To jest wspólny post napisany wspólnie przez AWS i Voxel51. Voxel51 jest firmą stojącą za FiftyOne, zestawem narzędzi typu open source do tworzenia wysokiej jakości zestawów danych i komputerowych modeli wizyjnych.
Firma handlu detalicznego tworzy aplikację mobilną, aby pomóc klientom kupować ubrania. Aby utworzyć tę aplikację, potrzebują wysokiej jakości zbioru danych zawierającego obrazy odzieży oznaczone różnymi kategoriami. W tym poście pokazujemy, jak zmienić przeznaczenie istniejącego zestawu danych poprzez czyszczenie danych, wstępne przetwarzanie i wstępne etykietowanie za pomocą modelu klasyfikacji zero-shot w Pięćdziesiąt jedeni dopasowując te etykiety za pomocą Amazon SageMaker Ground Prawda.
Możesz użyć Ground Truth i FiftyOne, aby przyspieszyć swój projekt etykietowania danych. Pokazujemy, jak bezproblemowo używać razem tych dwóch aplikacji, aby tworzyć wysokiej jakości zestawy danych z etykietami. W naszym przykładowym przypadku użycia pracujemy z Zbiór danych Fashion200K, wydany na ICCV 2017.
Omówienie rozwiązania
Ground Truth to w pełni samoobsługowa i zarządzana usługa etykietowania danych, która umożliwia analitykom danych, inżynierom uczenia maszynowego (ML) i badaczom tworzenie zestawów danych wysokiej jakości. Pięćdziesiąt jeden by Woksel51 to zestaw narzędzi typu open source do kuracji, wizualizacji i oceny zestawów danych wizji komputerowej, dzięki czemu można trenować i analizować lepsze modele, przyspieszając przypadki użycia.
W poniższych sekcjach pokazujemy, jak wykonać następujące czynności:
- Wizualizuj zestaw danych w FiftyOne
- Oczyść zestaw danych za pomocą filtrowania i deduplikacji obrazu w FiftyOne
- Wstępnie oznacz oczyszczone dane klasyfikacją zerowego strzału w FiftyOne
- Oznacz mniejszy wyselekcjonowany zestaw danych o Ground Truth
- Wstrzyknij oznakowane wyniki z Ground Truth do FiftyOne i przejrzyj oznaczone wyniki w FiftyOne
Omówienie przypadków użycia
Załóżmy, że jesteś właścicielem firmy zajmującej się sprzedażą detaliczną i chcesz stworzyć aplikację mobilną, która dostarcza spersonalizowane rekomendacje, aby pomóc użytkownikom zdecydować, w co się ubrać. Twoi potencjalni użytkownicy szukają aplikacji, która powie im, które ubrania w ich szafie dobrze ze sobą współgrają. Widzisz w tym szansę: jeśli potrafisz zidentyfikować dobre stroje, możesz to wykorzystać, aby polecić nowe artykuły odzieżowe, które uzupełniają odzież, którą klient już posiada.
Chcesz, aby wszystko było jak najłatwiejsze dla użytkownika końcowego. Idealnie byłoby, gdyby ktoś korzystający z Twojej aplikacji zrobił tylko zdjęcia ubrań w swojej szafie, a Twoje modele ML zadziałają magicznie za kulisami. Możesz wytrenować model ogólnego przeznaczenia lub dostosować model do unikalnego stylu każdego użytkownika, korzystając z jakiejś formy informacji zwrotnej.
Najpierw jednak musisz określić, jaki rodzaj odzieży fotografuje użytkownik. Czy to koszula? Para spodni? Albo coś innego? W końcu prawdopodobnie nie chcesz polecać stroju, który ma wiele sukienek lub wiele czapek.
Aby sprostać temu początkowemu wyzwaniu, chcesz wygenerować zestaw danych szkoleniowych składający się z obrazów różnych artykułów odzieżowych o różnych wzorach i stylach. Aby stworzyć prototyp z ograniczonym budżetem, chcesz przeprowadzić ładowanie przy użyciu istniejącego zestawu danych.
Aby zilustrować i przeprowadzić Cię przez proces w tym poście, używamy zestawu danych Fashion200K opublikowanego na ICCV 2017. Jest to uznany i dobrze cytowany zestaw danych, ale nie jest bezpośrednio dopasowany do twojego przypadku użycia.
Chociaż artykuły odzieżowe są oznaczone kategoriami (i podkategoriami) i zawierają wiele pomocnych tagów pochodzących z oryginalnych opisów produktów, dane nie są systematycznie oznaczane informacjami o wzorze lub stylu. Twoim celem jest przekształcenie tego istniejącego zestawu danych w solidny zestaw danych szkoleniowych dla modeli klasyfikacji odzieży. Musisz wyczyścić dane, rozszerzając schemat etykietowania o etykiety stylów. I chcesz to zrobić szybko i przy jak najmniejszych wydatkach.
Pobierz dane lokalnie
Najpierw pobierz plik zip women.tar i folder labels (wraz ze wszystkimi jego podfolderami), postępując zgodnie z instrukcjami podanymi w Zestaw danych Fashion200K Repozytorium GitHub. Po rozpakowaniu ich obu, utwórz nadrzędny katalog fashion200k i przenieś do niego etykiety i foldery kobiet. Na szczęście te obrazy zostały już przycięte do ramek ograniczających wykrywanie obiektów, więc możemy skupić się na klasyfikacji, zamiast martwić się wykrywaniem obiektów.
Pomimo nazwy „200 338,339” wyodrębniony przez nas katalog kobiet zawiera 200 300,000 obrazów. Aby wygenerować oficjalny zestaw danych FashionXNUMXK, jego autorzy przeszukali ponad XNUMX XNUMX produktów online i tylko produkty z opisami zawierającymi więcej niż cztery słowa zostały wybrane. Do naszych celów, gdy opis produktu nie jest niezbędny, możemy wykorzystać wszystkie zindeksowane obrazy.
Przyjrzyjmy się, jak uporządkowane są te dane: w folderze kobiety obrazy są uporządkowane według typu artykułu najwyższego poziomu (spódnice, topy, spodnie, kurtki i sukienki) oraz podkategorii typu artykułu (bluzki, t-shirty, najfatalniejszy).
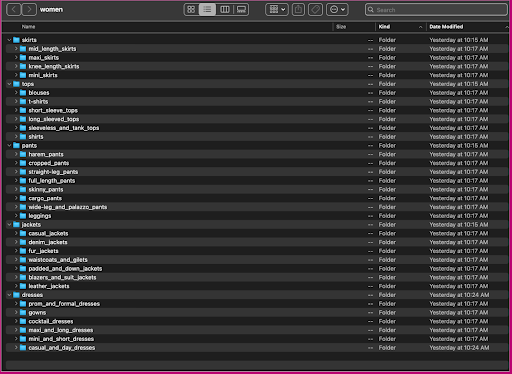
W katalogach podkategorii znajduje się podkatalog dla każdej listy produktów. Każdy z nich zawiera zmienną liczbę obrazów. Na przykład podkategoria cropped_pants zawiera następujące listy produktów i powiązane obrazy.
Folder labels zawiera plik tekstowy dla każdego typu artykułu najwyższego poziomu, zarówno dla podziałów pociągów, jak i testów. W każdym z tych plików tekstowych znajduje się oddzielna linia dla każdego obrazu, określająca względną ścieżkę pliku, ocenę i znaczniki z opisu produktu.
Ponieważ zmieniamy przeznaczenie zestawu danych, łączymy wszystkie obrazy pociągów i testów. Używamy ich do generowania wysokiej jakości zestawu danych specyficznych dla aplikacji. Po zakończeniu tego procesu możemy losowo podzielić wynikowy zestaw danych na nowe podziały pociągów i testów.
