Podczas wdrażania modelu dużego języka (LLM) specjaliści zajmujący się uczeniem maszynowym (ML) zazwyczaj zwracają uwagę na dwa pomiary wydajności obsługi modelu: opóźnienie definiowane przez czas potrzebny do wygenerowania pojedynczego tokenu oraz przepustowość definiowaną przez liczbę wygenerowanych tokenów na sekundę. Chociaż pojedyncze żądanie skierowane do wdrożonego punktu końcowego wykazywałoby przepustowość w przybliżeniu równą odwrotności opóźnienia modelu, nie musi tak być w przypadku jednoczesnego wysyłania wielu jednoczesnych żądań do punktu końcowego. Ze względu na techniki udostępniania modeli, takie jak ciągłe grupowanie współbieżnych żądań po stronie klienta, opóźnienia i przepustowość mają złożoną relację, która znacznie różni się w zależności od architektury modelu, konfiguracji obsługi, sprzętu typu instancji, liczby jednoczesnych żądań i różnic w ładunkach wejściowych, takich jak jako liczba żetonów wejściowych i żetonów wyjściowych.
W tym poście zbadano te relacje poprzez kompleksową analizę porównawczą LLM dostępnych w Amazon SageMaker JumpStart, w tym wariantów Llama 2, Falcon i Mistral. Dzięki SageMaker JumpStart specjaliści ML mogą wybierać spośród szerokiej gamy publicznie dostępnych modeli podstawowych, które można wdrożyć w dedykowanych Amazon Sage Maker instancje w środowisku izolowanym od sieci. Zapewniamy teoretyczne zasady dotyczące wpływu specyfikacji akceleratorów na testy porównawcze LLM. Pokazujemy również wpływ wdrożenia wielu instancji za jednym punktem końcowym. Na koniec przedstawiamy praktyczne zalecenia dotyczące dostosowania procesu wdrażania SageMaker JumpStart w celu dostosowania go do wymagań dotyczących opóźnień, przepustowości, kosztów i ograniczeń dostępnych typów instancji. Wszystkie wyniki testów porównawczych, a także zalecenia opierają się na wszechstronnym notatnik które możesz dostosować do swojego przypadku użycia.
Wdrożone testy porównawcze punktów końcowych
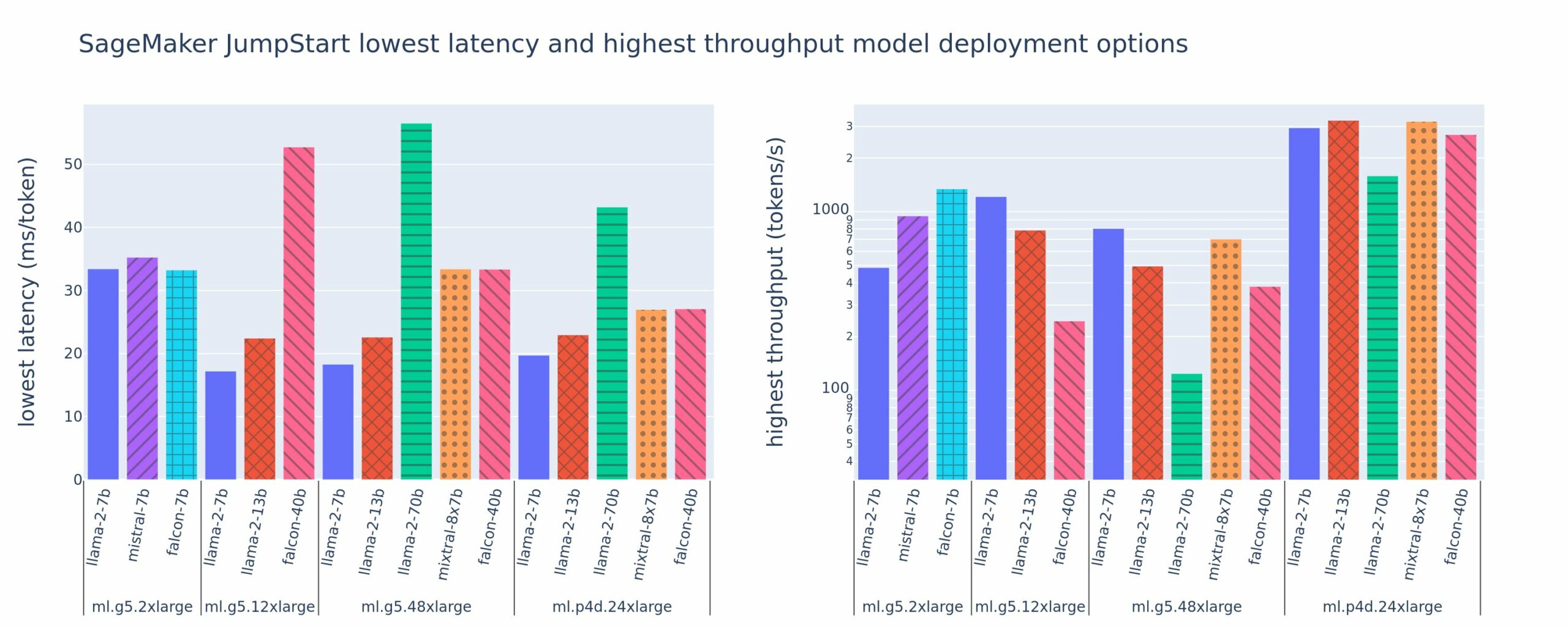
Na poniższej ilustracji przedstawiono najniższe opóźnienia (po lewej) i najwyższą przepływność (po prawej) dla konfiguracji wdrożenia w różnych typach modeli i typach wystąpień. Co ważne, każde z tych wdrożeń modeli korzysta z konfiguracji domyślnych dostarczonych przez SageMaker JumpStart, z uwzględnieniem żądanego identyfikatora modelu i typu instancji do wdrożenia.
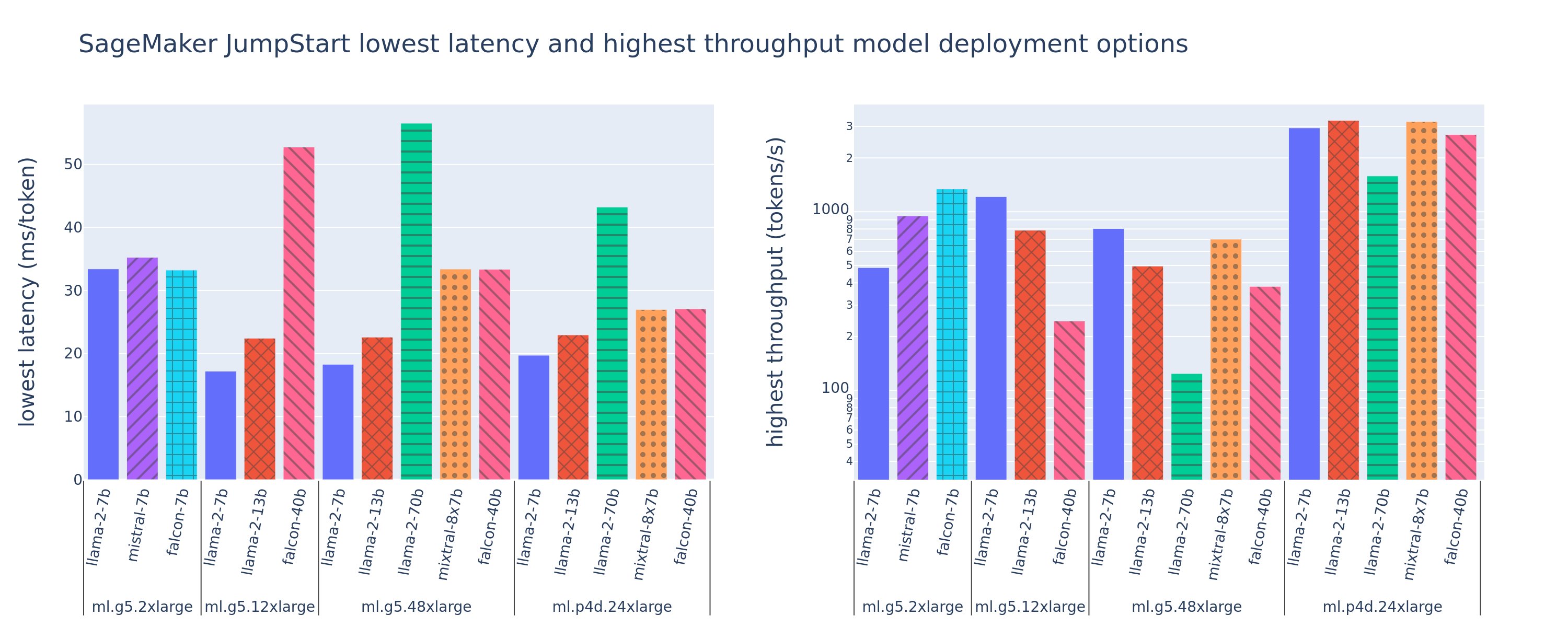
Te wartości opóźnień i przepływności odpowiadają ładunkom z 256 tokenami wejściowymi i 256 tokenami wyjściowymi. Konfiguracja o najniższym opóźnieniu ogranicza model obsługujący pojedyncze współbieżne żądanie, a konfiguracja o najwyższej przepustowości maksymalizuje możliwą liczbę jednoczesnych żądań. Jak widać z naszych testów porównawczych, zwiększenie liczby jednoczesnych żądań monotonicznie zwiększa przepustowość przy malejącej poprawie w przypadku dużych jednoczesnych żądań. Ponadto modele są w pełni dzielone na obsługiwane wystąpienia. Na przykład, ponieważ instancja ml.g5.48xlarge ma 8 procesorów graficznych, wszystkie modele SageMaker JumpStart korzystające z tej instancji są dzielone na fragmenty przy użyciu równoległości tensorów na wszystkich ośmiu dostępnych akceleratorach.
