Web scraping może być potężnym narzędziem do wydobywania danych ze stron internetowych, ale może być również złożonym i czasochłonnym procesem. Na szczęście Arkusze Google oferują przyjazne dla użytkownika rozwiązanie do zbierania danych ze stron internetowych bez konieczności pisania skomplikowanego kodu. Wykorzystując możliwości Arkuszy Google, możesz łatwo wyodrębniać dane ze stron internetowych i analizować je na różne sposoby. Na tym blogu przeprowadzę Cię przez proces korzystania z Arkuszy Google do scrapowania stron internetowych i pomogę odblokować potencjał web scrapingu we własnych projektach. Więc zacznijmy!
Pobieranie danych z sieci może być czasochłonne, złożone i wymagać dużej ilości kodowania. Dla niekodujących. Arkusze Google to doskonała alternatywa dla skrobania stron internetowych. Skrobanie arkuszy Google w sieci nie wymaga kodowania i zapewnia wiele sposobów analizowania danych witryny.
Na tym blogu zobaczymy, jak używać Arkuszy Google do łatwego zeskrobywania stron internetowych. Więc zacznijmy!
Dlaczego warto używać Arkuszy Google do skrobania stron internetowych?
Istnieje kilka powodów, dla których Arkusze Google są doskonałym narzędziem do przeglądania stron internetowych:
- Arkusze Google są przyjazne dla użytkownika i mają znajomy interfejs.
- Nie wymaga znajomości języka programowania.
- Arkusze Google są dostępne z dowolnego miejsca.
- Arkusze Google są bezpłatne, dzięki czemu są przystępne cenowo dla osób prywatnych i małych firm.
- Google łatwo integruje się z innymi narzędziami Suite.
- Możesz użyć makr lub skryptów do automatyzacji zadań związanych ze skrobaniem stron internetowych.
- Możesz łatwo analizować zeskrobane dane za pomocą formuł Arkusza Google.
Wyodrębnij tekst z dowolnej strony internetowej jednym kliknięciem. Udaj się do Nanonets skrobak strony internetowej, Dodaj adres URL i kliknij „Scrape” i natychmiast pobierz tekst strony jako plik. Wypróbuj teraz za darmo.
Jakich funkcji użyć do skrobania stron internetowych w Arkuszach Google?
Oto kilka funkcji, których możesz użyć, gdy chcesz zeskrobać strony internetowe za pomocą Arkuszy Google.
IMPORTHTML:
Wyodrębnij tabele i listy ze stron HTML.
=IMPORTHTML(url, query, index)- url: To jest link do strony internetowej, którą chcesz zeskrobać
- zapytanie: Typ danych – Tabela, Lista
- index: Jeśli chcesz wyodrębnić określoną tabelę, możesz jej użyć
Przykład:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)IMPORTXML:
Wyodrębnij dane ze stron XML.
=IMPORTXML(url, xpath_query)- url: To jest link do strony internetowej, którą chcesz zeskrobać
- xpath_query: wyrażenie XPath identyfikujące dane, które chcesz wyodrębnić
Przykład:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")ZAIMPORTOWAĆ DANE:
Wyodrębnij dane z plików CSV i TSV.
=IMPORTDATA(url)- url: adres URL pliku CSV lub TSV, z którego chcesz wyodrębnić dane
Przykład:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")WYCIĄGNIĘCIE REGEXTRAKTU:
Ta funkcja może wyodrębnić dane pasujące do wzorca wyrażenia regularnego.
=REGEXEXTRACT(text, regular_expression)- tekst: tekst, w którym chcesz wyszukać wzór
- wyrażenie_regularne: wzorzec, który chcesz dopasować
Przykład:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")Uwaga: te funkcje mogą nie działać w przypadku każdej witryny. To zależy od układu strony. Jeśli potrzebujesz więcej danych, możesz skorzystać z samouczków dotyczących skrobania stron internetowych przy użyciu Pythona i Javy lub użyć narzędzi przekształcających witrynę w tekst, takich jak Nanonets.