Wstawiaj, przeglądaj i zarządzaj zestawem danych w FiftyOne
Jeśli jeszcze tego nie zrobiłeś, zainstaluj Open Source FiftyOne za pomocą pip:
Najlepszą praktyką jest robienie tego w nowym środowisku wirtualnym (venv lub conda). Następnie zaimportuj odpowiednie moduły. Zaimportuj podstawową bibliotekę, fiveone, FiftyOne Brain, która ma wbudowane metody ML, FiftyOne Zoo, z której załadujemy model, który będzie generował dla nas etykiety zero-shot, oraz ViewField, który pozwala nam skutecznie filtrować dane w naszym zbiorze danych:
Chcesz również zaimportować moduły glob i os Python, które pomogą nam pracować ze ścieżkami i dopasowaniem wzorców do zawartości katalogu:
Teraz jesteśmy gotowi do załadowania zestawu danych do FiftyOne. Najpierw tworzymy zestaw danych o nazwie fashion200k i czynimy go trwałym, co pozwala nam zapisywać wyniki operacji wymagających dużej mocy obliczeniowej, więc wystarczy obliczyć te ilości tylko raz.
Możemy teraz przeglądać wszystkie katalogi podkategorii, dodając wszystkie obrazy w katalogach produktów. Do każdej próbki dodajemy etykietę klasyfikacyjną FiftyOne z nazwą pola typ_artykułu, wypełnioną przez kategorię artykułu najwyższego poziomu obrazu. Dodajemy również informacje o kategorii i podkategorii jako tagi:
W tym momencie możemy zwizualizować nasz zbiór danych w aplikacji FiftyOne uruchamiając sesję:
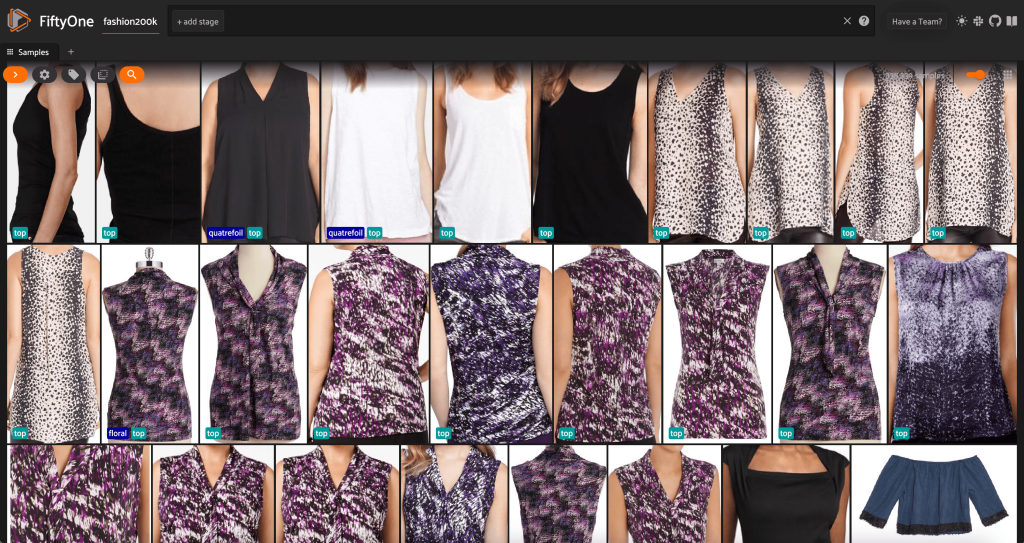
Możemy również wydrukować podsumowanie zestawu danych w Pythonie, uruchamiając print(dataset):
Możemy również dodać tagi z pliku labels katalog do próbek w naszym zbiorze danych:
Patrząc na dane, kilka rzeczy staje się jasnych:
- Niektóre obrazy są dość ziarniste i mają niską rozdzielczość. Jest tak prawdopodobnie dlatego, że te obrazy zostały wygenerowane przez przycięcie początkowych obrazów w obwiedniach wykrywania obiektów.
- Niektóre ubrania są noszone przez osobę, a niektóre są fotografowane samodzielnie. Te szczegóły są zawarte w
viewpointwłasność. - Wiele zdjęć tego samego produktu jest bardzo podobnych, więc przynajmniej na początku umieszczanie więcej niż jednego zdjęcia na produkt może nie zwiększyć mocy predykcyjnej. W większości pierwsze zdjęcie każdego produktu (kończące się na
_0.jpeg) jest najczystszy.
Na początku możemy chcieć wytrenować nasz model klasyfikacji stylów odzieży na kontrolowanym podzbiorze tych obrazów. W tym celu używamy zdjęć naszych produktów w wysokiej rozdzielczości i ograniczamy nasz wgląd do jednej reprezentatywnej próbki na produkt.
Najpierw odfiltrowujemy obrazy o niskiej rozdzielczości. Używamy compute_metadata() metoda obliczania i przechowywania szerokości i wysokości obrazu w pikselach dla każdego obrazu w zbiorze danych. Następnie zatrudniamy FiftyOne ViewField aby odfiltrować obrazy na podstawie minimalnych dozwolonych wartości szerokości i wysokości. Zobacz następujący kod:
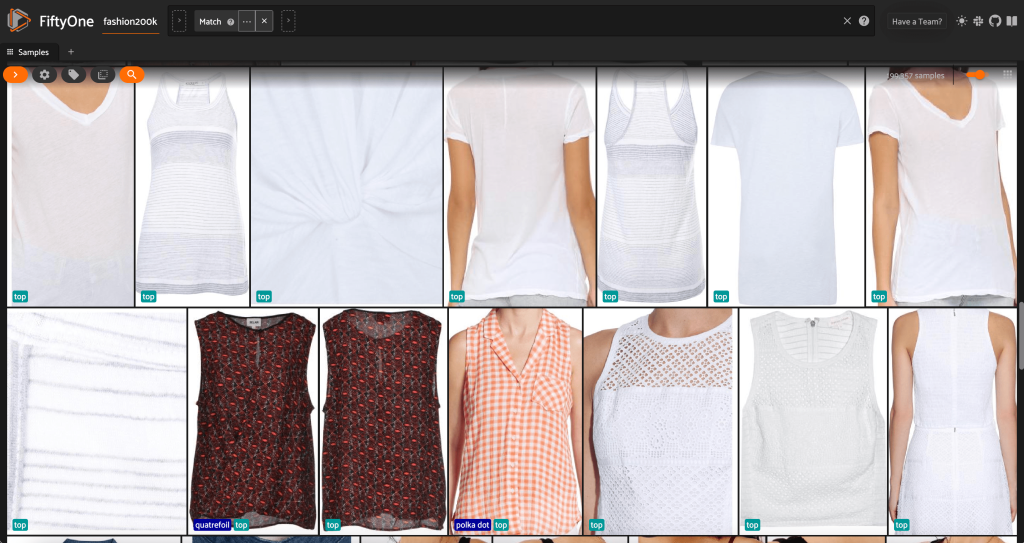
Ten podzbiór o wysokiej rozdzielczości zawiera prawie 200,000 XNUMX próbek.
