Witamy w erze danych. Sama ilość rejestrowanych codziennie danych stale rośnie, co wymaga ewolucji platform i rozwiązań. Usługi takie jak Usługa Amazon Simple Storage (Amazon S3) oferują skalowalne rozwiązanie, które dostosowuje się, ale pozostaje opłacalne dla rosnących zbiorów danych. The Inicjatywa danych dotyczących zrównoważonego rozwoju firmy Amazon (ASDI) wykorzystuje możliwości Amazon S3, aby zapewnić bezpłatne rozwiązanie do przechowywania i udostępniania obciążeń związanych z klimatologią na całym świecie. Program sponsorowania otwartych danych firmy Amazon umożliwia organizacjom bezpłatne hostowanie w AWS.
W ciągu ostatniej dekady byliśmy świadkami gwałtownego rozwoju platform nauki o danych, wraz z masową adopcją przez społeczność zajmującą się nauką o danych. Jednym z takich ram jest Deska rozdzielcza, która jest potężna ze względu na możliwość udostępniania orkiestracji roboczych węzłów obliczeniowych, przyspieszając w ten sposób złożoną analizę dużych zestawów danych.
W tym poście pokazujemy, jak wdrożyć plik custom Zestaw programistyczny AWS Cloud (AWS CDK), które rozszerza funkcjonalność Dask o pracę międzyregionalną w globalnej sieci Amazon. Rozwiązanie AWS CDK wdraża sieć pracowników Dask w dwóch regionach AWS, łącząc się z regionem klienta. Aby uzyskać więcej informacji, patrz Wskazówki dotyczące przetwarzania rozproszonego z międzyregionalnym Dask w AWS oraz GitHub repo dla otwartego kodu źródłowego.
Po wdrożeniu użytkownik będzie miał dostęp do notatnika Jupyter, w którym będzie mógł wchodzić w interakcje z dwoma zestawami danych z ASDI na AWS: Projekt wzajemnego porównania modeli sprzężonych 6 (CMIP6) i Ponowna analiza ECMWF ERA5. CMIP6 koncentruje się na szóstej fazie globalnego zespołu modeli ogólnej cyrkulacji sprzężonej oceanu z atmosferą; ERA5 to piąta generacja ponownych analiz atmosferycznych globalnego klimatu ECMWF i pierwsza ponowna analiza wykonana jako usługa operacyjna.
Inspiracją do tego rozwiązania była praca z kluczowym klientem AWS, firmą UK Met Office. Met Office zostało założone w 1854 roku i jest narodową służbą meteorologiczną Wielkiej Brytanii. Zapewniają prognozy pogody i klimatu, aby pomóc Ci podejmować lepsze decyzje, aby zachować bezpieczeństwo i rozwijać się. Współpraca między Met Office i EUMETSAT, szczegółowo opisana w Bezpośrednie obliczenia danych w klastrze Dask rozproszonym między centrami danych, podkreśla rosnącą potrzebę opracowania trwałego, wydajnego i skalowalnego rozwiązania do analizy danych. To rozwiązanie osiąga ten cel, przybliżając moc obliczeniową do danych, zamiast zmuszać dane do zbliżania się do zasobów obliczeniowych, co zwiększa koszty, opóźnienia i energię.
Omówienie rozwiązania
Każdego dnia brytyjskie biuro meteorologiczne generuje do 300 TB danych pogodowych i klimatycznych, z których część jest publikowana w ASDI. Te zbiory danych są dystrybuowane na całym świecie i hostowane do użytku publicznego. Met Office pragnie umożliwić konsumentom lepsze wykorzystanie swoich danych, aby pomóc w podejmowaniu kluczowych decyzji dotyczących rozwiązywania problemów, takich jak lepsze przygotowanie na pożary lasów i powodzie wywołane zmianami klimatycznymi oraz zmniejszenie braku bezpieczeństwa żywnościowego poprzez lepszą analizę plonów.
Tradycyjne rozwiązania stosowane obecnie, zwłaszcza w przypadku danych klimatycznych, są czasochłonne i niezrównoważone, ponieważ replikują zestawy danych między regionami. Zbędny transfer danych w skali petabajtów jest kosztowny, powolny i zużywa energię.
Oszacowaliśmy, że gdyby użytkownicy Met Office przyjęli tę praktykę, każdego dnia można by zaoszczędzić równowartość dziennego zużycia energii przez 40 gospodarstw domowych, a także ograniczyć przesyłanie danych między regionami.
Poniższy schemat ilustruje architekturę rozwiązania.
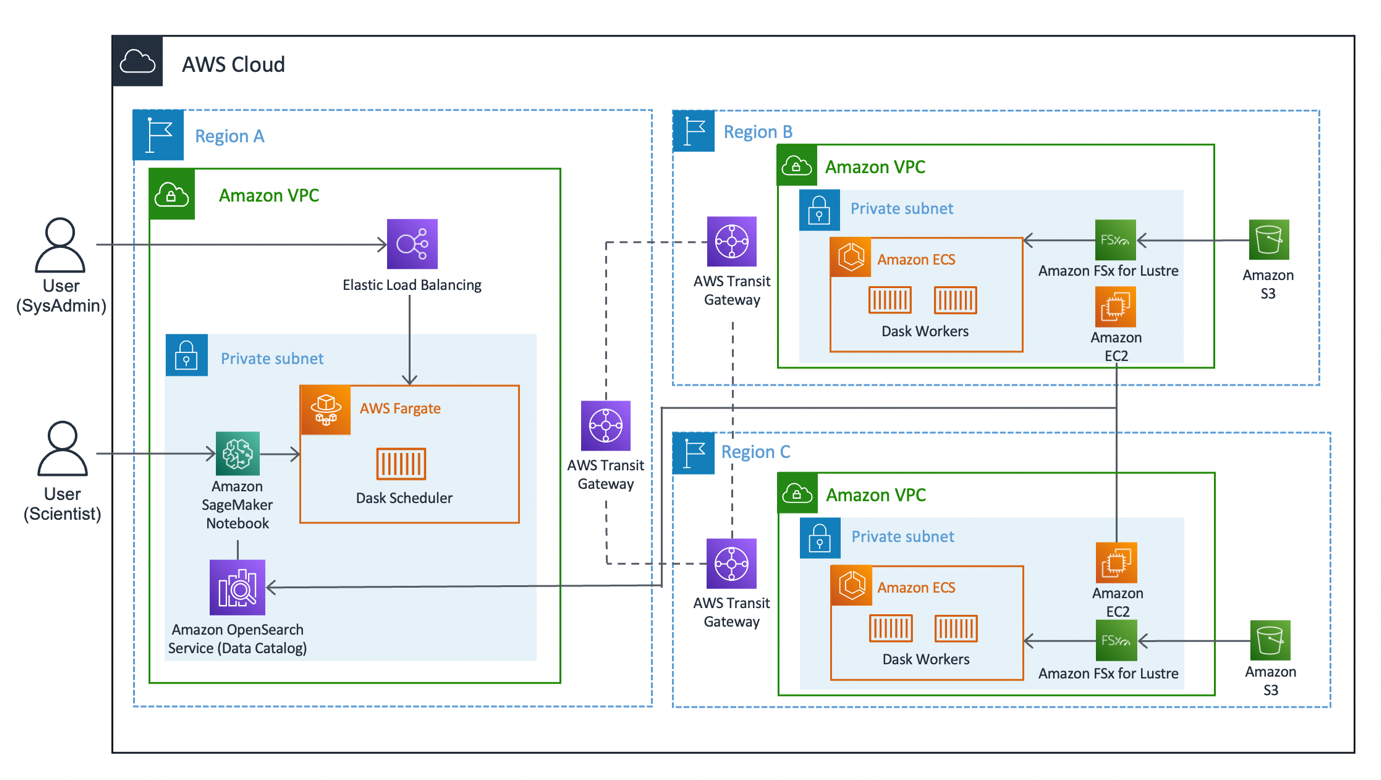
Rozwiązanie można podzielić na trzy główne segmenty: klient, pracownicy i sieć. Zanurzmy się w każdym z nich i zobaczmy, jak się łączą.
