W dzisiejszym świecie klienci zarządzają ogromnymi ilościami danych Usługa Amazon Simple Storage (Amazon S3) jeziora danych, które wymagają skomplikowanych potoków danych, aby stale rozumieć zmiany w układzie danych i udostępniać je konsumującym systemom. Klej AWS roboty indeksujące zapewniają prosty sposób katalogowania danych w AWS Glue Data Catalog, co eliminuje konieczność podnoszenia ciężarów, jeśli chodzi o zarządzanie schematami i klasyfikację danych. Roboty indeksujące AWS Glue wyodrębniają schemat danych i partycje z usługi Amazon S3, aby automatycznie wypełniać katalog danych, zachowując aktualność metadanych.
Jednak przy wykładniczym wzroście danych w czasie liczba partycji w danej tabeli może znacznie wzrosnąć. Ponieważ usługi analityczne, takie jak Amazonka Atena zapytania do tabeli zawierającej miliony partycji, czas potrzebny do pobrania partycji wzrasta i może spowodować wydłużenie czasu wykonywania zapytania.
Obecnie obsługa robota indeksującego AWS Glue została rozszerzona o automatyczne dodawanie indeksów partycji dla nowo odkrytych tabel w celu optymalizacji przetwarzania zapytań w partycjonowanym zbiorze danych. Teraz, gdy przeszukiwacz tworzy nową tabelę Data Catalog podczas działania przeszukiwacza, domyślnie tworzy również indeks partycji z największą permutacją ze wszystkich kolumn partycji typu liczbowego i łańcuchowego jako kluczami. Katalog danych tworzy następnie przeszukiwalny indeks oparty na tych kluczach, skracając czas wymagany do pobierania i filtrowania metadanych partycji w tabelach z milionami partycji. Tworzenie indeksów partycji jest korzystne dla obciążeń analitycznych działających w systemie Athena, Amazon EMR, Widmo przesunięcia ku czerwieni Amazonkii kleju AWS.
W tym poście opisujemy, jak tworzyć indeksy partycji za pomocą robota indeksującego AWS Glue i porównujemy poprawę wydajności zapytań podczas uzyskiwania dostępu do przeszukiwanych danych z indeksem partycji z Atheny i bez niego.
Omówienie rozwiązania
Używamy Tworzenie chmury AWS szablon do tworzenia naszych zasobów rozwiązań. W poniższych krokach pokazujemy, jak skonfigurować robota indeksującego AWS Glue do tworzenia indeksu partycji przy użyciu konsoli AWS Glue lub Interfejs wiersza poleceń AWS (AWS CLI). Następnie porównujemy ulepszenia wydajności zapytań przy użyciu Atheny.
Wymagania wstępne
Aby śledzić ten post, musisz mieć dostęp do an AWS Zarządzanie tożsamością i dostępem (IAM) rola administratora do tworzenia zasobów przy użyciu AWS CloudFormation.
Skonfiguruj zasoby rozwiązania
Szablon CloudFormation generuje następujące zasoby:
- Role i zasady uprawnień
- Baza danych AWS Glue do przechowywania schematu
- Robot indeksujący AWS Glue wskazujący na mocno podzielony zbiór danych
- Grupa robocza Athena i zasobnik do przechowywania wyników zapytań
Wykonaj następujące kroki, aby skonfigurować zasoby rozwiązania:
- Zaloguj się, aby Konsola zarządzania AWS jako administrator IAM.