Z tego widoku możemy utworzyć nowy widok w naszym zbiorze danych zawierający tylko jedną reprezentatywną próbkę (maksymalnie) dla każdego produktu. Używamy ViewField jeszcze raz dopasowanie wzorca dla ścieżek plików, które kończą się na _0.jpeg:
Zobaczmy losowo przetasowaną kolejność obrazów w tym podzbiorze:
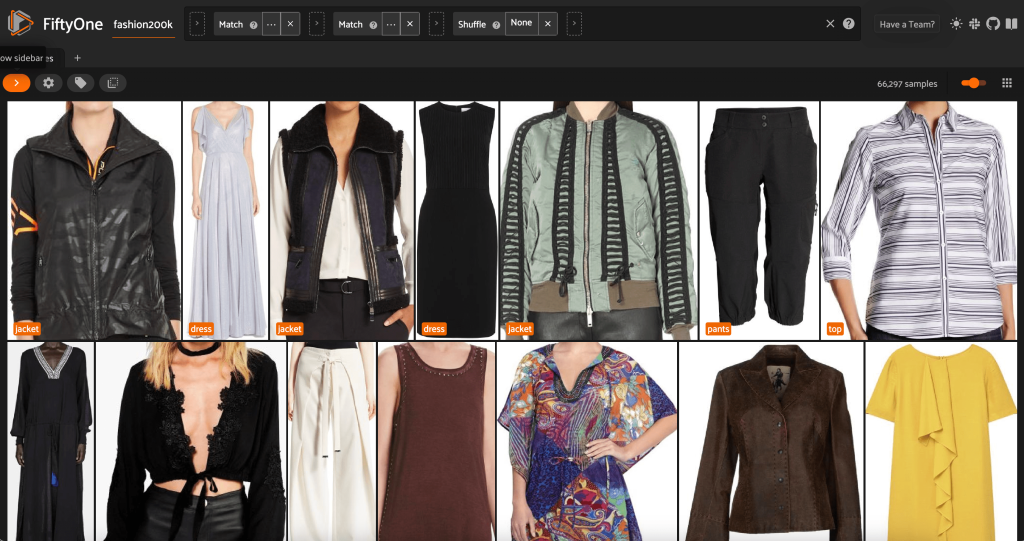
Usuń zbędne obrazy w zbiorze danych
Ten widok zawiera 66,297 19 obrazów, czyli nieco ponad XNUMX% oryginalnego zbioru danych. Kiedy jednak spojrzymy na widok, widzimy, że jest wiele bardzo podobnych produktów. Przechowywanie wszystkich tych kopii prawdopodobnie zwiększy tylko koszty naszego szkolenia w zakresie etykietowania i modelowania, bez zauważalnej poprawy wydajności. Zamiast tego pozbądźmy się prawie duplikatów, aby utworzyć mniejszy zestaw danych, który wciąż ma ten sam cios.
Ponieważ te obrazy nie są dokładnymi duplikatami, nie możemy sprawdzić równości w pikselach. Na szczęście możemy użyć FiftyOne Brain, aby pomóc nam oczyścić nasz zbiór danych. W szczególności obliczymy osadzanie dla każdego obrazu — niskowymiarowy wektor reprezentujący obraz — a następnie poszukamy obrazów, których wektory osadzania są blisko siebie. Im bliższe wektory, tym bardziej podobne obrazy.
Używamy modelu CLIP do generowania 512-wymiarowego wektora osadzania dla każdego obrazu i przechowujemy te osadzania w osadzaniach terenowych na próbkach w naszym zbiorze danych:
Następnie obliczamy bliskość między osadzaniami, używając podobieństwo cosinusowei stwierdzić, że dowolne dwa wektory, których podobieństwo jest większe niż pewien próg, prawdopodobnie będą prawie duplikatami. Wyniki podobieństwa cosinusów mieszczą się w zakresie [0, 1], a patrząc na dane, wynik progowy thresh=0.5 wydaje się być mniej więcej prawidłowy. Ponownie, to nie musi być idealne. Kilka prawie zduplikowanych obrazów prawdopodobnie nie zrujnuje naszej mocy predykcyjnej, a odrzucenie kilku nieduplikatów nie wpłynie znacząco na wydajność modelu.
Możemy zobaczyć rzekome duplikaty, aby sprawdzić, czy rzeczywiście są one zbędne:
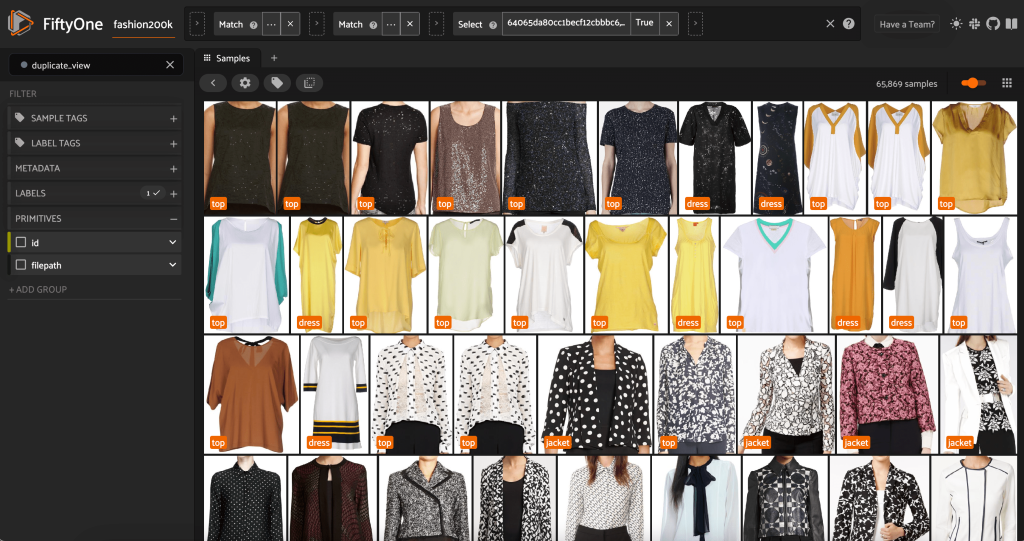
Kiedy jesteśmy zadowoleni z wyniku i uważamy, że te obrazy są rzeczywiście prawie duplikatami, możemy wybrać jedną próbkę z każdego zestawu podobnych próbek do zachowania i zignorować pozostałe:
Teraz ten widok zawiera 3,729 obrazów. Czyszcząc dane i identyfikując wysokiej jakości podzbiór zbioru danych Fashion200K, FiftyOne pozwala nam ograniczyć naszą koncentrację z ponad 300,000 4,000 obrazów do prawie 98, co stanowi redukcję o 90%. Samo użycie osadzania w celu usunięcia prawie zduplikowanych obrazów zmniejszyło całkowitą liczbę rozważanych obrazów o ponad XNUMX%, przy niewielkim lub żadnym wpływie na jakiekolwiek modele, które miały być szkolone na tych danych.
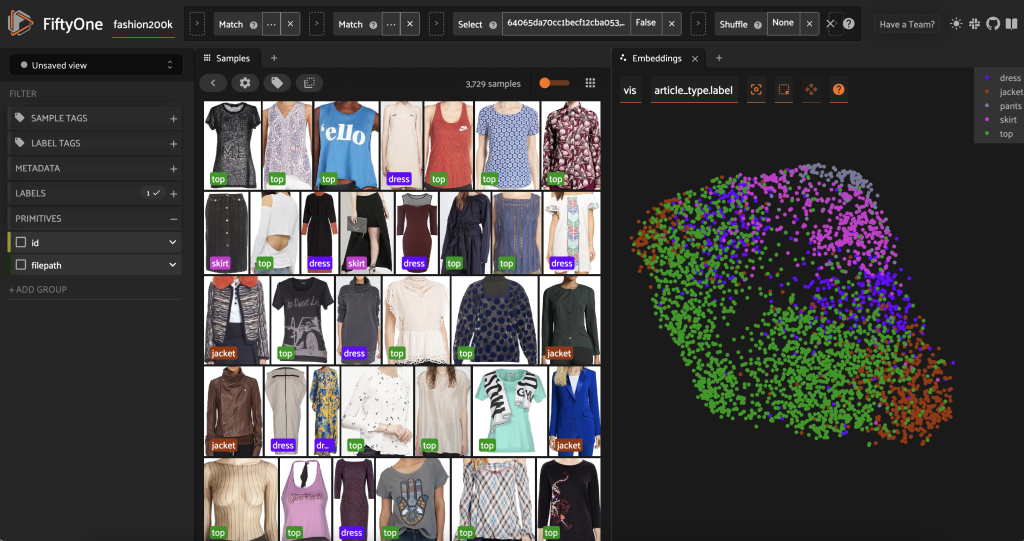
Przed wstępnym oznaczeniem tego podzbioru możemy lepiej zrozumieć dane, wizualizując już obliczone osadzenie. Możemy użyć wbudowanego w FiftyOne Brain compute_visualization(), która wykorzystuje technikę jednolitej aproksymacji rozmaitości (UMAP) do rzutowania 512-wymiarowych wektorów osadzania na dwuwymiarową przestrzeń, abyśmy mogli je zwizualizować:
Otwieramy nowy Panel osadzania w aplikacji FiftyOne i kolorowanie według typu artykułu, i widzimy, że te osadzenia z grubsza kodują pojęcie typu artykułu (między innymi!).
