
W miarę migracji sztucznej inteligencji z chmury do urządzenia Edge widzimy, że technologia ta jest wykorzystywana w coraz większej liczbie zastosowań – od wykrywania anomalii po zastosowania obejmujące inteligentne zakupy, nadzór, robotykę i automatyzację fabryk. Dlatego nie ma jednego, uniwersalnego rozwiązania. Jednak wraz z szybkim rozwojem urządzeń wyposażonych w kamery sztuczna inteligencja jest najczęściej stosowana do analizowania danych wideo w czasie rzeczywistym w celu automatyzacji monitorowania wideo w celu zwiększenia bezpieczeństwa, poprawy wydajności operacyjnej i zapewnienia lepszej obsługi klientów, ostatecznie zyskując przewagę konkurencyjną w swoich branżach . Aby lepiej wspierać analizę wideo, musisz zrozumieć strategie optymalizacji wydajności systemu we wdrożeniach brzegowej sztucznej inteligencji.
- Wybór silników obliczeniowych o odpowiedniej wielkości, aby osiągnąć lub przekroczyć wymagane poziomy wydajności. W przypadku aplikacji AI te silniki obliczeniowe muszą wykonywać funkcje całego potoku wizyjnego (tj. wstępne i końcowe przetwarzanie wideo, wnioskowanie przez sieć neuronową).
Może być wymagany dedykowany akcelerator AI, oddzielny lub zintegrowany z SoC (w przeciwieństwie do uruchamiania wnioskowania AI na procesorze lub karcie graficznej).
- Zrozumienie różnicy między przepustowością a opóźnieniem; przy czym przepustowość to szybkość, z jaką dane mogą być przetwarzane w systemie, a opóźnienie mierzy opóźnienie przetwarzania danych w systemie i często jest powiązane z reakcją w czasie rzeczywistym. Na przykład system może generować dane obrazu z szybkością 100 klatek na sekundę (przepustowość), ale przejście obrazu przez system zajmuje 100 ms (opóźnienie).
- Uwzględnienie możliwości łatwego skalowania wydajności sztucznej inteligencji w przyszłości w celu uwzględnienia rosnących potrzeb, zmieniających się wymagań i rozwijających się technologii (np. bardziej zaawansowanych modeli sztucznej inteligencji w celu zwiększenia funkcjonalności i dokładności). Skalowanie wydajności można osiągnąć za pomocą akceleratorów AI w formacie modułowym lub z dodatkowymi chipami akceleratorów AI.
Rzeczywiste wymagania dotyczące wydajności zależą od aplikacji. Zazwyczaj można się spodziewać, że do celów analizy wideo system musi przetwarzać strumienie danych napływające z kamer z szybkością 30-60 klatek na sekundę i rozdzielczością 1080p lub 4k. Kamera obsługująca sztuczną inteligencję przetwarzałaby pojedynczy strumień; urządzenie brzegowe przetwarzałoby wiele strumieni równolegle. W obu przypadkach brzegowy system AI musi obsługiwać funkcje wstępnego przetwarzania, aby przekształcić dane z czujnika kamery w format odpowiadający wymaganiom wejściowym sekcji wnioskowania AI (rysunek 1).
Funkcje wstępnego przetwarzania pobierają surowe dane i wykonują zadania, takie jak zmiana rozmiaru, normalizacja i konwersja przestrzeni kolorów, przed wprowadzeniem danych wejściowych do modelu działającego na akceleratorze AI. Przetwarzanie wstępne może wykorzystywać wydajne biblioteki przetwarzania obrazów, takie jak OpenCV, w celu skrócenia czasu przetwarzania wstępnego. Przetwarzanie końcowe obejmuje analizę wyników wnioskowania. Wykorzystuje takie zadania, jak tłumienie niemaksymalne (NMS interpretuje dane wyjściowe większości modeli wykrywania obiektów) i wyświetlanie obrazu w celu generowania praktycznych spostrzeżeń, takich jak obwiednie, etykiety klas lub wskaźniki ufności.

Rysunek 1. W przypadku wnioskowania modelu AI funkcje przetwarzania wstępnego i końcowego są zwykle wykonywane na procesorze aplikacji.
