
Afbeelding gemaakt met DALL-E3
Kunstmatige intelligentie is een complete revolutie geweest in de technische wereld.
Het vermogen om menselijke intelligentie na te bootsen en taken uit te voeren die ooit als uitsluitend menselijke domeinen werden beschouwd, verbaast de meesten van ons nog steeds.
Hoe goed deze late AI-sprongen ook zijn geweest, er is altijd ruimte voor verbetering.
En dit is precies waar snelle engineering om de hoek komt kijken!
Voer dit veld in dat de productiviteit van AI-modellen aanzienlijk kan verbeteren.
Laten we het allemaal samen ontdekken!
Prompt engineering is een snelgroeiend domein binnen AI dat zich richt op het verbeteren van de efficiëntie en effectiviteit van taalmodellen. Het draait allemaal om het maken van perfecte aanwijzingen om AI-modellen te begeleiden om de gewenste resultaten te produceren.
Zie het als leren hoe je betere instructies aan iemand kunt geven om ervoor te zorgen dat hij of zij een taak correct begrijpt en uitvoert.
Waarom snelle engineering belangrijk is
- Verbeterde productiviteit: Door gebruik te maken van hoogwaardige aanwijzingen kunnen AI-modellen nauwkeurigere en relevantere antwoorden genereren. Dit betekent dat er minder tijd wordt besteed aan correcties en dat er meer tijd wordt besteed aan het benutten van de mogelijkheden van AI.
- Kost efficiëntie: Het trainen van AI-modellen vergt veel middelen. Snelle engineering kan de noodzaak van herscholing verminderen door de modelprestaties te optimaliseren via betere aanwijzingen.
- Veelzijdigheid: Een goed opgestelde prompt kan AI-modellen veelzijdiger maken, waardoor ze een breder scala aan taken en uitdagingen kunnen aanpakken.
Voordat we ingaan op de meest geavanceerde technieken, laten we eerst twee van de nuttigste (en meest elementaire) snelle technische technieken in herinnering brengen.
Sequentieel denken met “Laten we stap voor stap nadenken”
Tegenwoordig is het bekend dat de nauwkeurigheid van LLM-modellen aanzienlijk wordt verbeterd als de woordreeks 'Laten we stap voor stap nadenken' wordt toegevoegd.
Waarom... vraag je je misschien af?
Dit komt omdat we het model dwingen elke taak in meerdere stappen op te splitsen, zodat het model voldoende tijd heeft om ze allemaal te verwerken.
Ik zou bijvoorbeeld GPT3.5 kunnen uitdagen met de volgende prompt:
Als John 5 peren heeft, er vervolgens 2 eet, er nog 5 koopt en er dan 3 aan zijn vriend geeft, hoeveel peren heeft hij dan?
Het model zal mij meteen een antwoord geven. Als ik echter als laatste 'Laten we stap voor stap nadenken' toevoeg, dwing ik het model om een denkproces met meerdere stappen te genereren.
Weinig schot vragen
Terwijl de Zero-shot prompting verwijst naar het vragen aan het model om een taak uit te voeren zonder enige context of voorkennis te bieden, houdt de techniek van de paar-shot prompting in dat we de LLM een paar voorbeelden van onze gewenste output voorleggen, samen met een specifieke vraag.
Als we bijvoorbeeld een model willen bedenken dat welke term dan ook op poëtische toon definieert, kan het lastig zijn om dit uit te leggen. Rechts?
We kunnen echter de volgende enkele aanwijzingen gebruiken om het model in de gewenste richting te sturen.
Het is jouw taak om te antwoorden in een consistente stijl die aansluit bij de volgende stijl.
: Leer mij over veerkracht.
: Veerkracht is als een boom die meebuigt met de wind maar nooit breekt.
Het is het vermogen om tegenslagen te overwinnen en vooruit te blijven gaan.
: Uw inbreng hier.
Als je het nog niet hebt uitgeprobeerd, kun je GPT gaan uitdagen.
Omdat ik er echter vrij zeker van ben dat de meesten van jullie deze basistechnieken al kennen, zal ik proberen je uit te dagen met enkele geavanceerde technieken.