Teraz jesteśmy gotowi do wstępnego oznakowania tych danych.
Sprawdzając te bardzo unikalne obrazy o wysokiej rozdzielczości, możemy wygenerować przyzwoitą wstępną listę stylów do wykorzystania jako klasy w naszej wstępnej klasyfikacji zero-shotów. Naszym celem podczas wstępnego oznaczania tych obrazów niekoniecznie jest prawidłowe oznaczanie każdego obrazu. Naszym celem jest raczej zapewnienie dobrego punktu wyjścia dla adnotatorów, dzięki czemu możemy skrócić czas i koszty etykietowania.
Następnie możemy utworzyć instancję modelu klasyfikacji zerowej dla tej aplikacji. Używamy modelu CLIP, który jest modelem ogólnego przeznaczenia wytrenowanym zarówno na obrazach, jak i języku naturalnym. Tworzymy instancję modelu CLIP z zachętą tekstową „Odzież w stylu”, tak aby na podstawie obrazu model wyświetlił klasę, dla której „Odzież w stylu [klasa]” jest najlepiej dopasowana. CLIP nie jest przeszkolony w zakresie danych dotyczących handlu detalicznego ani mody, więc nie będzie to idealne rozwiązanie, ale może zaoszczędzić na kosztach etykietowania i adnotacji.
Następnie stosujemy ten model do naszego zredukowanego podzbioru i przechowujemy wyniki w pliku article_style pole:
Ponownie uruchamiając aplikację FiftyOne, możemy wizualizować obrazy z tymi przewidywanymi etykietami stylu. Sortujemy według pewności prognoz, więc najpierw przeglądamy najbardziej pewne prognozy stylu:
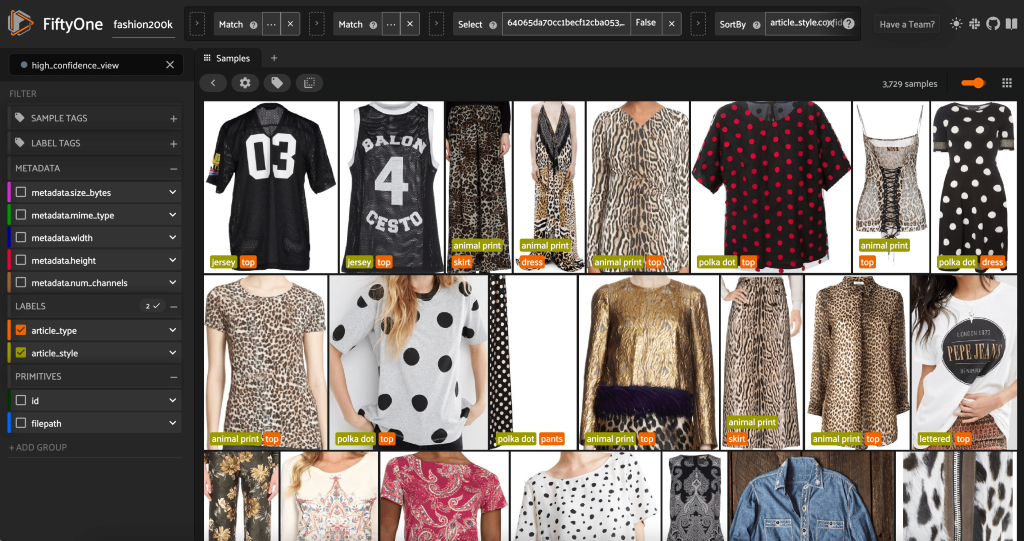
Widzimy, że prognozy o największej pewności wydają się dotyczyć stylów „dżersej”, „zwierzęcy nadruk”, „kropki” i „litery”. Ma to sens, ponieważ te style są stosunkowo różne. Wydaje się również, że w większości przewidywane etykiety stylów są dokładne.
Możemy również spojrzeć na prognozy stylu o najniższej pewności:
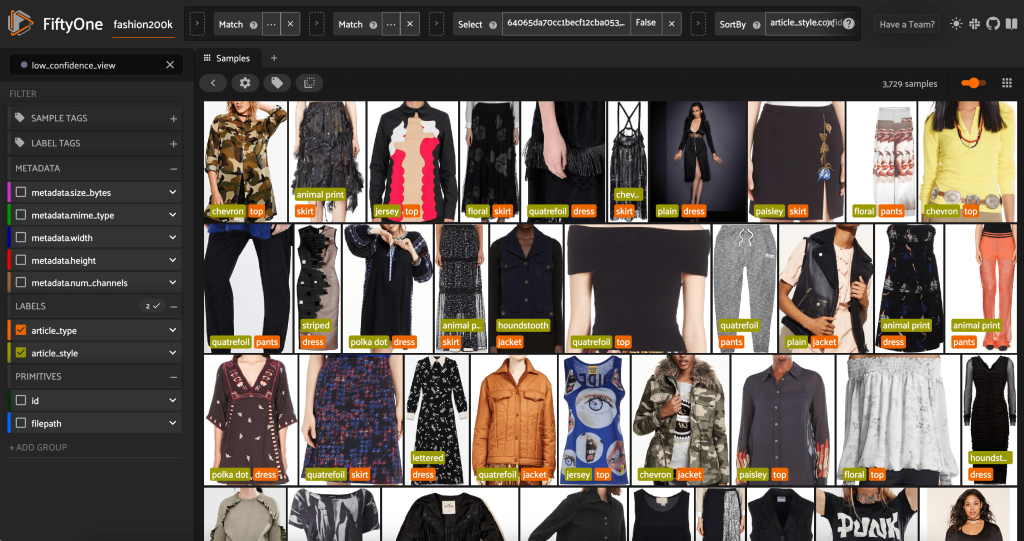
W przypadku niektórych z tych obrazów odpowiednia kategoria stylu znajduje się na podanej liście, a artykuł odzieżowy jest nieprawidłowo oznaczony. Na przykład pierwszy obraz w siatce powinien wyraźnie oznaczać „kamuflaż”, a nie „szewron”. Jednak w innych przypadkach produkty nie pasują do kategorii stylów. Na przykład sukienka na drugim obrazie w drugim rzędzie nie jest dokładnie „w paski”, ale biorąc pod uwagę te same opcje etykietowania, ludzki adnotator również mógł być w konflikcie. Budując nasz zbiór danych, musimy zdecydować, czy usunąć takie skrajne przypadki, dodać nowe kategorie stylów, czy rozszerzyć zbiór danych.