Wnioskowanie o modelu AI może wiązać się z dodatkowym wyzwaniem polegającym na przetwarzaniu wielu modeli sieci neuronowych na ramkę, w zależności od możliwości aplikacji. Aplikacje do przetwarzania obrazu komputerowego zwykle obejmują wiele zadań AI wymagających potoku wielu modeli. Co więcej, dane wyjściowe jednego modelu są często danymi wejściowymi następnego modelu. Innymi słowy, modele w aplikacji często są od siebie zależne i muszą być wykonywane sekwencyjnie. Dokładny zestaw modeli do wykonania może nie być statyczny i może zmieniać się dynamicznie, nawet klatka po klatce.
Wyzwanie polegające na dynamicznym uruchamianiu wielu modeli wymaga zewnętrznego akceleratora AI z dedykowaną i wystarczająco dużą pamięcią do przechowywania modeli. Często zintegrowany akcelerator AI w SoC nie jest w stanie poradzić sobie z obciążeniem wielomodelowym ze względu na ograniczenia nałożone przez podsystem pamięci współdzielonej i inne zasoby w SoC.
Na przykład śledzenie obiektów w oparciu o przewidywanie ruchu opiera się na ciągłych detekcjach w celu określenia wektora, który służy do identyfikacji śledzonego obiektu w przyszłej pozycji. Skuteczność tego podejścia jest ograniczona, ponieważ brakuje mu prawdziwej możliwości ponownej identyfikacji. Dzięki przewidywaniu ruchu ślad obiektu może zostać utracony w wyniku pominięcia wykrycia, okluzji lub nawet chwilowego opuszczenia przez obiekt pola widzenia. Po utracie nie ma możliwości ponownego powiązania śladu obiektu. Dodanie ponownej identyfikacji rozwiązuje to ograniczenie, ale wymaga osadzenia wyglądu wizualnego (tj. odcisku palca obrazu). Osadzanie wyglądu wymaga, aby druga sieć wygenerowała wektor cech poprzez przetworzenie obrazu zawartego wewnątrz ramki ograniczającej obiektu wykrytego przez pierwszą sieć. To osadzenie może zostać wykorzystane do ponownej identyfikacji obiektu, niezależnie od czasu i przestrzeni. Ponieważ dla każdego obiektu wykrytego w polu widzenia należy wygenerować osadzanie, wymagania dotyczące przetwarzania rosną w miarę zwiększania się ruchu w scenie. Śledzenie obiektów z ponowną identyfikacją wymaga dokładnego rozważenia pomiędzy wykrywaniem z dużą dokładnością / wysoką rozdzielczością / dużą liczbą klatek na sekundę a zarezerwowaniem wystarczającego narzutu dla skalowalności osadzania. Jednym ze sposobów rozwiązania wymagań dotyczących przetwarzania jest zastosowanie dedykowanego akceleratora AI. Jak wspomniano wcześniej, silnik AI SoC może cierpieć z powodu braku zasobów pamięci współdzielonej. Optymalizację modelu można również zastosować w celu obniżenia wymagań dotyczących przetwarzania, ale może to mieć wpływ na wydajność i/lub dokładność.
W inteligentnej kamerze lub urządzeniu brzegowym zintegrowany SoC (tj. procesor hosta) pobiera klatki wideo i wykonuje etapy wstępnego przetwarzania, które opisaliśmy wcześniej. Funkcje te można realizować za pomocą rdzeni procesora lub procesora graficznego SoC (jeśli jest dostępny), ale można je również wykonywać za pomocą dedykowanych akceleratorów sprzętowych w SoC (np. procesora sygnału obrazu). Po zakończeniu tych etapów wstępnego przetwarzania akcelerator AI zintegrowany z SoC może następnie uzyskać bezpośredni dostęp do skwantowanych danych wejściowych z pamięci systemowej lub, w przypadku dyskretnego akceleratora AI, dane wejściowe są następnie dostarczane do wnioskowania, zazwyczaj przez Interfejs USB lub PCIe.