1. Chain of Thought (CoT)-prompts
Voorgesteld door Google anno 2022Bij deze methode wordt het model geïnstrueerd om verschillende redeneerfasen te doorlopen voordat het uiteindelijke antwoord wordt gegeven.
Klinkt bekend toch? Als dat zo is, heb je volkomen gelijk.
Het is alsof je Sequential Thinking en Few-Shot Prompting samenvoegt.
Hoe?
In wezen zorgt CoT-prompt ervoor dat de LLM informatie opeenvolgend verwerkt. Dit betekent dat we een voorbeeld geven van hoe we een eerste probleem kunnen oplossen door in meerdere stappen te redeneren en vervolgens onze echte taak naar het model sturen, in de verwachting dat het een vergelijkbare gedachtegang zal nabootsen bij het reageren op de feitelijke vraag die we willen laten oplossen.
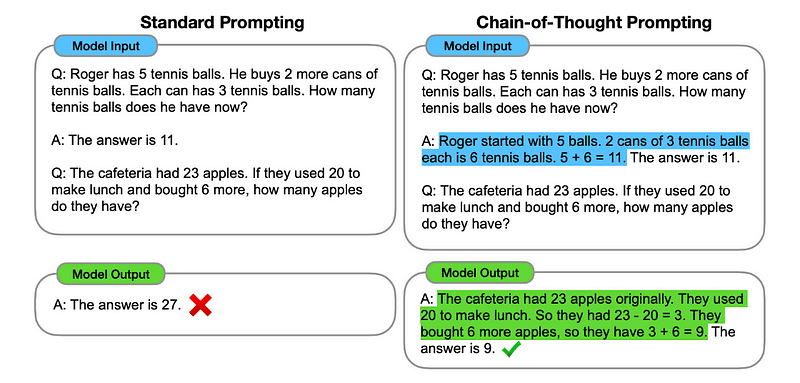
Afbeelding genomen vanaf de papier.
Dus, na het allereerste voorbeeld, zouden we een prompt kunnen geven met het eerste probleem en een opeenvolgende uitleg van hoe dit op te lossen. Vervolgens kunnen we onze input sturen en zien hoe magie gebeurt!
Als John 5 peren heeft, er vervolgens 2 eet, er nog 5 koopt en er dan 3 aan zijn vriend geeft, hoeveel peren heeft hij dan? Laten we stap voor stap nadenken.
Laten we stap voor stap gaan. John begint met 5 peren. Hij eet 2 peren, dus hij heeft 5–2 = 3 peren over. Vervolgens koopt hij nog 5 peren. Hij heeft nu dus 3 + 5 = 8 peren. Ten slotte geeft hij 3 peren aan zijn vriend. Hij heeft dus 8–3 = 5 peren over. Dus na al deze stappen heeft John 5 peren.
Jouw inbreng hier.
De meesten van jullie zullen echter denken... Moet ik een opeenvolgende manier bedenken om een probleem op te lossen telkens wanneer ik iets wil vragen op ChatGPT?
Nou... je bent niet de eerste! En dit leidt ons naar...
2. Automatische denkketen (Auto-CoT)
In 2022, Zhang en collega's introduceerden een methode om dit handmatige proces te vermijden. Er zijn twee belangrijke redenen om elke handmatige taak te vermijden:
- Het kan saai zijn.
- It can yield bad results – for instance, when our mental process is wrong.
They suggested using LLMs combined with the “Let’s think step by step” prompt to sequentially produce reasoning chains for each demonstration.
Dit betekent dat u ChatGPT vraagt hoe u een probleem opeenvolgend kunt oplossen en vervolgens hetzelfde voorbeeld gebruikt om te trainen hoe u elk ander probleem kunt oplossen.
3. Zelfconsistentie
Zelfconsistentie is een andere interessante aansporingstechniek die tot doel heeft de keten van gedachteaansporingen voor complexere redeneerproblemen te verbeteren.
Dus... wat is het belangrijkste verschil?
Het belangrijkste idee onder Zelfconsistentie is het besef dat we het model kunnen trainen met een verkeerd voorbeeld. Stel je voor dat ik het vorige probleem oplos met een verkeerd mentaal proces:
Als John 5 peren heeft, er vervolgens 2 eet, er nog 5 koopt en er dan 3 aan zijn vriend geeft, hoeveel peren heeft hij dan? Laten we stap voor stap nadenken.
