Jednym z najbardziej przydatnych wzorców aplikacji do generatywnych obciążeń AI jest generowanie rozszerzone pobierania (RAG). We wzorcu RAG znajdujemy fragmenty treści referencyjnych powiązane z monitem wejściowym, przeprowadzając wyszukiwanie podobieństw w osadzeniu. Osadzanie przechwytuje zawartość informacyjną w treści tekstu, umożliwiając modelom przetwarzania języka naturalnego (NLP) pracę z językiem w formie numerycznej. Osadzenia to po prostu wektory liczb zmiennoprzecinkowych, więc możemy je przeanalizować, aby odpowiedzieć na trzy ważne pytania: Czy nasze dane referencyjne zmieniają się w czasie? Czy pytania zadawane przez użytkowników zmieniają się z biegiem czasu? I wreszcie, jak dobrze nasze dane referencyjne obejmują zadawane pytania?
W tym poście dowiesz się o niektórych zagadnieniach związanych z analizą wektorową osadzania i wykrywaniem sygnałów dryfu osadzania. Ponieważ osadzania są ważnym źródłem danych dla modeli NLP w ogóle, a w szczególności dla generatywnych rozwiązań AI, potrzebujemy sposobu na zmierzenie, czy nasze osadzania zmieniają się w czasie (dryfowanie). W tym poście zobaczysz przykład wykrywania dryftu na wektorach osadzających przy użyciu techniki grupowania z dużymi modelami językowymi (LLMS) wdrożonymi z Amazon SageMaker JumpStart. Będziesz także mógł poznać te koncepcje za pomocą dwóch dostarczonych przykładów, w tym kompleksowej przykładowej aplikacji lub, opcjonalnie, podzbioru aplikacji.
Przegląd RAG
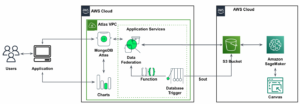
Połączenia Wzór RAG umożliwia pobieranie wiedzy ze źródeł zewnętrznych, takich jak dokumenty PDF, artykuły wiki lub transkrypcje rozmów, a następnie wykorzystanie tej wiedzy do uzupełnienia monitu z instrukcjami wysyłanego do LLM. Dzięki temu LLM może odwoływać się do bardziej istotnych informacji podczas generowania odpowiedzi. Na przykład, jeśli zapytasz LLM, jak zrobić ciasteczka z kawałkami czekolady, może zawierać informacje z Twojej własnej biblioteki przepisów. W tym wzorcu tekst przepisu jest konwertowany na wektory osadzania przy użyciu modelu osadzania i przechowywany w bazie danych wektorów. Przychodzące pytania są konwertowane na osadzania, a następnie baza danych wektorów przeprowadza wyszukiwanie podobieństw w celu znalezienia powiązanych treści. Pytanie i dane referencyjne następnie trafiają do zachęty dla LLM.
Przyjrzyjmy się bliżej tworzonym wektorom osadzania i sposobom przeprowadzenia analizy dryfu na tych wektorach.
Analiza wektorów osadzania
Wektory osadzania to numeryczne reprezentacje naszych danych, więc analiza tych wektorów może zapewnić wgląd w nasze dane referencyjne, które można później wykorzystać do wykrycia potencjalnych sygnałów dryfu. Wektory osadzania reprezentują element w przestrzeni n-wymiarowej, gdzie n jest często duże. Na przykład model GPT-J 6B użyty w tym poście tworzy wektory o rozmiarze 4096. Aby zmierzyć dryf, załóżmy, że nasza aplikacja przechwytuje wektory osadzania zarówno dla danych referencyjnych, jak i przychodzących podpowiedzi.