Możemy wyciągnąć kilka wniosków z tej liczby. Po pierwsze, nie wszystkie modele są obsługiwane we wszystkich instancjach; niektóre mniejsze modele, takie jak Falcon 7B, nie obsługują fragmentowania modelu, podczas gdy większe modele mają większe wymagania dotyczące zasobów obliczeniowych. Po drugie, wraz ze wzrostem fragmentowania wydajność zazwyczaj się poprawia, ale niekoniecznie musi się poprawiać w przypadku małych modeli. Dzieje się tak dlatego, że małe modele, takie jak 7B i 13B, powodują znaczne obciążenie komunikacyjne w przypadku podziału na zbyt wiele akceleratorów. Omówimy to bardziej szczegółowo później. Wreszcie instancje ml.p4d.24xlarge mają zwykle znacznie lepszą przepustowość ze względu na poprawę przepustowości pamięci A100 w porównaniu z procesorami graficznymi A10G. Jak omówimy później, decyzja o użyciu określonego typu instancji zależy od wymagań dotyczących wdrożenia, w tym od opóźnień, przepustowości i ograniczeń kosztowych.
Jak uzyskać najniższe opóźnienia i najwyższą przepustowość w konfiguracji? Zacznijmy od wykreślenia opóźnienia w funkcji przepustowości dla punktu końcowego Lamy 2 7B w instancji ml.g5.12xlarge dla ładunku zawierającego 256 tokenów wejściowych i 256 tokenów wyjściowych, jak widać na poniższej krzywej. Podobna krzywa istnieje dla każdego wdrożonego punktu końcowego LLM.

Wraz ze wzrostem współbieżności monotonicznie wzrasta również przepustowość i opóźnienia. Dlatego najniższy punkt opóźnienia występuje przy wartości równoczesnego żądania wynoszącej 1, a przepustowość systemu można w opłacalny sposób zwiększyć, zwiększając liczbę współbieżnych żądań. Na tej krzywej istnieje wyraźne „kolano”, w którym oczywiste jest, że wzrost przepustowości związany z dodatkową współbieżnością nie przewyższa związanego z tym wzrostu opóźnień. Dokładna lokalizacja tego kolana zależy od konkretnego przypadku; niektórzy praktycy mogą zdefiniować kolano w momencie przekroczenia wcześniej określonego wymagania dotyczącego opóźnienia (na przykład 100 ms/token), podczas gdy inni mogą stosować testy porównawcze testów obciążenia i metody teorii kolejkowania, takie jak reguła połowy opóźnienia, a jeszcze inni mogą używać teoretyczne specyfikacje akceleratora.
Zauważamy również, że maksymalna liczba jednoczesnych żądań jest ograniczona. Na powyższym rysunku śledzenie linii kończy się 192 współbieżnymi żądaniami. Źródłem tego ograniczenia jest limit czasu wywołania programu SageMaker, w przypadku którego punkty końcowe programu SageMaker przekraczają limit czasu odpowiedzi na wywołanie po 60 sekundach. To ustawienie jest specyficzne dla konta i nie można go konfigurować dla pojedynczego punktu końcowego. W przypadku LLM wygenerowanie dużej liczby tokenów wyjściowych może zająć sekundy lub nawet minuty. Dlatego duże ładunki wejściowe lub wyjściowe mogą powodować niepowodzenie żądań wywołania. Co więcej, jeśli liczba jednoczesnych żądań jest bardzo duża, dla wielu żądań czas oczekiwania w kolejce będzie długi, co skutkuje 60-sekundowym limitem czasu. Na potrzeby tego badania limit czasu jest używany do zdefiniowania maksymalnej przepustowości możliwej do wdrożenia modelu. Co ważne, chociaż punkt końcowy SageMaker może obsłużyć dużą liczbę jednoczesnych żądań bez przestrzegania limitu czasu odpowiedzi na wywołanie, warto zdefiniować maksymalną liczbę jednoczesnych żądań w odniesieniu do kolana na krzywej opóźnienia-przepustowości. Prawdopodobnie jest to moment, w którym zaczynasz rozważać skalowanie poziome, w którym pojedynczy punkt końcowy udostępnia wiele instancji z replikami modelu i równoważy obciążenie żądań przychodzących między replikami, aby obsługiwać więcej jednoczesnych żądań.
Idąc o krok dalej, poniższa tabela zawiera wyniki testów porównawczych dla różnych konfiguracji modelu Lama 2 7B, w tym różną liczbę tokenów wejściowych i wyjściowych, typy instancji i liczbę jednoczesnych żądań. Należy zauważyć, że na poprzednim rysunku przedstawiono tylko jeden wiersz tej tabeli.
| . | Przepustowość (tokeny/s) | Opóźnienie (ms/token) | ||||||||||||||||||
| Równoczesne żądania | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Całkowita liczba żetonów: 512, Liczba żetonów wyjściowych: 256 | ||||||||||||||||||||
| ml.g5.2xduży | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xduży | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xduży | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xduży | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Całkowita liczba żetonów: 4096, Liczba żetonów wyjściowych: 256 | ||||||||||||||||||||
| ml.g5.2xduży | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xduży | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xduży | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xduży | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
W tych danych obserwujemy kilka dodatkowych prawidłowości. Zwiększanie rozmiaru kontekstu zwiększa opóźnienia i zmniejsza przepustowość. Na przykład na ml.g5.2xlarge z współbieżnością 1 przepustowość wynosi 30 tokenów/s, gdy całkowita liczba tokenów wynosi 512, w porównaniu z 20 tokenami/s, jeśli całkowita liczba tokenów wynosi 4,096. Dzieje się tak dlatego, że przetwarzanie większych danych wejściowych zajmuje więcej czasu. Widzimy również, że zwiększenie wydajności procesora graficznego i shardingu wpływa na maksymalną przepustowość i maksymalną liczbę obsługiwanych jednoczesnych żądań. Tabela pokazuje, że Llama 2 7B ma znacząco różne wartości maksymalnej przepustowości dla różnych typów instancji, a te maksymalne wartości przepustowości występują przy różnych wartościach równoczesnych żądań. Te cechy skłoniłyby specjalistę ML do uzasadnienia kosztu jednej instancji w porównaniu z drugą. Na przykład, biorąc pod uwagę wymagania dotyczące małego opóźnienia, specjalista może wybrać instancję ml.g5.12xlarge (4 procesory graficzne A10G) zamiast instancji ml.g5.2xlarge (1 procesor graficzny A10G). W przypadku wymagań dotyczących dużej przepustowości użycie instancji ml.p4d.24xlarge (8 procesorów graficznych A100) z pełnym fragmentowaniem byłoby uzasadnione tylko w przypadku dużej współbieżności. Należy jednak zauważyć, że często korzystne jest ładowanie wielu komponentów wnioskowania modelu 7B w pojedynczej instancji ml.p4d.24xlarge; taka obsługa wielu modeli została omówiona w dalszej części tego postu.
