Introductie
Stel je voor dat je in een slecht verlichte bibliotheek staat en worstelt met het ontcijferen van een complex document terwijl je met tientallen andere teksten jongleert. Dit was de wereld van Transformers voordat het artikel ‘Attention is All You Need’ zijn revolutionaire spotlight onthulde: de aandachtsmechanisme.
Inhoudsopgave
Beperkingen van RNN's
Traditionele sequentiële modellen, zoals Terugkerende neurale netwerken (RNN's), verwerkte taal woord voor woord, wat tot verschillende beperkingen leidde:
- Afhankelijkheid op korte termijn: RNN's hadden moeite om verbanden tussen verre woorden te begrijpen, waarbij ze vaak de betekenis verkeerd interpreteerden van zinnen als 'de man die gisteren de dierentuin bezocht', waarbij het onderwerp en het werkwoord ver uit elkaar liggen.
- Beperkt parallellisme: Het sequentieel verwerken van informatie is inherent traag, waardoor een efficiënte training en gebruik van computerbronnen wordt verhinderd, vooral bij lange reeksen.
- Focus op lokale context: RNN's houden vooral rekening met directe buren, waardoor mogelijk cruciale informatie uit andere delen van de zin ontbreekt.
Deze beperkingen belemmerden het vermogen van Transformers om complexe taken uit te voeren, zoals automatische vertaling en het begrijpen van natuurlijke taal. Toen kwam de aandachtsmechanisme, een revolutionaire spotlight die de verborgen verbindingen tussen woorden belicht en ons begrip van taalverwerking transformeert. Maar wat heeft aandacht precies opgelost, en hoe heeft het de game voor Transformers veranderd?
Laten we ons concentreren op drie belangrijke gebieden:
Afhankelijkheid op lange termijn
- probleem: Traditionele modellen stuitten vaak op zinnen als ‘de vrouw die op de heuvel woonde, zag gisteravond een vallende ster’. Vanwege hun afstand hadden ze moeite om ‘vrouw’ en ‘vallende ster’ met elkaar te verbinden, wat tot verkeerde interpretaties leidde.
- Aandachtsmechanisme: Stel je voor dat het model een heldere straal door de zin laat schijnen, ‘vrouw’ rechtstreeks verbindt met ‘vallende ster’ en de zin als geheel begrijpt. Dit vermogen om relaties vast te leggen, ongeacht de afstand, is cruciaal voor taken als automatische vertaling en samenvatting.
Lees ook: Een overzicht van het langetermijngeheugen (LSTM)
Parallelle verwerkingskracht
- probleem: Traditionele modellen verwerkten informatie opeenvolgend, alsof je een boek pagina voor pagina leest. Dit was traag en inefficiënt, vooral bij lange teksten.
- Aandachtsmechanisme: Stel je voor dat meerdere spotlights tegelijkertijd de bibliotheek scannen en tegelijkertijd verschillende delen van de tekst analyseren. Dit versnelt het werk van het model dramatisch, waardoor het grote hoeveelheden gegevens efficiënt kan verwerken. Deze parallelle verwerkingskracht is essentieel voor het trainen van complexe modellen en het maken van realtime voorspellingen.
Mondiaal contextbewustzijn
- probleem: Traditionele modellen concentreerden zich vaak op individuele woorden en misten de bredere context van de zin. Dit leidde tot misverstanden in gevallen als sarcasme of dubbele betekenissen.
- Aandachtsmechanisme: Stel je voor dat de spotlight over de hele bibliotheek schijnt, elk boek in je opneemt en begrijpt hoe ze zich tot elkaar verhouden. Door dit globale contextbewustzijn kan het model bij de interpretatie van elk woord de gehele tekst in beschouwing nemen, wat leidt tot een rijker en genuanceerder begrip.
Polysemische woorden ondubbelzinnig maken
- probleem: Woorden als ‘bank’ of ‘appel’ kunnen zelfstandige naamwoorden, werkwoorden of zelfs bedrijven zijn, waardoor dubbelzinnigheid ontstaat die traditionele modellen moeilijk konden oplossen.