klientem
Klient reprezentuje region źródłowy, z którym łączą się naukowcy zajmujący się danymi. Ten region (region A na diagramie) zawiera Notatnik Amazon SageMaker, Usługa Amazon OpenSearch domena i a Harmonogram dnia jako kluczowe komponenty. Administratorzy systemu mają dostęp do wbudowanego pulpitu nawigacyjnego Dask udostępnianego za pośrednictwem Elastyczny moduł równoważenia obciążenia.
Analitycy danych mają dostęp do notatnika Jupyter hostowanego w SageMaker. Notebook może łączyć się i uruchamiać obciążenia w harmonogramie Dask. Domena usługi OpenSearch przechowuje metadane w zestawach danych połączonych w regionach. Użytkownicy notebooków mogą wysyłać zapytania do tej usługi, aby uzyskać szczegółowe informacje, takie jak właściwy region pracowników Dask, bez konieczności wcześniejszej znajomości regionalnej lokalizacji danych.
Pracownik
Każdy z regionów roboczych (regiony B i C na diagramie) składa się z jednego Usługa Amazon Elastic Container Service (Amazon ECS) klaster Pracownicy Daska, Amazon FSx dla Luster system plików i autonomiczny Elastyczna chmura obliczeniowa Amazon (Amazon EC2). FSx for Luster umożliwia pracownikom Dask dostęp i przetwarzanie danych Amazon S3 z systemu plików o wysokiej wydajności poprzez połączenie systemów plików z segmentami S3. Zapewnia opóźnienia poniżej milisekundy, przepustowość do setek GB/s i miliony IOPS. Kluczową cechą Luster jest to, że synchronizowane są tylko metadane systemu plików. Luster zarządza równowagą plików, które mają być ładowane i utrzymywane w cieple, w zależności od zapotrzebowania.
Klastry procesów roboczych skalują się na podstawie użycia procesora, dostarczają dodatkowych pracowników w dłuższych okresach zapotrzebowania i skalują się w dół, gdy zasoby stają się bezczynne.
Każdej nocy o godzinie 0:00 UTC zadanie synchronizacji danych monituje system plików Luster o ponowną synchronizację z dołączonym zasobnikiem S3 i pobiera aktualny katalog metadanych zasobnika. Następnie samodzielna instancja EC2 wypycha te aktualizacje do usługi OpenSearch odpowiednio do indeksu tego regionu. Usługa OpenSearch dostarcza klientowi niezbędnych informacji o tym, która pula pracowników powinna zostać wezwana w celu uzyskania określonego zestawu danych.
Sieć
Sieć stanowi sedno tego rozwiązania, wykorzystując wewnętrzną sieć szkieletową Amazon. Używając Bramka tranzytowa AWS, jesteśmy w stanie połączyć każdy z regionów ze sobą bez konieczności przemierzania publicznego Internetu. Każdy z pracowników może dynamicznie łączyć się z harmonogramem Dask, umożliwiając analitykom danych uruchamianie zapytań międzyregionalnych za pośrednictwem Dask.
Wymagania wstępne
Pakiet AWS CDK wykorzystuje język programowania TypeScript. Postępuj zgodnie z instrukcjami w Wprowadzenie do AWS CDK aby skonfigurować środowisko lokalne i uruchomić konto deweloperskie (musisz uruchomić wszystkie regiony określone w GitHub repo).
Do pomyślnego wdrożenia będziesz potrzebować Zainstalowano Docker i działa na twojej lokalnej maszynie.
Wdróż pakiet AWS CDK
Wdrażanie pakietu AWS CDK jest proste. Po zainstalowaniu wymagań wstępnych i uruchomieniu konta możesz przystąpić do pobierania bazy kodu.
- Pobierz Repozytorium GitHub:
- Zainstaluj moduły węzłów:
- Wdróż CDK AWS:
Wdrożenie stosu może zająć ponad półtorej godziny.
Przewodnik po kodzie
W tej sekcji przyjrzymy się niektórym kluczowym cechom bazy kodu. Jeśli chcesz sprawdzić pełną bazę kodu, zapoznaj się z Repozytorium GitHub.
Skonfiguruj i dostosuj swój stos
W pliku bin/zmienne.ts, znajdziesz dwie deklaracje zmiennych: jedną dla klienta i jedną dla pracowników. Deklaracja klienta jest słownikiem z odniesieniem do regionu i zakresu CIDR. Dostosowanie tych zmiennych spowoduje zmianę zarówno regionu, jak i zakresu CIDR, w którym zostaną wdrożone zasoby klienta.