Powyższe obserwacje wykonano dla modelu Lamy 2 7B. Jednak podobne wzorce pozostają prawdziwe również w przypadku innych modeli. Najważniejszym wnioskiem jest to, że opóźnienia i przepustowość zależą od ładunku, typu instancji i liczby jednoczesnych żądań, dlatego konieczne będzie znalezienie idealnej konfiguracji dla konkretnej aplikacji. Aby wygenerować poprzednie liczby dla swojego przypadku użycia, możesz uruchomić pliklinked notatnik, gdzie możesz skonfigurować tę analizę testu obciążenia dla swojego modelu, typu instancji i ładunku.
Znaczenie specyfikacji akceleratorów
Wybór odpowiedniego sprzętu do wnioskowania LLM zależy w dużej mierze od konkretnych przypadków użycia, celów związanych z doświadczeniem użytkownika i wybranego LLM. W tej sekcji podjęto próbę zrozumienia kolana na krzywej opóźnienia-przepustowości w odniesieniu do zasad wysokiego poziomu opartych na specyfikacjach akceleratora. Same zasady nie wystarczą do podjęcia decyzji: potrzebne są prawdziwe punkty odniesienia. Termin urządzenie jest tu używany w celu uwzględnienia wszystkich akceleratorów sprzętowych ML. Twierdzimy, że załamanie krzywej opóźnienia i przepustowości wynika z jednego z dwóch czynników:
- Akcelerator wyczerpał pamięć do buforowania macierzy KV, dlatego kolejne żądania umieszczane są w kolejce
- Akcelerator nadal ma wolną pamięć na pamięć podręczną KV, ale wykorzystuje wystarczająco duży rozmiar wsadu, aby czas przetwarzania był zależny od opóźnienia operacji obliczeniowych, a nie przepustowości pamięci
Zazwyczaj wolimy ograniczać się przez drugi czynnik, ponieważ oznacza to, że zasoby akceleratora są nasycone. Zasadniczo maksymalizujesz zasoby, za które zapłaciłeś. Przeanalizujmy to twierdzenie bardziej szczegółowo.
Buforowanie KV i pamięć urządzenia
Standardowe mechanizmy uwagi transformatora obliczają uwagę dla każdego nowego tokena w porównaniu ze wszystkimi poprzednimi tokenami. Większość nowoczesnych serwerów ML buforuje klucze uwagi i wartości w pamięci urządzenia (DRAM), aby uniknąć ponownego obliczania na każdym kroku. Nazywa się to Pamięć podręczna KVi rośnie wraz z wielkością partii i długością sekwencji. Określa, ile żądań użytkowników może być obsługiwanych równolegle i określa załamanie krzywej opóźnienia-przepustowości, jeśli reżim związany z obliczeniami w drugim wspomnianym wcześniej scenariuszu nie został jeszcze spełniony, biorąc pod uwagę dostępną pamięć DRAM. Poniższy wzór jest przybliżonym przybliżeniem maksymalnego rozmiaru pamięci podręcznej KV.

W tym wzorze B oznacza wielkość partii, a N oznacza liczbę akceleratorów. Na przykład model Llama 2 7B w FP16 (2 bajty/parametr) obsługiwany na procesorze graficznym A10G (24 GB DRAM) zużywa około 14 GB, pozostawiając 10 GB na pamięć podręczną KV. Po podłączeniu pełnej długości kontekstu modelu (N = 4096) i pozostałych parametrów (n_layers=32, n_kv_attention_heads=32 i d_attention_head=128) to wyrażenie pokazuje, że jesteśmy ograniczeni do obsługi wsadowej wielkości czterech użytkowników równolegle ze względu na ograniczenia DRAM . Jeśli zaobserwujesz odpowiednie testy porównawcze w poprzedniej tabeli, jest to dobre przybliżenie obserwowanego kolana na tej krzywej opóźnienia-przepustowości. Metody takie jak zgrupowana uwaga na zapytanie (GQA) może zmniejszyć rozmiar pamięci podręcznej KV, w przypadku GQA o ten sam współczynnik, co zmniejsza liczbę głowic KV.
Intensywność arytmetyczna i przepustowość pamięci urządzenia
Wzrost mocy obliczeniowej akceleratorów ML przekroczył przepustowość ich pamięci, co oznacza, że mogą one wykonywać znacznie więcej obliczeń na każdym bajcie danych w czasie potrzebnym na uzyskanie dostępu do tego bajtu.
Połączenia intensywność arytmetycznalub stosunek operacji obliczeniowych do dostępu do pamięci, w przypadku operacji określa się, czy jest ona ograniczona przepustowością pamięci lub mocą obliczeniową wybranego sprzętu. Na przykład procesor graficzny A10G (rodzina instancji g5) z 70 TFLOPS FP16 i przepustowością 600 GB/s może obliczyć około 116 operacji/bajt. Procesor graficzny A100 (rodzina typów instancji p4d) może obliczyć około 208 operacji/bajt. Jeśli intensywność arytmetyczna modelu transformatora jest niższa od tej wartości, jest on związany z pamięcią; jeśli jest powyżej, jest związany z obliczeniami. Mechanizm uwagi dla Lamy 2 7B wymaga 62 operacji/bajt dla partii o rozmiarze 1 (wyjaśnienie można znaleźć w Przewodnik po wnioskowaniu i wydajności LLM), co oznacza, że jest związany z pamięcią. Kiedy mechanizm uwagi jest związany z pamięcią, drogie FLOPY pozostają niewykorzystane.
Istnieją dwa sposoby lepszego wykorzystania akceleratora i zwiększenia intensywności arytmetycznej: zmniejszenie wymaganego dostępu do pamięci dla operacji (to właśnie FlashUwaga skupia się na) lub zwiększyć wielkość partii. Jednakże możemy nie być w stanie zwiększyć rozmiaru partii na tyle, aby osiągnąć reżim związany z obliczeniami, jeśli nasza pamięć DRAM jest zbyt mała, aby pomieścić odpowiednią pamięć podręczną KV. Zgrubne przybliżenie krytycznego rozmiaru partii B* oddzielającego reżimy związane z obliczeniami od reżimów związanych z pamięcią dla standardowego wnioskowania dekodera GPT opisano za pomocą następującego wyrażenia, gdzie A_mb to przepustowość pamięci akceleratora, A_f to FLOPS akceleratora, a N to liczba akceleratorów. Ten krytyczny rozmiar partii można wyznaczyć, sprawdzając, gdzie czas dostępu do pamięci jest równy czasowi obliczeń. Odnosić się do ten wpis na blogu aby lepiej zrozumieć Równanie 2 i jego założenia.

Jest to ten sam stosunek operacji do bajtów, który obliczyliśmy wcześniej dla A10G, więc krytyczny rozmiar wsadu na tym procesorze graficznym wynosi 116. Jednym ze sposobów podejścia do tego teoretycznego, krytycznego rozmiaru wsadu jest zwiększenie fragmentowania modelu i podzielenie pamięci podręcznej na większą liczbę N akceleratorów. To skutecznie zwiększa pojemność pamięci podręcznej KV, a także rozmiar partii powiązanej z pamięcią.