- Aandachtsmechanisme: Stel je voor dat het model de spotlights richt op alle keren dat het woord ‘bank’ in een zin voorkomt, en vervolgens de omringende context en relaties met andere woorden analyseert. Door rekening te houden met de grammaticale structuur, zelfstandige naamwoorden in de buurt en zelfs zinnen uit het verleden, kan het aandachtsmechanisme de bedoelde betekenis afleiden. Dit vermogen om polysemische woorden ondubbelzinnig te maken is cruciaal voor taken als automatische vertaling, samenvatting van teksten en dialoogsystemen.
Deze vier aspecten – afhankelijkheid op lange termijn, parallelle verwerkingskracht, mondiaal contextbewustzijn en ondubbelzinnigheid – demonstreren de transformerende kracht van aandachtsmechanismen. Ze hebben Transformers naar de voorgrond gebracht op het gebied van natuurlijke taalverwerking, waardoor ze complexe taken met opmerkelijke nauwkeurigheid en efficiëntie kunnen uitvoeren.
Naarmate NLP en specifiek LLM's zich blijven ontwikkelen, zullen aandachtsmechanismen ongetwijfeld een nog crucialere rol spelen. Ze vormen de brug tussen de lineaire opeenvolging van woorden en het rijke tapijt van de menselijke taal, en uiteindelijk de sleutel tot het ontsluiten van het ware potentieel van deze taalkundige wonderen. Dit artikel gaat dieper in op de verschillende soorten aandachtsmechanismen en hun functionaliteiten.
1. Zelfaandacht: de leidende ster van de Transformer
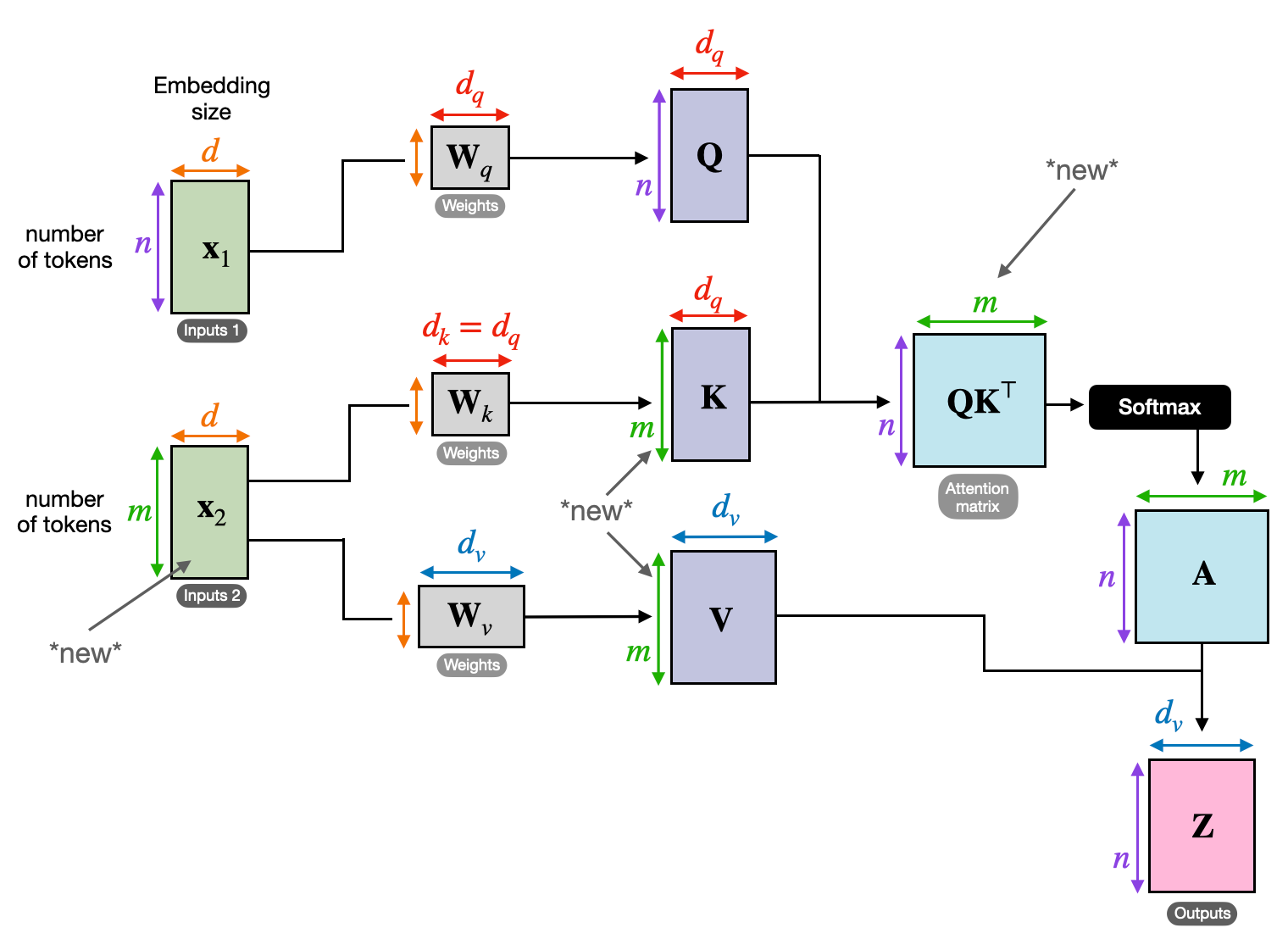
Stel je voor dat je met meerdere boeken moet jongleren en in elk boek naar specifieke passages moet verwijzen terwijl je een samenvatting schrijft. Zelfaandacht of Scaled Dot-Product-aandacht fungeert als een intelligente assistent en helpt modellen hetzelfde te doen met sequentiële gegevens zoals zinnen of tijdreeksen. Hierdoor kan elk element in de reeks aandacht besteden aan elk ander element, waardoor langeafstandsafhankelijkheden en complexe relaties effectief worden vastgelegd.
