Sponsorowane post

Wyzwania związane z budowaniem modeli multimodalnych od podstaw
W przypadku wielu przypadków użycia uczenia maszynowego organizacje polegają wyłącznie na danych tabelarycznych i modelach opartych na drzewach, takich jak XGBoost i LightGBM. Dzieje się tak, ponieważ głębokie uczenie się jest po prostu zbyt trudne dla większości zespołów ML. Typowe wyzwania obejmują:
- Brak wiedzy eksperckiej potrzebnej do opracowania złożonych modeli głębokiego uczenia
- Frameworki takie jak PyTorch i Tensorflow wymagają od zespołów napisania tysięcy wierszy kodu, który jest podatny na błędy ludzkie
- Szkolenie rozproszonych potoków DL wymaga głębokiej wiedzy na temat infrastruktury, a trenowanie modeli może zająć tygodnie
W rezultacie zespoły tracą cenne sygnały ukryte w nieustrukturyzowanych danych, takich jak tekst i obrazy.
Szybkie tworzenie modeli z systemami deklaratywnymi
Nowe deklaratywne systemy uczenia maszynowego — takie jak open-source, które Ludwig rozpoczął w firmie Uber — oferują niskokodowe podejście do automatyzacji uczenia maszynowego, które umożliwia zespołom danych szybsze tworzenie i wdrażanie najnowocześniejszych modeli za pomocą prostego pliku konfiguracyjnego. W szczególności Predibase — wiodąca deklaratywna platforma ML o niskim kodzie — wraz z Ludwigiem ułatwiają tworzenie multimodalnych modeli głębokiego uczenia się w mniej niż 15 liniach kodu.
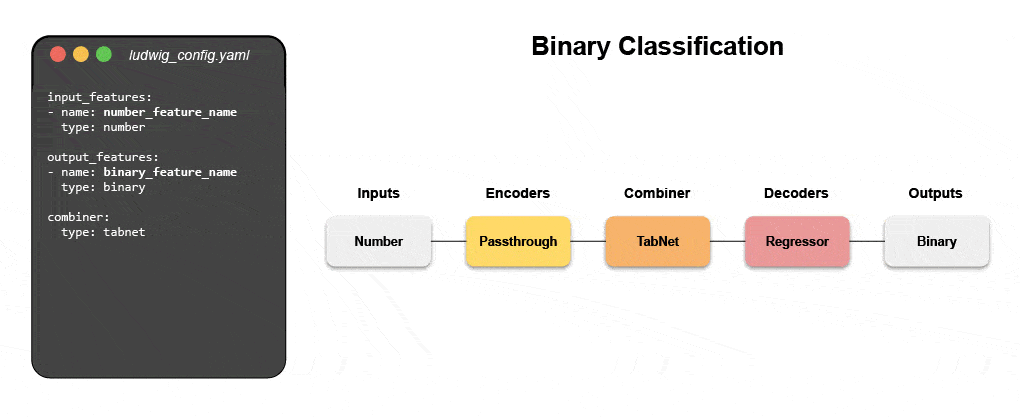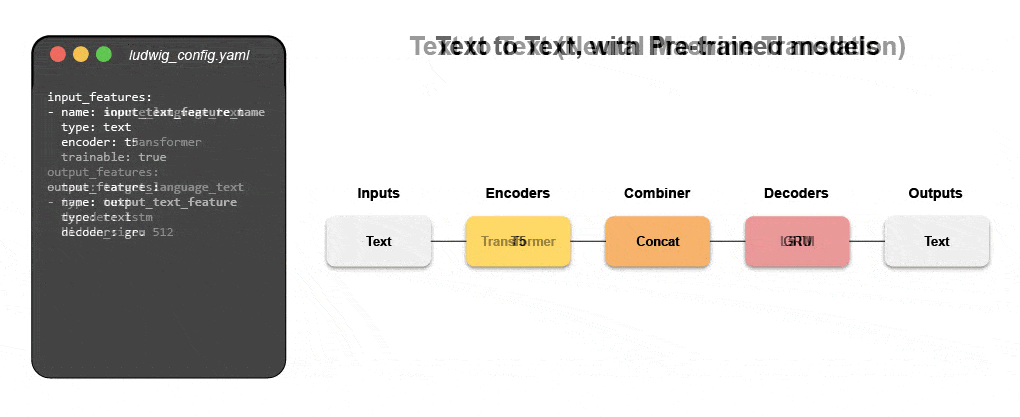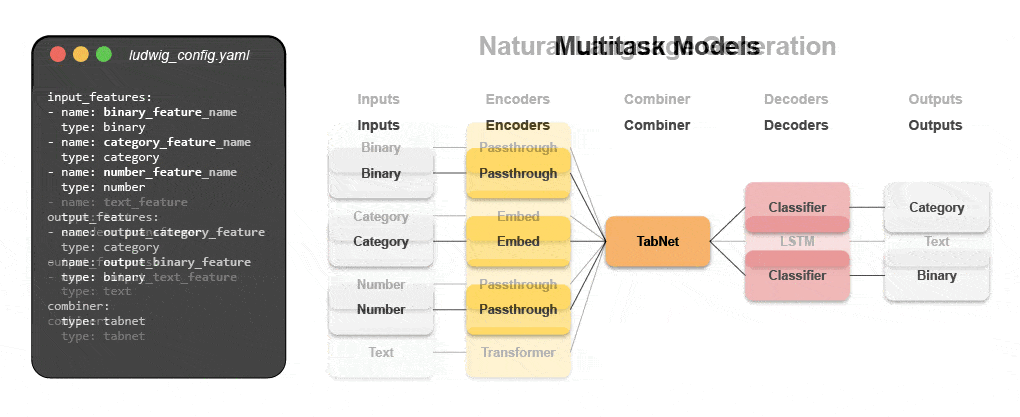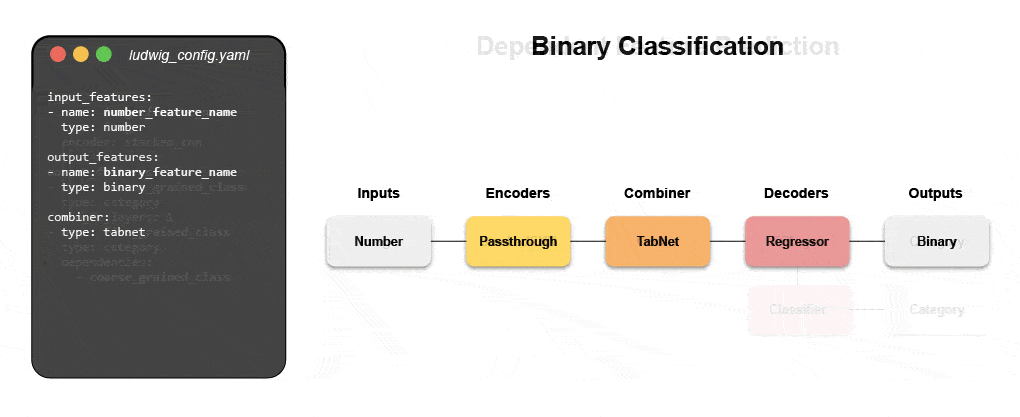
Dowiedz się, jak zbudować multimodalny model za pomocą deklaratywnego uczenia maszynowego