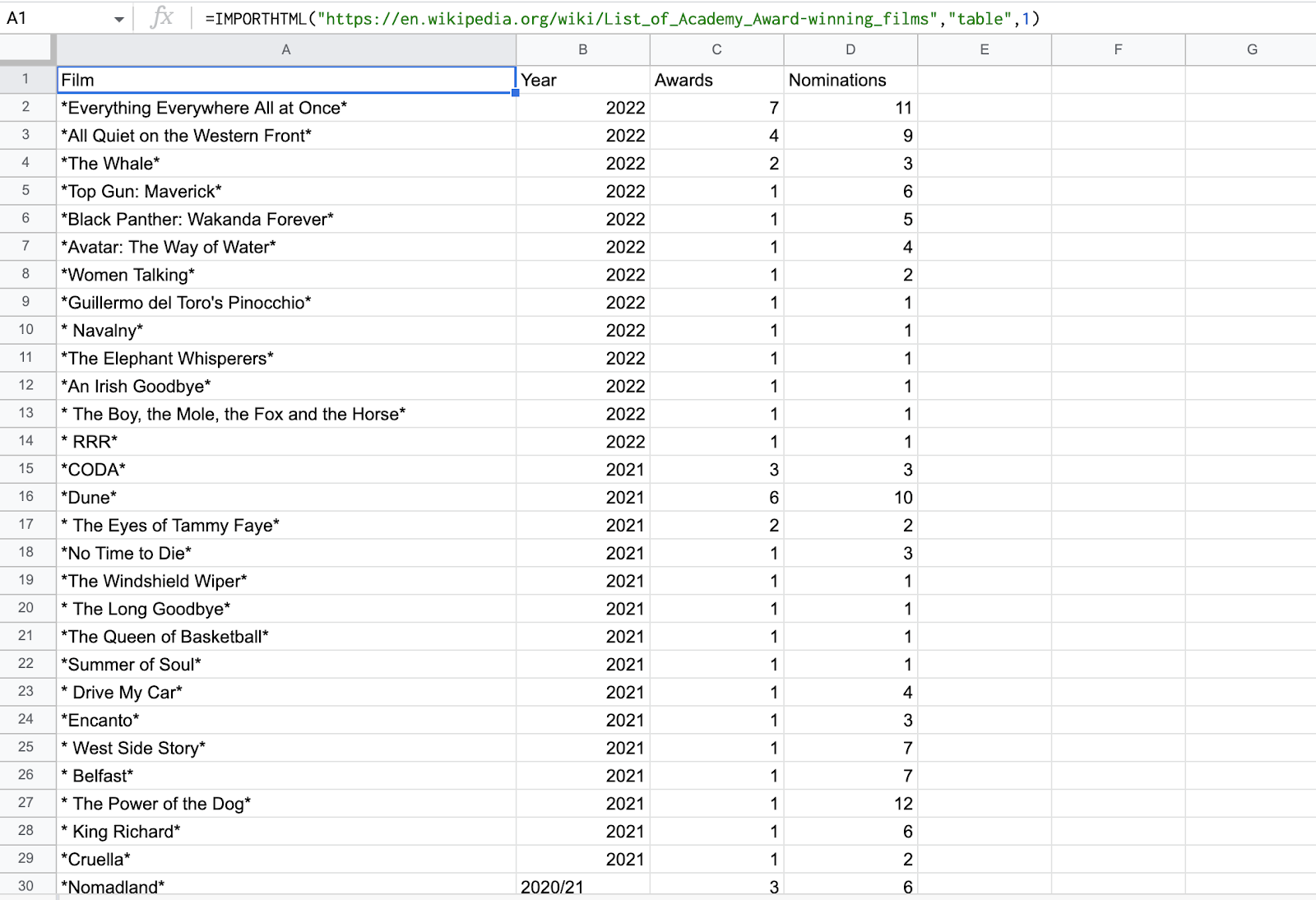
Spróbujmy wyodrębnić tabelę HTML do Arkuszy Google. Postaramy się zeskrobać stół z Strona Wikipedii z listą nagrodzonych przez Akademię filmów.
- Otwórz Arkusze Google.
- W nowej komórce wpisz =IMPORTHTML(adres URL, zapytanie, indeks)
1. Nasz kod staje się,
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","tabela",1)
zeskrobuje pierwszą tabelę na stronie Wikipedii
3. Sprawdź wyniki
Jak zeskrobać dane za pomocą skrobania internetowego Arkuszy Google?
Zobaczmy, jak zeskrobać tytuły, opisy, H1 i inne elementy za pomocą Arkuszy Google. Aby rozpocząć skrobanie H1 w Arkuszach Google, użyjemy funkcji IMPORTXML dla tego konkretnego strona Nanonets. Oto kroki:
- Otwórz nowy lub istniejący Arkusz Google.
- W komórce wpisz następującą formułę:
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- Aby wyodrębnić znacznik H1, użyj następującego wyrażenia XPath: //h1/text()
- Aby wyodrębnić tag tytułu, użyj następującego wyrażenia XPath: //title/text()
- Aby wyodrębnić tag metaopisu, użyj następującego wyrażenia XPath: //meta[@name='description']/@content
- Aby wyodrębnić wszystkie łącza do stron, użyj następującego wyrażenia XPath: //a/@href
Naciśnij Enter, a Arkusze Google automatycznie zeskanują dane i wyświetlą je w wybranej komórce.
Następnie możesz skopiować formułę do innych komórek, aby zeskrobać dodatkowe dane z tych samych lub różnych stron internetowych.
Wyodrębnij tekst z dowolnej strony internetowej jednym kliknięciem. Udaj się do Nanonets skrobak strony internetowej, Dodaj adres URL i kliknij „Scrape” i natychmiast pobierz tekst strony jako plik. Wypróbuj teraz za darmo.
Jakie są wady korzystania z Google Sheets Web Scraper?
- Arkusze Google mają ograniczone możliwości. Jeśli chodzi o złożone układy, nie radzi sobie z dynamiczną zawartością.
- Mogą wystąpić rozbieżności w danych podczas zbierania danych za pomocą formuł zbierania danych w Arkuszach Google.
