Żyjemy w epoce danych i spostrzeżeń w czasie rzeczywistym, napędzanych przez aplikacje do strumieniowego przesyłania danych o niskim opóźnieniu. Dziś każdy oczekuje spersonalizowanego doświadczenia w dowolnej aplikacji, a organizacje nieustannie wprowadzają innowacje, aby zwiększyć szybkość działania biznesowego i podejmowania decyzji. Ilość generowanych danych wrażliwych na upływ czasu szybko rośnie, wraz z wprowadzaniem różnych formatów danych w nowych firmach i przypadkach zastosowań klientów. Dlatego tak ważne jest, aby organizacje korzystały z skalowalnej i niezawodnej infrastruktury do strumieniowego przesyłania danych charakteryzującej się niskimi opóźnieniami, aby móc dostarczać aplikacje biznesowe działające w czasie rzeczywistym i zapewniać klientom lepszą obsługę.
To pierwszy post z serii blogów, która oferuje typowe wzorce architektoniczne w budowaniu infrastruktur przesyłania strumieniowego danych w czasie rzeczywistym przy użyciu strumieni danych Kinesis dla szerokiego zakresu przypadków użycia. Ma na celu zapewnienie platformy do tworzenia aplikacji do przesyłania strumieniowego o niskim opóźnieniu w chmurze AWS Strumienie danych Amazon Kinesis i Specjalnie zaprojektowane usługi analizy danych AWS.
W tym poście dokonamy przeglądu typowych wzorców architektonicznych dwóch przypadków użycia: analizy danych szeregów czasowych i mikrousług sterowanych zdarzeniami. W kolejnym poście z naszej serii przyjrzymy się wzorcom architektonicznym w budowaniu potoków przesyłania strumieniowego dla pulpitów BI w czasie rzeczywistym, agenta contact center, danych księgowych, spersonalizowanych rekomendacji w czasie rzeczywistym, analityki logów, danych IoT, przechwytywania danych zmian i rzeczywistych -czasowe dane marketingowe. Wszystkie te wzorce architektury są zintegrowane ze strumieniami danych Amazon Kinesis.
Przesyłanie strumieniowe w czasie rzeczywistym za pomocą strumieni danych Kinesis
Amazon Kinesis Data Streams to działająca w chmurze, bezserwerowa usługa przesyłania strumieniowego danych, która ułatwia przechwytywanie, przetwarzanie i przechowywanie danych w czasie rzeczywistym w dowolnej skali. Dzięki Kinesis Data Streams możesz zbierać i przetwarzać setki gigabajtów danych na sekundę z setek tysięcy źródeł, co pozwala łatwo pisać aplikacje przetwarzające informacje w czasie rzeczywistym. Zebrane dane są dostępne w ciągu milisekund, co pozwala na wykorzystanie analiz w czasie rzeczywistym, takich jak pulpity nawigacyjne w czasie rzeczywistym, wykrywanie anomalii w czasie rzeczywistym i dynamiczne ceny. Domyślnie dane w strumieniu danych Kinesis są przechowywane przez 24 godziny z opcją wydłużenia okresu przechowywania danych do 365 dni. Jeśli klienci chcą przetwarzać te same dane w czasie rzeczywistym za pomocą wielu aplikacji, mogą skorzystać z funkcji Enhanced Fan-Out (EFO). Przed wprowadzeniem tej funkcji każda aplikacja zużywająca dane ze strumienia udostępniała dane wyjściowe z szybkością 2 MB/sekundę/fragment. Konfigurując konsumentów strumienia tak, aby korzystali z ulepszonego rozdzielania, każdy odbiorca danych otrzymuje dedykowaną przepustowość odczytu o szybkości 2 MB/s na fragment, co jeszcze bardziej zmniejsza opóźnienia w pobieraniu danych.
Aby zapewnić wysoką dostępność i trwałość, Kinesis Data Streams osiąga wysoką trwałość poprzez synchroniczną replikację przesyłanych strumieniowo danych w trzech strefach dostępności w regionie AWS i daje możliwość przechowywania danych do 365 dni. Ze względów bezpieczeństwa strumienie danych Kinesis zapewniają szyfrowanie po stronie serwera, dzięki czemu można spełnić rygorystyczne wymagania dotyczące zarządzania danymi, szyfrując dane w spoczynku i punkty końcowe interfejsu Amazon Virtual Private Cloud (VPC), aby zachować prywatność ruchu między Amazon VPC i strumieniami danych Kinesis.
Kinesis Data Streams ma natywną integrację z innymi usługami AWS, takimi jak Klej AWS i Most zdarzeń Amazona do tworzenia aplikacji do przesyłania strumieniowego w czasie rzeczywistym na platformie AWS. Dodatkowe szczegóły można znaleźć w artykule Integracje strumieni danych Amazon Kinesis.