Zaczynamy od przeprowadzenia redukcji wymiarów za pomocą analizy głównych składowych (PCA). PCA stara się zmniejszyć liczbę wymiarów, zachowując jednocześnie większość wariancji w danych. W tym przypadku staramy się znaleźć liczbę wymiarów, która zachowuje 95% wariancji, co powinno ująć wszystko w granicach dwóch odchyleń standardowych.
Następnie używamy K-średnich do identyfikacji zestawu centrów klastrów. K-Średnie próbują grupować punkty w skupienia, tak aby każdy klaster był stosunkowo zwarty, a klastry były jak najbardziej od siebie oddalone.
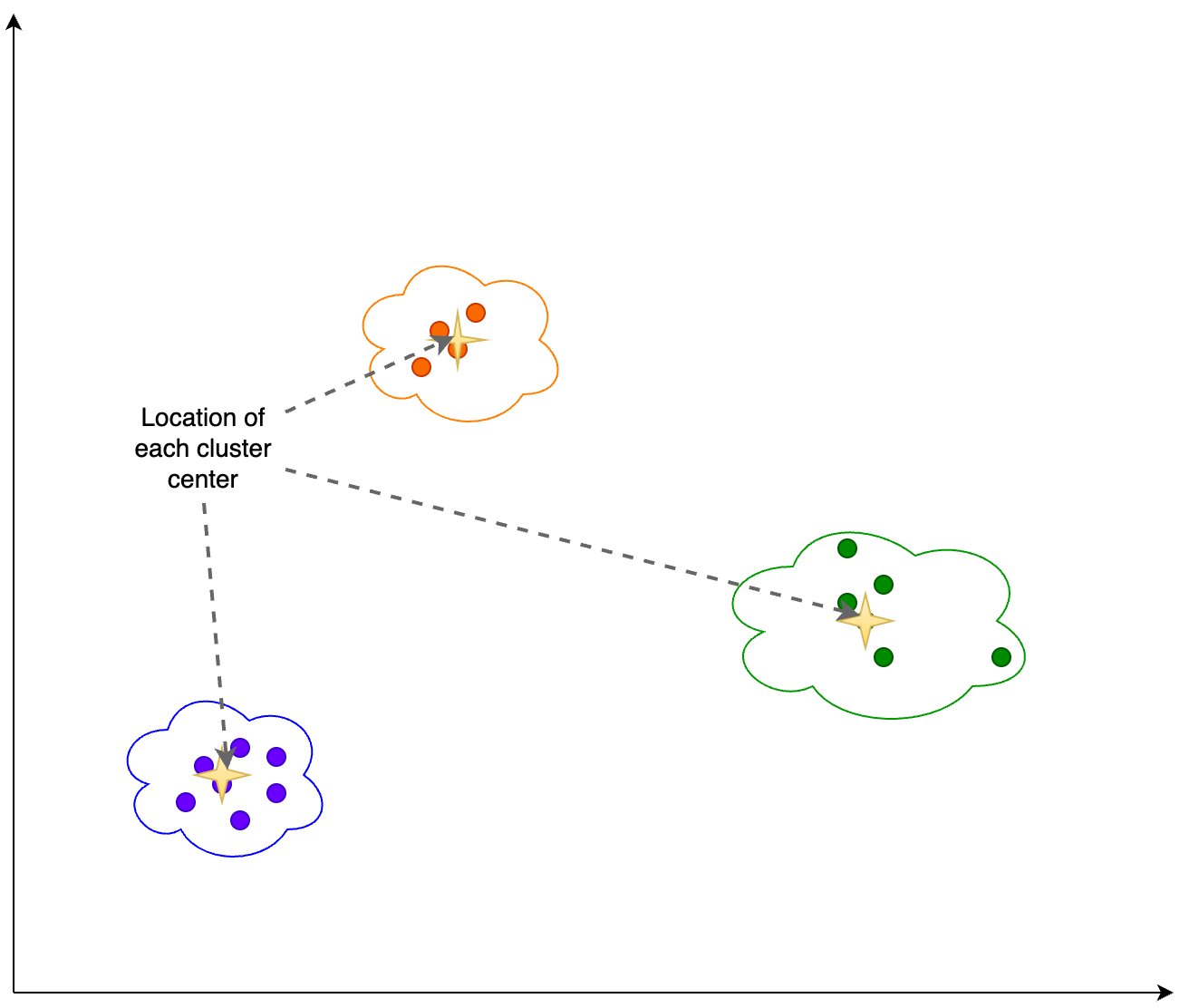
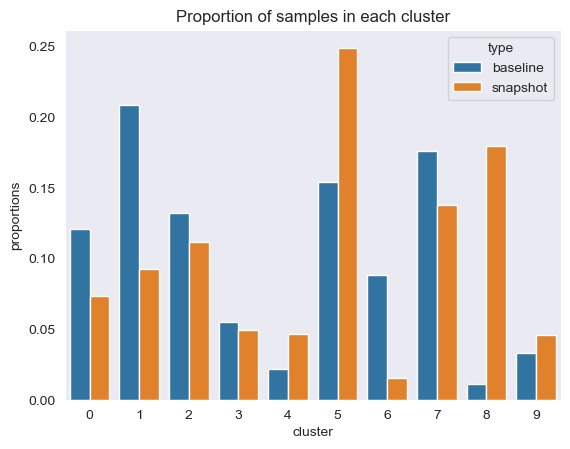
Obliczamy następujące informacje na podstawie wyników grupowania pokazanych na poniższym rysunku:
- Liczba wymiarów w PCA, które wyjaśniają 95% wariancji
- Lokalizacja każdego środka skupienia, czyli środka ciężkości
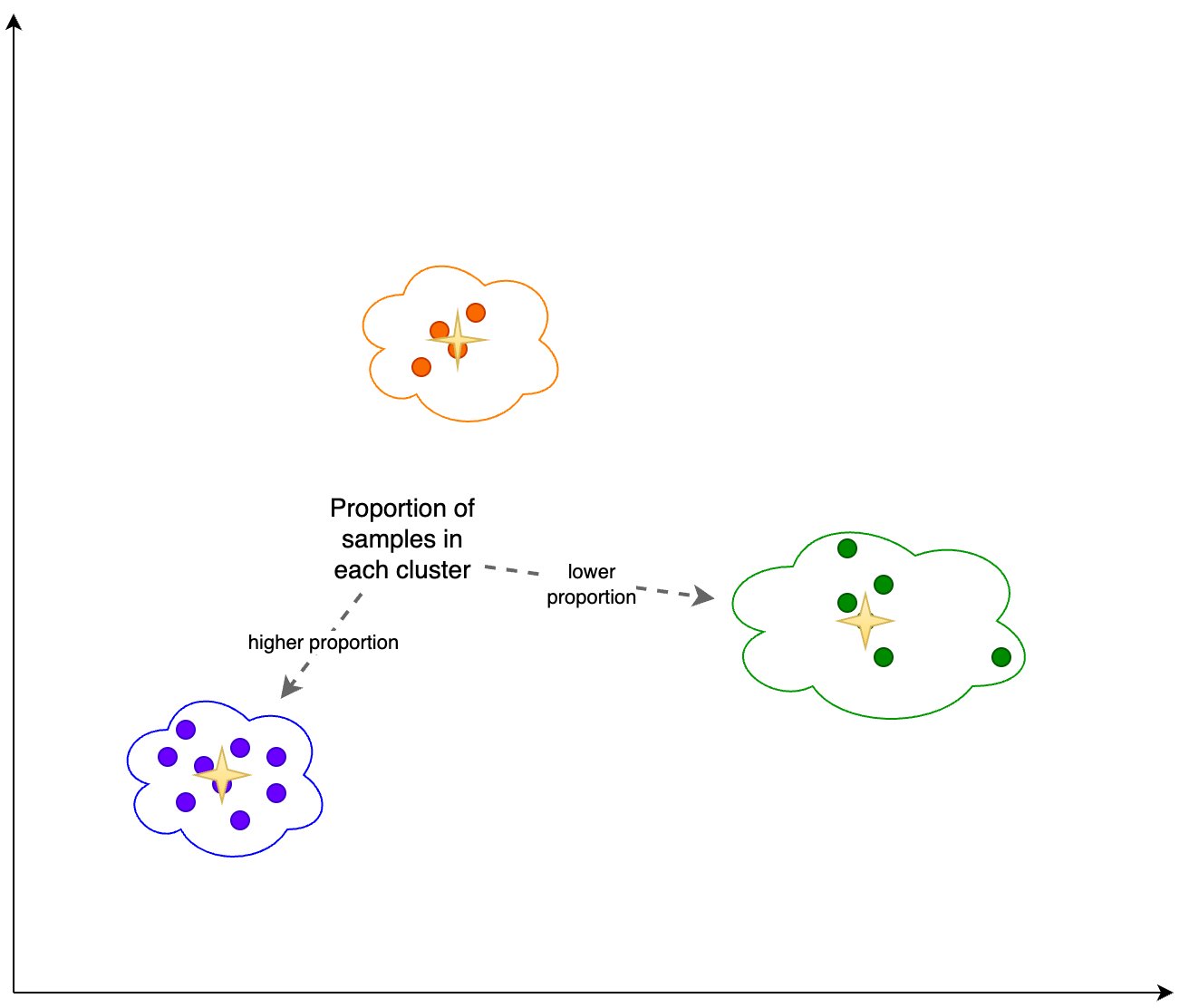
Dodatkowo sprawdzamy proporcję (wyższą lub niższą) próbek w każdym skupieniu, jak pokazano na poniższym rysunku.
Na koniec używamy tej analizy do obliczenia następujących elementów:
- Bezwładność – Bezwładność to suma kwadratów odległości do centroidów klastrów, która mierzy, jak dobrze dane zostały skupione przy użyciu K-średnich.
- Ocena sylwetki – Wynik sylwetki jest miarą potwierdzającą spójność w obrębie skupień i waha się od -1 do 1. Wartość bliska 1 oznacza, że punkty w skupieniu znajdują się blisko innych punktów w tym samym skupieniu i daleko od punktów pozostałych skupień. Wizualną reprezentację wyniku sylwetki można zobaczyć na poniższym rysunku.

Możemy okresowo przechwytywać te informacje w celu tworzenia migawek osadzania zarówno dla źródłowych danych referencyjnych, jak i dla podpowiedzi. Przechwytywanie tych danych pozwala nam analizować potencjalne sygnały dryfu osadzania.
Wykrywanie dryfu osadzania
Okresowo możemy porównywać informacje o klastrach poprzez migawki danych, które obejmują osadzanie danych referencyjnych i osadzanie podpowiedzi. Po pierwsze, możemy porównać liczbę wymiarów potrzebnych do wyjaśnienia 95% zmienności danych osadzania, bezwładności i wyniku sylwetki z zadania grupowania. Jak widać w poniższej tabeli, w porównaniu z wartością bazową najnowszy obraz osadzania wymaga 39 dodatkowych wymiarów, aby wyjaśnić wariancję, co wskazuje, że nasze dane są bardziej rozproszone. Bezwładność wzrosła, co wskazuje, że próbki łącznie znajdują się dalej od centrów skupisk. Dodatkowo, wynik sylwetki spadł, co wskazuje, że gromady nie są tak dobrze zdefiniowane. W przypadku danych podpowiedzi może to oznaczać, że typy pytań przychodzących do systemu dotyczą większej liczby tematów.
