In het eerste deel van deze driedelige serie presenteerden we een oplossing die laat zien hoe u het op grote schaal detecteren van geknoeid met documenten en fraude kunt automatiseren met behulp van AWS AI en machine learning (ML)-services voor een gebruiksscenario voor het afsluiten van hypotheken.
In dit artikel presenteren we een aanpak om een op deep learning gebaseerd computer vision-model te ontwikkelen om vervalste afbeeldingen bij het afsluiten van hypotheken te detecteren en onder de aandacht te brengen. We bieden begeleiding bij het bouwen, trainen en inzetten van deep learning-netwerken Amazon Sage Maker.
In deel 3 laten we zien hoe u de oplossing kunt implementeren Amazone fraude detector.
Overzicht oplossingen
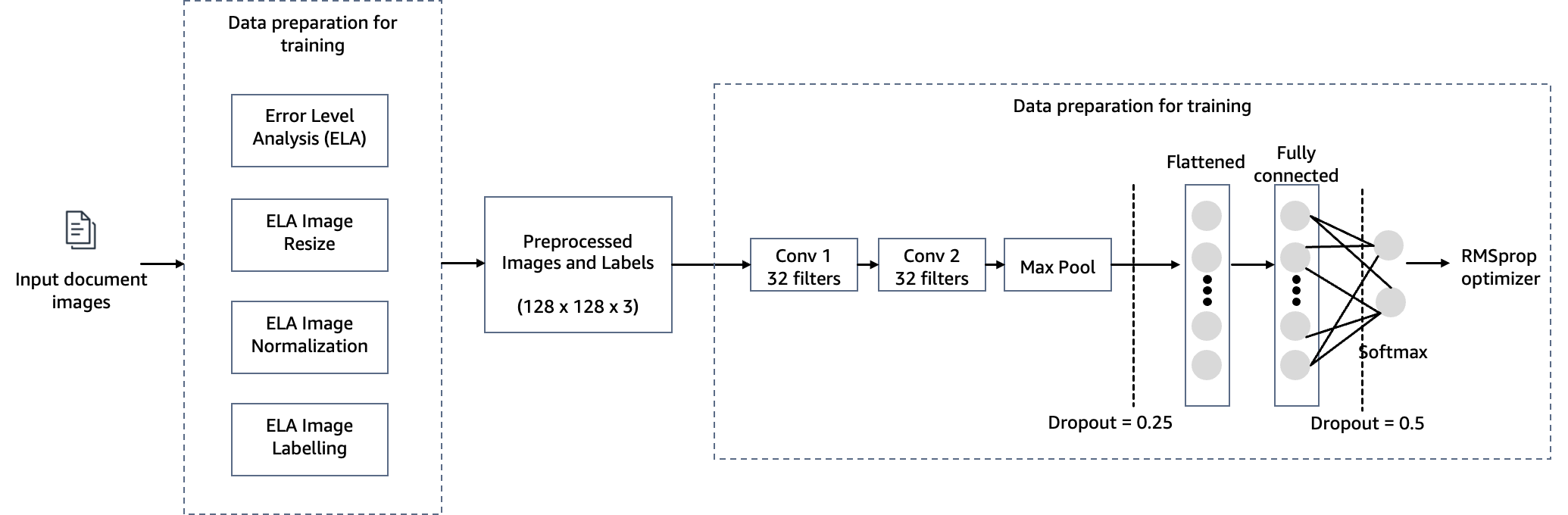
Om te voldoen aan het doel van het detecteren van geknoeid met documenten bij het afsluiten van hypotheken, gebruiken we een computer vision-model dat wordt gehost op SageMaker voor onze oplossing voor het detecteren van vervalsing van afbeeldingen. Dit model ontvangt een testbeeld als invoer en genereert als uitvoer een waarschijnlijkheidsvoorspelling van vervalsing. De netwerkarchitectuur is zoals weergegeven in het volgende diagram.
Bij het vervalsen van afbeeldingen zijn hoofdzakelijk vier technieken betrokken: splitsen, kopiëren en verplaatsen, verwijderen en verbeteren. Afhankelijk van de kenmerken van de vervalsing kunnen verschillende aanwijzingen worden gebruikt als basis voor detectie en lokalisatie. Deze aanwijzingen omvatten JPEG-compressieartefacten, inconsistenties aan de randen, ruispatronen, kleurconsistentie, visuele gelijkenis, EXIF-consistentie en cameramodel.
Gezien het uitgebreide domein van de detectie van vervalsing van afbeeldingen, gebruiken we het Error Level Analysis (ELA)-algoritme als een illustratieve methode voor het detecteren van vervalsingen. We hebben voor dit bericht de ELA-techniek geselecteerd om de volgende redenen:
- Het is sneller te implementeren en kan gemakkelijk manipulatie van afbeeldingen opsporen.
- Het werkt door de compressieniveaus van verschillende delen van een afbeelding te analyseren. Hierdoor kan het inconsistenties detecteren die op geknoei kunnen duiden, bijvoorbeeld als een gebied is gekopieerd en geplakt uit een andere afbeelding die op een ander compressieniveau is opgeslagen.
- Het is goed in het detecteren van subtielere of naadloze manipulatie die misschien moeilijk te zien is met het blote oog. Zelfs kleine wijzigingen aan een afbeelding kunnen detecteerbare compressie-afwijkingen veroorzaken.
- Het is niet afhankelijk van de originele, ongewijzigde afbeelding ter vergelijking. ELA kan alleen binnen het ondervraagde beeld zelf manipulatietekens identificeren. Bij andere technieken is vaak het ongewijzigde origineel nodig om mee te vergelijken.
- Het is een lichtgewicht techniek die alleen afhankelijk is van het analyseren van compressieartefacten in de digitale beeldgegevens. Het is niet afhankelijk van gespecialiseerde hardware of forensische expertise. Dit maakt ELA toegankelijk als een first-pass analysetool.
- Het uitgevoerde ELA-beeld kan de verschillen in compressieniveaus duidelijk benadrukken, waardoor de gemanipuleerde gebieden zichtbaar zichtbaar worden. Hierdoor kan zelfs een niet-expert tekenen van mogelijke manipulatie herkennen.
- Het werkt op veel afbeeldingstypen (zoals JPEG, PNG en GIF) en vereist alleen de afbeelding zelf om te analyseren. Andere forensische technieken kunnen beperkter zijn wat betreft formaten of originele beeldvereisten.
