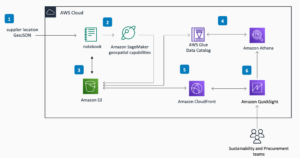
To jest post gościnny autorstwa AK Roya z Qualcomm AI.
Amazon Elastic Compute Cloud (Amazon EC2) Instancje DL2q, obsługiwane przez akceleratory Qualcomm AI 100 Standard, mogą być wykorzystywane do ekonomicznego wdrażania obciążeń głębokiego uczenia się (DL) w chmurze. Można ich również używać do opracowywania i sprawdzania wydajności i dokładności obciążeń DL, które zostaną wdrożone na urządzeniach Qualcomm. Instancje DL2q to pierwsze instancje, które wprowadzają technologię sztucznej inteligencji (AI) firmy Qualcomm do chmury.
Dzięki ośmiu akceleratorom Qualcomm AI 100 Standard i 128 GiB całkowitej pamięci akceleratora klienci mogą również używać instancji DL2q do uruchamiania popularnych aplikacji generatywnych AI, takich jak generowanie treści, podsumowywanie tekstu i wirtualni asystenci, a także klasycznych aplikacji AI do przetwarzania języka naturalnego i wizja komputerowa. Ponadto akceleratory Qualcomm AI 100 wykorzystują tę samą technologię sztucznej inteligencji, która jest stosowana w smartfonach, pojazdach autonomicznych, komputerach osobistych i zestawach słuchawkowych o rozszerzonej rzeczywistości, dzięki czemu instancje DL2q można wykorzystywać do opracowywania i sprawdzania obciążeń AI przed wdrożeniem.
Nowe najważniejsze informacje dotyczące instancji DL2q
Każda instancja DL2q zawiera osiem akceleratorów Qualcomm Cloud AI100, których łączna wydajność wynosi ponad 2.8 PetaOps w przypadku wnioskowania Int8 i 1.4 PetaFlops w przypadku wnioskowania FP16. Instancja ma łącznie 112 rdzeni AI, pojemność pamięci akceleratora na poziomie 128 GB i przepustowość pamięci na poziomie 1.1 TB na sekundę.
Każda instancja DL2q ma 96 procesorów vCPU, pojemność pamięci systemowej 768 GB i obsługuje przepustowość sieci 100 Gb/s, a także Sklep z blokami elastycznymi Amazon (Amazon EBS) pamięć o przepustowości 19 Gb/s.
| Nazwa instancji | vCPU | Akceleratory Cloud AI100 | Pamięć akceleratora | Pamięć akceleratora BW (zagregowana) | Pamięć instancji | Sieć instancji | Przepustowość pamięci masowej (Amazon EBS). |
| DL2q.24xduży | 96 | 8 | 128 GB | 1.088 TB / s | 768 GB | 100 Gbps | 19 Gbps |
Innowacyjny akcelerator Qualcomm Cloud AI100
System-on-chip (SoC) akceleratora Cloud AI100 to specjalnie zaprojektowana, skalowalna architektura wielordzeniowa, obsługująca szeroką gamę zastosowań głębokiego uczenia się, od centrum danych po brzeg. SoC wykorzystuje rdzenie obliczeniowe skalarne, wektorowe i tensorowe z wiodącą w branży pojemnością wbudowanej pamięci SRAM wynoszącą 126 MB. Rdzenie są połączone siatką typu „sieć na chipie” (NoC) o dużej przepustowości i niskim opóźnieniu.
Akcelerator AI100 obsługuje szeroką i kompleksową gamę modeli i przypadków użycia. Poniższa tabela przedstawia zakres wsparcia modelu.
| Kategoria modeli | Liczba modeli | Przykłady |
| NLP | 157 | BERT, BART, FasterTransformer, T5, kod Z MOE |
| Generatywna sztuczna inteligencja – NLP | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen |
| Generatywna sztuczna inteligencja – obraz | 3 | Stabilna dyfuzja v1.5 i v2.1, OpenAI CLIP |
| CV – Klasyfikacja obrazu | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| CV – wykrywanie obiektów | 23 | YOLO v2, v3, v4, v5 i v7, SSD-ResNet, RetinaNet |
| CV – inne | 15 | LPRNet, superrozdzielczość/SRGAN, ByteTrack |
| Sieci motoryzacyjne* | 53 | Percepcja i wykrywanie LIDAR, pieszych, pasów ruchu i sygnalizacji świetlnej |
| Razem | > 300 â € < | â € < |
* Większość sieci motoryzacyjnych to sieci złożone, składające się z połączenia pojedynczych sieci.