Wyeksportuj ostateczny zestaw danych z FiftyOne
Wyeksportuj ostateczny zestaw danych za pomocą następującego kodu:
Do folderu możemy wyeksportować mniejszy zbiór danych, na przykład 16 obrazów 200kFashionDatasetExportResult-16Images. Używając go, tworzymy zadanie dostosowania Ground Truth:
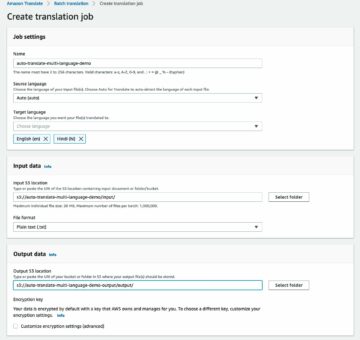
Prześlij poprawiony zestaw danych, przekonwertuj format etykiety na Ground Truth, prześlij do Amazon S3 i utwórz plik manifestu dla zadania dostosowania
Możemy przekonwertować etykiety w zbiorze danych, aby pasowały do wyjściowy schemat manifestu zadania pola granicznego Ground Truth i prześlij obrazy do pliku Usługa Amazon Simple Storage (Amazon S3) wiadro do uruchomienia Zadanie regulacji Ground Truth:
Prześlij plik manifestu do Amazon S3 z następującym kodem:
Twórz poprawione stylizowane etykiety za pomocą Ground Truth
Aby dodać adnotacje do danych za pomocą etykiet stylów przy użyciu funkcji Ground Truth, wykonaj niezbędne czynności, aby rozpocząć zadanie etykietowania obwiedni, postępując zgodnie z procedurą opisaną w Pierwsze kroki z podstawową prawdą przewodnik ze zbiorem danych w tym samym segmencie S3.
- W konsoli SageMaker utwórz zadanie etykietowania Ground Truth.
- Ustaw Wprowadź lokalizację zestawu danych być manifestem, który utworzyliśmy w poprzednich krokach.
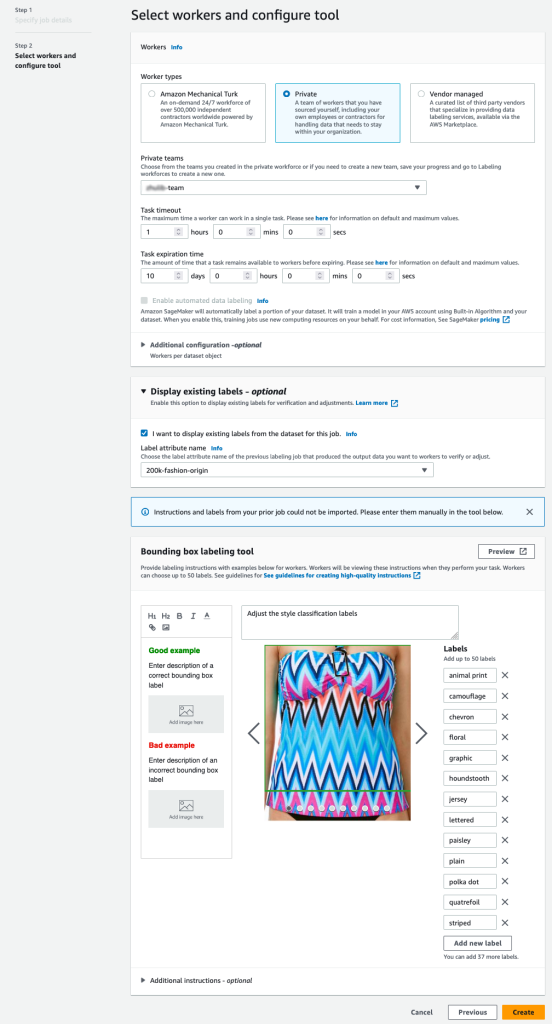
- Określ ścieżkę S3 dla Lokalizacja wyjściowego zbioru danych.
- W razie zamówieenia projektu Rola uprawnieńwybierz Wprowadź niestandardową rolę IAM RNA, a następnie wprowadź rolę ARN.
- W razie zamówieenia projektu Kategoria zadaniawybierz Obraz i wybierz Pudełko ograniczające.
- Dodaj Następna.
- W Pracownicy wybierz typ siły roboczej, z którego chcesz skorzystać.
Możesz wybrać siłę roboczą poprzez Amazon Mechanical Turk, dostawców zewnętrznych lub własnych pracowników prywatnych. Aby uzyskać więcej informacji na temat opcji siły roboczej, zobacz Twórz siły robocze i zarządzaj nimi. - Rozszerzać Opcje wyświetlania istniejących etykiet i wybierz Chcę wyświetlić istniejące etykiety ze zbioru danych dla tego zadania.
- W razie zamówieenia projektu Atrybut etykiety name wybierz z manifestu nazwę odpowiadającą etykietom, które chcesz wyświetlić w celu dostosowania.
Nazwy atrybutów etykiet będą widoczne tylko dla etykiet pasujących do typu zadania wybranego w poprzednich krokach. - Ręcznie wprowadź etykiety dla Narzędzie do etykietowania obwiedni.
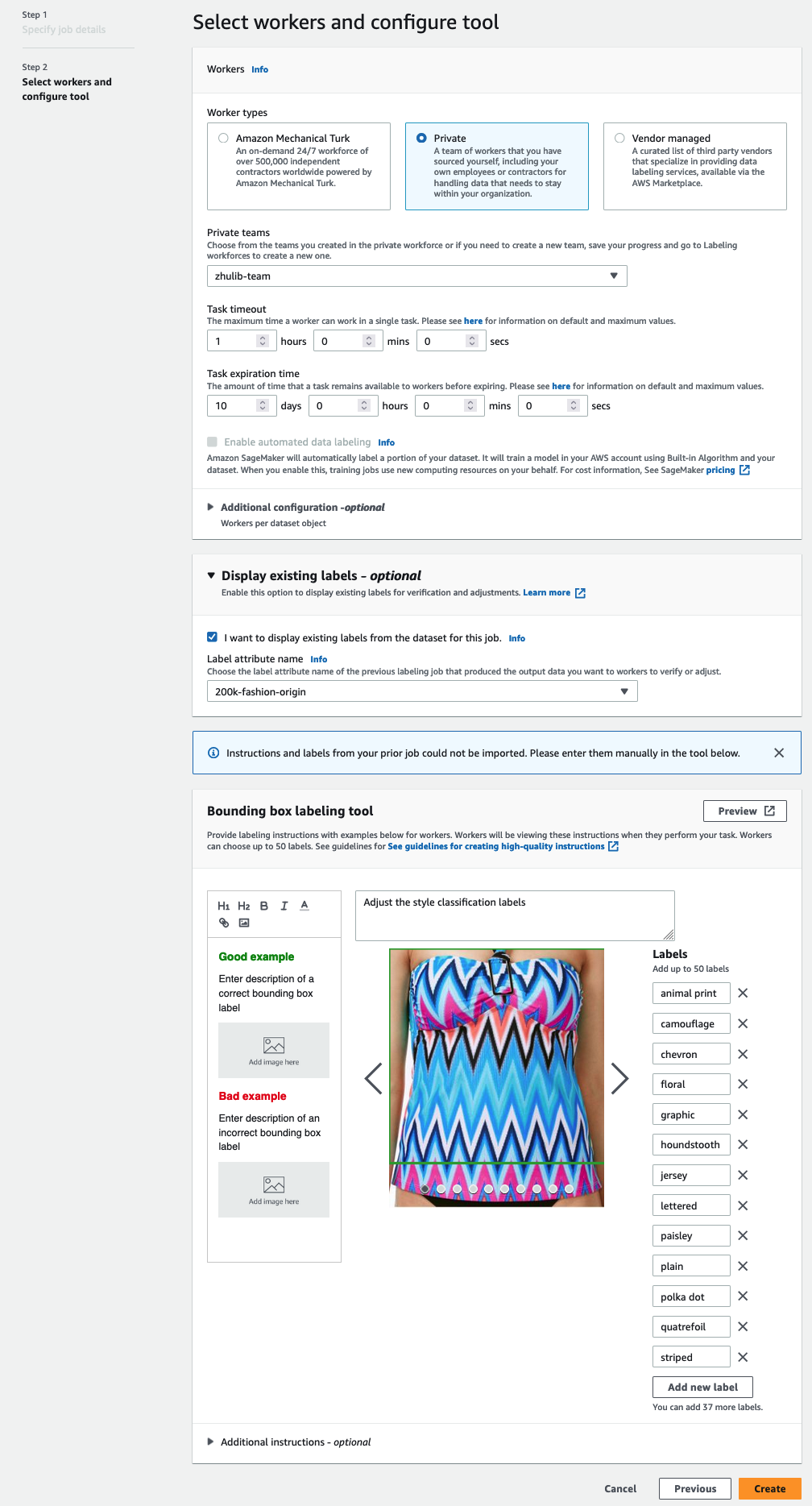 Etykiety muszą zawierać te same etykiety, które są używane w publicznym zbiorze danych. Możesz dodać nowe etykiety. Poniższy zrzut ekranu pokazuje, jak wybrać pracowników i skonfigurować narzędzie do zadania etykietowania.
