Automatyczna analiza danych (ADA) w AWS to rozwiązanie AWS, które umożliwia wyciąganie znaczących wniosków z danych w ciągu kilku minut za pomocą prostego i intuicyjnego interfejsu użytkownika. ADA oferuje platformę analizy danych natywną dla AWS, gotową do użycia od razu po wyjęciu z pudełka przez analityków danych w różnych przypadkach użycia. Dzięki ADA zespoły mogą pozyskiwać, przekształcać, zarządzać i wysyłać zapytania do różnorodnych zestawów danych z różnych źródeł danych bez konieczności posiadania specjalistycznych umiejętności technicznych. ADA zapewnia zestaw gotowe złącza do pozyskiwania danych z wielu różnych źródeł, w tym Usługa Amazon Simple Storage (Amazonka S3), Strumienie danych Amazon Kinesis, Amazon Cloud Watch, Amazon CloudTrail, Amazon DynamoDB jak również wiele innych.
ADA zapewnia podstawową platformę, z której mogą korzystać analitycy danych w różnorodnych zastosowaniach, w tym w IT, finansach, marketingu, sprzedaży i bezpieczeństwie. Gotowy do użycia łącznik danych CloudWatch ADA umożliwia pozyskiwanie danych z dzienników CloudWatch na tym samym koncie AWS, na którym wdrożono ADA, lub z innego konta AWS.
W tym poście pokazujemy, w jaki sposób programista lub tester aplikacji może wykorzystać ADA do uzyskania wglądu operacyjnego w aplikacje działające w AWS. Pokazujemy również, jak można wykorzystać rozwiązanie ADA do łączenia się z różnymi źródłami danych w AWS. My pierwsi wdrożyć rozwiązanie ADA na konto AWS i skonfiguruj rozwiązanie ADA tworząc produkty danych za pomocą złączy danych. Następnie używamy narzędzia ADA Query Workbench do łączenia oddzielnych zbiorów danych i wysyłania zapytań do skorelowanych danych przy użyciu znanego strukturalnego języka zapytań (SQL) w celu uzyskania wglądu. Pokazujemy również, jak ADA można zintegrować z narzędziami Business Intelligence (BI), takimi jak Tableau, w celu wizualizacji danych i tworzenia raportów.
Omówienie rozwiązania
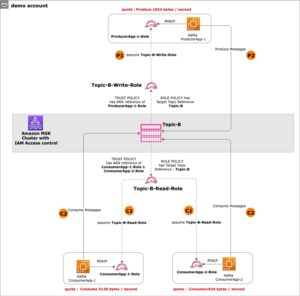
W tej sekcji przedstawiamy architekturę rozwiązania dla wersji demonstracyjnej i wyjaśniamy przepływ pracy. W celach demonstracyjnych aplikacja na zamówienie jest symulowana przy użyciu pliku AWS Lambda funkcja emitująca logowanie Format dziennika Apache w ustalonych odstępach czasu za pomocą Most zdarzeń Amazona. Ten standardowy format może być generowany przez wiele różnych serwerów internetowych i odczytywany przez wiele programów do analizy logów. Dzienniki aplikacji (funkcja Lambda) są wysyłane do grupy dzienników CloudWatch. Historyczne dzienniki aplikacji są przechowywane w zasobniku S3 w celach informacyjnych i do celów wykonywania zapytań. Tabela przeglądowa z listą Kody stanu HTTP wraz z opisami jest przechowywany w tabeli DynamoDB. Te trzy służą jako źródła, z których dane są pobierane do ADA w celu korelacji, zapytań i analiz. My wdrożyć rozwiązanie ADA na konto AWS i skonfiguruj ADA. Następnie tworzymy produkty danych w ramach ADA dla Grupa dzienników CloudWatch, Wiadro S3, DynamoDB. Po skonfigurowaniu produktów danych ADA udostępnia potoki danych w celu pozyskiwania danych ze źródeł. Za pomocą narzędzia ADA Query Workbench można wysyłać zapytania do pobranych danych przy użyciu zwykłego języka SQL w celu rozwiązywania problemów z aplikacjami lub diagnozowania problemów.
Poniższy diagram przedstawia przegląd architektury i przepływu pracy przy użyciu ADA w celu uzyskania wglądu w dzienniki aplikacji.
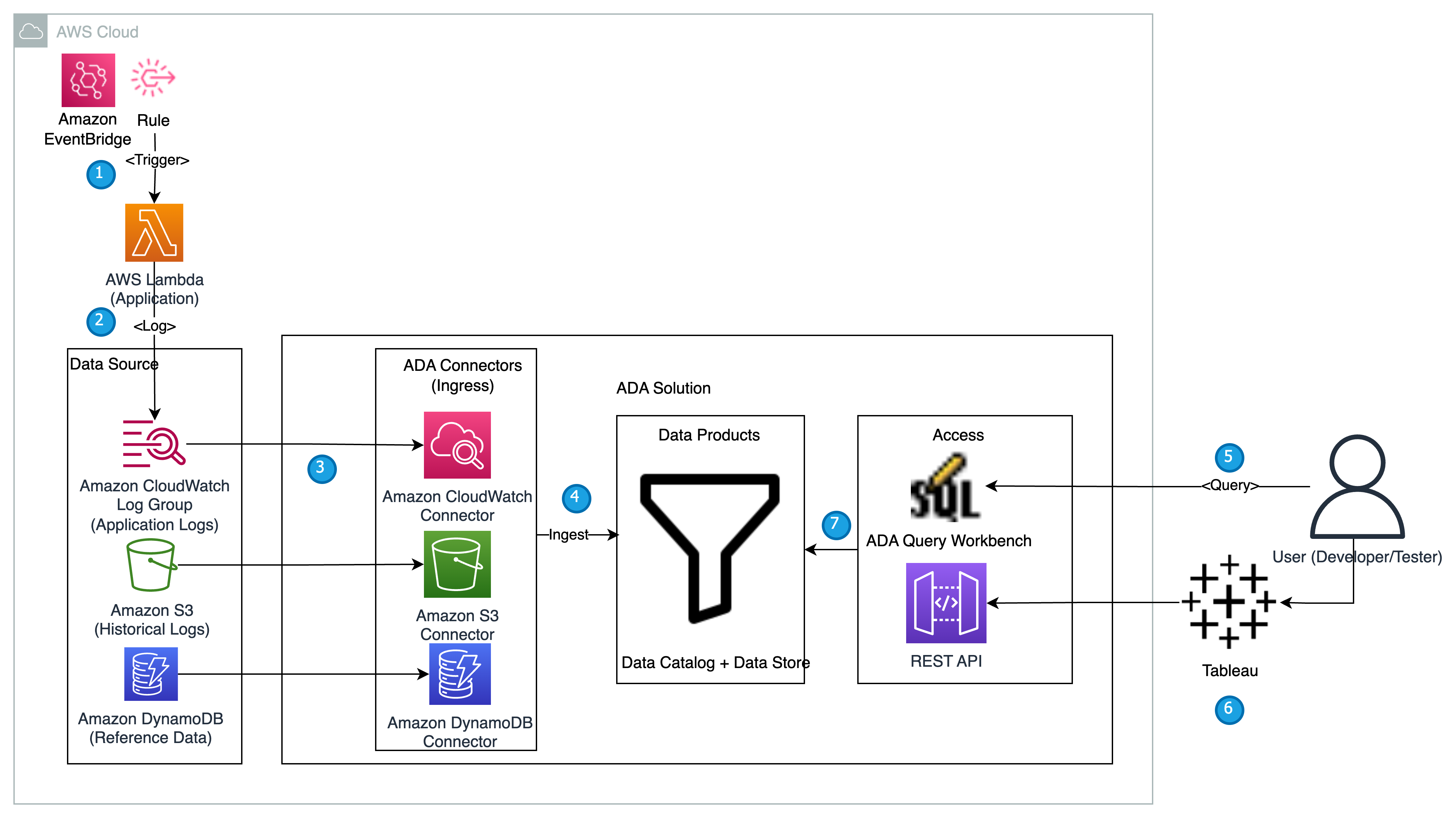
Przepływ pracy obejmuje następujące kroki:
- Zaplanowano wyzwalanie funkcji Lambda w 2-minutowych odstępach przy użyciu EventBridge.
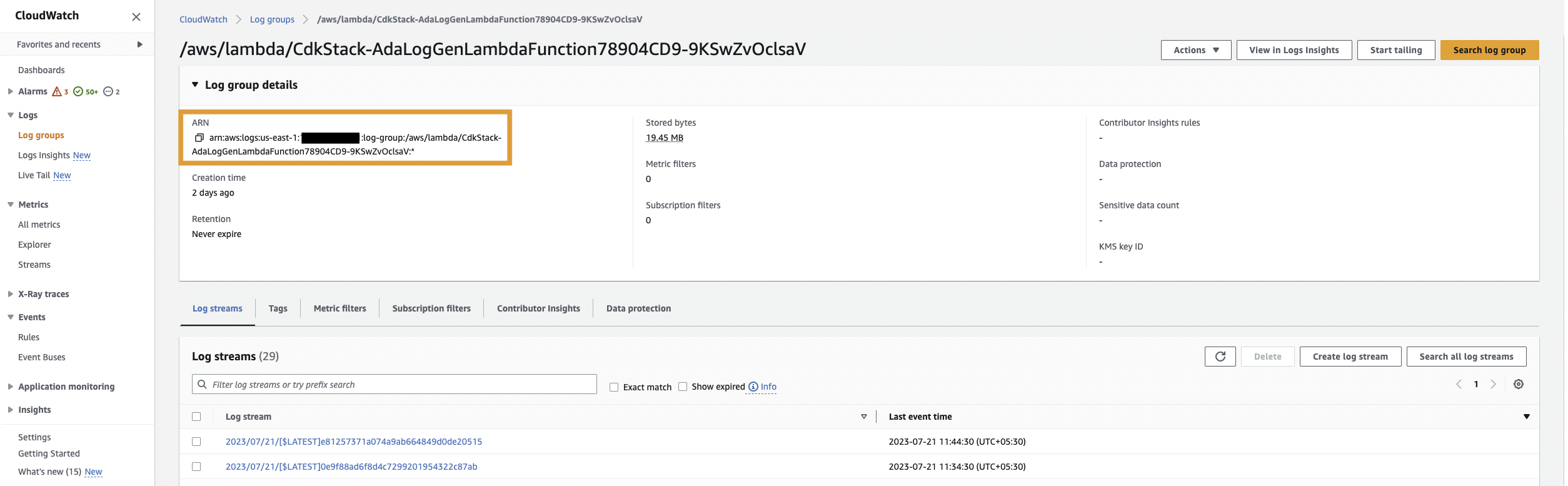
- Funkcja Lambda emituje dzienniki przechowywane w określonej grupie dzienników CloudWatch w obszarze
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Dzienniki aplikacji są generowane przy użyciu schematu Apache Log Format, ale są przechowywane w grupie dzienników CloudWatch w formacie JSON. - Produkty danych dla CloudWatch, Amazon S3 i DynamoDB są tworzone w ADA. Produkt danych CloudWatch łączy się z grupą dzienników CloudWatch, w której przechowywane są dzienniki aplikacji (funkcja Lambda). Złącze Amazon S3 łączy się z folderem segmentu S3, w którym przechowywane są dzienniki historyczne. Łącznik DynamoDB łączy się z tabelą DynamoDB, w której przechowywane są kody stanu przywoływane przez aplikację oraz dzienniki historyczne.
- Dla każdego produktu danych ADA wdraża infrastrukturę potoku danych w celu pozyskiwania danych ze źródeł. Po zakończeniu pozyskiwania danych można pisać zapytania przy użyciu języka SQL za pośrednictwem narzędzia ADA Query Workbench.
- Możesz zalogować się do portalu ADA i tworzyć zapytania SQL z Query Workbench, aby uzyskać wgląd w dzienniki aplikacji. Opcjonalnie możesz zapisać zapytanie i udostępnić je innym użytkownikom ADA w tej samej domenie. Funkcja zapytań ADA jest obsługiwana przez Amazonka Atenato bezserwerowa, interaktywna usługa analityczna zapewniająca uproszczony i elastyczny sposób analizowania petabajtów danych.
- Tableau jest skonfigurowany tak, aby uzyskać dostęp do produktów danych ADA za pośrednictwem wyjściowych punktów końcowych ADA. Następnie tworzysz dashboard z dwoma wykresami. Pierwszy wykres to mapa cieplna pokazująca częstość występowania kodów błędów HTTP skorelowanych z punktami końcowymi API aplikacji. Drugi wykres to wykres słupkowy przedstawiający 10 najważniejszych interfejsów API aplikacji wraz z całkowitą liczbą kodów błędów HTTP na podstawie danych historycznych.
Wymagania wstępne
Aby móc pracować na tym stanowisku, musisz spełnić następujące wymagania wstępne:
- Instalacja Interfejs wiersza poleceń AWS (interfejs wiersza poleceń AWS), Zestaw programistyczny AWS Cloud (CDK AWS) warunki wstępne, specyficzne dla TypeScriptu warunki wstępne, odrzutowiec.
- Rozmieścić rozwiązanie ADA na Twoim koncie AWS w
us-east-1Region.- Podaj adres e-mail administratora podczas uruchamiania ADA Tworzenie chmury AWS stos. Jest to potrzebne, aby ADA wysłała hasło użytkownika root. Jeśli włączone jest uwierzytelnianie wieloskładnikowe (MFA), do otrzymania wiadomości z hasłem jednorazowym wymagany jest numer telefonu administratora. W przypadku tej wersji demonstracyjnej usługa MFA nie jest włączona.
- Kompiluj i wdrażaj przykładową aplikację (dostępną w witrynie GitHub repo) rozwiązanie, dzięki któremu na Twoim koncie będzie można udostępnić następujące zasoby w
us-east-1Region:- Funkcja Lambda symulująca aplikację logującą oraz reguła EventBridge wywołująca funkcję aplikacji w odstępach 2-minutowych.
- Wiadro S3 z odpowiednimi zasadami zasobnika i plik CSV zawierający historyczne logi aplikacji.
- Tabela DynamoDB z danymi wyszukiwania.
- Istotnych AWS Zarządzanie tożsamością i dostępem (IAM) role i uprawnienia wymagane dla usług.
- Opcjonalnie zainstaluj Tableau na pulpicie, zewnętrzny dostawca BI. W tym poście używamy Tableau Desktop w wersji 2021.2. Korzystanie z licencjonowanej wersji aplikacji Tableau Desktop wiąże się z pewnymi kosztami. Dodatkowe szczegóły można znaleźć w Licencja na tableau informacje.