In praktijkscenario's waarin u mogelijk een combinatie van invoerdocumenten (JPEG, PNG, GIF, TIFF, PDF) heeft, raden we u echter aan ELA te gebruiken in combinatie met verschillende andere methoden, zoals het detecteren van inconsistenties in randen, geluidspatronen, kleuruniformiteit, Consistentie van EXIF-gegevens, identificatie van het cameramodel en uniformiteit van het lettertype. We streven ernaar de code voor dit bericht bij te werken met aanvullende technieken voor het detecteren van vervalsing.
Het onderliggende uitgangspunt van ELA gaat ervan uit dat de invoerafbeeldingen het JPEG-formaat hebben, bekend om de compressie met verlies. Niettemin kan de methode nog steeds effectief zijn, zelfs als de invoerafbeeldingen oorspronkelijk een verliesvrij formaat hadden (zoals PNG, GIF of BMP) en later tijdens het manipulatieproces naar JPEG werden omgezet. Wanneer ELA wordt toegepast op originele verliesvrije formaten, duidt dit doorgaans op een consistente beeldkwaliteit zonder enige verslechtering, waardoor het een uitdaging wordt om gewijzigde gebieden te lokaliseren. Bij JPEG-afbeeldingen is de verwachte norm dat de hele afbeelding vergelijkbare compressieniveaus vertoont. Als een bepaald gedeelte in de afbeelding echter een duidelijk ander foutniveau vertoont, duidt dit er vaak op dat er een digitale wijziging is aangebracht.
ELA benadrukt verschillen in de JPEG-compressiesnelheid. Gebieden met uniforme kleuren zullen waarschijnlijk een lager ELA-resultaat hebben (bijvoorbeeld een donkerdere kleur vergeleken met randen met hoog contrast). De dingen waar u op moet letten om manipulatie of wijziging te identificeren, zijn onder meer:
- Soortgelijke randen moeten een vergelijkbare helderheid hebben in het ELA-resultaat. Alle randen met hoog contrast moeten op elkaar lijken, en alle randen met laag contrast moeten er hetzelfde uitzien. Bij een originele foto moeten randen met laag contrast bijna net zo helder zijn als randen met hoog contrast.
- Soortgelijke texturen moeten onder ELA een vergelijkbare kleur hebben. Gebieden met meer oppervlaktedetails, zoals een close-up van een basketbal, zullen waarschijnlijk een hoger ELA-resultaat hebben dan een glad oppervlak.
- Ongeacht de werkelijke kleur van het oppervlak, moeten alle vlakke oppervlakken onder ELA ongeveer dezelfde kleur hebben.
JPEG-afbeeldingen gebruiken een compressiesysteem met verlies. Elke hercodering (opnieuw opslaan) van de afbeelding voegt meer kwaliteitsverlies toe aan de afbeelding. Concreet werkt het JPEG-algoritme op een raster van 8×8 pixels. Elk vierkant van 8×8 wordt onafhankelijk gecomprimeerd. Als het beeld volledig ongewijzigd is, zouden alle 8×8 vierkanten vergelijkbare foutmogelijkheden moeten hebben. Als de afbeelding ongewijzigd is en opnieuw wordt opgeslagen, zou elk vierkant in ongeveer dezelfde mate moeten verslechteren.
ELA slaat de afbeelding op een opgegeven JPEG-kwaliteitsniveau op. Dit opnieuw opslaan introduceert een bekend aantal fouten in de hele afbeelding. De opnieuw opgeslagen afbeelding wordt vervolgens vergeleken met de originele afbeelding. Als een afbeelding wordt gewijzigd, zou elk 8x8 vierkant dat door de wijziging werd geraakt, een hoger foutpotentieel moeten hebben dan de rest van de afbeelding.
De resultaten van ELA zijn direct afhankelijk van de beeldkwaliteit. Misschien wilt u weten of er iets is toegevoegd, maar als de afbeelding meerdere keren wordt gekopieerd, staat ELA mogelijk alleen toe dat de opnieuw opgeslagen bestanden worden gedetecteerd. Probeer de beste kwaliteitsversie van de afbeelding te vinden.
Met training en oefening kan ELA ook leren transformaties op het gebied van afbeeldingsschaling, kwaliteit, bijsnijden en opnieuw opslaan te identificeren. Als een niet-JPEG-afbeelding bijvoorbeeld zichtbare rasterlijnen bevat (1 pixel breed in 8×8 vierkanten), betekent dit dat de afbeelding is begonnen als JPEG en is geconverteerd naar een niet-JPEG-indeling (zoals PNG). Als sommige delen van de afbeelding geen rasterlijnen hebben of als de rasterlijnen verschuiven, duidt dit op een splitsing of getekend gedeelte in de niet-JPEG-afbeelding.
In de volgende secties demonstreren we de stappen voor het configureren, trainen en implementeren van het computer vision-model.
Voorwaarden
Om dit bericht te volgen, moet u aan de volgende vereisten voldoen:
- Heb een AWS-account.
- Instellen Amazon SageMaker Studio. U kunt SageMaker Studio snel starten met behulp van standaardvoorinstellingen, waardoor een snelle lancering mogelijk wordt. Voor meer informatie, zie Amazon SageMaker vereenvoudigt de installatie van Amazon SageMaker Studio voor individuele gebruikers.
- Open SageMaker Studio en start een systeemterminal.
- Voer de volgende opdracht uit in de terminal:
git clone https://github.com/aws-samples/document-tampering-detection.git - De totale kosten voor het uitvoeren van SageMaker Studio voor één gebruiker en de configuraties van de notebookomgeving bedragen $ 7.314 USD per uur.
Stel het modeltrainingsnotebook in
Voer de volgende stappen uit om uw trainingsnotebook in te stellen:
- Open de
tampering_detection_training.ipynbbestand uit de map Document-manipulatie-detectie. - Stel de notebookomgeving in met de afbeelding TensorFlow 2.6 Python 3.8 CPU of GPU Optimized.
Het kan zijn dat u problemen ondervindt met onvoldoende beschikbaarheid of dat u de quotumlimiet voor GPU-instanties binnen uw AWS-account bereikt wanneer u voor GPU geoptimaliseerde instanties selecteert. Als u het quotum wilt verhogen, gaat u naar de Service Quota-console en verhoogt u de servicelimiet voor het specifieke exemplaartype dat u nodig hebt. In dergelijke gevallen kunt u ook een CPU-geoptimaliseerde notebookomgeving gebruiken. - Voor pit, kiezen Python3.
