Amazonka Przesunięcie ku czerwieni to szybka, w pełni zarządzana hurtownia danych o skali petabajtów, która zapewnia elastyczność korzystania z zasobów obliczeniowych udostępnianych lub bezserwerowych na potrzeby obciążeń analitycznych. Za pomocą Bezserwerowe Amazon Redshift i Edytor zapytań v2, możesz ładować i wyszukiwać duże zbiory danych za pomocą zaledwie kilku kliknięć i płacić tylko za to, z czego korzystasz. Oddzielna architektura obliczeniowa i pamięci masowej Amazon Redshift umożliwia tworzenie wysoce skalowalnych, odpornych i ekonomicznych obciążeń roboczych. Wielu klientów migruje swoje obciążenia hurtowni danych do Amazon Redshift i korzysta z bogatych możliwości, jakie oferuje. Oto tylko niektóre z godnych uwagi możliwości:
- Amazon Redshift bezproblemowo integruje się z szerszymi usługi analityczne na AWS. Dzięki temu możesz wybrać odpowiednie narzędzie do właściwej pracy. Nowoczesna analityka jest znacznie szersza niż hurtownie danych oparte na SQL. Amazon Redshift pozwala budować architektury domów nad jeziorem a następnie przeprowadzić wszelkiego rodzaju analizy, takie jak interaktywne analizy, analityka operacyjna, przetwarzanie dużych zbiorów danych, przygotowanie danych wizualnych, analityka predykcyjna, uczenie maszynowe (ML) i nie tylko.
- Nie musisz się martwić, że obciążenia, takie jak ETL, pulpity nawigacyjne, zapytania ad-hoc itd., kolidują ze sobą. Możesz izolować obciążenia przy użyciu udostępniania danych przy użyciu tych samych bazowych zestawów danych.
- Gdy użytkownicy wykonują wiele zapytań w godzinach szczytu, obliczenia płynnie skalują się w ciągu kilku sekund, aby zapewnić spójną wydajność przy wysokiej współbieżności. Otrzymujesz jedną godzinę bezpłatnego skalowania współbieżności na 24 godziny użytkowania. Ten bezpłatny kredyt zaspokaja zapotrzebowanie na współbieżność 97% bazy klientów Amazon Redshift.
- Amazon Redshift jest łatwy w użyciu samostrojenie i samooptymalizacja możliwości. Możesz uzyskać szybszy wgląd bez poświęcania cennego czasu na zarządzanie hurtownią danych.
- Odporność na awarie jest wbudowany. Wszystkie dane zapisane w Amazon Redshift są automatycznie i stale replikowane Usługa Amazon Simple Storage (Amazon S3). Wszelkie awarie sprzętu są automatycznie zastępowane.
- Amazon Redshift jest prosty w interakcji w. Możesz uzyskiwać dostęp do danych za pomocą tradycyjnych, chmurowych, kontenerowych i bezserwerowych aplikacji opartych na usługach internetowych lub sterowanych zdarzeniami i tak dalej.
- Przesunięcie ku czerwieni ML ułatwia analitykom danych tworzenie, trenowanie i wdrażanie modeli ML przy użyciu znajomego języka SQL. Mogą również uruchamiać prognozy przy użyciu języka SQL.
- Amazon Redshift zapewnia kompleksowe zabezpieczenie danych bez dodatkowych kosztów. Możesz skonfigurować kompleksowe szyfrowanie danych, skonfigurować reguły zapory, zdefiniować szczegółowe kontrole bezpieczeństwa na poziomie wiersza i kolumny dotyczące wrażliwych danych i tak dalej.
- Amazonka Przesunięcie ku czerwieni bezproblemowo integruje się z innymi usługami AWS i narzędziami innych firm. Możesz szybko i niezawodnie przenosić, przekształcać, ładować i wysyłać zapytania do dużych zestawów danych.
W tym poście przedstawiamy przewodnik dotyczący migracji hurtowni danych z Google BigQuery do Amazon Redshift przy użyciu Narzędzie do konwersji schematów AWS (AWS SCT) i Agenty ekstrakcji danych AWS SCT. AWS SCT to usługa, która sprawia, że migracje heterogenicznych baz danych są przewidywalne, automatycznie konwertując większość kodu bazy danych i obiektów pamięci masowej do formatu zgodnego z docelową bazą danych. Wszystkie obiekty, których nie można automatycznie przekonwertować, są wyraźnie oznaczone, aby można je było przekonwertować ręcznie w celu ukończenia migracji. Co więcej, AWS SCT może skanować kod aplikacji w poszukiwaniu osadzonych instrukcji SQL i konwertować je.
Omówienie rozwiązania
AWS SCT używa konta usługi do łączenia się z Twoim projektem BigQuery. Najpierw tworzymy bazę danych Amazon Redshift, do której migrowane są dane BigQuery. Następnie tworzymy wiadro S3. Następnie używamy AWS SCT do konwersji schematów BigQuery i zastosowania ich w Amazon Redshift. Wreszcie, do migracji danych używamy agentów ekstrakcji danych AWS SCT, które pobierają dane z BigQuery, przesyłają je do zasobnika S3, a następnie kopiują do Amazon Redshift.

