Wartość danych zależy od czasu. Przetwarzanie w czasie rzeczywistym sprawia, że decyzje oparte na danych są dokładne i wykonalne w ciągu sekund lub minut zamiast godzin lub dni. Przechwytywanie danych zmian (CDC) odnosi się do procesu identyfikowania i przechwytywania zmian wprowadzonych w danych w bazie danych, a następnie dostarczania tych zmian w czasie rzeczywistym do systemu niższego szczebla. Przechwytywanie każdej zmiany z transakcji w źródłowej bazie danych i przenoszenie ich do miejsca docelowego w czasie rzeczywistym zapewnia synchronizację systemów i pomaga w analizie przypadków użycia w czasie rzeczywistym oraz migracji baz danych bez przestojów. Oto kilka zalet CDC:
- Eliminuje potrzebę masowego ładowania aktualizacji i niewygodnych okien wsadowych, umożliwiając ładowanie przyrostowe lub przesyłanie strumieniowe zmian danych w czasie rzeczywistym do docelowego repozytorium.
- Zapewnia synchronizację danych w wielu systemach. Jest to szczególnie ważne w przypadku podejmowania decyzji, w których liczy się czas w środowisku danych o dużej szybkości.
Kafka Połącz to komponent typu open source Apache Kafka, który działa jako scentralizowane centrum danych do prostej integracji danych między bazami danych, magazynami klucz-wartość, indeksami wyszukiwania i systemami plików. The Rejestr schematów kleju AWS umożliwia centralne odkrywanie, kontrolowanie i rozwijanie schematów strumieni danych. Kafka Connect i Schema Registry integrują się w celu przechwytywania informacji o schemacie z konektorów. Kafka Connect zapewnia mechanizm konwersji danych z wewnętrznych typów danych używanych przez Kafka Connect na typy danych reprezentowane jako Avro, Protobuf lub JSON Schema. AvroConverter, ProtobufConverter i JsonSchemaConverter automatycznie rejestrują schematy generowane przez łączniki Kafki (źródło), które generują dane do Kafki. Łączniki (ujścia), które zużywają dane z Kafki, otrzymują informacje o schemacie oprócz danych dla każdej wiadomości. Dzięki temu łączniki ujścia znają strukturę danych w celu zapewnienia możliwości, takich jak utrzymywanie schematu tabeli bazy danych w wykazie danych.
Post pokazuje, jak zbudować kompleksowy CDC przy użyciu Amazon MSK Połącz, zarządzana usługa AWS do wdrażania i uruchamiania aplikacji Kafka Connect oraz AWS Glue Schema Registry, która umożliwia centralne odkrywanie, kontrolowanie i rozwijanie schematów strumieni danych.
Omówienie rozwiązania
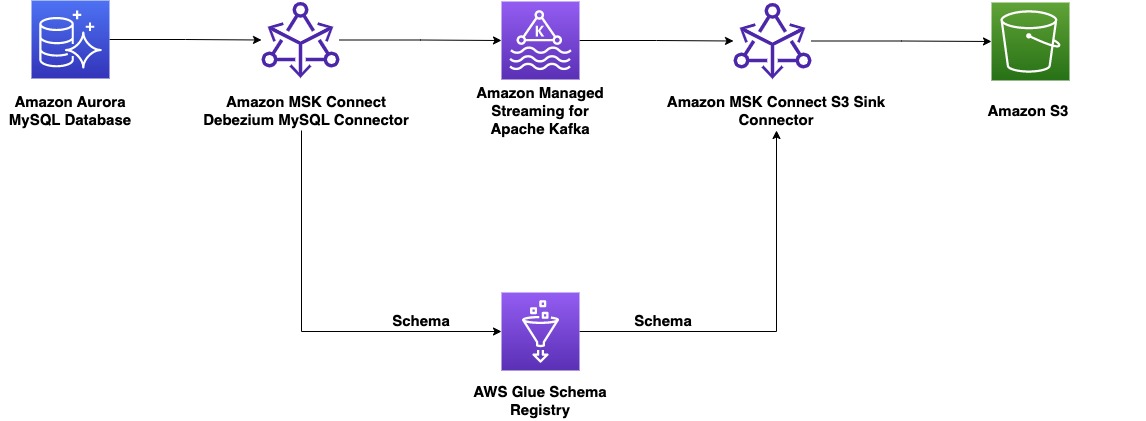
Po stronie producenta w tym przykładzie wybieramy kompatybilną z MySQL Amazonka Aurora baza danych jako źródło danych i mamy plik debezium Łącznik MySQL do wykonywania CDC. Konektor Debezium stale monitoruje bazy danych i wprowadza zmiany na poziomie wierszy do tematu Kafki. Łącznik pobiera schemat z bazy danych w celu serializacji rekordów do postaci binarnej. Jeśli schemat nie istnieje jeszcze w rejestrze, schemat zostanie zarejestrowany. Jeśli schemat istnieje, ale serializator używa nowej wersji, rejestr schematu sprawdza plik Tryb zgodności schematu przed aktualizacją schematu. W tym rozwiązaniu używamy tryb kompatybilności wstecznej. Rejestr schematów zwraca błąd, jeśli nowa wersja schematu nie jest kompatybilna wstecz, i możemy skonfigurować Kafka Connect do wysyłania niekompatybilnych komunikatów do kolejki utraconych wiadomości.