Zintegrowany SoC może zawierać szereg jednostek obliczeniowych, w tym procesory CPU, procesory graficzne, akcelerator AI, procesory wizyjne, kodery/dekodery wideo, procesor sygnału obrazu (ISP) i inne. Wszystkie te jednostki obliczeniowe korzystają z tej samej magistrali pamięci, dzięki czemu mają dostęp do tej samej pamięci. Co więcej, procesor i procesor graficzny mogą również odgrywać rolę we wnioskowaniu, a jednostki te będą zajęte wykonywaniem innych zadań we wdrożonym systemie. To właśnie rozumiemy przez obciążenie na poziomie systemu (rysunek 2).
Wielu programistów błędnie ocenia wydajność wbudowanego akceleratora AI w SoC, nie biorąc pod uwagę wpływu narzutu na poziomie systemu na całkowitą wydajność. Jako przykład rozważ przeprowadzenie testu porównawczego YOLO na akceleratorze AI 50 TOPS zintegrowanym z SoC, który może uzyskać wynik testu porównawczego wynoszący 100 wniosków na sekundę (IPS). Jednak we wdrożonym systemie z aktywnymi wszystkimi innymi jednostkami obliczeniowymi te 50 TOPS mogłoby zredukować się do około 12 TOPS, a ogólna wydajność dałaby jedynie 25 IPS, przy założeniu dużego współczynnika wykorzystania wynoszącego 25%. Jeśli platforma stale przetwarza strumienie wideo, obciążenie systemu jest zawsze czynnikiem. Alternatywnie, w przypadku dyskretnego akceleratora AI (np. Kinara Ara-1, Hailo-8, Intel Myriad X) wykorzystanie na poziomie systemu może przekraczać 90%, ponieważ gdy układ SoC hosta inicjuje funkcję wnioskowania i przesyła dane wejściowe modelu AI danych, akcelerator działa autonomicznie, wykorzystując dedykowaną pamięć w celu uzyskania dostępu do wag i parametrów modeli.
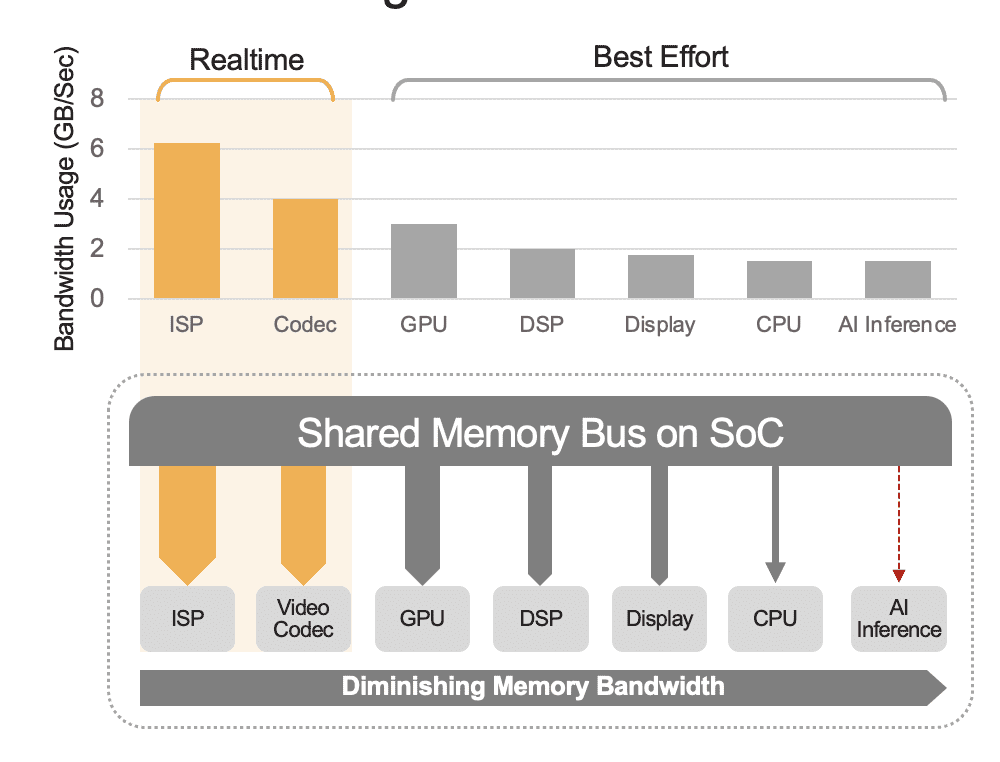
Rysunek 2. Szyna pamięci współdzielonej będzie regulować wydajność na poziomie systemu, pokazaną tutaj z szacunkowymi wartościami. Rzeczywiste wartości będą się różnić w zależności od modelu użycia aplikacji i konfiguracji jednostki obliczeniowej SoC.