Wymagania wstępne
Przed rozpoczęciem tego przewodnika musisz spełnić następujące wymagania wstępne:
- Stacja robocza z AWS SCT, Korekcja Amazona 11i sterowniki Amazon Redshift.
- Możesz użyć Amazon Elastic Compute Cloud (Amazon EC2) lub lokalny pulpit jako stację roboczą. W tym instruktażu używamy Instancja Amazon EC2 Windows. Aby go utworzyć, użyj ten przewodnik.
- Aby pobrać i zainstalować AWS SCT na utworzonej wcześniej instancji EC2, użyj ten przewodnik.
- Pobierz sterownik Amazon Redshift JDBC z Ta lokalizacja.
- Pobierz i zainstaluj Korekcja Amazona 11.
- Konto usługi GCP, którego AWS SCT może używać do łączenia się ze źródłowym projektem BigQuery.
- Dotacja Administrator BigQuery i Administrator magazynu role do konta usługi.
- Skopiuj plik klucza konta usługi, który został utworzony w konsoli zarządzania chmurą Google, do instancji EC2, która ma AWS SCT.
- Utwórz zasobnik Cloud Storage w GCP, aby przechowywać dane źródłowe podczas migracji.
Ten przewodnik obejmuje następujące kroki:
- Utwórz bezserwerową grupę roboczą i przestrzeń nazw Amazon Redshift
- Utwórz zasobnik i folder AWS S3
- Konwertuj i stosuj BigQuery Schema do Amazon Redshift przy użyciu AWS SCT
- Łączenie ze źródłem Google BigQuery
- Połącz się z Amazon Redshift Target
- Konwertuj schemat BigQuery na Amazon Redshift
- Przeanalizuj raport z oceny i zajmij się działaniami
- Zastosuj przekonwertowany schemat do docelowego przesunięcia ku czerwieni Amazon
- Migruj dane za pomocą agentów ekstrakcji danych AWS SCT
- Generowanie zaufanych magazynów i magazynów kluczy (opcjonalnie)
- Zainstaluj i uruchom agenta wyodrębniania danych
- Zarejestruj agenta ekstrakcji danych
- Dodaj wirtualne partycje dla dużych tabel (opcjonalnie)
- Utwórz lokalne zadanie migracji
- Uruchom zadanie migracji danych lokalnych
- Zobacz dane w Amazon Redshift
Utwórz bezserwerową grupę roboczą i przestrzeń nazw Amazon Redshift
W tym kroku tworzymy grupę roboczą i przestrzeń nazw Amazon Redshift Serverless. Grupa robocza to zbiór zasobów obliczeniowych, a przestrzeń nazw to zbiór obiektów bazy danych i użytkowników. Aby odizolować obciążenia i zarządzać różnymi zasobami w Amazon Redshift Serverless, możesz tworzyć przestrzenie nazw i grupy robocze oraz oddzielnie zarządzać pamięcią masową i zasobami obliczeniowymi.
Wykonaj następujące kroki, aby utworzyć grupę roboczą i przestrzeń nazw Amazon Redshift Serverless:
- Nawiguj do Konsola Amazon Redshift.
- W prawym górnym rogu wybierz region AWS, którego chcesz użyć.
- Rozwiń okienko Amazon Redshift po lewej stronie i wybierz Redshift bezserwerowy.
- Dodaj Utwórz grupę roboczą.
- W razie zamówieenia projektu nazwa grupy roboczej, wprowadź nazwę opisującą zasoby obliczeniowe.
- Sprawdź, czy VPC jest taki sam jak VPC w instancji EC2 z AWS SCT.
- Dodaj Następna.
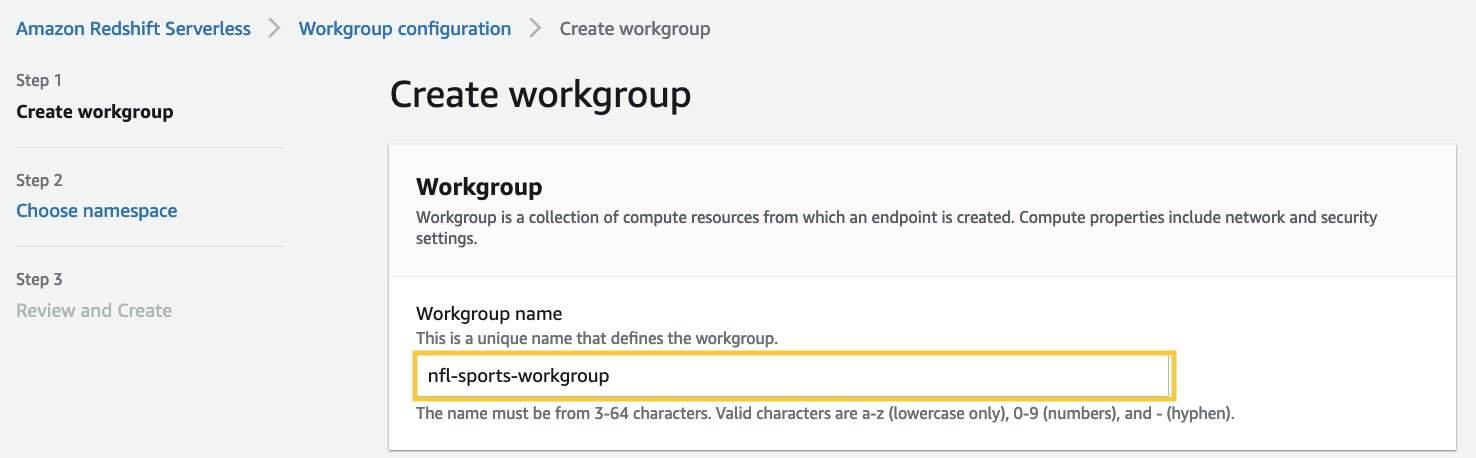
- W razie zamówieenia projektu Nazwa przestrzeni nazw, wprowadź nazwę opisującą Twój zbiór danych.
- In Nazwa bazy danych i hasło sekcji, zaznacz pole wyboru Dostosuj poświadczenia administratora.
- W razie zamówieenia projektu nazwa użytkownika administratora, wprowadź wybraną nazwę użytkownika, na przykład awsuser.
- W razie zamówieenia projektu Hasło administratora: wprowadź wybrane hasło, np MojaRedShiftPW2022.
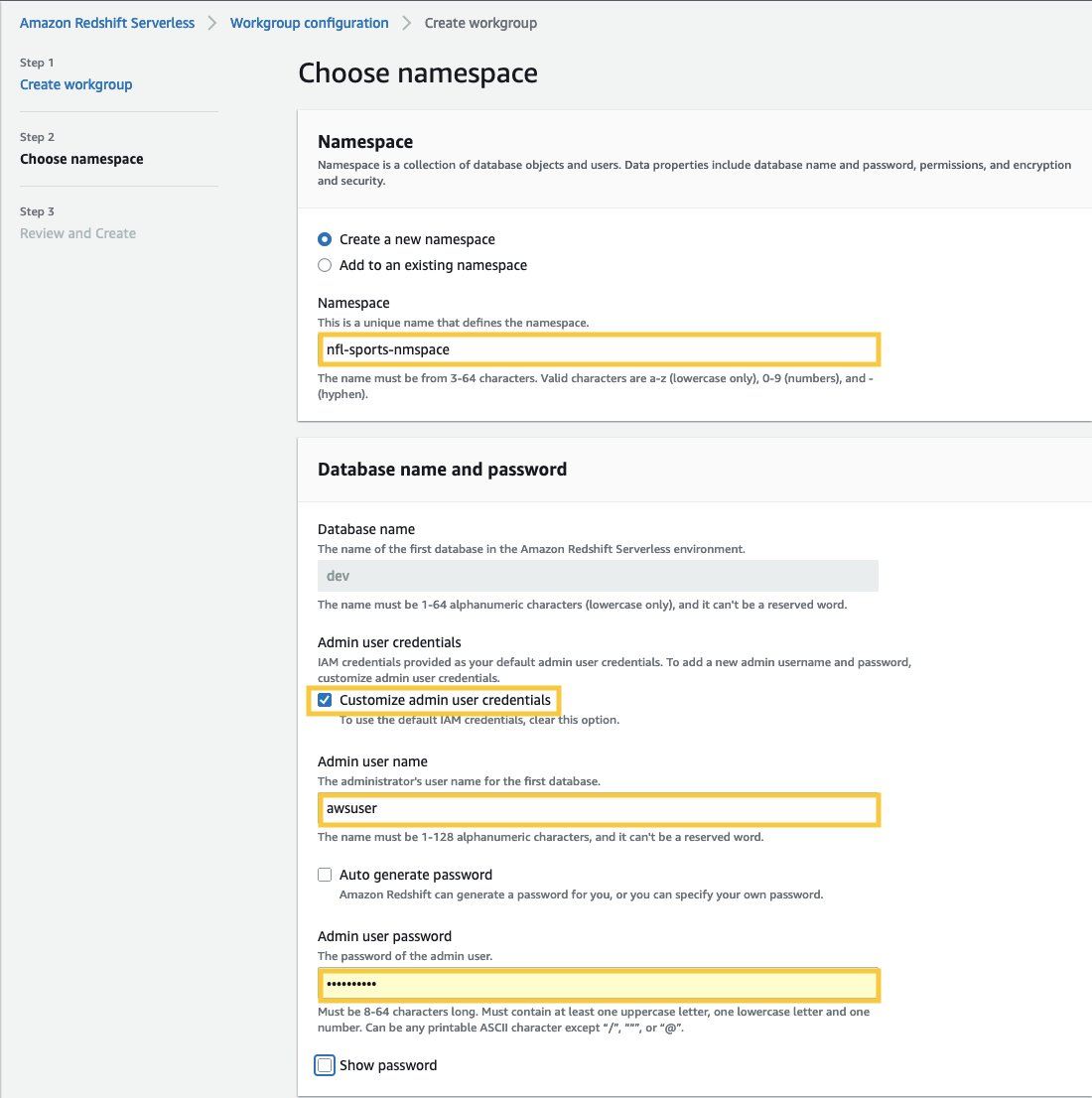
- Dodaj Dalej. Pamiętaj, że dane w przestrzeni nazw Amazon Redshift Serverless są domyślnie szyfrowane.
- W Przejrzyj i utwórz wybierz stronę Stwórz.
- Tworzenie Zarządzanie tożsamością i dostępem AWS (IAM) i ustaw ją jako domyślną w swojej przestrzeni nazw, zgodnie z poniższym opisem. Pamiętaj, że może istnieć tylko jedna domyślna rola uprawnień.
- Nawiguj do Bezserwerowy pulpit nawigacyjny Amazon Redshift.
- Pod Przestrzenie nazw / grupy robocze, wybierz właśnie utworzoną przestrzeń nazw.
- Nawigować doBezpieczeństwo i szyfrowanie.
- Pod Uprawnieniawybierz Zarządzaj rolami uprawnień.
- Nawigować do Zarządzaj rolami uprawnień. Następnie wybierz Zarządzaj rolami uprawnień rozwiń i wybierz Utwórz rolę IAM.
- Pod Określ zasobnik Amazon S3, do którego ma mieć dostęp rola IAM, wybierz jedną z następujących metod:
- Dodaj Brak dodatkowego wiadra Amazon S3 aby umożliwić utworzonej roli IAM dostęp tylko do zasobników S3 o nazwie rozpoczynającej się od przesunięcia ku czerwieni.
- Dodaj Dowolne wiadro Amazon S3 aby umożliwić utworzonej roli IAM dostęp do wszystkich zasobników S3.
- Dodaj Konkretne zasobniki Amazon S3 aby określić jeden lub więcej zasobników S3, do których ma mieć dostęp utworzona rola IAM. Następnie wybierz z tabeli jedno lub więcej wiader S3.
- Dodaj Utwórz rolę uprawnień jako domyślną. Amazon Redshift automatycznie tworzy i ustawia rolę IAM jako domyślną.
- Przechwyć punkt końcowy dla właśnie utworzonej grupy roboczej Amazon Redshift Serverless.
Utwórz wiadro i folder S3
Podczas procesu migracji danych AWS SCT wykorzystuje Amazon S3 jako obszar przejściowy dla wyodrębnionych danych. Wykonaj następujące kroki, aby utworzyć zasobnik S3:
- Nawiguj do Konsola Amazon S3
- Dodaj Utwórz wiadro, Utwórz wiadro otworzy się kreator.
- W razie zamówieenia projektu Nazwa wiadra, wprowadź unikalną nazwę zasobnika zgodną z DNS (np. unikalna nazwa-bq-rs). Zobacz zasady nazewnictwa zasobników przy wyborze imienia.
- W obszarze Region AWS wybierz region, w którym utworzono grupę roboczą Amazon Redshift Serverless.
- Wybierz Utwórz wiadro.
- W Konsola Amazon S3, przejdź do właśnie utworzonego zasobnika S3 (np. unikalna nazwa-bq-rs).
- Dodaj „Utwórz folder” aby utworzyć nowy folder.
- W razie zamówieenia projektu Nazwa folderu, wchodzić przychodzące i wybierz Utwórz folder.
Konwertuj i stosuj BigQuery Schema do Amazon Redshift przy użyciu AWS SCT
Aby przekonwertować schemat BigQuery na format Amazon Redshift, używamy AWS SCT. Zacznij od zalogowania się do utworzonej wcześniej instancji EC2, a następnie uruchom AWS SCT.
Wykonaj następujące kroki, korzystając z AWS SCT:
Połącz się ze źródłem BigQuery
- Z Menu Plik wybierać Utwórz nowy projekt.
- Wybierz lokalizację do przechowywania plików i danych projektu.
- Podaj znaczącą, ale zapadającą w pamięć nazwę projektu, np BigQuery do przesunięcia ku czerwieni Amazona.
- Aby połączyć się ze źródłową hurtownią danych BigQuery, wybierz Dodaj źródło z menu głównego.
- Dodaj bigquery i wybierz Następna. Plik Dodaj źródło pojawi się okno dialogowe.
- W razie zamówieenia projektu Nazwa połączenia, wpisz nazwę opisującą połączenie BigQuery. AWS SCT wyświetla tę nazwę w drzewie w lewym panelu.
- W razie zamówieenia projektu Kluczowa ścieżka, podaj ścieżkę do pliku klucza konta usługi, który został wcześniej utworzony w konsoli zarządzania Google Cloud.
- Dodaj Test połączenia aby sprawdzić, czy AWS SCT może połączyć się z Twoim źródłowym projektem BigQuery.
- Po pomyślnym zweryfikowaniu połączenia wybierz Skontaktuj się.