Etykiety muszą zawierać te same etykiety, które są używane w publicznym zbiorze danych. Możesz dodać nowe etykiety. Poniższy zrzut ekranu pokazuje, jak wybrać pracowników i skonfigurować narzędzie do zadania etykietowania.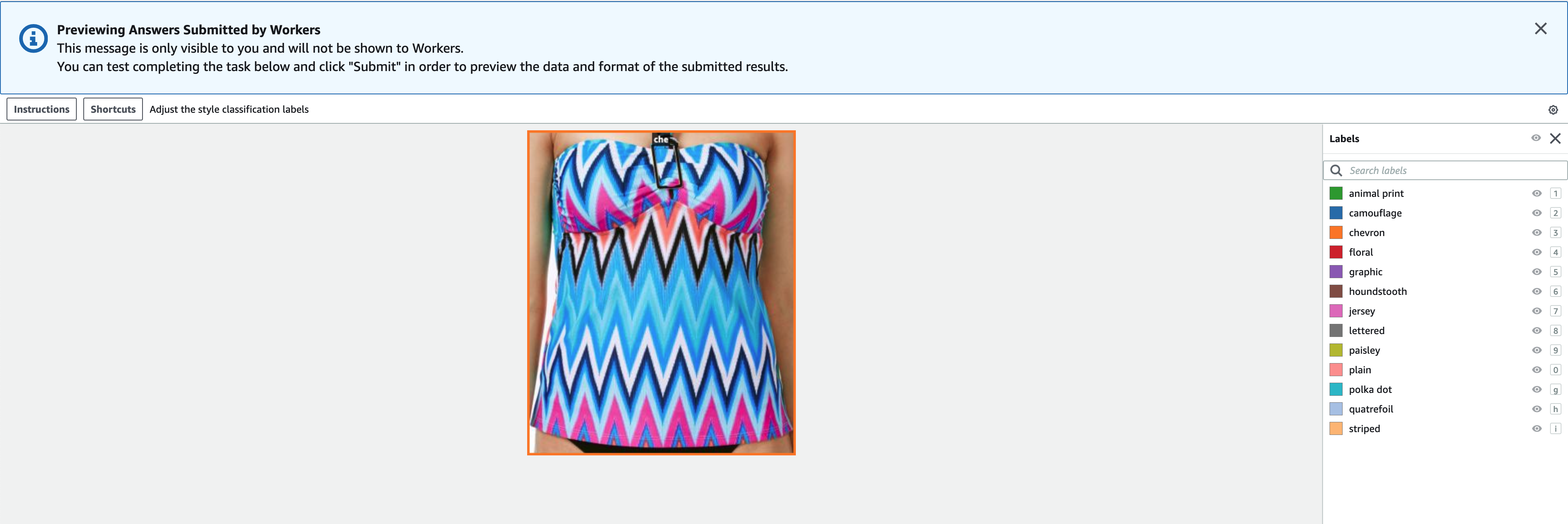
- Dodaj Podgląd aby wyświetlić podgląd obrazu i oryginalnych adnotacji.
Utworzyliśmy teraz zadanie etykietowania w Ground Truth. Po zakończeniu naszej pracy możemy załadować nowo wygenerowane dane z etykietami do FiftyOne. Ground Truth generuje dane wyjściowe w manifeście wyjściowym Ground Truth. Aby uzyskać więcej informacji na temat wyjściowego pliku manifestu, zobacz Wyjście zadania ramki ograniczającej. Poniższy kod przedstawia przykład formatu manifestu wyjściowego:
Przejrzyj oznaczone wyniki z Ground Truth w FiftyOne
Po zakończeniu zadania pobierz manifest wyjściowy zadania etykietowania z usługi Amazon S3.
Przeczytaj wyjściowy plik manifestu:
Utwórz zestaw danych FiftyOne i przekonwertuj wiersze manifestu na próbki w zestawie danych:
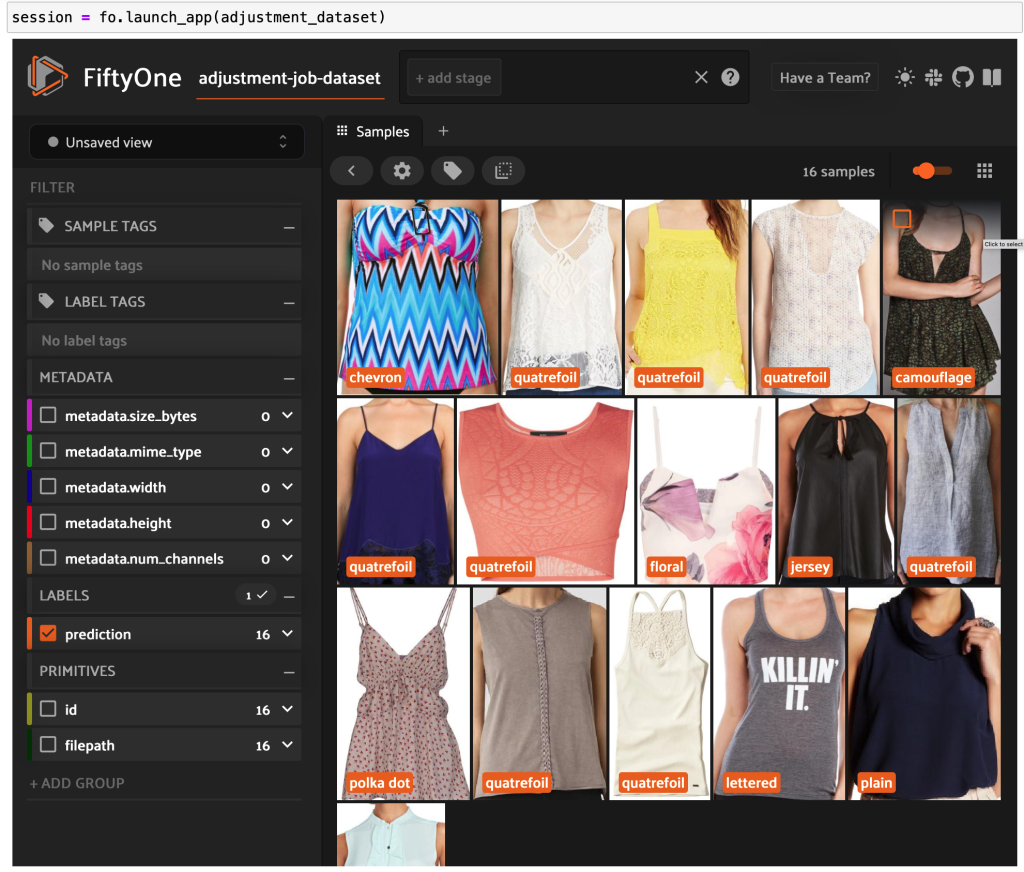
Możesz teraz zobaczyć wysokiej jakości oznaczone dane z Ground Truth w FiftyOne.