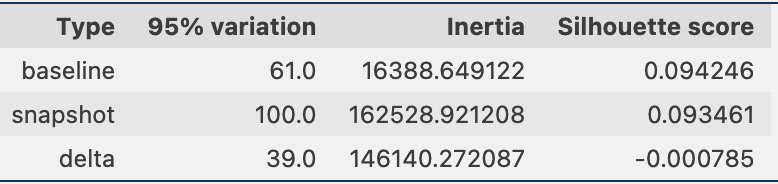
Następnie na poniższym rysunku możemy zobaczyć, jak proporcja próbek w każdym skupieniu zmieniała się w czasie. Może nam to pokazać, czy nasze nowsze dane referencyjne są zasadniczo podobne do poprzedniego zestawu, czy też obejmują nowe obszary.
Na koniec możemy zobaczyć, czy centra klastrów się poruszają, co wskazywałoby na dryf informacji w klastrach, jak pokazano w poniższej tabeli.

Zakres danych referencyjnych dla przychodzących pytań
Możemy również ocenić, jak dobrze nasze dane referencyjne odpowiadają napływającym pytaniom. Aby to zrobić, przypisujemy każde osadzenie podpowiedzi do klastra danych referencyjnych. Obliczamy odległość od każdego podpowiedzi do odpowiadającego mu środka i sprawdzamy średnią, medianę i odchylenie standardowe tych odległości. Możemy przechowywać te informacje i zobaczyć, jak zmieniają się w czasie.
Poniższy rysunek przedstawia przykład analizy odległości pomiędzy osadzeniem podpowiedzi a referencyjnymi centrami danych w czasie.

Jak widać, statystyki odległości średniej, mediany i odchylenia standardowego pomiędzy osadzaniami natychmiastowymi a referencyjnymi centrami danych zmniejszają się pomiędzy początkową linią bazową a najnowszą migawką. Chociaż wartość bezwzględna odległości jest trudna do zinterpretowania, możemy wykorzystać trendy, aby określić, czy nakładanie się semantyki między danymi referencyjnymi a napływającymi pytaniami z czasem staje się lepsze, czy gorsze.
Przykładowa aplikacja
Aby zebrać wyniki eksperymentów omówione w poprzedniej sekcji, zbudowaliśmy przykładową aplikację, która implementuje wzorzec RAG przy użyciu modeli osadzania i generowania wdrożonych za pomocą SageMaker JumpStart i hostowanych na Amazon Sage Maker punkty końcowe w czasie rzeczywistym.
Aplikacja składa się z trzech podstawowych komponentów:
- Korzystamy z interaktywnego przepływu, który zawiera interfejs użytkownika do przechwytywania podpowiedzi, w połączeniu z warstwą orkiestracyjną RAG, przy użyciu LangChain.
- Proces przetwarzania danych wyodrębnia dane z dokumentów PDF i tworzy osadzanie, w którym są one przechowywane Usługa Amazon OpenSearch. Używamy ich również w końcowym komponencie analizy dryfu osadzania w aplikacji.
- Osadzenia są przechwytywane w Usługa Amazon Simple Storage (Amazon S3) przez Wąż strażacki Amazon Kinesis Datai uruchamiamy kombinację Klej AWS wyodrębniaj, przekształcaj i ładuj zadania (ETL) oraz notesy Jupyter w celu przeprowadzenia analizy osadzania.
Poniższy diagram ilustruje kompleksową architekturę.
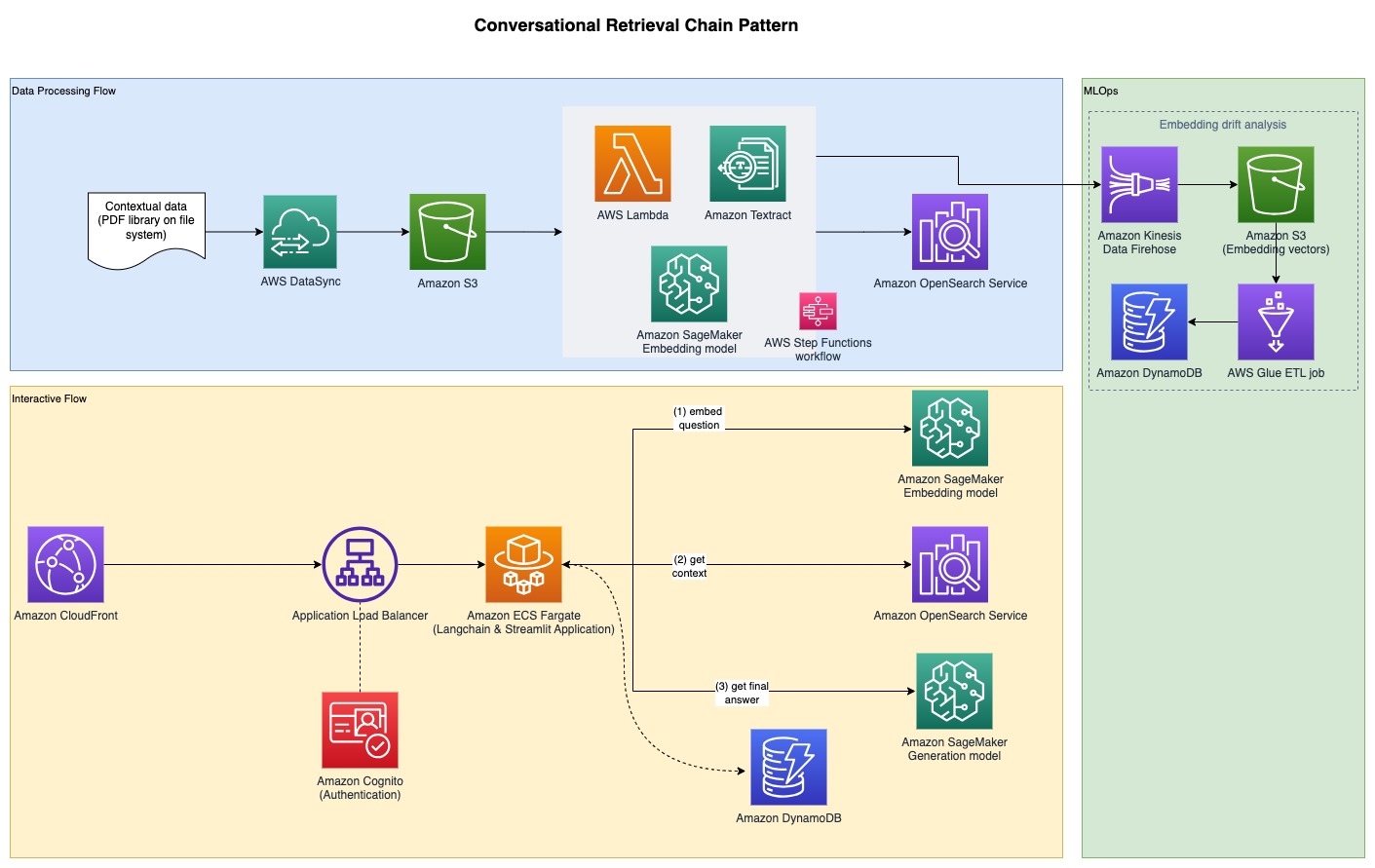
Pełny przykładowy kod jest dostępny na GitHub. Dostarczony kod jest dostępny w dwóch różnych wzorach:
- Przykładowa aplikacja typu full-stack z nakładką Streamlit – Zapewnia to kompleksową aplikację, w tym interfejs użytkownika wykorzystujący Streamlit do przechwytywania podpowiedzi, w połączeniu z warstwą orkiestracyjną RAG, wykorzystującą LangChain działającą na Usługa Amazon Elastic Container Service (Amazon ECS) z AWS-Fargate
- Aplikacja backendowa – Dla tych, którzy nie chcą wdrażać pełnego stosu aplikacji, możesz opcjonalnie zdecydować się na wdrożenie tylko backendu Zestaw programistyczny AWS Cloud (AWS CDK), a następnie użyj dostarczonego notatnika Jupyter, aby przeprowadzić orkiestrację RAG przy użyciu LangChain
Aby utworzyć dostarczone wzorce, należy spełnić kilka wymagań wstępnych szczegółowo opisanych w poniższych sekcjach, zaczynając od wdrożenia modeli generatywnych i osadzania tekstu, a następnie przechodząc do dodatkowych wymagań wstępnych.
