Znajdowanie podobnych kolumn w pliku a jezioro danych ma ważne zastosowania w czyszczeniu i adnotacji danych, dopasowywaniu schematów, odkrywaniu danych i analityce w wielu źródłach danych. Niezdolność do dokładnego wyszukiwania i analizowania danych z różnych źródeł stanowi potencjalny zabójca wydajności dla wszystkich, od analityków danych, badaczy medycznych, naukowców, po analityków finansowych i rządowych.
Konwencjonalne rozwiązania obejmują leksykalne wyszukiwanie słów kluczowych lub dopasowywanie wyrażeń regularnych, które są podatne na problemy z jakością danych, takie jak brak nazw kolumn lub różne konwencje nazewnictwa kolumn w różnych zbiorach danych (np. zip_code, zcode, postalcode).
W tym poście pokazujemy rozwiązanie do wyszukiwania podobnych kolumn na podstawie nazwy kolumny, zawartości kolumny lub obu. Rozwiązanie wykorzystuje przybliżone algorytmy najbliższych sąsiadów dostępne w Usługa Amazon OpenSearch aby wyszukać semantycznie podobne kolumny. Aby ułatwić wyszukiwanie, tworzymy reprezentacje cech (embeddings) dla poszczególnych kolumn w data lake przy użyciu wstępnie wytrenowanych modeli Transformer z biblioteka transformatorów zdań in Amazon Sage Maker. Na koniec, aby wchodzić w interakcje i wizualizować wyniki z naszego rozwiązania, budujemy interaktywne Strumieniowe działająca aplikacja internetowa AWS-Fargate.
Zaliczamy a samouczek kodu w celu wdrożenia zasobów w celu uruchomienia rozwiązania na przykładowych danych lub własnych danych.
Omówienie rozwiązania
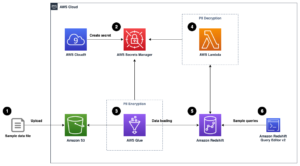
Poniższy diagram architektury ilustruje dwuetapowy przepływ pracy służący do znajdowania semantycznie podobnych kolumn. Pierwszy etap przebiega m Funkcje kroków AWS przepływ pracy, który tworzy osadzenie z kolumn tabelarycznych i buduje indeks wyszukiwania usługi OpenSearch. Drugi etap, czyli etap wnioskowania online, uruchamia aplikację Streamlit za pośrednictwem Fargate. Aplikacja internetowa gromadzi wejściowe zapytania wyszukiwania i pobiera z indeksu usługi OpenSearch przybliżone k-najbardziej podobnych kolumn do zapytania.

Rysunek 1. Architektura rozwiązania
Zautomatyzowany przepływ pracy przebiega w następujących krokach:
- Użytkownik przesyła tabelaryczne zestawy danych do pliku Usługa Amazon Simple Storage (Amazon S3), wiadro, które wywołuje AWS Lambda funkcja, która inicjuje przepływ pracy Step Functions.
- Przepływ pracy rozpoczyna się od Klej AWS zadanie, które konwertuje pliki CSV do Parkiet Apache Format danych.
- Zadanie SageMaker Processing tworzy osadzanie dla każdej kolumny przy użyciu wstępnie wyszkolonych modeli lub niestandardowych modeli osadzania kolumn. Zadanie SageMaker Processing zapisuje osadzenie kolumn dla każdej tabeli w Amazon S3.
- Funkcja Lambda tworzy domenę i klaster usługi OpenSearch w celu indeksowania osadzonych kolumn utworzonych w poprzednim kroku.
- Wreszcie wraz z Fargate wdrażana jest interaktywna aplikacja internetowa Streamlit. Aplikacja internetowa zapewnia użytkownikowi interfejs do wprowadzania zapytań w celu przeszukania domeny usługi OpenSearch w celu znalezienia podobnych kolumn.
Samouczek dotyczący kodu można pobrać ze strony GitHub aby wypróbować to rozwiązanie na przykładowych danych lub własnych danych. Instrukcje dotyczące sposobu wdrażania wymaganych zasobów dla tego samouczka są dostępne w witrynie Github.
Wymagania wstępne
Aby wdrożyć to rozwiązanie, potrzebujesz:
- An Konto AWS.