Nowoczesna architektura strumieniowania danych z Kinesis Data Streams
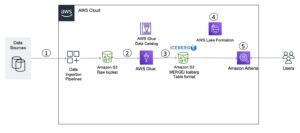
Nowoczesną architekturę danych strumieniowych z Kinesis Data Streams można zaprojektować jako stos pięciu warstw logicznych; każda warstwa składa się z wielu specjalnie zaprojektowanych komponentów, które spełniają określone wymagania, jak pokazano na poniższym schemacie:
Architektura składa się z następujących kluczowych elementów:
- Źródła strumieniowe – Twoje źródło danych przesyłanych strumieniowo obejmuje źródła danych, takie jak dane dotyczące strumienia kliknięć, czujniki, media społecznościowe, urządzenia Internetu rzeczy (IoT), pliki dziennika generowane za pomocą aplikacji internetowych i mobilnych oraz urządzenia mobilne, które generują dane częściowo ustrukturyzowane i nieustrukturyzowane w postaci ciągłych strumieni z dużą prędkością.
- Przetwarzanie strumieniowe – Warstwa pozyskiwania strumieni jest odpowiedzialna za pozyskiwanie danych do warstwy przechowywania strumieni. Zapewnia możliwość gromadzenia danych z dziesiątek tysięcy źródeł danych i ich pozyskiwania w czasie rzeczywistym. Możesz skorzystać z Kinesis SDK do pozyskiwania danych strumieniowych za pośrednictwem interfejsów API, Biblioteka producentów Kinesis do tworzenia wydajnych i długotrwałych producentów transmisji strumieniowych, lub a Środek kinezy do gromadzenia zestawu plików i przyjmowania ich do strumieni danych Kinesis. Dodatkowo można skorzystać z wielu gotowych integracji jak np Usługa migracji baz danych AWS (AWS DMS), Amazon DynamoDB, Rdzeń IoT AWS do pozyskiwania danych w sposób bez użycia kodu. Możesz także pozyskiwać dane z platform innych firm, takich jak Apache Spark i Apache Kafka Connect
- Przechowywanie strumieniowe – Strumienie danych Kinesis oferują dwa tryby obsługi przepustowości danych: na żądanie i udostępniane. Tryb na żądanie, będący obecnie wyborem domyślnym, umożliwia elastyczne skalowanie w celu absorbowania zmiennej przepustowości, dzięki czemu klienci nie muszą martwić się zarządzaniem pojemnością i płaceniem za przepustowość danych. Tryb na żądanie automatycznie zwiększa dwukrotnie pojemność strumienia w stosunku do historycznego maksymalnego poboru danych, aby zapewnić wystarczającą pojemność na wypadek nieoczekiwanych skoków poboru danych. Alternatywnie klienci, którzy chcą szczegółowej kontroli nad zasobami strumieniowymi, mogą skorzystać z trybu udostępnionego i proaktywnie skalować w górę i w dół liczbę fragmentów, aby spełnić wymagania dotyczące przepustowości. Ponadto Kinesis Data Streams może domyślnie przechowywać dane przesyłane strumieniowo do 2 godzin, ale może to wydłużyć się do 24 lub 7 dni w zależności od przypadków użycia. Wiele aplikacji może korzystać z tego samego strumienia.
- Przetwarzanie strumieniowe – Warstwa przetwarzania strumienia jest odpowiedzialna za przekształcanie danych w stan nadający się do wykorzystania poprzez sprawdzanie poprawności danych, czyszczenie, normalizację, transformację i wzbogacanie. Rekordy przesyłane strumieniowo są odczytywane w kolejności ich tworzenia, co pozwala na analizę w czasie rzeczywistym, tworzenie aplikacji sterowanych zdarzeniami lub przesyłanie strumieniowe ETL (wyodrębnianie, przekształcanie i ładowanie). Możesz użyć Usługa zarządzana przez Amazon dla Apache Flink do złożonego przetwarzania danych strumieniowych, AWS Lambda do bezstanowego przetwarzania danych strumieniowych oraz Klej AWS & Amazon EMR do obliczeń w czasie zbliżonym do rzeczywistego. Za pomocą narzędzia można także tworzyć niestandardowe aplikacje konsumenckie Biblioteka Konsumencka Kinesis, który zajmie się wieloma złożonymi zadaniami związanymi z przetwarzaniem rozproszonym.
- Miejsce docelowe - Warstwa docelowa przypomina celowo zbudowane miejsce docelowe, w zależności od przypadku użycia. Możesz przesyłać strumieniowo dane bezpośrednio do Amazonka Przesunięcie ku czerwieni do hurtowni danych i Amazon EventBridge do tworzenia aplikacji sterowanych zdarzeniami. Możesz także użyć Wąż strażacki Amazon Kinesis Data do integracji przesyłania strumieniowego, w której można przetwarzać strumień światła za pomocą AWS Lambda, a następnie dostarczać przetworzone przesyłanie strumieniowe do miejsc docelowych, takich jak Amazon S3 jezioro danych, usługa OpenSearch do analityki operacyjnej, hurtownia danych Redshift, bazy danych No-SQL, takie jak Amazon DynamoDB i relacyjne bazy danych, takie jak Amazon RDS do wykorzystywania strumieni w czasie rzeczywistym do aplikacji biznesowych. Miejscem docelowym może być aplikacja sterowana zdarzeniami, umożliwiająca korzystanie z pulpitów nawigacyjnych w czasie rzeczywistym, podejmowanie automatycznych decyzji na podstawie przetworzonych danych przesyłanych strumieniowo, wprowadzanie zmian w czasie rzeczywistym i nie tylko.