- Voor Instantietype, kiezen ml.m5d.24xgroot of een ander groot exemplaar.
We hebben een groter exemplaartype geselecteerd om de trainingstijd van het model te verkorten. Met een ml.m5d.24xlarge notebookomgeving bedragen de kosten per uur $7.258 USD per uur.
Voer het trainingsnotitieblok uit
Voer elke cel in het notitieblok uit tampering_detection_training.ipynb in volgorde. We bespreken enkele cellen in meer detail in de volgende paragrafen.
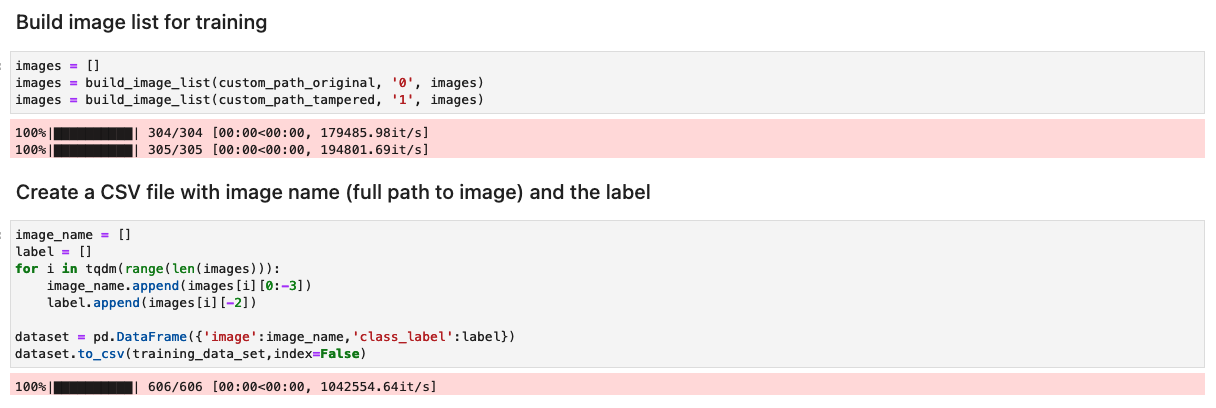
Bereid de dataset voor met een lijst met originele en gemanipuleerde afbeeldingen
Voordat u de volgende cel in het notitieblok uitvoert, moet u een gegevensset met originele en gemanipuleerde documenten voorbereiden op basis van uw specifieke zakelijke vereisten. Voor dit bericht gebruiken we een voorbeelddataset van geknoeide loonstrookjes en bankafschriften. De dataset is beschikbaar in de afbeeldingenmap van de GitHub-repository.

Het notitieboekje leest de originele en gemanipuleerde afbeeldingen van de images/training directory.
De gegevensset voor training wordt gemaakt met behulp van een CSV-bestand met twee kolommen: het pad naar het afbeeldingsbestand en het label voor de afbeelding (0 voor de originele afbeelding en 1 voor de afbeelding waarmee is geknoeid).
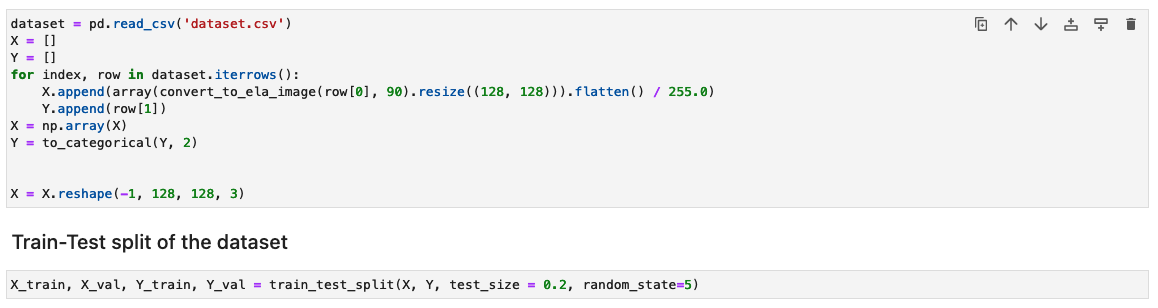
Verwerk de dataset door de ELA-resultaten van elk trainingsbeeld te genereren
In deze stap genereren we het ELA-resultaat (bij 90% kwaliteit) van het ingevoerde trainingsbeeld. De functie convert_to_ela_image heeft twee parameters nodig: pad, dat is het pad naar een afbeeldingsbestand, en kwaliteit, die de kwaliteitsparameter voor JPEG-compressie vertegenwoordigt. De functie voert de volgende stappen uit:
- Converteer de afbeelding naar RGB-formaat en sla de afbeelding opnieuw op als JPEG-bestand met de opgegeven kwaliteit onder de naam tempresaved.jpg.
- Bereken het verschil tussen de originele afbeelding en de opnieuw opgeslagen JPEG-afbeelding (ELA) om het maximale verschil in pixelwaarden tussen de originele en opnieuw opgeslagen afbeeldingen te bepalen.
- Bereken een schaalfactor op basis van het maximale verschil om de helderheid van het ELA-beeld aan te passen.
- Verbeter de helderheid van het ELA-beeld met behulp van de berekende schaalfactor.
- Wijzig het formaat van het ELA-resultaat naar 128x128x3, waarbij 3 het aantal kanalen vertegenwoordigt om de invoergrootte voor training te verkleinen.
- Retourneer de ELA-afbeelding.
Bij verliesgevende beeldformaten zoals JPEG leidt het initiële opslagproces tot aanzienlijk kleurverlies. Wanneer de afbeelding echter wordt geladen en vervolgens opnieuw wordt gecodeerd in hetzelfde verliesgevende formaat, is er over het algemeen minder kleurverslechtering. ELA-resultaten benadrukken de beeldgebieden die het meest gevoelig zijn voor kleurverslechtering bij opnieuw opslaan. Over het algemeen zijn veranderingen duidelijk zichtbaar in gebieden waar de kans op verslechtering groter is dan in de rest van de afbeelding.
Vervolgens worden de afbeeldingen verwerkt tot een NumPy-array voor training. Vervolgens splitsen we de invoergegevensset willekeurig op in trainings- en test- of validatiegegevens (80/20). U kunt eventuele waarschuwingen negeren wanneer u deze cellen uitvoert.
Afhankelijk van de grootte van de gegevensset kan het enige tijd duren voordat deze cellen zijn voltooid. Voor de voorbeelddataset die we in deze repository hebben verstrekt, kan dit 5 tot 10 minuten duren.