- Podstawowa znajomość usług AWS, takich jak Zestaw programistyczny AWS Cloud (AWS CDK), Lambda, usługa OpenSearch i przetwarzanie SageMaker.
- Tabelaryczny zestaw danych do tworzenia indeksu wyszukiwania. Możesz przynieść własne dane tabelaryczne lub pobrać przykładowe zestawy danych GitHub.
Zbuduj indeks wyszukiwania
Pierwszy etap buduje indeks wyszukiwarki kolumnowej. Poniższy rysunek ilustruje przepływ pracy Step Functions uruchamiający ten etap.

Rysunek 2 — przepływ pracy funkcji krokowych — wiele modeli osadzania
Zbiory danych
W tym poście tworzymy indeks wyszukiwania obejmujący ponad 400 kolumn z ponad 25 tabelarycznych zestawów danych. Zbiory danych pochodzą z następujących źródeł publicznych:
Aby zapoznać się z pełną listą tabel uwzględnionych w indeksie, zobacz samouczek dotyczący kodu GitHub.
Możesz przynieść własny zestaw danych tabelarycznych, aby rozszerzyć przykładowe dane lub zbudować własny indeks wyszukiwania. Dołączamy dwie funkcje Lambda, które inicjują przepływ pracy Step Functions w celu zbudowania indeksu wyszukiwania odpowiednio dla poszczególnych plików CSV lub partii plików CSV.
Przekształć plik CSV w parkiet
Surowe pliki CSV są konwertowane do formatu danych Parquet za pomocą kleju AWS. Parquet to zorientowany na kolumny format pliku preferowany w analizie dużych zbiorów danych, który zapewnia wydajną kompresję i kodowanie. W naszych eksperymentach format danych Parquet oferował znaczne zmniejszenie rozmiaru pamięci w porównaniu z nieprzetworzonymi plikami CSV. Użyliśmy również Parquet jako wspólnego formatu danych do konwersji innych formatów danych (na przykład JSON i NDJSON), ponieważ obsługuje on zaawansowane zagnieżdżone struktury danych.
Twórz osadzania kolumn tabelarycznych
Aby wyodrębnić osadzania dla poszczególnych kolumn tabeli w przykładowych tabelarycznych zestawach danych w tym poście, używamy następujących wstępnie wyszkolonych modeli z sentence-transformers biblioteka. Aby uzyskać informacje o dodatkowych modelach, zobacz Wstępnie wytrenowane modele.
Uruchomione zostanie zadanie przetwarzania SageMaker create_embeddings.py(kod) dla jednego modelu. W celu wyodrębnienia elementów osadzonych z wielu modeli przepływ pracy uruchamia równoległe zadania SageMaker Processing, jak pokazano w przepływie pracy Step Functions. Używamy modelu do stworzenia dwóch zestawów osadzeń:
- nazwa_kolumny_osadzenie – Osadzanie nazw kolumn (nagłówków)
- osadzenia_zawartości_kolumny – Średnie osadzenie wszystkich wierszy w kolumnie
Aby uzyskać więcej informacji na temat procesu osadzania kolumn, zobacz samouczek dotyczący kodu GitHub.
Alternatywą dla kroku SageMaker Processing jest utworzenie transformacji wsadowej SageMaker w celu osadzania kolumn w dużych zestawach danych. Wymagałoby to wdrożenia modelu w punkcie końcowym SageMaker. Aby uzyskać więcej informacji, zobacz Użyj transformacji wsadowej.
Osadzanie indeksów za pomocą usługi OpenSearch
W ostatnim kroku tego etapu funkcja Lambda dodaje osadzenie kolumn do przybliżonej usługi OpenSearch k-Nearest-Neighbor (kNN) indeks wyszukiwania. Każdy model ma przypisany własny indeks wyszukiwania. Aby uzyskać więcej informacji na temat przybliżonych parametrów indeksu wyszukiwania kNN, zobacz k-NN.
Wnioskowanie online i wyszukiwanie semantyczne za pomocą aplikacji internetowej
Drugi etap przepływu pracy uruchamia a Strumieniowe aplikacja internetowa, w której można wprowadzać dane wejściowe i wyszukiwać semantycznie podobne kolumny indeksowane w usłudze OpenSearch. Warstwa aplikacji wykorzystuje Moduł równoważenia obciążenia aplikacji, Fargate i Lambda. Infrastruktura aplikacji jest wdrażana automatycznie jako część rozwiązania.
