
Een model binnen een model
In de onderzoeksgemeenschap op het gebied van machinaal leren zijn veel wetenschappers gaan geloven dat grote taalmodellen in-context leren kunnen uitvoeren vanwege de manier waarop ze zijn getraind, zegt Akyürek. GPT-3 heeft bijvoorbeeld honderden miljarden parameters en is getraind door enorme hoeveelheden tekst op internet te lezen, van Wikipedia-artikelen tot Reddit-berichten. Dus als iemand de modelvoorbeelden van een nieuwe taak laat zien, heeft hij of zij waarschijnlijk al iets soortgelijks gezien, omdat de trainingsdataset tekst van miljarden websites bevatte. Het herhaalt patronen die het tijdens de training heeft gezien, in plaats van nieuwe taken te leren uitvoeren. Akyürek veronderstelde dat leerlingen in de context niet alleen eerder geziene patronen matchen, maar in plaats daarvan daadwerkelijk nieuwe taken leren uitvoeren. Hij en anderen hadden geëxperimenteerd door deze modellen aanwijzingen te geven met behulp van synthetische gegevens, die ze nergens eerder hadden kunnen zien, en ontdekten dat de modellen nog steeds konden leren van slechts een paar voorbeelden. Akyürek en zijn collega's dachten dat deze neurale netwerkmodellen misschien kleinere machine-learning-modellen bevatten die de modellen kunnen trainen om een nieuwe taak te voltooien. “Dat zou bijna alle leerverschijnselen kunnen verklaren die we bij deze grote modellen hebben gezien”, zegt hij. Om deze hypothese te testen, gebruikten de onderzoekers een neuraal netwerkmodel, een transformator genaamd, dat dezelfde architectuur heeft als GPT-3, maar specifiek was getraind voor in-context leren. Door de architectuur van deze transformator te onderzoeken, bewezen ze theoretisch dat deze binnen zijn verborgen toestanden een lineair model kan schrijven. Een neuraal netwerk bestaat uit vele lagen van onderling verbonden knooppunten die gegevens verwerken. De verborgen toestanden zijn de lagen tussen de invoer- en uitvoerlagen. Uit hun wiskundige evaluaties blijkt dat dit lineaire model ergens in de vroegste lagen van de transformator is geschreven. De transformator kan vervolgens het lineaire model bijwerken door eenvoudige leeralgoritmen te implementeren. In wezen simuleert en traint het model een kleinere versie van zichzelf.Het onderzoeken van verborgen lagen
De onderzoekers onderzochten deze hypothese met behulp van indringende experimenten, waarbij ze in de verborgen lagen van de transformator keken om te proberen een bepaalde hoeveelheid terug te winnen. “In dit geval probeerden we de daadwerkelijke oplossing van het lineaire model te achterhalen en konden we aantonen dat de parameter in de verborgen toestanden is geschreven. Dit betekent dat het lineaire model ergens aanwezig is”, zegt hij. Voortbouwend op dit theoretische werk kunnen de onderzoekers mogelijk een transformator in staat stellen om in-context leren uit te voeren door slechts twee lagen aan het neurale netwerk toe te voegen. Er moeten nog veel technische details worden uitgewerkt voordat dat mogelijk is, waarschuwt Akyürek, maar het zou ingenieurs kunnen helpen modellen te maken die nieuwe taken kunnen voltooien zonder dat ze opnieuw hoeven te trainen met nieuwe gegevens. In de toekomst is Akyürek van plan om in-context leren te blijven verkennen met functies die complexer zijn dan de lineaire modellen die ze in dit werk hebben bestudeerd. Ze zouden deze experimenten ook kunnen toepassen op grote taalmodellen om te zien of hun gedrag ook wordt beschreven door eenvoudige leeralgoritmen. Daarnaast wil hij dieper ingaan op de soorten voortrainingsgegevens die in-context leren mogelijk kunnen maken. “Met dit werk kunnen mensen nu visualiseren hoe deze modellen van voorbeelden kunnen leren. Ik hoop dus dat het de opvattingen van sommige mensen over in-context leren verandert”, zegt Akyürek. “Deze modellen zijn niet zo dom als mensen denken. Ze onthouden deze taken niet alleen. Ze kunnen nieuwe taken leren, en wij hebben laten zien hoe dat kan.”- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.nanowerk.com/news2/robotics/newsid=62325.php
- 10
- 7
- 9
- a
- in staat
- Over
- bereiken
- werkelijk
- toevoeging
- Na
- alberta
- algoritme
- algoritmen
- Alles
- al
- en
- overal
- Solliciteer
- architectuur
- rond
- artikelen
- kunstmatig
- kunstmatige intelligentie
- Assistent
- auteur
- auteurs
- omdat
- vaardigheden
- achter
- geloofd wie en wat je bent
- Betere
- tussen
- miljarden
- Beetje
- Hersenen
- Gebouw
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- in staat
- geval
- zeker
- Wijzigingen
- code
- collega's
- verzamelen
- hoe
- gemeenschap
- compleet
- complex
- samengesteld
- computer
- Computer Science
- computergebruik
- Conferentie
- consortium
- voortzetten
- kon
- en je merk te creëren
- LCS
- nieuwsgierig
- gegevens
- Datum
- diepere
- afdeling
- beschreven
- Niettegenstaande
- gegevens
- DIG
- Director
- Dont
- Deur
- gedurende
- Elektrotechniek
- in staat stellen
- Engineering
- Ingenieurs
- essentie
- evaluaties
- voorbeeld
- voorbeelden
- opwindend
- Verklaren
- exploratie
- Nagegaan
- Verkennen
- weinig
- vast
- Naar voren
- gevonden
- oppompen van
- functies
- voortbrengen
- Geven
- Vrijgevigheid
- Kopen Google Reviews
- afstuderen
- hulp
- verborgen
- hoop
- Hoe
- HTTPS
- reusachtig
- Honderden
- uitvoeren
- uitvoering
- belangrijk
- in
- inclusief
- informatie
- invoer
- instantie
- verkrijgen in plaats daarvan
- Intelligentie
- met elkaar verbonden
- Internationale
- Internet
- onderzoeken
- IT
- zelf
- aansluiting
- bekend
- laboratorium
- taal
- Groot
- groter
- Legkippen
- leiden
- LEARN
- leren
- Waarschijnlijk
- keek
- veel
- massief
- matching
- wiskundig
- middel
- lid
- MIT
- model
- modellen
- meer
- bewegend
- Mysterie
- Noodzaak
- negatief
- netwerk
- netwerken
- Neural
- neuraal netwerk
- neurale netwerken
- New
- volgende
- knooppunten
- opent
- Overig
- Papier
- parameter
- parameters
- patronen
- Mensen
- mensen
- uitvoeren
- misschien
- een fenomeen
- plannen
- Plato
- Plato gegevensintelligentie
- PlatoData
- Poëzie
- positief
- mogelijk
- Berichten
- voorspellen
- gepresenteerd
- mooi
- die eerder
- Principal
- processen
- Hoogleraar
- Programming
- bewezen
- hoeveelheid
- lezing
- Herstellen
- blijven
- onderzoek
- onderzoek Gemeenschap
- onderzoekers
- Resultaten
- heropleiding
- dezelfde
- zegt
- Wetenschap
- Wetenschapper
- wetenschappers
- te zien
- lijkt
- senior
- zin
- sentiment
- verscheidene
- tonen
- getoond
- Shows
- gelijk
- Eenvoudig
- Klein
- kleinere
- So
- oplossing
- Het oplossen van
- sommige
- Iemand
- iets
- ergens
- specifiek
- stanford
- Stanford University
- Staten
- statistiek
- Stap voor
- Still
- Student
- bestudeerd
- synthetisch
- synthetische gegevens
- Nemen
- Taak
- taken
- Technisch
- proef
- De
- hun
- theoretisch
- gedachte
- naar
- in de richting van
- Trainen
- getraind
- Trainingen
- treinen
- types
- typisch
- begrip
- universiteit-
- bijwerken
- bijgewerkt
- updates
- bijwerken
- versie
- .
- websites
- Wat
- of
- welke
- Wikipedia
- wil
- binnen
- zonder
- Mijn werk
- uitwerken
- zou
- schrijven
- geschreven
- X
- zephyrnet
Meer van Nanowerk
Superefficiënte door laserlicht geïnduceerde detectie van van kankercellen afkomstige nanodeeltjes
Bronknooppunt: 2919767
Tijdstempel: Oktober 6, 2023
Een goedkoop nanomateriaal gebruiken om koolstofdioxide uit industriële emissies te verwijderen
Bronknooppunt: 2753630
Tijdstempel: Juli 6, 2023