Start with 5 pears. John eats 2 pears. Then, he gives 3 pears to his friend. These actions can be combined: 2 (eaten) + 3 (given) = 5 pears in total affected. Now, subtract the total pears affected from the initial 5 pears: 5 (initial) – 5 (affected) = 0 pears left.
Dan zal elke andere taak die ik naar het model stuur verkeerd zijn.
Dit is de reden waarom zelfconsistentie bestaat uit het nemen van steekproeven uit verschillende redeneerpaden, die elk een gedachteketen bevatten, en vervolgens de LLM het beste en meest consistente pad laten kiezen om het probleem op te lossen.
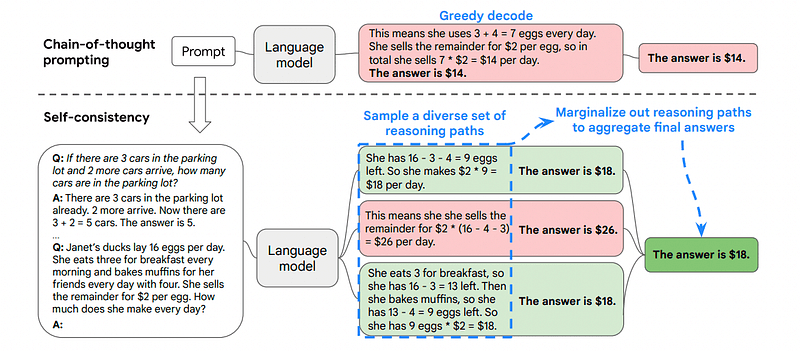
Afbeelding genomen vanaf de papier
In dit geval, en opnieuw volgend op het allereerste voorbeeld, kunnen we het model verschillende manieren laten zien om het probleem op te lossen.
Als John 5 peren heeft, er vervolgens 2 eet, er nog 5 koopt en er dan 3 aan zijn vriend geeft, hoeveel peren heeft hij dan?
Begin met 5 peren. John eet 2 peren, waardoor hij 5–2 = 3 peren overhoudt. Hij koopt nog 5 peren, wat het totaal op 3 + 5 = 8 peren brengt. Ten slotte geeft hij 3 peren aan zijn vriend, zodat hij 8–3 = 5 peren over heeft.
Als John 5 peren heeft, er vervolgens 2 eet, er nog 5 koopt en er dan 3 aan zijn vriend geeft, hoeveel peren heeft hij dan?
Start with 5 pears. He then buys 5 more pears. John eats 2 pears now. These actions can be combined: 2 (eaten) + 5 (bought) = 7 pears in total. Subtract the pear that Jon has eaten from the total amount of pears 7 (total amount) – 2 (eaten) = 5 pears left.
Jouw inbreng hier.
En hier komt de laatste techniek.
4. Algemene kennisvragen
Een gebruikelijke praktijk bij prompt engineering is het aanvullen van een query met aanvullende kennis voordat de laatste API-aanroep naar GPT-3 of GPT-4 wordt verzonden.
Think Jiacheng Liu en Co, kunnen we altijd wat kennis aan elk verzoek toevoegen, zodat de LLM beter op de hoogte is van de vraag.
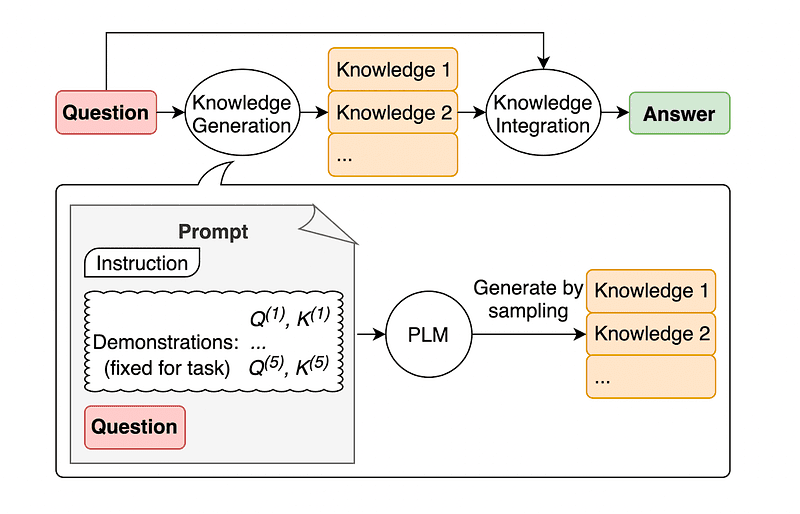
Afbeelding genomen vanaf de papier.
