
20 września 2023 r.
Modele podstawowe (FM) wyznaczają początek nowej ery w uczenie maszynowe (ML) i sztuczna inteligencja (AI), co prowadzi do szybszego rozwoju sztucznej inteligencji, którą można dostosować do szerokiego zakresu dalszych zadań i dostosować do szeregu zastosowań.
Wraz ze wzrostem znaczenia przetwarzania danych w miejscu wykonywania pracy, udostępnianie modeli sztucznej inteligencji na brzegu przedsiębiorstwa umożliwia przewidywanie w czasie zbliżonym do rzeczywistego, przy jednoczesnym przestrzeganiu wymogów dotyczących suwerenności danych i prywatności. Łącząc IBM Watsonx możliwości platformy danych i sztucznej inteligencji dla FM z przetwarzaniem brzegowym, przedsiębiorstwa mogą uruchamiać obciążenia AI w celu dostrajania FM i wnioskowania na krawędzi operacyjnej. Umożliwia to przedsiębiorstwom skalowanie wdrożeń sztucznej inteligencji na brzegu sieci, redukując czas i koszty wdrażania oraz skracając czas reakcji.
Koniecznie zapoznaj się ze wszystkimi częściami tej serii postów na blogu na temat przetwarzania brzegowego:
Czym są modele podstawowe?
Modele podstawowe (FM), które są szkolone na szeroką skalę na szerokim zestawie nieoznakowanych danych, napędzają najnowocześniejsze aplikacje sztucznej inteligencji (AI). Można je dostosować do szerokiego zakresu dalszych zadań i dostosować do szeregu zastosowań. Nowoczesne modele sztucznej inteligencji, które wykonują określone zadania w jednej domenie, ustępują miejsca FM, ponieważ uczą się bardziej ogólnie i działają w różnych domenach i problemach. Jak sama nazwa wskazuje, FM może być podstawą wielu zastosowań modelu AI.
FM zajmują się dwoma kluczowymi wyzwaniami, które powstrzymują przedsiębiorstwa przed skalowaniem wdrażania sztucznej inteligencji. Po pierwsze, przedsiębiorstwa wytwarzają ogromną ilość nieoznaczonych danych, z których tylko część jest oznaczona na potrzeby szkolenia w zakresie modeli sztucznej inteligencji. Po drugie, zadanie oznaczania i dodawania adnotacji wymaga ogromnego zaangażowania człowieka i często wymaga kilkuset godzin czasu eksperta merytorycznego (MŚP). To sprawia, że skalowanie w różnych przypadkach użycia jest nieopłacalne, ponieważ wymagałoby armii MŚP i ekspertów ds. danych. Przyjmując ogromne ilości nieoznaczonych danych i stosując techniki samonadzoru do uczenia modeli, menedżerowie zarządzający usunęli te wąskie gardła i otworzyli drogę do wdrożenia sztucznej inteligencji na szeroką skalę w całym przedsiębiorstwie. Te ogromne ilości danych, które istnieją w każdej firmie, czekają na uwolnienie w celu uzyskania wglądu.
Czym są duże modele językowe?
Duże modele językowe (LLM) to klasa modeli podstawowych (FM), które składają się z warstw sieci neuronowe które zostały przeszkolone na tak ogromnych ilościach nieoznakowanych danych. Używają algorytmów uczenia się samonadzorowanego do wykonywania różnych przetwarzanie języka naturalnego (NLP) zadania w sposób podobny do tego, jak ludzie używają języka (patrz rysunek 1).