Architektura analizy w czasie rzeczywistym dla szeregów czasowych
Dane szeregów czasowych to sekwencja punktów danych zarejestrowanych w przedziale czasu w celu pomiaru zdarzeń zmieniających się w czasie. Przykładami są zmiany cen akcji w czasie, strumienie kliknięć na stronach internetowych i dzienniki urządzeń w czasie. Klienci mogą używać danych szeregów czasowych do monitorowania zmian w czasie, dzięki czemu mogą wykrywać anomalie, identyfikować wzorce i analizować wpływ czasu na określone zmienne. Dane szeregów czasowych są zwykle generowane z wielu źródeł w dużych ilościach i muszą być gromadzone w sposób opłacalny w czasie zbliżonym do rzeczywistego.
Zazwyczaj istnieją trzy główne cele, które klienci chcą osiągnąć podczas przetwarzania danych szeregów czasowych:
- Uzyskuj w czasie rzeczywistym wgląd w wydajność systemu i wykrywaj anomalie
- Zrozumienie zachowań użytkowników końcowych w celu śledzenia trendów i tworzenia zapytań/tworzenia wizualizacji na podstawie tych spostrzeżeń
- Korzystaj z trwałego rozwiązania do przechowywania danych, które umożliwia pozyskiwanie i przechowywanie zarówno danych archiwalnych, jak i często używanych.
Dzięki Kinesis Data Streams klienci mogą w sposób ciągły przechwytywać terabajty danych szeregów czasowych z tysięcy źródeł w celu czyszczenia, wzbogacania, przechowywania, analizy i wizualizacji.
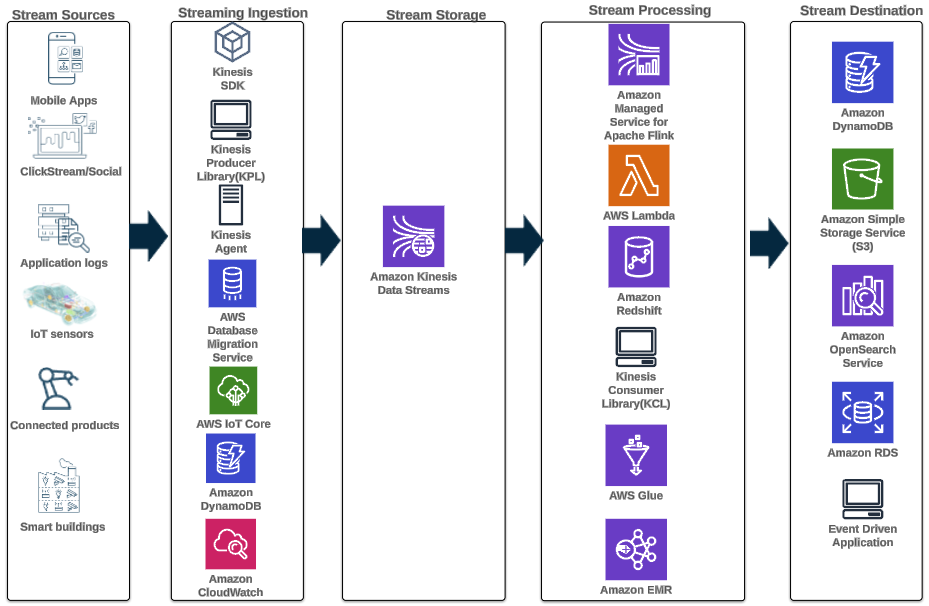
Poniższy wzorzec architektury ilustruje, w jaki sposób można przeprowadzić analizę danych szeregów czasowych w czasie rzeczywistym za pomocą strumieni danych Kinesis:
Kroki przepływu pracy są następujące:
- Pozyskiwanie i przechowywanie danych – Strumienie danych Kinesis mogą w sposób ciągły przechwytywać i przechowywać terabajty danych z tysięcy źródeł.
- Przetwarzanie strumieniowe – Aplikacja stworzona za pomocą Usługa zarządzana przez Amazon dla Apache Flink może odczytywać rekordy ze strumienia danych, aby wykryć i wyczyścić wszelkie błędy w danych szeregów czasowych oraz wzbogacić dane o określone metadane w celu optymalizacji analityki operacyjnej. Korzystanie ze strumienia danych w środku ma tę zaletę, że pozwala na jednoczesne wykorzystanie danych szeregów czasowych w innych procesach i rozwiązaniach. Następnie z tymi zdarzeniami wywoływana jest funkcja Lambda, która może wykonywać obliczenia szeregów czasowych w pamięci.
- Kierunki – Po oczyszczeniu i wzbogaceniu można przesyłać strumieniowo przetworzone dane szeregów czasowych Strumień czasu Amazona baza danych do tworzenia dashboardów i analiz w czasie rzeczywistym lub przechowywana w bazach danych, takich jak DynamoDB, na potrzeby zapytań użytkownika końcowego. Surowe dane można przesyłać strumieniowo do Amazon S3 w celu archiwizacji.