- Dodaj Uruchom stos aby wdrożyć szablon CloudFormation:

- W razie zamówieenia projektu Nazwa bazy danychzachowaj wartość domyślną
blog_partition_index_crawlerdb.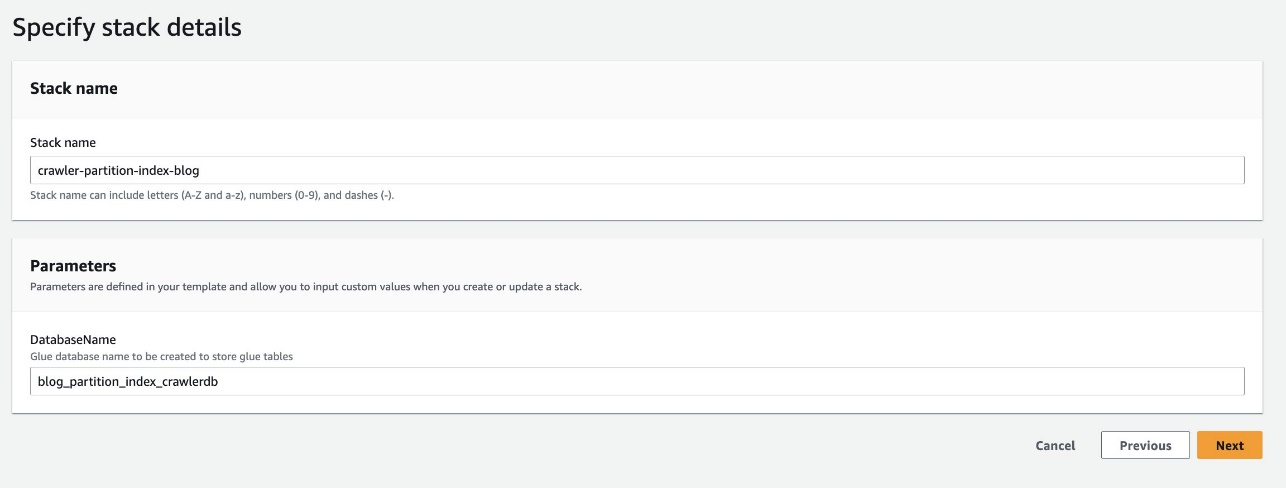
- Dodaj Następna.
- Przejrzyj szczegóły na ostatniej stronie i wybierz Przyjmuję do wiadomości, że AWS CloudFormation może tworzyć zasoby IAM.
- Dodaj Utwórz stos.
- Gdy stos jest kompletny, w konsoli AWS CloudFormation przejdź do pliku Wyjścia zakładka stosu.
- Zanotuj wartości
DatabaseNameiGlueCrawlerName.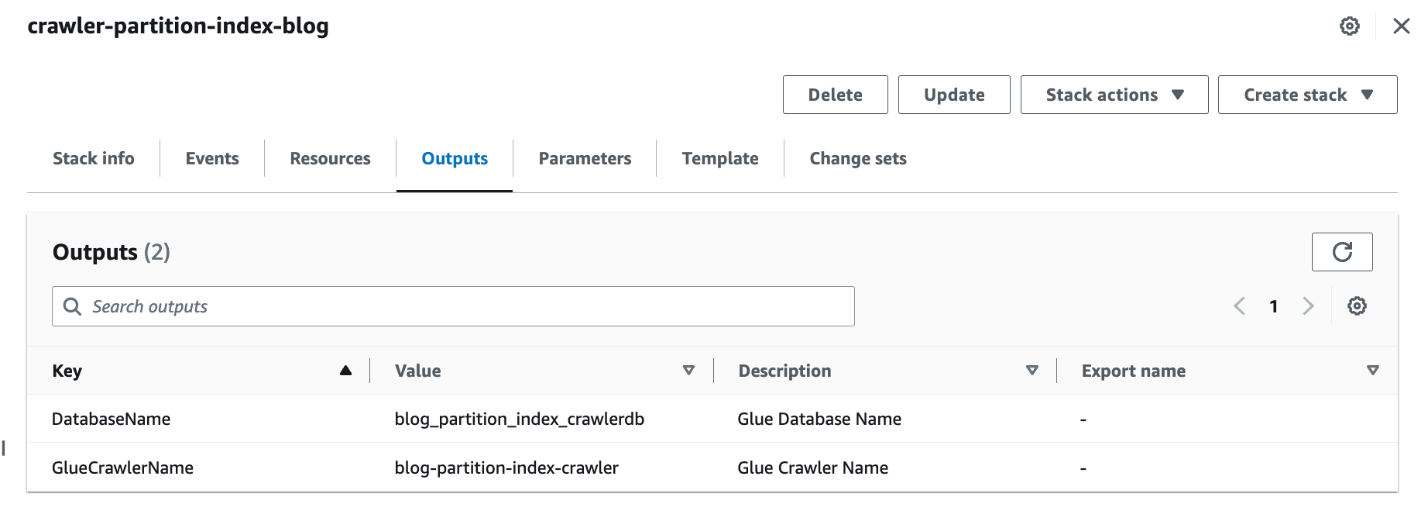
Niektóre zasoby wdrażane przez ten stos wiążą się z kosztami, gdy są używane.