Połącz się z Amazon Redshift Target
Wykonaj następujące kroki, aby połączyć się z Amazon Redshift:
- W AWS SCT wybierz Dodaj cel z menu głównego.
- Dodaj Amazonka Przesunięcie ku czerwieni, A następnie wybierz Dalej. Połączenia Dodaj cel pojawi się okno dialogowe.
- W razie zamówieenia projektu Nazwa połączenia, wprowadź nazwę opisującą połączenie Amazon Redshift. AWS SCT wyświetla tę nazwę w drzewie w prawym panelu.
- W razie zamówieenia projektu Nazwa serwera, wprowadź przechwycony wcześniej punkt końcowy grupy roboczej Amazon Redshift Serverless.
- W razie zamówieenia projektu Port serwera, wchodzić 5439.
- W razie zamówieenia projektu Baza danych, wchodzić dev.
- W razie zamówieenia projektu Nazwa użytkownika, wprowadź nazwę użytkownika wybraną podczas tworzenia grupy roboczej Amazon Redshift Serverless.
- W razie zamówieenia projektu Hasło, wprowadź hasło wybrane podczas tworzenia grupy roboczej Amazon Redshift Serverless.
- Odznacz pole „Użyj kleju AWS”.
- Dodaj Test połączenia aby sprawdzić, czy AWS SCT może połączyć się z docelową grupą roboczą Amazon Redshift.
- Dodaj Skontaktuj się aby połączyć się z celem Amazon Redshift.
Zauważ, że alternatywnie możesz użyć wartości połączenia, które są przechowywane w Menedżer tajemnic AWS.

Konwertuj schemat BigQuery na Amazon Redshift
Po pomyślnym nawiązaniu połączenia źródłowego i docelowego zobaczysz źródłowe drzewo obiektów BigQuery w lewym okienku i docelowe drzewo obiektów Amazon Redshift w prawym okienku.
Wykonaj te czynności, aby przekonwertować schemat BigQuery na format Amazon Redshift:
- W lewym okienku kliknij prawym przyciskiem myszy schemat, który chcesz przekonwertować.
- Dodaj Przekształć schemat.
- Pojawi się okno dialogowe z pytaniem, Obiekty mogą już istnieć w docelowej bazie danych. Zastępować?. Dodaj Tak.
Po zakończeniu konwersji zobaczysz nowy schemat utworzony w panelu Amazon Redshift (prawy panel) o tej samej nazwie co schemat BigQuery.

Przykładowy schemat, którego użyliśmy, zawiera 16 tabel, 3 widoki i 3 procedury. Możesz zobaczyć te obiekty w formacie Amazon Redshift w prawym okienku. AWS SCT konwertuje cały kod BigQuery i obiekty danych do formatu Amazon Redshift. Co więcej, możesz użyć AWS SCT do konwersji zewnętrznych skryptów SQL, kodu aplikacji lub dodatkowych plików z wbudowanym SQL.
Przeanalizuj raport z oceny i zajmij się działaniami
AWS SCT tworzy raport oceniający, aby ocenić złożoność migracji. AWS SCT może konwertować większość obiektów kodu i baz danych. Jednak niektóre obiekty mogą wymagać ręcznej konwersji. AWS SCT podświetla te obiekty na niebiesko na diagramie statystyk konwersji i tworzy elementy akcji z dołączoną do nich złożonością.
Aby wyświetlić raport oceny, przełącz się z Główny widok do Widok raportu z oceny w sposób następujący:
Połączenia Podsumowanie Karta pokazuje obiekty, które zostały przekonwertowane automatycznie, oraz obiekty, które nie zostały przekonwertowane automatycznie. Zielony reprezentuje automatycznie konwertowane lub z prostymi elementami akcji. Niebieski reprezentuje średnie i złożone działania, które wymagają ręcznej interwencji.
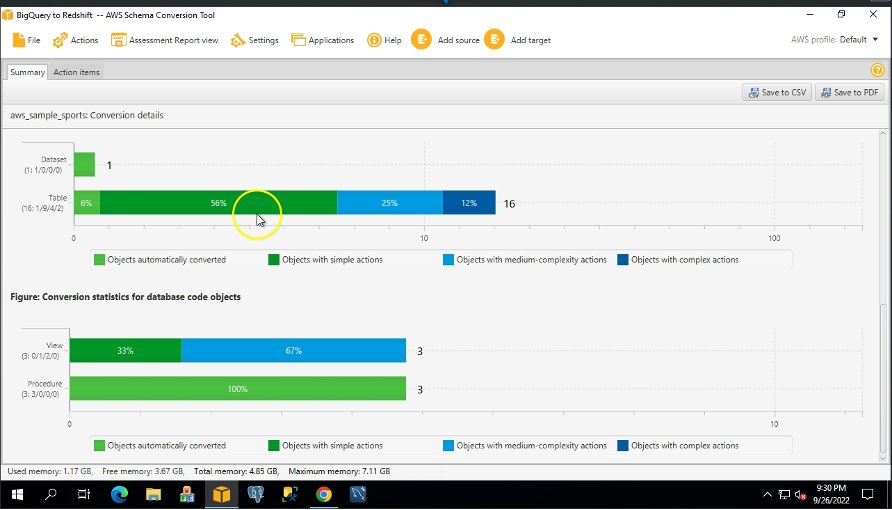
Połączenia Działania zawiera zalecane działania dla każdego problemu z konwersją. Jeśli wybierzesz element akcji z listy, AWS SCT podświetli obiekt, do którego odnosi się element akcji.
Raport zawiera również zalecenia dotyczące ręcznego konwertowania elementu schematu. Na przykład po uruchomieniu oceny szczegółowe raporty dotyczące bazy danych/schematu pokazują wysiłek wymagany do zaprojektowania i wdrożenia zaleceń dotyczących konwersji elementów akcji. Aby uzyskać więcej informacji na temat decydowania o sposobie obsługi konwersji ręcznych, zobacz Obsługa konwersji ręcznych w AWS SCT. Amazon Redshift wykonuje pewne czynności automatycznie podczas konwersji schematu na Amazon Redshift. Obiekty z tymi akcjami są oznaczone czerwonym znakiem ostrzegawczym.

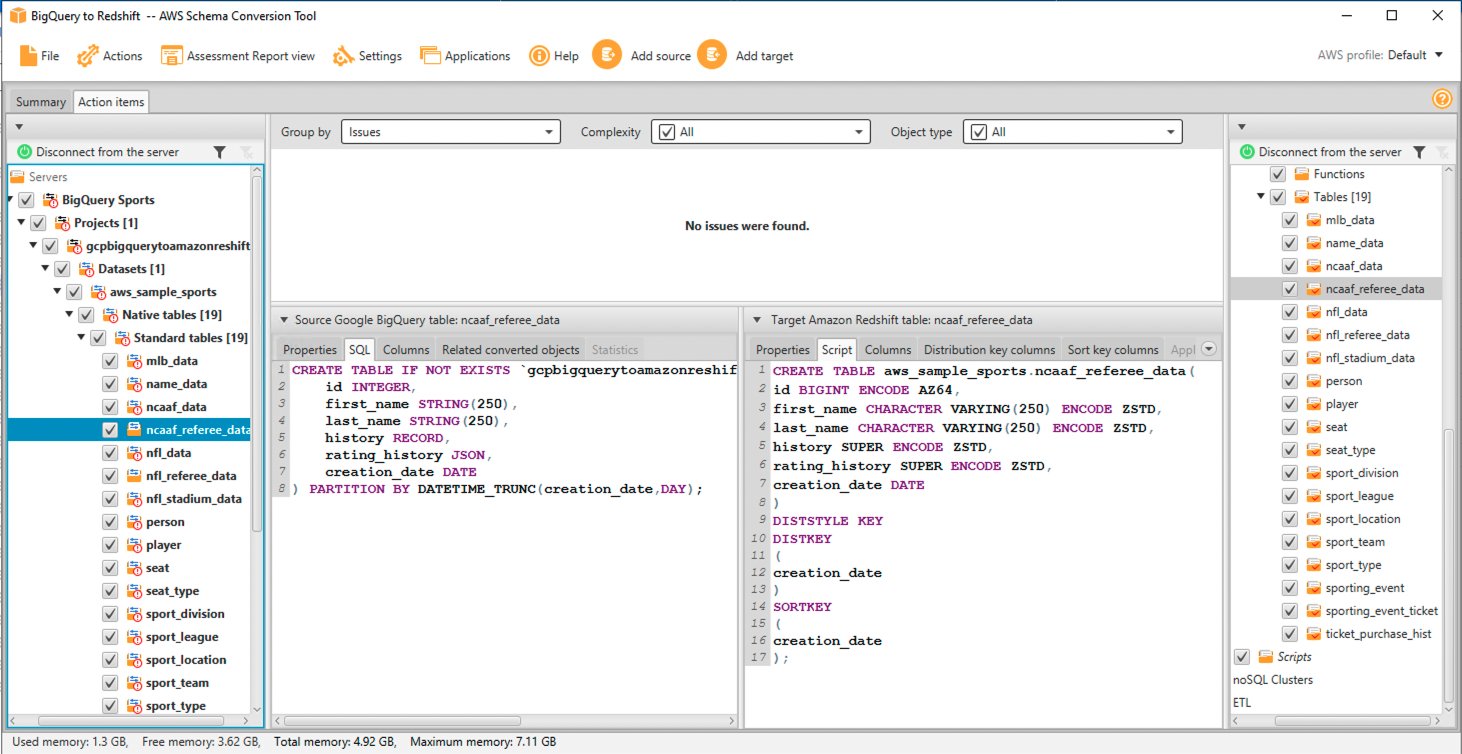
Pojedynczy obiekt DDL można oceniać i sprawdzać, wybierając go z prawego panelu, a także edytować w razie potrzeby. W poniższym przykładzie AWS SCT modyfikuje kolumny typu danych RECORD i JSON w tabeli BigQuery ncaaf_referee_data na typ danych SUPER w Amazon Redshift. Klucz partycji w tabeli ncaaf_referee_data jest konwertowany na klucz dystrybucji i klucz sortowania w Amazon Redshift.
Zastosuj przekonwertowany schemat do docelowego przesunięcia ku czerwieni Amazon
Aby zastosować przekonwertowany schemat do Amazon Redshift, wybierz przekonwertowany schemat w prawym okienku, kliknij prawym przyciskiem myszy, a następnie wybierz Zastosuj do bazy danych.
Migruj dane z BigQuery do Amazon Redshift za pomocą agentów wyodrębniania danych AWS SCT
Agenci ekstrakcji AWS SCT pobierają dane ze źródłowej bazy danych i migrują je do chmury AWS. W tym instruktażu pokazujemy, jak skonfigurować agenty ekstrakcji AWS SCT, aby wyodrębnić dane z BigQuery i przeprowadzić migrację do Amazon Redshift.
Najpierw zainstaluj agenta ekstrakcji AWS SCT na tej samej instancji systemu Windows, na której zainstalowano AWS SCT. Aby uzyskać lepszą wydajność, zalecamy, jeśli to możliwe, użycie oddzielnej instancji systemu Linux do zainstalowania agentów wyodrębniania. W przypadku dużych zestawów danych można użyć kilku agentów wyodrębniania danych, aby zwiększyć szybkość migracji danych.
Generowanie zaufanych magazynów i magazynów kluczy (opcjonalnie)
Możesz używać szyfrowanej komunikacji Secure Socket Layer (SSL) z ekstraktorami danych AWS SCT. Podczas korzystania z protokołu SSL wszystkie dane przesyłane między aplikacjami pozostają prywatne i integralne. Aby korzystać z komunikacji SSL, musisz wygenerować magazyny zaufania i magazyny kluczy za pomocą AWS SCT. Możesz pominąć ten krok, jeśli nie chcesz używać protokołu SSL. Zalecamy używanie protokołu SSL w przypadku obciążeń produkcyjnych.
Wykonaj następujące kroki, aby wygenerować magazyny zaufania i kluczy:
- W AWS SCT przejdź do Ustawienia → Ustawienia globalne → Bezpieczeństwo.
- Dodaj Wygeneruj zaufanie i magazyn kluczy.

