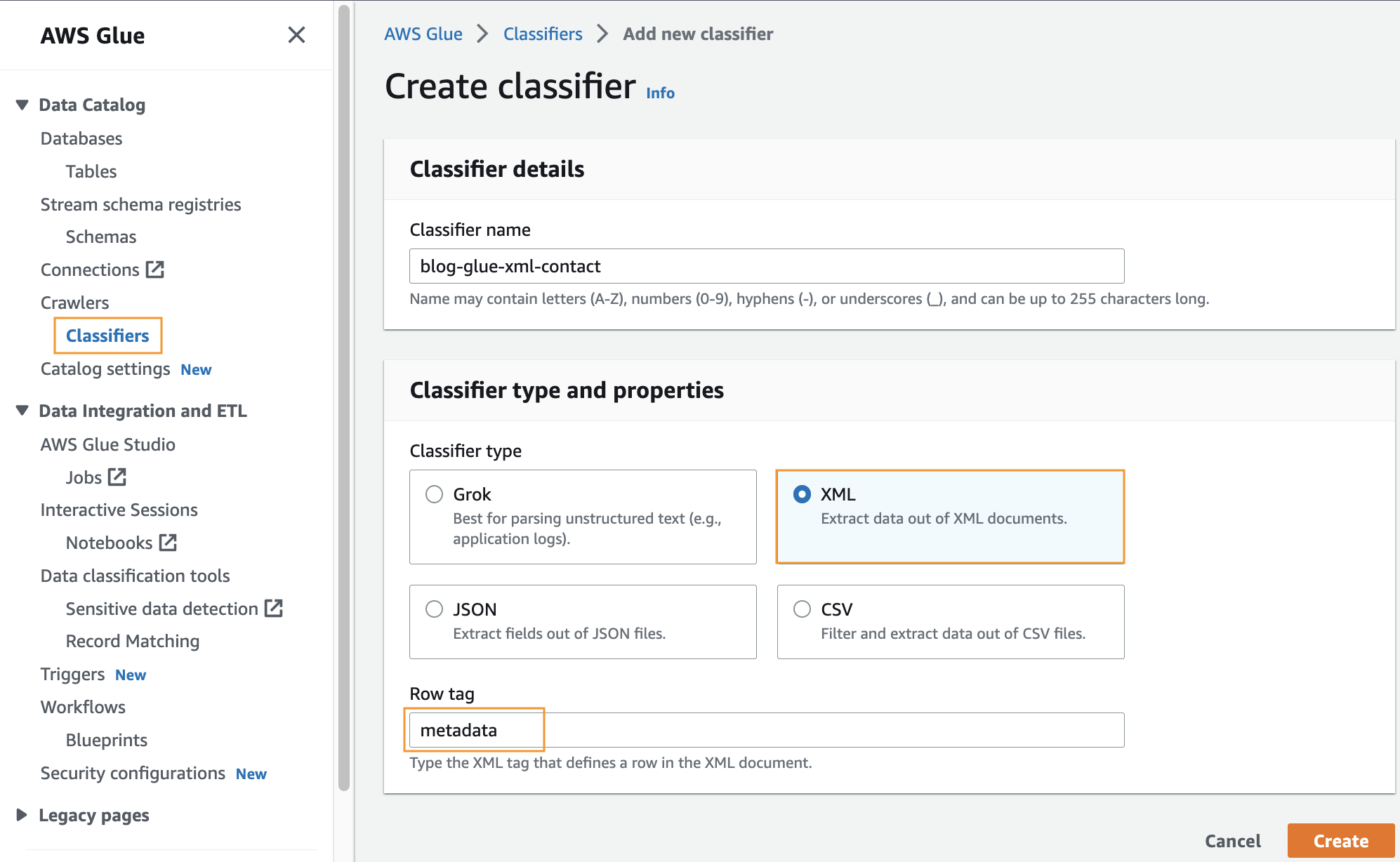
Utwórz niestandardowy klasyfikator
Na tym etapie utworzysz niestandardowy klasyfikator AWS Glue w celu wyodrębnienia metadanych z pliku XML. Wykonaj następujące kroki:
- Na konsoli AWS Glue pod Roboty w okienku nawigacji wybierz Klasyfikatory.
- Dodaj Dodaj klasyfikator.
- Wybierz XML jako typ klasyfikatora.
- Wprowadź nazwę klasyfikatora, np
blog-glue-xml-contact. - W razie zamówieenia projektu Znacznik wierszawprowadź nazwę tagu głównego zawierającego metadane (na przykład
metadata). - Dodaj Stwórz.
Utwórz przeszukiwacz kleju AWS, aby przeszukać plik xml
W tej sekcji tworzymy moduł Glue Crawler, który będzie wyodrębniał metadane z pliku XML przy użyciu klasyfikatora klienta utworzonego w poprzednim kroku.
Utwórz bazę danych
- Idź do Konsola AWS Gluewybierz Bazy danych w okienku nawigacji.
- Kliknij na Dodaj bazę danych.
- Podaj nazwę np
blog_glue_xml - Dodaj Stwórz Baza danych
Utwórz robota
Wykonaj następujące kroki, aby utworzyć pierwszego robota:
- Na konsoli AWS Glue wybierz Roboty w okienku nawigacji.
- Dodaj Utwórz robota.
- Na Ustaw właściwości przeszukiwacza stronie, podaj nazwę nowego robota (np
blog-glue-parquet), następnie wybierz Następna. - Na Wybierz źródła danych i klasyfikatory strona, wybierz Jeszcze nie dla Konfiguracja źródła danych.
- Dodaj Dodaj magazyn danych.
- W razie zamówieenia projektu Ścieżka S3, przejdź do
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Upewnij się, że wybrałeś folder XML, a nie plik w folderze.
- Resztę opcji pozostaw jako domyślną i wybieraj Dodaj źródło danych S3.
- Rozszerzać Klasyfikatory niestandardowe – opcjonalne, wybierz blog-glue-xml-contact, a następnie wybierz Następna i pozostaw resztę opcji jako domyślną.
- Wybierz swoją rolę IAM lub wybierz Utwórz nową rolę uprawnień, dodaj przyrostek
glue-xml-contact(na przykład,AWSGlueServiceNotebookRoleBlog) i wybierz Następna. - Na Ustaw wydajność i harmonogram strona, pod Konfiguracja wyjściowawybierz
blog_glue_xmldla Docelowa baza danych. - Wchodzę
console_jako przedrostek dodawany do tabel (opcjonalnie) i poniżej Harmonogram robota, zachowaj częstotliwość ustawioną na Na żądanie. - Dodaj Następna.