Do tego momentu omawialiśmy wydajność AI pod względem liczby klatek na sekundę i TOPS. Jednak niskie opóźnienia to kolejny ważny wymóg zapewniający responsywność systemu w czasie rzeczywistym. Na przykład w grach małe opóźnienia mają kluczowe znaczenie dla płynnej i responsywnej rozgrywki, szczególnie w grach sterowanych ruchem i systemach rzeczywistości wirtualnej (VR). W systemach jazdy autonomicznej małe opóźnienia są niezbędne do wykrywania obiektów w czasie rzeczywistym, rozpoznawania pieszych, wykrywania pasa ruchu i rozpoznawania znaków drogowych, aby uniknąć narażania bezpieczeństwa. Autonomiczne systemy napędowe zazwyczaj wymagają całkowitego opóźnienia mniejszego niż 150 ms od wykrycia do faktycznego działania. Podobnie w produkcji małe opóźnienia są niezbędne do wykrywania defektów w czasie rzeczywistym i rozpoznawania anomalii, a wskazówki robotyczne zależą od analityki wideo o niskim opóźnieniu, aby zapewnić wydajną pracę i zminimalizować przestoje w produkcji.
Ogólnie rzecz biorąc, w aplikacji do analizy wideo występują trzy elementy opóźnienia (rysunek 3):
- Opóźnienie przechwytywania danych to czas od przechwycenia klatki wideo przez czujnik kamery do udostępnienia klatki systemowi analitycznemu w celu przetworzenia. Możesz zoptymalizować to opóźnienie, wybierając kamerę z szybkim czujnikiem i procesorem o niskim opóźnieniu, wybierając optymalną liczbę klatek na sekundę i stosując wydajne formaty kompresji wideo.
- Opóźnienie przesyłania danych to czas, w którym przechwycone i skompresowane dane wideo są przesyłane z kamery do urządzeń brzegowych lub serwerów lokalnych. Obejmuje to opóźnienia przetwarzania sieci, które występują w każdym punkcie końcowym.
- Opóźnienie przetwarzania danych odnosi się do czasu, w jakim urządzenia brzegowe wykonują zadania przetwarzania wideo, takie jak dekompresja klatek i algorytmy analityczne (np. śledzenie obiektów w oparciu o przewidywanie ruchu, rozpoznawanie twarzy). Jak wskazano wcześniej, opóźnienie przetwarzania jest jeszcze ważniejsze w przypadku aplikacji, które muszą uruchamiać wiele modeli AI dla każdej klatki wideo.