Zmienna worker kopiuje tę samą funkcjonalność; jest to jednak lista słowników umożliwiająca dodawanie lub odejmowanie zestawów danych, które użytkownik chce uwzględnić. Dodatkowo każdy słownik zawiera dodane pola dataset i lustreFileSystemPath. Zestaw danych służy do określania identyfikatora URI łączenia S3, z którym Luster ma się łączyć. The lustreFileSystemPath zmienna jest używana jako mapowanie sposobu, w jaki użytkownik chce, aby ten zestaw danych był mapowany lokalnie w roboczym systemie plików. Zobacz następujący kod:
Dynamicznie publikuj adres IP programu planującego
Wyzwaniem związanym z ponadregionalnym charakterem tego projektu było utrzymanie dynamicznego połączenia między pracownikami Dask a planistą. Jak moglibyśmy opublikować adres IP, który może się zmieniać w różnych regionach AWS? Udało nam się to osiągnąć za pomocą tzw Mapa chmury AWS i skojarz-vpc-ze-strefą-hostowaną. Abstrakcje usług umożliwiające AWS prywatne zarządzanie tą przestrzenią nazw DNS. Zobacz następujący kod:
Interfejs użytkownika notebooka Jupyter
Notebook Jupyter hostowany w SageMaker zapewnia naukowcom gotowe środowisko do wdrożenia w celu łatwego łączenia się i eksperymentowania na załadowanych zestawach danych. Użyliśmy A skrypt konfiguracji cyklu życia udostępnić notebookowi wstępnie skonfigurowane środowisko programistyczne i przykładową bazę kodu. Zobacz następujący kod:
Węzły procesu roboczego Dask
Jeśli chodzi o pracowników Dask, zapewnione są większe możliwości dostosowywania, a dokładniej w zakresie typu instancji, wątków na kontener i skalowania alarmów. Domyślnie instancja robocza instancji typu m5d.4xlarge jest montowana do systemu plików Luster podczas uruchamiania i dynamicznie dzieli procesy robocze i wątki na porty. Wszystko to można opcjonalnie dostosować. Zobacz następujący kod:
Wydajność
Aby ocenić wydajność, używamy przykładowych obliczeń i wykresów temperatury powietrza z odległości 2 metrów w oparciu o różnicę między prognozą CMIP6 dla miesiąca a średnią temperaturą powietrza ERA5 dla 10 lat. Ustaliliśmy punkt odniesienia dla dwóch pracowników w każdym regionie i oceniliśmy różnicę w skróceniu czasu w miarę dodawania dodatkowych pracowników. Teoretycznie, w miarę skalowania rozwiązania, powinna istnieć produktywna różnica materiałowa w skróceniu całkowitego czasu.
Poniższa tabela podsumowuje szczegóły naszego zestawu danych.
| Dataset | Zmienne | Rozmiar dysku | Rozmiar zestawu danych Xarray | Region |
| ERA5 | 2011–2020 (120 plików netcdf) | 53.5GB | 364.1 GB | nam wschód-1 |
| CMIP6 | 1.13GB | 0.11 GB | us-zachód-2 |
W poniższej tabeli przedstawiono zebrane wyniki, prezentując czas (w sekundach) każdego obliczenia i predykcji w trzech etapach obliczania predykcji CMIP6, ERA5 i różnicy.
| . | . | Liczba pracowników | |||
| obliczać | Region | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
us-zachód-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
nam wschód-1 | 1512 | 711 | 427 | 202 |
Różnica (propogated pool) |
nas-zachód-2 i us-wschód-1 | 1527 | 906 | 469 | 251 |
Poniższy wykres przedstawia wydajność i skalę.
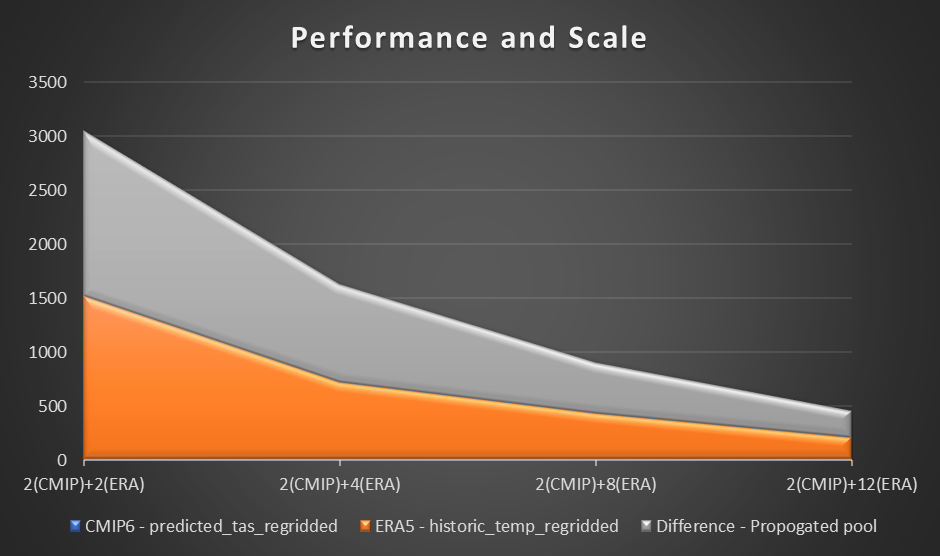
W naszym eksperymencie zaobserwowaliśmy liniową poprawę obliczeń dla zbioru danych ERA5 wraz ze wzrostem liczby pracowników. Wraz ze wzrostem liczby pracowników czas obliczeń skracał się czasami o połowę.
Notatnik Jupyter
W ramach uruchomienia rozwiązania wdrażamy wstępnie skonfigurowany notebook Jupyter, aby pomóc w testowaniu międzyregionalnego rozwiązania Dask. Notatnik demonstruje brak obaw związanych z koniecznością znajomości regionalnej lokalizacji zestawów danych, zamiast wykonywania zapytań w katalogu za pośrednictwem serii notesów Jupyter działających w tle.
Aby rozpocząć, postępuj zgodnie z instrukcjami w tej sekcji.
Kod do notatników można znaleźć w lib/SagemakerCode z podstawowym notatnikiem ux_notebook.ipynb. Ten notatnik odwołuje się do innych notatników, wyzwalając skrypty pomocnicze. ux_notebook ma być punktem wejścia dla naukowców, bez konieczności udawania się gdzie indziej.
Aby rozpocząć, otwórz ten notatnik w SageMaker po wdrożeniu AWS CDK. AWS CDK tworzy instancję notebooka ze wszystkimi plikami w repozytorium załadowanymi i zarchiwizowanymi w pliku Zatwierdzenie kodu AWS magazyn.
Aby uruchomić aplikację, otwórz i uruchom pierwszą komórkę ux_notebook. Ta komórka prowadzi get_variables notatnik w tle, który prosi o wprowadzenie danych, które chcesz wybrać. Dołączamy przykład; należy jednak pamiętać, że pytania pojawią się dopiero po wybraniu poprzedniej opcji. Jest to zamierzone w celu ograniczenia opcji rozwijanych i jest opcjonalnie konfigurowalne poprzez edycję pliku get_variables notatnik.