Po stronie konsumenta używamy Usługa Amazon Simple Storage (Amazon S3) złącze ujścia do deserializacji rekordu i przechowywania zmian w Amazon S3. Budujemy i wdrażamy łącznik Debezium i zlew Amazon S3 za pomocą MSK Connect.
Przykładowy schemat
W tym poście używamy następującego schematu jako pierwszej wersji tabeli:
Wymagania wstępne
Przed skonfigurowaniem łączników producenta i konsumenta MSK musimy najpierw skonfigurować źródło danych, klaster MSK i nowy rejestr schematów. Zapewniamy Tworzenie chmury AWS szablon do generowania zasobów pomocniczych potrzebnych do rozwiązania:
- Baza danych Aurora kompatybilna z MySQL jako źródło danych. Aby wykonać CDC, włączamy logowanie binarne w pliku Grupa parametrów klastra DB.
- Klaster MSK. Aby uprościć połączenie sieciowe, używamy tego samego VPC dla bazy danych Aurora i klastra MSK.
- Dwa rejestry schematów do obsługi schematów dla klucza komunikatu i wartości komunikatu.
- Jedno wiadro S3 jako ujście danych.
- Do tego pokazu potrzebne są wtyczki MSK Connect i konfiguracja procesu roboczego.
- jeden Elastyczna chmura obliczeniowa Amazon (Amazon EC2) do uruchamiania poleceń bazy danych.
Aby skonfigurować zasoby na swoim koncie AWS, wykonaj następujące kroki w regionie AWS, który obsługuje Amazon MSK, MSK Connect i AWS Glue Schema Registry:
- Dodaj Uruchom stos:
- Dodaj Następna.
- W razie zamówieenia projektu Nazwa stosu, wprowadź odpowiednią nazwę.
- W razie zamówieenia projektu Hasło bazy danych, wprowadź żądane hasło dla użytkownika bazy danych.
- Zachowaj inne wartości jako domyślne.
- Dodaj Następna.
- Na następnej stronie wybierz Następna.
- Przejrzyj szczegóły na ostatniej stronie i wybierz Przyjmuję do wiadomości, że AWS CloudFormation może tworzyć zasoby IAM.
- Dodaj Utwórz stos.
Niestandardowa wtyczka dla łącznika źródłowego i docelowego
Wtyczka niestandardowa to zestaw plików JAR zawierających implementację jednego lub większej liczby konektorów, transformacji lub konwerterów. Amazon MSK zainstaluje wtyczkę na pracownikach klastra MSK Connect, w którym działa łącznik. W ramach tej demonstracji dla łącznika źródłowego używamy oprogramowania typu open source Pliki JAR złącza Debezium MySQL, a dla łącznika docelowego używamy licencjonowanej społeczności Confluent JAR złącza zlewozmywaka Amazon S3. Obie wtyczki są również dodawane z bibliotekami dla Serializatory i deserializatory Avro rejestru AWS Glue Schema. Te niestandardowe wtyczki są już utworzone jako część szablonu CloudFormation wdrożonego w poprzednim kroku.
