Wraz z rozwojem Roblox w ciągu ostatnich 16 lat wzrosła skala i złożoność infrastruktury technicznej, która obsługuje miliony wciągających wspólnych doświadczeń 3D. Liczba obsługiwanych przez nas maszyn wzrosła ponad trzykrotnie w ciągu ostatnich dwóch lat, z około 36,000 30 na dzień 2021 czerwca 145,000 r. do prawie 1,000 XNUMX obecnie. Obsługa tych stale dostępnych usług dla ludzi na całym świecie wymaga ponad XNUMX usług wewnętrznych. Aby pomóc nam kontrolować koszty i opóźnienia sieci, wdrażamy te maszyny i zarządzamy nimi w ramach niestandardowej, hybrydowej infrastruktury chmury prywatnej, która działa głównie lokalnie.
Nasza infrastruktura obsługuje obecnie ponad 70 milionów aktywnych użytkowników dziennie na całym świecie, w tym twórców korzystających z oprogramowania Roblox gospodarka dla swoich biznesów. Wszystkie te miliony ludzi oczekują bardzo wysokiego poziomu niezawodności. Biorąc pod uwagę wciągający charakter naszych doświadczeń, istnieje niezwykle niska tolerancja opóźnień i opóźnień, nie mówiąc już o przestojach. Roblox to platforma komunikacji i połączeń, na której ludzie spotykają się podczas wciągających wrażeń 3D. Kiedy ludzie komunikują się jako swoje awatary w wciągającej przestrzeni, nawet drobne opóźnienia lub usterki są bardziej zauważalne niż w przypadku wątku tekstowego lub połączenia konferencyjnego.
W październiku 2021 r. doświadczyliśmy awarii całego systemu. Zaczęło się od drobnego problemu w jednym komponencie w jednym centrum danych. Jednak w trakcie naszych badań problem rozprzestrzenił się szybko i ostatecznie spowodował 73-godzinną awarię. W tamtym czasie dzieliliśmy się obydwoma szczegóły tego, co się wydarzyło i niektóre z naszych wczesnych wniosków wyciągniętych z tego problemu. Od tego czasu analizujemy te wnioski i pracujemy nad zwiększeniem odporności naszej infrastruktury na rodzaje awarii, które występują we wszystkich dużych systemach ze względu na takie czynniki, jak ekstremalne skoki ruchu, pogoda, awarie sprzętu, błędy oprogramowania lub po prostu ludzie popełniają błędy. Kiedy wystąpią takie awarie, jak możemy zapewnić, że problem w pojedynczym komponencie lub grupie komponentów nie rozprzestrzeni się na cały system? Kwestia ta skupiała się na nas przez ostatnie dwa lata i chociaż prace trwają, to, co zrobiliśmy do tej pory, już procentuje. Na przykład w pierwszej połowie 2023 r. zaoszczędziliśmy 125 milionów godzin zaangażowania miesięcznie w porównaniu z pierwszą połową 2022 r. Dziś dzielimy się pracą, którą już wykonaliśmy, a także naszą długoterminową wizją budowania bardziej odporny system infrastruktury.
Budowanie zabezpieczenia
W wielkoskalowych systemach infrastrukturalnych awarie na małą skalę zdarzają się wiele razy dziennie. Jeśli wystąpi problem z jedną maszyną i trzeba ją wycofać z eksploatacji, jest to wykonalne, ponieważ większość firm utrzymuje wiele instancji swoich usług zaplecza. Zatem gdy pojedyncza instancja ulegnie awarii, inne przejmą obciążenie. Aby zaradzić tym częstym błędom, żądania są zwykle ustawiane tak, aby automatycznie ponawiały próbę, jeśli wystąpią błąd.
Staje się to wyzwaniem, gdy system lub osoba ponawia próby zbyt agresywnie, co może stać się sposobem na rozprzestrzenianie się drobnych awarii w całej infrastrukturze na inne usługi i systemy. Jeśli sieć lub użytkownik będzie ponawiać próby wystarczająco uporczywie, w końcu przeciąży każdą instancję tej usługi i potencjalnie innych systemów na całym świecie. Nasza awaria w 2021 r. była wynikiem czegoś, co jest dość powszechne w systemach o dużej skali: awaria zaczyna się od małego, następnie rozprzestrzenia się w systemie i staje się poważna tak szybko, że trudno ją rozwiązać, zanim wszystko ulegnie awarii.