Hier is een nadere blik op de belangrijkste technische aspecten:
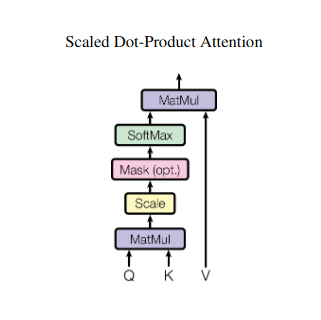
Vectorvertegenwoordiging
Elk element (woord, datapunt) wordt getransformeerd in een hoogdimensionale vector, die de informatie-inhoud ervan codeert. Deze vectorruimte dient als basis voor de interactie tussen elementen.
QKV-transformatie
Er worden drie sleutelmatrices gedefinieerd:
- Vraag (V): Vertegenwoordigt de ‘vraag’ die elk element aan de anderen stelt. Q legt de informatiebehoeften van het huidige element vast en begeleidt de zoektocht naar relevante informatie binnen de reeks.
- Sleutel (K): Bevat de “sleutel” tot de informatie van elk element. K codeert de essentie van de inhoud van elk element, waardoor andere elementen de potentiële relevantie kunnen identificeren op basis van hun eigen behoeften.
- Waarde (V): Slaat de daadwerkelijke inhoud op die elk element wil delen. V bevat de gedetailleerde informatie waar andere elementen toegang toe hebben en gebruik van kunnen maken op basis van hun aandachtsscores.
Berekening van de aandachtsscore
De compatibiliteit tussen elk elementenpaar wordt gemeten via een puntproduct tussen hun respectievelijke Q- en K-vectoren. Hogere scores duiden op een sterkere potentiële relevantie tussen de elementen.
Geschaalde aandachtsgewichten
Om het relatieve belang te garanderen, worden deze compatibiliteitsscores genormaliseerd met behulp van een softmax-functie. Dit resulteert in aandachtsgewichten, variërend van 0 tot 1, die het gewogen belang van elk element voor de context van het huidige element vertegenwoordigen.
Gewogen contextaggregatie
Aandachtsgewichten worden toegepast op de V-matrix, waardoor in wezen de belangrijke informatie van elk element wordt benadrukt op basis van de relevantie ervan voor het huidige element. Deze gewogen som creëert een gecontextualiseerde representatie voor het huidige element, waarbij inzichten uit alle andere elementen in de reeks worden meegenomen.