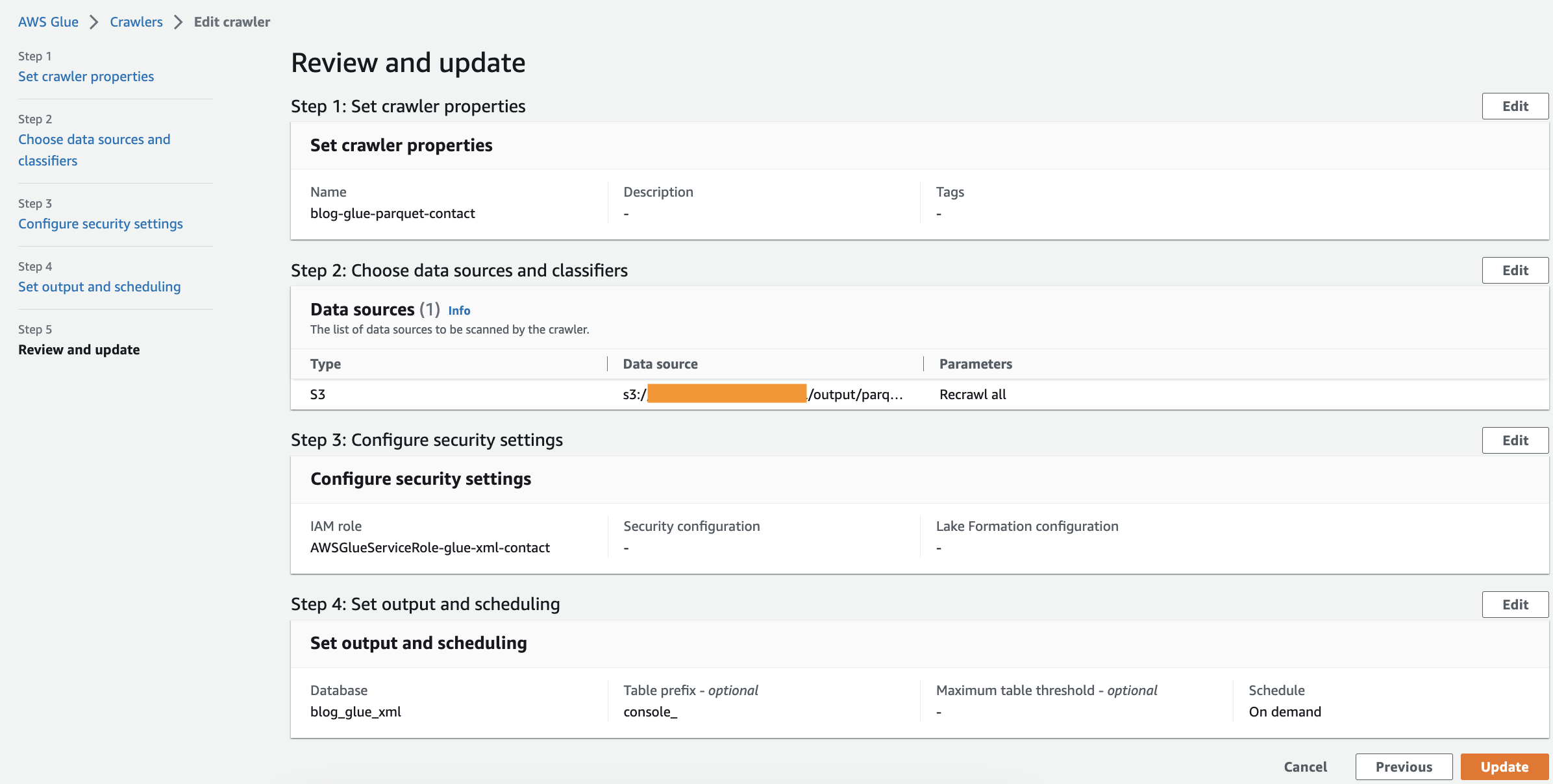
- Przejrzyj wszystkie parametry i wybierz Utwórz robota.
Uruchom robota
Po utworzeniu przeszukiwacza wykonaj następujące kroki, aby go uruchomić:
- Na konsoli AWS Glue wybierz Roboty w okienku nawigacji.
- Otwórz robota, który utworzyłeś i wybierz run.
Ukończenie robota zajmie 1–2 minuty.
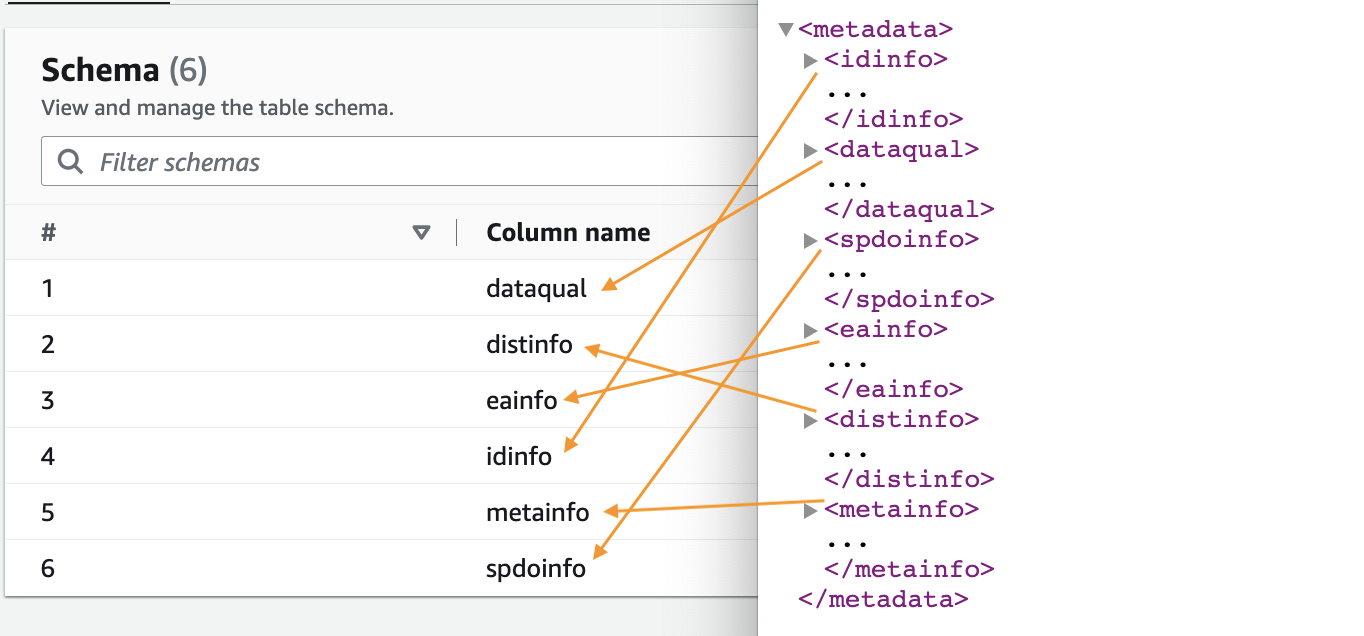
- Po zakończeniu robota wybierz Bazy danych w okienku nawigacji.
- Wybierz utworzoną bazę danych i wybierz nazwę tabeli, aby zobaczyć schemat wyodrębniony przez robota.