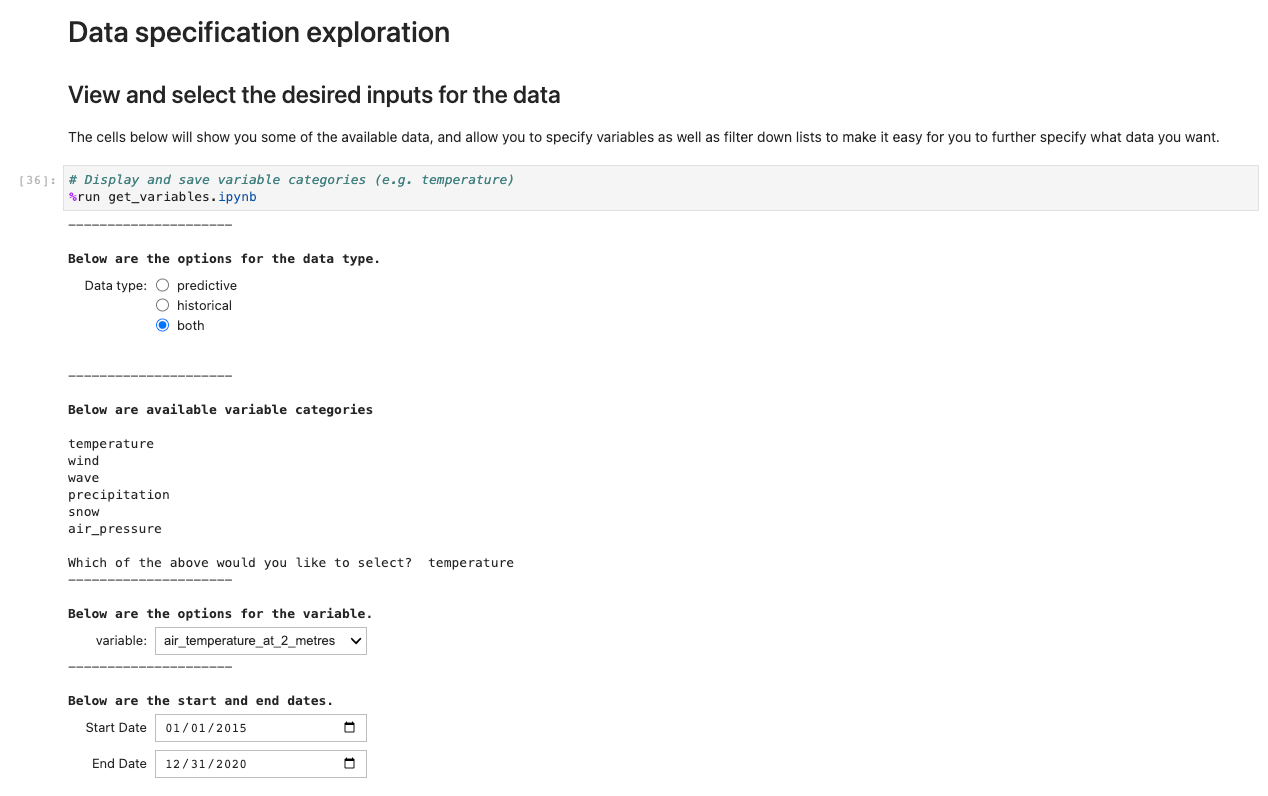
Powyższy kod przechowuje zmienne globalnie, dzięki czemu inne notesy mogą pobierać i ładować wybrane opcje. W celu demonstracji następna komórka powinna wypisać poprzednie zmienne zapisu.
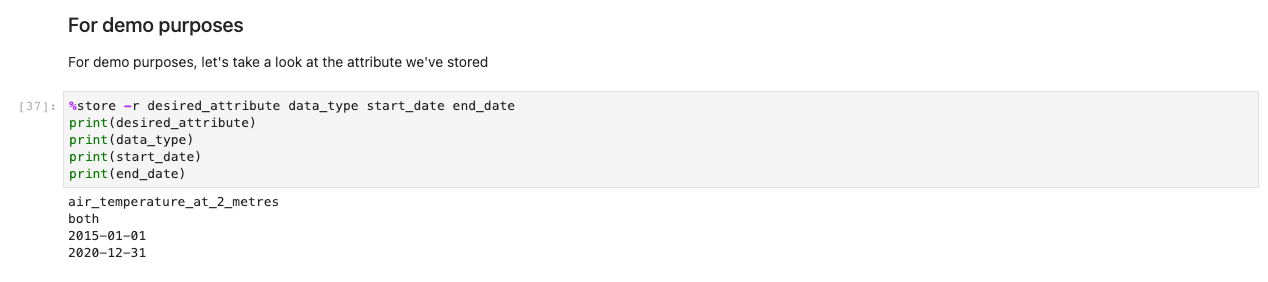
Następnie pojawi się monit o dalsze specyfikacje danych. Ta komórka zawęża dane, których szukasz, przedstawiając identyfikatory tabel w formacie czytelnym dla człowieka. Użytkownicy wybierają tak, jakby to był formularz, ale tytuły są odwzorowywane na tabele w tle, które pomagają systemowi pobrać odpowiednie zestawy danych.
