W dzisiejszym środowisku biznesowym opartym na danych organizacje stoją przed wyzwaniem skutecznego przygotowania i przekształcenia dużych ilości danych do celów analitycznych i nauki o danych. Firmy muszą budować hurtownie danych i jeziora danych w oparciu o dane operacyjne. Wynika to z potrzeby centralizacji i integracji danych pochodzących z różnych źródeł.
Jednocześnie dane operacyjne często pochodzą z aplikacji wspieranych przez starsze magazyny danych. Modernizacja aplikacji wymaga architektury mikroserwisowej, co z kolei wymaga konsolidacji danych z wielu źródeł w celu zbudowania operacyjnego magazynu danych. Bez modernizacji starsze aplikacje mogą wiązać się z rosnącymi kosztami utrzymania. Modernizacja aplikacji wymaga zmiany podstawowego silnika bazy danych na nowoczesną bazę danych opartą na dokumentach, taką jak MongoDB.
Te dwa zadania (budowanie jezior danych lub hurtowni danych oraz modernizacja aplikacji) obejmują przenoszenie danych, które wykorzystuje proces wyodrębniania, przekształcania i ładowania (ETL). Zadanie ETL jest kluczową funkcjonalnością dla posiadania dobrze ustrukturyzowanego procesu, aby odnieść sukces.
Klej AWS to bezserwerowa usługa integracji danych, która ułatwia odkrywanie, przygotowywanie, przenoszenie i integrowanie danych z wielu źródeł na potrzeby analiz, uczenia maszynowego (ML) i tworzenia aplikacji. Atlas MongoDB to zintegrowany pakiet baz danych i usług danych w chmurze, który łączy przetwarzanie transakcyjne, wyszukiwanie oparte na istotności, analizy w czasie rzeczywistym i synchronizację danych z urządzeń mobilnych do chmury w eleganckiej i zintegrowanej architekturze.
Używając AWS Glue z MongoDB Atlas, organizacje mogą usprawnić swoje procesy ETL. Dzięki w pełni zarządzanemu, skalowalnemu i bezpiecznemu rozwiązaniu bazodanowemu MongoDB Atlas zapewnia elastyczne i niezawodne środowisko do przechowywania danych operacyjnych i zarządzania nimi. Razem AWS Glue ETL i MongoDB Atlas stanowią potężne rozwiązanie dla organizacji, które chcą zoptymalizować sposób budowania jezior danych i hurtowni danych oraz zmodernizować swoje aplikacje w celu poprawy wydajności biznesowej, obniżenia kosztów oraz napędzania wzrostu i sukcesu.
W tym poście pokazujemy, jak przeprowadzić migrację danych z Usługa Amazon Simple Storage (Amazon S3) do Atlasu MongoDB przy użyciu AWS Glue ETL oraz jak wyodrębnić dane z Atlasu MongoDB do jeziora danych opartego na Amazon S3.
Omówienie rozwiązania
W tym poście przyjrzymy się następującym przypadkom użycia:
- Ekstrakcja danych z MongoDB – MongoDB to popularna baza danych używana przez tysiące klientów do przechowywania danych aplikacji na dużą skalę. Klienci korporacyjni mogą centralizować i integrować dane pochodzące z wielu magazynów danych, budując jeziora danych i hurtownie danych. Ten proces obejmuje wyodrębnianie danych z operacyjnych magazynów danych. Gdy dane znajdują się w jednym miejscu, klienci mogą je szybko wykorzystać do potrzeb analizy biznesowej lub uczenia maszynowego.
- Pobieranie danych do MongoDB – MongoDB służy również jako baza danych bez SQL do przechowywania danych aplikacji i budowania magazynów danych operacyjnych. Modernizacja aplikacji często wiąże się z migracją sklepu operacyjnego do MongoDB. Klienci musieliby wyodrębnić istniejące dane z relacyjnych baz danych lub z plików płaskich. Aplikacje mobilne i internetowe często wymagają od inżynierów danych tworzenia potoków danych w celu utworzenia pojedynczego widoku danych w Atlasie podczas pozyskiwania danych z wielu odizolowanych źródeł. Podczas tej migracji musieliby połączyć różne bazy danych, aby utworzyć dokumenty. Ta złożona operacja łączenia wymagałaby znacznej, jednorazowej mocy obliczeniowej. Deweloperzy musieliby to również szybko zbudować, aby przeprowadzić migrację danych.
