Amazonka Przesunięcie ku czerwieni, szeroko stosowana hurtownia danych w chmurze, znacznie ewoluowała, aby sprostać wymaganiom wydajnościowym najbardziej wymagających obciążeń. W tym poście omówiono jedną z takich nowych funkcji — klucz sortowania wielowymiarowego układu danych.
Usługa Amazon Redshift poprawia teraz wydajność zapytań, obsługując klucze sortowania wielowymiarowego układu danych, czyli nowy typ klucza sortowania, który sortuje dane tabeli według predykatów filtrów zamiast fizycznych kolumn tabeli. Klucze sortowania wielowymiarowego układu danych znacznie poprawią wydajność skanowania tabel, zwłaszcza gdy obciążenie zapytania zawiera powtarzalne filtry skanowania.
Amazon Redshift zapewnia już możliwość automatyczna optymalizacja stołu (ATO), który automatycznie optymalizuje projekt tabel poprzez zastosowanie kluczy sortowania i dystrybucji bez konieczności interwencji administratora. W tym poście przedstawiamy klucze sortowania wielowymiarowego układu danych jako dodatkową możliwość oferowaną przez ATO i wzmocnioną przez algorytm doradcy klucza sortowania Amazon Redshift.
Klucze sortowania wielowymiarowego układu danych
Kiedy zdefiniujesz tabelę za pomocą klucza sortowania AUTO, Amazon Redshift ATO przeanalizuje historię zapytań i automatycznie wybierze dla Twojej tabeli klucz sortowania jednokolumnowego lub klucz sortowania wielowymiarowego układu danych, w zależności od tego, która opcja jest lepsza dla Twojego obciążenia. Po wybraniu wielowymiarowego układu danych Amazon Redshift skonstruuje wielowymiarową funkcję sortowania, która będzie kolokować wiersze, do których zwykle uzyskują dostęp te same zapytania, a funkcja sortowania będzie następnie używana podczas wykonywania zapytań w celu pominięcia bloków danych, a nawet pominięcia skanowania poszczególnych predykatów kolumny.
Rozważ następujące zapytanie użytkownika, które jest dominującym wzorcem zapytań w obciążeniu użytkownika:
Amazon Redshift przechowuje dane dla każdej kolumny w blokach dyskowych o wielkości 1 MB i przechowuje wartości minimalne i maksymalne w każdym bloku jako część metadanych tabeli. Jeśli zapytanie używa a predykat o ograniczonym zakresie, Amazon Redshift może używać wartości minimalnych i maksymalnych, aby szybko pomijać dużą liczbę bloków podczas skanowania tabeli. Jednak filtr tego zapytania w kolumnie podregionu nie może zostać użyty do określenia, które bloki należy pominąć na podstawie wartości minimalnych i maksymalnych, w wyniku czego Amazon Redshift skanuje wszystkie wiersze z tabeli tytułów:
Kiedy zapytanie użytkownika zostało uruchomione titles przy użyciu klucza sortowania jednokolumnowego subregion, wynik poprzedniego zapytania jest następujący:
To pokazuje, że skanowanie tabeli odczytało 2,164,081,640 XNUMX XNUMX XNUMX wierszy.
Aby ulepszyć skanowanie w titles tabeli, Amazon Redshift może automatycznie zdecydować się na użycie klucza sortowania wielowymiarowego układu danych. Wszystkie wiersze spełniające warunek lower(subregion) like '%United States%' predykat byłby zlokalizowany w dedykowanym regionie tabeli, dlatego Amazon Redshift będzie skanował tylko bloki danych, które spełniają predykat.
Gdy zapytanie użytkownika jest uruchamiane za pomocą titles przy użyciu wielowymiarowego klucza sortowania układu danych, który obejmuje lower(subregion) like '%United States%' jako predykat, wynik sys_query_detail zapytanie brzmi następująco:
To pokazuje, że podczas skanowania tabeli odczytano 152,324,046 7 XNUMX wierszy, co stanowi zaledwie XNUMX% wartości oryginalnej, i wykorzystano klucz sortowania wielowymiarowego układu danych.
Należy zauważyć, że w tym przykładzie zastosowano pojedyncze zapytanie, aby zaprezentować funkcję wielowymiarowego układu danych, ale usługa Amazon Redshift uwzględni wszystkie zapytania uruchamiane względem tabeli i może utworzyć wiele regionów, aby spełnić najczęściej uruchamiane predykaty.
Weźmy inny przykład, tym razem z bardziej złożonymi predykatami i wieloma zapytaniami.