Configureer het CNN-model
In deze stap construeren we een minimale versie van het VGG-netwerk met kleine convolutionele filters. De VGG-16 bestaat uit 13 convolutionele lagen en drie volledig verbonden lagen. De volgende schermafbeelding illustreert de architectuur van ons Convolutional Neural Network (CNN) -model.
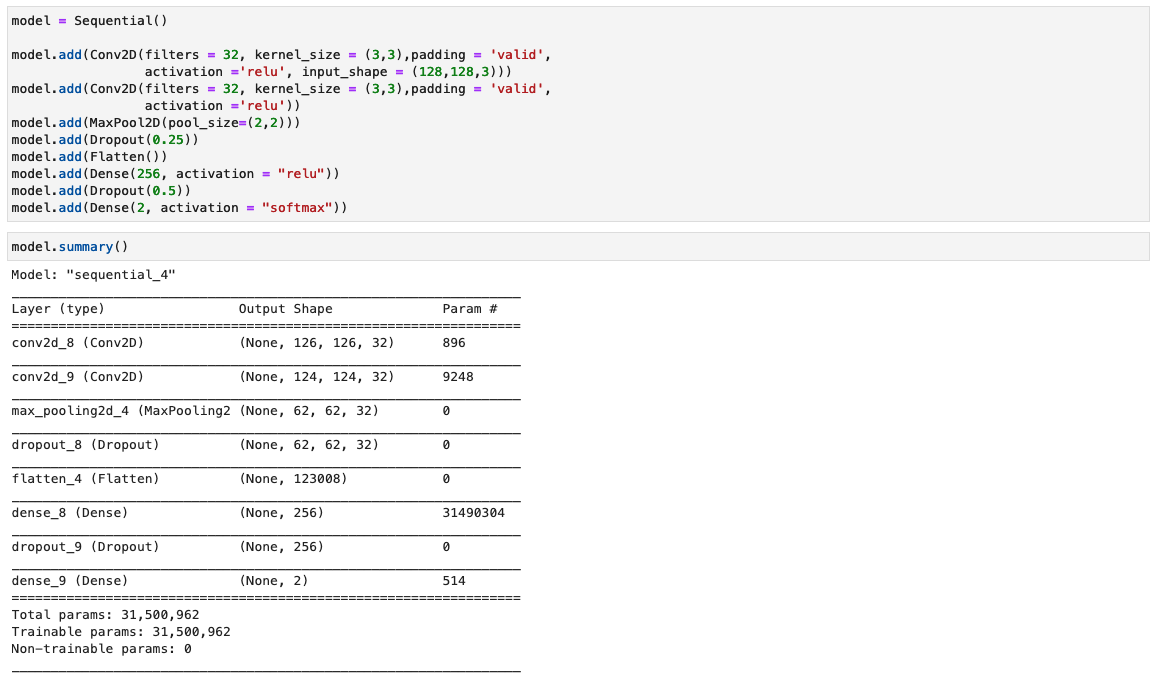
Let op de volgende configuraties:
- Invoer – Het model heeft een beeldinvoerformaat van 128x128x3.
- Convolutionele lagen – De convolutionele lagen gebruiken een minimaal receptief veld (3×3), de kleinst mogelijke grootte die nog steeds omhoog/omlaag en links/rechts opvangt. Dit wordt gevolgd door een rectified linear unit (ReLU)-activeringsfunctie die de trainingstijd verkort. Dit is een lineaire functie die de invoer uitvoert als deze positief is; anders is de uitvoer nul. De convolutiestap is vast ingesteld op de standaardwaarde (1 pixel) om de ruimtelijke resolutie na convolutie behouden te houden (stap is het aantal pixelverschuivingen over de invoermatrix).
- Volledig verbonden lagen – Het netwerk heeft twee volledig verbonden lagen. De eerste dichte laag maakt gebruik van ReLU-activering en de tweede gebruikt softmax om de afbeelding te classificeren als origineel of als er mee is geknoeid.
U kunt eventuele waarschuwingen negeren wanneer u deze cellen uitvoert.
Sla de modelartefacten op
Sla het getrainde model op met een unieke bestandsnaam, bijvoorbeeld op basis van de huidige datum en tijd, in een map met de naam model.

Het model wordt opgeslagen in Keras-formaat met de extensie .keras. We slaan de modelartefacten ook op als een map met de naam 1 die geserialiseerde handtekeningen bevat en de status die nodig is om ze uit te voeren, inclusief variabele waarden en vocabulaires om te implementeren in een SageMaker-runtime (die we later in dit bericht bespreken).
Meet de prestaties van modellen
De volgende verliescurve toont de voortgang van het verlies van het model over trainingstijdvakken (iteraties).
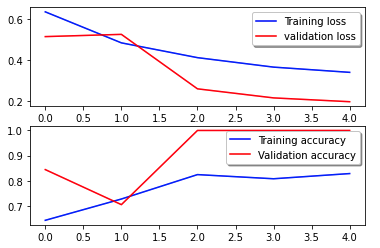
De verliesfunctie meet hoe goed de voorspellingen van het model overeenkomen met de werkelijke doelstellingen. Lagere waarden duiden op een betere afstemming tussen voorspellingen en werkelijke waarden. Het afnemende verlies over perioden betekent dat het model verbetert. De nauwkeurigheidscurve illustreert de nauwkeurigheid van het model over trainingsperioden. Nauwkeurigheid is de verhouding tussen correcte voorspellingen en het totale aantal voorspellingen. Een hogere nauwkeurigheid duidt op een beter presterend model. Doorgaans neemt de nauwkeurigheid toe tijdens de training naarmate het model patronen leert en zijn voorspellende vermogen verbetert. Hiermee kunt u bepalen of het model overfitting is (goed presteert op trainingsgegevens, maar slecht op onzichtbare gegevens) of te weinig past (niet genoeg leert van de trainingsgegevens).
De volgende verwarringsmatrix geeft visueel weer hoe goed het model nauwkeurig onderscheid maakt tussen de positieve (vervalste afbeelding, weergegeven als waarde 1) en negatieve (onvervalste afbeelding, weergegeven als waarde 0) klassen.