- Wizualizacja i zdobywanie spostrzeżeń – Klienci mogą wysyłać zapytania, wizualizować i tworzyć alerty za pomocą Usługa zarządzana przez Amazon dla Grafana. Grafana obsługuje źródła danych będące zapleczem do przechowywania danych szeregów czasowych. Aby uzyskać dostęp do danych z Timestream, musisz zainstalować wtyczkę Timestream dla Grafana. Użytkownicy końcowi mogą wysyłać zapytania do danych z tabeli DynamoDB za pomocą Brama Amazon API działając jako pełnomocnik.
Odnosić się do Przetwarzanie w czasie zbliżonym do rzeczywistego za pomocą Amazon Kinesis, Amazon Timestream i Grafana prezentuje bezserwerowy potok przesyłania strumieniowego do przetwarzania i przechowywania danych telemetrycznych IoT urządzeń w magazynie danych zoptymalizowanym pod kątem szeregów czasowych, takim jak Amazon Timestream.
Wzbogacanie i odtwarzanie danych w czasie rzeczywistym na potrzeby mikrousług pozyskiwania zdarzeń
Mikrousługi to architektoniczne i organizacyjne podejście do tworzenia oprogramowania, w którym oprogramowanie składa się z małych niezależnych usług komunikujących się za pośrednictwem dobrze zdefiniowanych interfejsów API. Budując mikroserwisy sterowane zdarzeniami, klienci chcą osiągnąć 1. wysoką skalowalność pozwalającą obsłużyć wolumen przychodzących zdarzeń oraz 2. niezawodność przetwarzania zdarzeń i utrzymanie funkcjonalności systemu w obliczu awarii.
Klienci wykorzystują wzorce architektury mikrousług, aby przyspieszyć innowacje i skrócić czas wprowadzania na rynek nowych funkcji, ponieważ ułatwia to skalowanie aplikacji i przyspiesza ich rozwój. Jednak wzbogacanie i odtwarzanie danych w wywołaniu sieciowym do innej mikrousługi jest trudne, ponieważ może to mieć wpływ na niezawodność aplikacji i utrudniać debugowanie i śledzenie błędów. Aby rozwiązać ten problem, efektywnym wzorcem projektowym jest pozyskiwanie zdarzeń, które centralizuje historyczne zapisy wszystkich zmian stanu w celu wzbogacania i odtwarzania oraz oddziela obciążenia odczytane od zapisu. Klienci mogą używać Kinesis Data Streams jako scentralizowanego magazynu zdarzeń dla mikrousług pozyskiwania zdarzeń, ponieważ KDS może 1/ obsługiwać gigabajty przepustowości danych na sekundę na strumień i przesyłać strumieniowo dane w milisekundach, aby spełnić wymagania dotyczące wysokiej skalowalności i czasu zbliżonego do rzeczywistego opóźnienia, 2/integracja z Flink i S3 w celu wzbogacania i osiągania danych przy całkowitym oddzieleniu od mikrousług oraz 3/umożliwienie ponownej próby i odczytu asynchronicznego w późniejszym czasie, ponieważ KDS przechowuje rekord danych domyślnie przez 24 godziny i opcjonalnie do 365 dni.
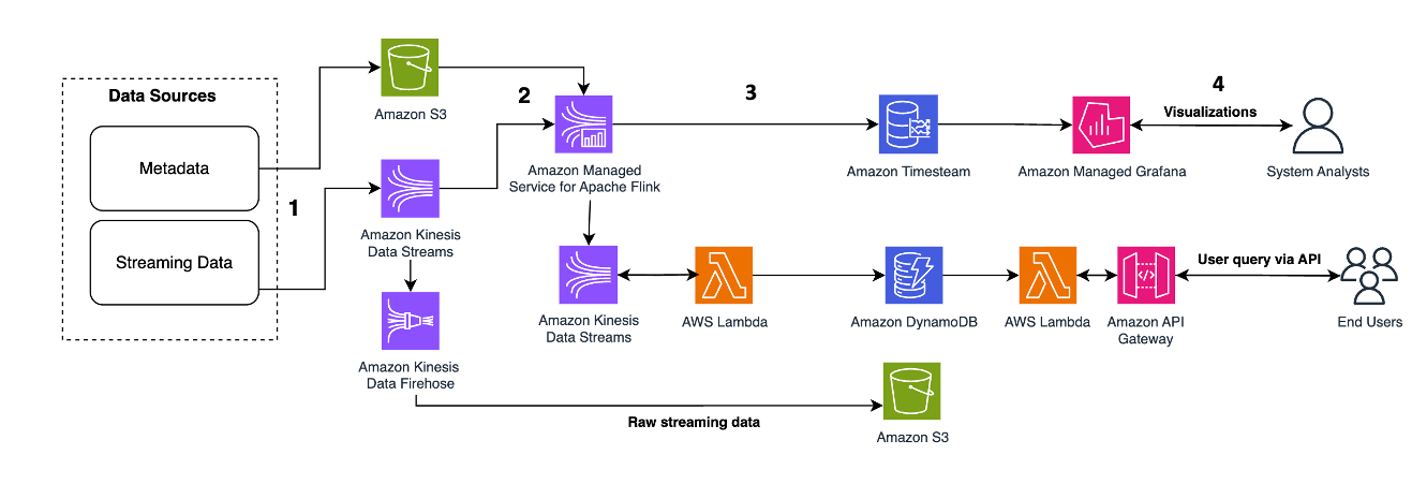
Poniższy wzorzec architektoniczny stanowi ogólną ilustrację sposobu wykorzystania strumieni danych Kinesis w mikrousługach pozyskiwania zdarzeń:
Etapy przepływu pracy są następujące:
- Pozyskiwanie i przechowywanie danych – Możesz agregować dane wejściowe z mikrousług do strumieni danych Kinesis w celu ich przechowywania.