Aplikacja umożliwia wprowadzenie danych wejściowych i wyszukiwanie semantycznie podobnych nazw kolumn, zawartości kolumn lub obu. Dodatkowo możesz wybrać model osadzania i liczbę najbliższych sąsiadów do zwrócenia z wyszukiwania. Aplikacja odbiera dane wejściowe, osadza je w określonym modelu i używa Wyszukiwanie kNN w usłudze OpenSearch aby wyszukać zaindeksowane osadzenie kolumn i znaleźć kolumny najbardziej podobne do podanego wejścia. Wyświetlane wyniki wyszukiwania obejmują nazwy tabel, nazwy kolumn i wyniki podobieństwa dla zidentyfikowanych kolumn, a także lokalizacje danych w Amazon S3 do dalszej eksploracji.
Poniższy rysunek przedstawia przykład aplikacji internetowej. W tym przykładzie wyszukaliśmy kolumny w naszym jeziorze danych, które mają podobne wartości Column Names (rodzaj ładunku) Do district (ładowność). Zastosowana aplikacja all-MiniLM-L6-v2 jak model osadzania i wrócił 10 (k) najbliżsi sąsiedzi z naszego indeksu usługi OpenSearch.
Aplikacja wróciła transit_district, city, borough, location jako cztery najbardziej podobne kolumny na podstawie danych zindeksowanych w usłudze OpenSearch. Ten przykład ilustruje zdolność podejścia wyszukiwania do identyfikowania semantycznie podobnych kolumn w zestawach danych.

Rysunek 3: Interfejs użytkownika aplikacji internetowej
Sprzątać
Aby usunąć zasoby utworzone przez AWS CDK w tym samouczku, uruchom następujące polecenie:
cdk destroy --allWnioski
W tym poście przedstawiliśmy kompleksowy przepływ pracy do budowy semantycznej wyszukiwarki kolumn tabelarycznych.
Już dziś zacznij korzystać z własnych danych, korzystając z naszego samouczka dotyczącego kodu dostępnego w witrynie GitHub. Jeśli potrzebujesz pomocy w przyspieszeniu korzystania z uczenia maszynowego w swoich produktach i procesach, skontaktuj się z Laboratorium rozwiązań do uczenia maszynowego Amazon Amazon.
O autorach
![]() Kachi Odoemene jest naukowcem stosowanym w AWS AI. Buduje rozwiązania AI/ML do rozwiązywania problemów biznesowych dla klientów AWS.
Kachi Odoemene jest naukowcem stosowanym w AWS AI. Buduje rozwiązania AI/ML do rozwiązywania problemów biznesowych dla klientów AWS.
![]() Taylora McNally'ego jest architektem głębokiego uczenia w Amazon Machine Learning Solutions Lab. Pomaga klientom z różnych branż budować rozwiązania wykorzystujące AI/ML na AWS. Lubi filiżankę dobrej kawy, przebywanie na świeżym powietrzu i czas z rodziną i energicznym psem.
Taylora McNally'ego jest architektem głębokiego uczenia w Amazon Machine Learning Solutions Lab. Pomaga klientom z różnych branż budować rozwiązania wykorzystujące AI/ML na AWS. Lubi filiżankę dobrej kawy, przebywanie na świeżym powietrzu i czas z rodziną i energicznym psem.
![]() Austina Welcha jest Data Scientist w Amazon ML Solutions Lab. Opracowuje niestandardowe modele głębokiego uczenia się, aby pomóc klientom AWS z sektora publicznego przyspieszyć wdrażanie sztucznej inteligencji i chmury. W wolnym czasie lubi czytać, podróżować i jiu-jitsu.