AWS Glue przydaje się w takich przypadkach dzięki modelowi płatności zgodnie z rzeczywistym użyciem i jego zdolności do przeprowadzania złożonych transformacji w ogromnych zbiorach danych. Programiści mogą używać AWS Glue Studio do wydajnego tworzenia takich potoków danych.
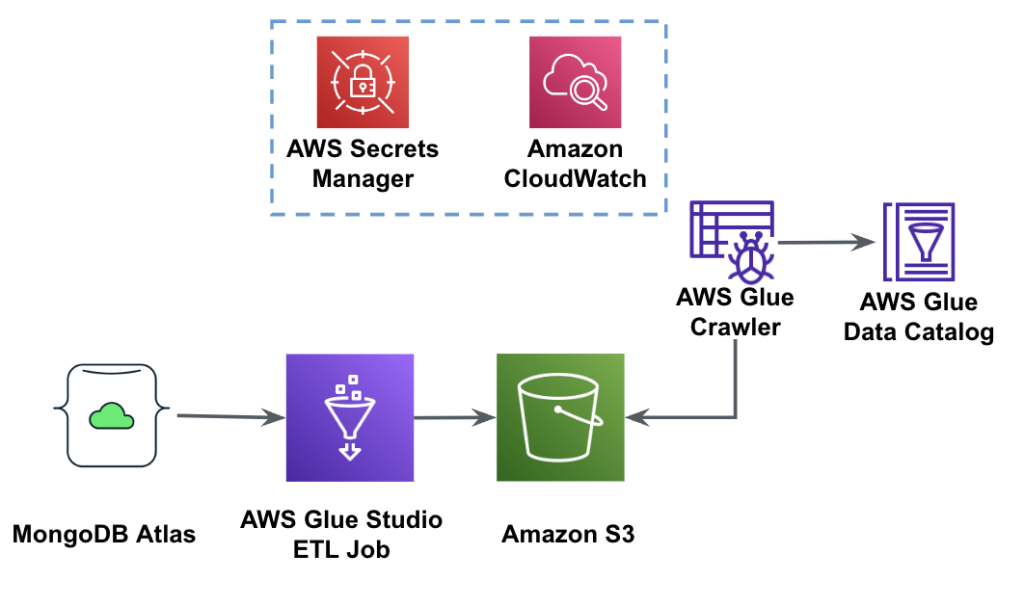
Poniższy diagram przedstawia przepływ pracy ekstrakcji danych z MongoDB Atlas do zasobnika S3 przy użyciu AWS Glue Studio.
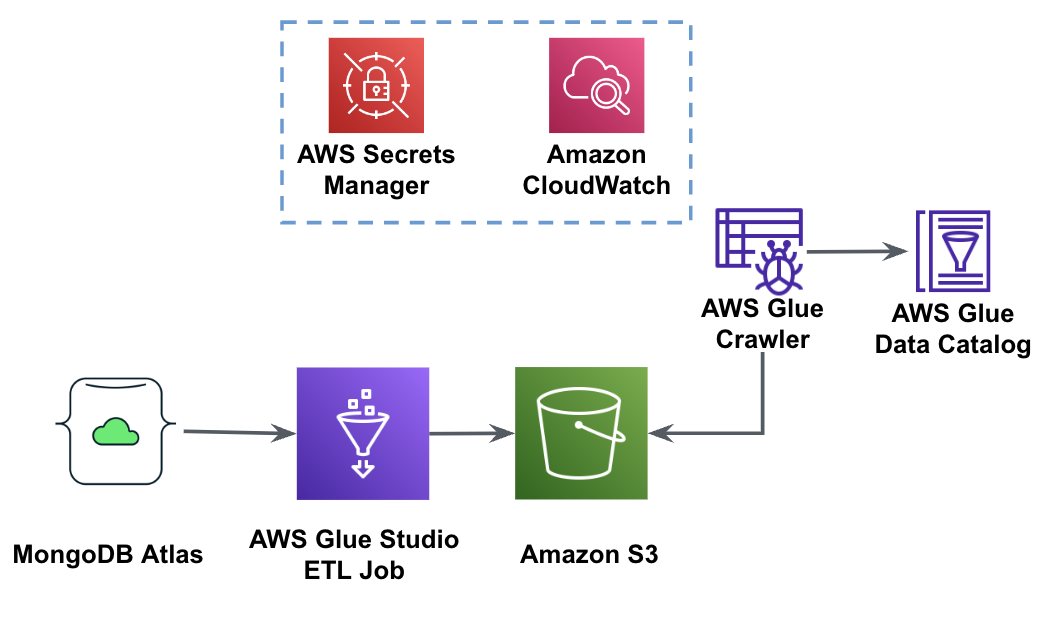
Aby zaimplementować tę architekturę, będziesz potrzebować klastra MongoDB Atlas, wiadra S3 i AWS Zarządzanie tożsamością i dostępem (IAM) rola dla kleju AWS. Aby skonfigurować te zasoby, zapoznaj się z poniższymi krokami dotyczącymi wymagań wstępnych GitHub repo.