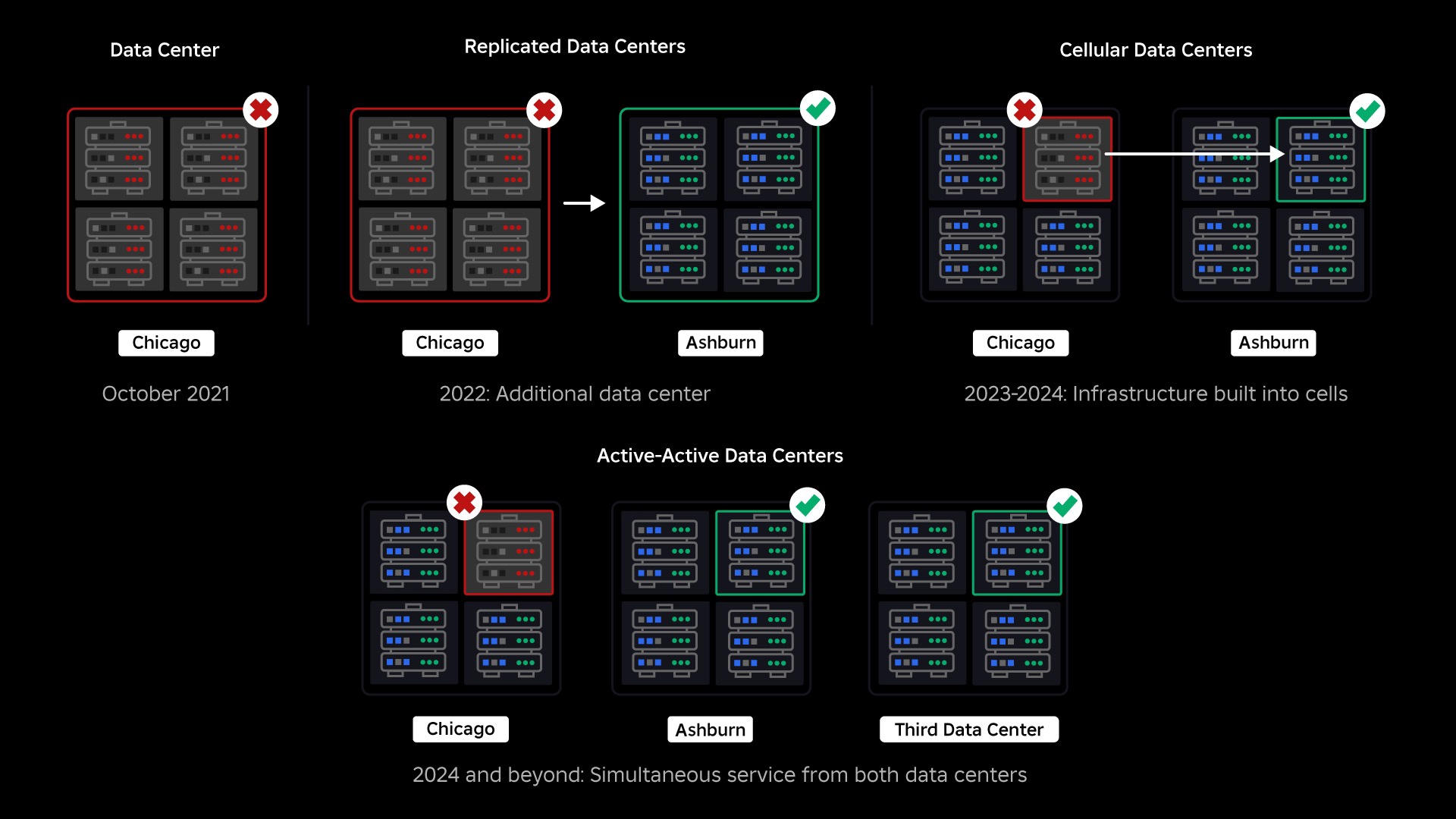
W momencie awarii mieliśmy jedno aktywne centrum danych (z komponentami działającymi w nim jako kopie zapasowe). Potrzebowaliśmy możliwości ręcznego przełączania awaryjnego do nowego centrum danych, gdy problem spowodował awarię istniejącego. Naszym pierwszym priorytetem było zapewnienie zapasowego wdrożenia Robloxa, dlatego zbudowaliśmy tę kopię zapasową w nowym centrum danych, zlokalizowanym w innym regionie geograficznym. To dodało ochronę w przypadku najgorszego scenariusza: awaria obejmująca wystarczającą liczbę komponentów w centrum danych, przez co centrum danych staje się całkowicie niezdatne do użytku. Mamy teraz jedno centrum danych obsługujące obciążenia (aktywne) i jedno w trybie gotowości, służące jako kopia zapasowa (pasywne). Naszym długoterminowym celem jest przejście z konfiguracji aktywno-pasywnej na konfigurację aktywno-aktywną, w której oba centra danych obsługują obciążenia, a moduł równoważenia obciążenia rozdziela żądania między nimi na podstawie opóźnienia, pojemności i kondycji. Kiedy już to wdrożymy, spodziewamy się jeszcze wyższej niezawodności całego Robloxa i możliwości przełączania awaryjnego niemal natychmiast, a nie w ciągu kilku godzin. 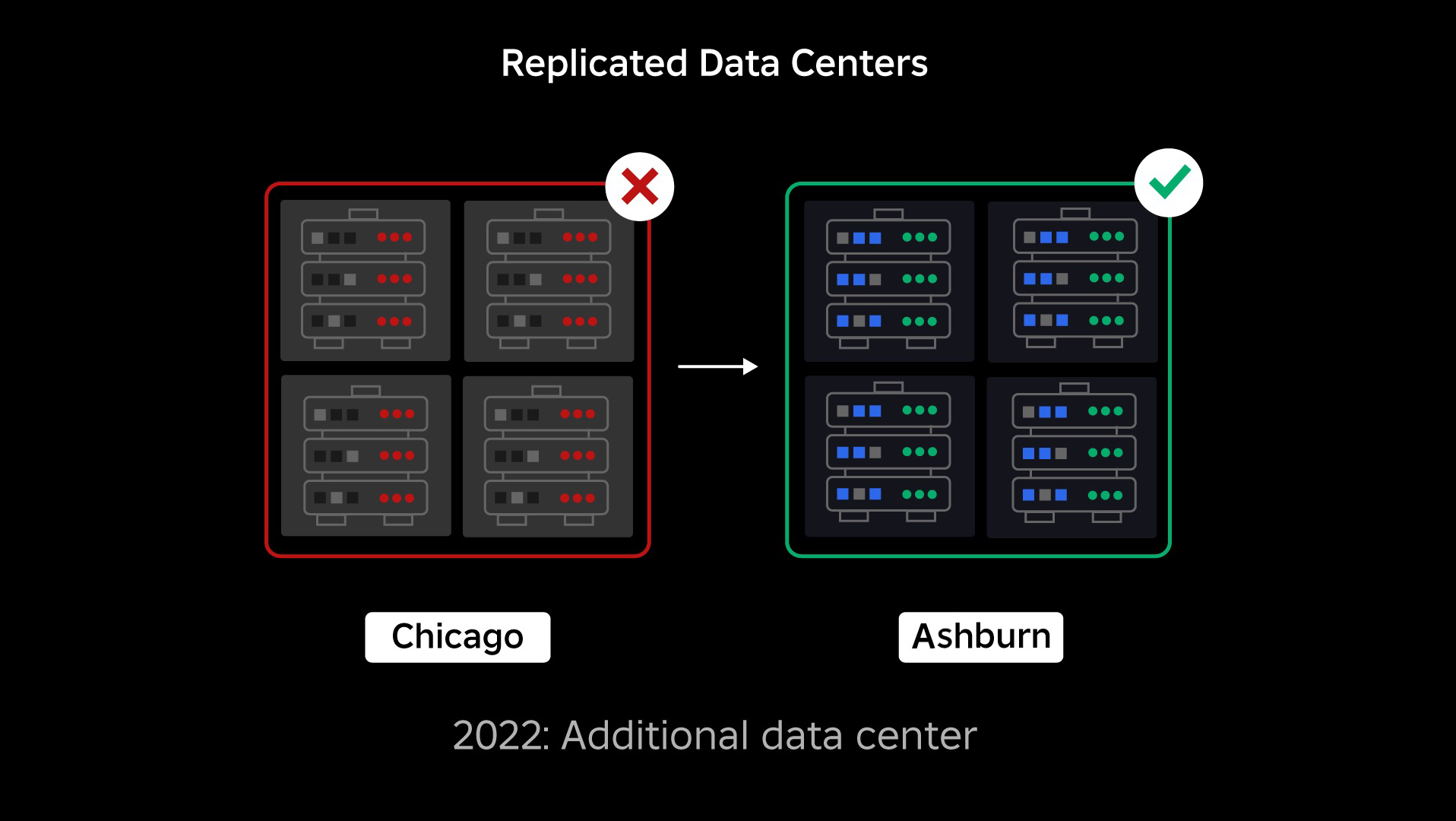
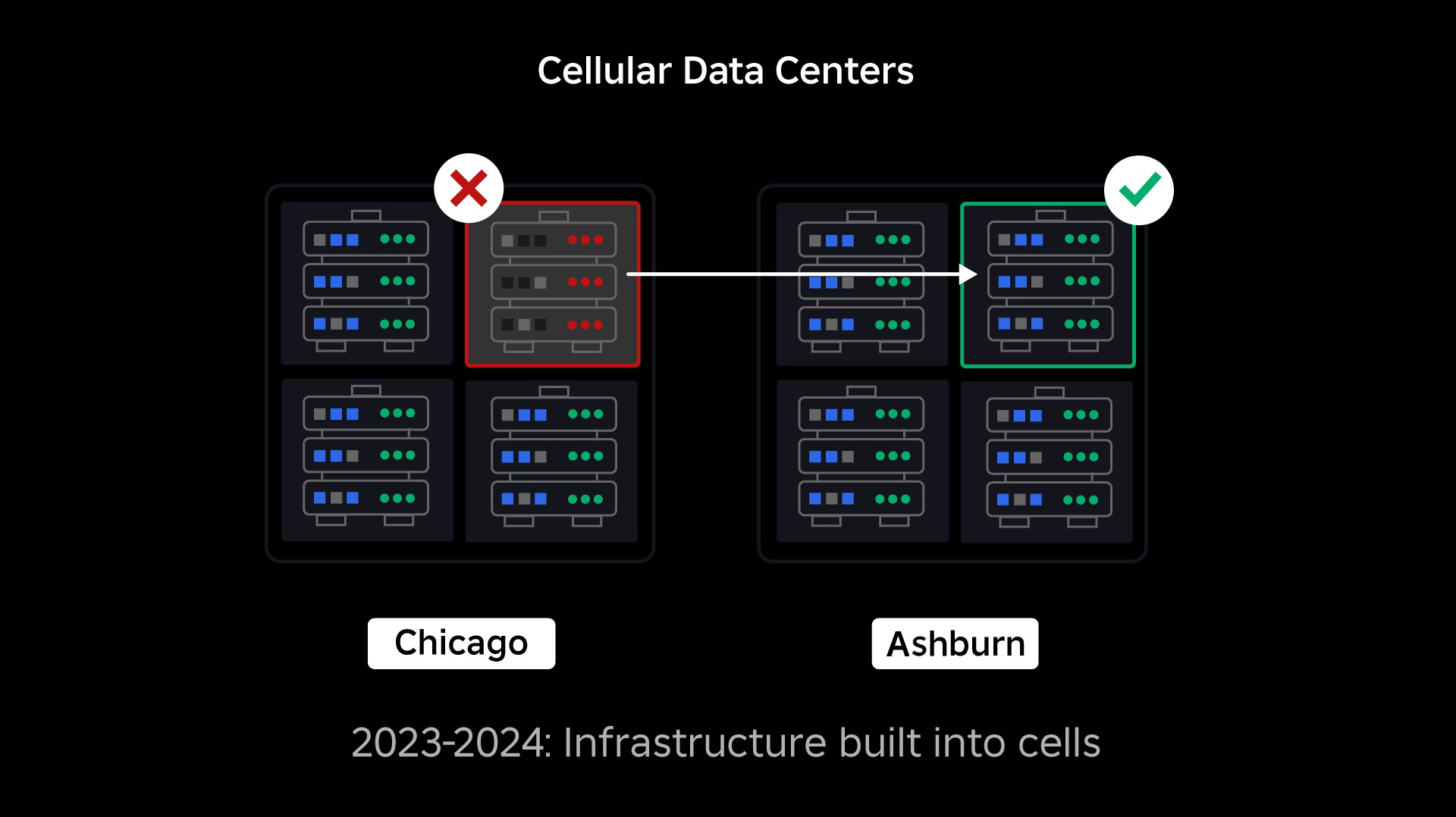