- Wprowadź nazwę i hasło do zaufanych magazynów i magazynów kluczy oraz wybierz lokalizację, w której chcesz je przechowywać.

- Dodaj Generuj swój.
Zainstaluj i skonfiguruj agenta wyodrębniania danych
W pakiecie instalacyjnym dla AWS SCT znajdziesz agenta podfolderu (aws-schema-conversion-tool-1.0.latest.zipagents). Zlokalizuj i zainstaluj plik wykonywalny o nazwie podobnej do aws-schema-conversion-tool-extractor-xxxxxxxx.msi.
W procesie instalacji wykonaj następujące kroki, aby skonfigurować AWS SCT Data Extractor:
- W razie zamówieenia projektu Port nasłuchowy, wprowadź numer portu, na którym nasłuchuje agent. Domyślnie jest to 8192.
- W razie zamówieenia projektu Dodaj dostawcę źródłowego, wchodzić Nie, ponieważ nie potrzebujesz sterowników, aby połączyć się z BigQuery.
- W razie zamówieenia projektu Dodaj sterownik Amazon Redshift, wchodzić TAK.
- W razie zamówieenia projektu Wprowadź plik lub pliki sterownika Redshift JDBC, wprowadź lokalizację, z której pobrałeś sterowniki Amazon Redshift JDBC.
- W razie zamówieenia projektu Folder roboczy, wprowadź ścieżkę, w której agent ekstrakcji danych AWS SCT będzie przechowywać wyodrębnione dane. Folder roboczy może znajdować się na innym komputerze niż agent, a jeden folder roboczy może być współużytkowany przez wielu agentów na różnych komputerach.
- W razie zamówieenia projektu Włącz komunikację SSL, wchodzić tak. Wybierz opcję Nie, jeśli nie chcesz korzystać z protokołu SSL.
- W razie zamówieenia projektu Magazyn kluczy, wprowadź lokalizację przechowywania wybraną podczas tworzenia zaufania i magazynu kluczy.
- W razie zamówieenia projektu Hasło magazynu kluczy, wprowadź hasło do magazynu kluczy.
- W razie zamówieenia projektu Włącz uwierzytelnianie SSL klienta, wchodzić tak.
- W razie zamówieenia projektu Sklep zaufania, wprowadź lokalizację przechowywania wybraną podczas tworzenia zaufania i magazynu kluczy.
- W razie zamówieenia projektu Hasło magazynu zaufania, wprowadź hasło do magazynu zaufanych certyfikatów.
Uruchamianie agentów wyodrębniania danych
Użyj poniższej procedury, aby uruchomić środki do ekstrakcji. Powtórz tę procedurę na każdym komputerze, na którym jest zainstalowany agent wyodrębniania.
Środki ekstrakcyjne działają jako słuchacze. Po uruchomieniu agenta za pomocą tej procedury agent zaczyna nasłuchiwać instrukcji. W dalszej części wyślesz agentom instrukcje dotyczące wyodrębniania danych z hurtowni danych.
Aby uruchomić agenta ekstrakcji, przejdź do katalogu AWS SCT Data Extractor Agent. Na przykład w systemie Microsoft Windows kliknij dwukrotnie C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
- Na komputerze, na którym jest zainstalowany agent wyodrębniania, z wiersza polecenia lub okna terminala uruchom polecenie wymienione po systemie operacyjnym.
- Aby sprawdzić status agenta, uruchom tę samą komendę, ale zamień start na status.
- Aby zatrzymać agenta, uruchom to samo polecenie, ale zamień start na stop.
- Aby ponownie uruchomić agenta, uruchom ten sam plik RestartAgent.bat.
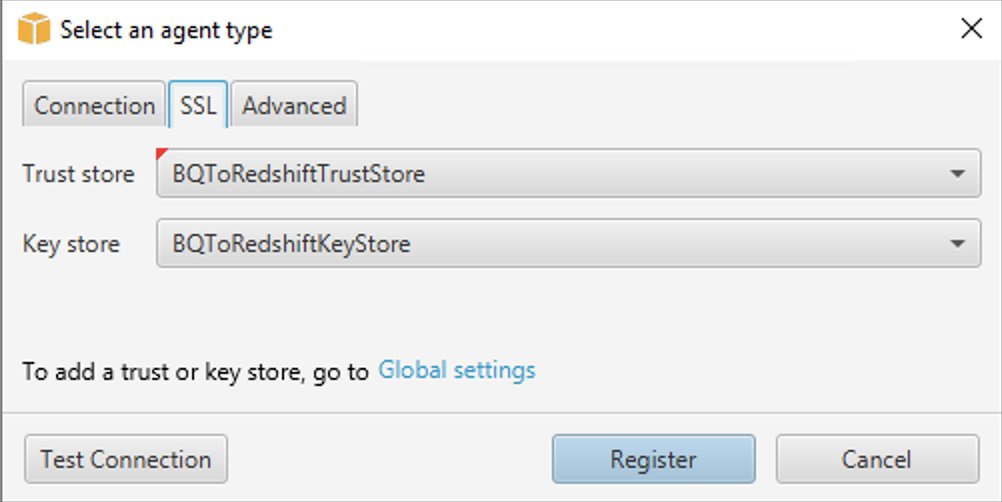
Zarejestruj agenta wyodrębniania danych
Wykonaj następujące kroki, aby zarejestrować agenta wyodrębniania danych:
- W AWS SCT zmień widok na Widok migracji danych (inny) i wybierz + Zarejestruj się.
- W zakładce połączenia:

- W razie zamówieenia projektu Opis, wprowadź nazwę identyfikującą agenta wyodrębniania danych.
- W razie zamówieenia projektu nazwa hosta, jeśli zainstalowałeś Data Extraction Agent na tej samej stacji roboczej co AWS SCT, wpisz 0.0.0.0, aby wskazać lokalnego hosta. W przeciwnym razie wprowadź nazwę hosta komputera, na którym jest zainstalowany Agent ekstrakcji danych AWS SCT. Zaleca się zainstalowanie agentów wyodrębniania danych w systemie Linux w celu uzyskania lepszej wydajności.
- W razie zamówieenia projektu Port, wprowadź numer wprowadzony dla Port nasłuchiwania podczas instalowania agenta ekstrakcji danych AWS SCT.
- Zaznacz pole wyboru, aby używać SSL (jeśli używasz SSL) do szyfrowania połączenia AWS SCT z Data Extraction Agent.
- Jeśli korzystasz z protokołu SSL, w zakładce SSL:
- W razie zamówieenia projektu sklep zaufania, wybierz nazwę magazynu zaufanych certyfikatów utworzoną podczas generowanie magazynów zaufania i kluczy (opcjonalnie możesz to pominąć, jeśli połączenie SSL nie jest potrzebne).
- W razie zamówieenia projektu sklep z kluczami, wybierz nazwę magazynu kluczy utworzoną podczas generowanie magazynów zaufania i kluczy (opcjonalnie możesz to pominąć, jeśli połączenie SSL nie jest potrzebne).

- Dodaj Test połączenia.
- Po pomyślnym sprawdzeniu poprawności połączenia wybierz Zarejestruj się.
Dodaj wirtualne partycje dla dużych tabel (opcjonalnie)
Możesz użyć AWS SCT do tworzenia partycji wirtualnych w celu optymalizacji wydajności migracji. Gdy tworzone są partycje wirtualne, AWS SCT wyodrębnia dane równolegle dla partycji. Zalecamy utworzenie partycji wirtualnych dla dużych tabel.
Wykonaj następujące kroki, aby utworzyć partycje wirtualne:
- Odznacz wszystkie obiekty w źródłowym widoku bazy danych w AWS SCT.
- Wybierz tabelę, dla której chcesz dodać wirtualne partycjonowanie.
- Kliknij prawym przyciskiem myszy na stole i wybierz Dodaj wirtualne partycjonowanie.