Wdróż i skonfiguruj usługę ADA
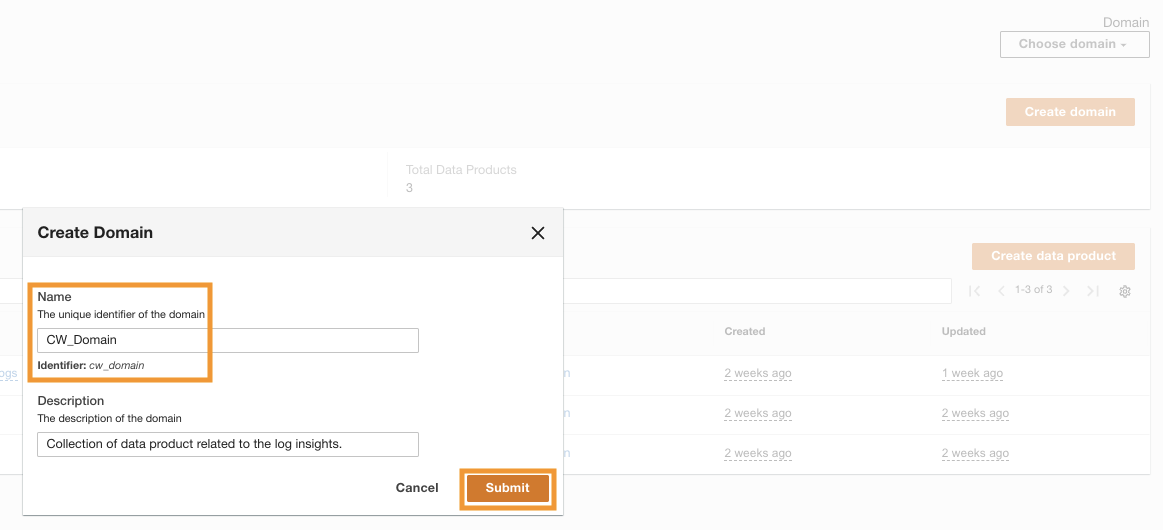
Możesz to zrobić po pomyślnym wdrożeniu usługi ADA Zaloguj Się korzystając z adresu e-mail administratora podanego podczas instalacji. Następnie tworzysz domena o imieniu CW_Domain. Domena to zdefiniowany przez użytkownika zbiór produktów danych. Na przykład domeną może być zespół lub projekt. Domeny zapewniają użytkownikom uporządkowany sposób organizowania produktów danych i zarządzania uprawnieniami dostępu.
- W konsoli ADA wybierz domeny w okienku nawigacji.
- Dodaj Utwórz domenę.
- Wpisz imię (
CW_Domain) i opis, a następnie wybierz Prześlij.
Skonfiguruj przykładową infrastrukturę aplikacji przy użyciu AWS CDK
Rozwiązanie AWS CDK, w którym wdrażana jest aplikacja demonstracyjna, jest hostowane na platformie GitHub. W tej sekcji szczegółowo opisano kroki klonowania repozytorium i konfigurowania projektu AWS CDK. Zanim uruchomisz te polecenia, pamiętaj o tym skonfigurować swoje dane uwierzytelniające AWS. Utwórz folder, otwórz terminal i przejdź do folderu, w którym należy zainstalować rozwiązanie AWS CDK. Uruchom następujący kod:
Te kroki wykonują następujące działania:
- Zainstaluj zależności bibliotek
- Zbuduj projekt
- Wygeneruj prawidłowy szablon CloudFormation
- Wdróż stos za pomocą AWS CloudFormation na swoim koncie AWS
Wdrożenie trwa około 1–2 minut i obejmuje utworzenie tabeli przeglądowej DynamoDB, funkcji Lambda i zasobnika S3 zawierającego pliki dziennika historycznego jako dane wyjściowe. Skopiuj te wartości do aplikacji do edycji tekstu, takiej jak Notatnik.
Twórz produkty danych ADA
Na potrzeby tej wersji demonstracyjnej tworzymy trzy różne produkty danych, po jednym dla każdego źródła danych, do którego będziesz odpytywać, aby uzyskać szczegółowe informacje operacyjne. Produkt danych to zbiór danych (zbiór danych, taki jak tabela lub plik CSV), który został pomyślnie zaimportowany do ADA i który można przeglądać.
Utwórz produkt danych CloudWatch
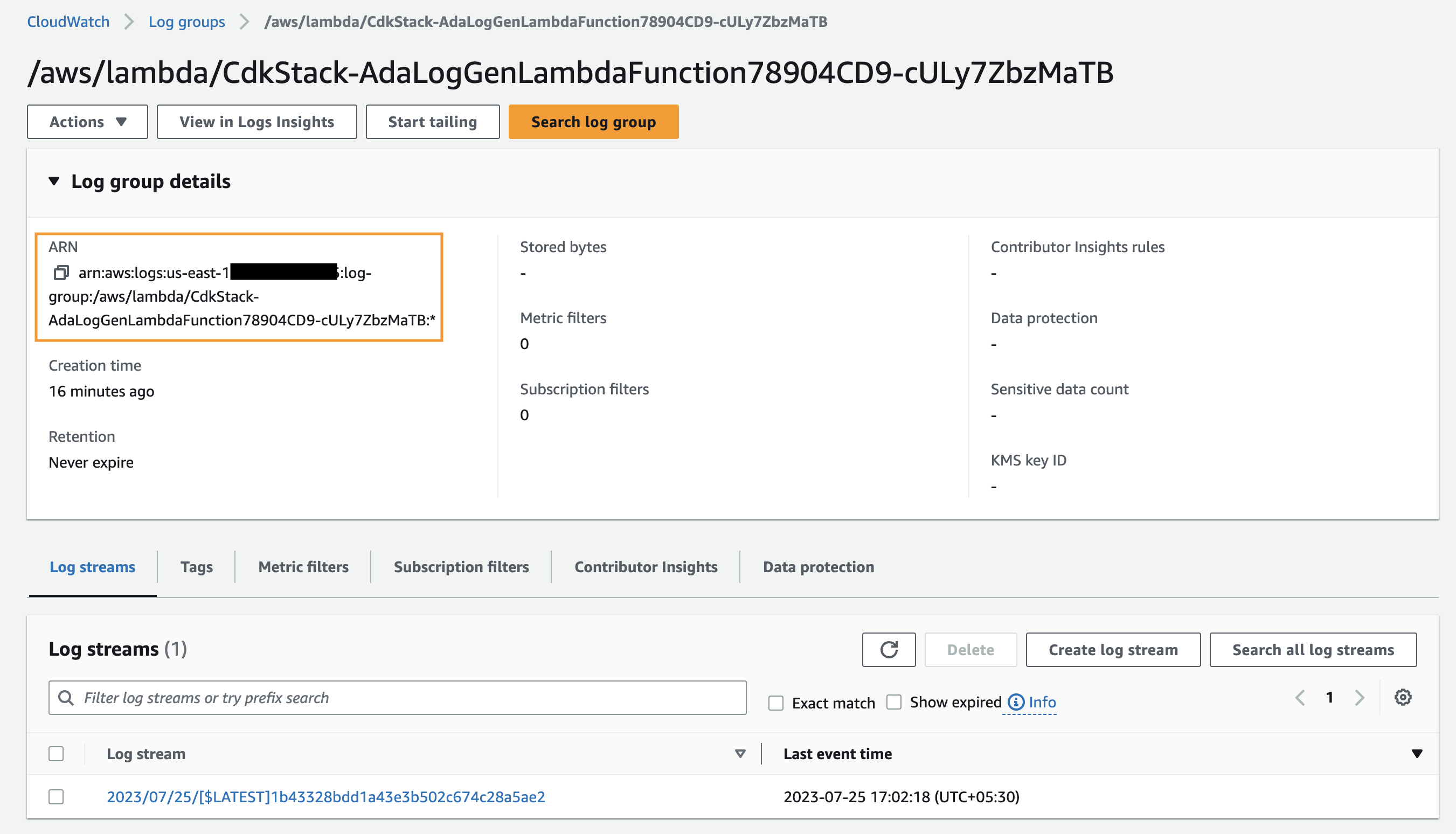
Najpierw tworzymy produkt danych dla dzienników aplikacji, konfigurując usługę ADA do pozyskiwania grupy dzienników CloudWatch dla przykładowej aplikacji (funkcja Lambda). Użyj CdkStack.LambdaFunction dane wyjściowe, aby uzyskać funkcję Lambda ARN i zlokalizować odpowiednią grupę dzienników CloudWatch ARN w konsoli CloudWatch.
Następnie wykonaj następujące czynności:
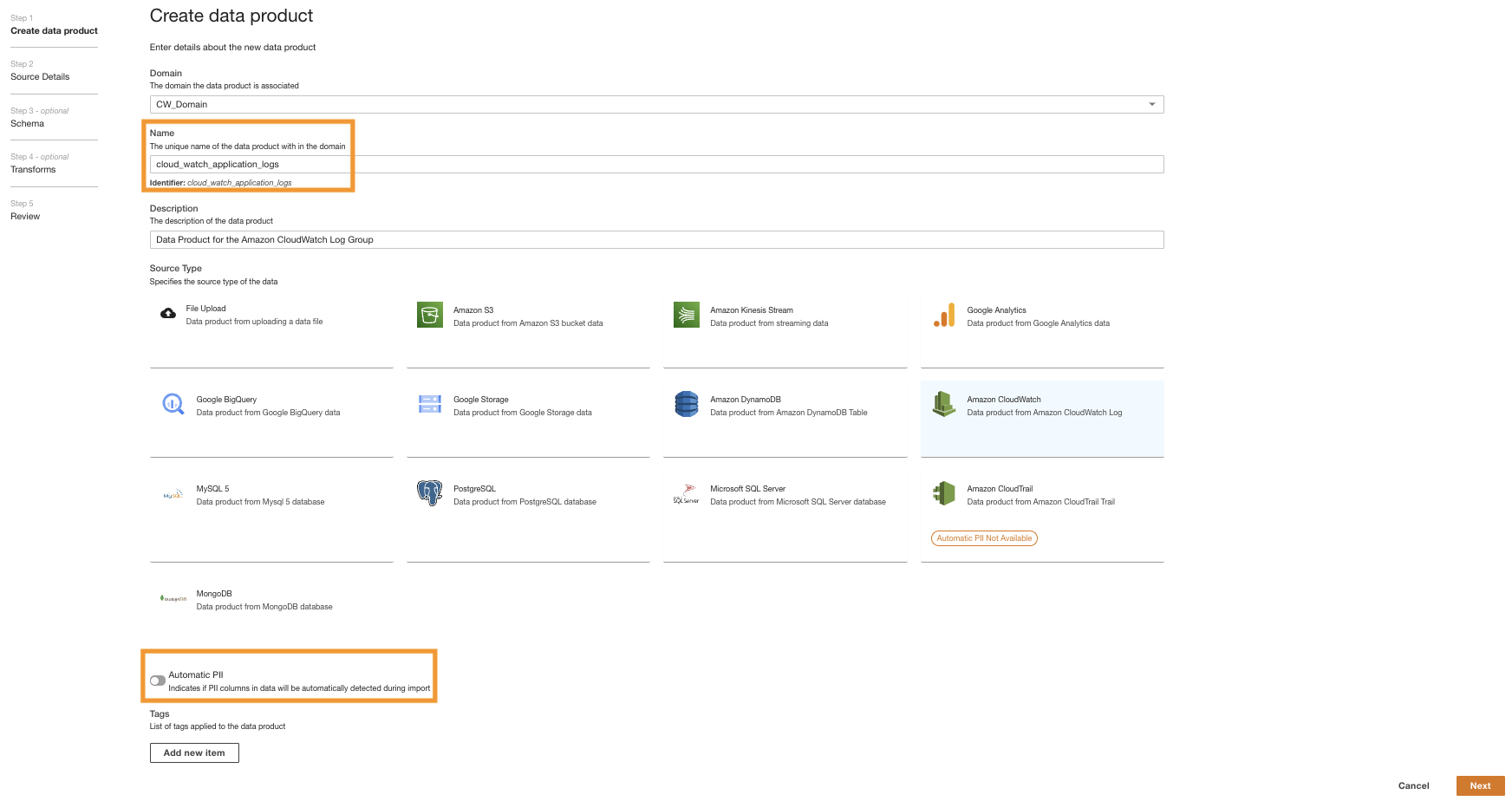
- W konsoli ADA przejdź do domeny ADA i utwórz produkt danych CloudWatch.
- W razie zamówieenia projektu ImięWpisz imię.
- W razie zamówieenia projektu Rodzaj źródła, wybierać Amazon Cloud Watch.
- Wyłącz Automatyczne informacje umożliwiające identyfikację.
ADA ma funkcję, która automatycznie wykrywa dane osobowe (PII) podczas importu, która jest domyślnie włączona. W przypadku tej wersji demonstracyjnej wyłączamy tę opcję dla produktu danych, ponieważ wykrywanie danych umożliwiających identyfikację nie wchodzi w zakres tej wersji demonstracyjnej.
- Dodaj Następna.
- Wyszukaj i wybierz grupę dzienników CloudWatch ARN skopiowaną z poprzedniego kroku.

- Skopiuj grupę logów ARN.
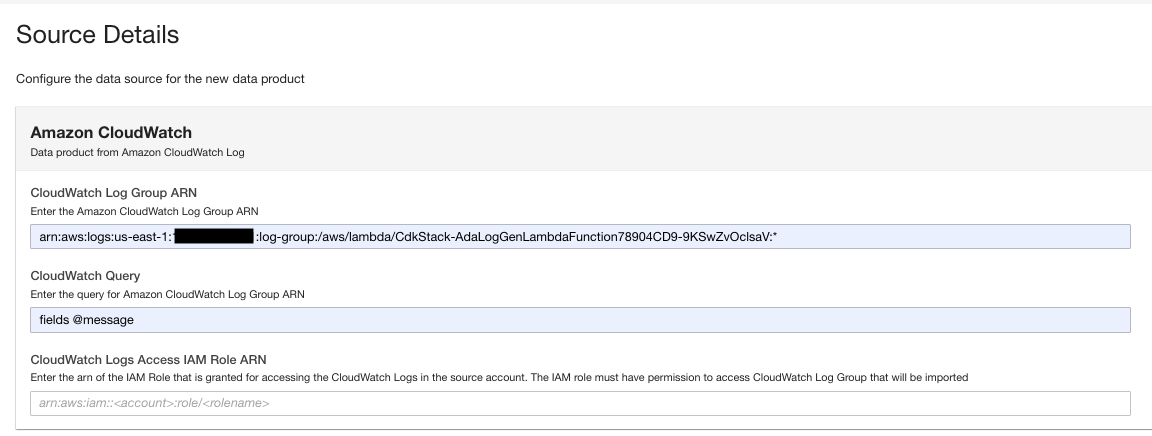
- Na stronie produktu danych wprowadź grupę dzienników ARN.
- W razie zamówieenia projektu Zapytanie CloudWatchwprowadź zapytanie, które ADA ma uzyskać z grupy dzienników.
W tym demo odpytujemy pole @message, ponieważ chcemy uzyskać dzienniki aplikacji z grupy dzienników.
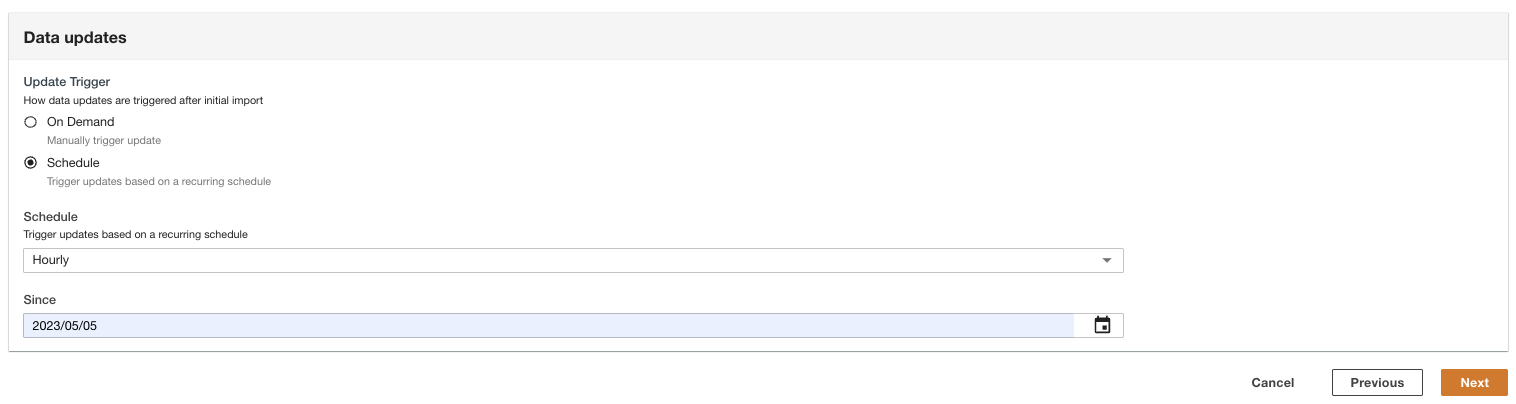
- Wybierz sposób wyzwalania aktualizacji danych po pierwszym imporcie.