Kolejną zaletą dzielenia modelu na fragmenty jest podzielenie parametrów modelu i ładowania danych na N akceleratorów. Ten typ fragmentowania jest rodzajem równoległości modelu, określanym również jako równoległość tensorowa. Naiwnie, łącznie jest N razy większa przepustowość pamięci i moc obliczeniowa. Zakładając brak jakichkolwiek narzutów (komunikacja, oprogramowanie itd.), zmniejszyłoby to opóźnienie dekodowania na token o N, jeśli jesteśmy ograniczeni pamięcią, ponieważ opóźnienie dekodowania tokenu w tym trybie jest ograniczone czasem potrzebnym do załadowania modelu wagi i pamięć podręczna. Jednak w prawdziwym życiu zwiększenie stopnia fragmentowania skutkuje zwiększoną komunikacją między urządzeniami w celu współużytkowania aktywacji pośrednich w każdej warstwie modelu. Szybkość komunikacji jest ograniczona przepustowością połączenia między urządzeniami. Trudno dokładnie oszacować jego wpływ (szczegóły zob Model równoległości), ale może to w końcu przestać przynosić korzyści lub pogorszyć wydajność — dotyczy to szczególnie mniejszych modeli, ponieważ mniejsze transfery danych prowadzą do niższych szybkości transferu.
Aby porównać akceleratory ML na podstawie ich specyfikacji, zalecamy wykonanie poniższych czynności. Najpierw oblicz przybliżoną wielkość partii krytycznej dla każdego typu akceleratora zgodnie z drugim równaniem oraz wielkość pamięci podręcznej KV dla wielkości partii krytycznej zgodnie z pierwszym równaniem. Następnie można użyć dostępnej pamięci DRAM w akceleratorze, aby obliczyć minimalną liczbę akceleratorów wymaganych do dopasowania pamięci podręcznej KV i parametrów modelu. Decydując się na wiele akceleratorów, należy nadać priorytet akceleratorom według najniższego kosztu na GB/s przepustowości pamięci. Na koniec przeprowadź test porównawczy tych konfiguracji i sprawdź, jaki jest najlepszy koszt/token dla górnej granicy pożądanego opóźnienia.
Wybierz konfigurację wdrożenia punktu końcowego
Wiele LLM dystrybuowanych przez SageMaker JumpStart korzysta z wnioskowanie dotyczące generowania tekstu (TGI) Pojemnik SageMakera do serwowania modelek. W poniższej tabeli omówiono sposób dostosowywania różnych parametrów udostępniania modelu, aby wpłynąć na obsługę modelu, co wpływa na krzywą opóźnienia-przepustowość, lub chronić punkt końcowy przed żądaniami, które mogłyby przeciążyć punkt końcowy. Są to podstawowe parametry, których można użyć do skonfigurowania wdrożenia punktu końcowego dla danego przypadku użycia. O ile nie określono inaczej, używamy wartości domyślnej parametry ładunku generowania tekstu i Zmienne środowiskowe TGI.
| Zmienna środowiskowa | Opis | Wartość domyślna programu SageMaker JumpStart |
| Modelowe konfiguracje udostępniania | . | . |
MAX_BATCH_PREFILL_TOKENS |
Ogranicza liczbę tokenów w operacji wstępnego napełniania. Ta operacja generuje pamięć podręczną KV dla nowej sekwencji monitów wejściowych. Wymaga dużej ilości pamięci i jest ograniczony do obliczeń, więc ta wartość ogranicza liczbę tokenów dozwolonych w pojedynczej operacji wstępnego wypełniania. Kroki dekodowania dla innych zapytań są wstrzymywane podczas wstępnego wypełniania. | 4096 (domyślnie TGI) lub maksymalna obsługiwana długość kontekstu specyficzna dla modelu (dostarczona aplikacja SageMaker JumpStart), w zależności od tego, która wartość jest większa. |
MAX_BATCH_TOTAL_TOKENS |
Kontroluje maksymalną liczbę tokenów, które można uwzględnić w partii podczas dekodowania lub pojedynczego przejścia do przodu przez model. W idealnym przypadku ustawienie to maksymalizuje wykorzystanie całego dostępnego sprzętu. | Nie określono (domyślnie TGI). TGI ustawi tę wartość w odniesieniu do pozostałej pamięci CUDA podczas rozgrzewania modelu. |
SM_NUM_GPUS |
Liczba fragmentów do użycia. Oznacza to liczbę procesorów graficznych użytych do uruchomienia modelu przy użyciu równoległości tensorów. | Zależne od instancji (dostarczony program SageMaker JumpStart). Dla każdej obsługiwanej instancji danego modelu SageMaker JumpStart zapewnia najlepsze ustawienie równoległości tensorów. |
| Konfiguracje chroniące Twój punkt końcowy (ustaw je dla swojego przypadku użycia) | . | . |
MAX_TOTAL_TOKENS |
Ogranicza to budżet pamięci pojedynczego żądania klienta, ograniczając liczbę tokenów w sekwencji wejściowej oraz liczbę tokenów w sekwencji wyjściowej (tzw. max_new_tokens parametr ładunku). |
Maksymalna obsługiwana długość kontekstu specyficzna dla modelu. Na przykład 4096 dla Lamy 2. |
MAX_INPUT_LENGTH |
Określa maksymalną dozwoloną liczbę tokenów w sekwencji wejściowej dla pojedynczego żądania klienta. Zwiększając tę wartość, należy wziąć pod uwagę następujące kwestie: dłuższe sekwencje wejściowe wymagają więcej pamięci, co wpływa na ciągłe przetwarzanie wsadowe, a wiele modeli ma obsługiwaną długość kontekstu, której nie należy przekraczać. | Maksymalna obsługiwana długość kontekstu specyficzna dla modelu. Na przykład 4095 dla Lamy 2. |
MAX_CONCURRENT_REQUESTS |
Maksymalna liczba jednoczesnych żądań dozwolona przez wdrożony punkt końcowy. Nowe żądania przekraczające ten limit natychmiast spowodują błąd przeciążenia modelu, aby zapobiec małym opóźnieniom w przypadku bieżących żądań przetwarzania. | 128 (domyślnie TGI). To ustawienie pozwala uzyskać wysoką przepustowość w różnych przypadkach użycia, ale należy je odpowiednio przypiąć, aby ograniczyć błędy przekroczenia limitu czasu wywołania SageMaker. |
Serwer TGI korzysta z ciągłego przetwarzania wsadowego, które dynamicznie grupuje współbieżne żądania w celu udostępnienia pojedynczego przebiegu przekazywania wnioskowania modelu. Istnieją dwa rodzaje przekazów do przodu: wstępne wypełnienie i dekodowanie. Każde nowe żądanie musi uruchomić pojedyncze wstępne wypełnienie w celu zapełnienia pamięci podręcznej KV dla tokenów sekwencji wejściowej. Po zapełnieniu pamięci podręcznej KV, dekodowanie w przód powoduje wykonanie pojedynczego przewidywania następnego tokenu dla wszystkich żądań wsadowych, które jest iteracyjnie powtarzane w celu wytworzenia sekwencji wyjściowej. Gdy do serwera wysyłane są nowe żądania, następny etap dekodowania musi poczekać, aby dla nowych żądań mógł zostać uruchomiony etap wstępnego wypełniania. Musi to nastąpić, zanim te nowe żądania zostaną uwzględnione w kolejnych, ciągłych etapach dekodowania wsadowego. Ze względu na ograniczenia sprzętowe ciągłe przetwarzanie wsadowe używane do dekodowania może nie obejmować wszystkich żądań. W tym momencie żądania trafiają do kolejki przetwarzania, a opóźnienie wnioskowania zaczyna znacznie wzrastać przy jedynie niewielkim wzroście przepustowości.