Poniższy rysunek przedstawia przepływ pracy ładowania danych z zasobnika S3 do MongoDB Atlas przy użyciu kleju AWS.
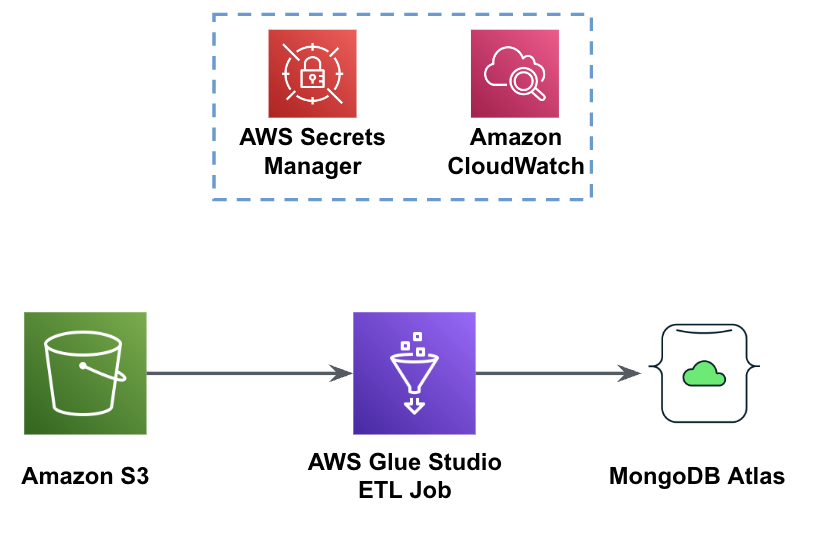
Tutaj potrzebne są te same wymagania wstępne: zasobnik S3, rola IAM i klaster MongoDB Atlas.
Załaduj dane z Amazon S3 do MongoDB Atlas za pomocą AWS Glue
Poniższe kroki opisują sposób ładowania danych z zasobnika S3 do MongoDB Atlas przy użyciu zadania AWS Glue. Proces ekstrakcji z MongoDB Atlas do Amazon S3 jest bardzo podobny, z wyjątkiem używanego skryptu. Zwracamy uwagę na różnice między tymi dwoma procesami.
- Utwórz bezpłatny klaster w atlasie MongoDB.
- Prześlij plik przykładowy plik JSON do Twojego wiadra S3.
- Utwórz nowe zadanie AWS Glue Studio za pomocą Edytor skryptów Spark opcja.

- W zależności od tego, czy chcesz załadować, czy wyodrębnić dane z klastra MongoDB Atlas, wprowadź plik załaduj skrypt or wypakuj skrypt w edytorze skryptów AWS Glue Studio.
Poniższy zrzut ekranu przedstawia fragment kodu służący do ładowania danych do klastra MongoDB Atlas.

Kod używa Menedżer tajemnic AWS aby pobrać nazwę klastra MongoDB Atlas, nazwę użytkownika i hasło. Następnie tworzy DynamicFrame dla zasobnika S3 i nazwa pliku przekazana do skryptu jako parametry. Kod pobiera nazwy bazy danych i kolekcji z konfiguracji parametrów zadania. Na koniec kod zapisuje plik DynamicFrame do klastra MongoDB Atlas przy użyciu pobranych parametrów.