ADA można skonfigurować tak, aby pobierał dane ze źródła w elastycznych odstępach czasu (do 15 minut lub później) lub na żądanie. Na potrzeby wersji demonstracyjnej ustawiliśmy, że aktualizacje danych będą uruchamiane co godzinę.
- Dodaj Następna.
Następnie ADA połączy się z grupą dzienników i prześle zapytanie do schematu. Ponieważ dzienniki są w formacie Apache Log, przekształcamy je w osobne pola, abyśmy mogli uruchamiać zapytania dotyczące określonych pól dziennika. ADA zapewnia cztery domyślnym transformacje i obsługuje niestandardowe transformacje za pomocą skryptu Python. W tym demo uruchamiamy niestandardowy skrypt w języku Python, który przekształca pole komunikatu JSON w pola w formacie Apache Log.
- Dodaj Przekształć schemat.
- Dodaj Utwórz nową transformację.
- Prześlij plik
apache-log-extractor-transform.pyskrypt z/asset/transform_logs/teczka. - Dodaj Prześlij.
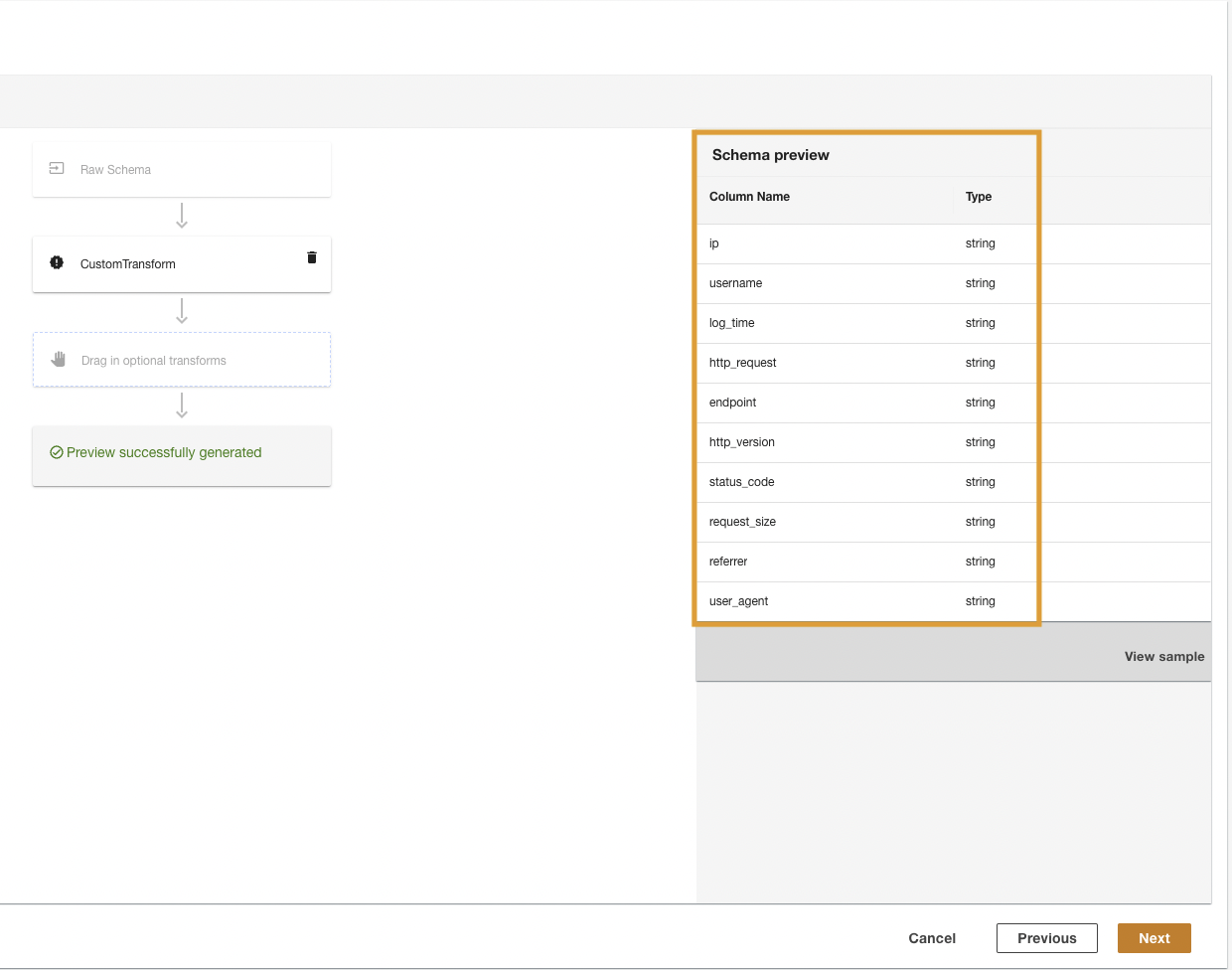
ADA przekształci logi CloudWatch za pomocą skryptu i zaprezentuje przetworzony schemat.
- Dodaj Następna.
- W ostatnim kroku przejrzyj kroki i wybierz Prześlij.
ADA rozpocznie przetwarzanie danych, utworzy potoki danych i przygotuje grupy dzienników CloudWatch do wysyłania zapytań z poziomu Query Workbench. Ten proces zajmie kilka minut i zostanie wyświetlony w konsoli ADA w sekcji Produkty danych.
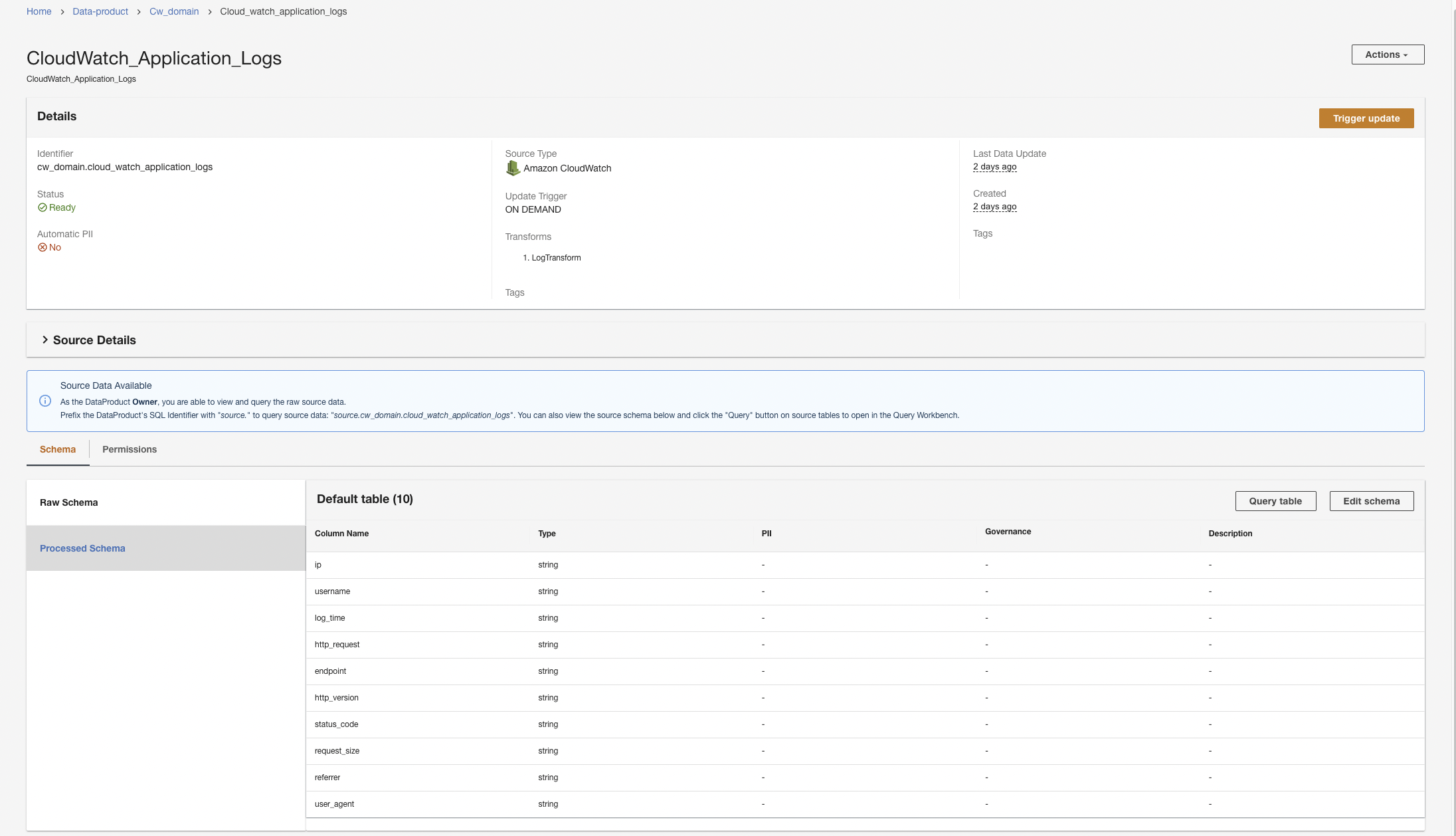
Utwórz produkt danych Amazon S3
Powtarzamy kroki, aby dodać logi historyczne ze źródła danych Amazon S3 i wyszukać dane referencyjne z tabeli DynamoDB. W przypadku tych dwóch źródeł danych nie tworzymy niestandardowych przekształceń, ponieważ formaty danych są w formacie CSV (w przypadku dzienników historycznych) i mają atrybuty kluczowe (w przypadku danych wyszukiwania referencyjnego).
- W konsoli ADA utwórz nowy produkt danych.
- Wpisz imię (
hist_logs) i wybierz Amazon S3.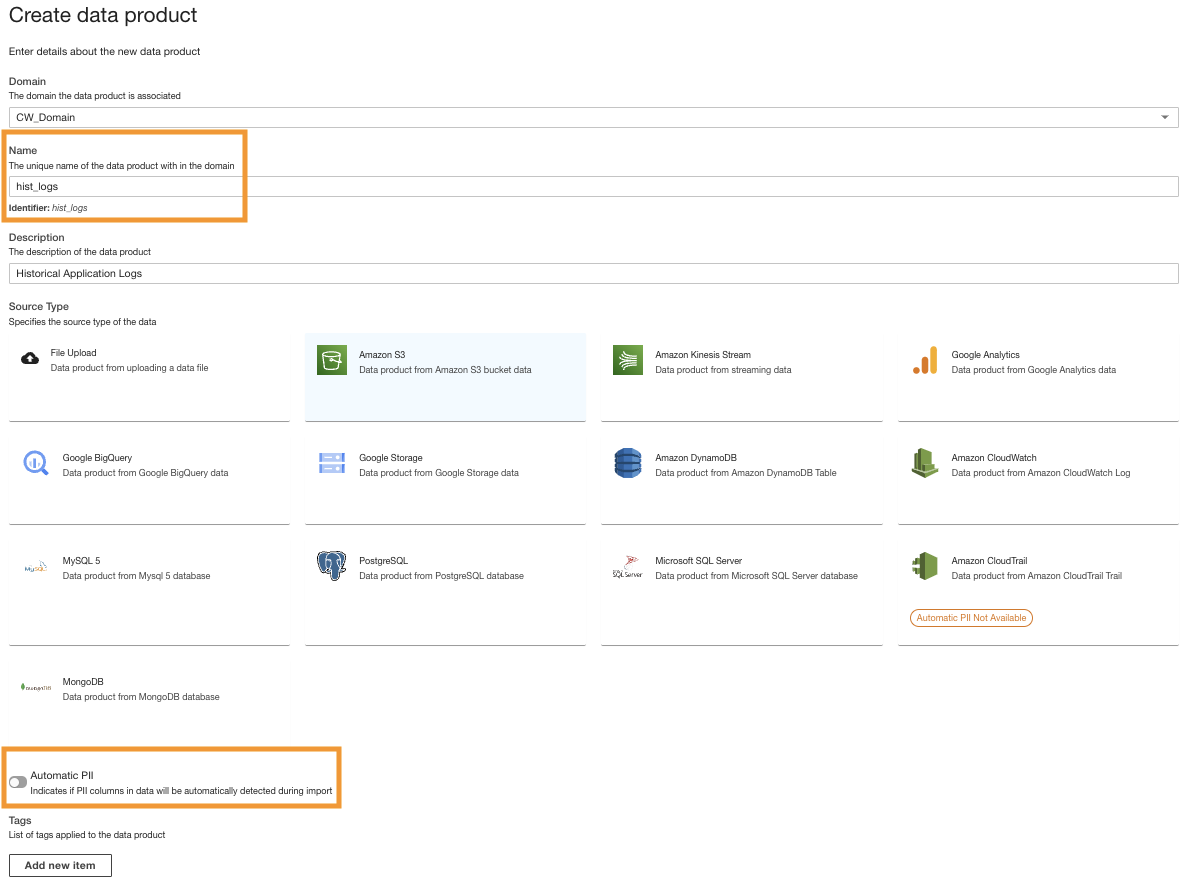
- Skopiuj identyfikator URI Amazon S3 (tekst po
arn:aws:s3:::) OdCdkStack.S3zmienną wyjściową i przejdź do konsoli Amazon S3. - W polu wyszukiwania wpisz skopiowany tekst, otwórz segment S3, wybierz
/logsfolder i wybierz opcję Kopiuj identyfikator URI S3.
W tej ścieżce przechowywane są logi historyczne.
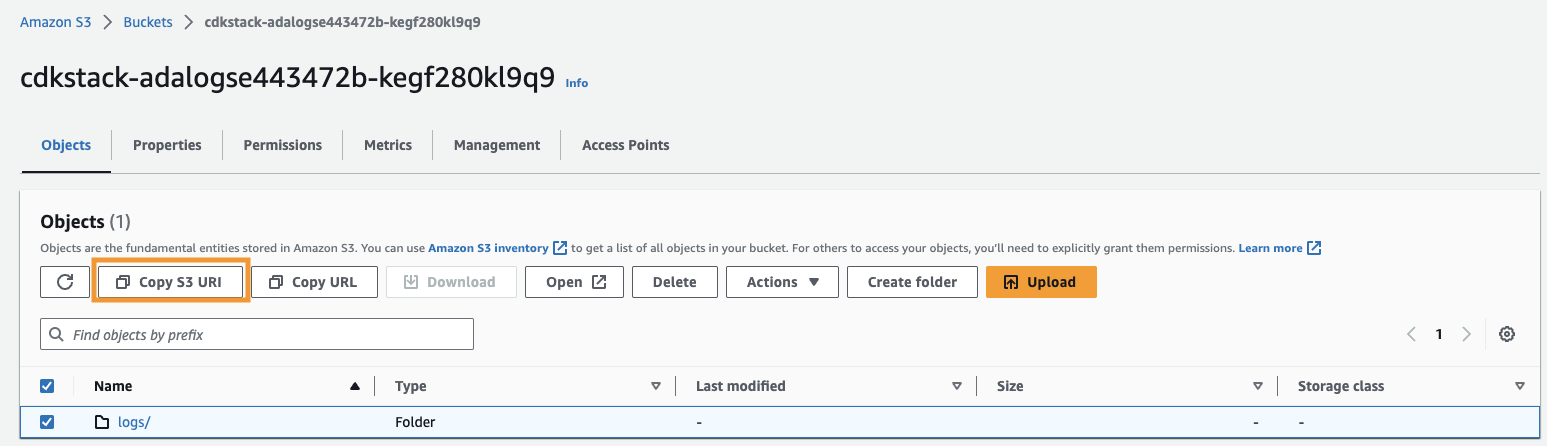
- Wróć do konsoli ADA i wprowadź skopiowany identyfikator URI S3 Lokalizacja S3.