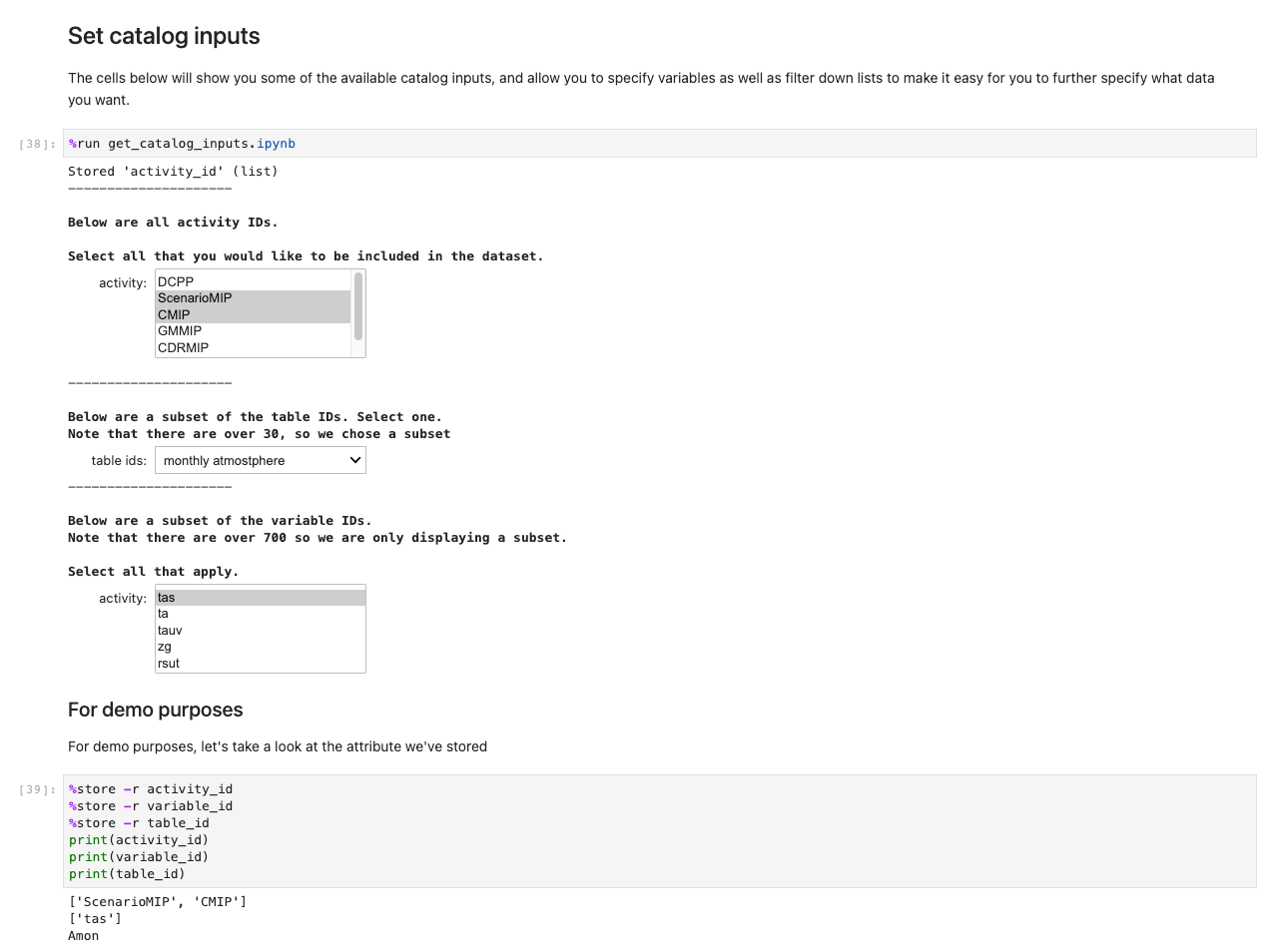
Po zapisaniu wszystkich wyborów i komórek zaznaczenia załaduj dane do Regionów, uruchamiając komórkę w Pobieranie danych zestaw Sekcja. Polecenie %%capture pominie niepotrzebne wyjścia z pliku get_data zeszyt. Uwaga: możesz to usunąć, aby sprawdzić dane wyjściowe z innych notebooków. Dane są następnie pobierane w zapleczu.
Podczas gdy inne notebooki działają w tle, jedynym punktem kontaktu dla użytkownika jest ux_notebook. Ma to na celu streszczenie żmudnego procesu importowania danych do formatu, który każdy użytkownik może z łatwością śledzić.
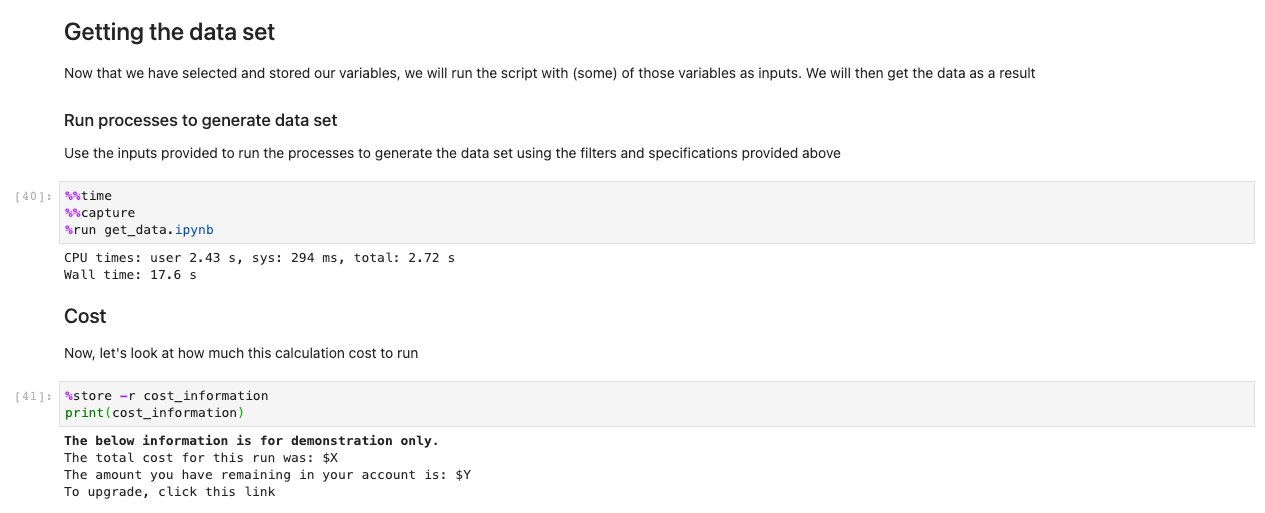
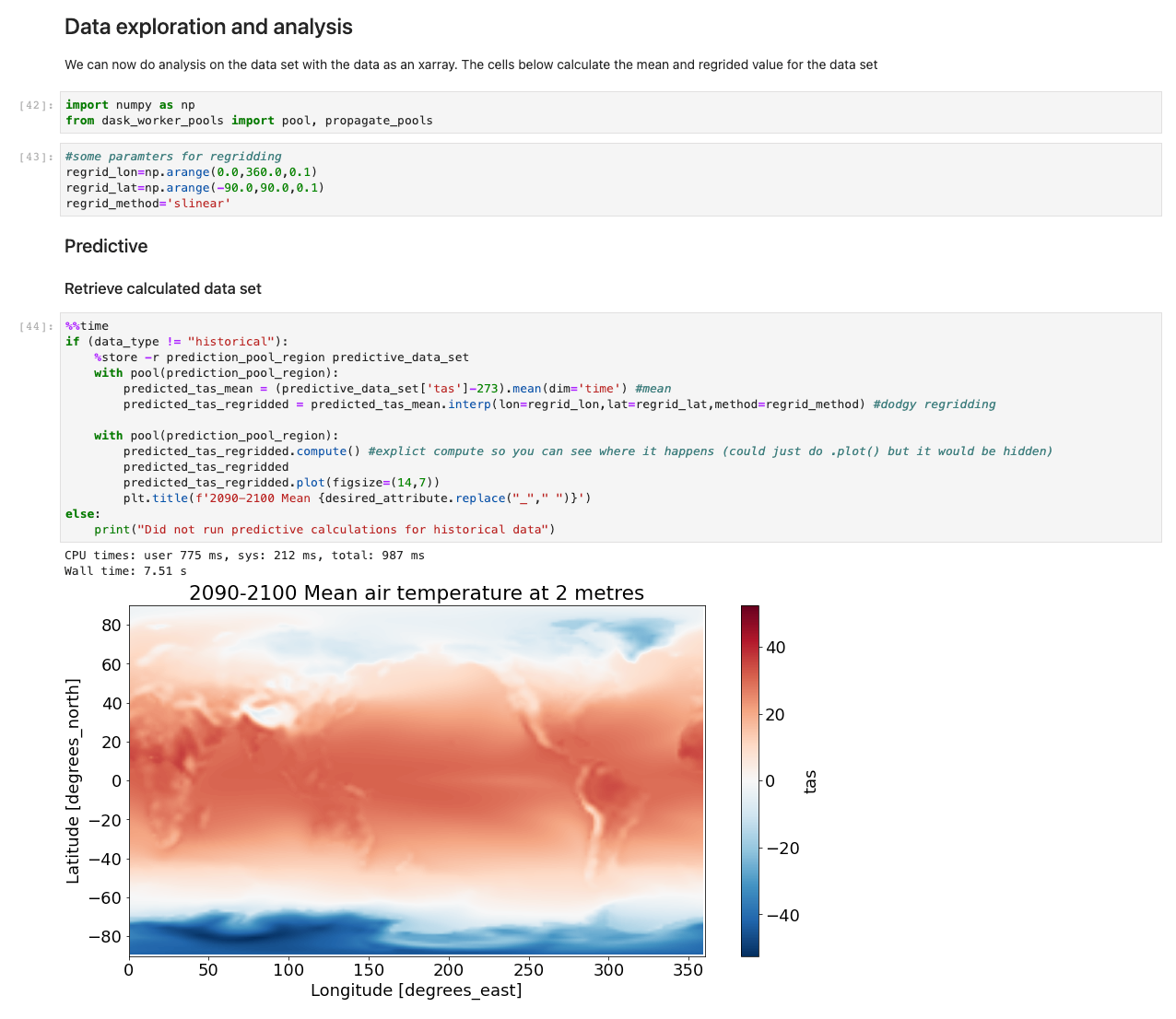
Po załadowaniu danych możemy rozpocząć z nimi interakcję. Poniższe komórki to przykłady obliczeń, które można wykonać na danych pogodowych. Za pomocą tablice x, importujemy, obliczamy, a następnie wykreślamy te zestawy danych.
Nasz przykład ilustruje wykres danych predykcyjnych pobierających dane, uruchamiających obliczenia i wykreślających wyniki w czasie krótszym niż 7.5 sekundy — o rzędy wielkości szybciej niż w przypadku typowego podejścia.
Pod maską
Zeszyty get_catalog_input i get_variables korzystać z biblioteki ipywidgets do wyświetlania widżetów, takich jak listy rozwijane i wybór wielu pól. Te opcje są zapisywane globalnie za pomocą polecenia %%store, dzięki czemu można uzyskać do nich dostęp z poziomu ux_notebook. Jedna z opcji monituje, czy chcesz dane historyczne, dane predykcyjne, czy oba. Ta zmienna jest przekazywana do get_data notebook, aby określić, które kolejne notebooki mają zostać uruchomione.
Połączenia get_data notebook najpierw pobiera współdzieloną domenę usługi OpenSearch, w której została zapisana Magazyn parametrów menedżera systemów AWS. Ta domena pozwala naszemu notatnikowi uruchomić zapytanie dotyczące zbierania informacji, które wskażą, gdzie są przechowywane wybrane zestawy danych Regionalnie. Z tymi zestawami danych zlokalizowanymi regionalnie, notebook podejmie próbę połączenia z harmonogramem Dask, przekazując informacje zebrane z usługi OpenSearch. Planista Dask z kolei będzie mógł wezwać pracowników we właściwych regionach.
Jak dostosować i kontynuować rozwój
Te notatniki mają być przykładem tego, jak można stworzyć sposób, w jaki użytkownicy mogą łączyć się z danymi i wchodzić z nimi w interakcje. Notatnik w tym poście służy jako ilustracja tego, co jest możliwe, i zapraszamy do dalszego rozwijania rozwiązania w celu dalszego zwiększania zaangażowania użytkowników. Podstawową częścią tego rozwiązania jest technologia zaplecza, ale bez mechanizmu interakcji z tym zapleczem użytkownicy nie będą w stanie w pełni wykorzystać potencjału rozwiązania.