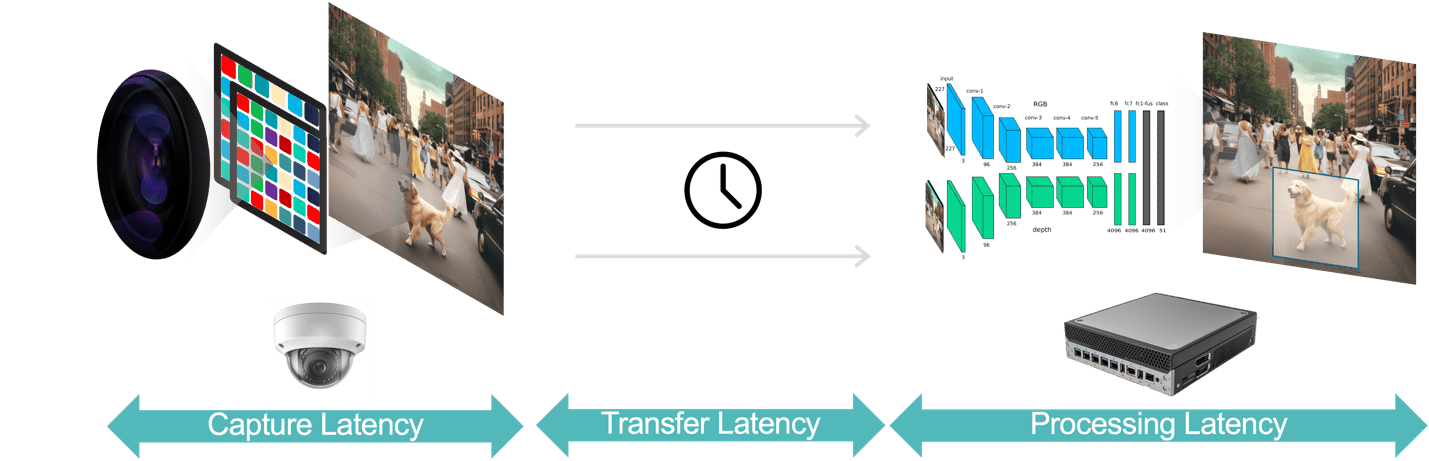
Rysunek 3. Potok analizy wideo składa się z przechwytywania, przesyłania i przetwarzania danych.
Opóźnienie przetwarzania danych można zoptymalizować za pomocą akceleratora AI o architekturze zaprojektowanej w celu minimalizacji przepływu danych w chipie oraz między obliczeniami a różnymi poziomami hierarchii pamięci. Ponadto, aby poprawić opóźnienia i wydajność na poziomie systemu, architektura musi obsługiwać zerowy (lub prawie zerowy) czas przełączania między modelami, aby lepiej obsługiwać aplikacje wielomodelowe, o których mówiliśmy wcześniej. Innym czynnikiem wpływającym zarówno na poprawę wydajności, jak i opóźnień jest elastyczność algorytmiczna. Innymi słowy, niektóre architektury są zaprojektowane pod kątem optymalnego działania tylko w przypadku określonych modeli sztucznej inteligencji, ale w obliczu szybko zmieniającego się środowiska sztucznej inteligencji nowe modele zapewniające wyższą wydajność i większą dokładność pojawiają się niemal co drugi dzień. Dlatego wybierz procesor brzegowy AI bez praktycznych ograniczeń dotyczących topologii modelu, operatorów i rozmiaru.
Aby zmaksymalizować wydajność urządzenia brzegowego AI, należy wziąć pod uwagę wiele czynników, w tym wymagania dotyczące wydajności i opóźnień oraz obciążenie systemu. Skuteczna strategia powinna uwzględniać zewnętrzny akcelerator AI, aby pokonać ograniczenia pamięci i wydajności w silniku AI SoC.