Austina Welcha jest Data Scientist w Amazon ML Solutions Lab. Opracowuje niestandardowe modele głębokiego uczenia się, aby pomóc klientom AWS z sektora publicznego przyspieszyć wdrażanie sztucznej inteligencji i chmury. W wolnym czasie lubi czytać, podróżować i jiu-jitsu.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- zdolność
- O nas
- nieobecny
- przyśpieszyć
- przyspieszenie
- dokładnie
- w poprzek
- Dodatkowy
- do tego
- Dodaje
- Przyjęcie
- zaawansowany
- AI
- AI / ML
- Wszystkie kategorie
- pozwala
- alternatywny
- Amazonka
- Uczenie maszynowe Amazon
- Laboratorium rozwiązań Amazon ML
- analitycy
- analityka
- w czasie rzeczywistym sprawiają,
- i
- Apache
- Zastosowanie
- aplikacje
- stosowany
- podejście
- architektura
- przydzielony
- zautomatyzowane
- automatycznie
- dostępny
- średni
- AWS
- Klej AWS
- na podstawie
- bo
- Duży
- Big Data
- przynieść
- budować
- Budowanie
- Buduje
- biznes
- Sprzątanie
- Chmura
- adopcja chmury
- Grupa
- kod
- Kawa
- zbiera
- Kolumna
- kolumny
- wspólny
- w porównaniu
- skontaktuj się
- zawartość
- Konwencje
- konwertować
- przeliczone
- Stwórz
- stworzony
- tworzy
- Kubek
- zwyczaj
- Klientów
- dane
- Analityka danych
- Jezioro danych
- jakość danych
- naukowiec danych
- zbiory danych
- głęboko
- głęboka nauka
- wykazać
- demonstruje
- rozwijać
- wdrażane
- wdrażanie
- zniszczyć
- oprogramowania
- rozwija się
- różne
- odkrycie
- różny
- inny
- Pies
- domena
- pobieranie
- każdy
- efektywność
- wydajny
- koniec końców
- Punkt końcowy
- silnik
- Eter (ETH)
- wszyscy
- przykład
- eksploracja
- wyciąg
- ułatwiać
- Znajomość
- członków Twojej rodziny
- Korzyści
- Postać
- filet
- Akta
- finał
- W końcu
- budżetowy
- Znajdź
- znalezieniu
- i terminów, a
- następujący
- format
- od
- pełny
- funkcjonować
- Funkcje
- dalej
- otrzymać
- dany
- dobry
- Rząd
- headers
- pomoc
- pomaga
- W jaki sposób
- How To
- HTML
- HTTPS
- zidentyfikowane
- zidentyfikować
- wdrożenia
- ważny
- in
- niemożność
- zawierać
- włączony
- wskaźnik
- indywidualny
- przemysłowa
- Informacja
- Infrastruktura
- zainicjować
- Inicjuje
- wkład
- instrukcje
- interakcji
- interaktywne
- Interfejs
- inwokuje
- angażować
- problemy
- IT
- Praca
- Oferty pracy
- json
- laboratorium
- jezioro
- duży
- warstwa
- nauka
- lewarowanie
- Biblioteka
- Lista
- załadować
- lokalizacji
- maszyna
- uczenie maszynowe
- dopasowywanie
- medyczny
- ML
- model
- modele
- jeszcze
- większość
- wielokrotność
- Nazwa
- Nazwy
- nazywania
- Potrzebować
- sąsiedzi
- numer
- oferowany
- Online
- Inne
- na zewnątrz
- własny
- Parallel
- parametry
- część
- plato
- Analiza danych Platona
- PlatoDane
- Proszę
- Post
- potencjał
- Korzystny
- przedstawione
- poprzedni
- problemy
- dochód
- wygląda tak
- procesów
- przetwarzanie
- Wytworzony
- Produkty
- zapewniać
- zapewnia
- publiczny
- jakość
- Surowy
- Czytający
- otrzymuje
- regularny
- reprezentuje
- wymagać
- wymagany
- Badacze
- Zasoby
- odpowiednio
- Efekt
- powrót
- run
- bieganie
- sagemaker
- Naukowiec
- Naukowcy
- Szukaj
- Wyszukiwarka
- poszukiwania
- druga
- sektor
- usługa
- Usługi
- Zestawy
- pokazane
- Targi
- znaczący
- podobny
- Prosty
- pojedynczy
- Rozmiar
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Źródła
- określony
- STAGE
- rozpoczęty
- Ewolucja krok po kroku
- Cel
- przechowywanie
- taki
- podpory
- wrażliwy
- stół
- Połączenia
- ich
- Przez
- czas
- do
- już dziś
- Przekształcać
- Transformatory
- Podróżowanie
- Tutorial
- posługiwać się
- Użytkownik
- Interfejs użytkownika
- różnorodny
- sieć
- Aplikacja internetowa
- który
- workflow
- by
- Twój
- zefirnet