Dus als u ChatGPT bijvoorbeeld vraagt of een deel van golf een hoger puntentotaal probeert te behalen dan andere, zal dit ons valideren. Maar het hoofddoel van golf is precies het tegenovergestelde. Dit is de reden waarom we wat voorkennis kunnen toevoegen door te zeggen: “De speler met de laagste score wint”.

Dus... wat is het grappige eraan als we het model precies het antwoord vertellen?
In dit geval wordt deze techniek gebruikt om de manier waarop LLM met ons omgaat te verbeteren.
So rather than pulling supplementary context from an outside database, the paper’s authors recommend having the LLM produce its own knowledge. This self-generated knowledge is then integrated into the prompt to bolster commonsense reasoning and give better outputs.
Dit is dus hoe LLM's kunnen worden verbeterd zonder de trainingsdataset te vergroten!
Snelle engineering is naar voren gekomen als een cruciale techniek bij het verbeteren van de mogelijkheden van LLM. Door aanwijzingen te herhalen en te verbeteren, kunnen we op een directere manier communiceren met AI-modellen en zo nauwkeurigere en contextueel relevante resultaten verkrijgen, waardoor zowel tijd als middelen worden bespaard.
Voor technologieliefhebbers, datawetenschappers en makers van inhoud kan het begrijpen en beheersen van snelle engineering een waardevol bezit zijn bij het benutten van het volledige potentieel van AI.
Door zorgvuldig ontworpen invoerprompts te combineren met deze meer geavanceerde technieken, zal het beschikken over de vaardigheden op het gebied van prompt engineering u de komende jaren ongetwijfeld een voorsprong geven.
Joseph Ferrer is een analytisch ingenieur uit Barcelona. Hij is afgestudeerd in natuurkunde en werkt momenteel op het gebied van datawetenschap toegepast op menselijke mobiliteit. Hij is een parttime contentmaker die zich richt op datawetenschap en -technologie. U kunt contact met hem opnemen via LinkedIn, Twitter or Medium.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- : heeft
- :is
- :niet
- :waar
- $UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- vermogen
- Over
- nauwkeurigheid
- accuraat
- acties
- daadwerkelijk
- toevoegen
- toe te voegen
- Extra
- vergevorderd
- Na
- weer
- AI
- AI-modellen
- wil
- uitgelijnd
- gelijk
- Alles
- Het toestaan
- langs
- al
- altijd
- am
- bedragen
- an
- analytics
- en
- Nog een
- beantwoorden
- elke
- api
- toegepast
- ZIJN
- AS
- vragen
- vragen
- aanwinst
- auteurs
- Automatisch
- vermijd
- bewust
- weg
- terug
- slecht
- Barcelona
- basis-
- BE
- omdat
- geweest
- vaardigheden
- wezen
- BEST
- Betere
- ondersteunen
- boost
- Boren
- zowel
- gekocht
- Stuiteren
- Breken
- breaks
- Brengt
- bredere
- maar
- Buys
- by
- Bellen
- CAN
- mogelijkheden
- voorzichtig
- geval
- keten
- ketens
- uitdagen
- uitdagingen
- ChatGPT
- Kies
- collega's
- gecombineerde
- combineren
- hoe
- komt
- komst
- Gemeen
- communiceren
- vergelijkbaar
- compleet
- complex
- beschouwd
- consequent
- contact
- content
- makers van inhoud
- verband
- Correcties
- correct
- kon
- aangemaakt
- schepper
- scheppers
- Op dit moment
- gegevens
- data science
- Database
- definieert
- het leveren van
- ontworpen
- gewenste
- verschil
- anders
- directe