Przejście na infrastrukturę komórkową
Naszym kolejnym priorytetem było stworzenie mocnych ścian przeciwwybuchowych wewnątrz każdego centrum danych, aby zmniejszyć ryzyko awarii całego centrum danych. Komórki (niektóre firmy nazywają je klastrami) to w zasadzie zbiór maszyn i dzięki nim tworzymy te ściany. Replikujemy usługi zarówno w obrębie komórek, jak i pomiędzy nimi, aby zapewnić dodatkową redundancję. Ostatecznie chcemy, aby wszystkie usługi w Roblox działały w komórkach, aby mogły korzystać zarówno z mocnych ścian przeciwwybuchowych, jak i redundancji. Jeśli komórka nie jest już funkcjonalna, można ją bezpiecznie dezaktywować. Replikacja między komórkami umożliwia dalsze działanie usługi do czasu naprawy komórki. W niektórych przypadkach naprawa komórki może oznaczać całkowite odnowienie komórki. W całej branży czyszczenie i ponowne konfigurowanie pojedynczej maszyny lub małego zestawu maszyn jest dość powszechne, ale robienie tego w przypadku całej komórki, która zawiera około 1,400 maszyn, już nie.
Aby to zadziałało, komórki te muszą być w dużej mierze jednolite, abyśmy mogli szybko i sprawnie przenosić obciążenia z jednej komórki do drugiej. Ustaliliśmy pewne wymagania, które usługi muszą spełnić, zanim zostaną uruchomione w komórce. Na przykład usługi muszą być konteneryzowane, co