Aby uniknąć naliczania przyszłych opłat, usuń zasoby. Zniszczmy nasze wdrożone rozwiązanie za pomocą następującego polecenia:
Wnioski
Ten post przedstawia rozszerzenie Dask między regionami na AWS i możliwą integrację z publicznymi zbiorami danych na AWS. Rozwiązanie zostało zbudowane jako ogólny wzorzec, a kolejne zestawy danych można ładować w celu przyspieszenia analiz złożonych danych z dużą liczbą wejść/wyjść.
Dane zmieniają każdą dziedzinę i każdą firmę. Jednak ze względu na to, że dane rosną szybciej, niż większość firm jest w stanie śledzić, gromadzenie danych i uzyskiwanie z nich wartości stanowi wyzwanie. Nowoczesna strategia dotycząca danych może pomóc w uzyskaniu lepszych wyników biznesowych dzięki danym. AWS zapewnia najbardziej kompletny zestaw usług dla kompleksowej podróży danych, aby pomóc Ci uwolnić wartość z danych i przekształcić je w wiedzę.
Aby dowiedzieć się więcej o różnych sposobach korzystania z danych w chmurze, odwiedź stronę Blog AWS Big Data. Ponadto zapraszamy do komentowania swoich przemyśleń na temat tego postu i określania, czy jest to rozwiązanie, które planujesz wypróbować.
O autorach
 Patrick O'Connor jest inżynierem prototypowania WWSO z siedzibą w Londynie. Jest kreatywnym rozwiązywaniem problemów, zdolnym do adaptacji w szerokim zakresie technologii, takich jak IoT, technologie bezserwerowe, technologie przestrzenne 3D i ML/AI, a także nieustającą ciekawość, w jaki sposób technologia może nadal ewoluować w codziennych podejściach.
Patrick O'Connor jest inżynierem prototypowania WWSO z siedzibą w Londynie. Jest kreatywnym rozwiązywaniem problemów, zdolnym do adaptacji w szerokim zakresie technologii, takich jak IoT, technologie bezserwerowe, technologie przestrzenne 3D i ML/AI, a także nieustającą ciekawość, w jaki sposób technologia może nadal ewoluować w codziennych podejściach.
 Czakra Nagarajana jest Principal Machine Learning Prototyping SA z 21-letnim doświadczeniem w uczeniu maszynowym, big data i obliczeniach o wysokiej wydajności. W swojej obecnej roli pomaga klientom rozwiązywać złożone problemy biznesowe w świecie rzeczywistym, budując prototypy z kompleksowymi rozwiązaniami AI/ML w chmurze i urządzeniach brzegowych. Jego specjalizacja ML obejmuje widzenie komputerowe, przetwarzanie języka naturalnego, prognozowanie szeregów czasowych i personalizację.