Wyobraź sobie, że masz stół items (cost int, available int, demand int) z czterema rzędami, jak pokazano w poniższym przykładzie.
| #ID | koszt | dostępny | popyt |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Twoje dominujące obciążenie składa się z dwóch zapytań:
- Wzór zapytań 70%:
- Wzór zapytań 20%:
W przypadku tradycyjnych technik sortowania można posortować tabelę według kolumny kosztów, tak aby ocena cost > 3 skorzystają z tego rodzaju. Tak więc tabela elementów po posortowaniu za pomocą pojedynczego cost kolumna będzie wyglądać następująco.
| #ID | koszt | dostępny | popyt |
| Region nr 1, z kosztem <= 3 | |||
| Region nr 2, z kosztem > 3 | |||
| #ID | koszt | dostępny | popyt |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Korzystając z tego tradycyjnego sortowania, możemy natychmiast wykluczyć dwa górne (niebieskie) wiersze z ID 4 i ID 2, ponieważ nie spełniają cost > 3.
Z drugiej strony, w przypadku wielowymiarowego klucza sortowania układu danych tabela zostanie posortowana na podstawie kombinacji dwóch często występujących predykatów w obciążeniu użytkownika, którymi są cost > 3 i available < demand. W rezultacie wiersze tabeli są posortowane na cztery obszary.
| #ID | koszt | dostępny | popyt |
| Region nr 1, z kosztem <= 3 i dostępnością < popytu | |||
| Region nr 2, z kosztem <= 3 i dostępnością >= popytu | |||
| Region nr 3, z kosztem > 3 i dostępnością < zapotrzebowania | |||
| Region nr 4, z kosztem > 3 i dostępnością >= popytu | |||
| #ID | koszt | dostępny | popyt |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Ta koncepcja jest jeszcze skuteczniejsza, gdy zostanie zastosowana do całych bloków zamiast pojedynczych wierszy, gdy zostanie zastosowana do złożonych predykatów, które używają operatorów nieodpowiednich dla tradycyjnych technik sortowania (takich jak like) i po zastosowaniu do więcej niż dwóch predykatów.
Tabele systemowe
Poniższe tabele systemu Amazon Redshift pokażą użytkownikom, czy w ich tabelach i zapytaniach używane są wielowymiarowe układy danych:
- Aby ustalić, czy dana tabela korzysta z wielowymiarowego klucza sortowania układu danych, możesz sprawdzić, czy
sortkey1in svv_table_info jest równeAUTO(SORTKEY(padb_internal_mddl_key_col)). - Aby określić, czy określone zapytanie wykorzystuje wielowymiarowy układ danych w celu przyspieszenia skanowania tabeli, możesz to sprawdzić