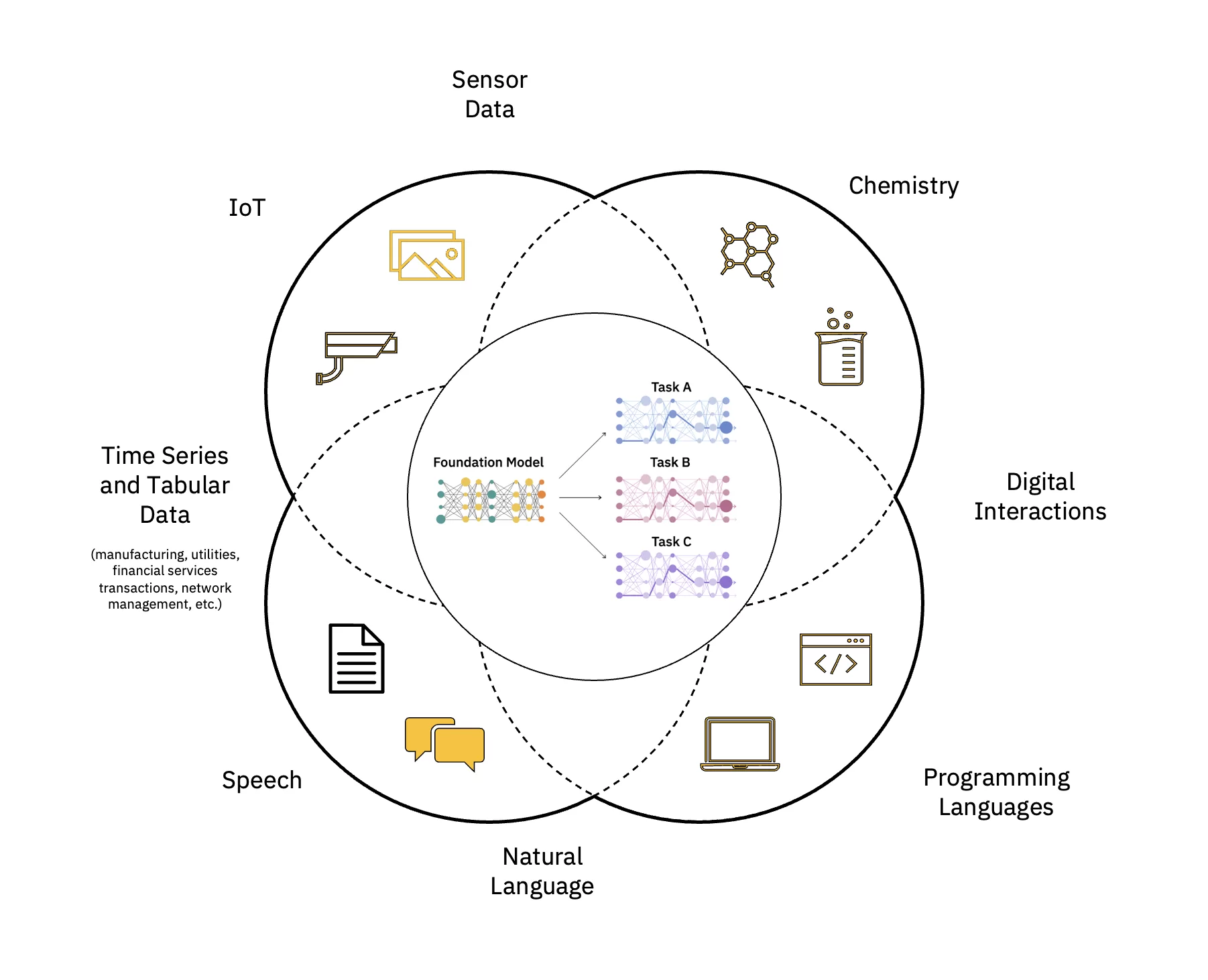
Skaluj i przyspieszaj wpływ sztucznej inteligencji
Budowa i wdrażanie modelu podstawowego (FM) składa się z kilku etapów. Obejmują one pozyskiwanie danych, selekcję danych, wstępne przetwarzanie danych, wstępne uczenie FM, dostrajanie modelu do jednego lub większej liczby dalszych zadań, obsługę wnioskowania oraz zarządzanie danymi i modelami sztucznej inteligencji oraz zarządzanie cyklem życia – wszystko to można opisać jako FMOps.
Aby pomóc w tym wszystkim, IBM oferuje przedsiębiorstwom niezbędne narzędzia i możliwości, aby wykorzystać moc tych FM IBM Watsonx, gotowa do zastosowania w przedsiębiorstwach platforma sztucznej inteligencji i danych, zaprojektowana w celu zwielokrotnienia wpływu sztucznej inteligencji na całe przedsiębiorstwo. IBM watsonx składa się z następujących elementów:
- IBM watsonx.ai przynosi nowe generatywna sztuczna inteligencja możliwości — wspierane przez FM i tradycyjne uczenie maszynowe (ML) — w potężne studio obejmujące cały cykl życia sztucznej inteligencji.
- IBM watsonx.data to dostosowany do potrzeb magazyn danych zbudowany w oparciu o otwartą architekturę Lakehouse, umożliwiający skalowanie obciążeń AI pod kątem wszystkich danych w dowolnym miejscu.
- IBM watsonx.governance to kompleksowy, zautomatyzowany zestaw narzędzi do zarządzania cyklem życia AI, który został stworzony, aby umożliwić odpowiedzialne, przejrzyste i zrozumiałe przepływy pracy AI.