Utwórz zadanie klejenia AWS, aby przekonwertować format XML na format parkietu
W tym kroku utworzysz zadanie AWS Glue Studio w celu przekonwertowania pliku XML na plik Parquet. Wykonaj następujące kroki:
- Na konsoli AWS Glue wybierz Oferty pracy w okienku nawigacji.
- Pod Utwórz pracę, Wybierz Wizualne z pustym płótnem.
- Dodaj Stwórz.
- Zmień nazwę zadania na
blog_glue_xml_job.
Teraz masz pusty edytor zadań wizualnych AWS Glue Studio. Na górze edytora znajdują się zakładki różnych widoków.
- Wybierz Scenariusz tab, aby zobaczyć pustą powłokę skryptu AWS Glue ETL.
W miarę dodawania nowych kroków w edytorze wizualnym skrypt będzie aktualizowany automatycznie.
- Wybierz Szczegóły pracy aby wyświetlić wszystkie konfiguracje zadań.
- W razie zamówieenia projektu Rola IAMwybierz
AWSGlueServiceNotebookRoleBlog. - W razie zamówieenia projektu Wersja klejuwybierz Klej 4.0 – obsługa Spark 3.3, Scala 2, Python 3.
- Zestaw Żądana liczba pracowników do 2.
- Zestaw Liczba ponownych prób do 0.
- Wybierz Wizualny aby wrócić do edytora wizualnego.
- Na Źródło wybierz z menu rozwijanego Katalog danych kleju AWS.
- Na Właściwości źródła danych — Data Catalog zakładkę, podaj następujące informacje:
- W razie zamówieenia projektu Baza danychwybierz
blog_glue_xml. - W razie zamówieenia projektu Stół, wybierz tabelę zaczynającą się od nazwy console_ utworzonej przez przeszukiwacza (na przykład
console_geologicalsurvey).
- W razie zamówieenia projektu Baza danychwybierz
- Na Właściwości węzła zakładkę, podaj następujące informacje:
- zmiana Imię do
geologicalsurveyzestaw danych. - Dodaj Działania i transformacja Zmień schemat (Zastosuj mapowanie).
- Dodaj Właściwości węzła i zmień nazwę transformacji z Zmień schemat (Zastosuj mapowanie) na
ApplyMapping. - Na cel menu, wybierz S3.
- zmiana Imię do
- Na Właściwości źródła danych - S3 zakładkę, podaj następujące informacje:
- W razie zamówieenia projektu utworzony, Wybierz Parkiet.
- W razie zamówieenia projektu Rodzaj kompresji, Wybierz Bez kompresji.
- W razie zamówieenia projektu Typ źródła S3, Wybierz Lokalizacja S3.
- W razie zamówieenia projektu URL S3, wchodzić
s3://${BUCKET_NAME}/output/parquet/. - Dodaj Właściwości węzła i zmień nazwę na
Output.
- Dodaj Zapisz aby zapisać pracę.
- Dodaj run do uruchomienia zadania.
Poniższy zrzut ekranu przedstawia zadanie w edytorze wizualnym.
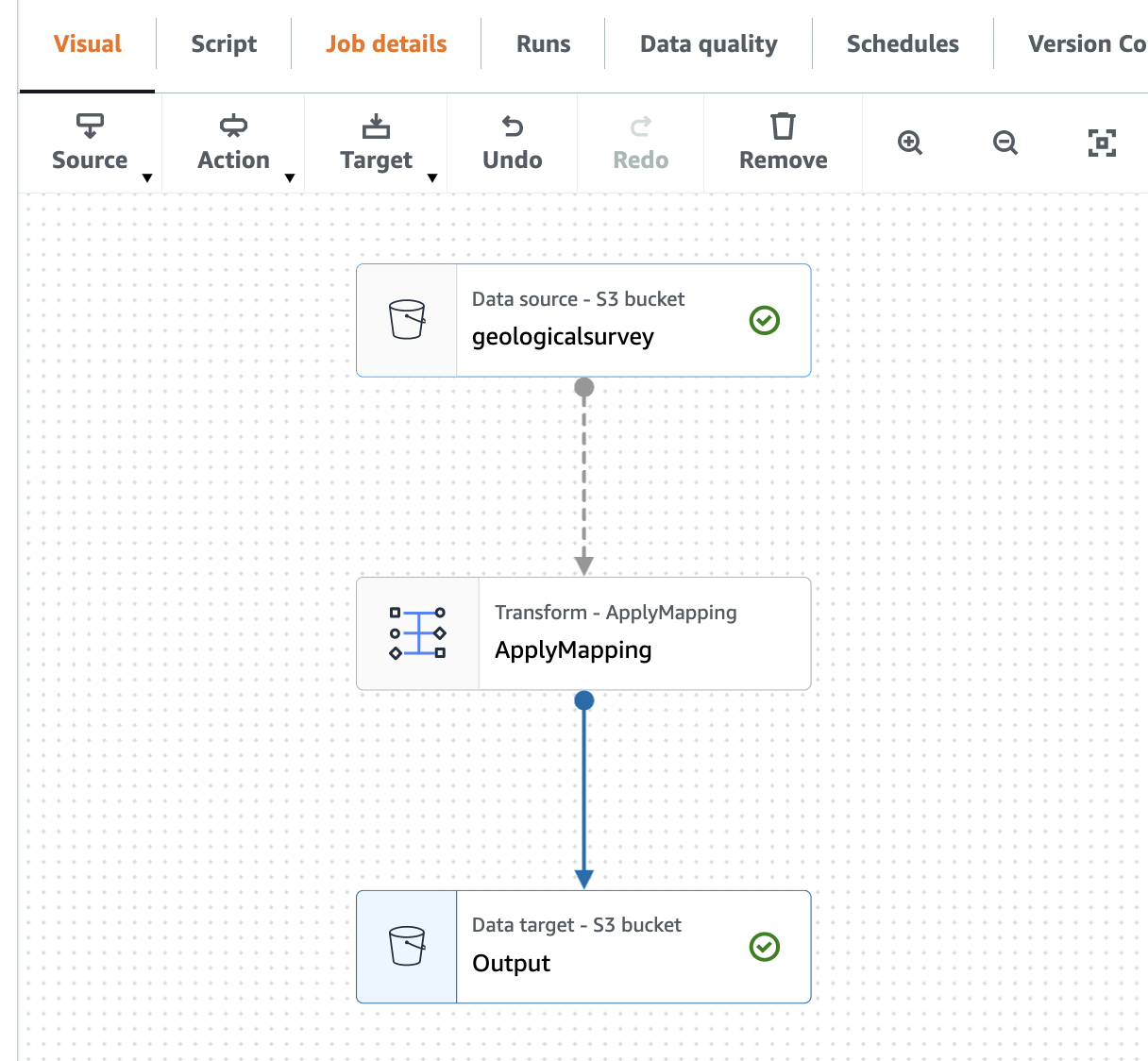
Utwórz przeszukiwacz AWS Gue, aby przeszukać plik Parquet
Na tym etapie utworzysz przeszukiwacz AWS Glue w celu wyodrębnienia metadanych z pliku Parquet utworzonego przy użyciu zadania AWS Glue Studio. Tym razem używasz domyślnego klasyfikatora. Wykonaj następujące kroki:
- Na konsoli AWS Glue wybierz Roboty w okienku nawigacji.