CH Serio Chee to utalentowany dyrektor ds. marketingu i zarządzania produktami. Chee ma rozległe doświadczenie w promowaniu produktów i rozwiązań w branży półprzewodników, koncentrując się na opartej na wizji sztucznej inteligencji, łączności i interfejsach wideo dla wielu rynków, w tym przedsiębiorstw i konsumentów. Jako przedsiębiorca Chee był współzałożycielem dwóch start-upów zajmujących się półprzewodnikami wideo, które zostały przejęte przez publiczną firmę produkującą półprzewodniki. Chee kieruje zespołami zajmującymi się marketingiem produktów i lubi pracować z małym zespołem, który koncentruje się na osiąganiu świetnych wyników.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :ma
- :Jest
- :nie
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- zdolność
- akcelerator
- akceleratory
- dostęp
- Dostęp
- pomieścić
- wykonać
- precyzja
- osiągnięcia
- nabyty
- Przejmuje
- w poprzek
- Działania
- aktywny
- rzeczywisty
- dodanie
- Dodatkowy
- przyjęty
- zaawansowany
- Po
- ponownie
- AI
- Silnik AI
- Modele AI
- algorytmiczny
- Algorytmy
- Wszystkie kategorie
- również
- zawsze
- an
- analiza
- analityka
- Analizując
- i
- wykrywanie anomalii
- Inne
- Zastosowanie
- aplikacje
- podejście
- architektura
- SĄ
- AS
- powiązany
- At
- zautomatyzować
- Automatyzacja
- autonomiczny
- autonomicznie
- dostępność
- dostępny
- uniknąć
- na podstawie
- podstawa
- BE
- bo
- staje się
- być
- zanim
- jest
- Benchmark
- Ulepsz Swój
- pomiędzy
- obie
- Pudełko
- Skrzynki
- wbudowany
- autobus
- zajęty
- ale
- by
- aparat fotograficzny
- kamery
- CAN
- możliwości
- zdolność
- zdobyć
- Zajęte
- Przechwytywanie
- ostrożny
- walizka
- Etui
- wyzwanie
- wymiana pieniędzy
- żeton
- Frytki
- Wybierając
- klasa
- Chmura
- kolor
- przyjście
- sukcesy firma
- konkurencyjny
- Zakończony
- składniki
- kompromis
- obliczenia
- obliczeniowy
- obliczać
- komputer
- Wizja komputerowa
- Aplikacje do widzenia komputerowego
- pewność siebie
- systemu
- Łączność
- w konsekwencji
- Rozważać
- wynagrodzenie
- za
- wobec
- składa się
- Ograniczenia
- konsument
- zawierać
- zawarte
- ciągły
- bez przerwy
- Konwersja
- mógłby
- CPU
- krytyczny
- klient
- dane
- analiza danych
- dzień
- dedykowane
- opóźnienie
- opóźnienia
- dostarczyć
- dostarczona
- zależny
- W zależności
- wdrażane
- wdrożenia
- opisane
- zaprojektowany
- wykryte
- Wykrywanie
- Ustalać
- deweloperzy
- urządzenia
- różnica
- bezpośrednio
- omówione
- Wyświetlacz
- przestojów
- jazdy
- z powodu
- dynamicznie
- e
- każdy
- Wcześniej
- z łatwością
- krawędź
- efekt
- skuteczność
- efektywność
- efektywność
- wydajny
- bądź
- osadzanie
- zakończenia
- koniec końców
- silnik
- silniki
- wzmacniać
- zapewnić
- Enterprise
- Cały
- Przedsiębiorca
- Środowisko
- niezbędny
- szacunkowa
- oceniać
- Parzyste
- Każdy
- ewoluuje
- przykład
- przekraczać
- wykonać
- wykonany
- wykonawczy
- oczekiwać
- doświadczenie
- Doświadczenia
- rozległy
- Szerokie doświadczenie
- zewnętrzny
- Twarz
- rozpoznawanie twarzy
- czynnik
- Czynniki
- fabryka
- FAST
- Cecha
- karmienie
- pole
- Postać
- odcisk palca
- i terminów, a
- Elastyczność
- koncentruje
- skupienie
- W razie zamówieenia projektu
- format
- FRAME
- od
- funkcjonować
- Funkcjonalność
- Funkcje
- Ponadto
- przyszłość
- zyskuje
- Games
- gier
- wrażenia z gry
- Ogólne
- Generować
- wygenerowane
- hojny
- Go
- GPU
- GPU
- wspaniały
- większy
- Rozwój
- Wzrost
- poradnictwo
- sprzęt komputerowy
- Have
- stąd
- tutaj
- hierarchia
- Wysoki
- wyższy
- gospodarz
- HTTPS
- i
- zidentyfikować
- if
- obraz
- Rezultat
- ważny
- nałożone
- podnieść
- ulepszony
- in
- W innych
- obejmuje
- Włącznie z
- Zwiększać
- wzrosła
- przemysłowa
- przemysł
- Inicjuje
- wkład
- wewnątrz
- spostrzeżenia
- zintegrowany
- Intel
- Interfejs
- interfejsy
- najnowszych
- angażować
- dotyczy
- niezależny
- ISP
- IT
- JEGO
- Knuggety
- Etykiety
- Brak
- Tor
- duży
- Utajenie
- pozostawiając
- Doprowadziło
- mniej
- poziomy
- biblioteki
- lubić
- ograniczenie
- Ograniczenia
- Ograniczony
- miejscowy
- stracił
- niski
- niższy
- zarządzanie
- i konserwacjami
- produkcja
- wiele
- Marketing
- rynki
- Maksymalizuj
- maksymalizacji
- Może..