Możliwe jest rozdzielenie analiz porównawczych opóźnień LLM na opóźnienie wstępnego wypełnienia, opóźnienie dekodowania i opóźnienie kolejki. Czas zużywany przez każdy z tych komponentów ma zasadniczo różny charakter: wstępne wypełnienie to jednorazowe obliczenie, dekodowanie odbywa się raz dla każdego tokenu w sekwencji wyjściowej, a kolejkowanie obejmuje procesy wsadowe serwerów. Gdy przetwarzanych jest wiele jednoczesnych żądań, trudno jest rozdzielić opóźnienia od każdego z tych komponentów, ponieważ opóźnienia doświadczane przez dowolne żądanie klienta obejmują opóźnienia w kolejce wynikające z konieczności wstępnego wypełnienia nowych współbieżnych żądań, a także opóźnienia w kolejce wynikające z włączenia żądania w procesach dekodowania wsadowego. Z tego powodu ten post skupia się na opóźnieniach przetwarzania typu end-to-end. Kolano krzywej opóźnienia-przepustowości występuje w punkcie nasycenia, w którym opóźnienia w kolejce zaczynają znacząco rosnąć. Zjawisko to występuje w przypadku dowolnego serwera wnioskowania modelu i jest zależne od specyfikacji akceleratora.
Typowe wymagania podczas wdrażania obejmują spełnienie minimalnej wymaganej przepływności, maksymalnego dozwolonego opóźnienia, maksymalnego kosztu na godzinę i maksymalnego kosztu wygenerowania 1 miliona tokenów. Należy uzależnić te wymagania od ładunków reprezentujących żądania użytkowników końcowych. Projekt spełniający te wymagania powinien uwzględniać wiele czynników, w tym konkretną architekturę modelu, rozmiar modelu, typy instancji i liczbę instancji (skalowanie poziome). W poniższych sekcjach skupiamy się na wdrażaniu punktów końcowych, aby zminimalizować opóźnienia, zmaksymalizować przepustowość i zminimalizować koszty. W tej analizie uwzględniono łącznie 512 tokenów i 256 tokenów wyjściowych.
Minimalizuj opóźnienia
Opóźnienie jest ważnym wymaganiem w wielu przypadkach użycia w czasie rzeczywistym. W poniższej tabeli przyjrzymy się minimalnym opóźnieniom dla każdego modelu i każdego typu instancji. Minimalne opóźnienie można osiągnąć poprzez ustawienie MAX_CONCURRENT_REQUESTS = 1.
| Minimalne opóźnienie (ms/token) | |||||
| ID modelu | ml.g5.2xduży | ml.g5.12xduży | ml.g5.48xduży | ml.p4d.24xduży | ml.p4de.24xlarge |
| Lama 2 7B | 33 | 17 | 18 | 20 | - |
| Lama 2 7B Czat | 33 | 17 | 18 | 20 | - |
| Lama 2 13B | - | 22 | 23 | 23 | - |
| Lama 2 13B Czat | - | 23 | 23 | 23 | - |
| Lama 2 70B | - | - | 57 | 43 | - |
| Lama 2 70B Czat | - | - | 57 | 45 | - |
| Mistrala 7B | 35 | - | - | - | - |
| Instrukcja Mistrala 7B | 35 | - | - | - | - |
| Mieszany 8x7B | - | - | 33 | 27 | - |
| Sokół 7B | 33 | - | - | - | - |
| Instrukcja Falcona 7B | 33 | - | - | - | - |
| Sokół 40B | - | 53 | 33 | 27 | - |
| Instrukcja Falcona 40B | - | 53 | 33 | 28 | - |
| Sokół 180B | - | - | - | - | 42 |
| Czat dotyczący Falcona 180B | - | - | - | - | 42 |
Aby osiągnąć minimalne opóźnienie modelu, możesz użyć następującego kodu, zastępując żądany identyfikator modelu i typ instancji:
Należy pamiętać, że liczby opóźnień zmieniają się w zależności od liczby tokenów wejściowych i wyjściowych. Jednak proces wdrażania pozostaje taki sam, z wyjątkiem zmiennych środowiskowych MAX_INPUT_TOKENS i MAX_TOTAL_TOKENS. W tym miejscu te zmienne środowiskowe są ustawione, aby pomóc zagwarantować wymagania dotyczące opóźnienia punktu końcowego, ponieważ większe sekwencje wejściowe mogą naruszać wymagania dotyczące opóźnienia. Należy pamiętać, że SageMaker JumpStart udostępnia już inne optymalne zmienne środowiskowe podczas wybierania typu instancji; na przykład użycie ml.g5.12xlarge ustawi SM_NUM_GPUS do 4 w środowisku modelu.
Maksymalizuj przepustowość
W tej sekcji maksymalizujemy liczbę generowanych tokenów na sekundę. Zwykle osiąga się to przy maksymalnej liczbie prawidłowych jednoczesnych żądań dla modelu i typu instancji. W poniższej tabeli przedstawiono przepustowość osiągniętą przy największej wartości jednoczesnego żądania osiągniętej przed przekroczeniem limitu czasu wywołania SageMaker dla dowolnego żądania.
| Maksymalna przepustowość (tokeny/s), równoczesne żądania | |||||
| ID modelu | ml.g5.2xduży | ml.g5.12xduży | ml.g5.48xduży | ml.p4d.24xduży | ml.p4de.24xlarge |
| Lama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Lama 2 7B Czat | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Lama 2 13B Czat | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Lama 2 70B Czat | - | - | 114 (16) | 1546 (256) | - |
| Mistrala 7B | 947 (64) | - | - | - | - |
| Instrukcja Mistrala 7B | 986 (128) | - | - | - | - |
| Mieszany 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Sokół 7B | 1340 (128) | - | - | - | - |
| Instrukcja Falcona 7B | 1313 (128) | - | - | - | - |
| Sokół 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Instrukcja Falcona 40B | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Sokół 180B | - | - | - | - | 1100 (128) |
| Czat dotyczący Falcona 180B | - | - | - | - | 1081 (128) |
Aby osiągnąć maksymalną przepustowość modelu, możesz użyć następującego kodu:
Należy pamiętać, że maksymalna liczba jednoczesnych żądań zależy od typu modelu, typu instancji, maksymalnej liczby tokenów wejściowych i maksymalnej liczby tokenów wyjściowych. Dlatego należy ustawić te parametry przed ustawieniem MAX_CONCURRENT_REQUESTS.
Należy również pamiętać, że użytkownik zainteresowany minimalizacją opóźnień często jest w sprzeczności z użytkownikiem zainteresowanym maksymalizacją przepustowości. Ten pierwszy jest zainteresowany odpowiedziami w czasie rzeczywistym, drugi natomiast jest zainteresowany przetwarzaniem wsadowym tak, aby kolejka punktów końcowych była zawsze zapełniona, minimalizując w ten sposób przestoje przetwarzania. Użytkownicy, którzy chcą zmaksymalizować przepustowość w zależności od wymagań dotyczących opóźnień, często są zainteresowani operacją na kolanie krzywej opóźnienia-przepustowości.
Minimalizuj koszty
Pierwsza opcja minimalizacji kosztów polega na minimalizacji kosztu na godzinę. Dzięki temu możesz wdrożyć wybrany model w instancji SageMaker przy najniższym koszcie na godzinę. Aby poznać ceny instancji SageMaker w czasie rzeczywistym, zobacz Cennik Amazon SageMaker. Ogólnie rzecz biorąc, domyślny typ instancji dla SageMaker JumpStart LLM jest najtańszą opcją wdrożenia.
Druga opcja minimalizacji kosztów polega na minimalizacji kosztów wygenerowania 1 miliona tokenów. Jest to prosta transformacja tabeli, którą omawialiśmy wcześniej, mająca na celu maksymalizację przepustowości, w której można najpierw obliczyć czas w godzinach potrzebny do wygenerowania 1 miliona tokenów (1e6 / przepustowość / 3600). Możesz następnie pomnożyć ten czas, aby wygenerować 1 milion tokenów przez cenę za godzinę określonej instancji SageMaker.