Innym kluczowym wektorem jest rosnące znaczenie obliczeń na obrzeżach przedsiębiorstwa, takich jak lokalizacje przemysłowe, hale produkcyjne, sklepy detaliczne, placówki telekomunikacyjne itp. Mówiąc dokładniej, sztuczna inteligencja na obrzeżach przedsiębiorstwa umożliwia przetwarzanie danych tam, gdzie wykonywana jest praca dla analiza w czasie zbliżonym do rzeczywistego. Krawędź przedsiębiorstwa to miejsce, w którym generowane są ogromne ilości danych przedsiębiorstwa i gdzie sztuczna inteligencja może dostarczać cennych, aktualnych i przydatnych spostrzeżeń biznesowych.
Udostępnianie modeli sztucznej inteligencji na brzegu sieci umożliwia przewidywanie w czasie zbliżonym do rzeczywistego, przy jednoczesnym przestrzeganiu wymogów dotyczących suwerenności danych i prywatności. To znacznie zmniejsza opóźnienia często związane z pozyskiwaniem, przesyłaniem, przekształcaniem i przetwarzaniem danych z inspekcji. Praca na brzegu sieci pozwala nam chronić wrażliwe dane przedsiębiorstwa i obniżać koszty przesyłania danych dzięki szybszemu czasowi reakcji.
Skalowanie wdrożeń sztucznej inteligencji na brzegu sieci nie jest jednak łatwym zadaniem w obliczu wyzwań związanych z danymi (heterogeniczność, wolumen i regulacje) oraz ograniczonymi zasobami (moc obliczeniowa, łączność sieciowa, pamięć masowa, a nawet umiejętności IT). Można je ogólnie opisać w dwóch kategoriach:
- Czas/koszt wdrożenia: Każde wdrożenie składa się z kilku warstw sprzętu i oprogramowania, które należy zainstalować, skonfigurować i przetestować przed wdrożeniem. Obecnie montaż może zająć specjaliście od tygodnia lub dwóch w każdej lokalizacji, poważnie ogranicza szybkość i efektywność kosztową, z jaką przedsiębiorstwa mogą zwiększać skalę wdrożeń w całej organizacji.
- Zarządzanie dniem 2: Ogromna liczba wdrożonych urządzeń brzegowych i lokalizacja geograficzna każdego wdrożenia często mogą sprawić, że zapewnienie lokalnego wsparcia IT w każdej lokalizacji w celu monitorowania, konserwacji i aktualizacji tych wdrożeń będzie zbyt kosztowne.
Wdrożenia brzegowej sztucznej inteligencji
IBM opracował architekturę brzegową, która pozwala sprostać tym wyzwaniom, wprowadzając zintegrowany model sprzętu/oprogramowania (HW/SW) do wdrożeń sztucznej inteligencji na krawędzi. Składa się z kilku kluczowych paradygmatów, które pomagają skalowalność wdrożeń AI:
- Oparte na zasadach, bezdotykowe udostępnianie pełnego stosu oprogramowania.
- Ciągłe monitorowanie stanu systemu brzegowego
- Możliwości zarządzania aktualizacjami oprogramowania/bezpieczeństwa/konfiguracji i przesyłania ich do wielu lokalizacji brzegowych — wszystko z centralnej lokalizacji w chmurze do zarządzania od drugiego dnia.
Rozproszoną architekturę typu „hub-and-szprychy” można wykorzystać do skalowania wdrożeń sztucznej inteligencji w przedsiębiorstwie na brzegu sieci, gdzie centralna chmura lub korporacyjne centrum danych pełni rolę koncentratora, a urządzenie typu „edytuj w pudełku” działa jak szprycha w lokalizacji brzegowej. Ten model centrum i szprych, obejmujący środowiska chmury hybrydowej i środowiska brzegowe, najlepiej ilustruje równowagę niezbędną do optymalnego wykorzystania zasobów potrzebnych do operacji FM (patrz rysunek 2).