Wdrażaj modele za pomocą SageMaker JumpStart
Obydwa wzorce zakładają wdrożenie modelu osadzania i modelu generatywnego. W tym celu wdrożysz dwa modele z SageMaker JumpStart. Pierwszy model, GPT-J 6B, służy jako model osadzający, a drugi model, Falcon-40b, służy do generowania tekstu.
Możesz wdrożyć każdy z tych modeli za pomocą SageMaker JumpStart z poziomu Konsola zarządzania AWS, Studio Amazon SageMakerlub programowo. Aby uzyskać więcej informacji, zobacz Jak korzystać z modeli fundamentów JumpStart. Aby uprościć wdrażanie, możesz użyć pliku dostarczony notatnik pochodzące z notatników tworzonych automatycznie przez SageMaker JumpStart. Ten notatnik pobiera modele z koncentratora SageMaker JumpStart ML i wdraża je w dwóch oddzielnych punktach końcowych czasu rzeczywistego SageMaker.
Przykładowy notatnik zawiera również sekcję czyszczenia. Nie uruchamiaj jeszcze tej sekcji, ponieważ spowoduje to usunięcie właśnie wdrożonych punktów końcowych. Oczyszczanie zakończysz na końcu poradnika.
Po potwierdzeniu pomyślnego wdrożenia punktów końcowych można przystąpić do wdrożenia pełnej przykładowej aplikacji. Jeśli jednak bardziej interesuje Cię eksplorowanie wyłącznie notesów zaplecza i analiz, możesz opcjonalnie wdrożyć tylko te notesy, które opisano w następnej sekcji.
Opcja 1: Wdróż tylko aplikację zaplecza
Ten wzorzec umożliwia wdrożenie wyłącznie rozwiązania zaplecza i interakcję z rozwiązaniem przy użyciu notesu Jupyter. Użyj tego wzorca, jeśli nie chcesz budować pełnego interfejsu frontendowego.
Wymagania wstępne
Powinieneś mieć następujące wymagania wstępne:
- Wdrożono punkt końcowy modelu SageMaker JumpStart – Wdróż modele w punktach końcowych SageMaker w czasie rzeczywistym za pomocą SageMaker JumpStart, jak opisano wcześniej
- Parametry wdrożenia – Zapisz co następuje:
- Nazwa punktu końcowego modelu tekstowego – Nazwa punktu końcowego modelu generowania tekstu wdrożonego w programie SageMaker JumpStart
- Nazwa punktu końcowego modelu osadzania – Nazwa punktu końcowego modelu osadzania wdrożonego za pomocą SageMaker JumpStart
Wdróż zasoby za pomocą AWS CDK
Użyj parametrów wdrażania opisanych w poprzedniej sekcji, aby wdrożyć stos AWS CDK. Więcej informacji na temat instalacji AWS CDK można znaleźć w artykule Pierwsze kroki z AWS CDK.
Upewnij się, że Docker jest zainstalowany i uruchomiony na stacji roboczej, która będzie używana do wdrożenia AWS CDK. Odnosić się do Pobierz Dockera w celu uzyskania dodatkowych wskazówek.
Alternatywnie możesz wprowadzić wartości kontekstu w pliku o nazwie cdk.context.json pattern1-rag/cdk katalog i uruchom cdk deploy BackendStack --exclusively.
Wdrożenie spowoduje wydrukowanie wyników, z których część będzie potrzebna do uruchomienia notatnika. Zanim zaczniesz zadawać pytania i udzielać odpowiedzi, umieść dokumenty referencyjne, jak pokazano w następnej sekcji.
Osadź dokumenty referencyjne
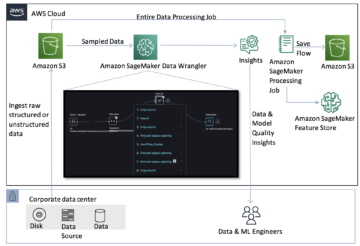
W przypadku tego podejścia RAG dokumenty referencyjne są najpierw osadzane w modelu osadzania tekstu i przechowywane w wektorowej bazie danych. W tym rozwiązaniu zbudowano potok pozyskiwania, który pobiera dokumenty PDF.
An Elastyczna chmura obliczeniowa Amazon Utworzono instancję (Amazon EC2) do przetwarzania dokumentów PDF i System plików Amazon Elastic System plików (Amazon EFS) jest montowany w instancji EC2 w celu zapisywania dokumentów PDF. Jakiś Synchronizacja danych AWS zadanie jest uruchamiane co godzinę w celu pobrania dokumentów PDF znalezionych w ścieżce systemu plików EFS i przesłania ich do zasobnika S3 w celu rozpoczęcia procesu osadzania tekstu. W ramach tego procesu dokumenty referencyjne są osadzane i zapisywane w usłudze OpenSearch. Zapisuje także archiwum osadzania w wiadrze S3 poprzez Kinesis Data Firehose do późniejszej analizy.
Aby pozyskać dokumenty referencyjne, wykonaj następujące kroki:
- Pobierz przykładowy identyfikator instancji EC2, który został utworzony (zobacz dane wyjściowe AWS CDK
JumpHostId) i połącz się za pomocą Menedżer sesji, zdolność Menedżer systemów AWS. Aby uzyskać instrukcje, zobacz Połącz się z instancją systemu Linux za pomocą menedżera sesji AWS Systems Manager. - Przejdź do katalogu
/mnt/efs/fs1, w którym zamontowany jest system plików EFS, i utwórz folder o nazwieingest: - Dodaj referencyjne dokumenty PDF do pliku
ingestkatalogiem.
Zadanie DataSync jest skonfigurowane tak, aby przesyłać wszystkie pliki znalezione w tym katalogu do Amazon S3 w celu rozpoczęcia procesu osadzania.
Zadanie DataSync jest uruchamiane według harmonogramu godzinowego; opcjonalnie możesz uruchomić zadanie ręcznie, aby natychmiast rozpocząć proces osadzania dodanych dokumentów PDF.
- Aby rozpocząć zadanie, znajdź identyfikator zadania na wyjściu AWS CDK
DataSyncTaskIDi rozpocznij zadanie z ustawieniami domyślnymi.
Po utworzeniu osadów możesz rozpocząć zadawanie pytań RAG i udzielanie odpowiedzi za pomocą notatnika Jupyter, jak pokazano w następnej sekcji.
Pytania i odpowiedzi za pomocą notatnika Jupyter
Wykonaj następujące kroki:
- Pobierz nazwę instancji notatnika SageMaker z danych wyjściowych AWS CDK
NotebookInstanceNamei połącz się z JupyterLab z konsoli SageMaker. - Przejdź do katalogu
fmops/full-stack/pattern1-rag/notebooks/. - Otwórz i uruchom notatnik
query-llm.ipynbw instancji notatnika, aby zadawać pytania i odpowiadać za pomocą RAG.
Pamiętaj, aby użyć conda_python3 jądro dla notebooka.