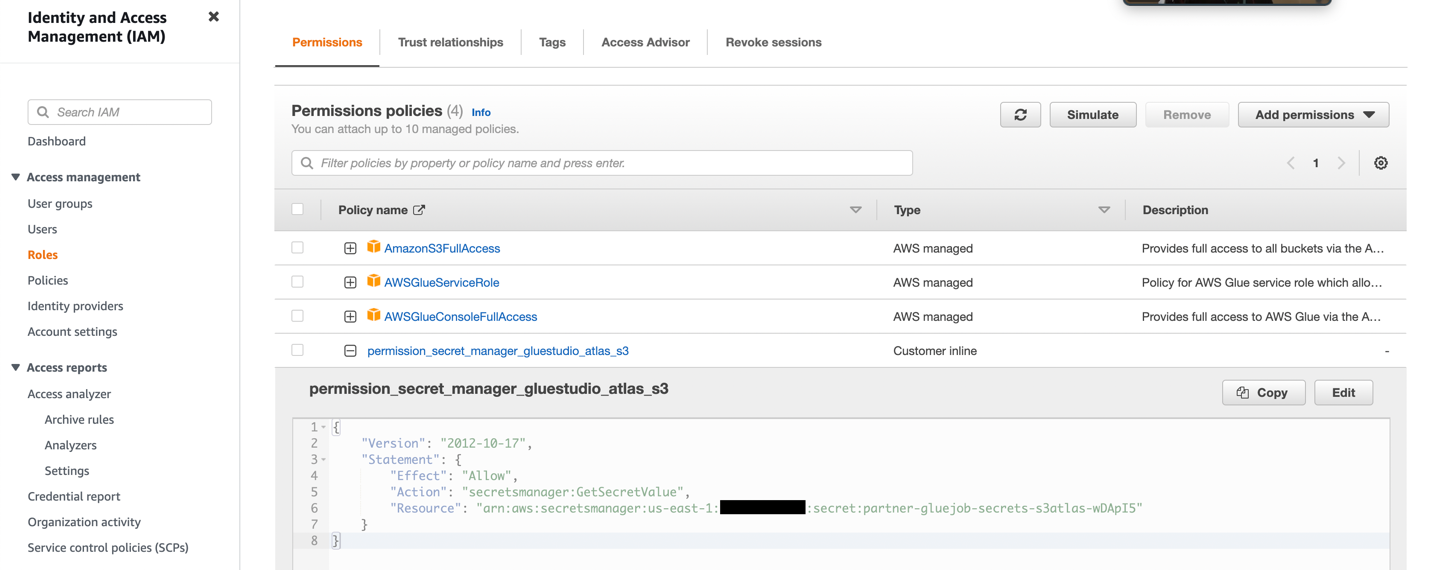
- Utwórz rolę IAM z uprawnieniami pokazanymi na poniższym zrzucie ekranu.
Aby uzyskać więcej informacji, zobacz Skonfiguruj rolę IAM dla zadania ETL.
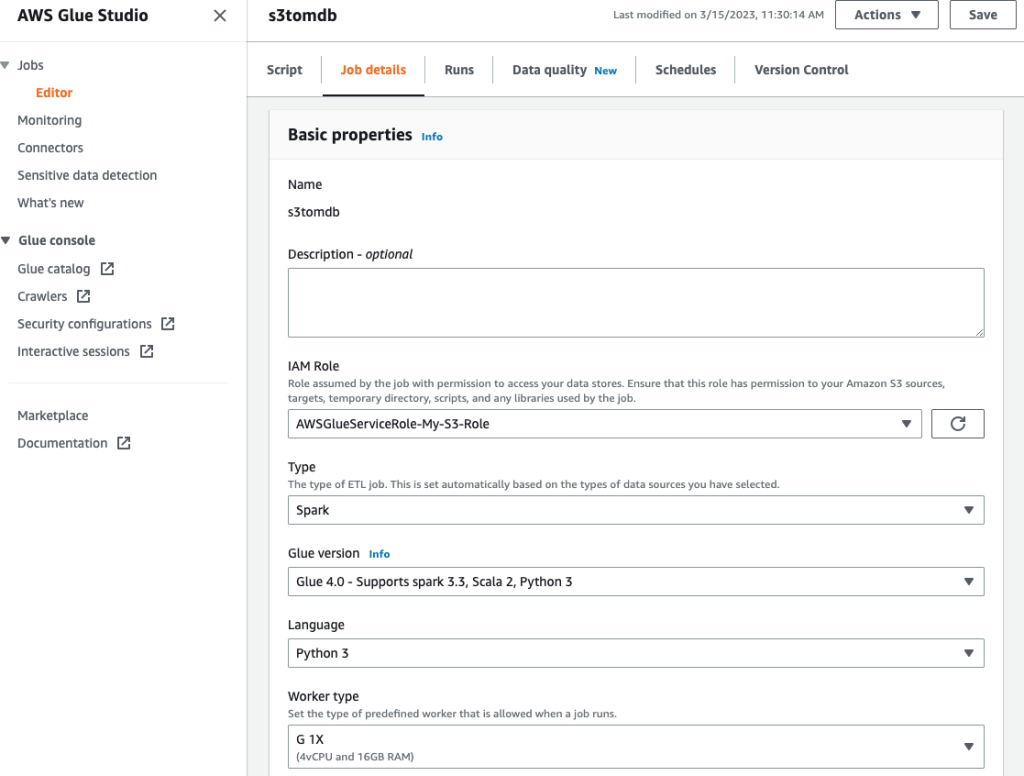
- Nadaj zadaniu nazwę i podaj rolę IAM utworzoną w poprzednim kroku na Szczegóły pracy patka.