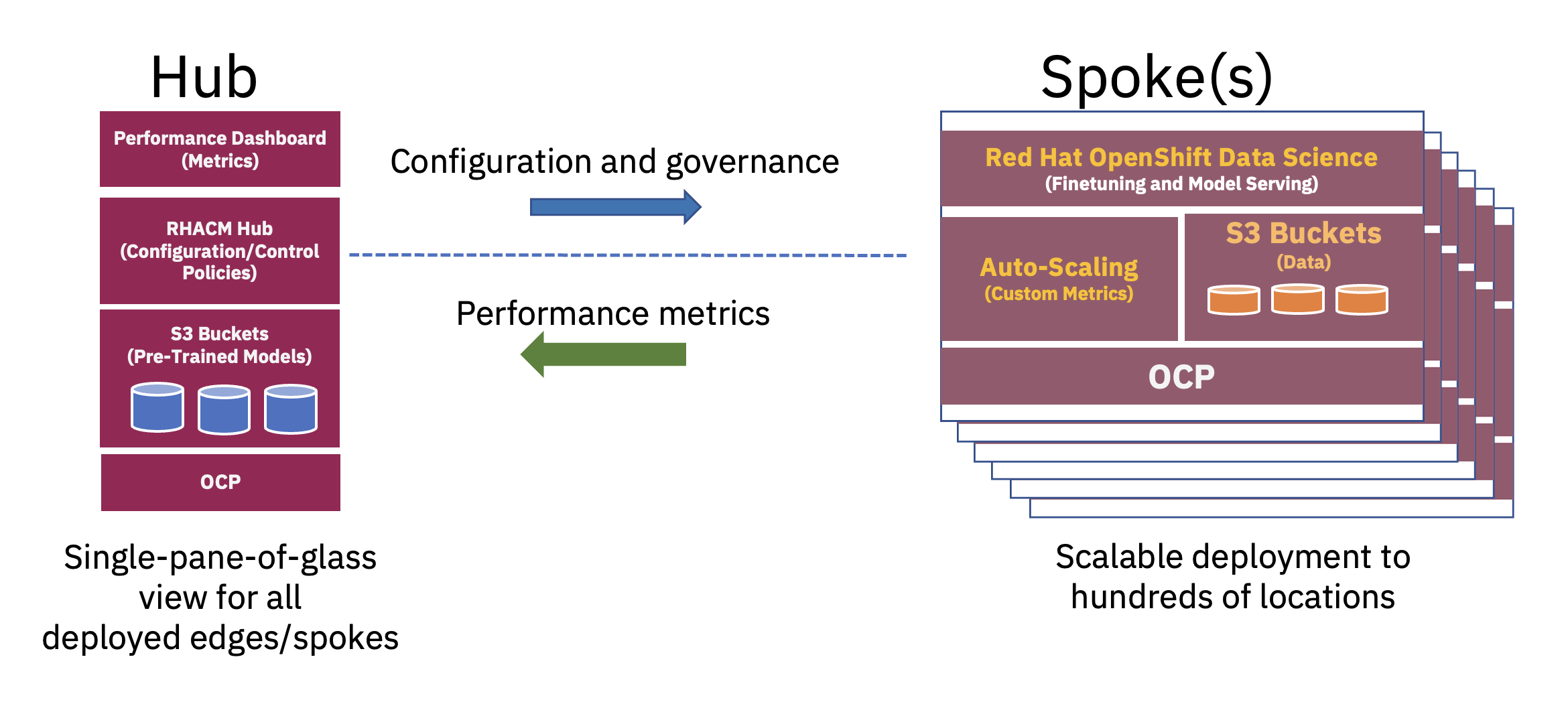
Wstępne uczenie tych podstawowych modeli dużych języków (LLM) i innych typów modeli podstawowych przy użyciu technik samonadzoru na ogromnych, nieoznaczonych zbiorach danych często wymaga znacznych zasobów obliczeniowych (GPU) i najlepiej jest wykonywać je w centrum. Praktycznie nieograniczone zasoby obliczeniowe i duże stosy danych, często przechowywane w chmurze, pozwalają na wstępne uczenie modeli o dużych parametrach i ciągłe doskonalenie dokładności tych podstawowych modeli podstawowych.
Z drugiej strony dostrojenie tych podstawowych FM do dalszych zadań – które wymagają jedynie kilkudziesięciu lub setek oznaczonych próbek danych i obsługi wnioskowania – można wykonać za pomocą zaledwie kilku procesorów graficznych na brzegu przedsiębiorstwa. Dzięki temu wrażliwe, oznakowane dane (lub dane stanowiące klejnot koronny przedsiębiorstwa) mogą bezpiecznie pozostać w środowisku operacyjnym przedsiębiorstwa, jednocześnie zmniejszając koszty przesyłania danych.
Korzystając z podejścia pełnego stosu do wdrażania aplikacji na urządzeniach brzegowych, analityk danych może dostrajać, testować i wdrażać modele. Można to osiągnąć w jednym środowisku, skracając jednocześnie cykl rozwoju w celu udostępniania nowych modeli sztucznej inteligencji użytkownikom końcowym. Platformy takie jak Red Hat OpenShift Data Science (RHODS) i niedawno ogłoszona Red Hat OpenShift AI zapewniają narzędzia umożliwiające szybkie opracowywanie i wdrażanie gotowych do produkcji modeli sztucznej inteligencji w rozproszona chmura i środowiska brzegowe.