czyni je znacznie bardziej przenośnymi i uniemożliwia nikomu wprowadzanie zmian w konfiguracji na poziomie systemu operacyjnego. Przyjęliśmy filozofię infrastruktury jako kodu dla komórek: w naszym repozytorium kodu źródłowego uwzględniamy definicję wszystkiego, co znajduje się w komórce, dzięki czemu możemy szybko odbudować ją od podstaw przy użyciu zautomatyzowanych narzędzi.
Nie wszystkie usługi spełniają obecnie te wymagania, dlatego staraliśmy się pomóc właścicielom usług w ich spełnieniu, tam gdzie to możliwe, i opracowaliśmy nowe narzędzia ułatwiające migrację usług do komórek, gdy są gotowe. Na przykład nasze nowe narzędzie do wdrażania automatycznie „rozmieszcza” wdrożenie usługi w komórkach, dzięki czemu właściciele usług nie muszą myśleć o strategii replikacji. Ten poziom rygorystyczności sprawia, że proces migracji jest znacznie trudniejszy i bardziej czasochłonny, ale w dłuższej perspektywie opłacalny będzie system, w którym:
- O wiele łatwiej jest powstrzymać awarię i zapobiec jej rozprzestrzenianiu się na inne komórki;
- Nasi inżynierowie infrastruktury mogą działać wydajniej i szybciej; I
- Inżynierowie tworzący usługi na poziomie produktu, które są ostatecznie wdrażane w komórkach, nie muszą wiedzieć ani martwić się o to, w których komórkach działają ich usługi.