- Możesz pozostawić pozostałe parametry jako domyślne, jak pokazano na poniższych zrzutach ekranu.
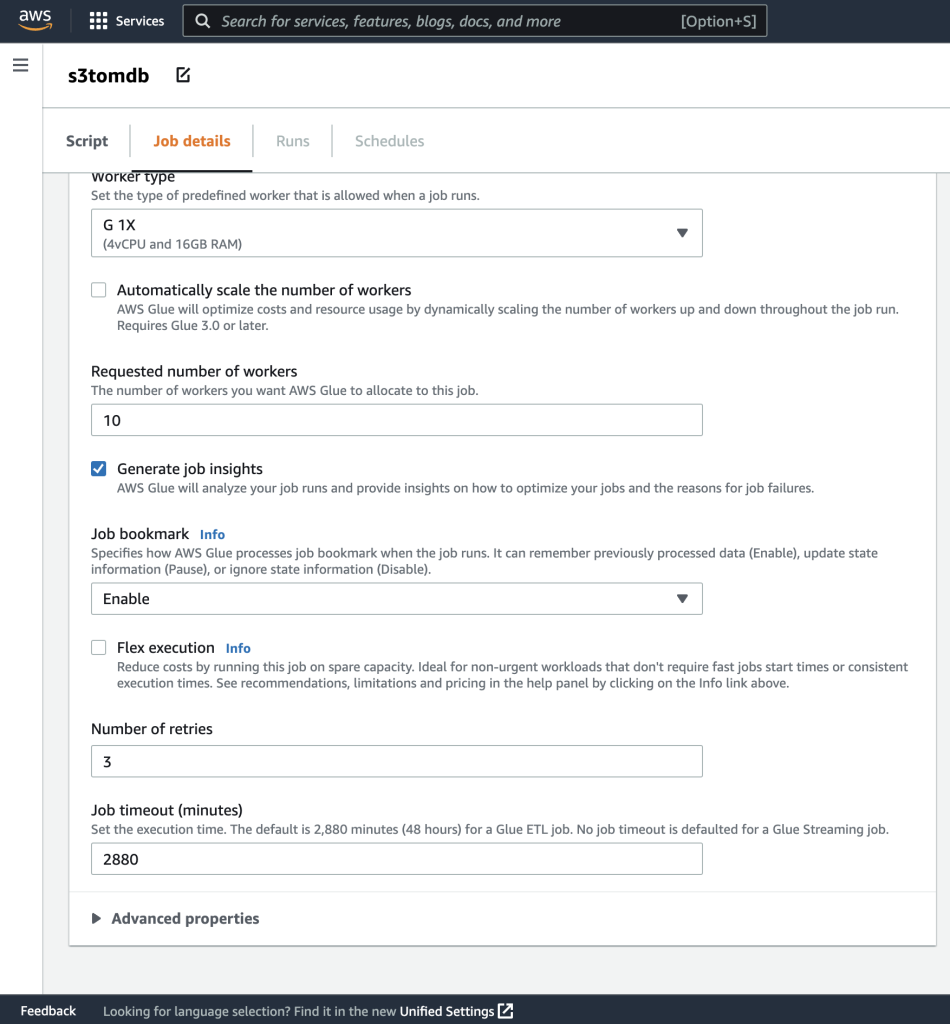
- Następnie zdefiniuj parametry zadania używane przez skrypt i podaj wartości domyślne.