Wreszcie udostępnienie dopracowanego modelu sztucznej inteligencji na brzegu przedsiębiorstwa znacznie zmniejsza opóźnienia często związane z pozyskiwaniem, przesyłaniem, przekształcaniem i przetwarzaniem danych. Oddzielenie wstępnego szkolenia w chmurze od dostrajania i wnioskowania na brzegu sieci obniża całkowity koszt operacyjny poprzez redukcję wymaganego czasu i kosztów przenoszenia danych związanych z dowolnym zadaniem wnioskowania (patrz rysunek 3).
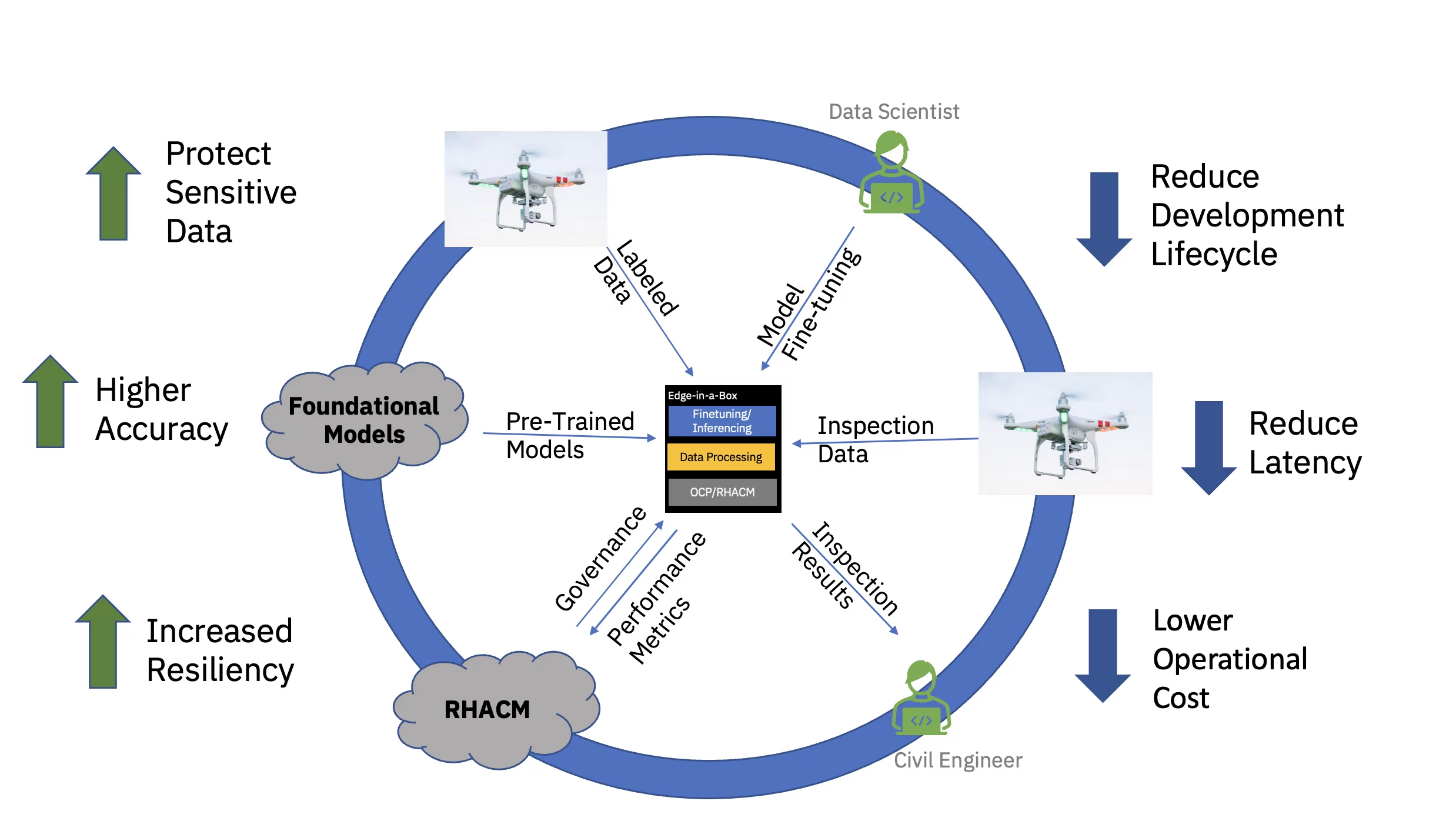
Aby kompleksowo zademonstrować tę propozycję wartości, dostrojono i wdrożono przykładowy model fundamentów infrastruktury cywilnej oparty na transformatorze wizyjnym (wstępnie przeszkolony przy użyciu publicznych i niestandardowych zbiorów danych specyficznych dla branży) i wdrożono go do wnioskowania na krawędzi z trzema węzłami (szprychowa) grupa. Stos oprogramowania obejmował platformę kontenerową Red Hat OpenShift i Red Hat OpenShift Data Science. Ten klaster brzegowy został również połączony z instancją koncentratora Red Hat Advanced Cluster Management for Kubernetes (RHACM) działającą w chmurze.