Edytuj i uruchom robota indeksującego AWS Glue
Aby skonfigurować i uruchomić robota indeksującego AWS Glue, wykonaj następujące kroki:
- Na konsoli AWS Glue wybierz Roboty w okienku nawigacji.
- Zlokalizuj
crawler blog-partition-index-crawleri wybierz Edytuj.
- W Ustaw wydajność i harmonogram sekcja, pod Opcje zaawansowane, Wybierz Automatyczne tworzenie indeksów partycji.
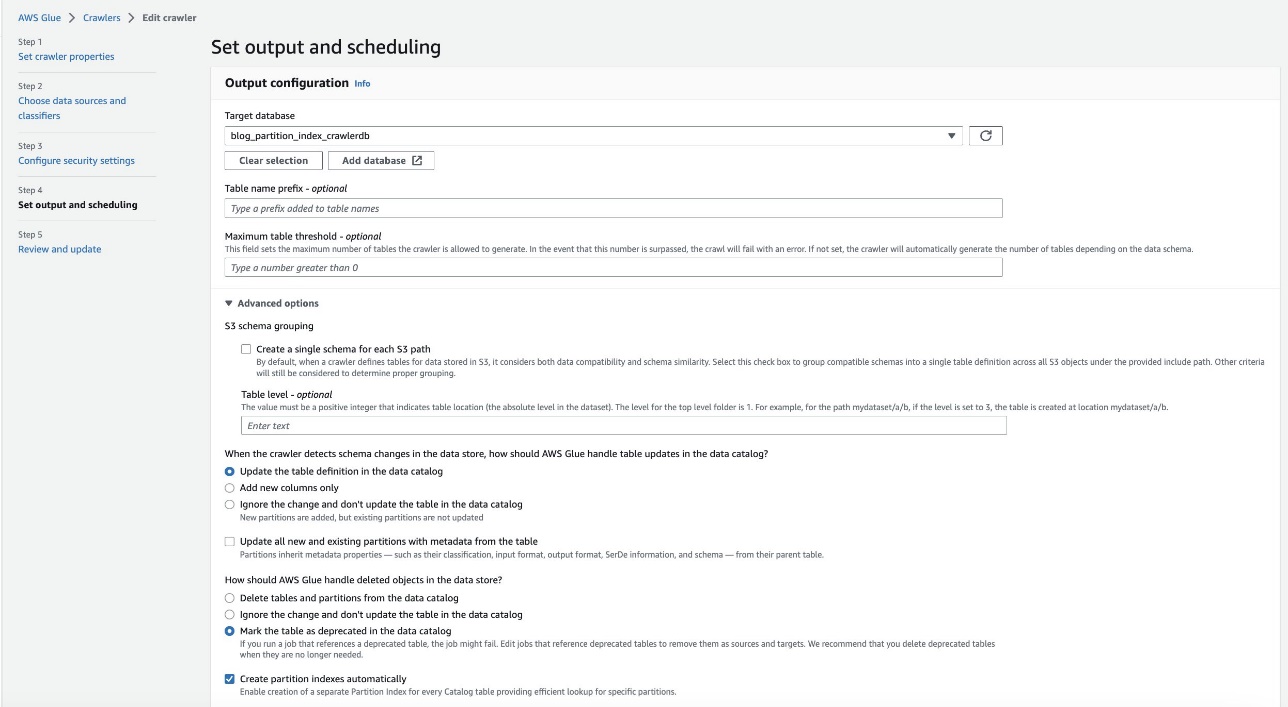
- Przejrzyj i zaktualizuj ustawienia robota.