Ten wzorzec jest przydatny do eksplorowania rozwiązania zaplecza bez konieczności udostępniania dodatkowych wymagań wstępnych wymaganych w przypadku aplikacji z pełnym stosem. Następna sekcja obejmuje implementację aplikacji z pełnym stosem, w tym zarówno komponentami frontendowymi, jak i backendowymi, w celu zapewnienia interfejsu użytkownika umożliwiającego interakcję z generatywną aplikacją AI.
Opcja 2: Wdróż przykładową aplikację z pełnym stosem za pomocą frontonu Streamlit
Ten wzorzec umożliwia wdrożenie rozwiązania z interfejsem użytkownika do zadawania pytań i udzielania odpowiedzi.
Wymagania wstępne
Aby wdrożyć przykładową aplikację, muszą być spełnione następujące wymagania wstępne:
- Wdrożono punkt końcowy modelu SageMaker JumpStart – Wdróż modele na punktach końcowych czasu rzeczywistego SageMaker za pomocą SageMaker JumpStart, jak opisano w poprzedniej sekcji, korzystając z dostarczonych notatników.
- Strefa hostowana Amazon Route 53 - Stworzyć Amazon trasy 53 publiczna strefa hostowana zastosować w tym rozwiązaniu. Możesz także skorzystać z istniejącej publicznej strefy hostowanej Route 53, takiej jak
example.com. - Certyfikat Menedżera certyfikatów AWS – Zapewnienie Menedżer certyfikatów AWS (ACM) Certyfikat TLS dla nazwy domeny strefy hostowanej Route 53 i jej odpowiednich subdomen, takich jak
example.comi*.example.comdla wszystkich subdomen. Aby uzyskać instrukcje, zobacz Żądanie certyfikatu publicznego. Ten certyfikat służy do konfiguracji protokołu HTTPS Amazon CloudFront oraz moduł równoważenia obciążenia pochodzenia. - Parametry wdrożenia – Zapisz co następuje:
- Niestandardowa nazwa domeny aplikacji frontendowej – Niestandardowa nazwa domeny używana w celu uzyskania dostępu do przykładowej aplikacji frontendowej. Podana nazwa domeny służy do utworzenia rekordu DNS Route 53 wskazującego na dystrybucję frontendową CloudFront; Na przykład,
app.example.com. - Niestandardowa nazwa domeny pochodzenia modułu równoważenia obciążenia – Niestandardowa nazwa domeny używana na potrzeby modułu równoważenia obciążenia w dystrybucji CloudFront. Podana nazwa domeny służy do utworzenia rekordu DNS Route 53 wskazującego początkowy moduł równoważenia obciążenia; Na przykład,
app-lb.example.com. - Identyfikator strefy hostowanej Route 53 – Identyfikator strefy hostowanej Route 53, w której będą hostowane podane niestandardowe nazwy domen; Na przykład,
ZXXXXXXXXYYYYYYYYY. - Nazwa strefy hostowanej Route 53 – Nazwa strefy hostowanej Route 53, w której będą hostowane podane niestandardowe nazwy domen; Na przykład,
example.com. - Certyfikat ACM ARN – ARN certyfikatu ACM, który ma być używany z dostarczoną domeną niestandardową.
- Nazwa punktu końcowego modelu tekstowego – Nazwa punktu końcowego modelu generowania tekstu wdrożonego w programie SageMaker JumpStart.
- Nazwa punktu końcowego modelu osadzania – Nazwa punktu końcowego modelu osadzania wdrożonego za pomocą SageMaker JumpStart.
- Niestandardowa nazwa domeny aplikacji frontendowej – Niestandardowa nazwa domeny używana w celu uzyskania dostępu do przykładowej aplikacji frontendowej. Podana nazwa domeny służy do utworzenia rekordu DNS Route 53 wskazującego na dystrybucję frontendową CloudFront; Na przykład,
Wdróż zasoby za pomocą AWS CDK
Użyj parametrów wdrożenia zanotowanych w wymaganiach wstępnych, aby wdrożyć stos AWS CDK. Aby uzyskać więcej informacji, zobacz Pierwsze kroki z AWS CDK.
Upewnij się, że Docker jest zainstalowany i uruchomiony na stacji roboczej, która będzie używana do wdrożenia AWS CDK.
W powyższym kodzie -c reprezentuje wartość kontekstu w postaci wymaganych warunków wstępnych, podaną na wejściu. Alternatywnie możesz wprowadzić wartości kontekstu w pliku o nazwie cdk.context.json pattern1-rag/cdk katalog i uruchom cdk deploy --all.
Pamiętaj, że w pliku określamy Region bin/cdk.ts. Konfiguracja dzienników dostępu ALB wymaga określonego regionu. Możesz zmienić ten region przed wdrożeniem.
Wdrożenie wydrukuje adres URL umożliwiający dostęp do aplikacji Streamlit. Zanim będziesz mógł rozpocząć zadawanie pytań i udzielanie odpowiedzi, musisz osadzić dokumenty referencyjne, jak pokazano w następnej sekcji.
Osadź dokumenty referencyjne
W przypadku podejścia RAG dokumenty referencyjne są najpierw osadzane w modelu osadzania tekstu i przechowywane w wektorowej bazie danych. W tym rozwiązaniu zbudowano potok pozyskiwania, który pobiera dokumenty PDF.
Jak omówiliśmy w pierwszej opcji wdrożenia, utworzono przykładową instancję EC2 do przyjmowania dokumentów PDF, a system plików EFS jest montowany w instancji EC2 w celu zapisywania dokumentów PDF. Zadanie DataSync jest uruchamiane co godzinę w celu pobrania dokumentów PDF znalezionych w ścieżce systemu plików EFS i przesłania ich do zasobnika S3 w celu rozpoczęcia procesu osadzania tekstu. W ramach tego procesu dokumenty referencyjne są osadzane i zapisywane w usłudze OpenSearch. Zapisuje także archiwum osadzania w wiadrze S3 poprzez Kinesis Data Firehose do późniejszej analizy.
Aby pozyskać dokumenty referencyjne, wykonaj następujące kroki:
- Pobierz przykładowy identyfikator instancji EC2, który został utworzony (zobacz dane wyjściowe AWS CDK
JumpHostId) i połącz się za pomocą Menedżera sesji. - Przejdź do katalogu
/mnt/efs/fs1, w którym zamontowany jest system plików EFS, i utwórz folder o nazwieingest: - Dodaj referencyjne dokumenty PDF do pliku
ingestkatalogiem.
Zadanie DataSync jest skonfigurowane tak, aby przesyłać wszystkie pliki znalezione w tym katalogu do Amazon S3 w celu rozpoczęcia procesu osadzania.
Zadanie DataSync jest uruchamiane według harmonogramu godzinowego. Opcjonalnie możesz uruchomić zadanie ręcznie, aby natychmiast rozpocząć proces osadzania dodanych dokumentów PDF.
- Aby rozpocząć zadanie, znajdź identyfikator zadania na wyjściu AWS CDK
DataSyncTaskIDi rozpocznij zadanie z ustawieniami domyślnymi.
Pytanie i odpowiedź
Po osadzeniu dokumentów referencyjnych możesz rozpocząć zadawanie pytań i udzielanie odpowiedzi w ramach RAG, odwiedzając adres URL umożliwiający dostęp do aplikacji Streamlit. Jakiś Amazon Cognito używana jest warstwa uwierzytelniania, dlatego wymaga utworzenia konta użytkownika w puli użytkowników Amazon Cognito wdrożonej za pośrednictwem AWS CDK (zobacz dane wyjściowe AWS CDK dla nazwy puli użytkowników) w celu uzyskania pierwszego dostępu do aplikacji. Aby uzyskać instrukcje dotyczące tworzenia użytkownika Amazon Cognito, zobacz Tworzenie nowego użytkownika w AWS Management Console.