- W razie zamówieenia projektu Aktualizuj wyzwalacz, Wybierz On Demand ponieważ logi historyczne są aktualizowane z nieokreśloną częstotliwością.
- W razie zamówieenia projektu Polityka aktualizacji, Wybierz Dodać aby dołączyć nowo zaimportowane dane do istniejących danych.
- Dodaj Następna.
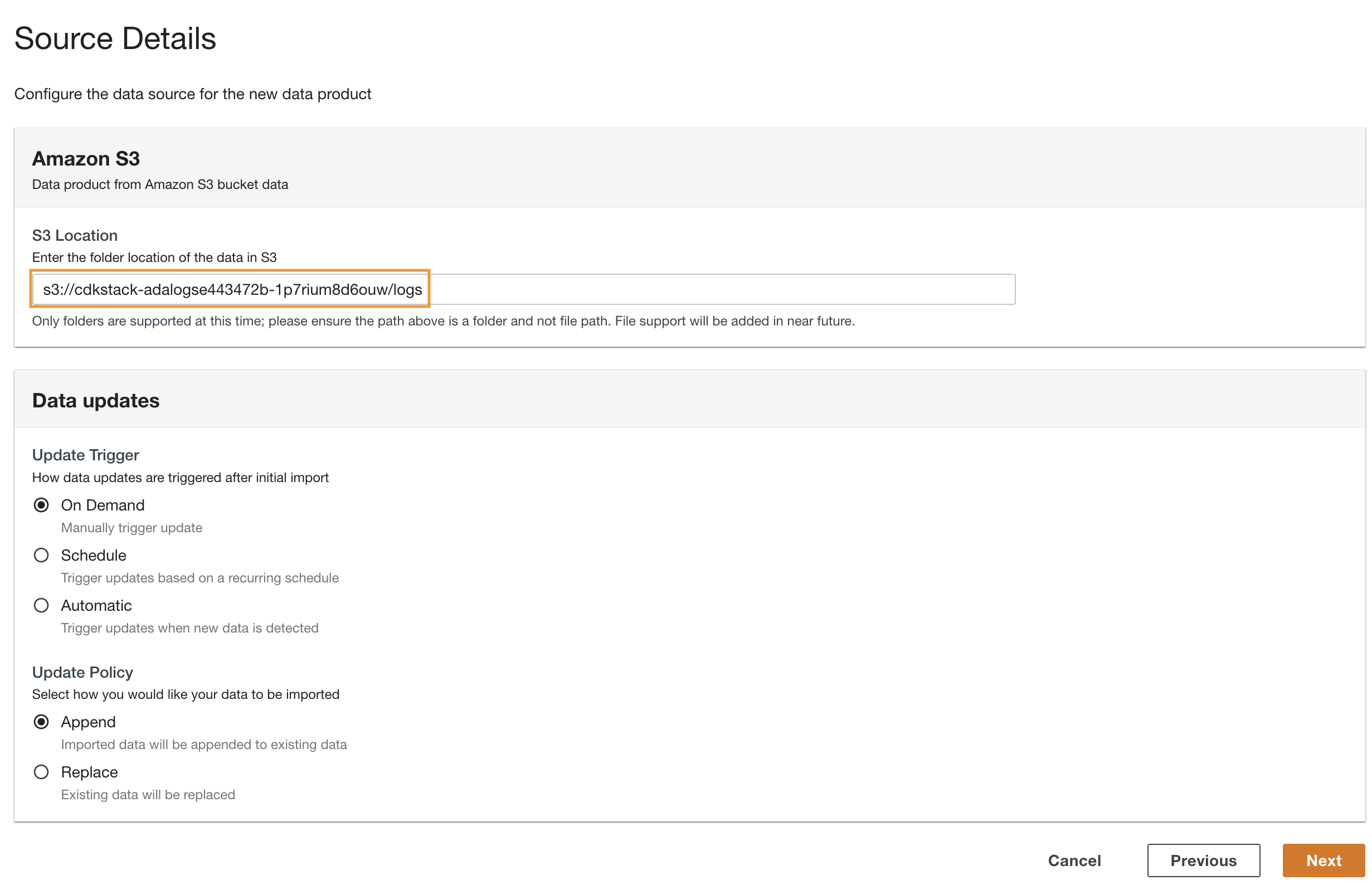
ADA przetwarza schemat dla plików w wybranej ścieżce folderu. Ponieważ dzienniki są w formacie CSV, ADA może odczytać nazwy kolumn bez konieczności dodatkowych przekształceń. Jednak kolumny status_code i request_size są uznawane przez ADA za typ długi. Chcemy zachować spójność typów danych kolumn w produktach danych, abyśmy mogli łączyć tabele danych i wykonywać zapytania dotyczące danych. Kolumna status_code będzie używany do tworzenia złączeń w tabelach danych.
- Dodaj Przekształć schemat aby zmienić typy danych dwóch kolumn na typ danych typu string.
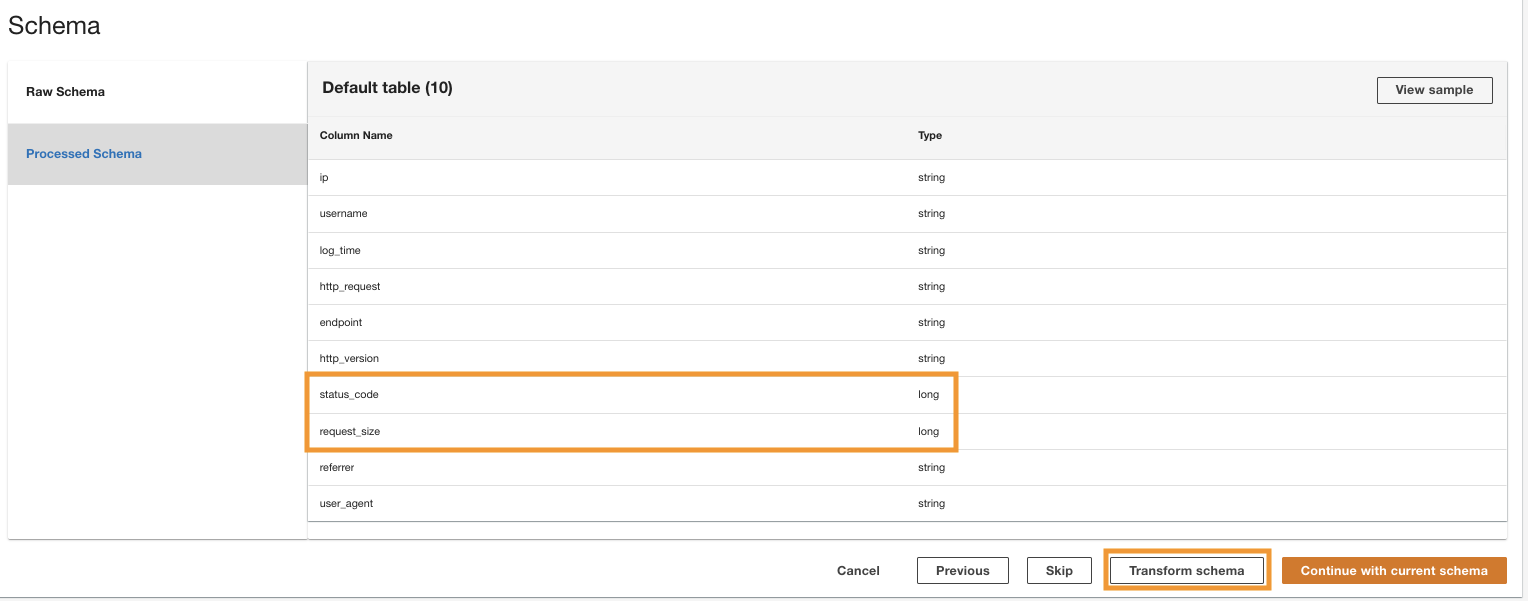
Zwróć uwagę na wyróżnione nazwy kolumn w pliku Podgląd schematu panelu przed zastosowaniem transformacji typu danych.
- W Przekształć plan okienko pod Wbudowane transformacjewybierz Zastosuj mapowanie.
Ta opcja umożliwia zmianę typu danych z jednego typu na inny.
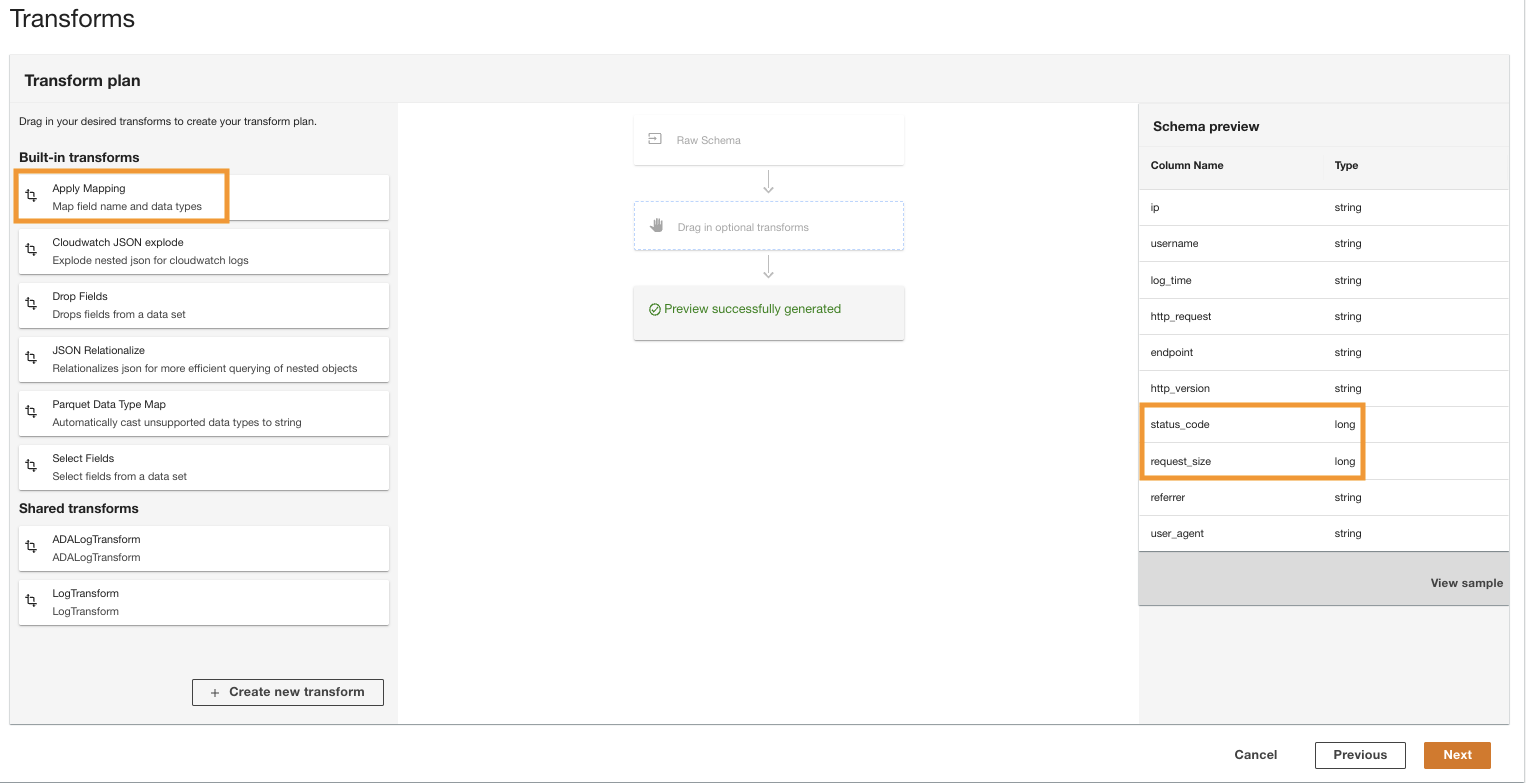
- W Zastosuj mapowanie sekcja, odznacz Usuń inne pola.
Jeśli ta opcja nie jest wyłączona, zachowane zostaną tylko przekształcone kolumny, a wszystkie pozostałe zostaną usunięte. Ponieważ chcemy zachować wszystkie kolumny, wyłączamy tę opcję.
- Pod Mapowania póldla Stara nazwa i Nowa nazwa, wchodzić
status_codei dla Nowy typ, wchodzićstring.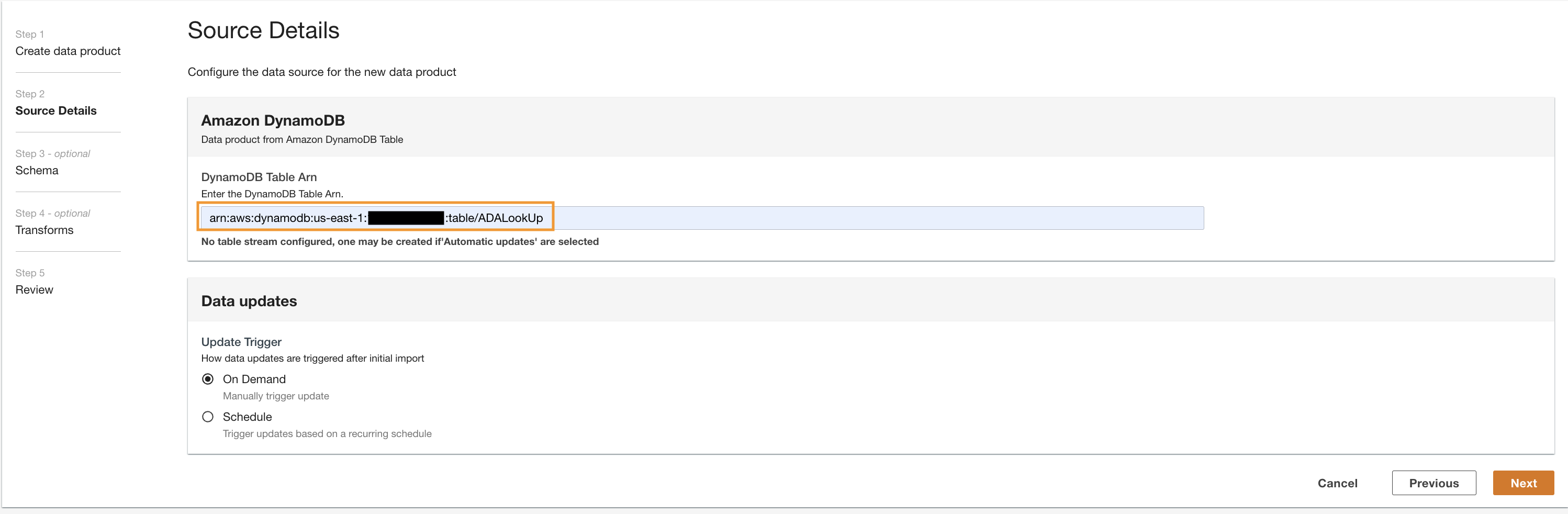
- Dodaj Dodaj Przedmiot.