- Przetwarzanie strumienia - Funkcje stanowe Apache Flink upraszcza tworzenie rozproszonych, stanowych aplikacji sterowanych zdarzeniami. Może odbierać zdarzenia z wejściowego strumienia danych Kinesis i kierować powstały strumień do wyjściowego strumienia danych. Za pomocą Apache Flink możesz utworzyć klaster funkcji stanowych w oparciu o logikę biznesową aplikacji.
- Migawka stanu w Amazon S3 – Możesz przechowywać migawkę stanu w Amazon S3 w celu śledzenia.
- Strumienie wyjściowe – Strumienie wyjściowe mogą być wykorzystywane poprzez zdalne funkcje Lambda poprzez protokół HTTP/gRPC poprzez API Gateway.
- Funkcje zdalne Lambda – Funkcje Lambda mogą działać jako mikrousługi dla różnych aplikacji i logiki biznesowej w celu obsługi aplikacji biznesowych i aplikacji mobilnych.
Aby dowiedzieć się, jak inni klienci zbudowali swoje mikrousługi oparte na zdarzeniach za pomocą strumieni danych Kinesis, zapoznaj się z poniższymi informacjami:
Kluczowe uwagi i najlepsze praktyki
Poniżej znajdują się uwagi i najlepsze praktyki, o których należy pamiętać:
- Odkrywanie danych powinno być pierwszym krokiem w tworzeniu nowoczesnych aplikacji do strumieniowego przesyłania danych. Aby osiągnąć pożądane wyniki biznesowe, musisz zdefiniować wartość biznesową, a następnie zidentyfikować źródła danych strumieniowych i osoby użytkowników.
- Wybierz narzędzie do pozyskiwania danych przesyłanych strumieniowo na podstawie źródła danych przesyłanych strumieniowo. Można na przykład użyć Kinesis SDK do pozyskiwania danych strumieniowych za pośrednictwem interfejsów API, Biblioteka producentów Kinesis do budowania wydajnych i długotrwałych producentów transmisji strumieniowych, a Środek kinezy za zebranie zestawu plików i wprowadzenie ich do Kinesis Data Streams, DMS AWS w przypadkach użycia przesyłania strumieniowego CDC oraz Rdzeń IoT AWS do pozyskiwania danych z urządzeń IoT do strumieni danych Kinesis. Możesz pobierać dane przesyłane strumieniowo bezpośrednio do Amazon Redshift, aby tworzyć aplikacje do przesyłania strumieniowego o niskim opóźnieniu. Możesz także używać bibliotek innych firm, takich jak Apache Spark i Apache Kafka, do pozyskiwania danych przesyłanych strumieniowo do strumieni danych Kinesis.
- Musisz wybrać usługi przetwarzania danych strumieniowych w oparciu o konkretny przypadek użycia i wymagania biznesowe. Na przykład możesz użyć usługi Amazon Kinesis Managed Service dla Apache Flink w przypadku zaawansowanego przesyłania strumieniowego z wieloma miejscami docelowymi przesyłania strumieniowego i złożonym przetwarzaniem strumienia stanowego lub jeśli chcesz monitorować wskaźniki biznesowe w czasie rzeczywistym (np. Co godzinę). Lambda jest dobra do przetwarzania opartego na zdarzeniach i bezstanowego. Możesz użyć Amazon EMR do strumieniowego przetwarzania danych w celu korzystania z ulubionych platform Big Data o otwartym kodzie źródłowym. AWS Glue jest dobry do przetwarzania danych strumieniowych w czasie zbliżonym do rzeczywistego w przypadkach użycia, takich jak przesyłanie strumieniowe ETL.
- Kinesis Data Streams w trybie na żądanie ładuje się w zależności od wykorzystania i automatycznie skaluje pojemność zasobów, dzięki czemu sprawdza się w przypadku dużych obciążeń związanych z przesyłaniem strumieniowym i konserwacji bez użycia rąk. Tryb udostępniony jest obciążany opłatami w zależności od pojemności i wymaga proaktywnego zarządzania pojemnością, dlatego sprawdza się w przypadku przewidywalnych obciążeń związanych z przesyłaniem strumieniowym.