Rozwiązywanie większych wyzwań
Podobnie jak drzwi przeciwpożarowe służą do powstrzymywania płomieni, ogniwa działają jak mocne ściany przeciwwybuchowe w naszej infrastrukturze, pomagając powstrzymać problem powodujący awarię w pojedynczej komórce. Ostatecznie wszystkie usługi tworzące Roblox zostaną wdrożone redundantnie wewnątrz i pomiędzy komórkami. Po zakończeniu tych prac problemy mogą nadal rozprzestrzeniać się na tyle szeroko, że cała komórka nie będzie działać, ale niezwykle trudno będzie rozprzestrzenić się poza tę komórkę. A jeśli uda nam się zapewnić wymienność ogniw, regeneracja będzie znacznie szybsza ponieważ będziemy mogli przejść awaryjnie do innej komórki i zapobiec wpływowi problemu na użytkowników końcowych.
Problemem jest oddzielenie tych komórek na tyle, aby ograniczyć możliwość rozprzestrzeniania się błędów, zachowując jednocześnie wydajność i funkcjonalność. W złożonym systemie infrastruktury usługi muszą się ze sobą komunikować, aby dzielić się zapytaniami, informacjami, obciążeniami itp. Replikując te usługi w komórkach, musimy dokładnie przemyśleć sposób zarządzania komunikacją między sobą. W idealnym świecie przekierowujemy ruch z jednej niezdrowej komórki do innych zdrowych komórek. Ale jak sobie poradzić z „zapytaniem o śmierć” – takim spowodowanie komórka jest niezdrowa? Jeśli przekierujemy to zapytanie do innej komórki, może to spowodować, że komórka stanie się niezdrowa w sposób, którego staramy się unikać. Musimy znaleźć mechanizmy umożliwiające przesunięcie „dobrego” ruchu z niezdrowych komórek, jednocześnie wykrywając i blokując ruch powodujący niezdrową kondycję komórek.
W perspektywie krótkoterminowej wdrożyliśmy kopie usług obliczeniowych w każdej komórce obliczeniowej, dzięki czemu większość żądań kierowanych do centrum danych może być obsługiwana przez pojedynczą komórkę. Równoważymy również ruch pomiędzy komórkami. Patrząc dalej, rozpoczęliśmy budowanie procesu odkrywania usług nowej generacji, który zostanie wykorzystany przez siatkę usług, co mamy nadzieję zakończyć w 2024 r. Pozwoli nam to wdrożyć wyrafinowane zasady, które umożliwią komunikację między komórkami tylko wtedy, gdy nie będzie to miało negatywnego wpływu na komórki przełączające. W 2024 r. pojawi się także metoda kierowania zależnych żądań do wersji usługi w tej samej komórce, co zminimalizuje ruch międzykomórkowy, a tym samym zmniejszy ryzyko rozprzestrzeniania się awarii między komórkami.
W szczytowym momencie ponad 70 procent naszego ruchu związanego z usługami zaplecza jest obsługiwane poza komórkami i dowiedzieliśmy się wiele o tym, jak tworzyć komórki, ale spodziewamy się dalszych badań i testów w miarę kontynuowania migracji naszych usług do roku 2024 i poza. W miarę postępów te ściany wybuchowe będą stawały się coraz silniejsze.
Migracja zawsze włączonej infrastruktury
Roblox to globalna platforma obsługująca użytkowników na całym świecie, dlatego nie możemy przenosić usług poza szczytem lub w „przestojach”, co jeszcze bardziej komplikuje proces migracji wszystkich naszych maszyn do komórek i uruchamiania naszych usług w tych komórkach . Mamy miliony zawsze aktywnych środowisk, które wymagają dalszego wsparcia, nawet gdy zmieniamy maszyny, na których działają, i obsługujące je usługi. Kiedy rozpoczynaliśmy ten proces, nie mieliśmy dziesiątek tysięcy nieużywanych maszyn, na które można było przenieść te obciążenia.
Mieliśmy jednak niewielką liczbę dodatkowych maszyn, które zakupiliśmy w oczekiwaniu na przyszły rozwój. Na początek zbudowaliśmy nowe komórki przy użyciu tych maszyn, a następnie przenieśliśmy do nich obciążenia. Cenimy wydajność i niezawodność, więc zamiast kupować więcej maszyn, gdy skończyły nam się „zapasowe” maszyny, zbudowaliśmy więcej ogniw, czyszcząc i ponownie udostępniając maszyny, z których migrowaliśmy. Następnie przenieśliśmy obciążenia na te ponownie przydzielone maszyny i rozpoczęliśmy proces od nowa. Proces ten jest złożony — w miarę jak maszyny są wymieniane i można je wbudować w komórki, nie uwalniają się one w idealny, uporządkowany sposób. Są one fizycznie pofragmentowane w halach danych, przez co możemy je udostępniać fragmentarycznie, co wymaga procesu defragmentacji na poziomie sprzętu, aby zapewnić zgodność lokalizacji sprzętu z domenami awarii fizycznych na dużą skalę.