Użyj AWS Glue Schema Registry ze złączem Debezium w MSK Connect jako producent MSK
Najpierw wdrażamy łącznik źródłowy za pomocą wtyczki Debezium MySQL do strumieniowego przesyłania danych z pliku Wersja zgodna z Amazon Aurora MySQL bazy danych do Amazon MSK. Wykonaj następujące kroki:
- W konsoli Amazon MSK, w okienku nawigacji, pod MSK Połączwybierz Złącza.
- Dodaj Utwórz łącznik.
- Dodaj Użyj istniejącej niestandardowej wtyczki a następnie wybierz niestandardową wtyczkę z nazwą zaczynającą się
msk-blog-debezium-source-plugin. - Dodaj Następna.
- Wpisz odpowiednią nazwę np
debezium-mysql-connectori opcjonalny opis. - W razie zamówieenia projektu Klaster Apache Kafkawybierz Klaster MSK i wybierz klaster utworzony przez szablon CloudFormation.
- In Konfiguracja złącza, usuń wartości domyślne i użyj następujących par klucz-wartość konfiguracji oraz odpowiednich wartości:
- Nazwa – Nazwa używana dla konektora.
- nazwa_bazy_danych.hostów – Dane wyjściowe CloudFormation dla Punkt końcowy bazy danych.
- baza danych.użytkownik i baza danych.hasło – Parametry przekazane w szablonie CloudFormation.
- baza danych.historia.kafka.bootstrap.servers – Dane wyjściowe CloudFormation dla Bootstrap Kafki.
- klucz.konwerter.region i wartość.konwerter.region – Twój region.
Niektóre z tych ustawień są ogólne i należy je określić dla dowolnego łącznika. Na przykład:
- connector.class to klasa Java konektora
- task.max to maksymalna liczba zadań, które należy utworzyć dla tego łącznika
Niektóre ustawienia (database.*, transforms.*) są specyficzne dla łącznika Debezium MySQL. Odnosić się do Właściwości konfiguracji złącza źródłowego Debezium MySQL po więcej informacji.
Niektóre ustawienia (key.converter.* i value.converter.*) są specyficzne dla rejestru schematów. Używamy AWSKafkaAvroConverter z Biblioteka rejestru schematu kleju AWS jako konwerter formatów. Konfigurować AWSKafkaAvroConverter, używamy wartości właściwości stałej łańcuchowej w pliku Stałe rejestru AWSSchemaRegistry klasa:
key.converterivalue.converterkontrolować format danych, które będą zapisywane w Kafce dla konektorów źródłowych lub odczytywane z Kafki dla konektorów ujścia. UżywamyAWSKafkaAvroConverterdla formatu Avro.key.converter.registry.nameivalue.converter.registry.namezdefiniuj, który rejestr schematu ma być używany.key.converter.compatibilityivalue.converter.compatibilityzdefiniuj model kompatybilności.
Odnosić się do Używanie Kafka Connect z rejestrem AWS Glue Schema po więcej informacji.
- Następnie konfigurujemy Pojemność złącza. Możemy wybrać Zaopatrzony i pozostaw inne właściwości jako domyślne
- W razie zamówieenia projektu Konfiguracja pracownika, wybierz niestandardową konfigurację procesu roboczego z nazwą zaczynającą się
msk-gsr-blogutworzone w ramach szablonu CloudFormation. - W razie zamówieenia projektu Uprawnienia dostępu, Użyj AWS Zarządzanie tożsamością i dostępem (IAM) wygenerowana przez szablon CloudFormation
MSKConnectRole. - Dodaj Następna.
- W razie zamówieenia projektu Bezpieczeństwo, wybierz ustawienia domyślne.
- Dodaj Następna.
- W razie zamówieenia projektu Dostawa dziennika, Wybierz Dostarcz do dzienników Amazon CloudWatch i wyszukaj grupę dzienników utworzoną przez szablon CloudFormation (
msk-connector-logs). - Dodaj Następna.
- Przejrzyj ustawienia i wybierz Utwórz łącznik.
Po kilku minutach złącze zmieni stan na działające.