Alternatywnie możesz skonfigurować robota za pomocą AWS CLI (podaj swoją rolę IAM i region):
- Teraz uruchom przeszukiwacz i sprawdź, czy przebieg przeszukiwacza został zakończony.
Jest to wysoce podzielony na partycje zestaw danych, a jego ukończenie zajmie około 90 minut.
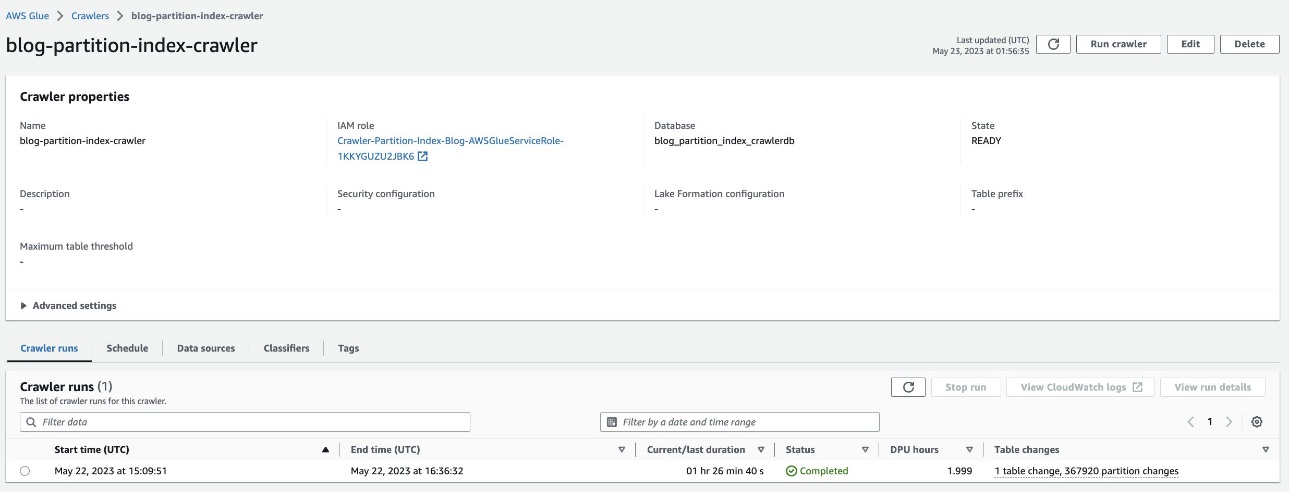
Sprawdź partycjonowaną tabelę
W bazie danych AWS Glue blog_partition_index_crawlerdb, sprawdź, czy tabela highly_partitioned_table jest tworzony.
Domyślnie przeszukiwacz określa indeks na podstawie największej permutacji kolumn partycji poprawnych typów kolumn w tej samej kolejności kolumn partycji, które są numeryczne lub łańcuchowe. Dla tabeli utworzonej przez robota (highly_partitioned_table), mamy kolumny partycji year (strunowy), month (strunowy), day (ciąg) i hour (strunowy).
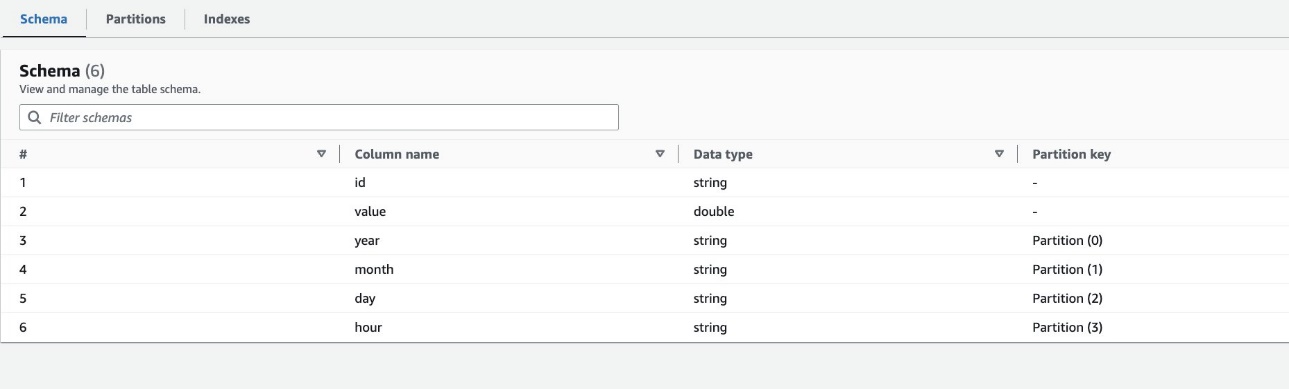
Na podstawie tej definicji robot indeksujący utworzył indeks zawierający permutację roku, miesiąca, dnia i godziny. Przeszukiwacz utworzył indeksy poprzedzone przedrostkiem crawler_ na dowolnym indeksie partycji utworzonym domyślnie.