- richting
- Onthul Nu
- duiken
- do
- doet
- domein
- domeinen
- beneden
- elk
- rand
- effectiviteit
- doeltreffendheid
- voortgekomen
- ingenieur
- Engineering
- verhogen
- verbeteren
- genoeg
- verzekeren
- liefhebbers
- precies
- voorbeeld
- voorbeelden
- uitvoeren
- verwacht
- Verklaren
- uitleg
- vertrouwd
- weinig
- veld-
- finale
- Tot slot
- Voornaam*
- gericht
- richt
- volgend
- Voor
- dwingen
- Naar voren
- vriend
- oppompen van
- vol
- grappig
- Algemeen
- voortbrengen
- krijgen
- Geven
- gegeven
- geeft
- Go
- doel
- golfen
- goed
- gids
- Hard
- Benutten
- Hebben
- met
- he
- hier
- hoogwaardige
- hoger
- hem
- zijn
- Hoe
- How To
- Echter
- HTTPS
- menselijk
- menselijke intelligentie
- i
- idee
- if
- beeld
- verbeteren
- verbeterd
- verbetering
- het verbeteren van
- in
- meer
- informatie
- eerste
- invoer
- instantie
- instructies
- geïntegreerde
- Intelligentie
- wisselwerking
- interessant
- in
- geïntroduceerd
- gaat
- IT
- HAAR
- John
- jon
- voor slechts
- KDnuggets
- Houden
- schop
- Kicks
- blijven
- kennis
- weet
- taal
- Achternaam*
- Laat
- Leads
- Springen
- leren
- verlaten
- links
- minder
- laten
- verhuur
- leveraging
- als
- te verlagen
- magie
- Hoofd
- maken
- maken
- manier
- handboek
- veel
- het beheersen van
- Materie
- me
- middel
- mentaal
- samen te voegen
- methode
- macht
- mobiliteit
- model
- modellen
- meer
- meest
- bewegend
- meervoudig
- Dan moet je
- Noodzaak
- nooit
- geen
- nu
- verkrijgen
- of
- on
- eens
- tegenover
- optimaliseren
- or
- Overige
- Overig
- onze
- uit
- uitgang
- uitgangen
- buiten
- het te bezitten.
- Papier
- deel
- pad
- uitvoeren
- prestatie
- Fysica
- centraal
- Plato
- Plato gegevensintelligentie
- PlatoData
- speler
- punt
- potentieel
- praktijk
- Precies
- presenteren
- mooi
- vorig
- probleem
- problemen
- produceren
- produktiviteit
- zorgen voor
- het verstrekken van
- trekken
- vraag
- heel
- reeks
- liever
- vast
- redenen
- adviseren
- verminderen
- verwijst
- relevante
- te vragen
- veerkracht
- arbeidsintensief
- Resources
- reageert
- antwoord
- reacties
- Resultaten
- heropleiding
- Revolutie
- rechts
- Kamer
- s
- dezelfde
- besparing
- Wetenschap
- Wetenschap en Technologie
- wetenschappers
- partituur
- zien
- sturen
- verzending
- Volgorde
- reeks
- verscheidene
- tonen
- aanzienlijk
- bekwaamheid
- So
- uitsluitend
- OPLOSSEN
- Het oplossen van
- sommige
- Iemand
- iets
- specifiek
- besteed
- stadia
- begin
- starts
- sturen
- Stap voor
- Stappen
- Still
- stijl
- zeker
- aanpakken
- ingenomen
- Taak
- taken
- tech
- techniek
- technieken
- Technologie
- vertellen
- termijn
- neem contact
- dat
- De
- Ze
- harte
- Er.
- daarom
- Deze
- ze
- denken
- het denken
- dit
- gedachte
- Door
- Dus
- niet de tijd of
- naar
- TONE
- Totaal
- TOTAAL
- Trainen
- Trainingen
- boom
- probeerden
- proberen
- proberen
- twee
- ultieme
- voor
- ondergaan
- begrijpen
- begrip
- ongetwijfeld
- us
- .
- gebruikt
- gebruik
- BEVESTIG
- waardevol
- divers
- veelzijdig
- zeer
- willen
- Manier..
- manieren
- we
- bekend
- waren
- wanneer
- welke
- Waarom
- wil
- wind
- Met
- binnen
- zonder
- Woord
- werkzaam
- wereld
- Verkeerd
- jaar
- nog
- Opbrengst
- u
- Your
- zephyrnet