Należy pamiętać, że instancje o najniższym koszcie na godzinę to nie to samo, co instancje o najniższym koszcie wygenerowania 1 miliona tokenów. Na przykład, jeśli żądania wywołania są sporadyczne, optymalna może być instancja o najniższym koszcie na godzinę, podczas gdy w scenariuszach ograniczania przepustowości bardziej odpowiednia może być najniższa cena wygenerowania miliona tokenów.
Równoległość tensora a kompromis między wieloma modelami
We wszystkich poprzednich analizach rozważaliśmy wdrożenie repliki pojedynczego modelu ze stopniem równoległości tensora równym liczbie procesorów graficznych w typie instancji wdrożeniowej. Jest to domyślne zachowanie programu SageMaker JumpStart. Jednakże, jak wcześniej zauważono, dzielenie modelu na fragmenty może poprawić opóźnienia i przepustowość modelu tylko do pewnego limitu, powyżej którego czas obliczeń dominują wymagania dotyczące komunikacji między urządzeniami. Oznacza to, że często korzystne jest wdrożenie wielu modeli o niższym stopniu równoległości tensora w jednej instancji zamiast jednego modelu o wyższym stopniu równoległości tensora.
Tutaj wdrażamy punkty końcowe Lamy 2 7B i 13B w instancjach ml.p4d.24xlarge ze stopniami tensora równoległego (TP) wynoszącymi 1, 2, 4 i 8. Dla przejrzystości zachowania modelu każdy z tych punktów końcowych ładuje tylko jeden model.
| . | Przepustowość (tokeny/s) | Opóźnienie (ms/token) | ||||||||||||||||||
| Równoczesne żądania | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Stopień TP | Lama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Nasze poprzednie analizy wykazały już znaczną przewagę przepustowości w instancjach ml.p4d.24xlarge, co często przekłada się na lepszą wydajność pod względem kosztów wygenerowania 1 miliona tokenów w porównaniu z rodziną instancji g5 w warunkach dużego jednoczesnego obciążenia żądań. Ta analiza wyraźnie pokazuje, że należy rozważyć kompromis między fragmentowaniem modelu a replikacją modelu w ramach jednej instancji; oznacza to, że model w pełni podzielony na fragmenty nie jest zazwyczaj najlepszym sposobem wykorzystania zasobów obliczeniowych ml.p4d.24xlarge dla rodzin modeli 7B i 13B. W rzeczywistości w przypadku rodziny modeli 7B najlepszą przepustowość uzyskuje się dla repliki pojedynczego modelu ze stopniem równoległości tensora wynoszącym 4 zamiast 8.
Stąd można ekstrapolować, że konfiguracja o najwyższej przepustowości dla modelu 7B obejmuje stopień równoległości tensora równy 1 z ośmioma replikami modelu, a konfiguracja o najwyższej przepustowości dla modelu 13B to prawdopodobnie stopień równoległości tensora równy 2 z czterema replikami modelu. Aby dowiedzieć się więcej o tym, jak to osiągnąć, zobacz Zmniejsz koszty wdrażania modeli średnio o 50%, korzystając z najnowszych funkcji Amazon SageMaker, co demonstruje użycie punktów końcowych opartych na komponentach wnioskowania. Ze względu na techniki równoważenia obciążenia, routing serwerów i współdzielenie zasobów procesora, możesz nie osiągnąć w pełni poprawy przepustowości dokładnie równej liczbie replik pomnożonej przez przepustowość pojedynczej repliki.
Skalowanie poziome
Jak zauważono wcześniej, każde wdrożenie punktu końcowego ma ograniczenie liczby jednoczesnych żądań w zależności od liczby tokenów wejściowych i wyjściowych, a także typu instancji. Jeśli nie spełnia to wymagań dotyczących przepływności lub współbieżnych żądań, możesz skalować w górę, aby wykorzystać więcej niż jedno wystąpienie za wdrożonym punktem końcowym. SageMaker automatycznie równoważy obciążenie zapytań pomiędzy instancjami. Na przykład poniższy kod wdraża punkt końcowy obsługiwany przez trzy instancje:
Poniższa tabela przedstawia wzrost przepustowości jako współczynnik liczby instancji dla modelu Lama 2 7B.
| . | . | Przepustowość (tokeny/s) | Opóźnienie (ms/token) | ||||||||||||||
| . | Równoczesne żądania | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Liczba wystąpień | Typ wystąpienia | Całkowita liczba żetonów: 512, Liczba żetonów wyjściowych: 256 | |||||||||||||||
| 1 | ml.g5.2xduży | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xduży | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xduży | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Warto zauważyć, że kolano na krzywej opóźnienia-przepustowości przesuwa się w prawo, ponieważ większa liczba wystąpień może obsłużyć większą liczbę jednoczesnych żądań w punkcie końcowym z wieloma wystąpieniami. W tej tabeli wartość równoczesnych żądań dotyczy całego punktu końcowego, a nie liczby jednoczesnych żądań odbieranych przez każdą instancję.
Możesz także użyć automatycznego skalowania, funkcji monitorowania obciążeń i dynamicznego dostosowywania pojemności, aby utrzymać stałą i przewidywalną wydajność przy możliwie najniższych kosztach. To wykracza poza zakres tego wpisu. Aby dowiedzieć się więcej o autoskalowaniu, zobacz Konfigurowanie punktów końcowych wnioskowania z automatycznym skalowaniem w Amazon SageMaker.
Wywołaj punkt końcowy ze współbieżnymi żądaniami
Załóżmy, że masz dużą partię zapytań, których chcesz użyć do wygenerowania odpowiedzi z wdrożonego modelu w warunkach dużej przepływności. Na przykład w poniższym bloku kodu kompilujemy listę 1,000 ładunków, przy czym każdy ładunek żąda wygenerowania 100 tokenów. W sumie żądamy wygenerowania 100,000 XNUMX tokenów.
Podczas wysyłania dużej liczby żądań do interfejsu API środowiska wykonawczego SageMaker mogą wystąpić błędy ograniczania przepustowości. Aby temu zaradzić, możesz utworzyć niestandardowego klienta wykonawczego SageMaker, który zwiększa liczbę ponownych prób. Wynikowy obiekt sesji SageMaker możesz dostarczyć do pliku JumpStartModel konstruktor lub sagemaker.predictor.retrieve_default jeśli chcesz dołączyć nowy predyktor do już wdrożonego punktu końcowego. W poniższym kodzie używamy tego obiektu sesji podczas wdrażania modelu Lamy 2 z domyślnymi konfiguracjami SageMaker JumpStart:
Ten wdrożony punkt końcowy ma MAX_CONCURRENT_REQUESTS = 128 domyślnie. W następnym bloku używamy biblioteki współbieżnych kontraktów futures do iteracji po wywołaniu punktu końcowego dla wszystkich ładunków ze 128 wątkami roboczymi. Punkt końcowy przetworzy maksymalnie 128 jednoczesnych żądań, a za każdym razem, gdy żądanie zwróci odpowiedź, moduł wykonujący natychmiast wyśle nowe żądanie do punktu końcowego.
Powoduje to wygenerowanie łącznie 100,000 1255 tokenów z przepustowością 5.2 tokenów/s w pojedynczej instancji ml.g80xlarge. Przetwarzanie zajmuje około XNUMX sekund.