Część naszego zespołu inżynierów infrastruktury koncentruje się na migracji istniejących obciążeń z naszego starszego środowiska, czyli środowiska „przed komórką”, do komórek. Prace te będą kontynuowane, dopóki nie przeprowadzimy migracji tysięcy różnych usług infrastrukturalnych i tysięcy usług zaplecza do nowo zbudowanych komórek. Oczekujemy, że zajmie to cały przyszły rok, a być może także 2025, ze względu na pewne czynniki komplikujące. Po pierwsze, praca ta wymaga zbudowania solidnego oprzyrządowania. Na przykład potrzebujemy narzędzi, które automatycznie przywrócą równowagę dużej liczby usług po wdrożeniu nowej komórki — bez wpływu na naszych użytkowników. Widzieliśmy także usługi zbudowane w oparciu o założenia dotyczące naszej infrastruktury. Musimy zrewidować te usługi, aby nie były zależne od rzeczy, które mogą zmienić się w przyszłości, gdy będziemy przenosić się do komórek. Wdrożyliśmy także sposób wyszukiwania znanych wzorców projektowych, które nie będą dobrze działać z architekturą komórkową, a także metodyczny proces testowania każdej migrowanej usługi. Procesy te pomagają nam zapobiegać wszelkim problemom napotykanym przez użytkowników, spowodowanym niezgodnością usługi z komórkami.
Obecnie komórki zarządzają blisko 30,000 99.99 maszyn. To tylko ułamek naszej całkowitej floty, ale jak dotąd było to bardzo płynne przejście i nie miało negatywnego wpływu na graczy. Naszym ostatecznym celem jest, aby nasze systemy zapewniały co miesiąc sprawność działania użytkowników na poziomie 0.01%, co oznacza, że nie zakłócalibyśmy więcej niż XNUMX% godzin pracy. W całej branży przestojów nie można całkowicie wyeliminować, ale naszym celem jest ograniczenie wszelkich przestojów Roblox do takiego stopnia, aby były prawie niezauważalne.
Przyszłościowe rozwiązania w miarę skalowania
Chociaż nasze wczesne wysiłki okazują się skuteczne, nasza praca nad komórkami jest jeszcze daleka od ukończenia. W miarę dalszego skalowania Roblox będziemy nadal pracować nad poprawą wydajności i odporności naszych systemów za pomocą tej i innych technologii. W miarę upływu czasu platforma będzie coraz bardziej odporna na problemy, a wszelkie pojawiające się problemy powinny stopniowo stawać się mniej widoczne i uciążliwe dla osób korzystających z naszej platformy.
Podsumowując, na dzień dzisiejszy mamy:
- Zbudowano drugie centrum danych i pomyślnie osiągnięto status aktywny/pasywny.
- Utworzyliśmy komórki w naszych aktywnych i pasywnych centrach danych i pomyślnie przenieśliśmy do tych komórek ponad 70 procent ruchu związanego z usługami zaplecza.
- Ustaw wymagania i najlepsze praktyki, których będziemy musieli przestrzegać, aby zachować jednolitość wszystkich komórek w miarę kontynuowania migracji reszty naszej infrastruktury.
- Rozpoczął ciągły proces budowania silniejszych „ścian wybuchowych” pomiędzy komórkami.
W miarę jak komórki te staną się bardziej wymienne, przesłuchy między komórkami będą mniejsze. Otwiera to dla nas kilka bardzo interesujących możliwości w zakresie zwiększania automatyzacji monitorowania, rozwiązywania problemów, a nawet automatycznego przenoszenia obciążeń.
We wrześniu rozpoczęliśmy także przeprowadzanie eksperymentów typu aktywny/aktywny w naszych centrach danych. To kolejny mechanizm, który testujemy, aby poprawić niezawodność i zminimalizować czas przełączania awaryjnego. Eksperymenty te pomogły zidentyfikować szereg wzorców projektowania systemów, głównie związanych z dostępem do danych, które musimy przepracować, dążąc do osiągnięcia pełnej aktywności-aktywności. Ogólnie rzecz biorąc, eksperyment był na tyle udany, że pozostawił go uruchomionym dla ruchu pochodzącego od ograniczonej liczby naszych użytkowników.