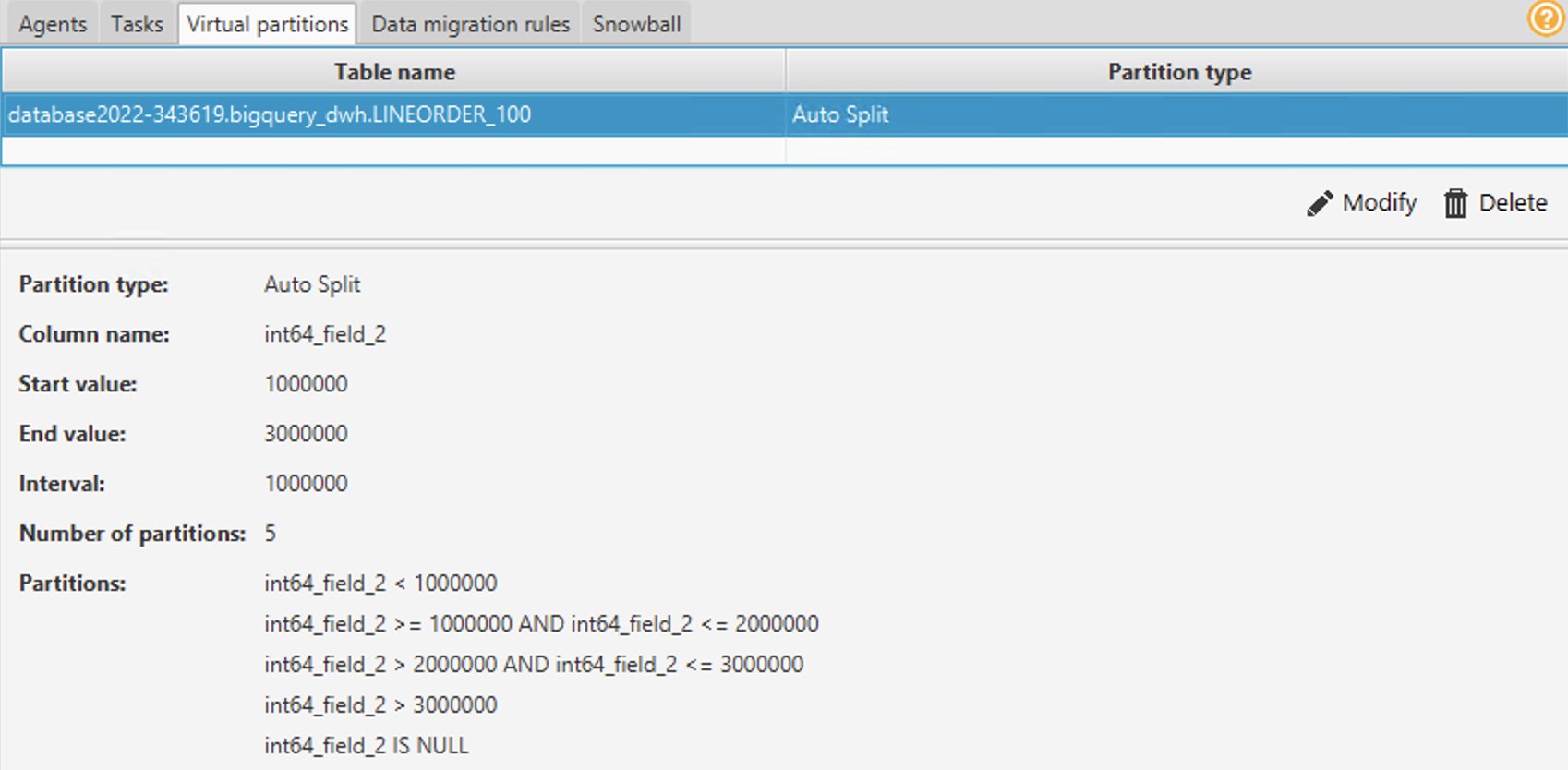
- Możesz użyć partycji List, Range lub Auto Split. Aby dowiedzieć się więcej o partycjonowaniu wirtualnym, zobacz Użyj wirtualnego partycjonowania w AWS SCT. W tym przykładzie używamy partycjonowania automatycznego podziału, które automatycznie generuje partycje zakresu. Określisz wartość początkową, wartość końcową i wielkość partycji. AWS SCT automatycznie określa partycje. Dla demonstracji, na stole Lineorder:
- W razie zamówieenia projektu Wartość początkowa, wpisz 1000000.
- W razie zamówieenia projektu Wartość końcowa, wpisz 3000000.
- W razie zamówieenia projektu Przedział, wprowadź 1000000, aby wskazać rozmiar partycji.
- Dodaj Ok.

Możesz zobaczyć partycje wygenerowane automatycznie w Wirtualne partycje patka. W tym przykładzie AWS SCT automatycznie utworzył pięć następujących partycji dla pola:
-
- >=1000000 i <=2000000
- >2000000 i <=3000000
- > 3000000
- IS NULL
Utwórz lokalne zadanie migracji
Aby przeprowadzić migrację danych z BigQuery do Amazon Redshift, utwórz, uruchom i monitoruj lokalne zadanie migracji z AWS SCT. Ten krok używa agenta wyodrębniania danych do migracji danych przez utworzenie zadania.
Wykonaj następujące kroki, aby utworzyć zadanie migracji lokalnej:
- W AWS SCT pod nazwą schematu w lewym okienku kliknij prawym przyciskiem myszy Stoły standardowe.
- Dodaj Utwórz zadanie lokalne.

- Istnieją trzy tryby migracji do wyboru:
- Wyodrębnij dane źródłowe i zapisz je na komputerze lokalnym/maszynie wirtualnej (VM), na której działa agent.
- Wyodrębnij dane i prześlij je do zasobnika S3.
- Wybierz opcję Wyodrębnij przesyłanie i kopiowanie, która wyodrębnia dane do zasobnika S3, a następnie kopiuje je do Amazon Redshift.