- Podczas zgarniania danych ze stron internetowych możesz przypadkowo zeskrobać poufne lub poufne informacje. Może to budzić obawy dotyczące prywatności i bezpieczeństwa, zwłaszcza jeśli zebrane dane są udostępniane lub przechowywane w niezabezpieczonej lokalizacji.
Wskazówka: funkcja Web Scraping w Arkuszach Google to świetna alternatywa dla nieskomplikowanych zadań związanych z przeglądaniem stron internetowych, takich jak metatytuły, listy lub wyodrębnianie tabel. W przypadku złożonych zadań należy używać narzędzi do skrobania stron internetowych.
Najczęściej zadawane pytania
Czy mogę przeglądać strony internetowe za pomocą Arkuszy Google?
Tak, Arkusze Google mają wbudowane funkcje, takie jak IMPORTHTML, IMPORTXML, IMPORTDATA,
i REGEXTRACT, które umożliwiają przechwytywanie danych ze stron internetowych bezpośrednio do Arkuszy Google. Jednak funkcjonalność może być ograniczona, a bardziej złożone zadania związane ze skrobaniem sieci mogą wymagać użycia oddzielnego narzędzia do skrobania stron internetowych lub napisania niestandardowego kodu.
Jak zeskrobać dane do arkusza Google?
Możesz zeskrobać dane do Arkusza Google, używając jednej z wbudowanych funkcji, takich jak IMPORTHTML, IMPORTXML, IMPORTDATA lub REGEXTRACT. Funkcje te umożliwiają wyodrębnianie danych ze stron internetowych, plików CSV lub TSV oraz dopasowywanie wzorców wyrażeń regularnych. Po prostu określ adres URL, zapytanie, indeks lub wzorzec wyrażenia regularnego, a dane zostaną zeskrobane i umieszczone w Arkuszu Google.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :Jest
- 1
- 11
- 2023
- 7
- a
- Akademia
- dostępny
- Dodatkowy
- przystępne
- Wszystkie kategorie
- alternatywny
- w czasie rzeczywistym sprawiają,
- i
- nigdzie
- SĄ
- AS
- zautomatyzować
- automatycznie
- Wielokrotnie nagradzana
- BE
- staje się
- Blog
- wbudowany
- biznes
- by
- CAN
- możliwości
- zdobyć
- walizka
- Komórki
- ZOBACZ
- kliknij
- Zamknij
- kod
- Kodowanie
- kompleks
- Obawy
- zawartość
- zwyczaj
- dane
- zależy
- opis
- różne
- bezpośrednio
- Wyświetlacz
- pobieranie
- dynamiczny
- każdy
- z łatwością
- Wchodzę
- szczególnie
- Eter (ETH)
- Każdy
- doskonała
- Przede wszystkim system został opracowany
- wyciąg
- ekstrakcja
- znajomy
- Korzyści
- filet
- Akta
- filmy
- i terminów, a
- następujący
- W razie zamówieenia projektu
- formuła
- na szczęście
- Darmowy
- od
- funkcjonować
- Funkcjonalność
- Funkcje
- otrzymać
- Govt
- wspaniały
- poprowadzi
- uchwyt
- głowa
- pomoc
- tutaj
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- i
- identyfikuje
- in
- wskaźnik
- osób
- Informacja
- Integruje się
- Interfejs
- angażować
- IT
- Java
- tylko jeden
- wiedza
- język
- układ
- lewarowanie
- lubić
- Ograniczony
- LINK
- linki
- wykazy
- lokalizacja
- Partia
- makra
- Dokonywanie
- wiele
- Mecz
- Meta
- może
- jeszcze
- Potrzebować
- potrzeba
- Nowości
- of
- Oferty
- on
- ONE
- zamówienie
- Inne
- własny
- strona
- szczególny
- Wzór
- wzory
- plato
- Analiza danych Platona
- PlatoDane
- zaludniony
- potencjał
- funt
- power
- mocny
- prywatność
- Prywatność i bezpieczeństwo
- wygląda tak
- Programowanie
- projektowanie
- zapewnia
- Python
- podnieść
- Przyczyny
- regularny
- wymagać
- Wymaga
- Resort
- s
- taki sam
- skrobanie
- skrypty
- Szukaj
- bezpieczeństwo
- wybrany
- wrażliwy
- oddzielny
- kilka
- shared
- powinien
- Prosty
- po prostu
- mały
- małych firm
- So
- rozwiązanie
- kilka
- specyficzny
- rozpoczęty
- statystyki
- Cel
- przechowywany
- taki
- apartament
- stół
- ekstrakcja stołu
- TAG
- zadania
- że
- Połączenia
- Te
- Przez
- czasochłonne
- Tytuł
- tytuły
- do
- narzędzie
- narzędzia
- tutoriale
- odblokować
- niezabezpieczony
- URL
- posługiwać się
- łatwy w obsłudze
- różnorodność
- sposoby
- sieć
- skrobanie sieci
- Strona internetowa
- strony internetowe
- Wikipedia
- będzie
- w
- bez
- Praca
- napisać
- pisanie
- XML
- Twój
- zefirnet