- Możesz użyć Udostępniony kalkulator Kinesis do obliczenia liczby fragmentów potrzebnych w trybie aprowizacji. W trybie na żądanie nie musisz się martwić fragmentami.
- Nadając uprawnienia, decydujesz, kto otrzyma jakie uprawnienia do jakich zasobów Kinesis Data Streams. Włączasz określone akcje, na które chcesz zezwolić na tych zasobach. Dlatego należy nadawać tylko te uprawnienia, które są wymagane do wykonania zadania. Można także szyfrować dane w stanie spoczynku przy użyciu klucza zarządzanego przez klienta KMS (CMK).
- Możesz zaktualizować okres przechowywania za pośrednictwem konsoli Kinesis Data Streams lub za pomocą Zwiększ okres przechowywania strumienia oraz ZmniejszStreamRetentionPeriod operacje w oparciu o konkretne przypadki użycia.
- Obsługuje strumienie danych Kinesis ponowne shardingowanie. Zalecanym interfejsem API dla tej funkcji jest ZaktualizujShardCount, co pozwala modyfikować liczbę fragmentów w strumieniu, aby dostosować się do zmian w szybkości przepływu danych przez strumień. Interfejsy API reshardingu (Split i Merge) są zwykle używane do obsługi gorących fragmentów.
Wnioski
W tym poście zademonstrowano różne wzorce architektoniczne do tworzenia aplikacji do przesyłania strumieniowego o niskim opóźnieniu za pomocą strumieni danych Kinesis. Korzystając z informacji zawartych w tym poście, możesz tworzyć własne aplikacje do przesyłania strumieniowego o niskim opóźnieniu za pomocą strumieni danych Kinesis.
Szczegółowe wzorce architektoniczne można znaleźć w następujących zasobach:
Jeśli chcesz zbudować wizję i strategię dotyczącą danych, sprawdź Wszystko oparte na danych AWS programu (D2E).
O autorach
 Raghavarao Sodabathina jest głównym architektem rozwiązań w AWS, koncentrującym się na analizie danych, sztucznej inteligencji/ML i bezpieczeństwie chmury. Współpracuje z klientami w celu tworzenia innowacyjnych rozwiązań rozwiązujących problemy biznesowe klientów i przyspieszających wdrażanie usług AWS. W wolnym czasie Raghavarao lubi spędzać czas z rodziną, czytając książki i oglądając filmy.
Raghavarao Sodabathina jest głównym architektem rozwiązań w AWS, koncentrującym się na analizie danych, sztucznej inteligencji/ML i bezpieczeństwie chmury. Współpracuje z klientami w celu tworzenia innowacyjnych rozwiązań rozwiązujących problemy biznesowe klientów i przyspieszających wdrażanie usług AWS. W wolnym czasie Raghavarao lubi spędzać czas z rodziną, czytając książki i oglądając filmy.
 Powieś Zuo jest starszym menedżerem produktu w zespole Amazon Kinesis Data Streams w Amazon Web Services. Pasjonuje się tworzeniem intuicyjnych doświadczeń produktowych, które rozwiązują złożone problemy klientów i umożliwiają im osiąganie celów biznesowych.
Powieś Zuo jest starszym menedżerem produktu w zespole Amazon Kinesis Data Streams w Amazon Web Services. Pasjonuje się tworzeniem intuicyjnych doświadczeń produktowych, które rozwiązują złożone problemy klientów i umożliwiają im osiąganie celów biznesowych.
 Shwetha Radhakrishnan jest architektem rozwiązań dla AWS ze specjalizacją w analizie danych. Tworzy rozwiązania, które napędzają przyjęcie chmury i pomagają organizacjom w podejmowaniu decyzji opartych na danych w sektorze publicznym. Poza pracą uwielbia tańczyć, spędzać czas z przyjaciółmi i rodziną oraz podróżować.
Shwetha Radhakrishnan jest architektem rozwiązań dla AWS ze specjalizacją w analizie danych. Tworzy rozwiązania, które napędzają przyjęcie chmury i pomagają organizacjom w podejmowaniu decyzji opartych na danych w sektorze publicznym. Poza pracą uwielbia tańczyć, spędzać czas z przyjaciółmi i rodziną oraz podróżować.
 Bretania Ly jest architektem rozwiązań w AWS. Koncentruje się na pomaganiu klientom korporacyjnym w procesie wdrażania i modernizacji chmury. Interesuje się obszarami bezpieczeństwa i analityki. Poza pracą uwielbia spędzać czas ze swoim psem i grać w pikle.