Czakra Nagarajana jest Principal Machine Learning Prototyping SA z 21-letnim doświadczeniem w uczeniu maszynowym, big data i obliczeniach o wysokiej wydajności. W swojej obecnej roli pomaga klientom rozwiązywać złożone problemy biznesowe w świecie rzeczywistym, budując prototypy z kompleksowymi rozwiązaniami AI/ML w chmurze i urządzeniach brzegowych. Jego specjalizacja ML obejmuje widzenie komputerowe, przetwarzanie języka naturalnego, prognozowanie szeregów czasowych i personalizację.
 Vala Cohena jest starszym inżynierem prototypowania WWSO z siedzibą w Londynie. Z natury rozwiązująca problemy, Val lubi pisać kod do automatyzacji procesów, tworzyć narzędzia obsesyjne na punkcie klienta i tworzyć infrastrukturę dla różnych aplikacji dla swojej globalnej bazy klientów. Val ma doświadczenie w wielu różnych technologiach, takich jak tworzenie frontendów internetowych, backend i sztuczna inteligencja/uczenie maszynowe.
Vala Cohena jest starszym inżynierem prototypowania WWSO z siedzibą w Londynie. Z natury rozwiązująca problemy, Val lubi pisać kod do automatyzacji procesów, tworzyć narzędzia obsesyjne na punkcie klienta i tworzyć infrastrukturę dla różnych aplikacji dla swojej globalnej bazy klientów. Val ma doświadczenie w wielu różnych technologiach, takich jak tworzenie frontendów internetowych, backend i sztuczna inteligencja/uczenie maszynowe.
 Nialla Robinsona jest szefem kontraktów terminowych na produkty w brytyjskim Met Office. On i jego zespół badają nowe sposoby, w jakie Met Office może zapewnić wartość poprzez innowacje produktowe i strategiczne partnerstwa. Ma zróżnicowaną karierę, kierując multidyscyplinarnym zespołem badawczo-rozwojowym informatyki, badaniami akademickimi w dziedzinie nauki o danych oraz naukowcem terenowym wraz z doświadczeniem w zakresie modelowania klimatu.
Nialla Robinsona jest szefem kontraktów terminowych na produkty w brytyjskim Met Office. On i jego zespół badają nowe sposoby, w jakie Met Office może zapewnić wartość poprzez innowacje produktowe i strategiczne partnerstwa. Ma zróżnicowaną karierę, kierując multidyscyplinarnym zespołem badawczo-rozwojowym informatyki, badaniami akademickimi w dziedzinie nauki o danych oraz naukowcem terenowym wraz z doświadczeniem w zakresie modelowania klimatu.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :ma
- :Jest
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- zdolność
- Zdolny
- O nas
- powyżej
- ABSTRACT
- streszczenia
- akademicki
- badania naukowe
- przyśpieszyć
- przyspieszenie
- dostęp
- dostęp
- pomieścić
- wykonać
- Konto
- Osiąga
- w poprzek
- dostosowuje się
- w dodatku
- dodanie
- Dodatkowy
- do tego
- adres
- adresowanie
- Dodaje
- Administratorzy
- przyjęty
- Przyjęcie
- Po
- AI / ML
- AIR
- Wszystkie kategorie
- Pozwalać
- pozwala
- wzdłuż
- również
- Amazonka
- Amazon EC2
- an
- analiza
- i
- każdy
- zjawić się
- Zastosowanie
- aplikacje
- podejście
- awanse
- właściwy
- architektura
- SĄ
- AS
- At
- Atmosfera
- atmosferyczny
- zautomatyzować
- uniknąć
- AWS
- Klient AWS
- Kręgosłup
- poparła
- Backend
- tło
- Bilans
- baza
- na podstawie
- BE
- stają się
- być
- zanim
- jest
- poniżej
- Benchmark
- Ulepsz Swój
- pomiędzy
- Duży
- Big Data
- Bootstrap
- obie
- Bringing
- Złamany
- budować
- Budowanie
- wybudowany
- wbudowany
- biznes
- ale
- by
- obliczać
- wezwanie
- nazywa
- powołanie
- Połączenia
- CAN
- możliwości
- zdolny
- Kariera
- katalog
- CD
- Komórki
- wyzwanie
- wyzwanie
- zmiana
- wymiana pieniędzy
- opłata
- Opłaty
- wybory
- Obieg
- klient
- Klimat
- bliższy
- Chmura
- Grupa
- CO
- kod
- podstawa kodu
- współpraca
- Zbieranie
- jak
- byliśmy spójni, od początku
- przyjście
- komentarz
- społeczność
- Firmy
- kompletny
- kompleks
- składniki
- Składa się
- obliczenia
- obliczać
- komputer
- Wizja komputerowa
- computing
- systemu
- Skontaktuj się
- połączony
- Podłączanie
- połączenie
- Konsumenci
- konsumpcja
- Pojemnik
- zawiera
- kontynuować
- ciągły
- kopie
- rdzeń
- skorygowania
- Koszty:
- opłacalne
- mógłby
- sprzężony
- CPU
- Stwórz
- tworzy
- Twórczy
- krytyczny
- wole
- Krzyż
- ciekawość
- Aktualny
- zwyczaj
- klient
- Klientów
- konfigurowalny
- dostosować
- codziennie
- tablica rozdzielcza
- dane
- nauka danych
- strategia danych
- zbiory danych
- dzień
- dekada
- Decyzje
- Domyślnie
- Kreowanie
- demonstruje
- rozwijać
- wdrażane
- Wdrożenie
- wdraża się
- zaprojektowany
- zniszczyć
- szczegółowe
- detale
- Ustalać
- rozwijać
- Deweloper
- oprogramowania
- urządzenia
- różnica
- niepełnosprawny
- odkrycie
- Wyświetlacz
- dystrybuowane
- przetwarzanie rozproszone
- dns
- Doker
- domena
- na dół
- dynamiczny
- dynamicznie
- każdy
- łatwość
- z łatwością
- krawędź
- redagowanie
- wydajny
- gdzie indziej
- umożliwiać
- koniec końców
- energia
- zaręczynowy
- inżynier
- wejście
- Środowisko
- Równoważny
- Era
- szacunkowa
- Eter (ETH)
- Każdy
- codziennie
- codzienny
- ewoluuje
- przykład
- przykłady
- doświadczenie
- eksperyment
- ekspertyza
- odkryj
- eksport
- narażony
- rozbudowa
- szybciej
- Cecha
- Korzyści
- pole
- Łąka
- filet