Duża pamięć SRAM w akceleratorze DL2q umożliwia efektywne wdrażanie zaawansowanych technik wydajności, takich jak precyzja mikrowykładnika MX6 do przechowywania ciężarów i precyzja mikrowykładnika MX9 do komunikacji między akceleratorami. Technologia mikrowykładników została opisana w następującym ogłoszeniu branżowym Open Compute Project (OCP): AMD, Arm, Intel, Meta, Microsoft, NVIDIA i Qualcomm standaryzują wąskie precyzyjne formaty danych nowej generacji dla sztucznej inteligencji » Projekt Open Compute.
Użytkownik instancji może zastosować następującą strategię, aby zmaksymalizować stosunek wydajności do kosztu:
- Przechowuj ciężary z precyzją mikrowykładnika MX6 w pamięci DDR wbudowanej w akcelerator. Korzystanie z precyzji MX6 maksymalizuje wykorzystanie dostępnej pojemności pamięci i przepustowości pamięci, aby zapewnić najlepszą w swojej klasie przepustowość i opóźnienia.
- Obliczenia w FP16, aby zapewnić wymaganą dokładność przypadku użycia, przy użyciu doskonałej wbudowanej pamięci SRAM i zapasowych TOPów na karcie, aby wdrożyć wysokowydajne jądra MX6 do FP16 o niskim opóźnieniu.
- Użyj zoptymalizowanej strategii dozowania i większego rozmiaru partii, korzystając z dużej dostępnej pamięci SRAM na chipie, aby zmaksymalizować ponowne wykorzystanie obciążników, zachowując jednocześnie maksymalnie możliwe aktywacje na chipie.
Stos AI DL2q i łańcuch narzędzi
Instancji DL2q towarzyszy Qualcomm AI Stack, który zapewnia spójne środowisko programistyczne w ramach Qualcomm AI w chmurze i innych produktach Qualcomm. Ten sam stos Qualcomm AI i podstawowa technologia AI działa na instancjach DL2q i urządzeniach brzegowych Qualcomm, zapewniając klientom spójne środowisko programistyczne dzięki ujednoliconemu interfejsowi API w środowiskach chmurowych, motoryzacyjnych, komputerów osobistych, rozszerzonej rzeczywistości i środowisk programistycznych smartfonów.
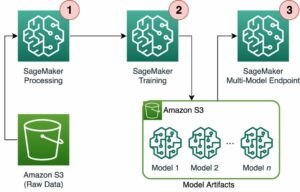
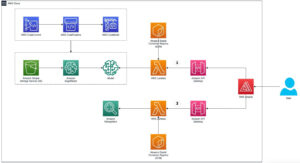
Łańcuch narzędzi umożliwia użytkownikowi instancji szybkie wdrożenie wcześniej wyszkolonego modelu, skompilowanie i zoptymalizowanie modelu pod kątem możliwości instancji, a następnie wdrożenie skompilowanych modeli na potrzeby wnioskowania produkcyjnego w trzech krokach pokazanych na poniższym rysunku.

Aby dowiedzieć się więcej na temat dostrajania wydajności modelu, zobacz Kluczowe parametry wydajności Cloud AI 100 Dokumentacja.
Rozpocznij pracę z instancjami DL2q
W tym przykładzie kompilujesz i wdrażasz wstępnie przeszkolony modelu BERT od Przytulanie Twarzy na instancji EC2 DL2q przy użyciu wstępnie zbudowanego, dostępnego DL2q AMI, w czterech krokach.
Możesz użyć gotowego Qualcomm DLAMI na instancji lub zacznij od Amazon Linux2 AMI i zbuduj własny DL2q AMI z platformą Cloud AI 100 i pakietem SDK aplikacji dostępnym w tym Usługa Amazon Simple Storage (Amazon S3) wiaderko: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
W poniższych krokach wykorzystano wstępnie zbudowany moduł AMI DL2q, Qualcomm Base AL2 DLAMI.
Użyj protokołu SSH, aby uzyskać dostęp do instancji DL2q za pomocą Qualcomm Base AL2 DLAMI AMI i wykonaj kroki od 1 do 4.