Udostępnianie bezdotykowe
Opartą na zasadach, bezdotykową aprowizację przeprowadzono za pomocą Red Hat Advanced Cluster Management for Kubernetes (RHACM) za pośrednictwem zasad i znaczników rozmieszczenia, które wiążą określone klastry brzegowe z zestawem komponentów oprogramowania i konfiguracji. Te komponenty oprogramowania — obejmujące cały stos i obejmujące obliczenia, pamięć masową, sieć i obciążenie sztucznej inteligencji — zostały zainstalowane przy użyciu różnych operatorów OpenShift, dostarczania wymaganych usług aplikacyjnych i S3 Bucket (pamięć masowa).
Wstępnie wytrenowany model podstawowy (FM) infrastruktury cywilnej został dostrojony za pomocą Jupyter Notebook w ramach Red Hat OpenShift Data Science (RHODS), korzystając z oznakowanych danych w celu sklasyfikowania sześciu typów defektów występujących na mostach betonowych. Obsługa wnioskowania tego precyzyjnie dostrojonego FM została również zademonstrowana przy użyciu serwera Triton. Co więcej, monitorowanie stanu tego systemu brzegowego było możliwe dzięki agregowaniu wskaźników obserwowalności ze sprzętu i oprogramowania za pośrednictwem Prometheusa do centralnego pulpitu RHACM w chmurze. Przedsiębiorstwa zajmujące się infrastrukturą cywilną mogą wdrażać te FM w swoich lokalizacjach brzegowych i wykorzystywać obrazy z dronów do wykrywania defektów w czasie zbliżonym do rzeczywistego, co przyspiesza uzyskiwanie informacji i zmniejsza koszty przenoszenia dużych ilości danych w wysokiej rozdzielczości do i z chmury.
Podsumowanie
łącząc IBM Watsonx Możliwości platformy danych i sztucznej inteligencji dla modeli podstawowych (FM) za pomocą urządzenia typu Edge-in-a-Box umożliwiają przedsiębiorstwom uruchamianie obciążeń AI w celu dostrajania FM i wnioskowania na krawędzi operacyjnej. To urządzenie od razu radzi sobie ze złożonymi przypadkami użycia i tworzy platformę typu hub-and-szprychy do scentralizowanego zarządzania, automatyzacji i samoobsługi. Wdrożenia Edge FM można skrócić z tygodni do godzin, zapewniając powtarzalny sukces, większą odporność i bezpieczeństwo.
Dowiedz się więcej o modelach podstawowych
Koniecznie zapoznaj się ze wszystkimi częściami tej serii postów na blogu na temat przetwarzania brzegowego:
Więcej z chmury




- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- O nas
- przyśpieszyć
- dostęp
- realizowane
- precyzja
- nabycie
- w poprzek
- Dzieje Apostolskie
- przystosowany
- do tego
- adres
- Adresy
- Przyjęcie
- zaawansowany
- postępy
- Reklama
- AI
- Przyjęcie AI
- Modele AI
- Platforma AI
- AID
- Algorytmy
- Wszystkie kategorie
- dopuszczać
- pozwala
- również
- Wśród
- ilość
- kwoty
- amp
- an
- analiza
- analityka
- i
- ogłosił
- każdy
- nigdzie
- Zastosowanie
- aplikacje
- podejście
- architektura
- SĄ
- Szyk
- artykuł
- sztuczny
- sztuczna inteligencja
- Sztuczna inteligencja (AI)
- AS
- powiązany
- At
- autor
- zautomatyzowane
- Automatyzacja
- dostępny
- Aleja
- z powrotem
- Bilans
- Bank
- Banki
- baza
- BE
- bo
- stają się
- staje
- być
- Początek
- jest
- uwierzyć
- BEST
- związania
- Blog
- Najnowsze wpisy
- blogi
- obie
- Pudełko
- mosty
- Bringing
- Przynosi
- szeroki
- szeroko
- Budowanie
- Buduje
- wybudowany
- biznes
- by
- CAN
- możliwości
- kapitał
- Przechwytywanie
- węgiel
- karta
- Kartki okolicznosciowe