Użyj rejestru AWS Glue Schema z konektorem zlewu Confluent S3 działającym w MSK Connect jako konsument MSK
Wdrażamy złącze zlewu za pomocą wtyczki zlewu Confluent S3 do strumieniowego przesyłania danych z Amazon MSK do Amazon S3. Wykonaj następujące kroki:
-
- W konsoli Amazon MSK, w okienku nawigacji, pod MSK Połączwybierz Złącza.
- Dodaj Utwórz łącznik.
- Dodaj Użyj istniejącej niestandardowej wtyczki i wybierz niestandardową wtyczkę z nazwą zaczynającą się
msk-blog-S3sink-plugin. - Dodaj Następna.
- Wpisz odpowiednią nazwę np
s3-sink-connectori opcjonalny opis. - W razie zamówieenia projektu Klaster Apache Kafkawybierz Klaster MSK i wybierz klaster utworzony przez szablon CloudFormation.
- In Konfiguracja złącza, usuń podane wartości domyślne i użyj następujących par klucz-wartość konfiguracji z odpowiednimi wartościami:
-
- Nazwa – Ta sama nazwa, co złącze.
- s3.nazwa.wiaderka – Dane wyjściowe CloudFormation dla Nazwa wiadra.
- s3.region, key.converter.region i value.converter.region – Twój region.
-
- Następnie konfigurujemy Pojemność złącza. Możemy wybrać Zaopatrzony i pozostaw inne właściwości jako domyślne
- W razie zamówieenia projektu Konfiguracja pracownika, wybierz niestandardową konfigurację procesu roboczego z nazwą zaczynającą się
msk-gsr-blogutworzone w ramach szablonu CloudFormation. - W razie zamówieenia projektu Uprawnienia dostępu, użyj roli IAM wygenerowanej przez szablon CloudFormation
MSKConnectRole. - Dodaj Następna.
- W razie zamówieenia projektu Bezpieczeństwo, wybierz ustawienia domyślne.
- Dodaj Następna.
- W razie zamówieenia projektu Dostawa dziennika, Wybierz Dostarcz do dzienników Amazon CloudWatch i wyszukaj grupę dzienników utworzoną przez szablon CloudFormation
msk-connector-logs. - Dodaj Następna.
- Przejrzyj ustawienia i wybierz Utwórz łącznik.
Po kilku minutach łącznik działa.
Przetestuj kompleksowy strumień dziennika CDC
Teraz, gdy złącza zlewu Debezium i S3 są już uruchomione, wykonaj następujące kroki, aby przetestować kompleksowe CDC:
- Na konsoli Amazon EC2 przejdź do Grupy bezpieczeństwa strona.
- Wybierz grupę zabezpieczeń
ClientInstanceSecurityGroupi wybierz Edytuj reguły przychodzące. - Dodaj regułę ruchu przychodzącego zezwalającą na połączenie SSH z Twojej sieci lokalnej.
- Na Instancje wybierz instancję
ClientInstancei wybierz Skontaktuj się. - Na Połączenie instancji EC2 kartę, wybierz Skontaktuj się.
- Upewnij się, że bieżący katalog roboczy to
/home/ec2-useri ma plikicreate_table.sql,alter_table.sql,initial_insert.sql,insert_data_with_new_column.sql. - Utwórz tabelę w bazie danych MySQL, uruchamiając następujące polecenie (podaj nazwę hosta bazy danych z danych wyjściowych szablonu CloudFormation):
- Po wyświetleniu monitu o hasło wprowadź hasło z parametrów szablonu CloudFormation.
- Wstaw przykładowe dane do tabeli za pomocą następującego polecenia:
- Po wyświetleniu monitu o hasło wprowadź hasło z parametrów szablonu CloudFormation.
- Na konsoli AWS Glue wybierz Rejestry schematów w okienku nawigacji, a następnie wybierz Schematy.
- Nawigować do
db1.sampledatabase.movieswersja 1, aby sprawdzić nowy schemat utworzony dla tabeli filmów:
Dla każdej partycji tematu Kafka tworzony jest osobny folder S3, a dane dla tematu są zapisywane w tym folderze.
- Na konsoli Amazon S3 sprawdź, czy w folderze dotyczącym tematu Kafki znajdują się dane zapisane w formacie Parquet.