Należy zauważyć, że ta wartość przepustowości znacznie różni się od maksymalnej przepustowości dla Lamy 2 7B na ml.g5.2xlarge w poprzednich tabelach tego wpisu (486 tokenów/s przy 64 równoczesnych żądaniach). Dzieje się tak dlatego, że ładunek wejściowy wykorzystuje 8 tokenów zamiast 256, liczba tokenów wyjściowych wynosi 100 zamiast 256, a mniejsza liczba tokenów pozwala na 128 równoczesnych żądań. To ostatnie przypomnienie, że wszystkie wartości opóźnień i przepustowości zależą od ładunku! Zmiana liczby tokenów ładunku będzie miała wpływ na procesy wsadowe podczas udostępniania modelu, co z kolei będzie miało wpływ na pojawiające się czasy wstępnego wypełniania, dekodowania i kolejki dla aplikacji.
Wnioski
W tym poście przedstawiliśmy testy porównawcze SageMaker JumpStart LLM, w tym Llama 2, Mistral i Falcon. Zaprezentowaliśmy także przewodnik dotyczący optymalizacji opóźnień, przepustowości i kosztów konfiguracji wdrożenia punktu końcowego. Możesz zacząć od uruchomienia pliku powiązany notatnik do porównania Twojego przypadku użycia.
O autorach
 dr Kyle Ulrich jest naukowcem stosowanym w zespole Amazon SageMaker JumpStart. Jego zainteresowania badawcze obejmują skalowalne algorytmy uczenia maszynowego, wizję komputerową, szeregi czasowe, nieparametrykę Bayesa i procesy Gaussa. Jego doktorat uzyskał na Duke University i opublikował artykuły w czasopismach NeurIPS, Cell i Neuron.
dr Kyle Ulrich jest naukowcem stosowanym w zespole Amazon SageMaker JumpStart. Jego zainteresowania badawcze obejmują skalowalne algorytmy uczenia maszynowego, wizję komputerową, szeregi czasowe, nieparametrykę Bayesa i procesy Gaussa. Jego doktorat uzyskał na Duke University i opublikował artykuły w czasopismach NeurIPS, Cell i Neuron.
 Dr. Vivek Madan jest naukowcem w zespole Amazon SageMaker JumpStart. Uzyskał doktorat na Uniwersytecie Illinois w Urbana-Champaign i był badaczem podoktoranckim w Georgia Tech. Jest aktywnym badaczem w dziedzinie uczenia maszynowego i projektowania algorytmów. Publikował artykuły na konferencjach EMNLP, ICLR, COLT, FOCS i SODA.
Dr. Vivek Madan jest naukowcem w zespole Amazon SageMaker JumpStart. Uzyskał doktorat na Uniwersytecie Illinois w Urbana-Champaign i był badaczem podoktoranckim w Georgia Tech. Jest aktywnym badaczem w dziedzinie uczenia maszynowego i projektowania algorytmów. Publikował artykuły na konferencjach EMNLP, ICLR, COLT, FOCS i SODA.
 Dr Ashish Khetan jest starszym naukowcem w Amazon SageMaker JumpStart i pomaga opracowywać algorytmy uczenia maszynowego. Stopień doktora uzyskał na Uniwersytecie Illinois w Urbana-Champaign. Jest aktywnym badaczem w dziedzinie uczenia maszynowego i wnioskowania statystycznego. Opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
Dr Ashish Khetan jest starszym naukowcem w Amazon SageMaker JumpStart i pomaga opracowywać algorytmy uczenia maszynowego. Stopień doktora uzyskał na Uniwersytecie Illinois w Urbana-Champaign. Jest aktywnym badaczem w dziedzinie uczenia maszynowego i wnioskowania statystycznego. Opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
 Joao Moura jest starszym architektem rozwiązań specjalistycznych AI/ML w AWS. João pomaga klientom AWS – od małych start-upów po duże przedsiębiorstwa – efektywnie szkolić i wdrażać duże modele, a także szerzej budować platformy ML na AWS.
Joao Moura jest starszym architektem rozwiązań specjalistycznych AI/ML w AWS. João pomaga klientom AWS – od małych start-upów po duże przedsiębiorstwa – efektywnie szkolić i wdrażać duże modele, a także szerzej budować platformy ML na AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- Zdolny
- O nas
- powyżej
- akcelerator
- akceleratory
- akceptacja
- dostęp
- wykonać
- Stosownie
- Osiągać
- osiągnięty
- w poprzek
- aktywacje
- aktywny
- przystosować
- Dodatkowy
- do tego
- dostosować
- Zalety
- oddziaływać
- Po
- przed
- agregat
- AI / ML
- algorytm
- Algorytmy
- wyrównać
- Wszystkie kategorie
- dopuszczać
- dozwolony
- pozwala
- sam
- już
- również
- Chociaż
- zawsze
- Amazonka
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- ilość
- an
- analizuje
- analiza
- i
- Inne
- każdy
- api
- Zastosowanie
- stosowany
- podejście
- właściwy
- przybliżony
- w przybliżeniu
- architektura
- SĄ
- AS
- powiązany
- Założenia
- At
- dołączać
- Próby
- Uwaga
- automatycznie
- dostępny
- średni
- uniknąć
- AWS
- b
- salda
- równoważenie
- przepustowość
- na podstawie
- Gruntownie
- partie
- Bayesian
- BE
- bo
- staje się
- zanim
- zachowanie
- za
- jest
- uwierzyć
- Benchmark
- Benchmarkingu
- Benchmarki
- korzystny
- korzyści
- Korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Poza
- Blokować
- Blog
- związany
- szeroki
- szeroko
- budżet
- budować
- ale
- by
- Pamięć podręczna
- obliczać
- obliczony
- nazywa
- CAN
- Może uzyskać
- zdolność
- Pojemność
- Czapki
- który
- walizka
- Etui
- Spowodować
- komórka
- pewien
- zmiana
- wymiana pieniędzy
- Charakterystyka
- Dodaj
- wybrany
- klarowność
- wyraźnie
- klient
- kod
- Komunikacja
- porównać
- kompleks
- składniki
- wszechstronny
- obliczenia
- obliczeniowy
- moc obliczeniowa
- obliczenia
- obliczać
- komputer
- Wizja komputerowa
- równoległy
- warunek
- Warunki
- konferencje
- systemu
- Rozważać
- za
- rozważa
- Ograniczenia
- spożywane
- zawiera
- kontekst
- ciągły
- bez przerwy
- Odpowiedni
- Koszty:
- Koszty:
- liczyć
- CPU
- Stwórz
- krytyczny
- surowy
- Aktualny
- krzywa
- zwyczaj
- Klientów
- dane
- Decydowanie
- decyzja
- Rozszyfrowanie
- spadek
- zmniejsza
- dedykowane
- Domyślnie
- określić
- zdefiniowane
- Definiuje
- Stopień
- wykazać
- demonstruje
- zależny
- W zależności
- zależy
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- wdrożenia
- wdraża się
- głębokość
- Pochodny
- opisane
- Wnętrze
- życzenia
- detal
- detale
- Ustalać
- określa
- rozwijać
- urządzenie
- urządzenia
- różne
- trudny
- zmniejsza się
- dyskutować
- omówione
- odrębny
- dystrybuowane
- Nie
- dominować
- nie
- przestojów
- dr
- napęd
- napędzany
- jazdy
- z powodu
- Książę
- uniwersytet książęcy
- podczas
- dynamicznie
- każdy
- Wcześniej
- faktycznie
- skutecznie
- osiem
- bądź
- objąć
- spotkanie
- koniec końców
- Punkt końcowy
- Punkty końcowe
- kończy się
- dość
- Wchodzę