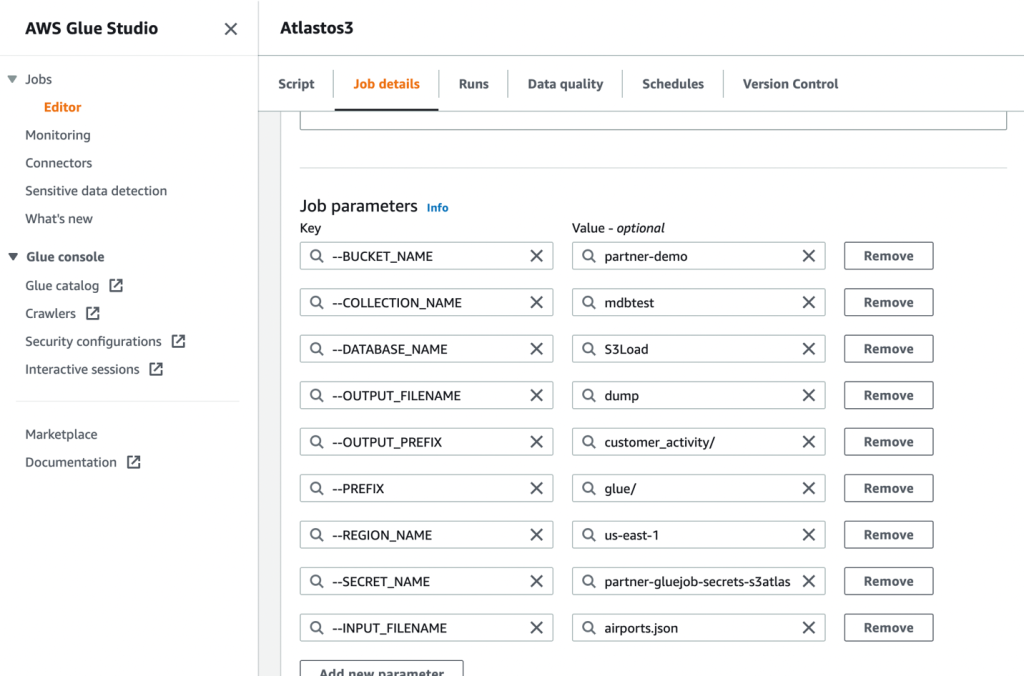
- Zapisz zadanie i uruchom je.
- Aby potwierdzić pomyślne uruchomienie, obserwuj zawartość kolekcji bazy danych MongoDB Atlas w przypadku ładowania danych lub zasobnika S3 w przypadku wykonywania wyodrębniania.



Poniższy zrzut ekranu przedstawia wyniki pomyślnego załadowania danych z zasobnika Amazon S3 do klastra MongoDB Atlas. Dane są teraz dostępne dla zapytań w interfejsie użytkownika MongoDB Atlas.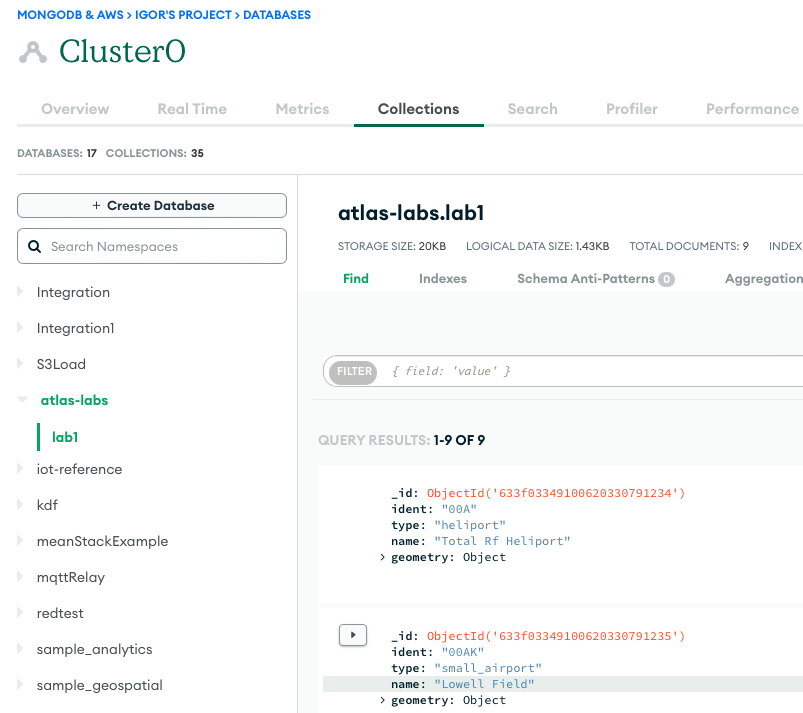
- Aby rozwiązać problemy z przebiegami, przejrzyj Amazon Cloud Watch dzienniki za pomocą łącza w zadaniu run patka.