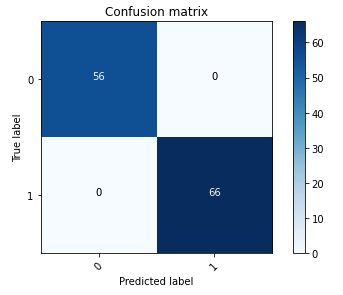
Na de modeltraining is onze volgende stap het inzetten van het computer vision-model als een API. Deze API zal worden geïntegreerd in bedrijfsapplicaties als onderdeel van de acceptatieworkflow. Om dit te bereiken gebruiken we Amazon SageMaker Inference, een volledig beheerde service. Deze service kan naadloos worden geïntegreerd met MLOps-tools, waardoor schaalbare modelimplementatie, kostenefficiënte gevolgtrekking, verbeterd modelbeheer in de productie en verminderde operationele complexiteit mogelijk worden. In dit bericht implementeren we het model als een realtime inferentie-eindpunt. Het is echter belangrijk op te merken dat, afhankelijk van de workflow van uw bedrijfsapplicaties, de modelimplementatie ook kan worden aangepast als batchverwerking, asynchrone verwerking of via een serverloze implementatiearchitectuur.
Stel het modelimplementatienotebook in
Voer de volgende stappen uit om uw modelimplementatienotebook in te stellen:
- Open de
tampering_detection_model_deploy.ipynbbestand uit de directory voor het detecteren van manipulatie van documenten. - Stel de notebookomgeving in met de afbeelding Data Science 3.0.
- Voor pit, kiezen Python3.
- Voor Instantietype, kiezen ml.t3.medium.
Met een ml.t3.medium notebookomgeving bedragen de kosten per uur $ 0.056 USD.
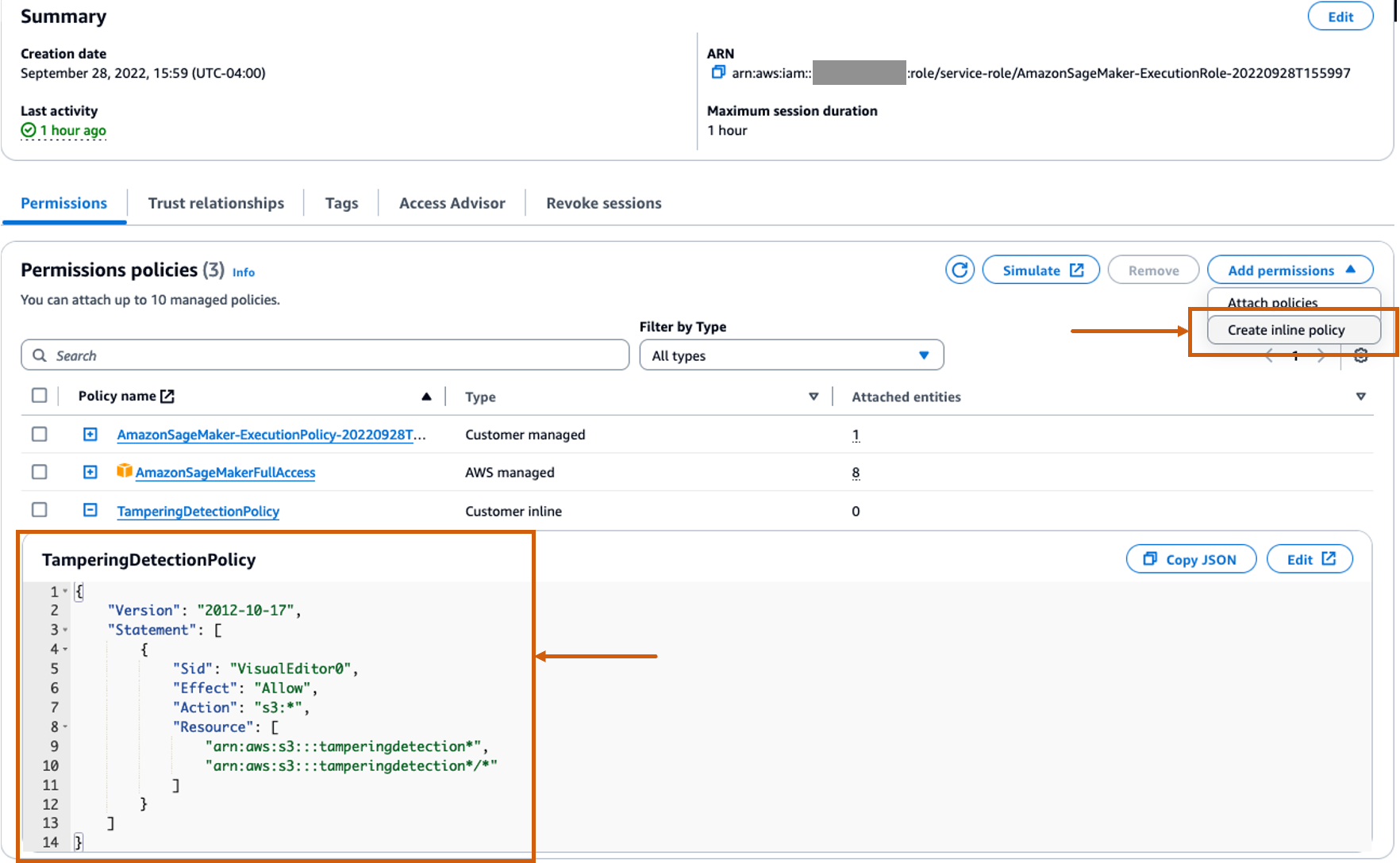
Maak een aangepast inline-beleid voor de SageMaker-rol om alle Amazon S3-acties toe te staan
De AWS Identiteits- en toegangsbeheer (IAM)-rol voor SageMaker zal in het formaat zijn AmazonSageMaker- ExecutionRole-<random numbers>. Zorg ervoor dat u de juiste rol gebruikt. De rolnaam vindt u onder de gebruikersgegevens binnen de SageMaker-domeinconfiguraties.

Werk de IAM-rol bij om een inline-beleid op te nemen dat alles toestaat Amazon eenvoudige opslagservice (Amazon S3) acties. Dit is nodig om het maken en verwijderen van S3-buckets waarin de modelartefacten worden opgeslagen, te automatiseren. U kunt de toegang tot specifieke S3-buckets beperken. Houd er rekening mee dat we in het IAM-beleid een jokerteken hebben gebruikt voor de S3-bucketnaam (tamperingdetection*).
Voer het implementatienotebook uit
Voer elke cel in het notitieblok uit tampering_detection_model_deploy.ipynb in volgorde. We bespreken enkele cellen in meer detail in de volgende paragrafen.