Osadź analizę dryfu
W tej sekcji pokażemy, jak przeprowadzić analizę dryftu, tworząc najpierw linię bazową osadzania danych referencyjnych i osadzania podpowiedzi, a następnie tworząc migawkę osadzania w czasie. Dzięki temu można porównać osadzenie linii bazowej z osadzeniem migawki.
Utwórz linię bazową osadzania dla danych referencyjnych i podpowiedzi
Aby utworzyć linię bazową osadzania danych referencyjnych, otwórz konsolę AWS Glue i wybierz zadanie ETL embedding-drift-analysis. Ustaw parametry zadania ETL w następujący sposób i uruchom zadanie:
- Zestaw
--job_typedoBASELINE. - Zestaw
--out_tabledo Amazon DynamoDB tabela referencyjna dotycząca osadzania danych. (Zobacz wyjście AWS CDKDriftTableReferencedla nazwy tabeli.) - Zestaw
--centroid_tabledo tabeli DynamoDB w celu uzyskania danych środka ciężkości odniesienia. (Zobacz wyjście AWS CDKCentroidTableReferencedla nazwy tabeli.) - Zestaw
--data_pathdo wiadra S3 z prefiksem; Na przykład,s3:///embeddingarchive/. (Zobacz wyjście AWS CDKBucketNamedla nazwy wiadra.)
Podobnie, używając zadania ETL embedding-drift-analysis, utwórz osadzaną linię bazową podpowiedzi. Ustaw parametry zadania ETL w następujący sposób i uruchom zadanie:
- Zestaw
--job_typedoBASELINE - Zestaw
--out_tabledo tabeli DynamoDB w celu szybkiego osadzania danych. (Zobacz wyjście AWS CDKDriftTablePromptsNamedla nazwy tabeli.) - Zestaw
--centroid_tabledo tabeli DynamoDB, aby uzyskać natychmiastowe dane dotyczące środka ciężkości. (Zobacz wyjście AWS CDKCentroidTablePromptsdla nazwy tabeli.) - Zestaw
--data_pathdo wiadra S3 z prefiksem; Na przykład,s3:///promptarchive/. (Zobacz wyjście AWS CDKBucketNamedla nazwy wiadra.)
Utwórz migawkę osadzania dla danych referencyjnych i podpowiedzi
Po przyjęciu dodatkowych informacji do usługi OpenSearch Service uruchom zadanie ETL embedding-drift-analysis ponownie, aby wykonać migawkę osadzonych danych referencyjnych. Parametry będą takie same jak w przypadku zadania ETL uruchomionego w celu utworzenia linii bazowej osadzania danych referencyjnych, jak pokazano w poprzedniej sekcji, z wyjątkiem ustawienia --job_type parametr SNAPSHOT.
Podobnie, aby wykonać migawkę osadzonych podpowiedzi, uruchom zadanie ETL embedding-drift-analysis Ponownie. Parametry będą takie same jak w przypadku zadania ETL uruchomionego w celu utworzenia linii bazowej osadzania dla podpowiedzi, jak pokazano w poprzedniej sekcji, z wyjątkiem ustawienia --job_type parametr SNAPSHOT.
Porównaj linię bazową z migawką
Aby porównać osadzaną linię bazową i migawkę pod kątem danych referencyjnych i podpowiedzi, użyj dostarczonego notesu pattern1-rag/notebooks/drift-analysis.ipynb.
Aby sprawdzić porównanie osadzania danych referencyjnych lub podpowiedzi, zmień zmienne nazwy tabeli DynamoDB (tbl i c_tbl) w notatniku do odpowiedniej tabeli DynamoDB dla każdego uruchomienia notatnika.
Zmienna notatnika tbl należy zmienić na odpowiednią nazwę tabeli dryfu. Poniżej znajduje się przykład konfiguracji zmiennej w notatniku.

Nazwy tabel można pobrać w następujący sposób:
- Aby uzyskać referencyjne dane osadzania, pobierz nazwę tabeli dryfów z danych wyjściowych AWS CDK
DriftTableReference - Aby uzyskać monit o osadzenie danych, pobierz nazwę tabeli dryfów z danych wyjściowych AWS CDK
DriftTablePromptsName
Dodatkowo zmienna notatnik c_tbl należy zmienić na odpowiednią nazwę tabeli centroidów. Poniżej znajduje się przykład konfiguracji zmiennej w notatniku.

Nazwy tabel można pobrać w następujący sposób:
- Aby uzyskać referencyjne dane osadzające, pobierz nazwę tabeli centroidów z danych wyjściowych AWS CDK
CentroidTableReference - Aby uzyskać monit o osadzenie danych, pobierz nazwę tabeli centroidów z danych wyjściowych AWS CDK
CentroidTablePrompts
Przeanalizuj natychmiastową odległość od danych referencyjnych
Najpierw uruchom zadanie klejenia AWS embedding-distance-analysis. To zadanie polega na ustaleniu, do którego klastra, na podstawie oceny K-średnich osadzonych danych referencyjnych, należy każdy monit. Następnie oblicza średnią, medianę i odchylenie standardowe odległości od każdego podpowiedzi do środka odpowiedniego skupienia.
Możesz uruchomić notatnik pattern1-rag/notebooks/distance-analysis.ipynb aby zobaczyć trendy w pomiarach odległości w czasie. Dzięki temu uzyskasz pogląd na ogólny trend w rozkładzie odległości szybkiego osadzania.
Notatnik pattern1-rag/notebooks/prompt-distance-outliers.ipynb to notatnik AWS Glue, który wyszukuje wartości odstające, co może pomóc Ci określić, czy otrzymujesz więcej podpowiedzi niezwiązanych z danymi referencyjnymi.
Monitoruj wyniki podobieństwa
Wszystkie wyniki podobieństwa z usługi OpenSearch są logowane Amazon Cloud Watch pod rag przestrzeń nazw. Deska rozdzielcza RAG_Scores pokazuje średni wynik i całkowitą liczbę przyjętych wyników.
Sprzątać
Aby uniknąć przyszłych opłat, usuń wszystkie utworzone zasoby.
Usuń wdrożone modele SageMaker
Zapoznaj się z sekcją dotyczącą czyszczenia w pliku podany przykładowy notatnik aby usunąć wdrożone modele SageMaker JumpStart, lub możesz to zrobić usuń modele z konsoli SageMaker.
Usuń zasoby AWS CDK
Jeśli wprowadziłeś parametry w a cdk.context.json plik, wyczyść w następujący sposób:
Jeśli wprowadziłeś parametry w wierszu poleceń i wdrożyłeś tylko aplikację zaplecza (stos zaplecza AWS CDK), wyczyść w następujący sposób:
Jeśli wprowadziłeś parametry w wierszu poleceń i wdrożyłeś pełne rozwiązanie (stosy frontonu i backendu AWS CDK), wyczyść w następujący sposób:
Wnioski
W tym poście przedstawiliśmy działający przykład aplikacji, która przechwytuje wektory osadzania zarówno dla danych referencyjnych, jak i podpowiedzi we wzorcu RAG dla generatywnej sztucznej inteligencji. Pokazaliśmy, jak przeprowadzić analizę skupień, aby określić, czy dane referencyjne lub podpowiedzi zmieniają się w czasie i jak dobrze dane referencyjne pokrywają rodzaje pytań zadawanych przez użytkowników. Jeśli wykryjesz dryf, może to dać sygnał, że środowisko się zmieniło i Twój model otrzymuje nowe dane wejściowe, do obsługi których może nie być zoptymalizowany. Pozwala to na proaktywną ocenę bieżącego modelu pod kątem zmieniających się danych wejściowych.