Cieszymy się, że możemy kontynuować prace nad zwiększeniem wydajności i odporności platformy. Ta praca nad komórkami i infrastrukturą typu aktywny-aktywny, wraz z innymi naszymi wysiłkami, umożliwi nam rozwinięcie się w niezawodne, wysokowydajne narzędzie dla milionów ludzi i dalszy rozwój w miarę prac nad połączeniem miliarda ludzi w rzeczywistym czas.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- zdolność
- Zdolny
- O nas
- dostęp
- Osiągać
- osiągnięty
- w poprzek
- działać
- gra aktorska
- aktywny
- w dodatku
- Dodatkowy
- adres
- przyjęty
- ponownie
- agresywnie
- wyrównany
- Wszystkie kategorie
- dopuszczać
- sam
- wzdłuż
- już
- również
- an
- i
- Inne
- przewidywać
- przewidywanie
- każdy
- ktoś
- w przybliżeniu
- architektura
- SĄ
- na około
- AS
- Założenia
- At
- zautomatyzowane
- automatycznie
- Automatyzacja
- dostępny
- awatary
- uniknąć
- Back-end
- backup
- stabilizator
- równoważenie
- na podstawie
- BE
- bo
- stają się
- staje się
- staje
- być
- zanim
- zaczął
- jest
- korzyści
- BEST
- Najlepsze praktyki
- pomiędzy
- Poza
- Duży
- większe
- Miliard
- Blog
- obie
- przynieść
- przyniósł
- błędy
- budować
- Budowanie
- wybudowany
- biznes
- ale
- Zakup
- by
- wezwanie
- CAN
- nie może
- Pojemność
- Etui
- Spowodować
- powodowany
- spowodowanie
- komórka
- Komórki
- komórkowy
- Centrum
- Centra
- pewien
- wyzwanie
- zmiana
- Zmiany
- Zamknij
- Chmura
- infrastruktura chmurowa
- kod
- jak
- przyjście
- wspólny
- komunikować
- przyległy
- Komunikacja
- Firmy
- w porównaniu
- kompletny
- całkowicie
- kompleks
- kompleksowość
- składnik
- składniki
- obliczać
- computing
- Konferencja
- systemu
- Skontaktuj się
- połączenie
- zawierać
- zawiera
- kontynuować
- ciągły
- ciągły
- kontrola
- kopie
- Koszty:
- mógłby
- Stwórz
- Tworzenie
- twórcy
- Obecnie
- Specyfikacji klienta
- codziennie
- dane
- dostęp do danych
- Centrum danych
- centra danych
- Data
- dzień
- definicja
- Stopień
- opóźnienia
- zależeć
- zależny
- rozwijać
- wdrażane
- Wdrożenie
- Wnętrze
- wzorce projektowe
- ZROBIŁ
- różne
- trudny
- kierowniczy
- odkrycie
- Zakłócać
- uciążliwy
- rozdzielczy
- do
- robi
- robi
- domeny
- zrobić
- nie
- Drzwi
- na dół
- przestojów
- jazdy
- z powodu
- podczas
- każdy
- Wcześnie
- łatwiej
- łatwo
- efektywność
- wydajny
- skutecznie
- starania
- wyłączony
- Umożliwia
- zakończenia
- zaręczynowy
- Inżynieria
- Inżynierowie
- dość
- zapewnić
- Cały
- całkowicie
- Środowisko
- błąd
- Błędy
- istotnie
- itp
- Parzyste
- ostatecznie
- Każdy
- wszystko
- przykład
- podniecony
- Przede wszystkim system został opracowany
- oczekiwać
- doświadczony
- Doświadczenia
- eksperyment
- eksperymenty
- skrajny
- niezwykle
- Czynniki
- FAIL
- nie
- nie
- Brak
- Awarie
- dość
- daleko
- Moda
- szybciej
- Znajdź
- natura
- i terminów, a
- FLOTA
- Skupiać
- koncentruje
- obserwuj
- W razie zamówieenia projektu
- Naprzód
- frakcja
- rozdrobniony
- Darmowy
- częsty
- od
- pełny
- w pełni
- funkcjonalny
- dalej
- przyszłość
- przyszły wzrost
- ogólnie
- geograficzny
- otrzymać
- miejsce
- dany
- Globalne
- Globalnie
- Go
- cel
- Goes
- będzie
- większy
- Zarządzanie
- Rosnąć
- dorosły
- Wzrost
- miał
- Pół
- uchwyt
- Prowadzenie
- zdarzyć
- Ciężko
- sprzęt komputerowy
- Have
- głowa
- Zdrowie
- zdrowy
- pomoc
- pomógł
- Wysoki
- wyższy
- nadzieję
- GODZINY
- W jaki sposób
- How To
- Jednak
- HTTPS
- Ludzie
- Hybrydowy
- idealny
- zidentyfikować
- if
- wciągające
- Rezultat
- wpływ
- wdrożenia
- realizowane
- podnieść
- in
- zawierać
- Włącznie z
- niezgodny
- Zwiększać
- wzrastający
- coraz bardziej
- indywidualny
- przemysł
- Informacja
- Infrastruktura
- wewnątrz
- przykład
- instancje
- momentalnie
- ciekawy
- wewnętrzny