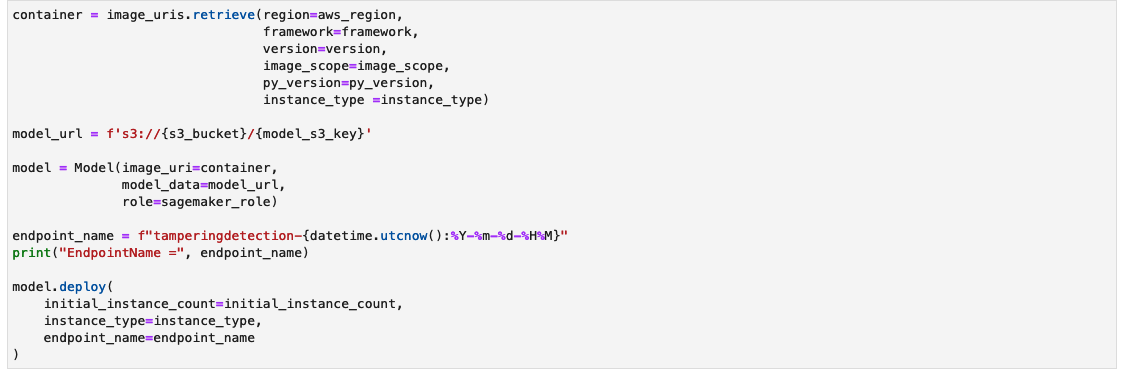
Maak een S3-bucket
Voer de cel uit om een S3-bucket te maken. De emmer krijgt een naam tamperingdetection<current date time> en in dezelfde AWS-regio als uw SageMaker Studio-omgeving.

Maak het modelartefactarchief en upload het naar Amazon S3
Maak een tar.gz-bestand van de modelartefacten. We hebben de modelartefacten opgeslagen als een map met de naam 1, die geserialiseerde handtekeningen bevat en de status die nodig is om ze uit te voeren, inclusief variabele waarden en vocabulaires om te implementeren in de SageMaker-runtime. U kunt ook een aangepast inferentiebestand opnemen met de naam inference.py in de codemap in het modelartefact. De aangepaste gevolgtrekking kan worden gebruikt voor de voor- en nabewerking van de invoerafbeelding.
![]()
Maak een SageMaker-inferentie-eindpunt
Het kan enkele minuten duren voordat de cel voor het maken van een SageMaker-inferentie-eindpunt is voltooid.
Test het inferentie-eindpunt
De functie check_image verwerkt een afbeelding voor als een ELA-afbeelding, stuurt deze naar een SageMaker-eindpunt voor gevolgtrekking, haalt de voorspellingen van het model op en verwerkt deze, en drukt de resultaten af. Het model gebruikt een NumPy-array van de invoerafbeelding als een ELA-afbeelding om voorspellingen te doen. De voorspellingen worden uitgevoerd als 0, wat een ongemanipuleerd beeld vertegenwoordigt, en 1, wat een vervalst beeld vertegenwoordigt.

Laten we het model oproepen met een onbewerkte afbeelding van een loonstrookje en het resultaat controleren.

Het model voert de classificatie uit als 0, wat een ongemanipuleerd beeld vertegenwoordigt.
Laten we nu het model met een geknoeide afbeelding van een loonstrookje oproepen en het resultaat controleren.

Het model geeft de classificatie als 1 weer, wat een vervalst beeld vertegenwoordigt.
Beperkingen
Hoewel ELA een uitstekend hulpmiddel is om wijzigingen te helpen detecteren, zijn er een aantal beperkingen, zoals de volgende:
- Het is mogelijk dat een enkele pixelverandering of een kleine kleuraanpassing geen merkbare verandering in de ELA genereert, omdat JPEG op een raster werkt.
- ELA identificeert alleen welke regio's verschillende compressieniveaus hebben. Als een afbeelding van lagere kwaliteit wordt samengevoegd tot een afbeelding van hogere kwaliteit, kan de afbeelding van lagere kwaliteit als een donkerder gebied verschijnen.
- Door een afbeelding te schalen, opnieuw te kleuren of ruis toe te voegen, wordt de hele afbeelding gewijzigd, waardoor er een hoger foutniveau ontstaat.
- Als een afbeelding meerdere keren opnieuw wordt opgeslagen, kan dit een minimaal foutniveau hebben, waarbij meer opnieuw opslaan de afbeelding niet verandert. In dit geval retourneert de ELA een zwart beeld en kunnen er met dit algoritme geen wijzigingen worden geïdentificeerd.
- Met Photoshop kan de simpele handeling van het opslaan van de foto de texturen en randen automatisch verscherpen, waardoor er een hoger foutniveau ontstaat. Dit artefact identificeert geen opzettelijke wijziging; het geeft aan dat er een Adobe-product is gebruikt. Technisch gezien lijkt ELA een wijziging omdat Adobe automatisch een wijziging heeft uitgevoerd, maar de wijziging was niet noodzakelijkerwijs opzettelijk door de gebruiker.
We raden aan om ELA te gebruiken naast andere technieken die eerder in de blog zijn besproken, om een groter aantal gevallen van beeldmanipulatie te kunnen detecteren. ELA kan ook dienen als een onafhankelijk hulpmiddel voor het visueel onderzoeken van beeldverschillen, vooral wanneer het trainen van een op CNN gebaseerd model een uitdaging wordt.
Opruimen
Voer de volgende stappen uit om de bronnen te verwijderen die u als onderdeel van deze oplossing hebt gemaakt:
- Voer de notebookcellen uit onder het Opruimen sectie. Hiermee wordt het volgende verwijderd:
- SageMaker-eindpunt voor inferentie – De naam van het inferentie-eindpunt is
tamperingdetection-<datetime>. - Objecten binnen de S3-bucket en de S3-bucket zelf – De bucketnaam zal zijn
tamperingdetection<datetime>.
- SageMaker-eindpunt voor inferentie – De naam van het inferentie-eindpunt is
- stilgelegd de SageMaker Studio-notebookbronnen.
Conclusie
In dit bericht presenteerden we een end-to-end-oplossing voor het detecteren van geknoei met documenten en fraude met behulp van deep learning en SageMaker. We hebben ELA gebruikt om afbeeldingen voor te bewerken en discrepanties in compressieniveaus te identificeren die op manipulatie kunnen duiden. Vervolgens hebben we een CNN-model op deze verwerkte dataset getraind om afbeeldingen als origineel of gemanipuleerd te classificeren.