O autorach
 Abdullahi Olaoye jest starszym architektem rozwiązań w Amazon Web Services (AWS). Abdullahi posiada tytuł MSC w dziedzinie sieci komputerowych uzyskany na Uniwersytecie Stanowym Wichita i jest autorem publikacji, który zajmował stanowiska w różnych dziedzinach technologii, takich jak DevOps, modernizacja infrastruktury i sztuczna inteligencja. Obecnie koncentruje się na generatywnej sztucznej inteligencji i odgrywa kluczową rolę we wspieraniu przedsiębiorstw w projektowaniu i budowaniu najnowocześniejszych rozwiązań opartych na generatywnej sztucznej inteligencji. Poza dziedziną technologii radość odnajduje w sztuce eksploracji. Kiedy nie tworzy rozwiązań AI, lubi podróżować z rodziną, aby odkrywać nowe miejsca.
Abdullahi Olaoye jest starszym architektem rozwiązań w Amazon Web Services (AWS). Abdullahi posiada tytuł MSC w dziedzinie sieci komputerowych uzyskany na Uniwersytecie Stanowym Wichita i jest autorem publikacji, który zajmował stanowiska w różnych dziedzinach technologii, takich jak DevOps, modernizacja infrastruktury i sztuczna inteligencja. Obecnie koncentruje się na generatywnej sztucznej inteligencji i odgrywa kluczową rolę we wspieraniu przedsiębiorstw w projektowaniu i budowaniu najnowocześniejszych rozwiązań opartych na generatywnej sztucznej inteligencji. Poza dziedziną technologii radość odnajduje w sztuce eksploracji. Kiedy nie tworzy rozwiązań AI, lubi podróżować z rodziną, aby odkrywać nowe miejsca.
 Randy’ego DeFauwa jest starszym głównym architektem rozwiązań w AWS. Posiada tytuł MSEE uzyskany na Uniwersytecie Michigan, gdzie pracował nad wizją komputerową dla pojazdów autonomicznych. Posiada również tytuł MBA uzyskany na Colorado State University. Randy zajmował różne stanowiska w przestrzeni technologicznej, od inżynierii oprogramowania po zarządzanie produktem. W przestrzeń Big Data weszła w 2013 roku i nadal eksploruje ten obszar. Aktywnie pracuje nad projektami w przestrzeni ML i występował na licznych konferencjach, w tym Strata i GlueCon.
Randy’ego DeFauwa jest starszym głównym architektem rozwiązań w AWS. Posiada tytuł MSEE uzyskany na Uniwersytecie Michigan, gdzie pracował nad wizją komputerową dla pojazdów autonomicznych. Posiada również tytuł MBA uzyskany na Colorado State University. Randy zajmował różne stanowiska w przestrzeni technologicznej, od inżynierii oprogramowania po zarządzanie produktem. W przestrzeń Big Data weszła w 2013 roku i nadal eksploruje ten obszar. Aktywnie pracuje nad projektami w przestrzeni ML i występował na licznych konferencjach, w tym Strata i GlueCon.
 Shelbee Eigenbrode jest głównym specjalistą ds. rozwiązań AI i uczenia maszynowego w Amazon Web Services (AWS). Od 24 lat zajmuje się technologią, obejmując wiele branż, technologii i ról. Obecnie koncentruje się na połączeniu swojego doświadczenia w zakresie DevOps i ML z domeną MLOps, aby pomóc klientom dostarczać i zarządzać obciążeniami ML na dużą skalę. Z ponad 35 patentami przyznanymi w różnych dziedzinach technologii, ma pasję do ciągłych innowacji i wykorzystywania danych do osiągania wyników biznesowych. Shelbee jest współtwórcą i instruktorem specjalizacji Practical Data Science na Coursera. Jest również współdyrektorem Women In Big Data (WiBD), oddział w Denver. W wolnym czasie lubi spędzać czas z rodziną, przyjaciółmi i nadpobudliwymi psami.
Shelbee Eigenbrode jest głównym specjalistą ds. rozwiązań AI i uczenia maszynowego w Amazon Web Services (AWS). Od 24 lat zajmuje się technologią, obejmując wiele branż, technologii i ról. Obecnie koncentruje się na połączeniu swojego doświadczenia w zakresie DevOps i ML z domeną MLOps, aby pomóc klientom dostarczać i zarządzać obciążeniami ML na dużą skalę. Z ponad 35 patentami przyznanymi w różnych dziedzinach technologii, ma pasję do ciągłych innowacji i wykorzystywania danych do osiągania wyników biznesowych. Shelbee jest współtwórcą i instruktorem specjalizacji Practical Data Science na Coursera. Jest również współdyrektorem Women In Big Data (WiBD), oddział w Denver. W wolnym czasie lubi spędzać czas z rodziną, przyjaciółmi i nadpobudliwymi psami.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35%
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95%
- a
- Zdolny
- O nas
- bezwzględny
- dostęp
- Konto
- ACM
- w poprzek
- aktywnie
- w dodatku
- dodatek
- Dodatkowy
- Dodatkowe informacje
- do tego
- ponownie
- przed
- agregat
- AI
- Wyrównuje
- Wszystkie kategorie
- Pozwalać
- pozwala
- również
- Chociaż
- Amazonka
- Amazon Cognito
- Amazon EC2
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- analiza
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- odpowiedź
- sekretarka
- wszystko
- odpowiedni
- Zastosowanie
- podejście
- właściwy
- architektura
- Archiwum
- SĄ
- POWIERZCHNIA
- obszary
- Sztuka
- towary
- AS
- zapytać
- pytanie
- pomoc
- założyć
- At
- zwiększać
- zwiększona
- Uwierzytelnianie
- autor
- automatycznie
- autonomiczny
- pojazdy autonomiczne
- dostępny
- średni
- uniknąć
- z dala
- AWS
- Klej AWS
- Backend
- tło
- stabilizator
- na podstawie
- Baseline
- BE
- bo
- być
- zanim
- jest
- należy
- Ulepsz Swój
- pomiędzy
- Poza
- Duży
- Big Data
- ciała
- obie
- szeroko
- budować
- wybudowany
- biznes
- by
- obliczać
- oblicza
- wezwanie
- nazywa
- CAN
- zdolność
- zdobyć
- Zajęte
- przechwytuje
- Przechwytywanie
- walizka
- CD
- Centrum
- Centra
- świadectwo
- zmiana
- zmieniony
- Zmiany
- wymiana pieniędzy
- Rozdział
- Opłaty
- żeton
- Czekolada
- Dodaj
- kleń
- Zamknij
- bliższy
- Chmura
- Grupa
- klastrowanie
- kod
- Kolorado
- połączenie
- połączony
- łączenie
- przyjście
- kompaktowy
- porównać
- w porównaniu
- porównanie
- kompletny
- składnik
- składniki
- obliczać
- komputer
- Wizja komputerowa
- Koncepcje
- konferencje
- skonfigurowany
- konfigurowanie
- Skontaktuj się
- Rozważania
- konsystencja
- Konsola
- Pojemnik
- zawartość
- kontekst
- ciągły
- ciągły