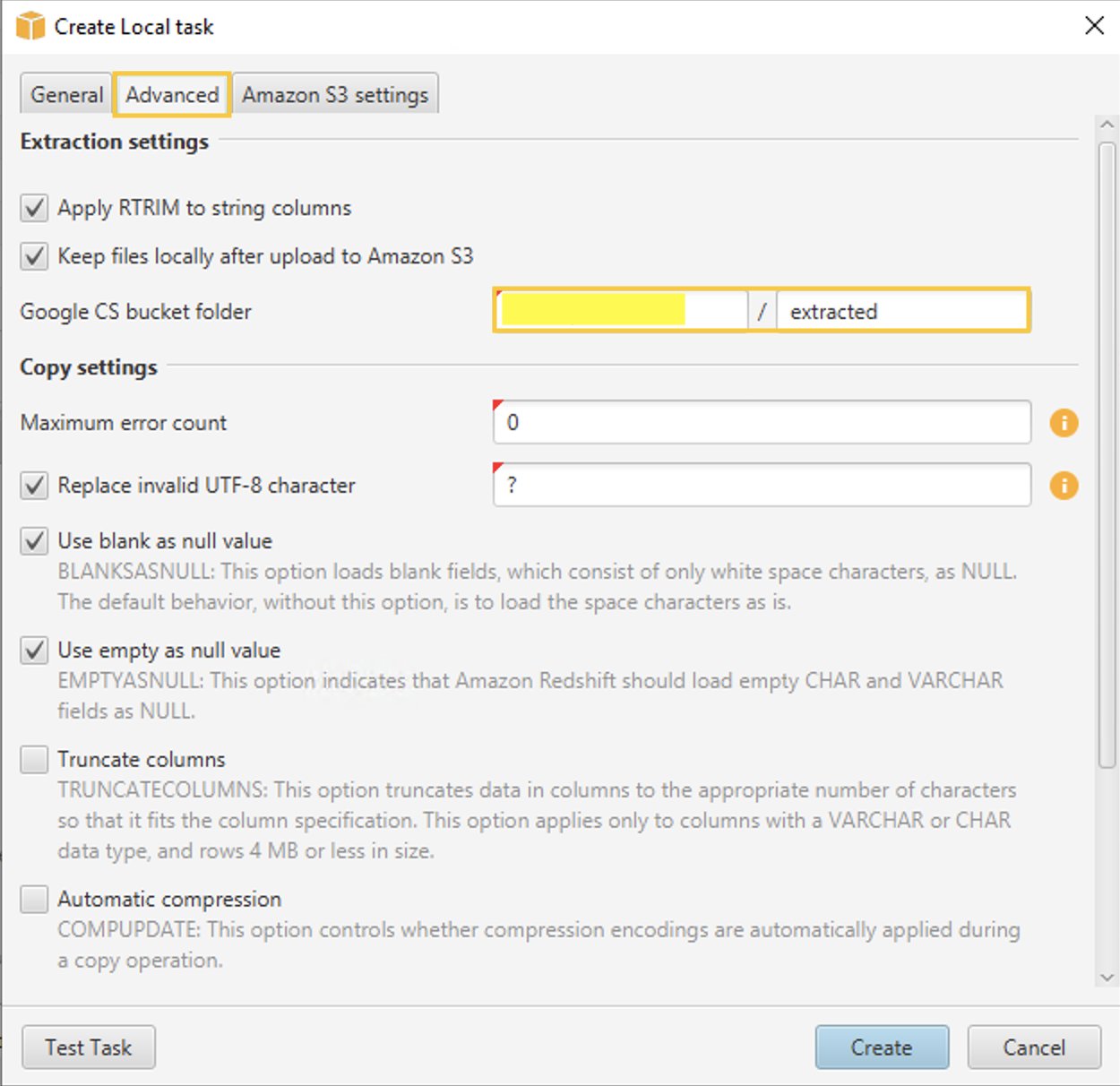
- W Zaawansowane tab, dla Folder zasobnika Google CS wprowadź zasobnik/folder Google Cloud Storage utworzony wcześniej w konsoli zarządzania GCP. AWS SCT przechowuje wyodrębnione dane w tej lokalizacji.
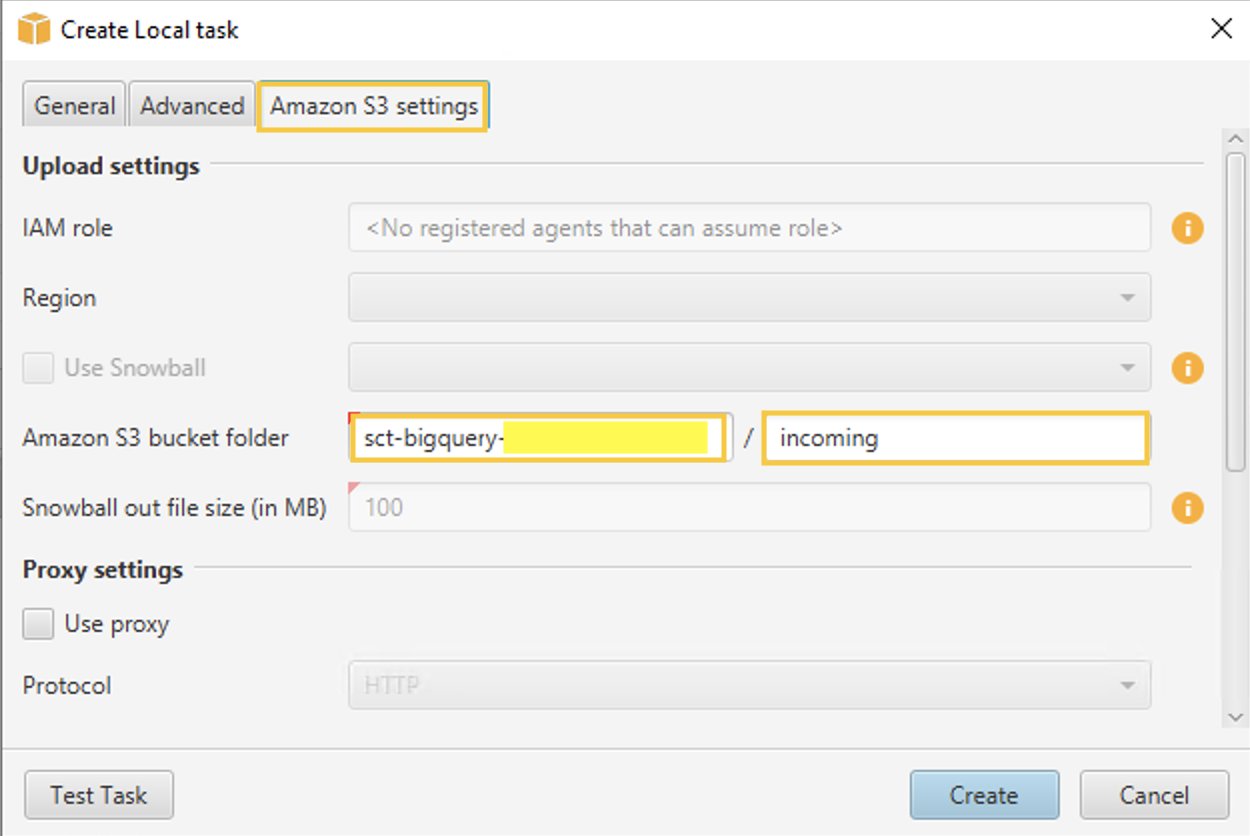
- W Ustawienia Amazon S3 tab, dla folder wiadra Amazon S3, podaj nazwy zasobników i folderów utworzonego wcześniej zasobnika S3. Agent ekstrakcji danych AWS SCT przesyła dane do zasobnika/folderu S3 przed skopiowaniem do Amazon Redshift.
- Dodaj Zadanie testowe.
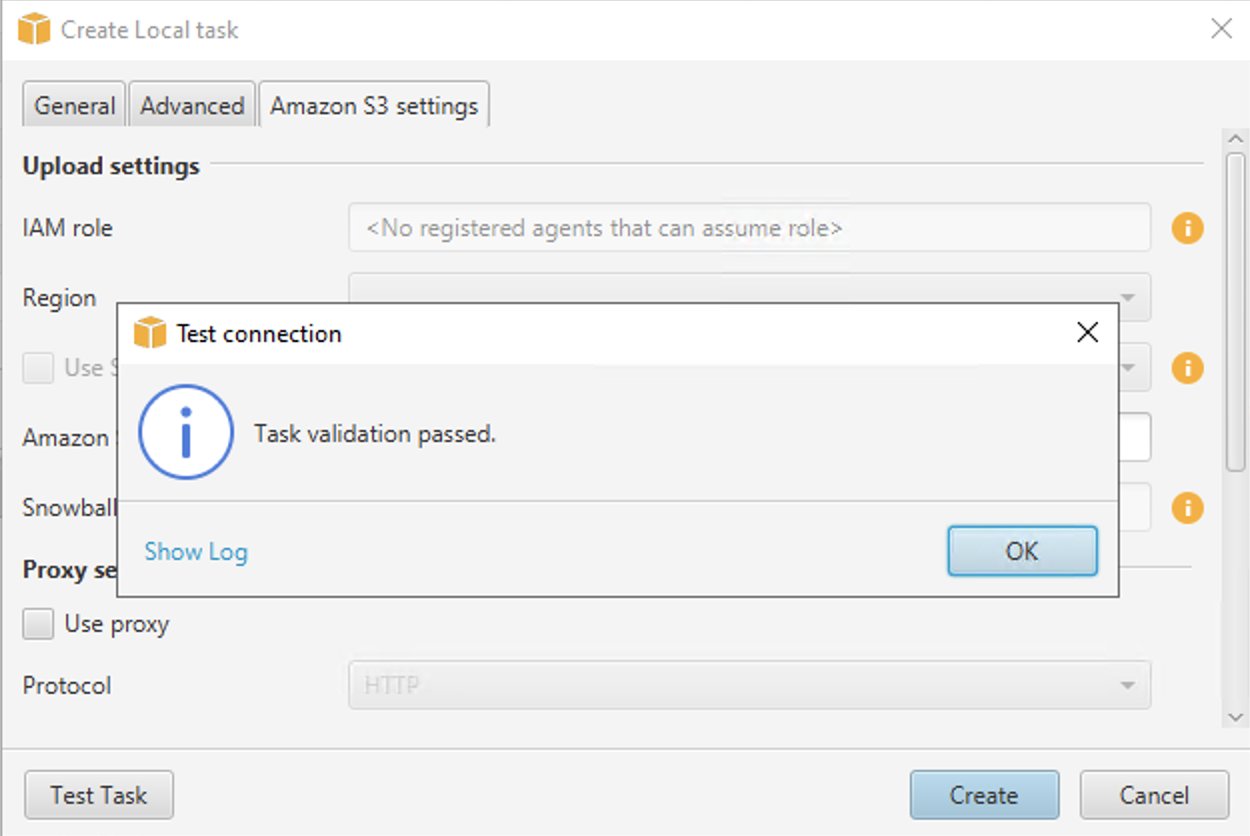
- Po pomyślnym sprawdzeniu poprawności zadania wybierz Stwórz.
Uruchom zadanie migracji danych lokalnych
Aby rozpocząć zadanie, wybierz Start przycisk w Zadania patka.

- Najpierw Data Extraction Agent wyodrębnia dane z BigQuery do zasobnika na dane GCP.
- Następnie agent przesyła dane do Amazon S3 i uruchamia polecenie kopiowania, aby przenieść dane do Amazon Redshift.
- W tym momencie AWS SCT pomyślnie przeprowadził migrację danych ze źródłowej tabeli BigQuery do tabeli Amazon Redshift.
Zobacz dane w Amazon Redshift
Po pomyślnym wykonaniu zadania migracji danych możesz połączyć się z Amazon Redshift i zweryfikować dane.
Wykonaj następujące kroki, aby zweryfikować dane w Amazon Redshift:
- Nawiguj do Edytor zapytań Amazon Redshift V2.
- Kliknij dwukrotnie nazwę utworzonej grupy roboczej Amazon Redshift Serverless.
- Wybierz Użytkownik federacyjny opcja w obszarze Uwierzytelnianie.
- Dodaj Utwórz połączenie.
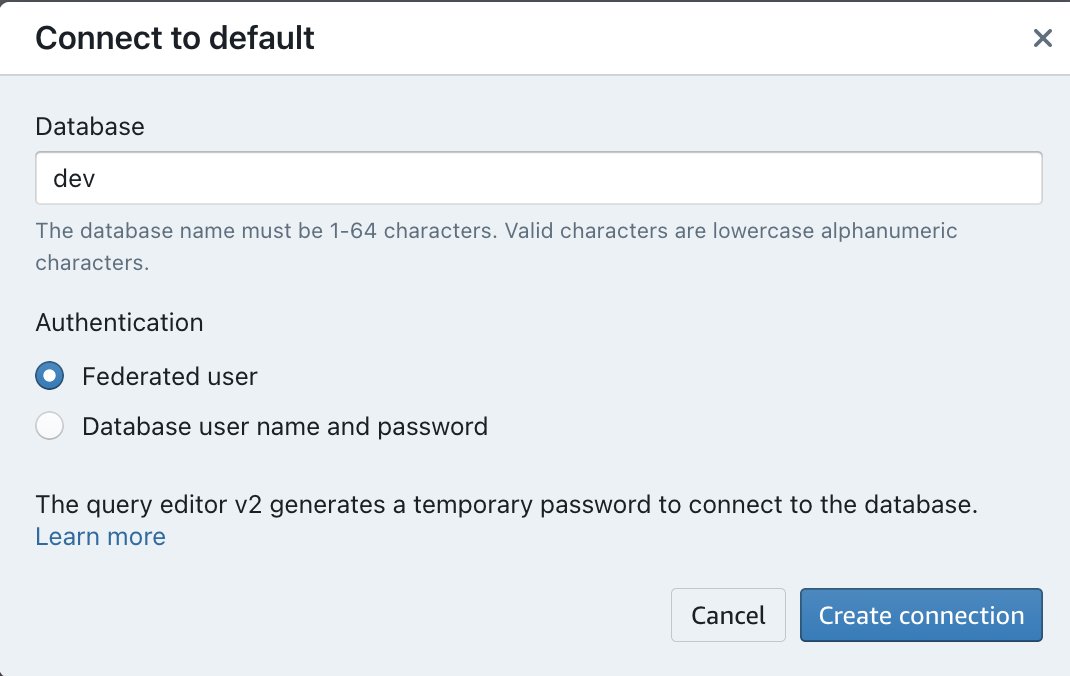
- Utwórz nowego edytora, wybierając + icon.
- W edytorze napisz zapytanie, aby wybrać nazwę schematu i nazwę tabeli/nazwę widoku, które chcesz zweryfikować. Eksploruj dane, wykonuj zapytania ad hoc oraz twórz wizualizacje, wykresy i widoki.