Ewolucja schematu
Po zdefiniowaniu początkowego schematu aplikacje mogą potrzebować go ewoluować w czasie. W takim przypadku krytyczne znaczenie dla dalszych konsumentów ma możliwość bezproblemowej obsługi danych zakodowanych zarówno w starym, jak i nowym schemacie. Tryby zgodności pozwalają kontrolować sposób, w jaki schematy mogą lub nie mogą ewoluować w czasie. Te tryby tworzą kontrakt między aplikacjami produkującymi i zużywającymi dane. Aby uzyskać szczegółowe informacje na temat różnych trybów zgodności dostępnych w rejestrze schematu kleju AWS, zobacz Rejestr schematów kleju AWS. W naszym przykładzie używamy wstecznej możliwości łączenia, aby zapewnić konsumentom możliwość odczytania zarówno bieżącej, jak i poprzedniej wersji schematu. Wykonaj następujące kroki:
- Dodaj nową kolumnę do tabeli, uruchamiając następujące polecenie:
- Wstaw nowe dane do tabeli, uruchamiając następujące polecenie:
- Na konsoli AWS Glue wybierz Rejestry schematów w okienku nawigacji, a następnie wybierz Schematy.
- Przejdź do schematu
db1.sampledatabase.movieswersja 2, aby sprawdzić nową wersję schematu utworzonego dla filmów w tabeli filmów, w tym dodaną kolumnę kraju:
- Na konsoli Amazon S3 sprawdź, czy w folderze dotyczącym tematu Kafka znajdują się dane zapisane w formacie Parquet.
Sprzątać
Aby zapobiec niechcianym obciążeniom konta AWS, usuń zasoby AWS, których użyłeś w tym poście:
- Na konsoli Amazon S3 przejdź do zasobnika S3 utworzonego przez szablon CloudFormation.
- Wybierz wszystkie pliki i foldery i wybierz Usuń.
- Wprowadź trwale usuń zgodnie z zaleceniami i wybierz Usuń obiekty.
- W konsoli AWS CloudFormation usuń utworzony stos.
- Poczekaj, aż stan stosu zmieni się na DELETE_KOMPLETE.
Wnioski
W tym poście pokazano, jak używać Amazon MSK, MSK Connect i AWS Glue Schema Registry do tworzenia strumienia dziennika CDC i rozwijania schematów dla strumieni danych w miarę zmieniających się potrzeb biznesowych. Ten wzorzec architektury można zastosować do innych źródeł danych z różnymi łącznikami Kafka. Aby uzyskać więcej informacji, zapoznaj się z Przykłady MSK Connect.
O autorze
 Kalian Janaki jest starszym specjalistą ds. Big Data i analityki w Amazon Web Services. Pomaga klientom w projektowaniu i budowaniu wysoce skalowalnych, wydajnych i bezpiecznych rozwiązań opartych na chmurze w AWS.
Kalian Janaki jest starszym specjalistą ds. Big Data i analityki w Amazon Web Services. Pomaga klientom w projektowaniu i budowaniu wysoce skalowalnych, wydajnych i bezpiecznych rozwiązań opartych na chmurze w AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :Jest
- $W GÓRĘ
- 1
- 10
- 11
- 7
- 8
- a
- Zdolny
- O nas
- dostęp
- Konto
- dokładny
- uznać
- w dodatku
- dodatek
- Wszystkie kategorie
- Pozwalać
- pozwala
- już
- Amazonka
- Amazon EC2
- Amazon Web Services
- analityka
- i
- Apache
- Apache Kafka
- aplikacje
- Aplikuj
- właściwy
- architektura
- SĄ
- AS
- jutrzenka
- automatycznie
- dostępny
- AWS
- Tworzenie chmury AWS
- Klej AWS
- BE
- zanim
- Korzyści
- pomiędzy
- Duży
- Big Data
- Bootstrap
- budować
- biznes
- by
- CAN
- możliwości
- zdobyć
- Przechwytywanie
- Etui
- katalog
- CDC
- scentralizowane
- zmiana
- Zmiany
- Opłaty
- ZOBACZ
- Wykrywanie urządzeń szpiegujących
- Dodaj
- klasa
- Grupa