step_attributesys_query_detail pogląd. Wartość będzie równamulti-dimensionaljeśli podczas skanowania użyto klucza sortowania wielowymiarowego układu danych tabeli.
Testy wydajności
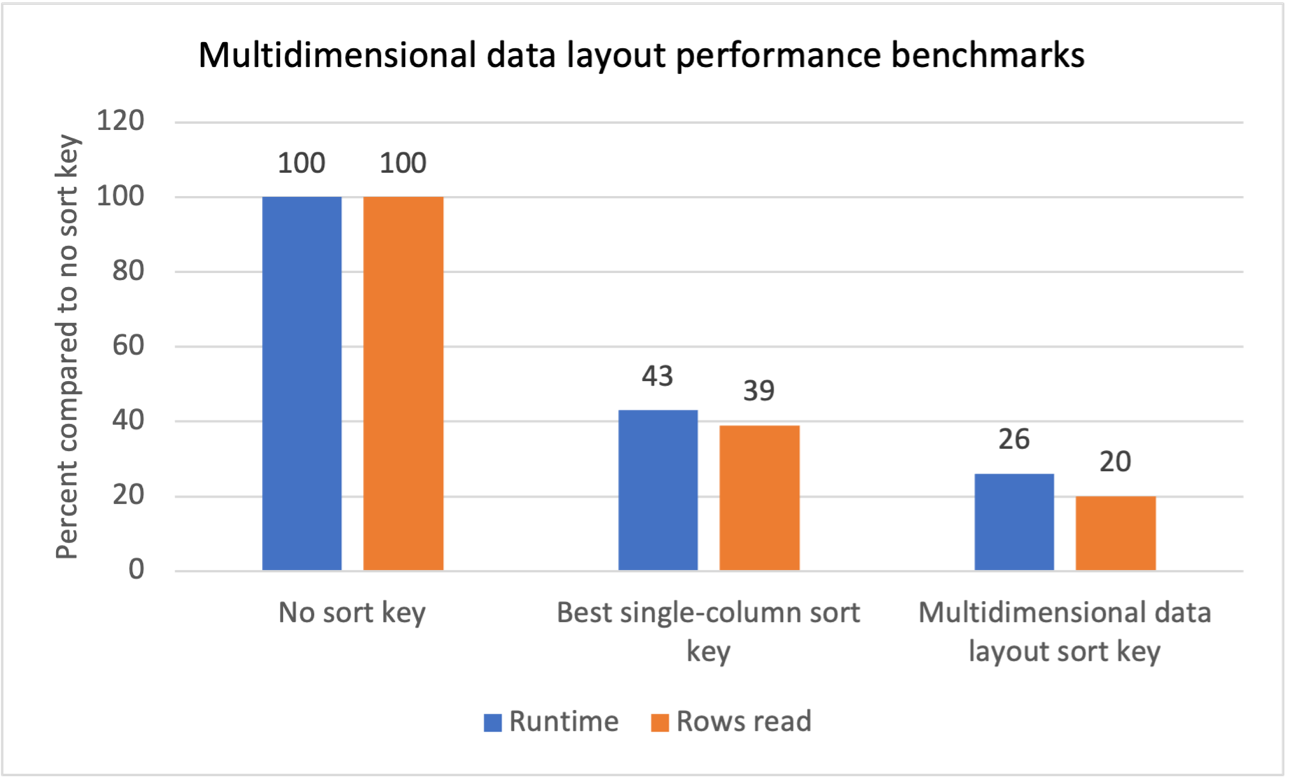
Przeprowadziliśmy wewnętrzne testy porównawcze dla wielu obciążeń z powtarzalnymi filtrami skanowania i zauważyliśmy, że wprowadzenie kluczy sortowania wielowymiarowego układu danych dało następujące wyniki:
- Całkowite skrócenie czasu działania o 74% w porównaniu z brakiem klucza sortowania.
- Skrócenie całkowitego czasu działania o 40% w porównaniu z posiadaniem najlepszego klucza sortowania jednokolumnowego w każdej tabeli.
- Zmniejszenie o 80% całkowitej liczby wierszy odczytanych z tabel w porównaniu z brakiem klucza sortowania.
- Zmniejszenie o 47% całkowitej liczby wierszy odczytanych z tabel w porównaniu z posiadaniem najlepszego klucza sortowania jednokolumnowego w każdej tabeli.
Porównanie funkcji
Dzięki wprowadzeniu wielowymiarowych kluczy sortowania układu danych tabele można teraz sortować według wyrażeń na podstawie często występujących predykatów filtrów w obciążeniu. Poniższa tabela zawiera porównanie funkcji Amazon Redshift z dwoma konkurentami.
| Cecha | Amazonka Przesunięcie ku czerwieni | Konkurent A | Konkurent B |
| Wsparcie sortowania po kolumnach | Tak | Tak | Tak |
| Obsługa sortowania według wyrażeń | Tak | Tak | Nie |
| Automatyczny wybór kolumn do sortowania | Tak | Nie | Tak |
| Automatyczny wybór wyrażeń do sortowania | Tak | Nie | Nie |
| Automatyczny wybór pomiędzy sortowaniem kolumn lub sortowaniem wyrażeń | Tak | Nie | Nie |
| Automatyczne wykorzystanie właściwości sortowania wyrażeń podczas skanowania | Tak | Nie | Nie |
rozważania
Korzystając z wielowymiarowego układu danych, należy pamiętać o następujących kwestiach:
- Wielowymiarowy układ danych jest włączony, gdy ustawisz tabelę na KLUCZ AUTOMATYCZNY.
- Amazon Redshift Advisor automatycznie wybierze jednokolumnowy klucz sortowania lub wielowymiarowy układ danych dla tabeli, analizując historyczne obciążenie pracą.
- Amazon Redshift ATO dostosowuje wyniki sortowania wielowymiarowego układu danych w oparciu o sposób, w jaki bieżące zapytania wchodzą w interakcję z obciążeniem pracą.
- Amazon Redshift ATO utrzymuje klucze sortowania wielowymiarowego układu danych w taki sam sposób, jak obecnie ma to miejsce w przypadku istniejących kluczy sortowania. Odnosić się do Praca z automatyczną optymalizacją tabeli aby uzyskać więcej informacji na temat ATO.