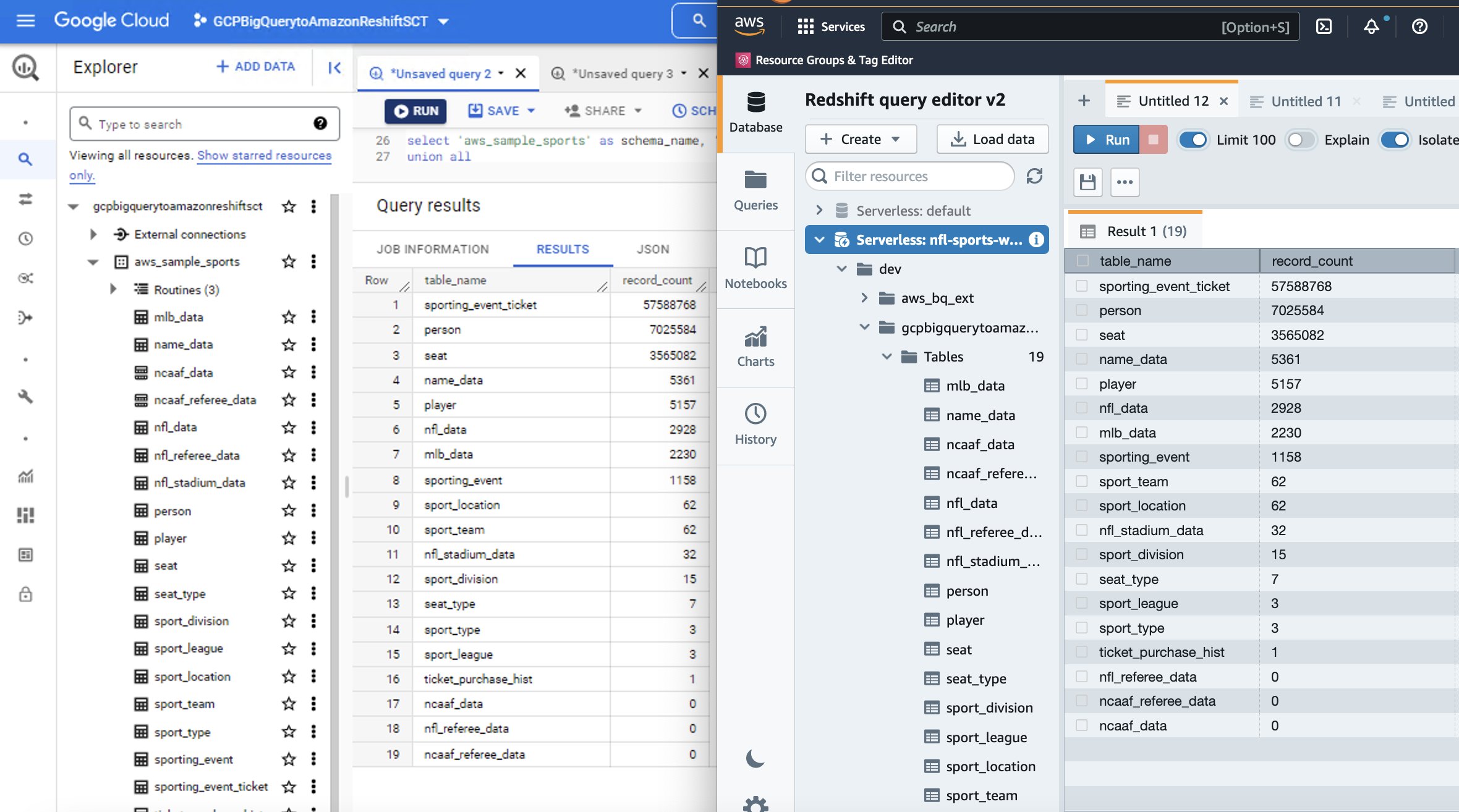
Poniżej znajduje się bezpośrednie porównanie źródłowego BigQuery i docelowego Amazon Redshift dla zestawu danych sportowych, którego użyliśmy w tym instruktażu.
Wyczyść wszystkie zasoby AWS utworzone na potrzeby tego ćwiczenia
Wykonaj następujące kroki, aby zakończyć instancję EC2:
- Nawiguj do Konsola Amazon EC2.
- W okienku nawigacji wybierz Instancje.
- Zaznacz pole wyboru dla utworzonej instancji EC2.
- Dodaj Stan instancji, A następnie Zakończ instancję.
- Dodaj Zakończyć po wyświetleniu monitu o potwierdzenie.
Wykonaj następujące kroki, aby usunąć grupę roboczą i przestrzeń nazw Amazon Redshift Serverless
- Nawigować do Bezserwerowy pulpit nawigacyjny Amazon Redshift.
- Pod Przestrzenie nazw / grupy roboczewybierz utworzony obszar roboczy.
- Pod Akcjewybierz Usuń grupę roboczą.
- Zaznacz pole wyboru Usuń skojarzoną przestrzeń nazw.
- Odznacz Utwórz ostateczną migawkę.
- Wchodzę usunąć w polu tekstowym potwierdzenia usunięcia i wybierz Usuń.

