ChatGPT nie zdał egzaminów American College of Gastroenterology i nie jest w stanie generować dokładnych informacji medycznych dla pacjentów, ostrzegają lekarze.
A study led by physicians at the Feinstein Institutes for Medical Research tested both variants of ChatGPT – powered by OpenAI's older GPT-3.5 model and the latest GPT-4 system. The academic team copy and pasted the multiple choice questions taken from the 2021 and 2022 American College of Gastroenterology (ACG) Self-Assessment Tests into the bot, and analyzed the software's responses.
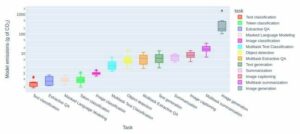
Co ciekawe, mniej zaawansowana wersja oparta na GPT-3.5 odpowiedziała poprawnie na 65.1 procent z 455 pytań, podczas gdy mocniejsza wersja GPT-4 uzyskała wynik 62.4 procent. Trudno wyjaśnić, jak to się stało, ponieważ OpenAI ukrywa sposób, w jaki trenuje swoje modele. Jego rzecznicy powiedzieli nam, że przynajmniej oba modele zostały przeszkolone na danych datowanych na wrzesień 2021 r.
W każdym razie żaden wynik nie był na tyle dobry, aby osiągnąć próg 70 procent, aby zdać egzaminy.
Arvind Trindade, profesor nadzwyczajny w The Feinstein Institutes for Medical Research i główny autor badania opublikowany American Journal of Gastroenterology, powiedziała Rejestr.
"Although the score is not far away from passing or obtaining a 70 percent, I would argue that for medical advice or medical education, the score should be over 95."
"I don't think a patient would be comfortable with a doctor that only knows 70 percent of his or her medical field. If we demand this high standard for our doctors, we should demand this high standard from medical chatbots," he added.
American College of Gastroenterology szkoli lekarzy, a jego testy są wykorzystywane jako praktyka przed oficjalnymi egzaminami. Aby zostać certyfikowanym gastroenterologiem, lekarze muszą zdać egzamin Gastroenterologii Amerykańskiej Rady Chorób Wewnętrznych. To wymaga wiedzy i nauki – nie tylko przeczucia.
ChatGPT generates responses by predicting the next word in a given sentence. AI learns common patterns in its training data to figure out what word should go next, and is partially effective at recalling information. Although the technology has improved rapidly, it's not perfect and is often prone to hallucinating false facts – especially if it's being quizzed on niche subjects that may not be present in its training data.
"ChatGPT's basic function is to predict the next word in a string of text to produce an expected response based on available information, regardless of whether such a response is factually correct or not. It does not have any intrinsic understanding of a topic or issue," the paper explains.
Trindade told us that it's possible that the gastroenterology-related information on webpages used to train the software is not accurate, and that the best resources like medical journals or databases should be used.
Zasoby te nie są jednak łatwo dostępne i można je ukryć za zaporami płatniczymi. W takim przypadku ChatGPT mogło nie być wystarczająco narażone na wiedzę ekspercką.
"The results are only applicable to ChatGPT – other chatbots need to be validated. The crux of the issue is where these chatbots are obtaining the information. In its current form ChatGPT should not be used for medical advice or medical education," Trindade concluded. ®
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://go.theregister.com/feed/www.theregister.com/2023/05/24/chatgpt_gastroenterology_exams/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 2021
- 2022
- 70
- a
- O nas
- akademicki
- dokładny
- w dodatku
- zaawansowany
- Rada
- AI
- Chociaż
- amerykański
- an
- i
- każdy
- odpowiedni
- SĄ
- argumentować
- AS
- Współpracownik
- At
- autor
- dostępny
- z dala
- na podstawie
- podstawowy
- BE
- stają się
- być
- za
- jest
- BEST
- deska
- Bot
- obie
- by
- CAN
- zdolny
- walizka
- nasze chatboty
- ChatGPT
- wybór
- CO
- Studentki
- wygodny
- wspólny
- zawarta
- skorygowania
- nie mogłem
- Aktualny
- dane
- Bazy danych
- przestarzały
- Kreowanie
- Lekarz
- Lekarze
- robi
- darowizna
- Edukacja
- Efektywne
- dość
- szczególnie
- Eter (ETH)
- spodziewany
- ekspert
- Wyjaśniać
- Objaśnia
- narażony
- fakty
- Failed
- fałszywy
- daleko
- pole
- Postać
- W razie zamówieenia projektu
- Nasz formularz
- od
- funkcjonować
- generuje
- generujący
- dany
- Go
- dobry
- się
- Ciężko
- Have
- he
- jej
- Wysoki
- jego
- W jaki sposób
- Jednak
- HTTPS
- i
- if
- ulepszony
- in
- Informacja
- wewnętrzny
- najnowszych
- wewnętrzny
- problem
- IT
- JEGO
- dziennik
- jpg
- właśnie
- wiedza
- firmy
- najmniej
- Doprowadziło
- mniej
- lubić
- zamknięty
- Może..
- medyczny
- badania medyczne
- lekarstwo
- model
- modele
- jeszcze
- wielokrotność
- Potrzebować
- Ani
- Następny
- uzyskiwanie
- of
- urzędnik
- często
- on
- tylko
- OpenAI
- or
- Inne
- ludzkiej,
- na zewnątrz
- koniec
- Papier
- przechodzić
- Przechodzący
- pacjent
- pacjenci
- wzory
- procent
- doskonały
- plato
- Analiza danych Platona
- PlatoDane
- możliwy
- powered
- mocny
- praktyka
- przewidzieć
- przewidywanie
- teraźniejszość
- produkować
- Profesor
- pytania
- szybko
- dosięgnąć
- niedawny
- Bez względu
- Badania naukowe
- Zasoby
- odpowiedź
- Odpowiedzi
- dalsze
- Efekt
- s
- wynik
- senior
- wyrok
- wrzesień
- powinien
- Tworzenie
- standard
- sznur
- Badanie
- taki
- system
- Zadania
- trwa
- zespół
- Technologia
- Testy
- że
- Połączenia
- Informacje
- Te
- myśleć
- to
- próg
- do
- aktualny
- Pociąg
- przeszkolony
- Trening
- pociągi
- zrozumienie
- us
- używany
- zatwierdzony
- wersja
- była
- Droga..
- we
- były
- Co
- czy
- Podczas
- w
- słowo
- by
- zefirnet