Het model kan sterke prestaties leveren, met een nauwkeurigheid van meer dan 95%, met een dataset (vervalst en origineel) die geschikt is voor uw zakelijke vereisten. Dit geeft aan dat het op betrouwbare wijze vervalste documenten zoals loonstrookjes en bankafschriften kan detecteren. Het getrainde model wordt geïmplementeerd op een SageMaker-eindpunt om inferentie met lage latentie op schaal mogelijk te maken. Door deze oplossing te integreren in hypotheekworkflows kunnen instellingen automatisch verdachte documenten markeren voor verder fraudeonderzoek.
Hoewel krachtig, heeft ELA enkele beperkingen bij het identificeren van bepaalde soorten subtielere manipulatie. Als volgende stappen zou het model kunnen worden verbeterd door aanvullende forensische technieken in de training op te nemen en grotere, meer diverse datasets te gebruiken. Over het geheel genomen laat deze oplossing zien hoe u deep learning- en AWS-services kunt gebruiken om impactvolle oplossingen te bouwen die de efficiëntie verhogen, risico's verminderen en fraude voorkomen.
In deel 3 laten we zien hoe u de oplossing op Amazon Fraud Detector kunt implementeren.
Over de auteurs
 Anup Ravindranath is een Senior Solutions Architect bij Amazon Web Services (AWS), gevestigd in Toronto, Canada en werkt samen met financiële dienstverleners. Hij helpt klanten om hun bedrijf te transformeren en te innoveren in de cloud.
Anup Ravindranath is een Senior Solutions Architect bij Amazon Web Services (AWS), gevestigd in Toronto, Canada en werkt samen met financiële dienstverleners. Hij helpt klanten om hun bedrijf te transformeren en te innoveren in de cloud.
 Vinnie Saini is een Senior Solutions Architect bij Amazon Web Services (AWS), gevestigd in Toronto, Canada. Ze heeft financiële dienstverleners geholpen om te transformeren naar de cloud, met AI- en ML-gestuurde oplossingen die zijn gebaseerd op sterke pijlers van architecturale uitmuntendheid.
Vinnie Saini is een Senior Solutions Architect bij Amazon Web Services (AWS), gevestigd in Toronto, Canada. Ze heeft financiële dienstverleners geholpen om te transformeren naar de cloud, met AI- en ML-gestuurde oplossingen die zijn gebaseerd op sterke pijlers van architecturale uitmuntendheid.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- : heeft
- :is
- :niet
- :waar
- $UP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95%
- a
- vermogen
- Over
- toegang
- beschikbaar
- Account
- nauwkeurigheid
- nauwkeurig
- Bereiken
- over
- Handelen
- acties
- Activering
- daadwerkelijk
- toegevoegd
- toe te voegen
- Extra
- Voegt
- aanpassen
- Aanpassing
- adobe
- Na
- tegen
- AI
- streven
- algoritme
- opstelling
- Alles
- toelaten
- toestaat
- bijna
- langs
- naast
- ook
- gewijzigd
- Amazone
- Amazone fraude detector
- Amazon Sage Maker
- Amazon SageMaker Studio
- Amazon Web Services
- Amazon Web Services (AWS)
- bedragen
- an
- analyse
- analyseren
- het analyseren van
- en
- Nog een
- elke
- api
- verschijnen
- komt naar voren
- toepassingen
- toegepast
- nadering
- ongeveer
- bouwkundig
- architectuur
- Archief
- ZIJN
- GEBIED
- gebieden
- reeks
- AS
- gaat uit van
- At
- automatiseren
- webmaster.
- beschikbaarheid
- Beschikbaar
- AWS
- Bank
- gebaseerde
- Basketbal
- BE
- omdat
- wordt
- geweest
- BEST
- Betere
- tussen
- Zwart
- Blog
- boost
- Helder
- bouw
- Gebouw
- bedrijfsdeskundigen
- Business Applications
- ondernemingen
- maar
- by
- berekend
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- camera
- CAN
- Canada
- captures
- geval
- gevallen
- het worstelen
- cel
- Cellen
- zeker
- uitdagend
- verandering
- Wijzigingen
- kanalen
- kenmerken
- controle
- Kies
- klassen
- classificatie
- classificeren
- duidelijk
- Cloud
- CNN
- code
- kleur
- columns
- combinatie van
- vergelijken
- vergeleken
- vergelijking
- compleet
- compleet
- ingewikkeldheid
- bestanddeel
- computer
- Computer visie
- configureren
- verwarring
- samenwerking
- gekoppeld blijven
- aanzienlijk
- consequent
- bestaat uit
- troosten
- bouwen
- bevat
- converteren
- geconverteerd
- convolutioneel neuraal netwerk
- te corrigeren
- Kosten
- kon
- CPU
- en je merk te creëren
- aangemaakt
- Wij creëren
- het aanmaken
- Actueel
- curve
- gewoonte
- Klanten
- donkerder
- gegevens
- data science
- datasets
- Datum
- afnemende
- deep
- diepgaand leren
- Standaard
- tonen
- demonstreert
- duidt
- dicht
- afhangen
- afhankelijk
- Afhankelijk
- implementeren
- ingezet
- het inzetten
- inzet
- detail
- gegevens
- opsporen
- Opsporing
- Bepalen
- ontwikkelen
- diagram
- verschil
- verschillen
- anders
- digitaal
- direct
- bespreken
- besproken
- displays
- onderscheidt
- diversen
- do
- document
- documenten
- Nee
- domein
- getrokken
- gedreven
- gedurende
- elk
- gemakkelijk
- rand
- effectief
- doeltreffendheid
- benadrukken
- gebruik
- in staat stellen
- waardoor
- eind tot eind
- Endpoint
- verbeterde
- enhancement
- genoeg
- Geheel
- geheel
- Milieu
- tijdperken
- fout
- fouten
- vooral
- Ether (ETH)
- Zelfs
- Alle
- Onderzoeken
- voorbeeld
- Uitmuntendheid
- uitstekend
- tentoonstellen
- exposeren
- expansieve
- verwacht
- expertise
- uitbreiding
- oog
- faciliterende
- factor
- weinig
- veld-
- Dien in
- filters
- financieel
- financiële diensten
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- vast
- plat
- volgen
- gevolgd
- volgend
- Voor
- gerechtelijk
- forensisch onderzoek
- nagemaakt
- formaat
- gevonden
- Foundation
- Basis
- vier
- bedrog
- oppompen van
- geheel
- functie
- verder
- algemeen
- voortbrengen
- genereert
- het genereren van
- gif
- Git
- goed
- GPU
- meer
- Raster
- leiding
- HAD
- Behandeling
- Hard
- Hardware
- Hebben
- met
- he
- hulp
- het helpen van
- helpt
- hoger
- Markeer
- highlights
- Hit
- gastheer
- gehost
- uur
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- IAM
- geïdentificeerd
- identificeert
- identificeren
- het identificeren van
- Identiteit
- IEEE
- if
- negeren
- illustreert
- beeld
- afbeeldingen
- impactvolle
- uitvoeren
- belangrijk
- verbetert
- het verbeteren van
- in
- omvatten
- Inclusief
- inconsistenties
- opnemen
- Laat uw omzet
- Verhoogt
- onafhankelijk
- onafhankelijk
- aangeven
- geeft aan
- individueel
- informatie
- eerste
- beginnen
- innoveren
- invoer
- instantie
- gevallen
- instellingen
- geïntegreerde
- integreert
- Integreren
- Opzettelijk
- in
- voorstellen
- Introduceert
- onderzoek
- gaat
- kwestie
- IT
- iteraties
- HAAR
- zelf
- jpg
- Houden
- Keras
- blijven
- bekend
- label
- Gebrek
- Groot
- groter
- later
- lancering
- lagen
- Legkippen
- Leads
- LEARN
- leren
- minder
- Niveau
- niveaus
- lichtgewicht
- als
- waarschijnlijkheid
- Waarschijnlijk
- LIMIT
- beperkingen
- lineair
- lijnen
- Lijst
- Lokalisatie
- Kijk
- uit
- te verlagen
- machine
- machine learning
- gemaakt
- voornamelijk
- maken
- MERKEN
- maken
- beheerd
- management
- Manipulatie
- veel
- Match
- Matrix
- maximaal
- Mei..