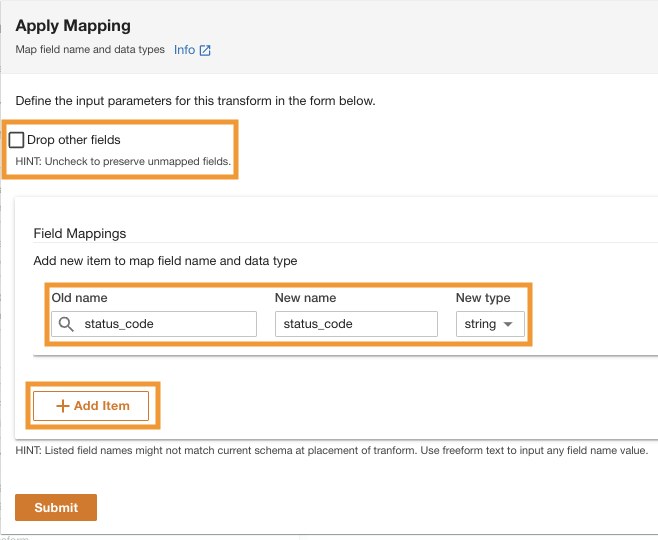
- W razie zamówieenia projektu Stara nazwa i Nowa nazwa¸ wpisz request_size i for Nowy typ danych, wpisz ciąg.
- Dodaj Prześlij.
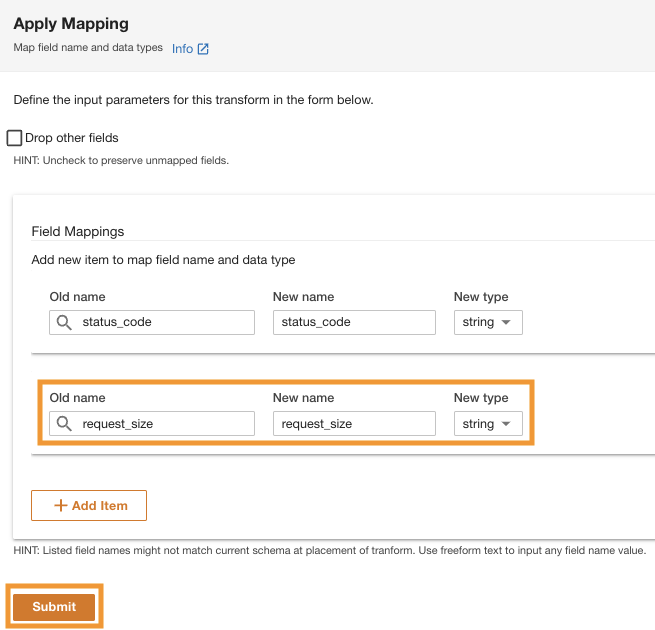
ADA zastosuje transformację mapowania w źródle danych Amazon S3. Zwróć uwagę na typy kolumn w Podgląd schematu szkło.
- Dodaj Zobacz próbkę aby wyświetlić podgląd danych z zastosowaną transformacją.
ADA wyświetli potwierdzenie danych PII, aby upewnić się, że tylko autoryzowani użytkownicy mogą przeglądać dane lub że zbiór danych nie zawiera żadnych danych PII.
- Dodaj Akceptuję aby kontynuować przeglądanie przykładowych danych.
Należy pamiętać, że schemat jest identyczny ze schematem grupy dzienników CloudWatch, ponieważ zarówno bieżące, jak i historyczne dzienniki aplikacji są w formacie dziennika Apache.
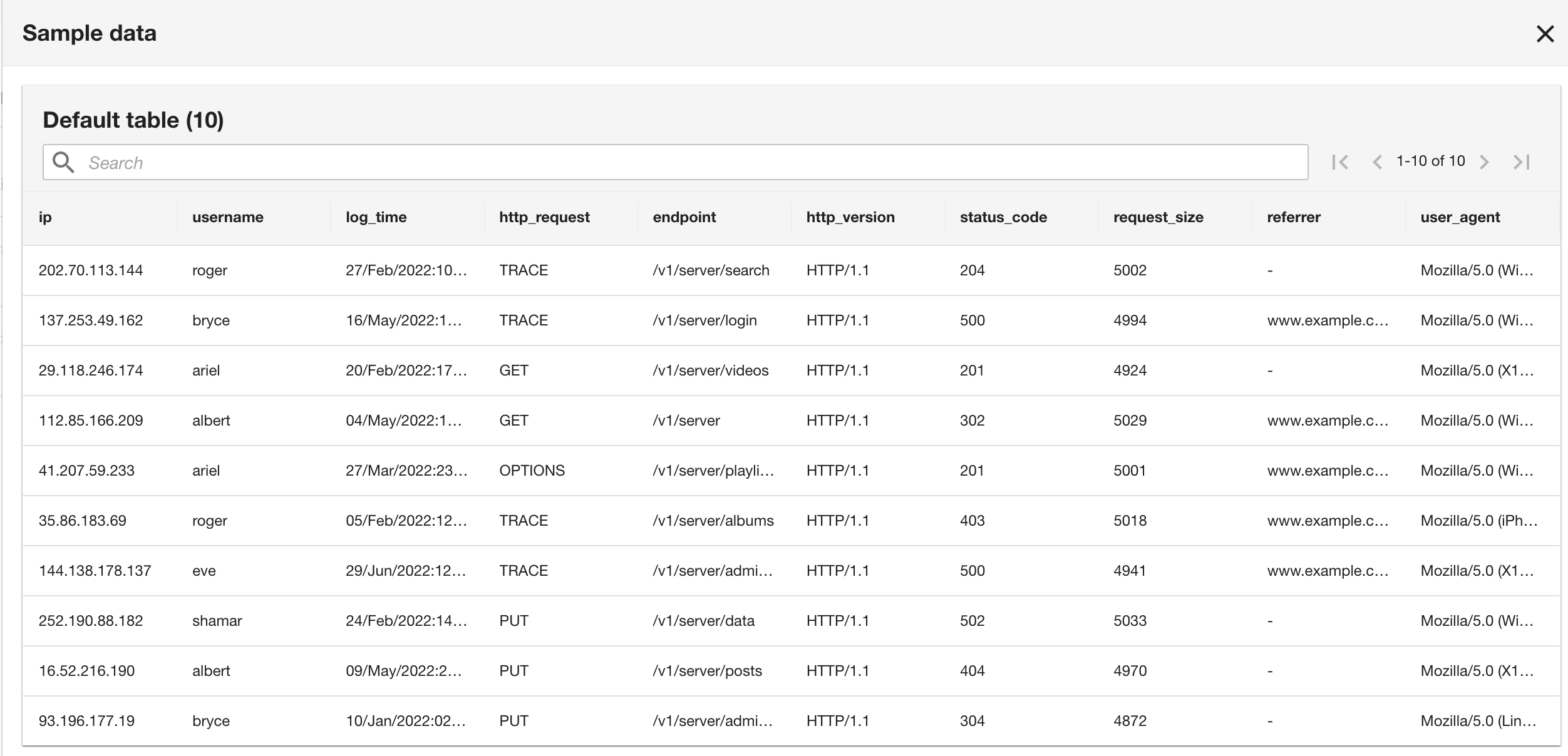
- W ostatnim kroku przejrzyj konfigurację i wybierz Prześlij.
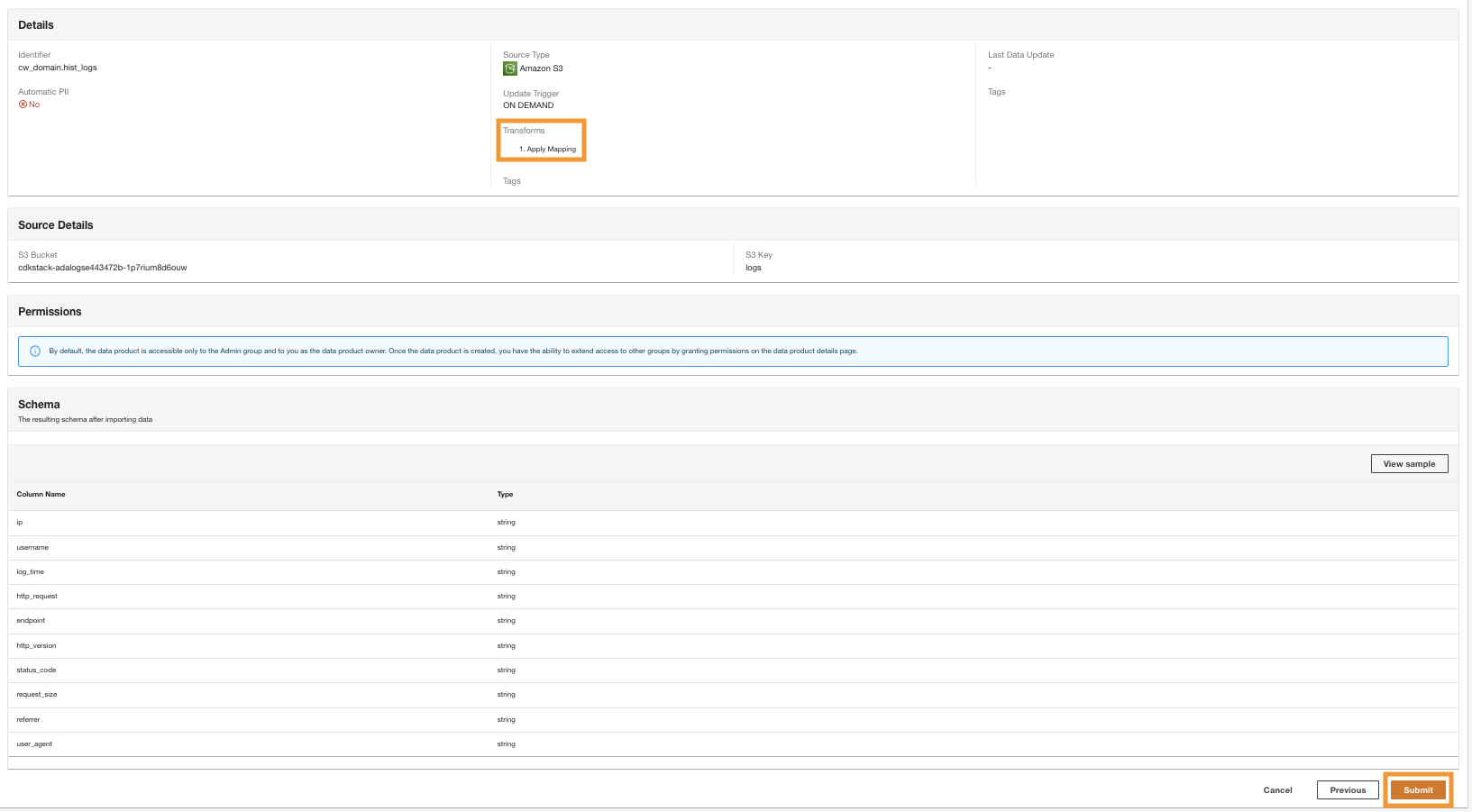
ADA rozpoczyna przetwarzanie danych ze źródła Amazon S3, tworzy infrastrukturę backendową i przygotowuje produkt danych. Proces ten zajmuje kilka minut, w zależności od rozmiaru danych.
Utwórz produkt danych DynamoDB
Na koniec tworzymy produkt danych DynamoDB. Wykonaj następujące kroki:
- W konsoli ADA utwórz nowy produkt danych.
- Wpisz imię (
lookup) i wybierz Amazon DynamoDB.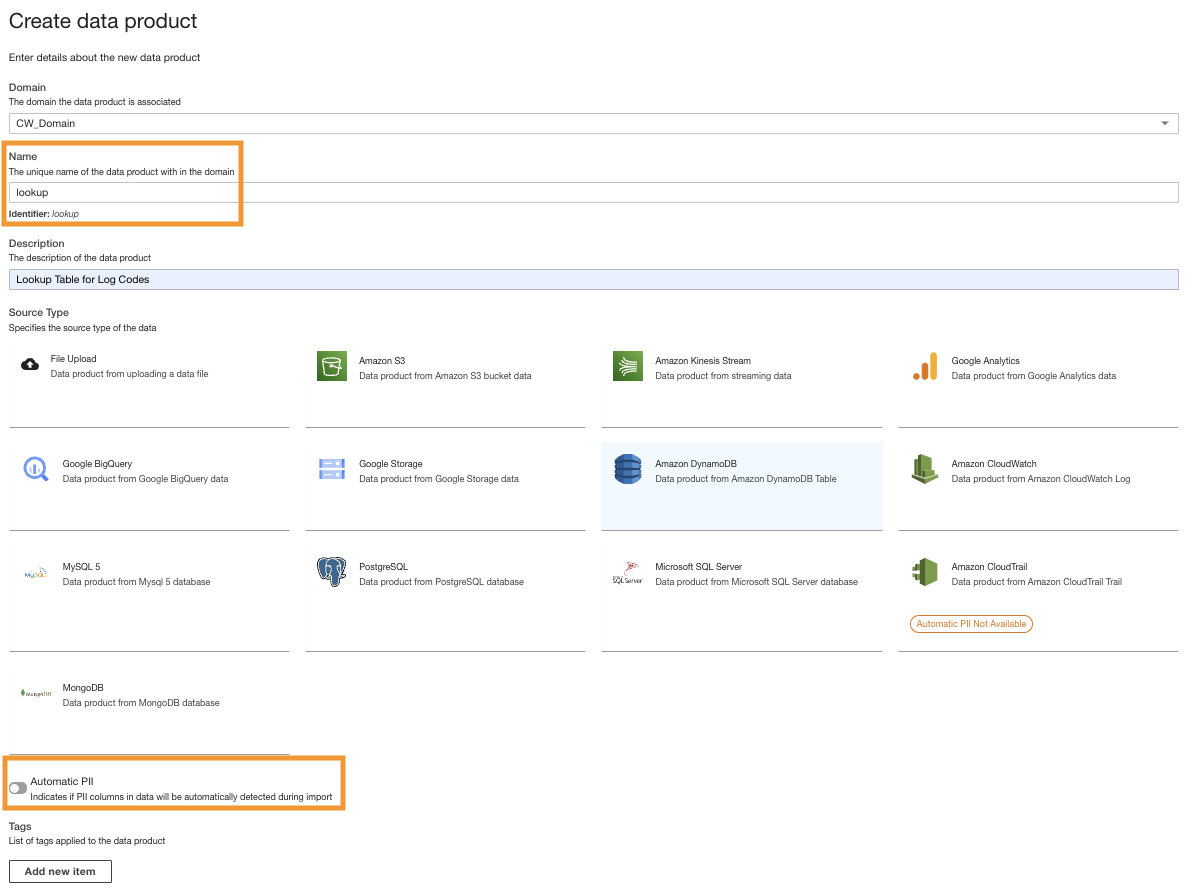
- Wpisz
Cdk.DynamoDBTablezmienna wyjściowa dla Tabela DynamoDB ARN.
Ta tabela zawiera kluczowe atrybuty, które będą używane jako tabela przeglądowa w tym pokazie. Do wyszukiwania danych używamy kodów HTTP oraz długich i krótkich opisów kodów. Alternatywnie możesz także użyć źródła pliku PostgreSQL, MySQL lub CSV.
- W razie zamówieenia projektu Aktualizuj wyzwalacz, Wybierz Na żądanie.
Aktualizacje będą dostępne na żądanie, ponieważ wyszukiwanie służy głównie celom referencyjnym podczas wykonywania zapytań, a wszelkie aktualizacje danych wyszukiwania można aktualizować w programie ADA przy użyciu wyzwalaczy na żądanie.
- Dodaj Następna.
ADA odczytuje schemat z bazowego schematu DynamoDB i przedstawia nazwę i typ kolumny do opcjonalnej transformacji. Będziemy kontynuować wybór schematu domyślnego, ponieważ typy kolumn są zgodne z typami z grupy logów CloudWatch i źródła danych Amazon S3 CSV. Posiadanie spójnych typów danych we wszystkich źródłach danych pozwala nam pisać zapytania w celu pobrania rekordów poprzez łączenie tabel za pomocą pól kolumn. Na przykład kolumna key w schemacie DynamoDB odpowiada status_code w produktach danych Amazon S3 i CloudWatch. Możemy pisać zapytania, które mogą łączyć trzy tabele za pomocą nazwy kolumny key. Przykład pokazano w następnej sekcji.