- przeliczone
- cookies
- rdzeń
- Odpowiedni
- Coursera
- pokrycie
- pokryty
- pokrycie
- obejmuje
- Stwórz
- stworzony
- tworzy
- Tworzenie
- Aktualny
- Obecnie
- zwyczaj
- Klientów
- pionierski nowatorski
- tablica rozdzielcza
- dane
- centra danych
- analiza danych
- nauka danych
- Baza danych
- zmniejszenie
- Domyślnie
- zdefiniowane
- usunąć
- dostarczyć
- Denver
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- wdraża się
- Pochodny
- zniszczyć
- szczegółowe
- wykryć
- Wykrywanie
- Ustalać
- oprogramowania
- odchylenie
- DevOps
- schemat
- różne
- trudny
- Wymiary
- Wymiary
- omówione
- rozproszone
- dystans
- Odległy
- 分配
- dns
- do
- Doker
- dokument
- dokumenty
- psy
- domena
- Nazwa domeny
- NAZWY DOMEN
- domeny
- nie
- na dół
- napęd
- każdy
- osadzać
- osadzone
- osadzanie
- zakończenia
- koniec końców
- Punkt końcowy
- Punkty końcowe
- Inżynieria
- Wchodzę
- wpisana
- przedsiębiorstwa
- Środowisko
- Eter (ETH)
- oceniać
- ewaluację
- Każdy
- przykład
- przykłady
- wyjątek
- Przede wszystkim system został opracowany
- eksperymentalny
- Wyjaśniać
- eksploracja
- odkryj
- Exploring
- zewnętrzny
- wyciąg
- Wyciągi
- członków Twojej rodziny
- daleko
- Postać
- filet
- Akta
- finał
- W końcu
- Znajdź
- znajduje
- i terminów, a
- unoszący się
- pływ
- koncentruje
- skupienie
- następujący
- następujący sposób
- W razie zamówieenia projektu
- Nasz formularz
- znaleziono
- Fundacja
- przyjaciele
- od
- frontend
- pełny
- przyszłość
- zbierać
- Ogólne
- generujący
- generacja
- generatywny
- generatywna sztuczna inteligencja
- model generatywny
- otrzymać
- miejsce
- Dać
- Go
- poszedł
- udzielony
- Zarządzanie
- poradnictwo
- uchwyt
- Have
- he
- Trzymany
- pomoc
- jej
- wyższy
- jego
- posiada
- gospodarz
- hostowane
- godzina
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- Piasta
- ID
- zidentyfikować
- if
- ilustruje
- natychmiast
- realizacja
- narzędzia
- ważny
- in
- zawierać
- obejmuje
- Włącznie z
- Przybywający
- wskazać
- wskazując,
- przemysłowa
- bezwładność
- Informacja
- Infrastruktura
- początkowy
- Innowacja
- wkład
- Wejścia
- wgląd
- instalacja
- przykład
- instrukcje
- interakcji
- interakcji
- interaktywne
- zainteresowany
- Interfejs
- najnowszych
- IT
- JEGO
- Praca
- Oferty pracy
- radość
- jpg
- Notebook Jupyter
- właśnie
- Klawisz
- Wąż strażacki danych Kinesis
- wiedza
- język
- duży
- później
- firmy
- warstwa
- UCZYĆ SIĘ
- nauka
- pozwala
- Biblioteka
- lubi
- Linia
- linux
- llm
- załadować
- lokalizacja
- zalogowany
- Popatrz
- WYGLĄD
- niższy
- maszyna
- uczenie maszynowe
- robić
- zarządzanie
- i konserwacjami
- kierownik
- ręcznie
- Może..
- MBA
- oznaczać
- znaczy
- zmierzyć
- środków
- Metryka
- Michigan
- może
- ML
- MLOps
- model
- modele
- modernizacja
- monitor
- jeszcze
- większość
- przeniesienie
- wielokrotność
- musi
- Nazwa
- Nazwy
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Potrzebować
- potrzebne
- potrzeba
- sieci
- Nowości
- nowsza
- Następny
- nlp
- notatnik
- laptopy
- zauważyć
- numer
- z naszej
- liczny
- of
- często
- on
- tylko
- koncepcja
- zoptymalizowane
- Option
- or
- orkiestracja
- zamówienie
- Origin
- Inne
- ludzkiej,
- na zewnątrz
- wyniki
- opisane
- wydajność
- Wyjścia
- koniec
- ogólny
- zakładka
- własny
- parametr
- parametry
- szczególny
- pasja
- Patenty
- ścieżka
- Wzór
- wzory
- wykonać
- wykonywania
- sztuk
- rurociąg
- Miejsca
- plato
- Analiza danych Platona
- PlatoDane
- odgrywa
- punkt
- zwrotnica
- basen
- Pozycje
- możliwy
- Post
- potencjał
- powered
- Praktyczny
- poprzedzający
- warunki wstępne
- przedstawione
- zachowuje
- konserwowanie
- poprzedni
- poprzednio
- Główny
- Proaktywne
- wygląda tak
- przetwarzanie
- Produkt
- zarządzanie produktem
- projektowanie
- monity
- odsetek
- zapewniać
- pod warunkiem,
- zapewnia
- zaopatrzenie
- publiczny
- opublikowany
- Ściąga
- pytanie
- pytania
- szmata
- zakresy
- nośny
- gotowy
- w czasie rzeczywistym
- królestwo
- Przepis
- rekord
- zmniejszyć
- redukcja
- odnosić się
- odniesienie
- region
- związane z
- stosunkowo
- reprezentować
- reprezentacja
- reprezentuje
- wymagany
- Wymaga
- Zasoby
- odpowiedź
- Efekt
- wyszukiwanie
- Rola
- role
- Trasa
- run
- bieganie
- działa
- sagemaker
- taki sam
- Zapisz
- Skala
- rozkład
- nauka
- wynik
- wyniki
- Szukaj
- wyszukiwania
- druga
- Sekcja
- działy
- widzieć
- widziany
- wybierać
- semantyczny
- senior
- rozsądek
- wysłany
- oddzielny
- usługa
- Usługi
- Sesja
- zestaw
- ustawienie
- kilka
- ona
- powinien
- pokazać
- pokazał
- pokazane
- Targi
- Signal
- Sygnały
- podobny
- Prosty
- upraszczać
- Rozmiar
- Migawka
- So
- Tworzenie
- Inżynieria oprogramowania
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Źródła
- Typ przestrzeni
- napięcie
- specjalista
- określony
- wydać
- Do kwadratu
- stos
- Półki na książki
- standard
- początek
- rozpoczęty
- Startowy
- Stan
- statystyka
- Cel
- przechowywanie
- sklep
- przechowywany
- udany
- taki
- suma
- pewnie
- system
- systemy
- stół
- Brać
- Zadanie
- technika
- Technologies
- Technologia
- XNUMX
- generowanie tekstu
- że
- Połączenia
- Informacje
- Źródło
- ich
- Im
- następnie
- Tam.
- Te
- to
- tych
- trzy
- Przez
- czas
- TLS
- do
- razem
- tematy
- Kwota produktów:
- Przekształcać
- Podróżowanie
- Trend
- Trendy
- próbuje
- próbować
- drugiej
- typy
- dla
- uniwersytet
- University of Michigan
- URL
- us
- posługiwać się
- używany
- użyteczny
- Użytkownik
- Interfejs użytkownika
- Użytkownicy
- za pomocą
- uprawomocnienie
- wartość
- Wartości
- zmienna
- zmienne
- różnorodność
- różnorodny
- wektor
- wektory
- Pojazdy
- przez
- wizja
- wizualny
- solucja
- chcieć
- była
- Droga..
- we
- sieć
- usługi internetowe
- DOBRZE
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- będzie
- w
- w ciągu
- bez
- Kobieta
- Praca
- pracował
- pracujący
- stacja robocza
- gorzej
- by
- lat
- jeszcze
- ty
- Twój
- zefirnet
- strefa