Krok 1. Skonfiguruj środowisko i zainstaluj wymagane pakiety
- Zainstaluj Pythona 3.8.
- Skonfiguruj środowisko wirtualne Python 3.8.
- Aktywuj środowisko wirtualne Python 3.8.
- Zainstaluj wymagane pakiety pokazane w pliku dokument wymagania.txt dostępne w publicznej witrynie Github firmy Qualcomm.
- Zaimportuj niezbędne biblioteki.
Krok 2. Zaimportuj model
- Zaimportuj i tokenizuj model.
- Zdefiniuj przykładowe dane wejściowe i wyodrębnij plik
inputIdsiattentionMask. - Konwertuj model na ONNX, który można następnie przekazać do kompilatora.
- Uruchomisz model z precyzją FP16. Należy więc sprawdzić, czy model zawiera jakieś stałe spoza zakresu FP16. Przekaż model do
fix_onnx_fp16funkcję wygenerowania nowego pliku ONNX z wymaganymi poprawkami.
Krok 3. Skompiluj model
Połączenia qaic-exec Do kompilowania modelu używane jest narzędzie kompilatora interfejsu wiersza poleceń (CLI). Dane wejściowe tego kompilatora to plik ONNX wygenerowany w kroku 2. Kompilator tworzy plik binarny (tzw. QPC, Dla Kontener programu Qualcomm) w ścieżce zdefiniowanej przez -aic-binary-dir argumenty.
W poniższym poleceniu kompilacji do skompilowania modelu używasz czterech rdzeni obliczeniowych AI i partii o wielkości jednego.
QPC jest generowany w pliku bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc teczka.
Krok 4. Uruchom model
Skonfiguruj sesję, aby uruchomić wnioskowanie na akceleratorze Cloud AI100 Qualcomm w instancji DL2q.
Biblioteka Qualcomm qaic Python to zestaw interfejsów API zapewniający obsługę uruchamiania wnioskowania w akceleratorze Cloud AI100.
- Użyj wywołania API sesji, aby utworzyć instancję sesji. Wywołanie API sesji jest punktem wyjścia do korzystania z biblioteki Pythona qaic.
- Zrestrukturyzuj dane z bufora wyjściowego za pomocą
output_shapeioutput_type. - Dekoduj wygenerowany wynik.
Oto wyniki dla zdania wejściowego „Pies [MASKA] na macie”.
Otóż to. W kilku krokach skompilowałeś i uruchomiłeś model PyTorch na instancji Amazon EC2 DL2q. Aby dowiedzieć się więcej na temat dołączania i kompilowania modeli w instancji DL2q, zobacz Dokumentacja samouczka Cloud AI100.
Aby dowiedzieć się więcej o tym, które architektury modeli DL dobrze pasują do instancji AWS DL2q i o aktualnej macierzy obsługi modeli, zobacz Dokumentacja Qualcomm Cloud AI100.
Już dostępny
Możesz już dziś uruchomić instancje DL2q w regionach AWS w zachodnich stanach USA (Oregon) i Europie (Frankfurt) jako Na żądanie, Zarezerwowane, Instancje Spotlub jako część Plan oszczędnościowy. Jak zwykle w przypadku Amazon EC2 płacisz tylko za to, z czego korzystasz. Aby uzyskać więcej informacji, zobacz Ceny Amazon EC2.
Instancje DL2q można wdrożyć przy użyciu AMI głębokiego uczenia się AWS (DLAMI), a obrazy kontenerów są dostępne za pośrednictwem usług zarządzanych, takich jak Amazon Sage Maker, Usługa Amazon Elastic Kubernetes (Amazon EKS), Usługa elastycznych pojemników Amazon (Amazon ECS), Klaster równoległy AWS.
Aby dowiedzieć się więcej, odwiedź stronę Instancja Amazon EC2 DL2q stronę i wyślij opinię na adres AWS re:Post dla EC2 lub za pośrednictwem zwykłych kontaktów pomocy technicznej AWS.
O autorach
 AK Roy jest dyrektorem ds. zarządzania produktami w Qualcomm ds. produktów i rozwiązań AI w chmurze i Datacenter. Ma ponad 20-letnie doświadczenie w strategii i rozwoju produktów, obecnie koncentruje się na najlepszej w swojej klasie wydajności i wydajności/kompleksowych rozwiązaniach do wnioskowania AI w chmurze, dla szerokiego zakresu przypadków użycia, w tym GenAI, LLM, automatyczna i hybrydowa sztuczna inteligencja.