Verbeterde elementrepresentatie
Dankzij de verrijkte weergave beschikt het element nu over een dieper begrip van zijn eigen inhoud en van zijn relaties met andere elementen in de reeks. Deze getransformeerde representatie vormt de basis voor verdere verwerking binnen het model.
Dit uit meerdere stappen bestaande proces maakt zelfaandacht mogelijk voor:
- Leg afhankelijkheden op lange termijn vast: Relaties tussen op afstand gelegen elementen worden snel duidelijk, zelfs als ze gescheiden zijn door meerdere tussenliggende elementen.
- Modelleer complexe interacties: Subtiele afhankelijkheden en correlaties binnen de reeks worden aan het licht gebracht, wat leidt tot een rijker begrip van de datastructuur en dynamiek.
- Contextualiseer elk element: Het model analyseert elk element niet afzonderlijk, maar binnen het bredere raamwerk van de reeks, wat leidt tot nauwkeurigere en genuanceerdere voorspellingen of representaties.
Zelfaandacht heeft een revolutie teweeggebracht in de manier waarop modellen sequentiële gegevens verwerken, waardoor nieuwe mogelijkheden zijn ontsloten op diverse gebieden, zoals automatische vertaling, het genereren van natuurlijke taal, het voorspellen van tijdreeksen en meer. Het vermogen om de verborgen relaties binnen reeksen te onthullen, biedt een krachtig hulpmiddel voor het blootleggen van inzichten en het bereiken van superieure prestaties bij een breed scala aan taken.
2. Aandacht voor meerdere hoofden: kijken door verschillende lenzen
Zelfaandacht biedt een holistisch beeld, maar soms is het cruciaal om je te concentreren op specifieke aspecten van de gegevens. Dat is waar multi-head aandacht om de hoek komt kijken. Stel je voor dat je meerdere assistenten hebt, elk uitgerust met een andere lens:
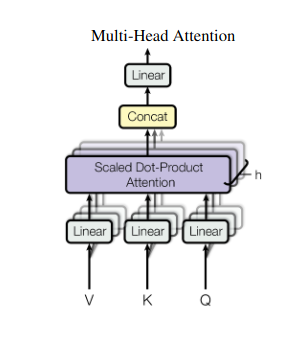
- Meerdere “hoofden” worden gemaakt, die elk de invoerreeks verzorgen via hun eigen Q-, K- en V-matrices.
- Elk hoofd leert zich te concentreren op verschillende aspecten van de gegevens, zoals afhankelijkheden op lange termijn, syntactische relaties of lokale woordinteracties.
- De outputs van elke kop worden vervolgens samengevoegd en geprojecteerd tot een uiteindelijke representatie, waarbij de veelzijdige aard van de input wordt vastgelegd.
Hierdoor kan het model tegelijkertijd verschillende perspectieven in overweging nemen, wat leidt tot een rijker en genuanceerder begrip van de gegevens.
3. Cross-aandacht: bruggen bouwen tussen reeksen
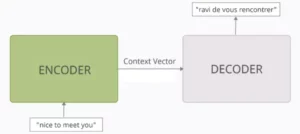
Het vermogen om verbindingen tussen verschillende stukjes informatie te begrijpen is cruciaal voor veel NLP-taken. Stel je voor dat je een boekrecensie schrijft. Je vat de tekst niet alleen woord voor woord samen, maar legt eerder inzichten en verbanden tussen de hoofdstukken. Binnenkomen kruis-aandacht, een krachtig mechanisme dat bruggen bouwt tussen reeksen, waardoor modellen informatie uit twee verschillende bronnen kunnen benutten.
- In encoder-decoder-architecturen zoals Transformers wordt de encoder verwerkt de invoerreeks (het boek) en genereert een verborgen representatie.
- De decoder gebruikt kruis-aandacht om bij elke stap aandacht te besteden aan de verborgen representatie van de encoder tijdens het genereren van de uitvoerreeks (de beoordeling).