Sprawdź to samo, przechodząc do tabeli highly_partitioned_table na konsoli AWS Glue i wybierając Indeksy patka.
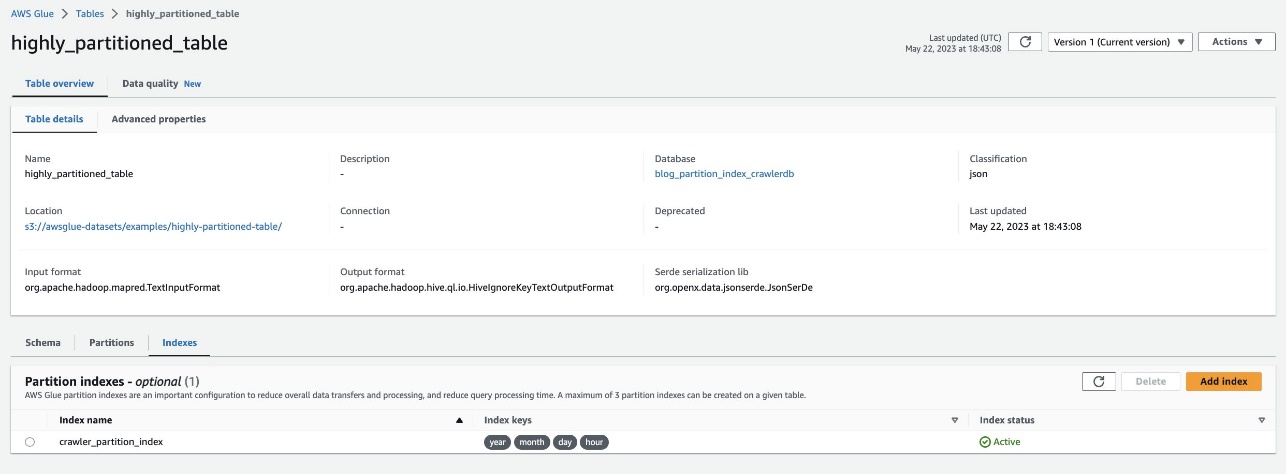
Przeszukiwacz mógł przeszukać źródło danych S3 i pomyślnie wypełnić indeksy partycji dla tabeli.
Porównaj ulepszenia wydajności zapytań za pomocą Athena
Najpierw wysyłamy zapytanie do tabeli w Athenie bez użycia indeksu partycji. Aby zweryfikować tabele za pomocą Atheny, wykonaj następujące kroki:
- Na konsoli Athena wybierz
crawler-primary-workgroupjako grupa robocza Athena i wybierz Uznać.
- Uruchom następujące zapytanie:
Poniższy zrzut ekranu pokazuje, że kwerenda trwała około 32 sekund bez włączonego filtrowania przy użyciu indeksu partycji.