Poniższy zrzut ekranu pokazuje, że zadanie zostało wykonane pomyślnie, z dodatkowymi szczegółami, takimi jak łącza do dzienników CloudWatch.

Wnioski
W tym poście opisaliśmy, jak wyodrębniać i przetwarzać dane do MongoDB Atlas za pomocą AWS Glue.
Dzięki zadaniom AWS Glue ETL możemy teraz przesyłać dane z Atlasu MongoDB do źródeł kompatybilnych z AWS Glue i odwrotnie. Możesz także rozszerzyć rozwiązanie o analitykę z wykorzystaniem usług AWS AI i ML.
Aby dowiedzieć się więcej, zapoznaj się z Repozytorium GitHub aby uzyskać instrukcje krok po kroku i przykładowy kod. Możesz zaopatrzyć się Atlas MongoDB na rynku AWS.
O autorach

Igor Aleksiejew jest starszym architektem rozwiązań partnerskich w AWS w domenie Data and Analytics. W swojej roli Igor współpracuje ze strategicznymi partnerami, pomagając im budować złożone architektury zoptymalizowane pod kątem AWS. Przed dołączeniem do AWS jako Data/Solution Architect zrealizował wiele projektów w domenie Big Data, w tym kilka jezior danych w ekosystemie Hadoop. Jako Data Engineer był zaangażowany w zastosowanie AI/ML do wykrywania nadużyć i automatyzacji biura.
 Babu Srinivasana jest starszym architektem rozwiązań partnerskich w MongoDB. W swojej obecnej roli współpracuje z AWS przy tworzeniu integracji technicznych i architektur referencyjnych dla rozwiązań AWS i MongoDB. Ma ponad dwudziestoletnie doświadczenie w technologiach baz danych i chmur. Pasjonuje się dostarczaniem rozwiązań technicznych klientom współpracującym z wieloma globalnymi integratorami systemów (GSI) w różnych regionach.
Babu Srinivasana jest starszym architektem rozwiązań partnerskich w MongoDB. W swojej obecnej roli współpracuje z AWS przy tworzeniu integracji technicznych i architektur referencyjnych dla rozwiązań AWS i MongoDB. Ma ponad dwudziestoletnie doświadczenie w technologiach baz danych i chmur. Pasjonuje się dostarczaniem rozwiązań technicznych klientom współpracującym z wieloma globalnymi integratorami systemów (GSI) w różnych regionach.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :ma
- :Jest
- 100
- 11
- a
- zdolność
- O nas
- dostęp
- w poprzek
- Dodatkowy
- AI
- AI / ML
- również
- Amazonka
- kwoty
- an
- analityka
- i
- Zastosowanie
- Application Development
- aplikacje
- Stosowanie
- mobilne i webowe
- architektura
- SĄ
- AS
- At
- atlas
- Automatyzacja
- dostępny
- AWS
- Klej AWS
- Rynek AWS
- poparła
- na podstawie
- jest
- pomiędzy
- Duży
- Big Data
- budować
- Budowanie
- biznes
- business intelligence
- wyniki biznesowe
- biznes
- by
- wezwanie
- CAN
- Etui
- wyzwanie
- wymiana pieniędzy
- Chmura
- Grupa
- kod
- kolekcja
- kombajny
- byliśmy spójni, od początku
- przyjście
- kompleks
- obliczać
- systemu
- Potwierdzać
- konsolidacja
- skonstruować
- treść
- nadal
- Koszty:
- Stwórz
- stworzony
- tworzy
- tworzenie
- Aktualny
- Klientów
- dane
- inżynier danych
- integracja danych
- Jezioro danych
- nauka danych
- magazyn danych
- sterowane danymi
- Baza danych
- Bazy danych
- zbiory danych
- lat
- Domyślnie
- wykazać
- opisać
- opisane
- detale
- Wykrywanie
- deweloperzy
- oprogramowania