- oznaczać
- środków
- Poznaj nasz
- Pamięć
- wzmiankowany
- może
- nieodebranych
- model
- modele
- moduł
- monitorowanie
- jeszcze
- większość
- ruch
- ruch
- wielokrotność
- musi
- miriada
- Blisko
- wymagania
- sieć
- Nerwowy
- sieci neuronowe
- Nowości
- Następny
- Nie
- przedmiot
- Wykrywanie obiektów
- występować
- of
- często
- on
- pewnego razu
- ONE
- tylko
- OpenCV
- działanie
- operacyjny
- operatorzy
- przeciwny
- Optymalny
- optymalizacja
- Optymalizacja
- zoptymalizowane
- optymalizacji
- or
- Inne
- na zewnątrz
- wydajność
- koniec
- ogólny
- Przezwyciężać
- Parallel
- parametry
- szczególnie
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- wykonywania
- wykonuje
- rurociąg
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- punkt
- position
- przetwarzanie końcowe
- Praktyczny
- przepowiednia
- wygląda tak
- obrobiony
- przetwarzanie
- Procesor
- Procesory
- Produkt
- Produkcja
- Produkty
- promowanie
- zapewniać
- publiczny
- zasięg
- nośny
- szybki
- szybko
- Kurs
- ceny
- Surowy
- surowe dane
- real
- w czasie rzeczywistym
- Rzeczywistość
- uznanie
- zmniejszyć
- odnosi
- wymagać
- wymagany
- wymaganie
- wymagania
- Wymaga
- Rozkład
- Zasoby
- czuły
- Ograniczenia
- dalsze
- Efekt
- robotyka
- Rola
- run
- bieganie
- działa
- Bezpieczeństwo
- taki sam
- Skalowalność
- Skala
- skala ai
- skalowaniem
- scena
- wyniki
- bezszwowy
- druga
- Sekcja
- widzieć
- wydaje
- wybierając
- Semiconductor
- zestaw
- Share
- shared
- Zakupy
- powinien
- pokazane
- znak
- Signal
- Podobnie
- ponieważ
- pojedynczy
- Rozmiar
- mały
- mądry
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Rozwiązuje
- kilka
- coś
- Typ przestrzeni
- specyficzny
- start-up
- Cel
- sklep
- strategie
- Strategia
- strumień
- Strumienie
- udany
- taki
- wystarczający
- wsparcie
- tłumienie
- inwigilacja
- system
- systemy
- Brać
- trwa
- zadania
- zespół
- Zespoły
- Technologies
- Technologia
- REGULAMIN
- niż
- że
- Połączenia
- Przyszłość
- ich
- następnie
- Tam.
- w związku z tym
- Te
- one
- to
- tych
- trzy
- Przez
- wydajność
- czas
- czasy
- do
- Topy
- Kwota produktów:
- śledzić
- Śledzenie
- ruch drogowy
- przenieść
- transfery
- Przekształcać
- podróżować
- prawdziwy
- drugiej
- zazwyczaj
- Ostatecznie
- niezdolny
- zrozumieć
- jednostka
- jednostek
- Stosowanie
- usb
- posługiwać się
- używany
- zastosowania
- za pomocą
- zazwyczaj
- Wykorzystując
- Wartości
- różnorodność
- różnorodny
- Wideo
- Zobacz i wysłuchaj
- Wirtualny
- Wirtualna rzeczywistość
- wizja
- istotny
- vr
- Droga..
- we
- były
- Co
- czy
- który
- szeroko
- będzie
- w
- bez
- słowa
- pracujący
- by
- X
- Wydajność
- Yolo
- ty
- Twój
- zefirnet
- zero