Wykonaj poniższe kroki, aby usunąć zasobnik S3
- Nawigować do Konsola Amazon S3.
- Wybierz utworzony zasobnik.
- Dodaj Usuń.
- Aby potwierdzić usunięcie, wpisz nazwę zasobnika w polu tekstowym.
- Dodaj Usuń zasobnik.
Wnioski
Migracja hurtowni danych może być trudnym, złożonym, ale satysfakcjonującym projektem. AWS SCT zmniejsza złożoność migracji hurtowni danych. Postępując zgodnie z tym przewodnikiem, możesz zrozumieć, w jaki sposób zadanie migracji danych wyodrębnia, pobiera, a następnie przenosi dane z BigQuery do Amazon Redshift. Rozwiązanie, które przedstawiliśmy w tym poście, wykonuje jednorazową migrację obiektów i danych bazy danych. Zmiany danych wprowadzone w BigQuery w trakcie migracji nie zostaną odzwierciedlone w Amazon Redshift. Gdy migracja danych jest w toku, wstrzymaj zadania ETL w BigQuery lub odtwórz ETL, wskazując Amazon Redshift po migracji. Rozważ użycie najlepsze praktyki dla AWS SCT.
AWS SCT ma pewne ograniczenia podczas używania BigQuery jako źródła. Na przykład AWS SCT nie może konwertować zapytań podrzędnych w funkcjach analitycznych, funkcjach geograficznych, statystycznych funkcjach agregujących i tak dalej. Znajdź pełną listę ograniczeń w Podręcznik użytkownika AWS SCT. Planujemy rozwiązać te ograniczenia w przyszłych wersjach. Pomimo tych ograniczeń możesz używać AWS SCT do automatycznej konwersji większości kodu BigQuery i obiektów pamięci masowej.
Pobierz i zainstaluj AWS SCT, zaloguj się do Konsola AWS, sprawdź Amazon Redshift Serverless i rozpocznij migrację!
O autorach
 Bluza z kapturem Cedricka jest Architektem Rozwiązań z naciskiem na migracje baz danych przy użyciu AWS Database Migration Service (DMS) i AWS Schema Conversion Tool (SCT) w AWS. Pracuje nad wyzwaniami związanymi z migracjami baz danych. Ściśle współpracuje z klientami biznesowymi z sektora EdTech, Energy i ISV, pomagając im w wykorzystaniu prawdziwego potencjału usługi DMS. Pomógł w migracji setek baz danych do chmury AWS przy użyciu DMS i SCT.
Bluza z kapturem Cedricka jest Architektem Rozwiązań z naciskiem na migracje baz danych przy użyciu AWS Database Migration Service (DMS) i AWS Schema Conversion Tool (SCT) w AWS. Pracuje nad wyzwaniami związanymi z migracjami baz danych. Ściśle współpracuje z klientami biznesowymi z sektora EdTech, Energy i ISV, pomagając im w wykorzystaniu prawdziwego potencjału usługi DMS. Pomógł w migracji setek baz danych do chmury AWS przy użyciu DMS i SCT.
 Amit Arora jest architektem rozwiązań ze szczególnym uwzględnieniem baz danych i analiz w AWS. Współpracuje z naszymi klientami z branży Financial Technology i Global Energy oraz certyfikowanymi partnerami AWS, zapewniając pomoc techniczną i projektując rozwiązania dla klientów w projektach migracji do chmury, pomagając klientom migrować i modernizować istniejące bazy danych do chmury AWS.
Amit Arora jest architektem rozwiązań ze szczególnym uwzględnieniem baz danych i analiz w AWS. Współpracuje z naszymi klientami z branży Financial Technology i Global Energy oraz certyfikowanymi partnerami AWS, zapewniając pomoc techniczną i projektując rozwiązania dla klientów w projektach migracji do chmury, pomagając klientom migrować i modernizować istniejące bazy danych do chmury AWS.
 Jagadisz Kumar jest analitykiem specjalizującym się w architekturze rozwiązań w AWS, koncentrującym się na Amazon Redshift. Pasjonuje się architekturą danych i pomaga klientom budować rozwiązania analityczne na dużą skalę w AWS.
Jagadisz Kumar jest analitykiem specjalizującym się w architekturze rozwiązań w AWS, koncentrującym się na Amazon Redshift. Pasjonuje się architekturą danych i pomaga klientom budować rozwiązania analityczne na dużą skalę w AWS.
 Anusza Challa jest starszym architektem rozwiązań w firmie AWS specjalizującym się w Amazon Redshift. Pomogła wielu klientom w budowaniu rozwiązań hurtowni danych na dużą skalę w chmurze i lokalnie. Anusha pasjonuje się analizą danych i nauką o danych oraz umożliwia klientom osiągnięcie sukcesu w projektach danych na dużą skalę.
Anusza Challa jest starszym architektem rozwiązań w firmie AWS specjalizującym się w Amazon Redshift. Pomogła wielu klientom w budowaniu rozwiązań hurtowni danych na dużą skalę w chmurze i lokalnie. Anusha pasjonuje się analizą danych i nauką o danych oraz umożliwia klientom osiągnięcie sukcesu w projektach danych na dużą skalę.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/migrate-google-bigquery-to-amazon-redshift-using-aws-schema-conversion-tool-sct/
- 1
- 10
- 100
- 9
- a
- O nas
- dostęp
- Konto
- Osiągać
- działać
- Działania
- działania
- Dodatkowy
- adres
- Admin
- Po
- Agent
- agentów
- Wszystkie kategorie
- już
- Amazonka
- Analityczny
- Analityczny
- analityka
- i
- Zastosowanie
- aplikacje
- Aplikuj
- architektura
- POWIERZCHNIA
- oszacowanie
- Wsparcie
- powiązany
- Uwierzytelnianie
- samochód
- automatycznie
- AWS
- baza
- BAT
- zanim
- korzyści
- Ulepsz Swój
- pomiędzy
- Duży
- Niebieski
- Pudełko
- budować
- biznes
- przycisk
- Może uzyskać
- nie może
- możliwości
- Pojemność
- Dyplomowani
- wyzwania
- wyzwanie
- zmiana
- Zmiany
- Wykresy
- ZOBACZ
- Koszyk
- wybór
- Dodaj
- Wybierając
- wybrany
- wyraźnie
- klient
- dokładnie
- Chmura
- przechowywanie w chmurze
- kod
- kolekcja
- Kolumna
- kolumny
- Komunikacja
- porównanie
- zgodny
- kompletny
- kompleks
- kompleksowość
- obliczać
- komputer
- komputery
- systemu
- Potwierdzać
- Skontaktuj się
- połączenie
- połączenia
- Łączność
- Rozważać
- zgodny
- Konsola
- zawiera
- kontroli
- Konwersja
- konwersje
- konwertować
- przeliczone
- biurowy
- Koszty:
- opłacalne
- Stwórz
- stworzony
- tworzy
- Tworzenie
- kredyt
- klient
- Rozwiązania dla klientów
- Klientów
- dane
- Analityka danych
- nauka danych
- udostępnianie danych
- Baza danych
- Bazy danych
- zbiory danych
- Decydowanie
- Domyślnie
- Kreowanie
- rozwijać
- opisać
- opisane
- Wnętrze
- stacjonarny
- Mimo
- szczegółowe
- określa
- Dialog
- różne
- wyświetlacze
- 分配
- nie
- pobieranie
- pliki do pobrania
- kierowca
- sterowniki
- podczas
- każdy
- Wcześniej
- łatwy w użyciu
- redaktor
- wysiłek
- osadzone
- umożliwiać
- Umożliwia
- umożliwiając
- szyfrowane
- szyfrowanie
- koniec końców
- Punkt końcowy
- energia
- Wchodzę
- wpisana
- Środowisko
- Eter (ETH)
- oceniać
- przykład
- Wykonuje
- Przede wszystkim system został opracowany
- odkryj
- zewnętrzny
- dodatkowy
- wyciąg
- Wyciągi
- znajomy
- FAST
- szybciej
- kilka
- pole
- filet
- Akta
- finał
- W końcu
- budżetowy
- technologia finansowa
- Znajdź
- zapora
- i terminów, a
- Elastyczność
- Skupiać
- koncentruje
- obserwuj
- następujący
- następujący sposób
- format
- Darmowy
- od
- pełny
- Funkcje
- Ponadto
- przyszłość
- Generować
- wygenerowane
- generuje
- geografia
- otrzymać
- Globalne
- Google Cloud
- Zielony
- uchwyt
- sprzęt komputerowy
- pomoc
- pomógł
- pomoc
- pomaga
- tutaj
- Wysoki
- pasemka
- wysoko
- przytrzymaj
- Strona główna
- gospodarz
- GODZINY
- dom
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- ICON
- zidentyfikować
- tożsamość
- wdrożenia
- in
- Zwiększać
- wskazać
- indywidualny
- Informacja
- wkład
- spostrzeżenia
- zainstalować
- Instalacja
- przykład
- instrukcje
- integralny
- Integruje się
- interakcji
- ingerowania
- interwencja
- problem
- IT
- szt
- Praca
- Oferty pracy
- json
- Klawisz
- Uprzejmy
- duży
- na dużą skalę
- firmy
- uruchomić
- uruchamia
- warstwa
- UCZYĆ SIĘ
- pozwala
- poziom
- Ograniczenia
- linux
- Lista
- Katalogowany
- Słuchanie
- załadować
- miejscowy
- lokalizacja
- maszyna
- zrobiony
- Główny
- Większość
- robić
- WYKONUJE
- zarządzanie
- i konserwacjami
- kierownik
- zarządzający
- podręcznik
- ręcznie
- wiele
- wymowny
- średni
- Spełnia
- Menu
- metody
- Microsoft
- Microsoft Windows
- może
- migrować
- migracja
- ML
- modele
- Nowoczesne technologie
- zmodernizować
- monitor
- jeszcze
- większość
- ruch
- msi
- wielokrotność
- Nazwa
- Nazwy
- nazywania
- Nawigacja
- Nawigacja
- Potrzebować
- Nowości
- Następny
- dostojnik
- numer
- przedmiot
- obiekty
- Oferty
- ONE
- otwiera
- operacyjny
- system operacyjny
- Optymalizacja
- Inne
- Inaczej
- pakiet
- chleb
- płyta
- Parallel
- wzmacniacz
- minęło
- namiętny
- Hasło
- ścieżka
- Zapłacić
- Szczyt
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonuje
- krok po kroku
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- możliwy
- Post
- potencjał
- praktyki
- Możliwy do przewidzenia
- Przewidywania
- warunki wstępne
- przedstawione
- poprzednio
- prywatny
- procedury
- wygląda tak
- Produkcja
- Program
- Postęp
- projekt
- projektowanie
- zapewniać
- zapewnia
- położyć
- pytanie
- szybko
- zasięg
- zrealizować
- polecić
- zalecenia
- Zalecana
- rekord
- Czerwony
- zmniejsza
- odzwierciedlenie
- region
- zarejestrować
- związane z
- prasowe
- szczątki
- powtarzać
- obsługi produkcji rolnej, która zastąpiła
- otrzymuje
- replikowane
- raport
- Raporty
- reprezentuje
- wywołań
- wymagać
- wymagany
- sprężysty
- Zasoby
- satysfakcjonujący
- Bogaty
- Kliknij prawym przyciskiem myszy
- Rola
- role
- RZĄD
- reguły
- run
- taki sam
- skalowalny
- Skala
- waga
- skalowaniem
- skanować
- nauka
- Naukowcy
- skrypty
- płynnie
- sekund
- Sekcja
- sektor
- bezpieczne
- bezpieczeństwo
- wybierając
- wrażliwy
- Bezserwerowe
- usługa
- Usługi
- zestaw
- Zestawy
- ustawienie
- w panelu ustawień
- kilka
- shared
- dzielenie
- powinien
- pokazać
- Targi
- znak
- Prosty
- pojedynczy
- Rozmiar
- Migawka
- So
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- specjalista
- prędkość
- Spędzanie
- dzielić
- SPORTOWE
- SSL
- inscenizacja
- początek
- Startowy
- rozpocznie
- oświadczenia
- statystyczny
- statystyka
- Rynek
- Ewolucja krok po kroku
- Cel
- Stop
- przechowywanie
- sklep
- przechowywany
- sklep
- sukces
- Z powodzeniem
- taki
- Wspaniały
- Przełącznik
- system
- stół
- Brać
- trwa
- cel
- Zadanie
- Techniczny
- Technologia
- terminal
- Połączenia
- Źródło
- ich
- innych firm
- trzy
- czas
- czasy
- do
- tolerancja
- narzędzie
- narzędzia
- tradycyjny
- Pociąg
- Przekształcać
- prawdziwy
- Zaufaj
- dla
- zasadniczy
- zrozumieć
- wyjątkowy
- Stosowanie
- posługiwać się
- Użytkownik
- Użytkownicy
- UPRAWOMOCNIĆ
- zatwierdzony
- Cenny
- wartość
- Wartości
- sprzedawca
- sprzedawców
- zweryfikować
- wersja
- Zobacz i wysłuchaj
- widoki
- Wirtualny
- solucja
- ostrzeżenie
- sieć
- Co
- który
- Podczas
- szerszy
- będzie
- okna
- w ciągu
- bez
- Workgroup
- pracujący
- działa
- stacja robocza
- by
- napisać
- napisany
- Twój
- zefirnet