- De Q-matrix van de decoder werkt samen met de K- en V-matrices van de encoder, waardoor deze zich kan concentreren op relevante delen van het boek terwijl hij elke zin van de recensie schrijft.
Dit mechanisme is van onschatbare waarde voor taken als automatische vertaling, samenvatting en het beantwoorden van vragen, waarbij het begrijpen van de relaties tussen invoer- en uitvoerreeksen essentieel is.
4. Causale aandacht: het behoud van de stroom van de tijd
Stel je voor dat je het volgende woord in een zin voorspelt zonder vooruit te kijken. Traditionele aandachtsmechanismen worstelen met taken waarbij de temporele volgorde van informatie behouden moet blijven, zoals het genereren van tekst en het voorspellen van tijdreeksen. Ze ‘kijken gemakkelijk vooruit’ in de reeks, wat leidt tot onnauwkeurige voorspellingen. Causale aandacht pakt deze beperking aan door ervoor te zorgen dat voorspellingen uitsluitend afhankelijk zijn van eerder verwerkte informatie.
Dit is hoe het werkt
- Maskeringsmechanisme: Er wordt een specifiek masker toegepast op de aandachtsgewichten, waardoor de toegang van het model tot toekomstige elementen in de reeks effectief wordt geblokkeerd. Bij het voorspellen van het tweede woord in ‘de vrouw die…’ kan het model bijvoorbeeld alleen rekening houden met ‘de’ en niet met ‘wie’ of daaropvolgende woorden.
- Autoregressieve verwerking: Informatie stroomt lineair, waarbij de representatie van elk element uitsluitend is opgebouwd uit elementen die ervoor verschijnen. Het model verwerkt de reeks woord voor woord en genereert voorspellingen op basis van de tot dan toe vastgestelde context.
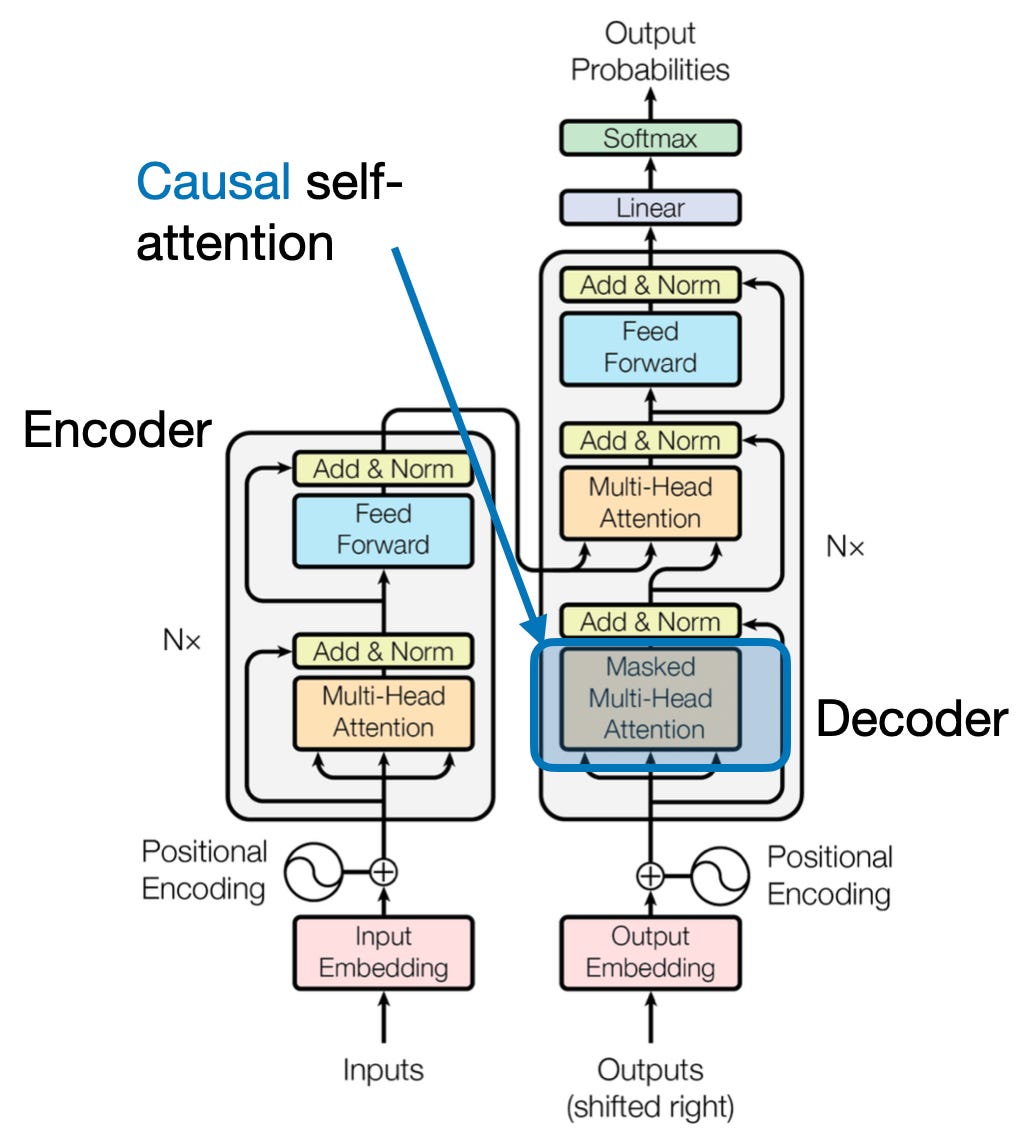
Causale aandacht is van cruciaal belang voor taken als het genereren van tekst en het voorspellen van tijdreeksen, waarbij het handhaven van de temporele volgorde van de gegevens essentieel is voor nauwkeurige voorspellingen.
5. Mondiale versus lokale aandacht: de balans vinden