'Slimme' verbanden bewaken wonden en zorgen voor een gerichte behandeling
Bronknooppunt: 2538905
Tijdstempel: 24-2023-XNUMX
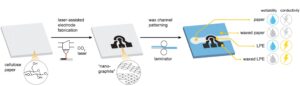
Door laser geïnduceerde grafenisatietechniek bevordert elektrofluïdische paden in microfluïdische op papier gebaseerde apparaten
Bronknooppunt: 2724415
Tijdstempel: Juni 15, 2023

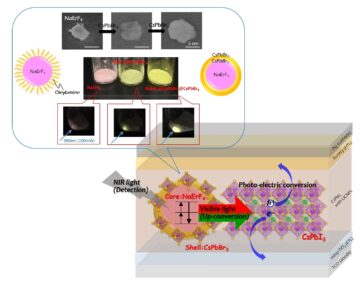
Nieuwe detectiemethode voor bijna-infraroodlicht met behulp van upconversion nanomaterialen
Bronknooppunt: 1790812
Tijdstempel: December 23, 2022
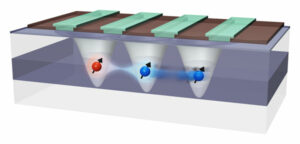
Het verbinden van verafgelegen siliciumqubits voor het opschalen van kwantumcomputers
Bronknooppunt: 2559199
Tijdstempel: 31-2023-XNUMX
Observatie van niet-lineaire disclinatietoestanden
Bronknooppunt: 2858168
Tijdstempel: September 1, 2023
Wiebelige gelmat traint spiercellen om samen te werken
Bronknooppunt: 2946503
Tijdstempel: Oktober 20, 2023
Nanodeeltjes maken het gemakkelijker om licht om te zetten in gesolvateerde elektronen
Bronknooppunt: 1905538
Tijdstempel: Jan 17, 2023

Metaalminnende microben zouden de chemische verwerking van zeldzame aardmetalen kunnen vervangen
Bronknooppunt: 2914288
Tijdstempel: Oktober 2, 2023

Intensieve lasers schijnen nieuw licht op de elektronendynamica van vloeistoffen
Bronknooppunt: 2911792
Tijdstempel: September 28, 2023