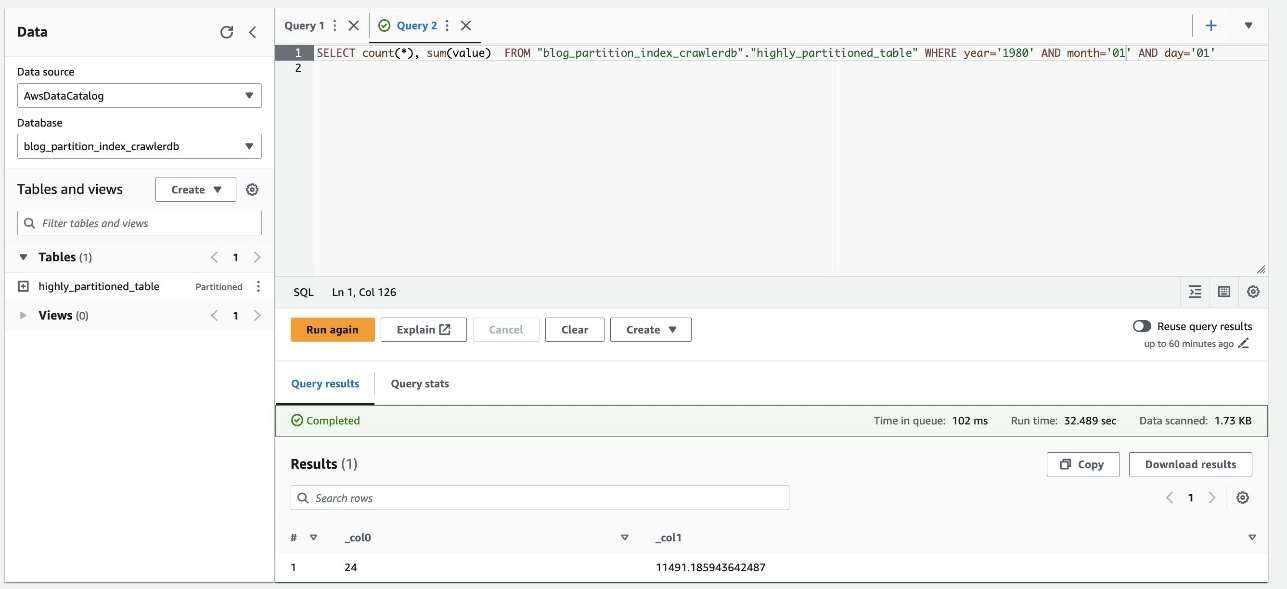
- Teraz włączamy indeks partycji w zapytaniu Athena:
- Ponownie uruchom następujące zapytanie i zanotuj środowisko wykonawcze:
Poniższy zrzut ekranu pokazuje, że kwerenda zajęła tylko 700 milisekund, co jest znacznie szybsze przy włączonym filtrowaniu przy użyciu indeksu partycji.
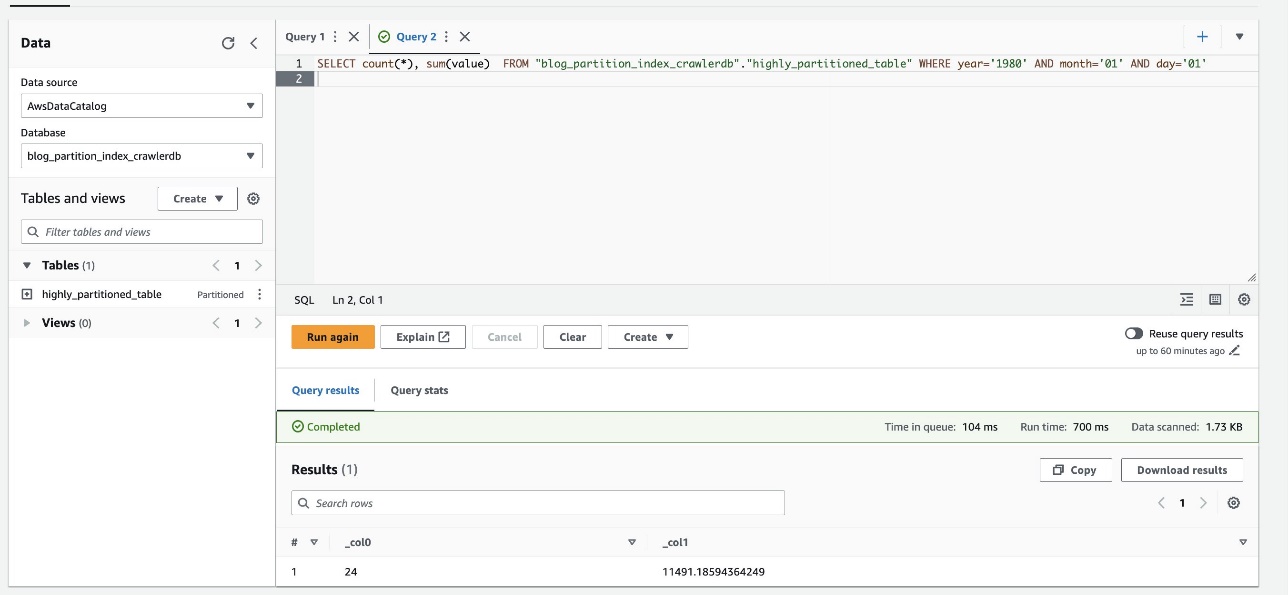
Sprzątać
Aby uniknąć niechcianych obciążeń konta AWS, możesz usunąć zasoby AWS:
- Zaloguj się do konsoli CloudFormation jako administrator IAM używany do tworzenia stosu CloudFormation.