- Dodaj Kontynuuj według bieżącego schematu.
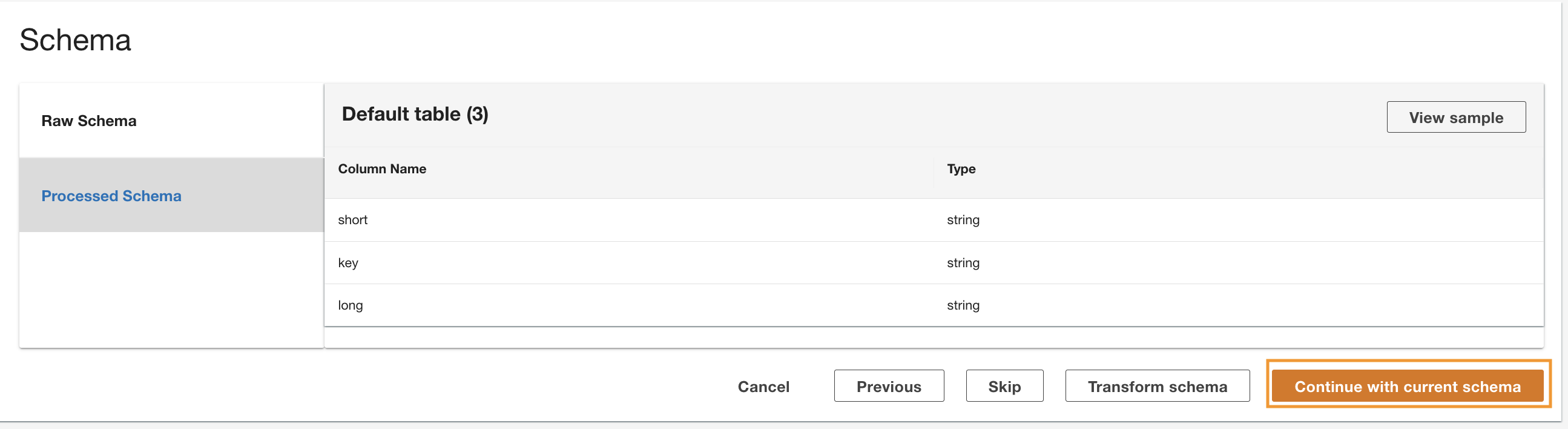
- Przejrzyj konfigurację i wybierz Prześlij.
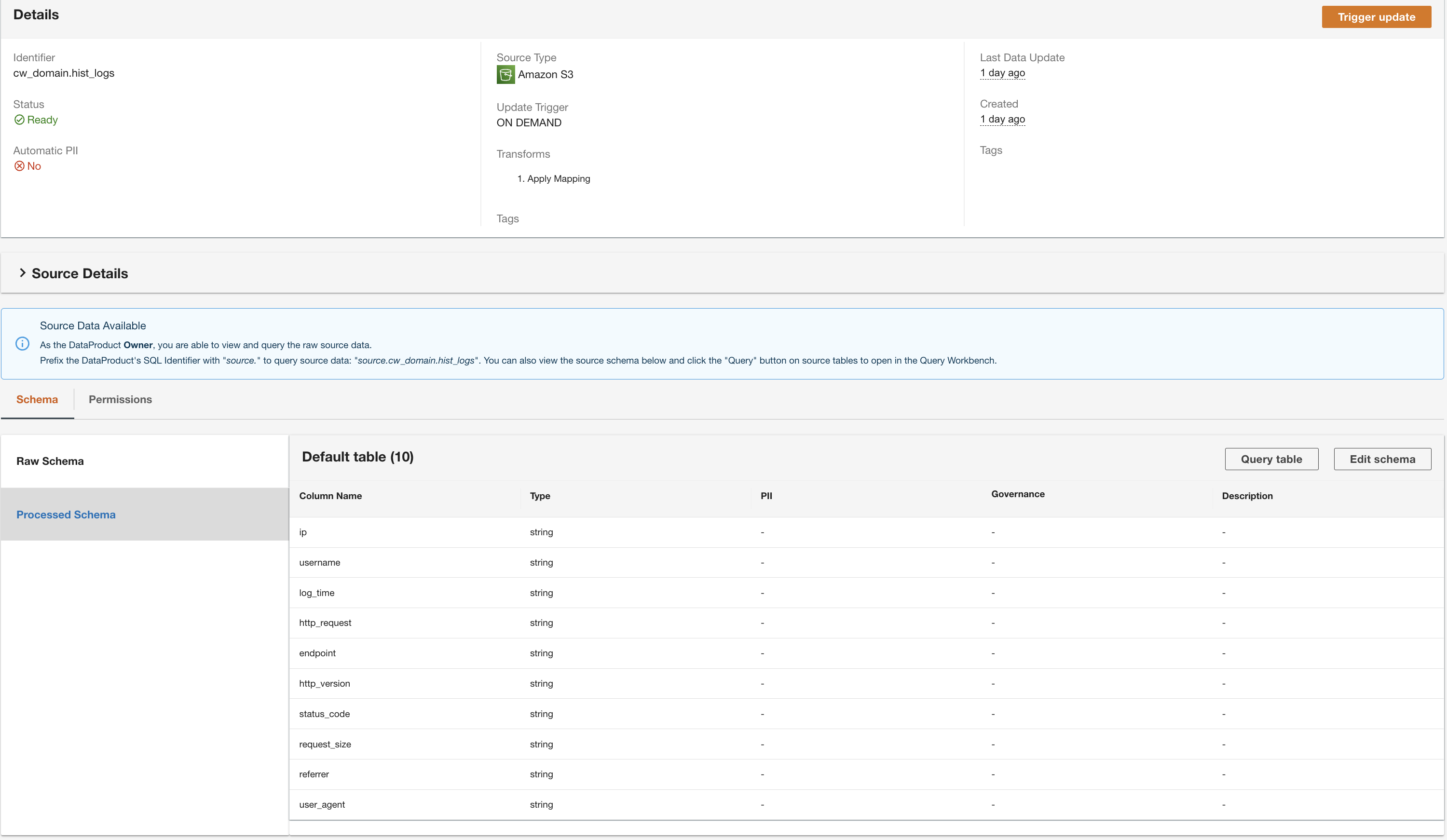
ADA przetworzy dane ze źródła danych tabeli DynamoDB i przygotuje produkt danych. W zależności od rozmiaru danych proces ten zajmuje kilka minut.
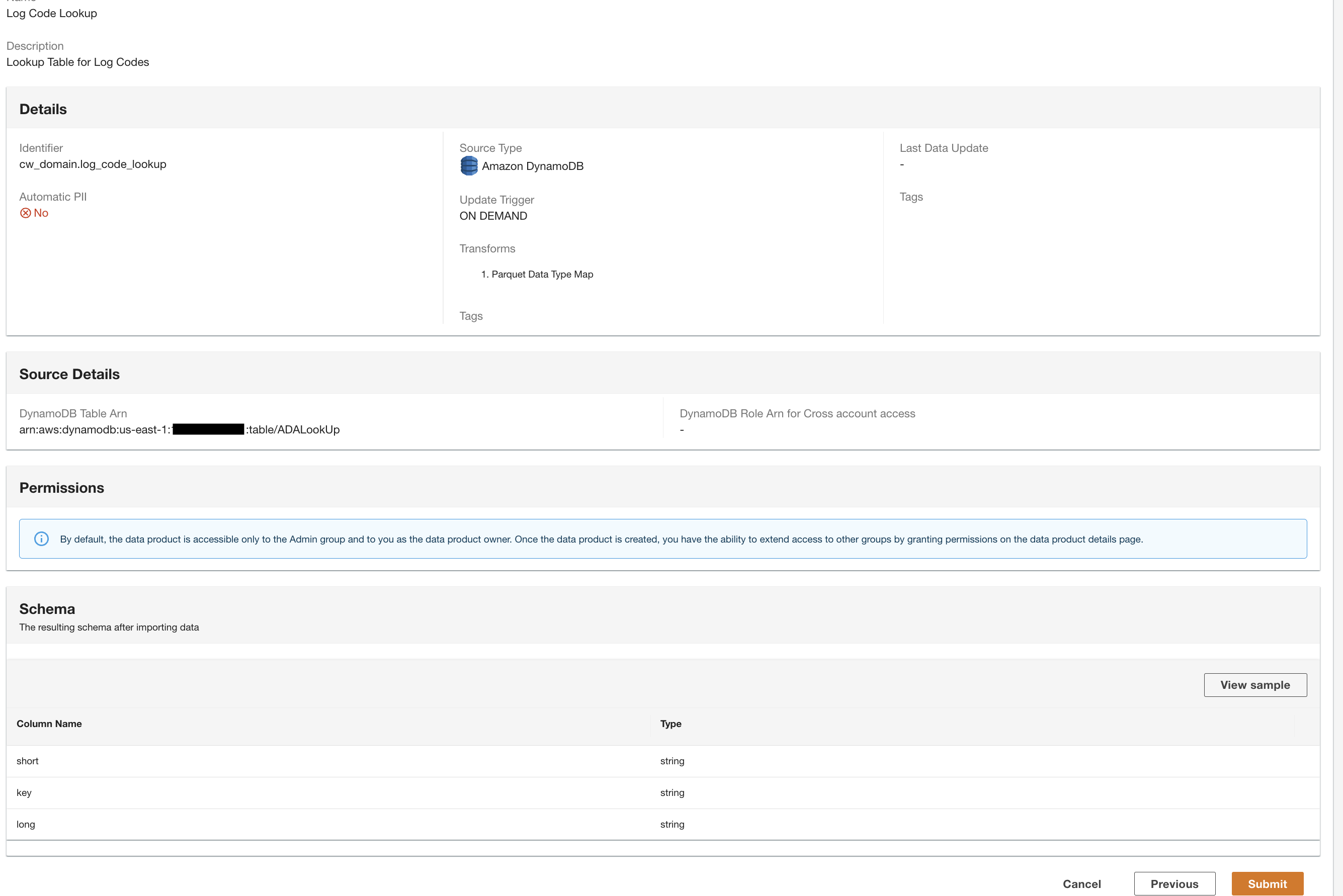
Teraz mamy wszystkie trzy produkty danych przetwarzane przez ADA i dostępne do uruchamiania zapytań.

Użyj Query Workbench, aby wysłać zapytanie do danych
ADA umożliwia uruchamianie zapytań względem produktów danych, jednocześnie wyodrębniając źródło danych i udostępniając je za pomocą języka SQL (Structured Query Language). Możesz pisać zapytania i łączyć je z tabelami w taki sam sposób, w jaki wykonujesz zapytania dotyczące tabel w relacyjnej bazie danych. Demonstrujemy możliwości wysyłania zapytań przez ADA za pomocą dwóch scenariuszy użytkownika. W obu scenariuszach łączymy zestaw danych dziennika aplikacji z tabelą wyszukiwania kodów błędów. W pierwszym przypadku użycia odpytujemy bieżące dzienniki aplikacji, aby zidentyfikować 10 najczęściej używanych punktów końcowych aplikacji wraz z odpowiednimi kodami stanu HTTP:
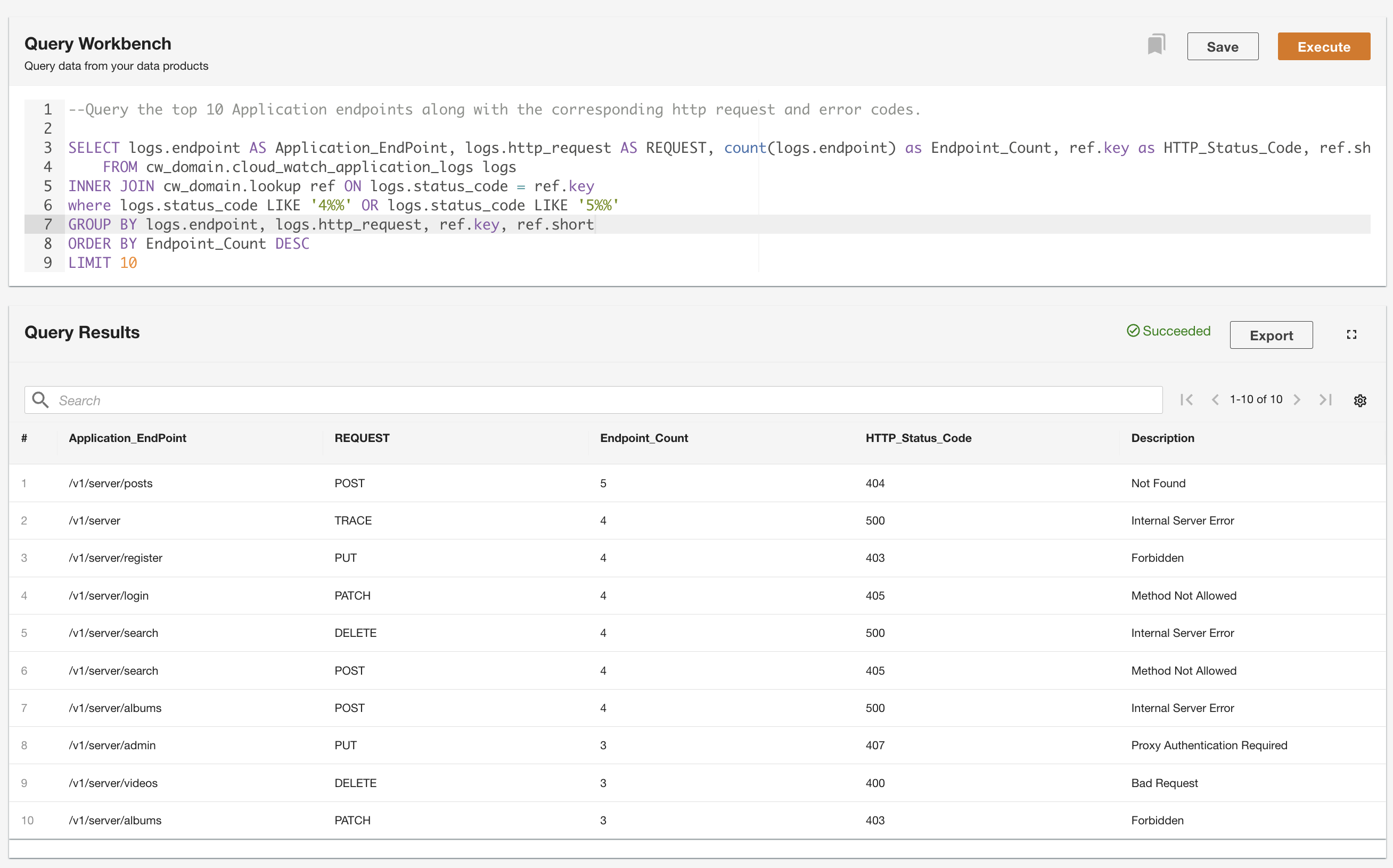
W drugim przykładzie odpytujemy tabelę logów historycznych, aby uzyskać 10 punktów końcowych aplikacji z największą liczbą błędów i zrozumieć wzorzec wywołań punktów końcowych:
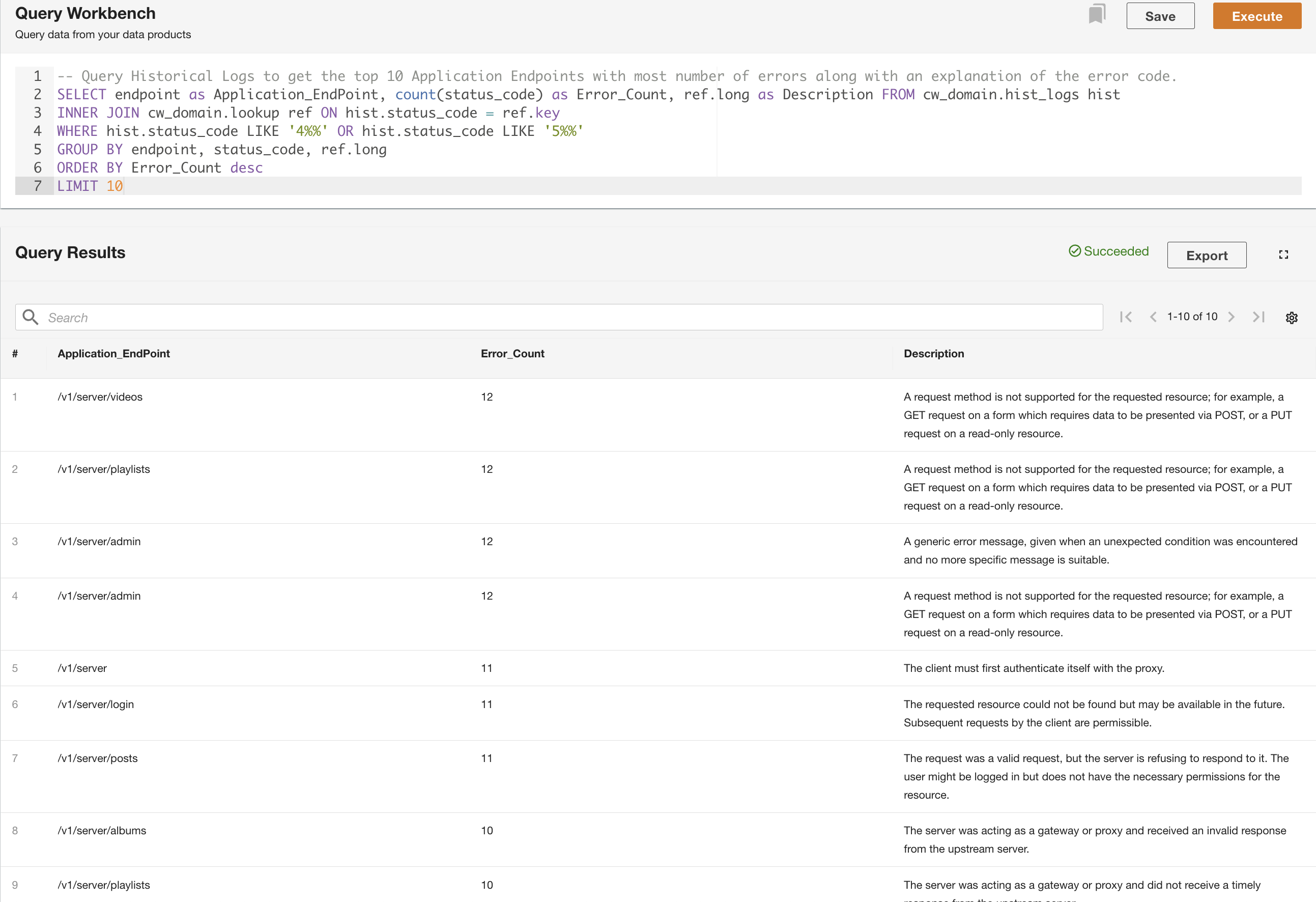
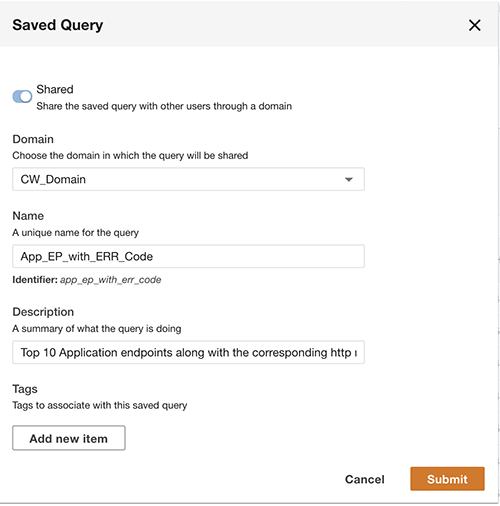
Oprócz wysyłania zapytań możesz opcjonalnie zapisać zapytanie i udostępnić zapisane zapytanie innym użytkownikom w tej samej domenie. Udostępnione zapytania są dostępne bezpośrednio z Query Workbench. Wyniki zapytania można również wyeksportować do formatu CSV.