- przedsiębiorstwa
- Cały
- Środowisko
- równy
- Równa się
- błąd
- Błędy
- szczególnie
- oszacowanie
- Eter (ETH)
- Parzyste
- ostatecznie
- Każdy
- dokładnie
- przykład
- prace
- Z wyjątkiem
- pokazać
- istnieje
- drogi
- doświadczenie
- doświadczony
- wyjaśnienie
- odkryj
- odkrywa
- wyrażenie
- fakt
- czynnik
- Czynniki
- FAIL
- sokół
- rodzin
- członków Twojej rodziny
- wykonalny
- Cecha
- Korzyści
- kilka
- Postać
- finał
- W końcu
- Znajdź
- znalezieniu
- i terminów, a
- dopasować
- Skupiać
- koncentruje
- następujący
- W razie zamówieenia projektu
- Dawny
- formuła
- Naprzód
- Fundacja
- cztery
- od
- pełny
- w pełni
- zasadniczo
- dalej
- Ponadto
- Futures
- Wzrost
- Zyski
- Ogólne
- Generować
- wygenerowane
- generuje
- generujący
- generacja
- otrzymać
- dany
- Gole
- dobry
- got
- GPU
- GPU
- większy
- Rośnie
- Wzrost
- gwarancja
- osłona
- poprowadzi
- uchwyt
- sprzęt komputerowy
- Have
- he
- głowice
- ciężko
- pomoc
- pomaga
- tutaj
- Wysoki
- na wysokim szczeblu
- wyższy
- Najwyższa
- jego
- przytrzymaj
- Poziomy
- godzina
- GODZINY
- W jaki sposób
- How To
- Jednak
- HTTPS
- i
- ICLR
- ID
- idealny
- idealnie
- zidentyfikować
- if
- Illinois
- natychmiast
- Rezultat
- Oddziaływania
- importować
- ważny
- co ważne
- podnieść
- poprawa
- ulepszenia
- poprawia
- in
- zawierać
- włączony
- Włącznie z
- włączenie
- Przybywający
- Zwiększać
- wzrosła
- Zwiększenia
- wzrastający
- indywidualny
- wkład
- Wejścia
- przykład
- instancje
- zamiast
- zainteresowany
- zainteresowania
- Pośredni
- najnowszych
- dotyczy
- IT
- JEGO
- jpg
- usprawiedliwiony
- Klawisze
- Uprzejmy
- Kyle
- język
- duży
- Duże przedsiębiorstwa
- większe
- największym
- Utajenie
- później
- firmy
- warstwa
- prowadzić
- UCZYĆ SIĘ
- nauka
- pozostawiając
- lewo
- Długość
- Biblioteka
- życie
- lubić
- Prawdopodobnie
- LIMIT
- ograniczenie
- Ograniczony
- Limity
- Linia
- Lista
- Lama
- załadować
- załadunek
- lokalizacja
- dłużej
- Popatrz
- niski
- niższy
- najniższy
- maszyna
- uczenie maszynowe
- zrobiony
- utrzymać
- robić
- wiele
- Maksymalizuj
- maksymalizuje
- maksymalizacji
- maksymalny
- Może..
- znaczenie
- znaczy
- Pomiary
- mechanizm
- Mechanizmy
- Poznaj nasz
- Pamięć
- wzmiankowany
- spełnione
- metody
- może
- milion
- zminimalizować
- minimalizowanie
- minimum
- moll
- minuty
- Złagodzić
- ML
- Moda
- model
- modele
- Nowoczesne technologie
- monitor
- jeszcze
- większość
- wielokrotność
- musi
- Natura
- koniecznie
- niezbędny
- Potrzebować
- NeuroIPS
- Nowości
- Następny
- Nie
- szczególnie
- noty
- zauważyć
- numer
- z naszej
- przedmiot
- obserwacje
- obserwować
- zauważony
- uzyskać
- oczywista
- występować
- występujący
- Szansa
- of
- często
- on
- ONE
- tylko
- operacyjny
- działanie
- operacje
- Optymalny
- Optymalizacja
- Option
- or
- zamówienie
- Inne
- Pozostałe
- Inaczej
- ludzkiej,
- wydajność
- koniec
- Papiery
- Parallel
- parametr
- parametry
- szczególny
- przechodzić
- przebiegi
- wzory
- pauza
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonuje
- PhD
- zjawisko
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- plus
- punkt
- biedny
- zaludniony
- możliwy
- Post
- power
- Praktyczny
- poprzedzający
- precyzyjnie
- przewidzieć
- Możliwy do przewidzenia
- przepowiednia
- Urządzenie prognozujące
- woleć
- przedstawione
- zapobiec
- poprzedni
- poprzednio
- Cena
- wycena
- pierwotny
- Zasady
- Priorytet
- wygląda tak
- obrobiony
- procesów
- przetwarzanie
- produkować
- chronić
- zapewniać
- pod warunkiem,
- zapewnia
- publicznie
- opublikowany
- cel
- zapytania
- podnieść
- ceny
- raczej
- stosunek
- dosięgnąć
- real
- prawdziwe życie
- w czasie rzeczywistym
- powód
- otrzymuje
- polecić
- zalecenia
- zmniejszyć
- zmniejsza
- odnosić się
- , o którym mowa
- reżim
- reżimy
- związek
- Relacje
- pozostawać
- pozostały
- szczątki
- przypomnienie
- powtórzony
- odpowiedzieć
- replikacja
- raport
- reprezentować
- zażądać
- z prośbą
- wywołań
- wymagać
- wymagany
- wymaganie
- wymagania
- Wymaga
- Badania naukowe
- badacz
- Zasób
- Zasoby
- poszanowanie
- odpowiedź
- Odpowiedzi
- wynikły
- Efekt
- powraca
- prawo
- Routing
- RZĄD
- Zasada
- run
- bieganie
- sagemaker
- taki sam
- skalowalny
- Skala
- skalowaniem
- scenariusz
- scenariusze
- Naukowiec
- zakres
- druga
- sekund
- Sekcja
- działy
- widzieć
- widziany
- wybierać
- wybrany
- wybierając
- wybór
- wysłać
- wysyłanie
- senior
- rozsądek
- wysłany
- oddzielny
- Sekwencja
- Serie
- służył
- serwer
- serwery
- Usługi
- służąc
- Sesja
- zestaw
- ustawienie
- rozdrobnione
- sharding
- Share
- dzielenie
- Przesunięcia
- powinien
- pokazał
- Targi
- znaczący
- znacznie
- podobny
- Prosty
- jednocześnie
- pojedynczy
- Rozmiar
- mały
- mniejszy
- So
- Tworzenie
- Rozwiązania
- kilka
- Źródło
- specjalista
- specyficzny
- Specyfikacje
- określony
- okular
- prędkość
- dzielić
- sporadyczny
- standard
- początek
- rozpoczęty
- rozpocznie
- Startups
- statystyczny
- stały
- Ewolucja krok po kroku
- Cel
- Nadal
- Stop
- Badanie
- kolejny
- znaczny
- taki
- odpowiedni
- wsparcie
- Utrzymany
- system
- stół
- krawiectwo
- Brać
- Takeaways
- trwa
- zespół
- tech
- Techniki
- Tendencję
- semestr
- REGULAMIN
- test
- niż
- że
- Połączenia
- Źródło
- ich
- następnie
- teoretyczny
- teoria
- Tam.
- a tym samym
- w związku z tym
- Te
- one
- rzeczy
- to
- tych
- trzy
- Przez
- wydajność
- czas
- Szereg czasowy
- czasy
- do
- razem
- żeton
- Żetony
- także
- Kwota produktów:
- tp
- wyśledzić
- Pociąg
- przenieść
- transfery
- Transformacja
- transformator
- prawdziwy
- SKRĘCAĆ
- drugiej
- rodzaj
- typy
- zazwyczaj
- dla
- zrozumieć
- zrozumienie
- uniwersytet
- Stosowanie
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Doświadczenie użytkownika
- Użytkownicy
- zastosowania
- za pomocą
- wykorzystać
- ważny
- wartość
- Wartości
- wariacje
- różnorodność
- zweryfikować
- wszechstronny
- początku.
- przez
- wizja
- vs
- czekać
- chcieć
- ciepły
- była
- Droga..
- sposoby
- we
- sieć
- usługi internetowe
- DOBRZE
- były
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- ilekroć
- natomiast
- który
- Podczas
- KIM
- będzie
- w
- w ciągu
- bez
- Praca
- pracownik
- by
- jeszcze
- wydajność
- ty
- Twój
- zefirnet