- Kolumna
- społeczność
- zgodność
- zgodny
- kompletny
- składnik
- obliczać
- systemu
- Dopływ
- Skontaktuj się
- połączenie
- Konsola
- stały
- konsumować
- konsument
- Konsumenci
- bez przerwy
- umowa
- kontrola
- kraj
- Stwórz
- stworzony
- krytyczny
- Aktualny
- zwyczaj
- Klientów
- dane
- integracja danych
- sterowane danymi
- Baza danych
- Bazy danych
- Dni
- Decyzje
- Domyślnie
- Domyślnie
- zdefiniowane
- dostarczanie
- Demo
- wykazać
- demonstruje
- rozwijać
- wdrażane
- opis
- miejsce przeznaczenia
- szczegółowe
- detale
- różne
- odkryj
- Nie
- Spadek
- każdy
- eliminuje
- umożliwiając
- koniec końców
- zapewnić
- zapewnia
- Wchodzę
- Środowisko
- błąd
- szczególnie
- Eter (ETH)
- Każdy
- ewoluuje
- przykład
- Przede wszystkim system został opracowany
- istnieje
- kilka
- Łąka
- filet
- Akta
- finał
- i terminów, a
- następujący
- W razie zamówieenia projektu
- Nasz formularz
- format
- od
- Generować
- wygenerowane
- Zarządzanie
- Grupy
- uchwyt
- Prowadzenie
- dzieje
- Have
- pomoc
- pomaga
- wysoko
- historia
- gospodarz
- GODZINY
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- Piasta
- IAM
- identyfikacja
- tożsamość
- realizacja
- ważny
- in
- Włącznie z
- indeksy
- Informacja
- początkowy
- zainstalować
- przykład
- zamiast
- integrować
- integracja
- wewnętrzny
- IT
- Java
- jpg
- json
- kafka
- Klawisz
- Wiedzieć
- Pozostawiać
- biblioteki
- Upoważniony
- lubić
- załadować
- załadunek
- miejscowy
- długo
- zrobiony
- WYKONUJE
- Dokonywanie
- zarządzane
- mistrz
- max
- maksymalny
- mechanizm
- wiadomość
- wiadomości
- może
- minuty
- model
- Tryby
- monitory
- jeszcze
- Kino
- przeniesienie
- wielokrotność
- MySQL
- Nazwa
- Nawigacja
- Nawigacja
- Potrzebować
- potrzebne
- wymagania
- sieć
- Nowości
- Następny
- numer
- of
- Stary
- on
- ONE
- open source
- Inne
- wydajność
- strona
- par
- chleb
- parametr
- parametry
- część
- minęło
- Hasło
- Wzór
- wykonać
- na stałe
- wybierać
- plato
- Analiza danych Platona
- PlatoDane
- wtyczka
- wtyczki
- Post
- zapobiec
- poprzedni
- wygląda tak
- przetwarzanie
- produkować
- producent
- niska zabudowa
- zapewniać
- pod warunkiem,
- zapewnia
- Czytaj
- real
- w czasie rzeczywistym
- otrzymać
- rekord
- dokumentacja
- odnosi
- region
- zarejestrować
- zarejestrowany
- rejestr
- składnica
- reprezentowane
- Zasoby
- powraca
- Rola
- Zasada
- run
- bieganie
- taki sam
- skalowalny
- płynnie
- Szukaj
- sekund
- bezpieczne
- bezpieczeństwo
- senior
- wrażliwy
- oddzielny
- usługa
- Usługi
- zestaw
- w panelu ustawień
- powinien
- Prosty
- upraszczać
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Źródła
- specjalista
- specyficzny
- określony
- stos
- Startowy
- Rynek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- sklep
- strumień
- Streaming
- Strumienie
- Struktura
- odpowiedni
- Wspierający
- podpory
- synchronizacja
- system
- systemy
- stół
- cel
- zadania
- szablon
- test
- że
- Połączenia
- Źródło
- Im
- Te
- czas
- Czasochłonne
- Tytuł
- do
- aktualny
- transakcje
- SKRĘCAĆ
- typy
- dla
- niepożądany
- aktualizowanie
- posługiwać się
- Użytkownik
- wartość
- Wartości
- wersja
- sieć
- usługi internetowe
- który
- będzie
- okna
- w
- pracownik
- pracowników
- pracujący
- działa
- napisany
- Twój
- zefirnet