Aandachtsmechanismen worden geconfronteerd met een belangrijke afweging: het vastleggen van afhankelijkheden op lange termijn versus het handhaven van efficiënte berekeningen. Dit manifesteert zich in twee primaire benaderingen: wereldwijde aandacht en lokale aandacht. Stel je voor dat je een heel boek leest in plaats van je te concentreren op een specifiek hoofdstuk. Globale aandacht verwerkt de hele reeks in één keer, terwijl lokale aandacht zich op een kleiner venster concentreert:
- Wereldwijde aandacht legt afhankelijkheden op lange afstand en de algehele context vast, maar kan rekenkundig duur zijn voor lange reeksen.
- Lokale aandacht is efficiënter, maar loopt mogelijk verre relaties mis.
De keuze tussen mondiale en lokale aandacht is afhankelijk van verschillende factoren:
- Taak vereisten: Taken als machinevertaling vereisen het vastleggen van verre relaties, waarbij de mondiale aandacht wordt bevorderd, terwijl sentimentanalyse de focus van lokale aandacht kan bevorderen.
- Sequentielengte:: Langere reeksen maken mondiale aandacht computationeel duur, waardoor lokale of hybride benaderingen nodig zijn.
- Modelcapaciteit: Beperkingen op het gebied van hulpbronnen kunnen lokale aandacht noodzakelijk maken, zelfs voor taken die een mondiale context vereisen.
Om de optimale balans te bereiken, kunnen modellen gebruik maken van:
- Dynamisch schakelen: gebruik mondiale aandacht voor sleutelelementen en lokale aandacht voor anderen, waarbij u zich aanpast op basis van belang en afstand.
- Hybride benaderingen: combineer beide mechanismen binnen dezelfde laag en benut hun respectieve sterke punten.
Lees ook: Analyse van soorten neurale netwerken bij deep learning
Conclusie
Uiteindelijk ligt de ideale aanpak in het spectrum tussen mondiale en lokale aandacht. Door deze afwegingen te begrijpen en geschikte strategieën toe te passen, kunnen modellen op efficiënte wijze relevante informatie op verschillende schaalniveaus benutten, wat leidt tot een rijker en nauwkeuriger begrip van de reeks.
Referenties
- Raschka, S. (2023). "Zelfaandacht, multi-head aandacht, kruisaandacht en causale aandacht in LLM's begrijpen en coderen."
- Vaswani, A., et al. (2017). “Aandacht is alles wat je nodig hebt.”