- Różnice
- różne
- odkryj
- różny
- dokumenty
- domena
- napęd
- napędzany
- podczas
- Ekosystem
- redaktor
- skutecznie
- silnik
- inżynier
- Inżynierowie
- Wchodzę
- Enterprise
- klienci korporacyjni
- Środowisko
- Eter (ETH)
- wyjątek
- Przede wszystkim system został opracowany
- doświadczenie
- odkryj
- rozciągać się
- wyciąg
- ekstrakcja
- Twarz
- Postać
- filet
- Akta
- W końcu
- mieszkanie
- elastyczne
- następujący
- W razie zamówieenia projektu
- oszustwo
- wykrywanie oszustw
- Darmowy
- od
- w pełni
- Funkcjonalność
- geografie
- Globalne
- Wzrost
- Hadoop
- poręczny
- mający
- he
- pomoc
- tutaj
- jego
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- olbrzymi
- IAM
- tożsamość
- if
- wdrożenia
- realizowane
- podnieść
- in
- Włącznie z
- wzrastający
- wkład
- instrukcje
- integrować
- zintegrowany
- integracja
- integracje
- Inteligencja
- najnowszych
- angażować
- zaangażowany
- IT
- JEGO
- Praca
- Oferty pracy
- przystąpić
- łączący
- json
- Klawisz
- jezioro
- duży
- UCZYĆ SIĘ
- nauka
- Pozostawiać
- Dziedzictwo
- lubić
- LINK
- linki
- załadować
- załadunek
- poszukuje
- maszyna
- uczenie maszynowe
- konserwacja
- WYKONUJE
- zarządzane
- zarządzający
- wiele
- rynek
- Może..
- migrować
- migracja
- ML
- Aplikacje mobilne
- model
- Nowoczesne technologie
- modernizacja
- zmodernizować
- MongoDB
- jeszcze
- ruch
- ruch
- wielokrotność
- Nazwa
- Nazwy
- Potrzebować
- potrzebne
- wymagania
- Nowości
- już dziś
- obserwować
- of
- Biurowe
- często
- on
- ONE
- działanie
- operacyjny
- Optymalizacja
- Option
- or
- zamówienie
- organizacji
- na zewnątrz
- parametry
- partnerem
- wzmacniacz
- minęło
- namiętny
- Hasło
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- uprawnienia
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- Popularny
- Post
- power
- mocny
- Przygotować
- przygotowanie
- warunki wstępne
- poprzedni
- Wcześniejszy
- wygląda tak
- procesów
- przetwarzanie
- projektowanie
- zapewnia
- że
- cele
- zapytania
- szybko
- w czasie rzeczywistym
- zmniejszyć
- rzetelny
- wymagać
- Wymaga
- Zasoby
- REST
- Efekt
- przeglądu
- Rola
- run
- taki sam
- skalowalny
- Skala
- nauka
- screeny
- Szukaj
- bezpieczne
- senior
- Bezserwerowe
- służy
- usługa
- Usługi
- kilka
- pokazane
- Targi
- znaczący
- podobny
- Prosty
- pojedynczy
- rozwiązanie
- Rozwiązania
- Źródła
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- sklep
- bezpośredni
- Strategiczny
- Partnerzy strategiczni
- opływowy
- studio
- osiągnąć sukces
- sukces
- udany
- Z powodzeniem
- taki
- apartament
- Dostawa
- synchronizacja
- system
- zadania
- Techniczny
- Technologies
- niż
- że
- Połączenia
- ich
- Im
- następnie
- Te
- one
- to
- tysiące
- czas
- do
- dzisiaj
- razem
- transakcyjny
- przenieść
- Przekształcać
- przemiany
- transformatorowy
- SKRĘCAĆ
- drugiej
- ui
- zasadniczy
- posługiwać się
- używany
- Użytkownik
- za pomocą
- Wartości
- początku.
- Zobacz i wysłuchaj
- chcieć
- była
- we
- sieć
- były
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- będzie
- w
- bez
- workflow
- pracujący
- by
- ty
- Twój
- zefirnet