- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :Jest
- 10
- 100
- 15%
- 2023
- 7
- a
- Zdolny
- w poprzek
- Przyjęcie
- AI
- zarówno
- Wszystkie kategorie
- Chociaż
- wśród
- an
- i
- odpowiedzi
- stosowany
- SĄ
- AS
- pytanie
- aspekty
- asystenci
- powiązany
- At
- atakować
- Ataki
- dostępny
- z dala
- BE
- jest
- pomiędzy
- miliardy
- budować
- biznes
- ale
- by
- CAN
- ostrożnie
- ceo
- nasze chatboty
- ChatGPT
- jasny
- zamknięte
- wspólny
- Firmy
- komputer
- Troska
- o
- Konferencja
- mógłby
- Stwórz
- Tworzenie
- krytyczny
- Obecnie
- cyber
- Data
- wykazać
- wykazać
- wdrażanie
- szczegółowe
- Wykrywanie
- rozwijać
- różne
- cyfrowy
- odkryty
- dr
- przedsiębiorstwa
- Cały
- Parzyste
- dowód
- istnieć
- Przede wszystkim system został opracowany
- Wykorzystać
- ekstrakcja
- niezwykle
- fascynujący
- budżetowy
- usługi finansowe
- i terminów, a
- koncentruje
- W razie zamówieenia projektu
- od
- dalej
- zdobyte
- dany
- Dający
- Ziemia
- Have
- Ukryty
- pasemka
- hostowane
- W jaki sposób
- How To
- Jednak
- HTTPS
- Przytulanie twarzy
- ważny
- in
- wzrosła
- coraz bardziej
- przemysł
- informować
- Informacja
- bezpieczeństwo informacji
- wnikliwy
- Internet
- Inwestuj
- inwestowanie
- IT
- jpg
- Klawisz
- wiedza
- znany
- język
- duży
- Duże przedsiębiorstwa
- uruchomić
- prowadzący
- UCZYĆ SIĘ
- nauka
- mniej
- mało
- maszyna
- uczenie maszynowe
- poważny
- Może..
- zmierzenie
- miliony
- model
- modele
- dużo
- Nowości
- of
- on
- koncepcja
- open source
- or
- na zewnątrz
- własny
- Papier
- przyjęcie
- Piotr
- Miejsca
- planowanie
- plato
- Analiza danych Platona
- PlatoDane
- możliwy
- potencjalnie
- mocny
- przygotowanie
- przedstawione
- Główny
- prywatny
- zapewniać
- publicznie
- zasięg
- Kurs
- replikowane
- wywołań
- Badania naukowe
- Badacze
- ujawniać
- ryzyko
- Powiedział
- powiedzieć
- Naukowcy
- bezpieczeństwo
- Usługi
- zestaw
- powinien
- pokazać
- mniejszy
- mądry
- So
- kilka
- Źródło
- STAGE
- Uruchomienie
- burza
- Badanie
- sukces
- Z powodzeniem
- taki
- Zadania
- rozmawiać
- ukierunkowane
- kierowania
- zadania
- zespół
- Technologies
- Technologia
- Testowanie
- niż
- że
- Połączenia
- Informacje
- UK
- świat
- ich
- następnie
- Tam.
- Te
- one
- myśleć
- Trzeci
- to
- w tym roku
- czasy
- do
- narzędzia
- przeniesione
- transformacyjny
- Uk
- zrozumienie
- podjąć
- uniwersytet
- posługiwać się
- używany
- zastosowania
- wyceniane
- początku.
- Luki w zabezpieczeniach
- była
- Droga..
- we
- tydzień
- były
- który
- szeroki
- Szeroki zasięg
- będzie
- w
- w ciągu
- bez
- Praca
- odrobić
- działa
- świat
- martwiąc
- rok
- zefirnet
Więcej z Nanowerk
Uwolnienie nowej ery dostrajanych kolorów nanourządzeń — najmniejsze jak dotąd źródło światła z możliwością przełączania kolorów
Węzeł źródłowy: 2801585
Znak czasu: Sierpnia 3, 2023

„Magiczny” rozpuszczalnik tworzy mocniejsze cienkie warstwy
Węzeł źródłowy: 1957849
Znak czasu: Luty 14, 2023
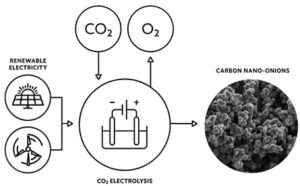
Nanorurki węglowe mogą odgrywać znaczącą rolę w wiązaniu atmosferycznego dwutlenku węgla
Węzeł źródłowy: 2836729
Znak czasu: Sierpnia 21, 2023

Rozróżnianie prawej i lewej strony za pomocą magnesów
Węzeł źródłowy: 1907121
Znak czasu: Jan 18, 2023
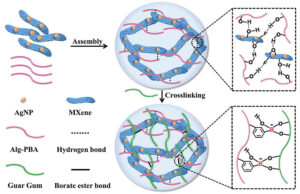
Antybakteryjne czujniki naskórka na bazie hydrożelu MXene
Węzeł źródłowy: 2661017
Znak czasu: 18 maja 2023 r.
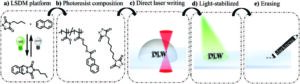
Wydruki 3D dołączają do ciemnej strony i znikają
Węzeł źródłowy: 2903619
Znak czasu: Września 27, 2023
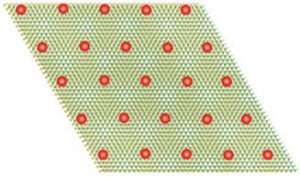
Kiedy materiał przechodzi w stan kwantowy, elektrony zwalniają i tworzą kryształ
Węzeł źródłowy: 1975767
Znak czasu: Luty 23, 2023

Inżynierowie opracowują wydajny proces wytwarzania paliwa z dwutlenku węgla
Węzeł źródłowy: 2963812
Znak czasu: Październik 30, 2023