- Klucze sortowania wielowymiarowego układu danych będą działać zarówno z udostępnionymi klastrami, jak i bezserwerowymi grupami roboczymi.
- Klucze sortowania wielowymiarowego układu danych będą działać z istniejącymi danymi, o ile w tabeli zostanie włączona opcja AUTO SORTKEY i zostanie wykryte obciążenie pracą z powtarzającymi się filtrami skanowania. Tabela zostanie zreorganizowana w oparciu o wyniki funkcji sortowania wielowymiarowego.
- Aby wyłączyć klucze sortowania wielowymiarowego układu danych dla tabeli, użyj tabeli alter:
ALTER TABLE table_name ALTER SORTKEY NONE. Wyłącza to funkcję klucza sortowania AUTO w tabeli. - Klucze sortowania wielowymiarowego układu danych są zachowywane podczas przywracania lub migracji udostępnionego klastra do klastra bezserwerowego i odwrotnie.
Wnioski
W tym poście pokazaliśmy, że klucze sortowania wielowymiarowego układu danych mogą znacznie poprawić wydajność środowiska wykonawczego zapytań w przypadku obciążeń, w których dominujące zapytania mają powtarzalne filtry skanowania.
Aby utworzyć klaster podglądu z konsoli Amazon Redshift, przejdź do Klastry stronę i wybierz Utwórz klaster podglądu. Możesz utworzyć klaster w regionach Wschodnie Stany Zjednoczone (Ohio), Wschodnie Stany Zjednoczone (Nowa Wirginia), Zachodnie Stany Zjednoczone (Oregon), Azja i Pacyfik (Tokio), Europa (Irlandia) i Europa (Sztokholm) i przetestować swoje obciążenia.
Chętnie poznamy Twoją opinię na temat tej nowej funkcji i czekamy na Twoje komentarze na temat tego wpisu.
O autorach
 Łagodny Oke jest specjalistą ds. rozwiązań hurtowni danych z siedzibą w Nowym Jorku. Buduje rozwiązania hurtowni danych od ponad 15 lat i specjalizuje się w Amazon Redshift.
Łagodny Oke jest specjalistą ds. rozwiązań hurtowni danych z siedzibą w Nowym Jorku. Buduje rozwiązania hurtowni danych od ponad 15 lat i specjalizuje się w Amazon Redshift.
 Jialin Ding jest naukowcem stosowanym w Learned Systems Group, specjalizującym się w stosowaniu uczenia maszynowego i technik optymalizacji w celu poprawy wydajności systemów danych, takich jak Amazon Redshift.
Jialin Ding jest naukowcem stosowanym w Learned Systems Group, specjalizującym się w stosowaniu uczenia maszynowego i technik optymalizacji w celu poprawy wydajności systemów danych, takich jak Amazon Redshift.
 Yanzhu Ji jest Product Managerem w zespole Amazon Redshift. Ma doświadczenie w zakresie wizji produktów i strategii w wiodących w branży produktach i platformach danych. Ma wybitne umiejętności w budowaniu znaczących produktów oprogramowania przy użyciu technik tworzenia stron internetowych, projektowania systemów, baz danych i programowania rozproszonego. W życiu osobistym Yanzhu lubi malować, fotografować i grać w tenisa.