- Radford, A., et al. (2019). “Taalmodellen zijn multitask-leerlingen zonder toezicht.”
Verwant
Ik ben een dataliefhebber en ik hou ervan om de verborgen patronen in de data te extraheren en te begrijpen. Ik wil leren en groeien op het gebied van Machine Learning en Data Science.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- vermogen
- toegang
- nauwkeurigheid
- accuraat
- Bereiken
- het bereiken van
- over
- Handelingen
- daadwerkelijk
- adressen
- De goedkeuring van
- vooruit
- AL
- Alles
- Het toestaan
- toestaat
- am
- Dubbelzinnigheid
- hoeveelheden
- an
- analyse
- analyseert
- het analyseren van
- en
- beantwoorden
- uit elkaar
- schijnbaar
- toegepast
- nadering
- benaderingen
- ZIJN
- gebieden
- dit artikel
- AS
- aspecten
- Assistent
- assistenten
- At
- bijwonen
- Bijwonen
- aandacht
- bewustzijn
- Balance
- gebaseerde
- basis
- BE
- Balk
- worden
- vaardigheden
- tussen
- Verder
- blokkeren
- boek
- Boeken
- zowel
- BRUG
- bruggen
- Helder
- bredere
- bracht
- Gebouw
- bouwt
- bebouwd
- maar
- by
- kwam
- CAN
- vangen
- captures
- Het vastleggen
- gevallen
- verandering
- Hoofdstuk
- hoofdstukken
- keuze
- dichterbij
- codering
- combineren
- komt
- Bedrijven
- verenigbaarheid
- complex
- berekening
- computationeel
- Verbinden
- Wij verbinden
- aansluitingen
- Overwegen
- aangezien
- beperkingen
- bevat
- content
- verband
- voortzetten
- Kern
- correlaties
- aangemaakt
- creëert
- Wij creëren
- kritisch
- cruciaal
- Actueel
- gegevens
- data science
- Ontcijferen
- deep
- diepere
- gedefinieerd
- duikt
- afhangen
- afhankelijkheid
- afhankelijkheden
- Afhankelijkheid
- afhankelijk
- gedetailleerd
- Dialoog
- DEED
- anders
- direct
- afstand
- afgelegen
- onderscheiden
- diversen
- do
- document
- DOT
- verdubbelen
- tientallen
- dramatisch
- trekken
- twee
- dynamica
- E & T
- elk
- effectief
- doeltreffendheid
- doeltreffend
- efficiënt
- element
- geeft je de mogelijkheid
- empowering
- maakt
- waardoor
- codering
- verrijkt
- verzekeren
- zorgen
- Enter
- Geheel
- geheel
- uitgerust
- vooral
- essentie
- essentieel
- in wezen
- gevestigd
- Zelfs
- Alle
- ontwikkelen
- precies
- duur
- Exploiteren
- extract
- Gezicht
- factoren
- ver
- Favor
- veld-
- Velden
- finale
- stroom
- Stromen
- Focus
- gericht
- richt
- gericht
- Voor
- Voorhoede
- formulieren
- Foundation
- vier
- Achtergrond
- oppompen van
- functie
- functionaliteiten
- toekomst
- spel
- genereert
- het genereren van
- generatie
- Globaal
- globale context
- grijpen
- Groeien
- Guides
- leidend
- handvat
- Hebben
- met
- hoofd
- het helpen van
- verborgen
- Hoge
- hoger
- markeren
- houdt
- holistische
- Hoe
- HTTPS
- menselijk
- Hybride
- i
- ideaal
- identificeren
- if
- beeld
- Onmiddellijk
- belang
- belangrijk
- in
- onnauwkeurig
- opnemen
- aangeven
- individueel
- ondoeltreffend
- informatie
- inherent
- invoer
- inzichten
- instantie
- Intelligent
- bestemde
- wisselwerking
- interacties
- wisselwerking
- tussenkomen
- in
- onschatbaar
- isolatie
- IT
- HAAR
- jpg
- voor slechts
- sleutel
- Sleutelgebieden
- taal
- Achternaam*
- lagen
- leidend
- LEARN
- Leer en groei
- leerlingen
- leren
- LED
- lens
- lenzen
- Hefboomwerking
- leveraging
- Bibliotheek
- ligt
- licht
- als
- beperking
- beperkingen
- lokaal
- lang
- langer
- Kijk
- liefde
- machine
- machine learning
- machine vertaling
- behoud van
- maken
- maken
- man
- veel
- maskeren
- Matrix
- max-width
- betekenis
- betekenissen
- afgemeten
- mechanisme
- mechanismen
- Geheugen
- macht
- missen
- vermist
- model
- modellen
- meer
- efficiënter
- veelzijdig
- meervoudig
- Naturel
- Natuurlijke taal
- Natuurlijke taalgeneratie
- Natural Language Processing
- Natuurlijk taalbegrip
- NATUUR
- Noodzaak
- nodig
- behoeften
- buren
- netwerken
- Neural
- neurale netwerken
- New
- volgende
- nacht
- nlp
- zelfstandige naamwoorden
- nu
- genuanceerd
- of
- vaak
- on
- eens
- Slechts
- optimale
- or
- bestellen
- Overige
- Overig
- onze
- uit
- uitgang
- uitgangen
- totaal
- overzicht
- het te bezitten.