AK Roy jest dyrektorem ds. zarządzania produktami w Qualcomm ds. produktów i rozwiązań AI w chmurze i Datacenter. Ma ponad 20-letnie doświadczenie w strategii i rozwoju produktów, obecnie koncentruje się na najlepszej w swojej klasie wydajności i wydajności/kompleksowych rozwiązaniach do wnioskowania AI w chmurze, dla szerokiego zakresu przypadków użycia, w tym GenAI, LLM, automatyczna i hybrydowa sztuczna inteligencja.
 Jianying Langa jest głównym architektem rozwiązań w Światowej Organizacji Specjalistycznej AWS (WWSO). Ma ponad 15-letnie doświadczenie zawodowe w dziedzinie HPC i AI. W AWS koncentruje się na pomaganiu klientom we wdrażaniu, optymalizowaniu i skalowaniu obciążeń AI/ML w instancjach z przyspieszonym przetwarzaniem. Jej pasją jest łączenie technik z obszarów HPC i AI. Jianying posiada stopień doktora fizyki obliczeniowej uzyskany na Uniwersytecie Kolorado w Boulder.
Jianying Langa jest głównym architektem rozwiązań w Światowej Organizacji Specjalistycznej AWS (WWSO). Ma ponad 15-letnie doświadczenie zawodowe w dziedzinie HPC i AI. W AWS koncentruje się na pomaganiu klientom we wdrażaniu, optymalizowaniu i skalowaniu obciążeń AI/ML w instancjach z przyspieszonym przetwarzaniem. Jej pasją jest łączenie technik z obszarów HPC i AI. Jianying posiada stopień doktora fizyki obliczeniowej uzyskany na Uniwersytecie Kolorado w Boulder.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- :ma
- :Jest
- $W GÓRĘ
- 1
- 1 TB
- 10
- 100
- 11
- 12
- 13
- 15 roku
- 15%
- 17
- 19
- 20
- 20 roku
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- O nas
- powyżej
- przyśpieszony
- akcelerator
- akceleratory
- dostęp
- towarzyszy
- precyzja
- w poprzek
- aktywacje
- do tego
- zaawansowany
- agregat
- AI
- AI / ML
- Wszystkie kategorie
- również
- Amazonka
- Amazon EC2
- Amazon Web Services
- an
- i
- Zapowiedź
- każdy
- api
- Pszczoła
- aplikacje
- mobilne i webowe
- architektura
- SĄ
- argument
- ARM
- sztuczny
- AS
- asystenci
- At
- samochód
- motoryzacyjny
- autonomiczny
- dostępny
- AWS
- OSIE
- przepustowość
- baza
- partie
- BE
- zanim
- poniżej
- Poza
- BIN
- Blokować
- Kwitnąć
- przynieść
- szeroki
- bufor
- budować
- by
- wezwanie
- nazywa
- CAN
- możliwości
- Pojemność
- karta
- walizka
- ZOBACZ
- klasyczny
- Chmura
- Kolorado
- łączenie
- Komunikacja
- skompilowany
- wszechstronny
- obliczeniowy
- obliczać
- komputer
- Wizja komputerowa
- komputery
- computing
- zgodny
- Składający się
- łączność
- Pojemnik
- zawiera
- zawartość
- Stwórz
- Aktualny
- Klientów
- dane
- Datacenter
- głęboko
- głęboka nauka
- zdefiniowane
- Stopień
- dostarczyć
- dostarcza
- rozwijać
- wdrażane
- Wdrożenie
- opisane
- rozwijać
- Deweloper
- oprogramowania
- urządzenie
- urządzenia
- Transmitowanie
- Dyrektor
- dokumentacja
- Pies
- jazdy
- dynamiczny
- ebs
- krawędź
- wydajny
- bądź
- zatrudnia
- Umożliwia
- koniec końców
- wejście
- Środowisko
- środowiska
- Eter (ETH)
- Europie
- przykład
- doświadczenie
- rozszerzona rzeczywistość
- wyciąg
- fałszywy
- Cecha
- informacja zwrotna
- kilka
- pole
- Łąka
- Postać
- filet
- i terminów, a
- dopasować
- poprawki
- Skupiać
- koncentruje
- obserwuj