Bretania Ly jest architektem rozwiązań w AWS. Koncentruje się na pomaganiu klientom korporacyjnym w procesie wdrażania i modernizacji chmury. Interesuje się obszarami bezpieczeństwa i analityki. Poza pracą uwielbia spędzać czas ze swoim psem i grać w pikle.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 100
- 24
- 7
- a
- zdolność
- O nas
- przyśpieszyć
- dostęp
- dostęp
- Osiągać
- osiągnięty
- Osiąga
- osiągnięcia
- w poprzek
- działać
- gra aktorska
- działania
- przystosować
- dodatek
- Dodatkowy
- do tego
- adres
- Przyjęcie
- zaawansowany
- Korzyść
- Po
- wiek
- Agent
- agregat
- AI / ML
- Cele
- Alerty
- Wszystkie kategorie
- dopuszczać
- Pozwalać
- pozwala
- również
- Amazonka
- Amazonka Kinesis
- Strumień czasu Amazona
- Amazon Web Services
- an
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- i
- wykrywanie anomalii
- Inne
- każdy
- Apache
- Apache Kafka
- Apache Spark
- api
- Pszczoła
- Zastosowanie
- aplikacje
- podejście
- mobilne i webowe
- architektoniczny
- architektura
- SĄ
- AS
- powiązany
- At
- automatycznie
- automatycznie
- dostępność
- dostępny
- AWS
- Klej AWS
- AWS Lambda
- na podstawie
- BE
- bo
- być
- zachowanie
- jest
- BEST
- Najlepsze praktyki
- Ulepsz Swój
- pomiędzy
- Duży
- Big Data
- Blog
- Książki
- obie
- budować
- Budowanie
- wybudowany
- biznes
- Aplikacje biznesowe
- biznes
- ale
- by
- obliczać
- wezwanie
- CAN
- Pojemność
- zdobyć
- który
- walizka
- Etui
- CDC
- Centrum
- scentralizowane
- pewien
- wyzwanie
- zmiana
- Zmiany
- Opłaty
- ZOBACZ
- wybór
- Dodaj
- kleń
- Sprzątanie
- Chmura
- adopcja chmury
- Cloud Security
- Grupa
- zbierać
- Zbieranie
- wspólny
- komunikować
- całkowicie
- kompleks
- składniki
- w składzie
- obliczać
- computing
- zaniepokojony
- konfigurowanie
- Rozważania
- składa się
- Konsola
- stale
- konsumować
- spożywane
- konsument
- Konsumenci
- skontaktuj się
- contact center
- ciągły
- bez przerwy
- kontrola
- Stwórz
- stworzony
- krytyczny
- klient
- Klientów
- dostosowane
- Taniec
- Deski rozdzielcze
- dane
- analiza danych
- Analityka danych
- wzbogacenie danych
- Jezioro danych
- zarządzanie danymi
- punkty danych
- analiza danych
- hurtownia danych
- sterowane danymi
- Baza danych
- Bazy danych
- Dni
- zdecydować
- decyzja
- Podejmowanie decyzji
- Decyzje
- oddzielony
- dedykowane
- Domyślnie
- określić
- dostarczyć
- wykazać
- W zależności
- Wnętrze
- zaprojektowany
- życzenia
- miejsce przeznaczenia
- Cele podróży
- szczegółowe
- detale
- wykryć
- Wykrywanie
- rozwijać
- rozwijanie
- oprogramowania
- urządzenie
- urządzenia
- różne
- trudny
- bezpośrednio
- odkrycie
- dystrybuowane
- przetwarzanie rozproszone
- do
- Pies
- nie
- na dół
- napęd
- napędzany
- trwałość
- dynamiczny
- każdy
- łatwiej
- z łatwością
- łatwo
- Efektywne
- objąć
- umożliwiać
- szyfrowanie
- Punkty końcowe
- zaangażowany
- wzmocnione
- wzbogacać
- Enterprise
- klienci korporacyjni
- Błędy
- Eter (ETH)
- wydarzenie
- wydarzenia
- Każdy
- wszyscy
- przykład
- przykłady
- oczekuje
- doświadczenie
- Doświadczenia
- odkryj
- rozciągać się
- wyciąg
- Twarz
- Awarie
- członków Twojej rodziny
- Moda
- szybciej
- Moja lista
- Cecha
- Korzyści
- pole
- Akta
- i terminów, a
- pięć
- pływ
- Skupiać
- koncentruje
- skupienie
- następujący
- następujący sposób
- W razie zamówieenia projektu
- Framework
- Ramy
- często
- przyjaciele
- od
- funkcjonować
- Funkcjonalność
- Funkcje
- dalej
- Wzrost
- Bramka
- Generować
- wygenerowane
- miejsce
- GitHub
- daje
- Gole
- dobry
- przyznać
- przyznanie
- uchwyt
- Zawiesić
- he
- pomoc
- pomoc
- jej
- Wysoki
- wysoka wydajność
- jego
- historyczny
- HOT
- godzina
- GODZINY
- W jaki sposób
- Jednak
- HTML
- http
- HTTPS
- Setki
- zidentyfikować
- if
- ilustruje
- Rezultat
- in
- W innych
- obejmuje
- Przybywający
- Zwiększać
- wzrastający
- niezależny
- pod wpływem
- Informacja
- Infrastruktura
- infrastruktura
- innowacyjne
- Innowacja
- Innowacyjny
- wkład
- spostrzeżenia
- zainstalować
- integrować
- zintegrowany