- middel
- maatregelen
- Medium
- Maak kennis met
- methode
- methoden
- minimaal
- minimum
- minder
- minuten
- ML
- MLops
- model
- wijzigingen
- gewijzigd
- wijzigen
- meer
- Hypotheek
- meest
- meervoudig
- naam
- Genoemd
- nodig
- Noodzaak
- nodig
- negatief
- netwerk
- netwerken
- Neural
- neuraal netwerk
- niettemin
- volgende
- geen
- Geluid
- nota
- notitieboekje
- aantal
- numpy
- doel van de persoon
- Voor de hand liggend
- of
- vaak
- on
- EEN
- Slechts
- exploiteert
- operationele
- geoptimaliseerde
- or
- bestellen
- organisaties
- origineel
- oorspronkelijk
- Overige
- anders-
- onze
- resultaten
- uitgang
- uitgangen
- over
- totaal
- parameter
- parameters
- deel
- bijzonder
- onderdelen
- pad
- patronen
- voor
- prestatie
- uitgevoerd
- uitvoerend
- presteert
- foto
- photoshop
- beeld
- pijlers
- pixel
- Plato
- Plato gegevensintelligentie
- PlatoData
- perceel
- beleidsmaatregelen
- deel
- positief
- mogelijk
- Post
- potentieel
- mogelijkheden
- krachtige
- praktijk
- voorspelling
- Voorspellingen
- voorspellend
- Voorbereiden
- vereisten
- presenteren
- gepresenteerd
- bewaard
- voorkomen
- die eerder
- prints
- verwerkt
- processen
- verwerking
- Product
- productie
- progressie
- zorgen voor
- mits
- Python
- kwaliteit
- Ondervraagd
- sneller
- willekeurige
- reeks
- snel
- tarief
- verhouding
- echte wereld
- real-time
- rijk
- redenen
- ontvangt
- herkennen
- adviseren
- gerectificeerd
- verminderen
- Gereduceerd
- vermindert
- verwijzen
- regio
- regio
- hervatting
- vertrouwen
- verwijdering
- verwijderen
- weergave
- bewaarplaats
- vertegenwoordigd
- vertegenwoordigen
- vertegenwoordigt
- vereisen
- nodig
- Voorwaarden
- vereist
- Resolutie
- Resources
- REST
- begrensd
- resultaat
- Resultaten
- terugkeer
- RGB
- Risico
- Rol
- lopen
- lopend
- sagemaker
- SageMaker Inferentie
- dezelfde
- Voorbeeldgegevensset
- Bespaar
- gered
- besparing
- schaalbare
- Scale
- scaling
- scenario's
- Wetenschap
- naadloos
- naadloos
- Tweede
- sectie
- secties
- gekozen
- selecteren
- verzendt
- senior
- -Series
- dienen
- Serverless
- service
- Diensten
- reeks
- setup
- ze
- verschuiving
- Ploegen
- moet
- Shows
- handtekeningen
- betekent
- Signs
- gelijk
- Eenvoudig
- vereenvoudigt
- single
- Maat
- Klein
- glad
- oplossing
- Oplossingen
- sommige
- iets
- ruimtelijke
- gespecialiseerde
- specifiek
- specifiek
- gespecificeerd
- spleet
- Spot
- vierkant
- pleinen
- gestart
- Land
- verklaringen
- Stap voor
- Stappen
- Still
- mediaopslag
- shop
- schrijden
- sterke
- studio
- Hierop volgend
- dergelijk
- Stelt voor
- zeker
- Oppervlak
- geneigd
- verdacht
- snel
- system
- op maat gemaakt
- Nemen
- neemt
- doelen
- technisch
- techniek
- technieken
- tensorflow
- terminal
- proef
- Testen
- neem contact
- dat
- De
- De Staat
- hun
- Ze
- harte
- Er.
- Deze
- spullen
- dit
- drie
- Door
- niet de tijd of
- keer
- naar
- tools
- tools
- toronto
- Totaal
- aangeraakt
- Trainen
- getraind
- Trainingen
- Transformeren
- transformaties
- waar
- proberen
- twee
- type dan:
- types
- typisch
- voor
- die ten grondslag liggen
- underwriting
- unieke
- eenheid
- bijwerken
- op
- USD
- .
- use case
- gebruikt
- Gebruiker
- toepassingen
- gebruik
- bevestiging
- waarde
- Values
- variabele
- divers
- versie
- zichtbaar
- visie
- Bezoek
- visuele
- visueel
- willen
- was
- we
- web
- webservices
- GOED
- waren
- Wat
- wanneer
- welke
- breed
- wil
- Met
- binnen
- zonder
- workflow
- workflows
- werkzaam
- Bedrijven
- u
- Your
- zephyrnet
- nul