- pagina
- paar
- Papier
- Parallel
- onderdelen
- passages
- verleden
- patronen
- uitvoeren
- prestatie
- perspectieven
- stukken
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- punt
- vormt
- bezit
- mogelijkheden
- krachtig
- potentieel
- mogelijk
- energie
- krachtige
- het voorspellen van
- Voorspellingen
- het behoud van
- het voorkomen van
- die eerder
- in de eerste plaats
- primair
- verwerkt
- processen
- verwerking
- Rekenkracht
- Product
- geprojecteerde
- voortgestuwd
- biedt
- vraag
- reeks
- variërend
- liever
- Lees
- gemakkelijk
- lezing
- real-time
- referentie
- achteloos
- Relaties
- relatief
- relevantie
- relevante
- opmerkelijk
- vertegenwoordiging
- vertegenwoordigen
- vertegenwoordigt
- vereisen
- oplossen
- hulpbron
- Resources
- degenen
- Resultaten
- beoordelen
- revolutionair
- revolutie
- Rijk
- Rol
- s
- dezelfde
- Sarcasme
- zagen
- balans
- het scannen
- Wetenschap
- partituur
- scores
- Ontdek
- Tweede
- te zien
- zin
- sentiment
- Volgorde
- -Series
- bedient
- verscheidene
- Delen
- schitterend
- schieten
- Bermuda's
- showcase
- gelijktijdig
- traag
- kleinere
- uitsluitend
- OPLOSSEN
- soms
- bronnen
- Tussenruimte
- specifiek
- specifiek
- Spectrum
- snelheden
- Spotlight
- staand
- Ster
- Stap voor
- winkels
- strategieën
- sterke punten
- sterker
- structuur
- Worstelen
- onderwerpen
- volgend
- dergelijk
- geschikt
- som
- samenvatten
- OVERZICHT
- superieur
- nabijgelegen
- Systems
- aanpakken
- het nemen
- tapijtwerk
- taken
- Technisch
- termijn
- tekst
- tekst generatie
- dat
- De
- de wereld
- hun
- Ze
- harte
- Deze
- ze
- dit
- drie
- Door
- niet de tijd of
- Tijdreeksen
- naar
- tools
- traditioneel
- Trainingen
- transformatieve
- getransformeerd
- transformator
- transformers
- transformeren
- Vertaling
- waar
- twee
- types
- Tenslotte
- begrijpen
- begrip
- ongetwijfeld
- ontgrendelen
- onthullen
- onthuld
- .
- toepassingen
- gebruik
- divers
- groot
- Tegen
- Bekijk
- bezocht
- vitaal
- vs
- willen
- wil
- was
- GOED
- Wat
- wanneer
- en
- WIE
- geheel
- breed
- Grote range
- wil
- venster
- Met
- binnen
- zonder
- vrouw
- Woord
- woorden
- Mijn werk
- wereld
- het schrijven van
- gisteren
- u
- zephyrnet
- ZOO