- integracja
- integracje
- odsetki
- Interfejs
- Internet
- Internet przedmiotów
- najnowszych
- wprowadzono
- intuicyjny
- przywołany
- Internet przedmiotów
- Urządzenie IoT
- IT
- JEGO
- podróż
- jpg
- kafka
- Trzymać
- Klawisz
- Strumienie danych kinezy
- jezioro
- Utajenie
- później
- warstwa
- nioski
- UCZYĆ SIĘ
- Księga główna
- biblioteki
- Biblioteka
- lekki
- lubić
- życie
- załadować
- log
- logika
- logiczny
- kocha
- utrzymać
- konserwacja
- robić
- WYKONUJE
- Dokonywanie
- zarządzane
- i konserwacjami
- kierownik
- wiele
- Marketing
- maksymalny
- zmierzenie
- Media
- Poznaj nasz
- Pamięć
- Łączyć
- Metadane
- Metryka
- mikroserwisy
- Środkowy
- migracja
- milisekund
- nic
- Aplikacje mobilne
- Aplikacje mobilne
- urządzenia mobilne
- aplikacje mobilne
- Moda
- Nowoczesne technologie
- modernizacja
- Tryby
- modyfikować
- monitor
- jeszcze
- Kino
- wielokrotność
- musi
- rodzimy
- Blisko
- Potrzebować
- potrzebne
- wymagania
- sieć
- Nowości
- Nowe funkcje
- już dziś
- numer
- of
- oferta
- Oferty
- on
- Na żądanie
- tylko
- koncepcja
- open source
- działanie
- operacyjny
- operacje
- Optymalizacja
- zoptymalizowane
- Option
- or
- zamówienie
- organizacyjny
- organizacji
- Inne
- ludzkiej,
- na zewnątrz
- wyniki
- wydajność
- zewnętrzne
- koniec
- własny
- część
- namiętny
- Wzór
- wzory
- Zapłacić
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uprawnienia
- Personalizowany
- rura
- rurociąg
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- wtyczka
- zwrotnica
- Post
- praktyki
- Możliwy do przewidzenia
- Cennik
- wycena
- pierwotny
- Główny
- Wcześniejszy
- prywatny
- Proaktywne
- Problem
- problemy
- wygląda tak
- obrobiony
- procesów
- przetwarzanie
- Wytworzony
- producent
- Producenci
- Produkt
- product manager
- Program
- protokół
- zapewniać
- zapewnia
- pełnomocnik
- publiczny
- zasięg
- szybko
- Kurs
- Surowy
- surowe dane
- Czytaj
- Czytający
- real
- w czasie rzeczywistym
- dane w czasie rzeczywistym
- otrzymać
- otrzymuje
- Rekomendacja
- Zalecana
- rekord
- nagrany
- dokumentacja
- zmniejszyć
- odnosić się
- region
- niezawodność
- rzetelny
- zdalny
- wymagany
- wymaganie
- wymagania
- Wymaga
- Zasób
- Zasoby
- odpowiedzialny
- REST
- wynikły
- zachować
- zachowuje
- retencja
- przeglądu
- Trasa
- taki sam
- Skalowalność
- skalowalny
- Skala
- waga
- druga
- sektor
- bezpieczeństwo
- senior
- czujniki
- Sekwencja
- Serie
- służyć
- Bezserwerowe
- usługa
- Usługi
- zestaw
- shared
- ona
- powinien
- ściąganie
- upraszcza
- mały
- Migawka
- So
- Obserwuj Nas
- Media społecznościowe
- Tworzenie
- rozwoju oprogramowania
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Źródło
- Źródła
- Iskra
- specyficzny
- prędkość
- wydać
- Spędzanie
- kolce
- dzielić
- stos
- Stan
- Ewolucja krok po kroku
- Cel
- stany magazynowe
- przechowywanie
- sklep
- przechowywany
- Strategia
- strumień
- strumieniowo
- Streaming
- Strumienie
- rygorystyczny
- kolejny
- taki
- wystarczający
- wsparcie
- podpory
- system
- stół
- Brać
- Zadanie
- zadania
- zespół
- kilkadziesiąt
- że
- Połączenia
- Informacje
- Państwo
- ich
- Im
- następnie
- Tam.
- w związku z tym
- Te
- one
- rzeczy
- innych firm
- to
- tych
- tysiące
- trzy
- Przez
- wydajność
- czas
- Szereg czasowy
- Czasochłonne
- do
- już dziś
- narzędzie
- wyśledzić
- śledzić
- Śledzenie
- ruch drogowy
- Przekształcać
- Transformacja
- transformatorowy
- Podróżowanie
- Trendy
- drugiej
- zazwyczaj
- Nieoczekiwany
- na
- Stosowanie
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- za pomocą
- wykorzystać
- uprawomocnienie
- wartość
- zmienna
- różnorodny
- Prędkość
- przez
- Wirtualny
- wizja
- wyobrażanie sobie
- wyobrażać sobie
- Tom
- kłęby
- chcieć
- Magazyn
- Magazynowanie
- oglądania
- we
- sieć
- usługi internetowe
- dobrze zdefiniowane
- Co
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- KIM
- szeroki
- Szeroki zasięg
- będzie
- w
- w ciągu
- Praca
- workflow
- martwić się
- napisać
- ty
- Twój
- zefirnet
- Strefy