- Dodaj Utwórz robota.
- Na Ustaw właściwości przeszukiwacza stronie, podaj nazwę nowego robota, np. blog-klej-parkiet-kontakt, a następnie wybierz Następna.
- Na Wybierz źródła danych i klasyfikatory strona, wybierz Jeszcze nie dla Konfiguracja źródła danych.
- Dodaj Dodaj magazyn danych.
- W razie zamówieenia projektu Ścieżka S3, przejdź do
s3://${BUCKET_NAME}/output/parquet/.
Upewnij się, że wybrałeś parquet folderze, a nie pliku wewnątrz folderu.
- Wybierz rolę uprawnień utworzoną w sekcji wymagań wstępnych lub wybierz Utwórz nową rolę uprawnień (na przykład,
AWSGlueServiceNotebookRoleBlog) i wybierz Następna. - Na Ustaw wydajność i harmonogram strona, pod Konfiguracja wyjściowawybierz
blog_glue_xmldla Baza danych. - Wchodzę
parquet_jako przedrostek dodawany do tabel (opcjonalnie) i poniżej Harmonogram robota, zachowaj częstotliwość ustawioną na Na żądanie. - Dodaj Następna.
- Przejrzyj wszystkie parametry i wybierz Utwórz robota.
Teraz możesz uruchomić robota, co zajmie 1–2 minuty.

Możesz wyświetlić podgląd nowo utworzonego schematu dla pliku Parquet w katalogu danych kleju AWS, który jest podobny do schematu pliku XML.
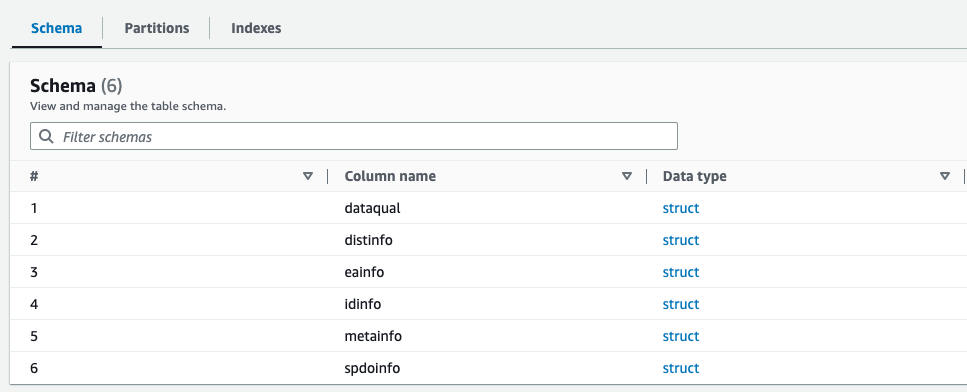
Obecnie posiadamy dane, które nadają się do wykorzystania w systemie Athena. W kolejnej części wykonujemy zapytania o dane za pomocą Atheny.
Zapytanie o plik Parquet przy użyciu narzędzia Athena
Athena nie obsługuje wysyłania zapytań do formacie pliku XML, dlatego też przekonwertowałeś plik XML na format Parquet, aby zapewnić wydajniejsze wykonywanie zapytań o dane i ich wykorzystanie notacja kropkowa do wykonywania zapytań o typy złożone i struktury zagnieżdżone.
Poniższy przykładowy kod używa notacji kropkowej do wykonywania zapytań o zagnieżdżone dane:
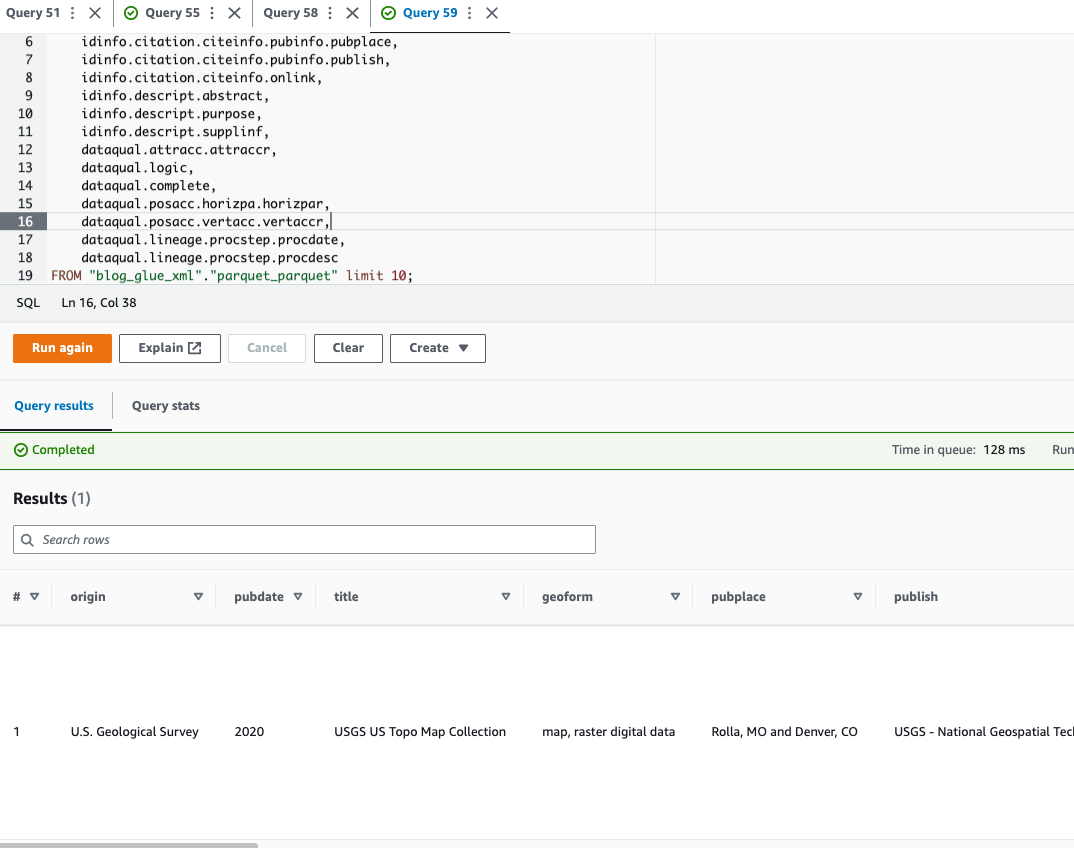
Skoro już ukończyliśmy technikę 1, przejdźmy do nauki techniki 2.