Dołącz do naszego nadchodzącego webinarium i samouczek na żywo, aby dowiedzieć się o systemach deklaratywnych, takich jak Ludwig, i postępuj zgodnie z instrukcjami krok po kroku, aby zbudować multimodalny model prognozowania opinii klientów, wykorzystujący dane tekstowe i tabelaryczne.
Na tej sesji dowiesz się jak:
- Błyskawicznie trenuj, iteruj i wdrażaj multimodalny model prognozowania recenzji klientów,
- Używaj niskokodowych deklaratywnych narzędzi ML, aby radykalnie skrócić czas potrzebny do zbudowania wielu modeli ML,
- Wykorzystaj dane nieustrukturyzowane równie łatwo, jak dane ustrukturyzowane, korzystając z oprogramowania typu open source Ludwig i Predibase
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- O nas
- i
- podejście
- automatyzacja
- bo
- budować
- Budowanie
- wyzwania
- kod
- wspólny
- kompleks
- systemu
- klient
- dane
- głęboko
- głęboka nauka
- rozwijać
- rozwijać
- oprogramowania
- dystrybuowane
- dramatycznie
- z łatwością
- Umożliwia
- błąd
- ekspert
- szybciej
- filet
- obserwuj
- od
- gif
- Ciężko
- Ukryty
- W jaki sposób
- How To
- HTML
- HTTPS
- człowiek
- zdjęcia
- in
- zawierać
- Infrastruktura
- instrukcje
- IT
- Knuggety
- wiedza
- prowadzący
- UCZYĆ SIĘ
- nauka
- lewarowanie
- linie
- relacja na żywo
- maszyna
- uczenie maszynowe
- robić
- wiele
- ML
- model
- modele
- większość
- wielokrotność
- potrzebne
- open source
- organizacji
- plato
- Analiza danych Platona
- PlatoDane
- przepowiednia
- Przewidywania
- płomień
- zmniejszyć
- wymagać
- Wymaga
- dalsze
- przeglądu
- Sesja
- Sygnały
- Prosty
- po prostu
- swoiście
- rozpoczęty
- state-of-the-art
- Ewolucja krok po kroku
- zbudowany
- systemy
- Brać
- trwa
- Zespoły
- tensorflow
- Połączenia
- tysiące
- czas
- do
- także
- narzędzia
- Pociąg
- Tutorial
- zbliżających
- przypadków użycia
- Cenny
- tygodni
- będzie
- w ciągu
- napisać
- XGBoost
- Twój
- zefirnet