- Usuń utworzony stos CloudFormation.
Wnioski
W tym poście wyjaśniliśmy, jak skonfigurować robota AWS do tworzenia indeksów partycji i porównaliśmy wydajność zapytania podczas uzyskiwania dostępu do danych z indeksami z Atheny.
Jeśli w tabeli nie ma indeksów partycji, AWS Glue ładuje wszystkie partycje tabeli, a następnie filtruje załadowane partycje, co skutkuje nieefektywnym pobieraniem metadanych. Usługi analityczne, takie jak Redshift Spectrum, Amazon EMR i AWS Glue ETL Spark DataFrames, mogą teraz wykorzystywać indeksy do pobierania partycji, co zapewnia znaczną wydajność zapytań.
Aby uzyskać więcej informacji na temat indeksów partycji i wydajności zapytań w różnych aparatach analitycznych, zobacz Popraw wydajność zapytań Amazon Athena za pomocą indeksów partycji AWS Glue Data Catalog i Popraw wydajność zapytań za pomocą indeksów partycji AWS Glue.
Specjalne podziękowania dla wszystkich, którzy przyczynili się do uruchomienia tej funkcji robota: Yuhang Chen, Kyle Duong i Mita Gavade.
O autorach
 Śrividya Parthasarathy jest starszym architektem Big Data w zespole AWS Lake Formation. Lubi budować rozwiązania data mesh i dzielić się nimi ze społecznością.
Śrividya Parthasarathy jest starszym architektem Big Data w zespole AWS Lake Formation. Lubi budować rozwiązania data mesh i dzielić się nimi ze społecznością.
 Sandeepa Adwankara jest Senior Technical Product Managerem w AWS. Mieszka w California Bay Area i współpracuje z klientami na całym świecie, aby przełożyć wymagania biznesowe i techniczne na produkty, które umożliwiają klientom poprawę zarządzania danymi, ich zabezpieczania i uzyskiwania do nich dostępu.
Sandeepa Adwankara jest Senior Technical Product Managerem w AWS. Mieszka w California Bay Area i współpracuje z klientami na całym świecie, aby przełożyć wymagania biznesowe i techniczne na produkty, które umożliwiają klientom poprawę zarządzania danymi, ich zabezpieczania i uzyskiwania do nich dostępu.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- EVM Finanse. Ujednolicony interfejs dla zdecentralizowanych finansów. Dostęp tutaj.