Wnioski
W tym poście pokazaliśmy, jak tworzyć wysokiej jakości zestawy danych, łącząc moc Pięćdziesiąt jeden by Woksel51, zestaw narzędzi typu open source, który umożliwia zarządzanie zestawem danych, śledzenie, wizualizację i kurację, oraz Ground Truth, usługę etykietowania danych, która umożliwia wydajne i dokładne etykietowanie zestawów danych wymaganych do szkolenia systemów uczenia maszynowego poprzez zapewnienie dostępu do wielu wbudowanych -w szablonach zadań i dostęp do zróżnicowanej siły roboczej za pośrednictwem Mechanical Turk, dostawców zewnętrznych lub własnej siły roboczej.
Zachęcamy do wypróbowania tej nowej funkcji poprzez zainstalowanie instancji FiftyOne i rozpoczęcie korzystania z konsoli Ground Truth. Aby dowiedzieć się więcej o Ground Truth, zobacz Dane etykiety, Często zadawane pytania dotyczące etykietowania danych Amazon SageMakeri Blog dotyczący uczenia maszynowego AWS.
Połącz się z Społeczność uczenia maszynowego i sztucznej inteligencji jeśli masz jakieś pytania lub uwagi!
Dołącz do społeczności FiftyOne!
Dołącz do tysięcy inżynierów i analityków danych, którzy już korzystają z FiftyOne, aby rozwiązywać niektóre z najtrudniejszych problemów współczesnej wizji komputerowej!
O autorach
Shalendra Chhabra jest obecnie szefem zarządzania produktami w Amazon SageMaker Human-in-the-Loop (HIL) Services. Wcześniej Shalendra inkubowała i prowadziła analizę językową i konwersacyjną dla Microsoft Teams Meetings, była EIR w Amazon Alexa Techstars Startup Accelerator, wiceprezesem ds. Omów.io, Head of Product and Marketing w Clipboard (przejętej przez Salesforce) oraz Lead Product Manager w Swype (przejętej przez Nuance). W sumie Shalendra pomogła budować, dostarczać i sprzedawać produkty, które wpłynęły na ponad miliard istnień ludzkich.
Jakub Marks jest inżynierem uczenia maszynowego i ewangelistą deweloperów w firmie Voxel51, gdzie pomaga zapewnić przejrzystość i przejrzystość danych na całym świecie. Przed dołączeniem do Voxel51 Jacob założył startup, który pomaga początkującym muzykom łączyć się i dzielić kreatywnymi treściami z fanami. Wcześniej pracował w Google X, Samsung Research i Wolfram Research. W poprzednim życiu Jacob był fizykiem teoretykiem, który zrobił doktorat na Uniwersytecie Stanforda, gdzie badał kwantowe fazy materii. W wolnym czasie Jacob lubi się wspinać, biegać i czytać powieści science fiction.
Jasona Corso jest współzałożycielem i dyrektorem generalnym firmy Voxel51, w której kieruje strategią mającą na celu zapewnienie przejrzystości i przejrzystości światowych danych za pomocą najnowocześniejszego elastycznego oprogramowania. Jest także profesorem robotyki, elektrotechniki i informatyki na Uniwersytecie Michigan, gdzie koncentruje się na najnowocześniejszych problemach na styku widzenia komputerowego, języka naturalnego i platform fizycznych. W wolnym czasie Jason lubi spędzać czas z rodziną, czytać, przebywać na łonie natury, grać w gry planszowe i wszelkiego rodzaju kreatywne zajęcia.
Brian Moore jest współzałożycielem i CTO Voxel51, gdzie kieruje strategią techniczną i wizją. Posiada doktorat z elektrotechniki na Uniwersytecie Michigan, gdzie jego badania koncentrowały się na wydajnych algorytmach dla wielkoskalowych problemów uczenia maszynowego, ze szczególnym uwzględnieniem komputerowych aplikacji wizyjnych. W wolnym czasie lubi badmintona, golfa, piesze wędrówki i zabawy ze swoimi bliźniaczymi Yorkshire Terrierami.
Zhuling Bai jest inżynierem rozwoju oprogramowania w Amazon Web Services. Zajmuje się tworzeniem wielkoskalowych systemów rozproszonych do rozwiązywania problemów związanych z uczeniem maszynowym.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- O nas
- przyśpieszyć
- przyspieszenie
- akcelerator
- dostęp
- dokładny
- dokładnie
- nabyty
- zajęcia
- Dodaj
- dodanie
- adres
- Skorygowana
- Regulacja
- Po
- ponownie
- AI
- Alexa
- Algorytmy
- Wszystkie kategorie
- pozwala
- sam
- już
- również
- Amazonka
- amazon alexa
- Amazon Sage Maker
- Amazon SageMaker Ground Prawda
- Amazon Web Services
- wśród
- an
- w czasie rzeczywistym sprawiają,
- i
- zwierzę
- każdy
- Aplikacja
- Zastosowanie
- aplikacje
- Aplikuj
- właściwy
- SĄ
- ułożone
- artykuł
- towary
- AS
- powiązany
- At
- Autorzy
- z dala
- AWS
- baza
- na podstawie
- BE
- bo
- stają się
- być
- zanim
- za
- za kulisami
- jest
- uwierzyć
- BEST
- Ulepsz Swój
- pomiędzy
- Miliard
- deska
- Gry planszowe
- KOŚĆ
- Bootstrap
- obie
- Pudełko
- Skrzynki
- Mózg
- przerwa
- przynieść
- przyniósł
- budżet
- budować
- Budowanie
- wbudowany
- ale
- kupować
- by
- CAN
- Przechwytywanie
- walizka
- Etui
- kategorie
- Kategoria
- ceo
- wyzwanie
- wyzwanie
- ZOBACZ
- Dodaj
- klarowność
- klasa
- Klasy
- klasyfikacja
- Sprzątanie
- jasny
- wyraźnie
- klient
- Wspinaczka
- Zamknij
- bliższy
- ubranie
- Odzież
- Współzałożyciel
- kod
- połączyć
- łączenie
- sukcesy firma
- Komplement
- kompletny
- wypełniając
- obliczać
- komputer
- Computer Science
- Wizja komputerowa
- Aplikacje do widzenia komputerowego
- pewność siebie
- pewność
- Skontaktuj się
- wynagrodzenie
- Składający się
- Konsola
- zawiera
- zawartość
- treść
- kontrolowanych
- konwersacyjny
- konwertować
- kopie
- rdzeń
- poprawione
- odpowiada
- Koszty:
- Koszty:
- Stwórz
- stworzony
- Twórczy
- Listy uwierzytelniające
- CTO
- kurator
- kurator
- Obecnie
- zwyczaj
- klient
- Klientów
- Ciąć
- pionierski nowatorski
- dane
- zbiory danych
- zdecydować
- wykazać
- Denim
- głębokość
- opis
- detale
- Wykrywanie
- Deweloper
- rozwijanie
- oprogramowania
- różne
- bezpośrednio
- katalogi
- Wyświetlacz
- odrębny
- dystrybuowane
- systemy rozproszone
- inny
- do
- Nie
- Pies
- robi
- zrobić
- nie
- DOT
- na dół
- pobieranie
- duplikaty
- e
- każdy
- łatwo