Technika 2: Użyj dynamicznych ramek AWS Glue z wywnioskowanymi i ustalonymi schematami
W poprzedniej sekcji omówiliśmy proces obsługi małego pliku XML przy użyciu przeszukiwacza AWS Glue w celu wygenerowania tabeli, zadania AWS Glue w celu konwersji pliku do formatu Parquet oraz narzędzia Athena w celu uzyskania dostępu do danych Parquet. Jednak przeszukiwacz napotyka ograniczenia w przetwarzaniu plików XML przekraczających Rozmiar 1 MB. W tej sekcji zagłębiamy się w temat przetwarzania wsadowego większych plików XML, wymagającego dodatkowego parsowania w celu wyodrębnienia poszczególnych zdarzeń i przeprowadzenia analizy za pomocą Atheny.
Nasze podejście polega na czytaniu plików XML za pomocą AWS Glue Ramki dynamiczne, wykorzystując zarówno wywnioskowane, jak i ustalone schematy. Następnie wyodrębniamy poszczególne zdarzenia w formacie Parquet za pomocą relacjonowac transformacji, dzięki czemu możemy bezproblemowo odpytywać i analizować je za pomocą Atheny.
Aby wdrożyć to rozwiązanie, wykonaj następujące czynności na wysokim poziomie:
- Utwórz notatnik AWS Glue, aby czytać i analizować plik XML.
- Zastosowanie
DynamicFrameswInferSchemado odczytania pliku XML. - Użyj funkcji relacyjnej, aby rozdzielić dowolne tablice.
- Konwertuj dane do formatu Parquet.
- Zapytaj o dane Parquet za pomocą Atheny.
- Powtórz poprzednie kroki, ale tym razem przekaż schemat do
DynamicFrameszamiast używaćInferSchema.
Plik XML z danymi dotyczącymi populacji pojazdów elektrycznych ma rozszerzenie response tag na poziomie głównym. Ten tag zawiera tablicę row tagi, które są w nim zagnieżdżone. Znacznik wiersza to tablica zawierająca zestaw kolejnych znaczników wiersza, które dostarczają informacji o pojeździe, w tym o jego marce, modelu i innych istotnych szczegółach. Poniższy zrzut ekranu pokazuje przykład.

Utwórz notatnik z klejem AWS
Aby utworzyć notatnik AWS Glue, wykonaj następujące kroki:
- Otwórz Pracownia Kleju AWS konsola, wybierz Oferty pracy w okienku nawigacji.
- Wybierz Notebook Jupyter i wybierz Stwórz.
- Wprowadź nazwę zadania klejenia AWS, np
blog_glue_xml_job_Jupyter. - Wybierz rolę utworzoną w wymaganiach wstępnych (
AWSGlueServiceNotebookRoleBlog).
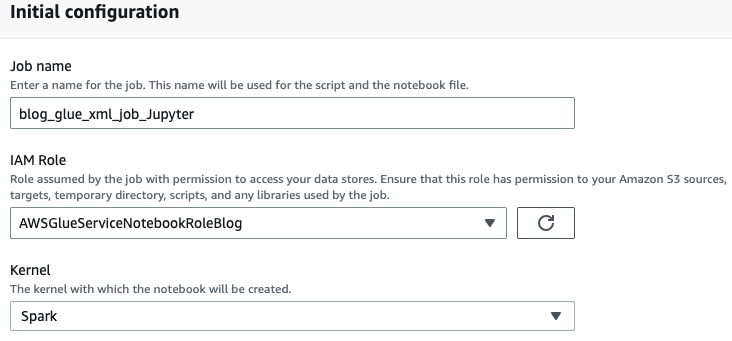
Notatnik AWS Glue zawiera istniejący przykład pokazujący, jak wykonać zapytanie do bazy danych i zapisać dane wyjściowe w Amazon S3.
- Dostosuj limit czasu (w minutach), jak pokazano na poniższym zrzucie ekranu i uruchom komórkę, aby utworzyć interaktywną sesję AWS Glue.
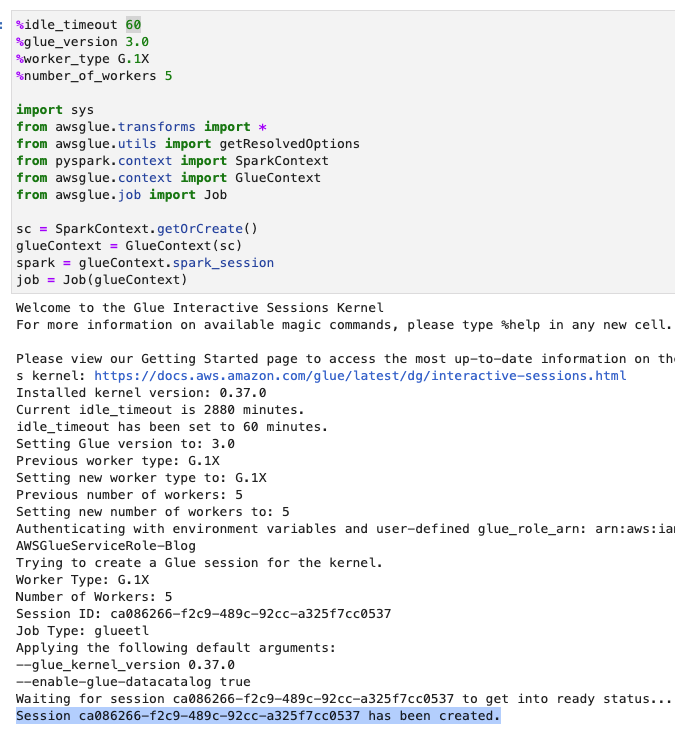
Utwórz podstawowe zmienne
Po utworzeniu sesji interaktywnej na końcu notatnika utwórz nową komórkę z następującymi zmiennymi (podaj własną nazwę segmentu):
Przeczytaj plik XML, na podstawie którego wywnioskowano schemat
Jeśli nie przekażesz schematu do DynamicFrame, wywnioskować będzie schemat plików. Aby odczytać dane za pomocą ramki dynamicznej, możesz użyć następującego polecenia:
Wydrukuj schemat DynamicFrame
Wydrukuj schemat z następującym kodem:
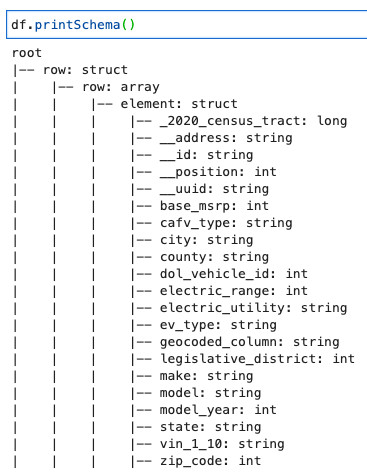
Schemat przedstawia zagnieżdżoną strukturę z a row tablica zawierająca wiele elementów. Aby rozdzielić tę strukturę na linie, możesz użyć kleju AWS relacjonowac transformacja:
Nas interesują tylko informacje zawarte w tablicy wierszy, a schemat możemy obejrzeć za pomocą polecenia:
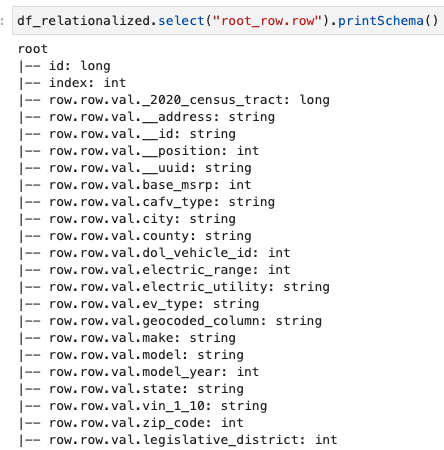
Nazwy kolumn zawierają row.row, które odpowiadają strukturze tablicy i kolumnie tablicy w zbiorze danych. Nie zmieniamy nazw kolumn w tym poście; Aby uzyskać instrukcje, jak to zrobić, zobacz Zautomatyzuj dynamiczne mapowanie i zmianę nazw kolumn w plikach danych za pomocą kleju AWS: część 1. Następnie możesz przekonwertować dane do formatu Parquet i utworzyć tabelę kleju AWS za pomocą następującego polecenia:
Klej AWS DynamicFrame udostępnia funkcje, których można używać w skrypcie ETL do tworzenia i aktualizowania schematu w wykazie danych. Używamy updateBehavior parametr, aby utworzyć tabelę bezpośrednio w katalogu danych. Dzięki takiemu podejściu nie musimy uruchamiać przeszukiwacza AWS Glue po zakończeniu zadania AWS Glue.