- następujący
- W razie zamówieenia projektu
- znaleziono
- cztery
- Frankfurt
- od
- funkcjonować
- fuzja
- ogólnie
- Generować
- wygenerowane
- generacja
- generatywny
- generatywna sztuczna inteligencja
- GitHub
- dany
- dobry
- Gość
- Guest Post
- he
- Słuchawki z mikrofonem
- pomoc
- tutaj
- wysoka wydajność
- wyższy
- pasemka
- posiada
- HPC
- HTML
- HTTPS
- Hybrydowy
- i
- IDX
- if
- obraz
- zdjęcia
- wdrożenia
- realizacja
- importować
- in
- Włącznie z
- zawiera
- indywidualny
- przemysł
- wiodący w branży
- Informacja
- wkład
- zainstalować
- przykład
- instancje
- Intel
- Inteligentny
- połączone
- Interfejs
- IT
- jpg
- właśnie
- Klawisz
- Kubernetes
- Tor
- język
- duży
- Utajenie
- uruchomić
- UCZYĆ SIĘ
- nauka
- biblioteki
- Biblioteka
- sprawa
- lekki
- Linia
- masa
- zarządzane
- i konserwacjami
- maska
- Matrix
- max
- Maksymalizuj
- maksymalizuje
- maksymalny
- Pamięć
- siatka
- Meta
- Microsoft
- min
- model
- modele
- zmodyfikowano
- jeszcze
- większość
- Nazwa
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- niezbędny
- Potrzebować
- sieć
- sieci
- sieci
- Nowości
- następna generacja
- już dziś
- tępy
- Nvidia
- przedmiot
- of
- on
- Onboard
- Wprowadzenie
- ONE
- tylko
- koncepcja
- OpenAI
- Optymalizacja
- zoptymalizowane
- or
- Oregon
- organizacja
- OS
- Inne
- na zewnątrz
- wydajność
- Wyjścia
- koniec
- własny
- Pakiety
- strona
- część
- przechodzić
- minęło
- namiętny
- ścieżka
- Zapłacić
- dla
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- osobisty
- Komputery osobiste
- PhD
- Fizyka
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- Popularny
- możliwy
- Post
- powered
- Detaliczność
- poprzednio
- Główny
- przetwarzanie
- Wytworzony
- produkuje
- Produkt
- zarządzanie produktem
- Produkcja
- Produkty
- Program
- projekt
- zapewnia
- że
- publiczny
- Python
- płomień
- Qualcomm
- szybko
- zasięg
- RE
- Czytający
- Rzeczywistość
- regiony
- wymagany
- wymagania
- wspornikowy
- powrót
- ponownie
- Roy
- run
- bieganie
- działa
- taki sam
- Zapisz
- oszczędność
- skalowalny
- Skala
- Sdk
- druga
- widzieć
- wysłać
- wyrok
- Sekwencja
- usługa
- Usługi
- Sesja
- zestaw
- ona
- pokazane
- Prosty
- upraszczać
- witryna internetowa
- Rozmiar
- smartphone
- smartfony
- So
- Rozwiązania
- napięcie
- specjalista
- stos
- standard
- początek
- rozpoczęty
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- Strategia
- Następnie
- taki
- przełożony
- wsparcie
- Wspierający
- podpory
- system
- stół
- Techniki
- Technologia
- XNUMX
- że
- Połączenia
- ich
- następnie
- Te
- one
- to
- trzy
- Przez
- wydajność
- thru
- do
- już dziś
- tokenizować
- narzędzie
- Topy
- pochodnia
- Kwota produktów:
- ruch drogowy
- przeszkolony
- Transformatory
- prawdziwy
- Tutorial
- Ujednolicony
- uniwersytet
- us
- posługiwać się
- przypadek użycia
- przypadków użycia
- używany
- Użytkownik
- za pomocą
- zwykły
- v1
- VAL
- UPRAWOMOCNIĆ
- wartość
- Wirtualny
- wizja
- Odwiedzić
- we
- sieć
- usługi internetowe
- DOBRZE
- Zachód
- Co
- który
- Podczas
- szeroki
- Szeroki zasięg
- będzie
- w
- słowo
- pracujący
- na calym swiecie
- lat
- ty
- Twój
- zefirnet