- Etui
- CAT
- kategorie
- Spowodować
- Centrum
- centralny
- Bank centralny
- waluty cyfrowe banku centralnego
- scentralizowane
- łańcuch
- wyzwania
- zmiana
- wymiana pieniędzy
- ZOBACZ
- wybory
- koła
- CIS
- cywilny
- klasa
- Klasyfikuj
- jasny
- klientów
- dokładnie
- Chmura
- Grupa
- kolor
- kolorowy
- łączenie
- konkurencyjny
- kompleks
- kompleksowość
- spełnienie
- składniki
- obliczać
- computing
- systemu
- skonfigurowany
- połączony
- Łączność
- składa się
- Pojemnik
- kontynuować
- kontrola
- Koszty:
- Koszty:
- mógłby
- pokrycie
- kryptowaluta
- CSS
- waluty
- zwyczaj
- klient
- doświadczenie klienta
- Klientów
- tablica rozdzielcza
- dane
- Centrum danych
- Platforma danych
- nauka danych
- naukowiec danych
- zbiory danych
- Data
- dedykowane
- Domyślnie
- definicje
- dostarczyć
- wykazać
- wykazać
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- wdrożenia
- opisane
- opis
- zaprojektowany
- rozwijać
- rozwinięty
- oprogramowania
- cyfrowy
- waluty cyfrowe
- digitalizacja
- Zakłócenie
- uciążliwy
- Zakłócacze
- dystrybuowane
- dzielnica
- domena
- domeny
- zrobić
- napęd
- jazdy
- truteń
- każdy
- łatwo
- Ekosystem
- krawędź
- przetwarzanie krawędziowe
- ELEWACJA
- podniesiony
- umożliwiać
- Umożliwia
- zakończenia
- koniec końców
- inżynier
- Inżynieria
- Wchodzę
- Enterprise
- przedsiębiorstwa
- przychodzące
- Środowisko
- środowiska
- Era
- szczególnie
- itp
- Eter (ETH)
- Parzyste
- wydarzenia
- Każdy
- ewoluowały
- Badanie
- przykłady
- wykonać
- istnieć
- Wyjście
- drogi
- doświadczenie
- eksperci
- Wytłumaczalne AI
- wyjaśniając
- rozsuwalny
- niezwykle
- Czynniki
- FAST
- szybciej
- kilka
- pole
- Postać
- budżetowy
- Instytucje finansowe
- finansowanie
- i terminów, a
- podłogi
- obserwuj
- następujący
- czcionki
- W razie zamówieenia projektu
- czoło
- znaleziono
- Fundacja
- frakcja
- Framework
- od
- pełny
- Pełny stos
- Ponadto
- ogólnie
- wygenerowane
- generator
- geograficzny
- Geopolityka
- Dający
- Globalne
- global Trade
- zarządzanie
- GPU
- GPU
- Krata
- ręka
- uchwyt
- sprzęt komputerowy
- kapelusz
- Have
- Zdrowie
- wysokość
- pomoc
- pomoc
- pomaga
- wysoka rozdzielczość
- wyższy
- wysoko
- historia
- gospodarz
- GODZINY
- W jaki sposób
- How To
- Jednak
- HTTPS
- Piasta
- Ludzie
- Setki
- Hybrydowy
- Chmura hybrydowa
- IBM
- IBM Cloud
- ICO
- ICON
- ilustruje
- obraz
- Rezultat
- znaczenie
- poprawa
- in
- zawierać
- włączony
- wzrastający
- coraz bardziej
- wskaźnik
- przemysłowy
- przemysłowa
- przemysł
- specyficzne dla branży
- inflacja
- Przegięcie
- Punkt przegięcia
- pod wpływem
- Infrastruktura
- inicjatywa
- Innowacja
- Innowacyjny
- Wejścia
- spostrzeżenia
- przykład
- instytucje
- zintegrowany
- Inteligencja
- wewnętrzny
- wprowadzenie
- IT
- Wsparcie IT
- Podróże
- jpg
- skok
- Notebook Jupyter
- właśnie
- tylko jeden
- trzymane
- Klawisz
- Kubernetes
- etykietowanie
- język
- duży
- w dużej mierze
- Utajenie
- firmy
- nioski
- prowadzący
- UCZYĆ SIĘ
- nauka
- Dźwignia
- wifecycwe
- lubić
- bezgraniczny
- linux
- miejscowy
- lokalny
- lokalizacja
- lokalizacji
- długo
- Popatrz
- maszyna
- uczenie maszynowe
- zrobiony
- utrzymać
- robić
- WYKONUJE
- zarządzanie
- i konserwacjami
- produkcja
- wiele
- Oznakowanie
- masywny
- mistrz
- Materia