Przeczytaj plik XML, ustawiając schemat
Alternatywnym sposobem odczytania pliku jest wstępne zdefiniowanie schematu. Aby to zrobić, wykonaj następujące kroki:
- Zaimportuj typy danych AWS Glue:
- Utwórz schemat dla pliku XML:
- Przekaż schemat podczas odczytu pliku XML:
- Rozgnieć zbiór danych jak poprzednio:
- Konwertuj zbiór danych na Parquet i utwórz tabelę kleju AWS:
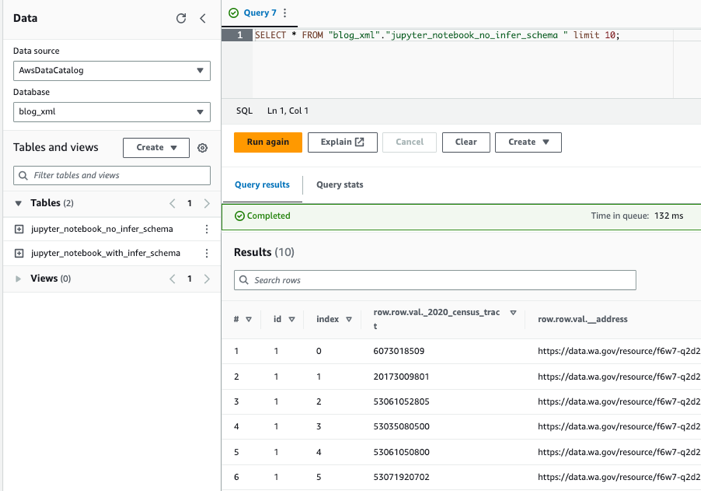
Zapytaj o tabele za pomocą narzędzia Athena
Teraz, gdy utworzyliśmy obie tabele, możemy wysyłać do nich zapytania za pomocą narzędzia Athena. Na przykład możemy użyć następującego zapytania:
Sprzątać
W tym poście utworzyliśmy rolę IAM, notatnik AWS Glue Jupyter i dwie tabele w katalogu danych kleju AWS. Przesłaliśmy także kilka plików do wiadra S3. Aby oczyścić te obiekty, wykonaj następujące kroki:
- W konsoli IAM usuń utworzoną rolę.
- W konsoli AWS Glue Studio usuń niestandardowy klasyfikator, przeszukiwacz, zadania ETL i notatnik Jupyter.
- Przejdź do katalogu danych kleju AWS i usuń utworzone tabele.
- Na konsoli Amazon S3 przejdź do utworzonego zasobnika i usuń nazwane foldery
temp,infer_schema,no_infer_schema.
Na wynos
W AWS Glue dostępna jest funkcja o nazwie InferSchema w kleju AWS DynamicFrames. Automatycznie określa strukturę ramki danych na podstawie zawartych w niej danych. Natomiast zdefiniowanie schematu oznacza wyraźne określenie, jaka powinna być struktura ramki danych przed załadowaniem danych.
XML, będący formatem tekstowym, nie ogranicza typów danych swoich kolumn. Może to powodować problemy z funkcją InferSchema. Na przykład w pierwszym uruchomieniu plik z kolumną A o wartości 2 daje w wyniku plik Parquet z kolumną A jako liczbą całkowitą. W drugim przebiegu nowy plik ma kolumnę A o wartości C, co prowadzi do pliku Parquet z kolumną A jako ciągiem znaków. Teraz na S3 znajdują się dwa pliki, każdy z kolumną A zawierającą różne typy danych, co może powodować problemy w dalszej części.
To samo dzieje się ze złożonymi typami danych, takimi jak struktury zagnieżdżone lub tablice. Na przykład, jeśli plik ma jeden wpis znacznika, tzw transaction, jest to wywnioskowane jako struktura. Ale jeśli inny plik ma ten sam znacznik, jest on uznawany za tablicę
Pomimo tych problemów z typami danych, InferSchema jest przydatne, gdy nie znasz schematu lub ręczne zdefiniowanie go jest niepraktyczne. Nie jest to jednak idealne rozwiązanie w przypadku dużych lub stale zmieniających się zbiorów danych. Definiowanie schematu jest bardziej precyzyjne, szczególnie w przypadku złożonych typów danych, ale wiąże się z pewnymi problemami, takimi jak konieczność ręcznego działania i brak elastyczności w przypadku zmian danych.
InferSchema ma ograniczenia, takie jak nieprawidłowe wnioskowanie o typie danych i problemy z obsługą wartości null. Definiowanie schematu ma również ograniczenia, takie jak wysiłek ręczny i potencjalne błędy.
Wybór pomiędzy wnioskowaniem a definiowaniem schematu zależy od potrzeb projektu. InferSchema doskonale nadaje się do szybkiej eksploracji małych zbiorów danych, natomiast zdefiniowanie schematu jest lepsze w przypadku większych, złożonych zbiorów danych wymagających dokładności i spójności. Rozważ kompromisy i ograniczenia każdej metody, aby wybrać tę, która najlepiej pasuje do Twojego projektu.
Wnioski
W tym poście omówiliśmy dwie techniki zarządzania danymi XML za pomocą AWS Glue, każdą dostosowaną do konkretnych potrzeb i wyzwań, jakie możesz napotkać.