- Akta
- Znajdź
- i terminów, a
- koncentruje
- obserwuj
- następujący
- jedzenie
- W razie zamówieenia projektu
- Nasz formularz
- format
- formularze
- znaleziono
- Założony
- Framework
- Ramy
- Darmowy
- od
- urzeczywistnienie
- pełny
- Funkcjonalność
- dalej
- przyszłość
- Futures
- Ogólne
- generacja
- otrzymać
- miejsce
- git
- Globalne
- Globalna sieć
- Globalnie
- globus
- będzie
- wykres
- większy
- Krata
- Rosnąć
- Rozwój
- miał
- Pół
- o połowę
- Have
- he
- głowa
- pomoc
- pomaga
- jej
- Wysoki
- wysoka wydajność
- pasemka
- jego
- historyczny
- gospodarz
- hostowane
- godzina
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- czytelne dla człowieka
- Setki
- Idle
- ids
- if
- ilustruje
- importować
- importowanie
- podnieść
- poprawa
- in
- zawierać
- obejmuje
- wzrosła
- wskaźnik
- wskazać
- informować
- Informacja
- Infrastruktura
- nieodłączny
- Innowacja
- wkład
- niepewność
- wgląd
- inspirowane
- zainstalować
- przykład
- zamiast
- instrukcje
- integracja
- Zamierzony
- interakcji
- interakcji
- Interfejs
- wewnętrzny
- Internet
- najnowszych
- zapraszać
- Internet przedmiotów
- IP
- Adres IP
- problemy
- IT
- JEGO
- Praca
- podróż
- jpg
- Notebook Jupyter
- Trzymać
- Klawisz
- Wiedzieć
- język
- duży
- Nazwisko
- Utajenie
- uruchomić
- prowadzący
- UCZYĆ SIĘ
- nauka
- Biblioteka
- wifecycwe
- lubić
- Powiązanie
- Lista
- załadować
- miejscowy
- lokalnie
- usytuowany
- lokalizacja
- Londyn
- maszyna
- uczenie maszynowe
- poważny
- robić
- zarządzanie
- kierownik
- zarządza
- mapa
- mapowanie
- Masa
- Masowa adopcja
- materiał
- Może..
- oznaczać
- mechanizm
- Metadane
- miliony
- ML
- model
- Nowoczesne technologie
- Moduły
- Miesiąc
- miesięcznie
- dane miesięczne
- jeszcze
- większość
- MONTAż
- multidyscyplinarny
- Nazwa
- narodowy
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Natura
- niezbędny
- Potrzebować
- potrzeba
- sieć
- Nowości
- Następny
- noc
- węzeł
- węzły
- notatnik
- laptopy
- już dziś
- numer
- z naszej
- of
- oferta
- Biurowe
- on
- ONE
- tylko
- koncepcja
- otwarte danych
- open source
- kod open source
- operacyjny
- Option
- Opcje
- or
- orkiestracja
- organizacji
- Inne
- ludzkiej,
- na zewnątrz
- wyniki
- wydajność
- koniec
- ogólny
- pakiet
- parametr
- część
- szczególny
- szczególnie
- partnerstwa
- minęło
- Przechodzący
- Wzór
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- okresy
- personalizacja
- petabajt
- faza
- krok po kroku
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- basen
- porty
- możliwy
- Post
- potencjał
- power
- mocny
- praktyka
- przepowiednia
- Przewidywania
- warunki wstępne
- poprzedni
- pierwotny
- Główny
- prywatny
- Problem
- problemy
- wygląda tak
- procesów
- przetwarzanie
- Wytworzony
- Produkt
- Innowacja produktowa
- produktywny
- Program
- Programowanie
- projekt
- prototypy
- prototypowanie
- zapewniać
- pod warunkiem,
- zapewnia
- zaopatrzenie
- publiczny
- publikować
- opublikowany
- Ściąga
- zapytania
- pytania
- R & D
- zasięg
- raczej
- gotowe
- Prawdziwy świat
- zrealizować
- zmniejszyć
- redukcja
- redukcja
- region
- regionalny
- regiony
- bezwzględny
- szczątki
- usunąć
- Usunięto
- składnica
- reprezentuje
- Badania naukowe
- Zasoby
- osób
- Efekt
- Rola
- run
- bieganie
- SA
- "bezpiecznym"
- sagemaker
- taki sam
- Zapisz
- skalowalny
- Skala
- waga
- skalowaniem
- nauka
- Naukowiec
- Naukowcy
- skrypty
- sekund
- Sekcja
- widzieć
- widziany
- Segmenty
- wybrany
- wybór
- senior
- Serie
- Bezserwerowe
- służy
- usługa
- Usługi
- zestaw
- Share
- shared
- powinien
- pokazać
- ściąganie
- Targi
- Prosty
- po prostu
- szósty
- powolny
- So
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- kilka
- Źródło
- Przestrzenne
- swoiście
- Specyfikacje
- określony
- sponsorowanie
- stos
- etapy
- standalone
- początek
- rozpoczęty
- pobyt
- Cel
- przechowywanie
- sklep
- przechowywany
- sklep
- bezpośredni
- Strategiczny
- Partnerstwo strategiczne
- Strategia
- kolejny
- Następnie
- udany
- taki
- Powierzchnia
- powstaje
- Zrównoważony rozwój
- zrównoważone
- system
- systemy
- stół
- Brać
- zespół
- tech
- Technologies
- Technologia
- test
- niż
- że
- Połączenia
- Informacje
- Źródło
- UK
- świat
- ich
- następnie
- Tam.
- a tym samym
- Te
- one
- to
- tych
- trzy
- Prosperować
- Przez
- wydajność
- czas
- Szereg czasowy
- czasy
- tytuły
- do
- już dziś
- razem
- narzędzia
- śledzić
- Śledzenie
- przenieść
- transformatorowy
- tranzyt
- wyzwalanie
- SKRĘCAĆ
- drugiej
- rodzaj
- Maszynopis
- typowy
- Uk
- dla
- odblokować
- niezrównoważony
- nowomodny
- Nowości
- na
- URI
- Stosowanie
- posługiwać się
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- UTC
- Wykorzystując
- VAL
- wartość
- różnorodność
- różnorodny
- przez
- wizja
- Odwiedzić
- Tom
- chcieć
- chce
- ciepły
- była
- Droga..
- sposoby
- we
- Pogoda
- sieć
- Tworzenie stron internetowych
- były
- czy
- który
- szeroki
- Szeroki zasięg
- będzie
- Życzenia
- w
- bez
- Praca
- pracownik
- pracowników
- świat
- martwić się
- by
- pisanie
- lat
- jeszcze
- Wydajność
- ty
- Twój
- zefirnet