- Maksymalna szerokość
- Mechanizmy
- metody
- Metryka
- min
- minimalizowanie
- minuty
- ML
- Aplikacje mobilne
- model
- modele
- Nowoczesne technologie
- modernizacja
- zmodernizować
- monitor
- monitorowanie
- jeszcze
- ruch
- przeniesienie
- Nazwa
- Nawigacja
- Blisko
- niezbędny
- Potrzebować
- potrzebne
- wymagania
- sieć
- Nowości
- Następny
- nlp
- notatnik
- nic
- już dziś
- numer
- liczny
- of
- oferuje
- często
- on
- ONE
- tylko
- koncepcja
- otwierany
- operacyjny
- operacje
- operatorzy
- zoptymalizowane
- or
- organizacja
- Inne
- ludzkiej,
- na zewnątrz
- ogólny
- Pakiety
- strona
- parametr
- płatność
- Metody Płatności
- płatności
- wykonać
- wykonywane
- PHP
- umieszczenie
- Platforma
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- wtyczka
- punkt
- polityka
- polityka
- position
- możliwy
- Post
- Wiadomości
- potencjał
- power
- mocny
- Przewidywania
- Wcześniejszy
- prywatność
- prywatny
- problemy
- przetwarzanie
- produkować
- profesjonalny
- propozycja
- zapewniać
- publiczny
- Naciskać
- zasięg
- szybko
- Czytający
- w czasie rzeczywistym
- niedawno
- rekord
- nagranie
- Czerwony
- Red Hat
- zmniejszyć
- Zredukowany
- zmniejsza
- redukcja
- regulamin
- Regulatory
- regulacyjne
- związane z
- Usunięto
- powtarzalne
- wymagać
- wymagany
- wymagania
- wymagany
- Badania naukowe
- Zasoby
- odpowiedź
- odpowiedzialny
- czuły
- detaliczny
- Rosnąć
- roboty
- run
- bieganie
- bezpiecznie
- taki sam
- Skalowalność
- Skala
- skala ai
- skalowaniem
- nauka
- Naukowiec
- Ekran
- skrypty
- druga
- bezpiecznie
- bezpieczeństwo
- widzieć
- widzenie
- wybór
- Samoobsługa
- wrażliwy
- seo
- wrzesień
- Serie
- serwer
- usługa
- Usługi
- służąc
- Sesja
- Sesje
- zestaw
- kilka
- Share
- pokazać
- znaczący
- znacznie
- podobny
- ponieważ
- Singapur
- pojedynczy
- pojedyncze środowisko
- witryna internetowa
- Witryny
- SIX
- umiejętności
- mały
- EMS
- MŚP
- Tworzenie
- komponenty oprogramowania
- rozwiązanie
- suwerenność
- Typ przestrzeni
- napięcie
- specyficzny
- swoiście
- Łącza
- stos
- początek
- state-of-the-art
- pobyt
- Cel
- przechowywanie
- sklep
- przechowywany
- sklep
- burza
- studio
- przedmiot
- sukces
- taki
- Wskazuje
- Dostawa
- łańcuch dostaw
- wsparcie
- pewnie
- system
- Brać
- Zadania
- Zadanie
- zadania
- Techniki
- Technologia
- Telco
- Temenos
- kilkadziesiąt
- Terraform
- przetestowany
- Testowanie
- że
- Połączenia
- ich
- motyw
- Tam.
- Te
- one
- to
- Przez
- czas
- aktualny
- czasy
- Tytuł
- do
- już dziś
- razem
- Zestaw narzędzi
- narzędzia
- Top
- handel
- tradycyjny
- Pociąg
- przeszkolony
- Trening
- przenieść
- Przekształcać
- Transformacja
- przemiany
- przezroczysty
- Tryton
- i twitterze
- drugiej
- rodzaj
- typy
- uwolniony
- Aktualizacja
- Nowości
- URL
- us
- posługiwać się
- używany
- Użytkownicy
- za pomocą
- wykorzystać
- wykorzystany
- Cenny
- wartość
- wartość oferty
- różnorodność
- różnorodny
- Naprawiono
- przez
- Zobacz i wysłuchaj
- prawie
- Tom
- kłęby
- W
- Czekanie
- Portfel
- była
- fala
- Droga..
- sposoby
- we
- tydzień
- tygodni
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- KIM
- dlaczego
- szeroki
- Szeroki zasięg
- w
- w ciągu
- kobieta
- WordPress
- Praca
- przepływów pracy
- pracujący
- by
- napisany
- Twój
- zefirnet