Technika 1 oferuje przyjazną dla użytkownika ścieżkę dla tych, którzy preferują interfejs graficzny. Możesz użyć przeszukiwacza AWS Glue i edytora wizualnego, aby bez wysiłku zdefiniować strukturę tabeli dla plików XML. Takie podejście upraszcza proces zarządzania danymi i jest szczególnie atrakcyjne dla tych, którzy szukają prostego sposobu obsługi swoich danych.
Jednakże zdajemy sobie sprawę, że przeszukiwacz ma swoje ograniczenia, szczególnie w przypadku plików XML zawierających wiersze większe niż 1 MB. Tutaj na ratunek przychodzi technika 2. Wykorzystując klej AWS DynamicFrames zarówno z wywnioskowanymi, jak i ustalonymi schematami oraz przy użyciu notatnika AWS Glue, możesz wydajnie obsługiwać pliki XML o dowolnym rozmiarze. Ta metoda zapewnia solidne rozwiązanie, które zapewnia płynne przetwarzanie nawet plików XML z wierszami przekraczającymi ograniczenie 1 MB.
Gdy poruszasz się po świecie zarządzania danymi, posiadanie tych technik w swoim zestawie narzędzi umożliwia podejmowanie świadomych decyzji w oparciu o konkretne wymagania Twojego projektu. Niezależnie od tego, czy wolisz prostotę techniki 1, czy skalowalność techniki 2, AWS Glue zapewnia elastyczność potrzebną do efektywnej obsługi danych XML.
O autorach
 Navnit Shuklapełni funkcję Specjalistycznego Architekta Rozwiązań AWS ze szczególnym uwzględnieniem Analityki. Z wielkim entuzjazmem pomaga klientom w odkrywaniu cennych wniosków z ich danych. Dzięki swojej wiedzy specjalistycznej konstruuje innowacyjne rozwiązania, które umożliwiają przedsiębiorstwom dokonywanie świadomych wyborów opartych na danych. Warto zauważyć, że Navnit Shukla jest znakomitym autorem książki zatytułowanej „Data Wrangling on AWS.
Navnit Shuklapełni funkcję Specjalistycznego Architekta Rozwiązań AWS ze szczególnym uwzględnieniem Analityki. Z wielkim entuzjazmem pomaga klientom w odkrywaniu cennych wniosków z ich danych. Dzięki swojej wiedzy specjalistycznej konstruuje innowacyjne rozwiązania, które umożliwiają przedsiębiorstwom dokonywanie świadomych wyborów opartych na danych. Warto zauważyć, że Navnit Shukla jest znakomitym autorem książki zatytułowanej „Data Wrangling on AWS.
 Patricka Mullera pracuje jako starszy architekt laboratorium danych w AWS. Do jego głównych obowiązków należy pomaganie klientom w przekształcaniu ich pomysłów w produkt danych gotowy do produkcji. W wolnym czasie Patrick lubi grać w piłkę nożną, oglądać filmy i podróżować.
Patricka Mullera pracuje jako starszy architekt laboratorium danych w AWS. Do jego głównych obowiązków należy pomaganie klientom w przekształcaniu ich pomysłów w produkt danych gotowy do produkcji. W wolnym czasie Patrick lubi grać w piłkę nożną, oglądać filmy i podróżować.
 Amogha Gaikwada jest starszym programistą rozwiązań w Amazon Web Services. Pomaga klientom na całym świecie budować i wdrażać rozwiązania AI/ML na AWS. Jego praca koncentruje się głównie na obrazowaniu komputerowym i przetwarzaniu języka naturalnego oraz pomaganiu klientom w optymalizacji obciążeń AI/ML pod kątem zrównoważonego rozwoju. Amogh uzyskał tytuł magistra informatyki ze specjalizacją w uczeniu maszynowym.
Amogha Gaikwada jest starszym programistą rozwiązań w Amazon Web Services. Pomaga klientom na całym świecie budować i wdrażać rozwiązania AI/ML na AWS. Jego praca koncentruje się głównie na obrazowaniu komputerowym i przetwarzaniu języka naturalnego oraz pomaganiu klientom w optymalizacji obciążeń AI/ML pod kątem zrównoważonego rozwoju. Amogh uzyskał tytuł magistra informatyki ze specjalizacją w uczeniu maszynowym.
 Sheela Sonone jest starszym architektem-rezydentem w AWS. Pomaga klientom AWS w dokonywaniu świadomych wyborów i kompromisów w zakresie przyspieszania ich danych, analiz oraz obciążeń i wdrożeń AI/ML. Wolny czas lubi spędzać z rodziną – najczęściej na kortach tenisowych.
Sheela Sonone jest starszym architektem-rezydentem w AWS. Pomaga klientom AWS w dokonywaniu świadomych wyborów i kompromisów w zakresie przyspieszania ich danych, analiz oraz obciążeń i wdrożeń AI/ML. Wolny czas lubi spędzać z rodziną – najczęściej na kortach tenisowych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- O nas
- ABSTRACT
- przyspieszenie
- dostęp
- dostępność
- realizowane
- precyzja
- w poprzek
- Działania
- Dodaj
- w dodatku
- Dodatkowy
- adres
- Po
- wiek
- AI / ML
- Wszystkie kategorie
- dopuszczać
- Pozwalać
- pozwala
- również
- alternatywny
- Amazonka
- Amazonka Atena
- Amazon Web Services
- an
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- Inne
- każdy
- Apache
- pociągający
- aplikacje
- Aplikuj
- podejście
- awanse
- architektura
- SĄ
- Szyk
- AS
- pomagać
- pomoc
- At
- autor
- automatycznie
- dostępny
- AWS
- Klej AWS
- z powrotem
- na podstawie
- podstawowy
- BE
- bo
- zanim
- rozpocząć
- jest
- BEST
- Ulepsz Swój
- pomiędzy
- pusty
- książka
- obie
- budować
- biznes
- ale
- by
- nazywa
- CAN
- katalog
- Spowodować
- komórka
- wyzwania
- zmiana
- Zmiany
- wymiana pieniędzy
- wybory
- Dodaj
- Miasto
- klasyfikacja
- klientów
- kod
- Kolumna
- kolumny
- COM
- byliśmy spójni, od początku
- wspólny
- powszechnie
- kompletny
- Zakończony
- kompleks
- komputer
- Computer Science
- Wizja komputerowa
- warunek
- Prowadzenie
- spójnik
- Rozważać
- Konsola
- stale
- Ograniczenia
- skonstruować
- zawierać
- zawarte
- zawiera
- kontrast
- kontrola
- konwertować
- przeliczone
- opłacalne
- ekonomiczne rozwiązanie
- hrabstwo
- Sądy
- pokryty