Wizualizuj produkty danych ADA w Tableau
ADA oferuje taką możliwość connect do zewnętrznych narzędzi BI w celu wizualizacji danych i tworzenia raportów z produktów danych ADA. W tym demo używamy natywnej integracji ADA z Tableau do wizualizacji danych z trzech skonfigurowanych wcześniej produktów danych. Korzystanie ze złącza Athena firmy Tableau i postępowanie zgodnie z instrukcjami w Konfiguracja tableau, możesz skonfigurować ADA jako źródło danych w Tableau. Po pomyślnym nawiązaniu połączenia pomiędzy Tableau i ADA, Tableau zapełni trzy produkty danych w katalogu Tableau cw_domain.
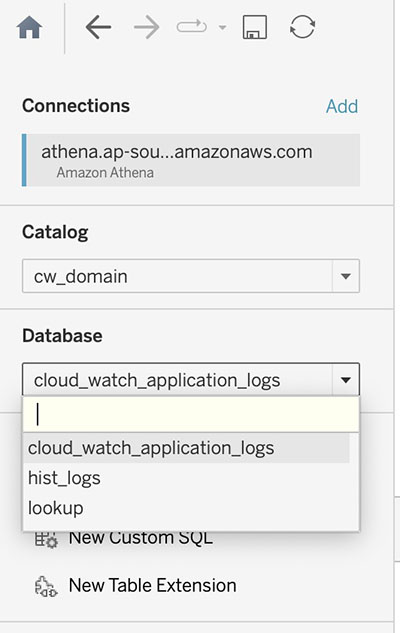
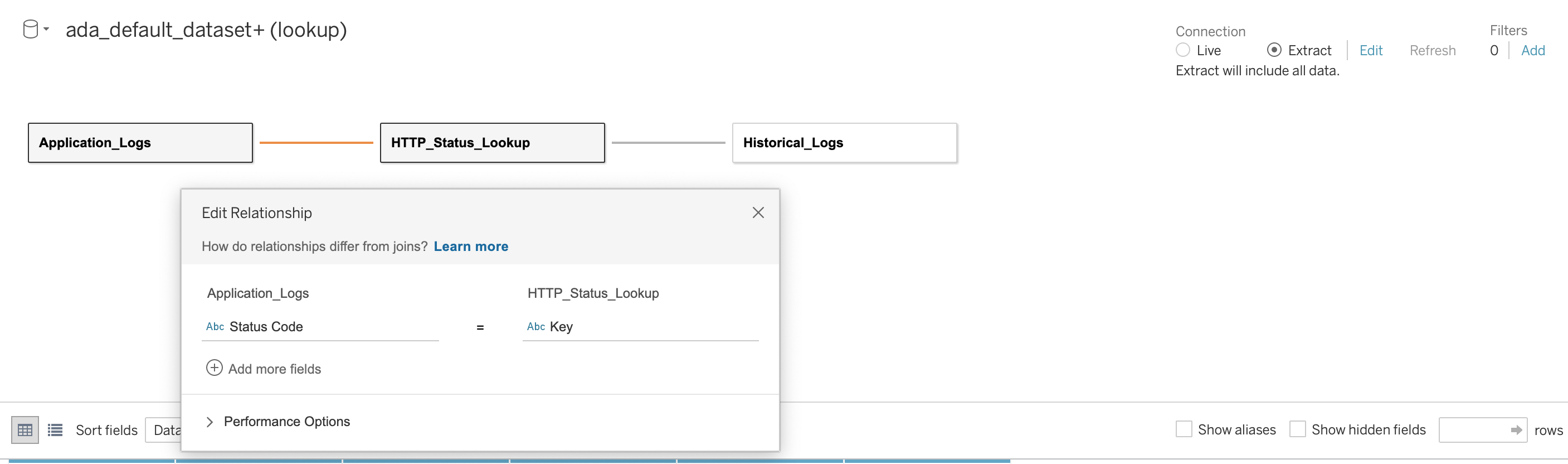
Następnie ustanawiamy relację pomiędzy trzema bazami danych, używając kodu stanu HTTP jako kolumny łączącej, jak pokazano na poniższym zrzucie ekranu. Tableau umożliwia nam pracę w trybie online i offline ze źródłami danych. W trybie online Tableau połączy się z ADA i na żywo zapyta o produkty danych. W trybie offline możemy korzystać z Wyciąg możliwość wyodrębnienia danych z ADA i zaimportowania ich do Tableau. W tym demo importujemy dane do Tableau, aby zapytania były bardziej responsywne. Następnie zapisujemy skoroszyt Tableau. Możemy sprawdzić dane ze źródeł danych, wybierając bazę danych i Zaktualizuj teraz.
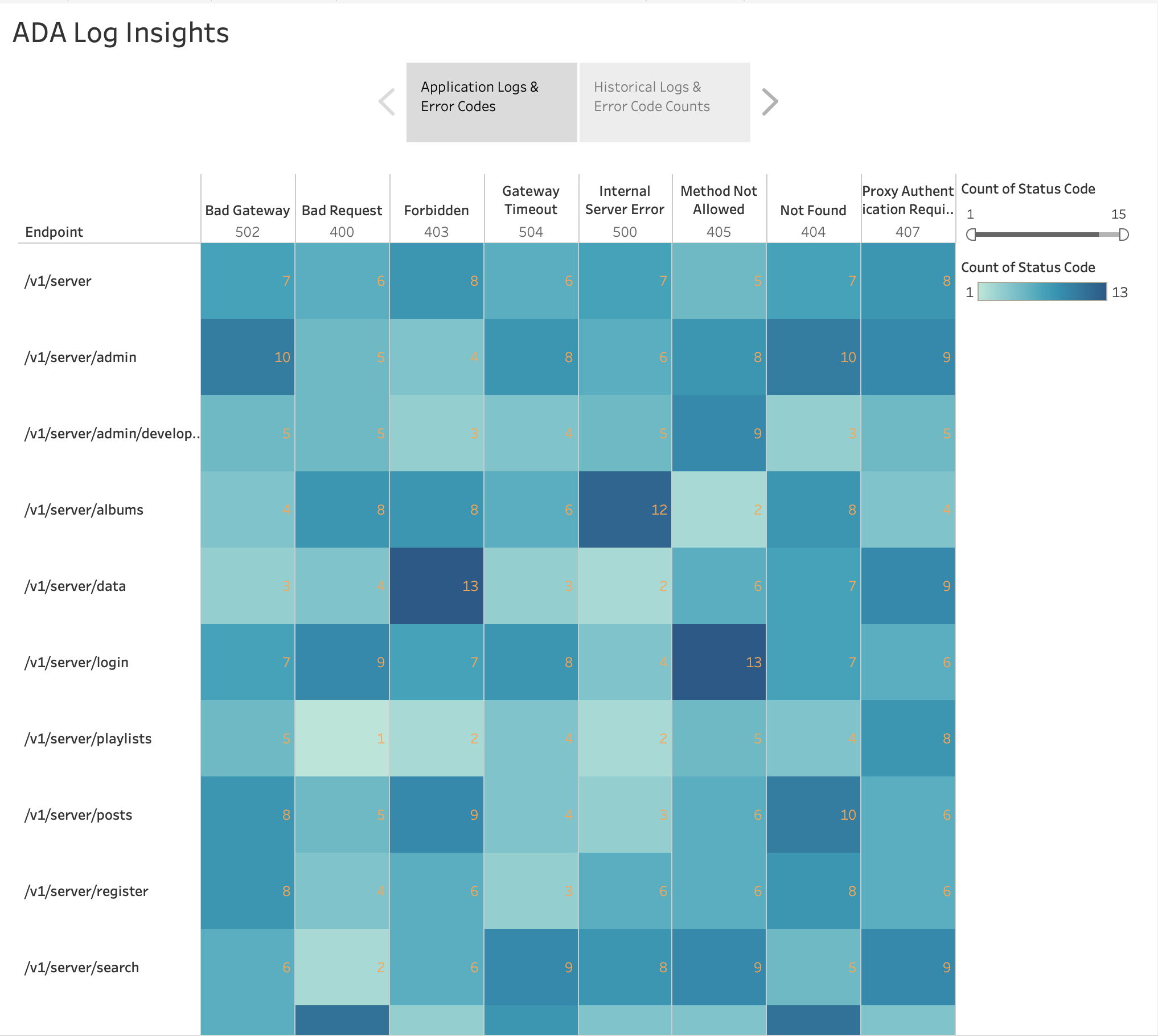
Dzięki konfiguracjom źródeł danych w Tableau możemy tworzyć niestandardowe raporty, wykresy i wizualizacje w produktach danych ADA. Rozważmy dwa przypadki użycia wizualizacji.
Jak pokazano na poniższym rysunku, zwizualizowaliśmy częstotliwość błędów HTTP według punktów końcowych aplikacji, korzystając z wbudowanego narzędzia Tableau Mapa ciepła wykres. Odfiltrowaliśmy kody stanu HTTP, aby uwzględnić tylko kody błędów z zakresu 4xx i 5xx.
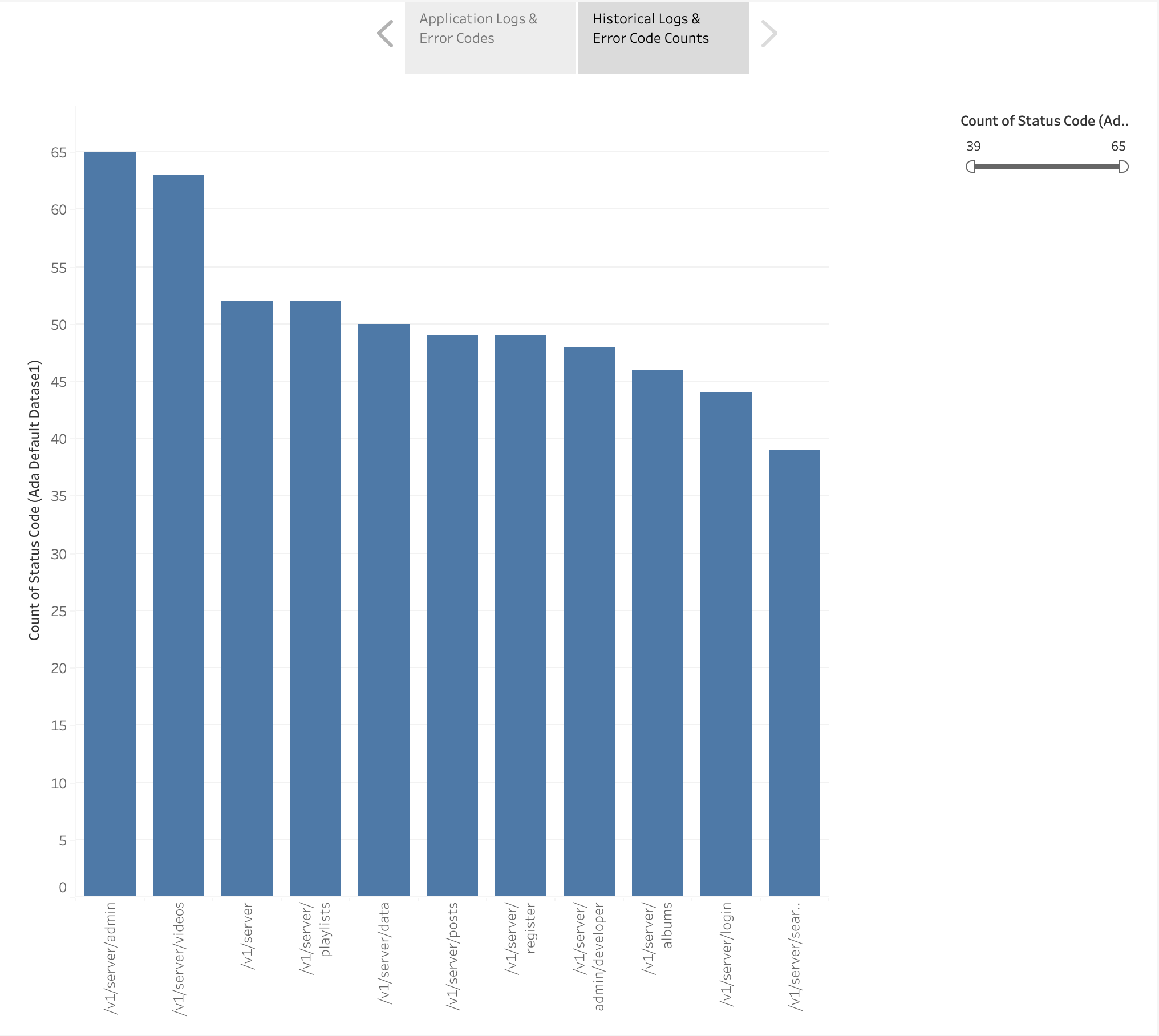
Stworzyliśmy także wykres słupkowy przedstawiający punkty końcowe aplikacji na podstawie dzienników historycznych uporządkowanych według liczby kodów błędów HTTP. Na tym wykresie widzimy, że /v1/server/admin punkt końcowy wygenerował najwięcej kodów stanu błędów HTTP.