- krawędź
- efekt
- wydajny
- skutecznie
- Inżynieria elektryczna
- osadzanie
- wschodzących
- nacisk
- zatrudnia
- upoważnia
- obudowane
- zachęcać
- zakończenia
- inżynier
- Inżynieria
- Inżynierowie
- Wchodzę
- Środowisko
- Równość
- niezbędny
- ustanowiony
- Eter (ETH)
- oceny
- Ewangelista
- dokładnie
- przykład
- Przede wszystkim system został opracowany
- eksport
- dość
- członków Twojej rodziny
- Fani
- informacja zwrotna
- kilka
- Fikcja
- pole
- Łąka
- filet
- Akta
- filtrować
- filtracja
- finał
- i terminów, a
- dopasować
- elastyczne
- Skupiać
- koncentruje
- koncentruje
- następujący
- W razie zamówieenia projektu
- Nasz formularz
- format
- na szczęście
- Założony
- cztery
- Darmowy
- od
- w pełni
- Funkcjonalność
- Games
- ogólny cel
- Generować
- wygenerowane
- otrzymać
- GitHub
- Dać
- dany
- cel
- golf
- dobry
- większy
- Krata
- Ziemia
- Zarządzanie
- poprowadzi
- Zaoszczędzić
- Have
- he
- głowa
- wysokość
- pomoc
- pomógł
- pomocny
- pomaga
- tutaj
- wysokiej jakości
- wysoka rozdzielczość
- Najwyższa
- wysoko
- turystyka
- jego
- posiada
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- człowiek
- i
- IAM
- ID
- zidentyfikować
- identyfikacja
- ids
- if
- obraz
- zdjęcia
- Rezultat
- importować
- poprawy
- in
- W innych
- Włącznie z
- niepoprawnie
- inkubowane
- Informacja
- początkowy
- początkowo
- zainstalować
- Instalacja
- przykład
- zamiast
- instrukcje
- Inteligencja
- skrzyżowanie
- najnowszych
- IT
- JEGO
- Golf
- Praca
- łączący
- połączenie
- json
- właśnie
- Trzymać
- konserwacja
- Etykieta
- etykietowanie
- Etykiety
- język
- na dużą skalę
- uruchomić
- wodowanie
- prowadzić
- Wyprowadzenia
- UCZYĆ SIĘ
- nauka
- najmniej
- Doprowadziło
- lewo
- pozwala
- Biblioteka
- życie
- lubić
- Prawdopodobnie
- LIMIT
- Ograniczony
- Linia
- linie
- Lista
- wymienianie kolejno
- ofert
- mało
- Zyje
- załadować
- Popatrz
- poszukuje
- Partia
- niski
- maszyna
- uczenie maszynowe
- zrobiony
- magia
- robić
- WYKONUJE
- zarządzanie
- zarządzane
- i konserwacjami
- kierownik
- wiele
- mapa
- rynek
- Marketing
- Mecz
- dopasowywanie
- materialnie
- Materia
- Może..
- mechaniczny
- Media
- Spotkania
- Meta
- Metadane
- metoda
- metody
- Michigan
- Microsoft
- zespoły Microsoft
- może
- minimum
- ML
- Aplikacje mobilne
- Aplikacja mobilna
- model
- modele
- Moduły
- jeszcze
- większość
- ruch
- dużo
- wielokrotność
- muzycy
- musi
- Nazwa
- O imieniu
- Nazwy
- Naturalny
- Język naturalny
- Natura
- Blisko
- koniecznie
- niezbędny
- Potrzebować
- wymagania
- Nowości
- zauważalnie
- Pojęcie
- już dziś
- niuans
- numer
- przedmiot
- Wykrywanie obiektów
- obiekty
- of
- urzędnik
- on
- pewnego razu
- ONE
- Online
- tylko
- koncepcja
- open source
- operacje
- Okazja
- Opcje
- or
- Zorganizowany
- oryginalny
- OS
- Inne
- Pozostałe
- ludzkiej,
- na zewnątrz
- opisane
- wydajność
- koniec
- własny
- posiada
- Pakiety
- sparowany
- część
- szczególny
- Przeszłość
- ścieżka
- Wzór
- wzory
- doskonały
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- osoba
- Personalizowany
- Fazy materii
- fizyczny
- wybierać
- Zdjęcia
- PLED
- Równina
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- gra
- punkt
- zaludniony
- możliwy
- Post
- power
- praktyka
- Przewiduje
- przepowiednia
- Przewidywania
- Podgląd
- poprzedni
- poprzednio
- Wcześniejszy
- prywatny
- prawdopodobnie
- problemy
- wygląda tak
- Produkt
- zarządzanie produktem
- product manager
- Produkty
- Profesor
- projekt
- własność
- spodziewany
- prototyp
- zapewniać
- pod warunkiem,
- że
- publiczny
- dziurkacz
- cele
- Python
- Kwant
- pytania
- szybko
- zasięg
- raczej
- Czytający
- gotowy
- polecić
- zalecenia
- zmniejszyć
- Zredukowany
- redukcja
- stosunkowo
- wydany
- usunąć
- przedstawiciel
- reprezentowanie
- wymagany
- Badania naukowe
- Badacze
- Rozkład
- ograniczać
- dalsze
- wynikły
- Efekt
- detaliczny
- powrót
- przeglądu
- Pozbyć się
- robotyka
- krzepki
- Rola
- w przybliżeniu
- RZĄD
- zrujnować
- bieganie
- sagemaker
- Powiedział
- sprzedawca
- taki sam
- Samsung
- Zapisz
- Sceny
- nauka
- Fantastyka naukowa
- Naukowcy
- wynik
- płynnie
- druga
- Sekcja
- działy
- widzieć
- wydać się
- wydaje
- wybrany
- rozsądek
- oddzielny
- usługa
- Usługi
- Sesja
- zestaw
- Share
- ona
- powinien
- pokazać
- Targi
- TAK
- podobny
- Prosty
- mniejszy
- So
- Tworzenie
- rozwoju oprogramowania
- ROZWIĄZANIA
- kilka
- Ktoś
- coś
- Typ przestrzeni
- wydać
- Spędzanie
- dzielić
- Dzieli
- Stanford
- początek
- rozpoczęty
- Startowy
- startup
- akcelerator uruchamiania
- state-of-the-art
- Cel
- Nadal
- przechowywanie
- sklep
- Strategia
- styl
- style
- PODSUMOWANIE
- Utrzymany
- systemy
- Brać
- Zadanie
- Zespoły
- Techniczny
- TechStars
- mówi
- Szablony
- test
- niż
- że
- Połączenia
- ich
- Im
- następnie
- teoretyczny
- Tam.
- Te
- one
- rzeczy
- myśleć
- innych firm
- to
- tysiące
- próg
- Przez
- Rzucanie
- czas
- do
- razem
- narzędzie
- Zestaw narzędzi
- Top
- najwyższy poziom
- Topy
- Kwota produktów:
- wzruszony
- śledzić
- Pociąg
- przeszkolony
- Trening
- Przekształcać
- Przezroczystość
- prawdziwy
- Prawda
- SKRĘCAĆ
- drugiej
- rodzaj
- typy
- dla
- zrozumieć
- wyjątkowy
- uniwersytet
- University of Michigan
- Aktualizacja
- us
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- Wartości
- różnorodność
- różnorodny
- sprzedawców
- zweryfikować
- początku.
- przez
- Zobacz i wysłuchaj
- Wirtualny
- wizja
- chcieć
- była
- we
- sieć
- usługi internetowe
- DOBRZE
- były
- Co
- jeśli chodzi o komunikację i motywację
- czy
- który
- Wikipedia
- będzie
- w
- w ciągu
- bez
- Kobieta
- słowa
- Praca
- pracował
- pracowników
- Siła robocza
- działa
- świat
- martwić się
- by
- napisać
- X
- ty
- Twój
- zefirnet
- Zamek błyskawiczny
- ZOO