- najnowszych
- problem
- problemy
- IT
- czerwiec
- właśnie
- Trzymać
- konserwacja
- Wiedzieć
- znany
- duży
- na dużą skalę
- w dużej mierze
- Utajenie
- dowiedziałem
- Pozostawiać
- pozostawiając
- Dziedzictwo
- mniej
- niech
- poziom
- dźwignia
- lubić
- Ograniczony
- załadować
- usytuowany
- lokalizacji
- długoterminowy
- dłużej
- poszukuje
- Partia
- niski
- maszyna
- maszyny
- utrzymać
- robić
- WYKONUJE
- Dokonywanie
- zarządzanie
- zarządzane
- ręcznie
- wiele
- Maksymalna szerokość
- oznaczać
- znaczenie
- mechanizm
- Mechanizmy
- Poznaj nasz
- siatka
- metoda
- metodyczny
- może
- migrować
- migrował
- migracja
- migracja
- milion
- miliony
- zminimalizować
- moll
- błędy
- monitorowanie
- Miesiąc
- jeszcze
- bardziej wydajny
- większość
- ruch
- dużo
- wielokrotność
- musi
- Natura
- prawie
- Potrzebować
- potrzebne
- ujemny
- ujemnie
- sieć
- Nowości
- nowo
- Następny
- następna generacja
- Nie
- już dziś
- numer
- z naszej
- występować
- październik
- of
- poza
- on
- pewnego razu
- ONE
- trwający
- tylko
- Szanse
- Okazja
- or
- OS
- Inne
- Pozostałe
- ludzkiej,
- na zewnątrz
- przerwa
- Awarie
- koniec
- ogólny
- właściciele
- część
- pasywny
- Przeszłość
- wzory
- zwracając
- Szczyt
- Ludzie
- dla
- procent
- wykonywania
- uporczywie
- osoba
- filozofia
- fizyczny
- Fizycznie
- wybierać
- Miejsce
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- gracz
- polityka
- przenośny
- część
- możliwość
- możliwy
- możliwie
- potencjalnie
- praktyki
- zapobiec
- zapobiega
- głównie
- priorytet
- prywatny
- wygląda tak
- procesów
- Postęp
- stopniowo
- propagacja
- ochrona
- udowodnienie
- zaopatrzenie
- zakupione
- Naciskać
- zapytania
- pytanie
- szybko
- raczej
- gotowy
- real
- w czasie rzeczywistym
- przywrócenie równowagi
- regeneracja
- przekierowanie
- zmniejszyć
- region
- niezawodność
- rzetelny
- polegać
- naprawa
- otrzymuje
- replikacja
- składnica
- wywołań
- wymagania
- Wymaga
- Badania naukowe
- sprężystość
- sprężysty
- rozwiązać
- REST
- dalsze
- wynikał
- zrewidować
- Ryzyko
- Roblox
- krzepki
- run
- bieganie
- działa
- bezpiecznie
- taki sam
- zapisywane
- Skala
- scenariusz
- zadraśnięcie
- Szukaj
- druga
- widziany
- rozsadzający
- wrzesień
- służył
- usługa
- Usługi
- służąc
- zestaw
- kilka
- Share
- shared
- dzielenie
- przesunięcie
- PRZESUNIĘCIE
- Short
- powinien
- znacznie
- ponieważ
- pojedynczy
- Siedzący
- mały
- gładki
- So
- dotychczas
- Tworzenie
- kilka
- coś
- wyrafinowany
- Źródło
- Kod źródłowy
- Typ przestrzeni
- kolce
- rozpiętość
- Rozpościerający się
- początek
- rozpoczęty
- rozpocznie
- Rynek
- Nadal
- Strategia
- silny
- silniejszy
- Studiowanie
- osiągnąć sukces
- udany
- Z powodzeniem
- PODSUMOWANIE
- wsparcie
- Utrzymany
- Wspierający
- podpory
- system
- systemy
- Brać
- Zadania
- zespół
- Techniczny
- Technologies
- kilkadziesiąt
- semestr
- REGULAMIN
- Testowanie
- XNUMX
- niż
- że
- Połączenia
- Przyszłość
- świat
- ich
- Im
- następnie
- Tam.
- a tym samym
- Te
- one
- rzeczy
- myśleć
- to
- tych
- tysiące
- Przez
- poprzez
- czas
- czasy
- do
- już dziś
- razem
- tolerancja
- także
- narzędzie
- narzędzia
- Kwota produktów:
- w kierunku
- ruch drogowy
- przejście
- wyzwalanie
- stara
- drugiej
- typy
- ostateczny
- Ostatecznie
- odblokowuje
- aż do
- nieużywana
- na
- uptime
- us
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- użyteczność
- wartość
- wersja
- początku.
- widoczny
- wizja
- chcieć
- była
- Droga..
- we
- Pogoda
- DOBRZE
- były
- Co
- cokolwiek
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- KIM
- szeroki
- będzie
- wycieranie
- w
- w ciągu
- Praca
- pracował
- pracujący
- świat
- martwić się
- by
- rok
- lat
- zefirnet