Sprzątać
Oczyszczanie infrastruktury przykładowej aplikacji jest procesem dwuetapowym. Po pierwsze, aby usunąć infrastrukturę udostępnioną na potrzeby tej wersji demonstracyjnej, uruchom w terminalu następujące polecenie:
W przypadku następującego pytania wpisz y, a AWS CDK usunie zasoby wdrożone na potrzeby wersji demonstracyjnej:
Alternatywnie możesz usunąć zasoby za pomocą konsoli AWS CloudFormation, przechodząc do stosu CdkStack i wybierając Usuń.
Drugim krokiem jest odinstalowanie ADA. Aby uzyskać instrukcje, zobacz Odinstaluj rozwiązanie.
Wnioski
W tym poście pokazaliśmy, jak wykorzystać rozwiązanie ADA do uzyskania spostrzeżeń z dzienników aplikacji przechowywanych w dwóch różnych źródłach danych. Pokazaliśmy, jak zainstalować ADA na koncie AWS i wdrożyć komponenty demonstracyjne za pomocą AWS CDK. Stworzyliśmy produkty danych w ADA i skonfigurowaliśmy produkty danych z odpowiednimi źródłami danych, korzystając z wbudowanych łączników danych ADA. Pokazaliśmy, jak wysyłać zapytania do produktów danych przy użyciu standardowych zapytań SQL i generować szczegółowe informacje na temat danych dziennika. Połączyliśmy także klienta Tableau Desktop, produkt BI innej firmy, z ADA i zademonstrowaliśmy, jak tworzyć wizualizacje na podstawie produktów danych.
ADA automatyzuje proces pozyskiwania, przekształcania, zarządzania i wysyłania zapytań do różnorodnych zbiorów danych oraz upraszcza zarządzanie cyklem życia danych. Wbudowane konektory ADA umożliwiają pozyskiwanie danych z różnych źródeł danych. Zespoły programistyczne posiadające podstawową wiedzę na temat produktów i usług AWS będą w stanie w ciągu kilku godzin skonfigurować platformę operacyjnej analizy danych i zapewnić bezpieczny dostęp do danych. Dane można następnie łatwo i szybko przeglądać za pomocą intuicyjnego i samodzielnego interfejsu użytkownika sieciowego.
Wypróbuj ADA już dziś, aby łatwo zarządzać danymi i uzyskiwać wgląd w dane.
O autorach
 Aparajithan Vaidyanathan jest głównym architektem rozwiązań dla przedsiębiorstw w AWS. Wspiera klientów korporacyjnych w migracji i modernizacji ich obciążeń w chmurze AWS. Jest architektem chmury z ponad 23-letnim doświadczeniem w projektowaniu i rozwijaniu wielkoskalowych i rozproszonych systemów oprogramowania dla przedsiębiorstw. Specjalizuje się w uczeniu maszynowym i analizie danych ze szczególnym uwzględnieniem dziedziny inżynierii danych i funkcji. Jest początkującym maratończykiem, a jego hobby to piesze wędrówki, jazda na rowerze i spędzanie czasu z żoną i dwoma synami.
Aparajithan Vaidyanathan jest głównym architektem rozwiązań dla przedsiębiorstw w AWS. Wspiera klientów korporacyjnych w migracji i modernizacji ich obciążeń w chmurze AWS. Jest architektem chmury z ponad 23-letnim doświadczeniem w projektowaniu i rozwijaniu wielkoskalowych i rozproszonych systemów oprogramowania dla przedsiębiorstw. Specjalizuje się w uczeniu maszynowym i analizie danych ze szczególnym uwzględnieniem dziedziny inżynierii danych i funkcji. Jest początkującym maratończykiem, a jego hobby to piesze wędrówki, jazda na rowerze i spędzanie czasu z żoną i dwoma synami.
 Rashima Rahmana to programista z Sydney w Australii z ponad 10-letnim doświadczeniem w tworzeniu oprogramowania i architekturze. Pracuje głównie nad budowaniem wielkoskalowych rozwiązań AWS typu open source dla typowych zastosowań klientów i problemów biznesowych. W wolnym czasie lubi sport oraz spędza czas z przyjaciółmi i rodziną.
Rashima Rahmana to programista z Sydney w Australii z ponad 10-letnim doświadczeniem w tworzeniu oprogramowania i architekturze. Pracuje głównie nad budowaniem wielkoskalowych rozwiązań AWS typu open source dla typowych zastosowań klientów i problemów biznesowych. W wolnym czasie lubi sport oraz spędza czas z przyjaciółmi i rodziną.
 Hafiza Saadullaha jest głównym menedżerem technicznym ds. produktów w Amazon Web Services. Hafiz koncentruje się na rozwiązaniach AWS, zaprojektowanych, aby pomagać klientom w rozwiązywaniu typowych problemów biznesowych i przypadków użycia.
Hafiza Saadullaha jest głównym menedżerem technicznym ds. produktów w Amazon Web Services. Hafiz koncentruje się na rozwiązaniach AWS, zaprojektowanych, aby pomagać klientom w rozwiązywaniu typowych problemów biznesowych i przypadków użycia.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- ChartPrime. Podnieś poziom swojej gry handlowej dzięki ChartPrime. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- zdolność
- Zdolny
- O nas
- dostęp
- dostęp
- dostępny
- Konto
- w poprzek
- działania
- ADA
- Dodaj
- dodatek
- Dodatkowy
- adresowanie
- Admin
- Po
- przed
- Wszystkie kategorie
- dopuszczać
- pozwala
- wzdłuż
- również
- alternatywny
- Amazonka
- Amazon Web Services
- wśród
- an
- analiza
- analitycy
- analityka
- w czasie rzeczywistym sprawiają,
- i
- Inne
- każdy
- Apache
- api
- Pszczoła
- Zastosowanie
- aplikacje
- stosowany
- Aplikuj
- Stosowanie
- architektura
- SĄ
- AS
- ambitny
- At
- atrybuty
- Australia
- Uwierzytelnianie
- upoważniony
- zautomatyzowane
- automaty
- automatycznie
- dostępny
- AWS
- Tworzenie chmury AWS
- z powrotem
- Backend
- bar
- na podstawie
- podstawowy
- BE
- bo
- być
- zanim
- zrobiony na zamówienie
- pomiędzy
- obie
- Pudełko
- budować
- Budowanie
- wbudowany
- biznes
- business intelligence
- ale
- by
- wezwanie
- CAN
- zdolność
- walizka
- Etui
- katalog
- CD
- zmiana
- Wykres
- Wykresy
- Dodaj
- Wybierając
- klient
- Chmura
- kod
- Kody
- kolekcja
- Kolumna
- kolumny
- wspólny
- kompletny
- składniki
- systemu
- skonfigurowany
- Skontaktuj się
- połączony
- połączenie
- łączy
- Rozważać
- zgodny
- Konsola
- zawiera
- kontynuować
- współzależny
- Korelacja
- Odpowiedni
- odpowiada
- Koszty:
- Stwórz
- stworzony
- tworzy
- Tworzenie
- Listy uwierzytelniające
- Aktualny
- zwyczaj
- klient
- Klientów
- tablica rozdzielcza
- dane
- Analityka danych
- analiza danych
- Baza danych
- Bazy danych
- zbiory danych
- Domyślnie
- Kreowanie
- Demo
- wykazać
- wykazać
- W zależności
- rozwijać
- wdrażane
- Wdrożenie
- wdraża się
- opis
- zaprojektowany
- projektowanie
- stacjonarny
- szczegółowe
- detale
- Deweloper
- rozwijanie
- oprogramowania
- diagnoza
- różne
- bezpośrednio
- niepełnosprawny
- odkrycie
- Wyświetlacz
- dystrybuowane
- inny
- Nie
- domena
- domeny
- nie
- porzucone
- podczas
- każdy
- Wcześniej
- z łatwością
- redagowanie
- bądź
- włączony
- Umożliwia
- Punkt końcowy
- Punkty końcowe
- Inżynieria
- zapewnić
- Wchodzę
- Enterprise
- klienci korporacyjni
- Enterprise Solutions
- błąd
- Błędy
- zapewniają
- ustanowiony
- Eter (ETH)
- przykład
- Przede wszystkim system został opracowany
- doświadczenie
- Wyjaśniać
- wyjaśnienie
- wyciąg
- wyodrębnić dane
- znajomy
- członków Twojej rodziny
- Cecha
- kilka
- pole
- Łąka
- Postać
- filet
- Akta
- finał
- finansować
- i terminów, a
- elastyczne
- Skupiać
- koncentruje
- następujący
- W razie zamówieenia projektu
- format
- cztery
- Częstotliwość
- przyjaciele
- od
- funkcjonować
- Wzrost
- Generować
- wygenerowane
- otrzymać
- miejsce
- rządzić
- Zarządzanie
- Grupy
- Have
- mający
- he
- pomoc
- Podświetlony
- turystyka
- jego
- historyczny
- Hobby
- hostowane
- GODZINY
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- IAM
- identiques
- zidentyfikować
- tożsamość
- if
- importować
- in
- zawierać
- obejmuje
- Włącznie z
- Informacja
- Infrastruktura
- początkowy
- spostrzeżenia
- zainstalować
- instalacja
- instrukcje
- zintegrowany
- integracja
- Inteligencja
- interaktywne
- zainteresowany
- Interfejs
- najnowszych
- intuicyjny
- inwokuje
- zaangażowany
- problem
- IT
- przystąpić
- łączący
- Łączy
- jpg
- json
- właśnie
- Trzymać
- Klawisz
- wiedza
- język
- duży
- na dużą skalę
- Nazwisko
- później
- wodowanie
- nauka
- Biblioteka
- Upoważniony
- wifecycwe
- lubić
- LIMIT
- Linia
- Lista
- relacja na żywo
- log
- zalogowaniu
- długo
- Popatrz
- wyszukiwania
- maszyna
- uczenie maszynowe
- robić
- Dokonywanie
- zarządzanie
- i konserwacjami
- kierownik
- wiele
- mapa
- mapowanie
- Maraton
- Marketing
- Materia
- wymowny
- wiadomość
- MSZ
- może
- migrować
- minuty
- Moda
- zmodernizować
- jeszcze
- większość
- przeważnie
- Mozilla
- wieloczynnikowe uwierzytelnianie
- MySQL
- Nazwa
- O imieniu
- Nazwy
- rodzimy
- Nawigacja
- żeglujący
- Nawigacja
- Potrzebować
- potrzebne
- wymagania
- Nowości
- nowo
- Następny
- numer
- of
- Oferty
- nieaktywny
- Stary
- on
- Na żądanie
- ONE
- Online
- tylko
- koncepcja
- open source
- operacyjny
- Option
- or
- zamówienie
- Inne
- Pozostałe
- na zewnątrz
- wydajność
- przegląd
- strona
- chleb
- Hasło
- ścieżka
- Wzór
- wykonać
- uprawnienia
- Osobiście
- telefon
- pii
- rurociąg
- Miejsce
- Równina
- krok po kroku
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- polityka
- Portal
- Post
- postgresql
- powered
- Przygotować
- Przygotowuje
- warunki wstępne
- teraźniejszość
- prezenty
- Podgląd
- poprzedni
- głównie
- Główny
- Wcześniejszy
- problemy
- kontynuować
- wygląda tak
- obrobiony
- procesów
- przetwarzanie
- Wytworzony
- Produkt
- product manager
- Produkty
- Produkty i usługi
- Programy
- projekt
- zapewniać
- pod warunkiem,
- dostawca
- zapewnia
- cel
- cele
- Python
- zapytania
- pytanie
- szybko
- zasięg
- Czytaj
- gotowy
- otrzymać
- dokumentacja
- , o którym mowa
- region
- związek
- usunąć
- powtarzać
- Raporty
- zażądać
- wymagany
- Zasoby
- osób
- czuły
- Efekt
- zachować
- przeglądu
- jazda konna
- role
- korzeń
- Zasada
- run
- biegacz
- bieganie
- sole
- taki sam
- Zapisz
- Skala
- scenariusze
- zaplanowane
- zakres
- Szukaj
- druga
- Sekcja
- bezpieczne
- bezpieczeństwo
- widzieć
- wybrany
- wybór
- wysłać
- wysłany
- oddzielny
- służyć
- Bezserwerowe
- usługa
- Usługi
- zestaw
- ustawienie
- Share
- shared
- Short
- pokazane
- Targi
- Prosty
- uproszczony
- upraszczanie
- Rozmiar
- umiejętności
- So
- Tworzenie
- rozwoju oprogramowania
- rozwiązanie
- Rozwiązania
- Źródło
- Źródła
- specjalista
- specjalizuje się
- specyficzny
- określony
- Spędzanie
- SPORTOWE
- SQL
- stos
- standalone
- standard
- początek
- rozpocznie
- Rynek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- przechowywany
- sznur
- zbudowany
- udany
- Z powodzeniem
- taki
- podpory
- pewnie
- sydney
- systemy
- stół
- Żywy obraz
- Brać
- trwa
- zespół
- Zespoły
- Techniczny
- umiejętności techniczne
- terminal
- że
- Połączenia
- Źródło
- ich
- następnie
- Tam.
- Te
- innych firm
- to
- trzy
- Przez
- czas
- do
- już dziś
- narzędzia
- Top
- Top 10
- Kwota produktów:
- Przekształcać
- Transformacja
- przemiany
- przekształcony
- transformatorowy
- transformacje
- rozsierdzony
- drugiej
- rodzaj
- typy
- dla
- zasadniczy
- zrozumieć
- zaktualizowane
- Nowości
- na
- URI
- us
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Interfejs użytkownika
- Użytkownicy
- za pomocą
- Wartości
- zmienna
- różnorodność
- wersja
- przez
- Zobacz i wysłuchaj
- chcieć
- Droga..
- we
- sieć
- usługi internetowe
- DOBRZE
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- szeroki
- Szeroki zasięg
- żona
- będzie
- w
- w ciągu
- bez
- Praca
- workflow
- działa
- by
- napisać
- lat
- ty
- Twój
- zefirnet