- crawler
- Stwórz
- stworzony
- Tworzenie
- istotny
- zwyczaj
- klient
- Klientów
- dane
- integracja danych
- zarządzanie danymi
- sterowane danymi
- Baza danych
- zbiory danych
- czynienia
- Decyzje
- Domyślnie
- określić
- definiowanie
- sięgać
- demonstruje
- zależy
- rozwijać
- zaprojektowany
- szczegółowe
- detale
- Deweloper
- różne
- trudny
- cyfrowy
- Era cyfrowa
- bezpośrednio
- odkrywanie
- odrębny
- do
- Nie
- zrobić
- nie
- DOT
- podczas
- dynamiczny
- każdy
- łatwość
- z łatwością
- łatwo
- redaktor
- efekt
- faktycznie
- efektywność
- wydajny
- skutecznie
- wysiłek
- bez wysiłku
- elektryczny
- pojazd elektryczny
- Elementy
- zatrudniający
- upoważniać
- upoważnia
- pusty
- umożliwiać
- umożliwiając
- spotkanie
- zakończenia
- silniki
- wzmacniać
- zapewnić
- zapewnia
- Wchodzę
- entuzjazm
- wejście
- Błędy
- szczególnie
- Eter (ETH)
- Parzyste
- wydarzenia
- Każdy
- przykład
- przekraczać
- wymiana
- ekspertyza
- eksploracja
- odkryj
- zbadane
- wyciąg
- ekstrakcja
- członków Twojej rodziny
- Cecha
- Korzyści
- Postacie
- filet
- Akta
- finansować
- i terminów, a
- ustalony
- Elastyczność
- Skupiać
- koncentruje
- następujący
- W razie zamówieenia projektu
- format
- FRAME
- Darmowy
- Częstotliwość
- od
- funkcjonować
- Wzrost
- ogólny cel
- Generować
- Globalne
- Go
- cel
- Rząd
- wspaniały
- uchwyt
- Prowadzenie
- dzieje
- Wykorzystywanie
- Have
- mający
- he
- opieki zdrowotnej
- Serce
- pomoc
- pomoc
- pomaga
- jej
- na wysokim szczeblu
- wysoko
- jego
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- IAM
- idealny
- pomysły
- tożsamość
- if
- ilustruje
- wdrożenia
- wdrożenia
- wykonawczych
- importować
- podnieść
- ulepszony
- in
- Włącznie z
- indywidualny
- osób
- przemysłowa
- Informacja
- poinformowany
- Infrastruktura
- Innowacyjny
- wewnątrz
- spostrzeżenia
- zamiast
- instrukcje
- integrować
- integracja
- interaktywne
- zainteresowany
- Interfejs
- najnowszych
- dotyczy
- problemy
- IT
- JEGO
- Praca
- Oferty pracy
- jpg
- json
- Notebook Jupyter
- Trzymać
- Wiedzieć
- laboratorium
- język
- duży
- większe
- prowadzący
- UCZYĆ SIĘ
- nauka
- poziom
- lubić
- LIMIT
- ograniczenie
- Ograniczenia
- Linia
- linie
- załadować
- załadunek
- logika
- poszukuje
- maszyna
- uczenie maszynowe
- Główny
- głównie
- robić
- Dokonywanie
- i konserwacjami
- zarządzający
- podręcznik
- ręcznie
- wiele
- mapowanie
- mistrzowski
- Może..
- znaczy
- Menu
- Metadane
- metoda
- minuty
- model
- jeszcze
- bardziej wydajny
- większość
- ruch
- Kino
- wielokrotność
- Nazwa
- O imieniu
- Nazwy
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Nawigacja
- Nawigacja
- niezbędny
- Potrzebować
- wymagania
- Nowości
- nowo
- Następny
- szczególnie
- notatnik
- już dziś
- numer
- obiekty
- of
- Oferty
- on
- ONE
- tylko
- operacje
- Optymalny
- Optymalizacja
- Optymalizuje
- Opcje
- or
- zamówienie
- organizacji
- Origin
- Inne
- ludzkiej,
- na zewnątrz
- wydajność
- koniec
- Przezwyciężać
- własny
- strona
- chleb
- parametr
- parametry
- część
- szczególnie
- przechodzić
- ścieżka
- Patrick
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uprawnienia
- wybierać
- plato
- Analiza danych Platona
- PlatoDane
- gra
- polityka
- populacja
- posiadać
- Post
- potencjał
- precyzyjny
- woleć
- warunki wstępne
- Podgląd
- poprzedni
- problemy
- wygląda tak
- obrobiony
- przetwarzanie
- Produkt
- projekt
- projektowanie
- niska zabudowa
- zapewniać
- zapewnia
- publikować
- cel
- Python
- zapytania
- Szybki
- raczej
- Czytaj
- łatwo
- Czytający
- Przyczyny
- Odebrane
- rozpoznać
- odnosić się
- wymagania
- ratowanie
- Zasób
- odpowiedź
- odpowiedzialność
- REST
- ograniczać
- ograniczenie
- Efekt
- krzepki
- Rola
- korzeń
- RZĄD
- run
- taki sam
- Zapisz
- Scala
- Skalowalność
- skalowalny
- nauka
- scenariusz
- bezszwowy
- płynnie
- druga
- Sekcja
- widzieć
- senior
- Usługi
- Sesja
- zestaw
- ustawienie
- kilka
- ona
- Powłoka
- powinien
- pokazać
- pokazane
- Targi
- podobny
- Prosty
- prostota
- upraszczanie
- pojedynczy
- Rozmiar
- mały
- So
- Piłka nożna
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Źródła
- Iskra
- specjalista
- specjalizujący się
- specyficzny
- swoiście
- prędkość
- Spędzanie
- SQL
- standard
- rozpocznie
- Stan
- Zestawienie sprzedaży
- stwierdzając
- Ewolucja krok po kroku
- Cel
- przechowywanie
- przechowywany
- bezpośredni
- opływowy
- sznur
- silny
- Struktura
- Struktury
- studio
- sukces
- taki
- odpowiedni
- wsparcie
- pewnie
- Zrównoważony rozwój
- systemy
- stół
- TAG
- dostosowane
- Brać
- trwa
- zadania
- Techniki
- tenis
- niż
- że
- Połączenia
- Informacje
- świat
- ich
- Im
- następnie
- Tam.
- Te
- one
- to
- tych
- Przez
- czas
- Tytuł
- pod tytulem
- do
- dzisiaj
- Zestaw narzędzi
- Top
- aktualny
- Przekształcać
- Transformacja
- Podróżowanie
- Obrócenie
- Tutorial
- drugiej
- rodzaj
- typy
- ostateczny
- dla
- Aktualizacja
- zaktualizowane
- przesłanych
- us
- użyteczność
- posługiwać się
- używany
- Użytkownik
- Interfejs użytkownika
- łatwy w obsłudze
- zastosowania
- za pomocą
- zazwyczaj
- Wykorzystując
- Cenny
- wartość
- Wartości
- pojazd
- wersja
- przez
- Zobacz i wysłuchaj
- widoki
- wizja
- oglądania
- Droga..
- we
- sieć
- usługi internetowe
- Co
- jeśli chodzi o komunikację i motywację
- natomiast
- czy
- który
- KIM
- dlaczego
- będzie
- w
- w ciągu
- bez
- Praca
- workflow
- przepływów pracy
- działa
- świat
- napisać
- XML
- ty
- Twój
- zefirnet