- Quantum Media Group. Wzmocnienie IR/PR. Dostęp tutaj.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :ma
- :Jest
- :Gdzie
- $W GÓRĘ
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Zdolny
- dostęp
- Dostęp
- Konto
- uznać
- w poprzek
- Dodaj
- Admin
- ponownie
- Wszystkie kategorie
- wzdłuż
- również
- Amazonka
- Amazonka Atena
- Amazon EMR
- Amazon Web Services
- kwoty
- an
- Analityczny
- analityka
- i
- każdy
- w przybliżeniu
- SĄ
- POWIERZCHNIA
- na około
- AS
- At
- automatycznie
- dostępny
- uniknąć
- AWS
- Tworzenie chmury AWS
- Klej AWS
- Formacja AWS Lake
- na podstawie
- Zatoka
- bo
- być
- Korzyści
- Duży
- Big Data
- Budowanie
- biznes
- by
- California
- CAN
- katalog
- Spowodować
- Zmiany
- Opłaty
- chen
- Dodaj
- Wybierając
- klasyfikacja
- Kolumna
- kolumny
- byliśmy spójni, od początku
- społeczność
- porównać
- w porównaniu
- kompletny
- Konsola
- bez przerwy
- przyczyniły
- Koszty:
- crawler
- Stwórz
- stworzony
- tworzy
- Tworzenie
- tworzenie
- Aktualny
- Klientów
- dane
- dostęp do danych
- Jezioro danych
- Baza danych
- dzień
- Domyślnie
- wykazać
- rozwijać
- wdraża się
- opisać
- detale
- określa
- odkryty
- na dół
- podczas
- skutecznie
- bądź
- umożliwiać
- włączony
- silniki
- Eter (ETH)
- wszyscy
- rozszerzony
- wyjaśnione
- wykładniczo
- wyciąg
- wyodrębnić dane
- szybciej
- Cecha
- filtrować
- filtracja
- filtry
- finał
- obserwuj
- następujący
- W razie zamówieenia projektu
- formacja
- od
- generuje
- dany
- globus
- Rosnąć
- Rozwój
- Have
- he
- ciężki
- ciężkie podnoszenie
- wysoko
- przytrzymaj
- godzina
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- IAM
- tożsamość
- podnieść
- poprawa
- ulepszenia
- in
- Zwiększać
- Zwiększenia
- wskaźnik
- indeksy
- niewydajny
- Informacja
- najnowszych
- IT
- jpg
- Trzymać
- konserwacja
- Klawisze
- jezioro
- największym
- uruchomić
- układ
- Modernizacja
- lubić
- Linia
- masa
- robić
- zarządzanie
- i konserwacjami
- kierownik
- siatka
- Metadane
- może
- miliony
- minuty
- Miesiąc
- jeszcze
- dużo
- musi
- Nawigacja
- żeglujący
- Nawigacja
- potrzebne
- Nowości
- nowo
- Nie
- już dziś
- numer
- of
- on
- tylko
- Optymalizacja
- or
- zamówienie
- ludzkiej,
- wydajność
- koniec
- strona
- chleb
- ścieżka
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- plato
- Analiza danych Platona
- PlatoDane
- Post
- teraźniejszość
- przetwarzanie
- Produkt
- product manager
- Produkty
- zapewniać
- redukcja
- region
- wymagany
- wymagania
- Wymaga
- Zasoby
- wynikły
- Efekt
- Rola
- role
- run
- bieganie
- taki sam
- sekund
- Sekcja
- bezpieczne
- senior
- Usługi
- zestaw
- w panelu ustawień
- dzielenie
- ona
- Targi
- znaczący
- znacznie
- Prosty
- rozwiązanie
- Rozwiązania
- Źródło
- Iskra
- Widmo
- stos
- Cel
- przechowywanie
- sklep
- bezpośredni
- sznur
- Z powodzeniem
- wsparcie
- systemy
- stół
- Brać
- zespół
- Techniczny
- szablon
- dzięki
- że
- Połączenia
- ich
- Im
- następnie
- Te
- one
- to
- czas
- do
- dzisiaj
- wziął
- tłumaczyć
- prawdziwy
- rodzaj
- typy
- dla
- zrozumieć
- niepożądany
- Aktualizacja
- posługiwać się
- używany
- za pomocą
- wykorzystać
- wartość
- Wartości
- różnorodny
- Naprawiono
- zweryfikować
- wersja
- była
- Droga..
- we
- sieć
- usługi internetowe
- jeśli chodzi o komunikację i motywację
- który
- KIM
- będzie
- w
- bez
- Workgroup
- działa
- świat
- jamla
- rok
- ty
- Twój
- zefirnet