Yanzhu Ji jest Product Managerem w zespole Amazon Redshift. Ma doświadczenie w zakresie wizji produktów i strategii w wiodących w branży produktach i platformach danych. Ma wybitne umiejętności w budowaniu znaczących produktów oprogramowania przy użyciu technik tworzenia stron internetowych, projektowania systemów, baz danych i programowania rozproszonego. W życiu osobistym Yanzhu lubi malować, fotografować i grać w tenisa.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :ma
- :Jest
- :nie
- :Gdzie
- 1
- 100
- 15 roku
- 15%
- 152
- 7
- 8
- 9
- a
- przyśpieszyć
- dostęp
- Dodatkowy
- doradca
- Po
- przed
- algorytm
- Wszystkie kategorie
- już
- Amazonka
- Amazon Web Services
- an
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- Inne
- stosowany
- Stosowanie
- SĄ
- AS
- Azja
- Azja i Pacyfik
- samochód
- automatycznie
- automatycznie
- dostępny
- AWS
- na podstawie
- BE
- bo
- być
- Benchmark
- korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Blokować
- Bloki
- Niebieski
- obie
- Budowanie
- ale
- by
- CAN
- zdolność
- ZOBACZ
- Dodaj
- Chmura
- Grupa
- Kolumna
- kolumny
- połączenie
- komentarze
- powszechnie
- w porównaniu
- porównanie
- konkurenci
- kompleks
- pojęcie
- Rozważać
- składa się
- Konsola
- skonstruować
- zawiera
- Koszty:
- obejmuje
- Stwórz
- Obecnie
- dane
- hurtownia danych
- Baza danych
- zdecydować
- dedykowane
- określić
- Kreowanie
- wymagający
- Wnętrze
- detale
- wykryte
- Ustalać
- oprogramowania
- dystrybuowane
- 分配
- robi
- dominujący
- nie
- podczas
- każdy
- Wschód
- bądź
- włączony
- Cały
- równy
- szczególnie
- Eter (ETH)
- Europie
- ewaluację
- Parzyste
- ewoluowały
- przykład
- Przede wszystkim system został opracowany
- doświadczenie
- wyrażeń
- Cecha
- informacja zwrotna
- filtrować
- filtry
- następujący
- następujący sposób
- W razie zamówieenia projektu
- Naprzód
- cztery
- od
- funkcjonować
- Zarządzanie
- ręka
- Have
- mający
- he
- słyszeć
- jej
- historyczny
- historia
- Jednak
- HTML
- HTTPS
- ID
- if
- natychmiast
- podnieść
- poprawia
- in
- obejmuje
- indywidualny
- wiodący w branży
- zamiast
- interakcji
- wewnętrzny
- interwencja
- najnowszych
- przedstawiać
- wprowadzenie
- Wprowadzenie
- Irlandia
- IT
- szt
- Klawisz
- Klawisze
- duży
- układ
- dowiedziałem
- nauka
- życie
- lubić
- lubi
- długo
- Popatrz
- wygląda jak
- miłość
- maszyna
- uczenie maszynowe
- utrzymuje
- kierownik
- sposób
- maksymalny
- Poznaj nasz
- Metadane
- może
- migracja
- nic
- minimum
- jeszcze
- większość
- wielokrotność
- Nawigacja
- Potrzebować
- Nowości
- Nowa cecha
- I Love New York
- Nie
- już dziś
- z naszej
- występujący
- of
- poza
- oferowany
- Ohio
- on
- ONE
- trwający
- tylko
- operatorzy
- optymalizacja
- Optymalizuje
- Option
- or
- zamówienie
- Oregon
- oryginalny
- Inne
- na zewnątrz
- wybitny
- koniec
- Pacyfik
- malarstwo
- część
- szczególny
- Wzór
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- osobisty
- fotografia
- fizyczny
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- gra
- Post
- mocny
- zachowane
- Podgląd
- Wytworzony
- Produkt
- product manager
- Produkty
- Programowanie
- niska zabudowa
- zapewnia
- zapytania
- szybko
- Czytaj
- redukcja
- odnosić się
- region
- regiony
- powtarzalne
- wymagania
- przywrócenie
- dalsze
- Efekt
- run
- bieganie
- działa
- taki sam
- skanować
- skanowanie
- skany
- Naukowiec
- Pora roku
- widzieć
- wybierać
- wybrany
- wybór
- Bezserwerowe
- Usługi
- zestaw
- ona
- pokazać
- prezentacja
- pokazał
- pokazane
- Targi
- znacznie
- pojedynczy
- umiejętność
- So
- Tworzenie
- Rozwiązania
- specjalista
- specjalizuje się
- specjalizujący się
- sklep
- Strategia
- Następnie
- znaczny
- taki
- odpowiedni
- Wspierający
- system
- systemy
- stół
- Brać
- zespół
- Techniki
- tenis
- test
- Testowanie
- niż
- że
- Połączenia
- ich
- w związku z tym
- one
- to
- czas
- tytuły
- do
- Tokio
- Top
- Kwota produktów:
- tradycyjny
- drugiej
- rodzaj
- zazwyczaj
- us
- posługiwać się
- używany
- Użytkownik
- Użytkownicy
- zastosowania
- za pomocą
- wartość
- Wartości
- wice
- Zobacz i wysłuchaj
- virginia
- wizja
- Magazyn
- była
- Droga..
- we
- sieć
- Tworzenie stron internetowych
- usługi internetowe
- Zachód
- jeśli chodzi o komunikację i motywację
- czy
- który
- szeroko
- będzie
- w
- bez
- Praca
- by
- lat
- york
- ty
- Twój
- zefirnet