Amazon SageMaker Studio biedt een volledig beheerde oplossing voor datawetenschappers om interactief machine learning (ML)-modellen te bouwen, trainen en implementeren. Amazon SageMaker-notebooktaken stellen datawetenschappers in staat hun notebooks op aanvraag of volgens een schema met een paar klikken in SageMaker Studio te gebruiken. Met deze lancering kunt u notebooks programmatisch als taken uitvoeren met behulp van API's van Amazon SageMaker-pijpleidingen, de ML-workfloworkestratiefunctie van Amazon Sage Maker. Bovendien kunt u met behulp van deze API's een ML-workflow met meerdere stappen maken met meerdere afhankelijke notebooks.
SageMaker Pipelines is een native workflow-orkestratietool voor het bouwen van ML-pijplijnen die profiteren van directe SageMaker-integratie. Elke SageMaker-pijplijn bestaat uit stappen, die overeenkomen met individuele taken zoals verwerking, training of gegevensverwerking met behulp van Amazon EMR. SageMaker-notebooktaken zijn nu beschikbaar als ingebouwd staptype in SageMaker-pijplijnen. U kunt deze notebooktaakstap gebruiken om notebooks eenvoudig uit te voeren als taken met slechts een paar regels code met behulp van de Amazon SageMaker Python-SDK. Bovendien kunt u meerdere afhankelijke notitieboekjes samenvoegen om een workflow te creëren in de vorm van Directed Acyclic Graphs (DAG's). Vervolgens kunt u deze notebooktaken of DAG's uitvoeren en ze beheren en visualiseren met SageMaker Studio.
Datawetenschappers gebruiken momenteel SageMaker Studio om hun Jupyter-notebooks interactief te ontwikkelen en gebruiken vervolgens SageMaker-notebooktaken om deze notebooks als geplande taken uit te voeren. Deze taken kunnen onmiddellijk of volgens een terugkerend tijdschema worden uitgevoerd, zonder dat datawerkers de code als Python-modules hoeven te herstructureren. Enkele veel voorkomende gebruiksscenario's om dit te doen zijn onder meer:
- Running long running-notebooks op de achtergrond
- Regelmatig lopende modelinferentie om rapporten te genereren
- Opschalen van het voorbereiden van kleine voorbeelddatasets tot het werken met big data op petabyteschaal
- Modellen opnieuw trainen en inzetten op een bepaalde cadans
- Taken plannen voor modelkwaliteit of monitoring van gegevensdrift
- Het verkennen van de parameterruimte voor betere modellen
Hoewel deze functionaliteit het voor datawerkers eenvoudig maakt om zelfstandige notebooks te automatiseren, bestaan ML-workflows vaak uit verschillende notebooks, die elk een specifieke taak met complexe afhankelijkheden uitvoeren. Een notebook die de drift van modelgegevens controleert, moet bijvoorbeeld een pre-stap hebben die het extraheren, transformeren en laden (ETL) en verwerken van nieuwe gegevens mogelijk maakt, en een post-stap van modelvernieuwing en training voor het geval er een significante drift wordt opgemerkt. . Bovendien willen datawetenschappers deze hele workflow misschien volgens een terugkerend schema activeren om het model bij te werken op basis van nieuwe gegevens. Om u in staat te stellen uw notebooks eenvoudig te automatiseren en zulke complexe workflows te creëren, zijn SageMaker-notebooktaken nu beschikbaar als stap in SageMaker Pipelines. In dit bericht laten we zien hoe u de volgende gebruiksscenario's kunt oplossen met een paar regels code:
- Voer een zelfstandig notebook programmatisch uit, onmiddellijk of volgens een terugkerend schema
- Creëer meerstapsworkflows van notebooks als DAG's voor continue integratie en continue levering (CI/CD) doeleinden die kunnen worden beheerd via de SageMaker Studio UI
Overzicht oplossingen
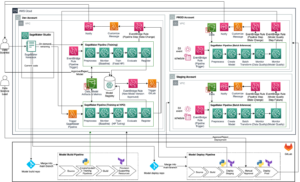
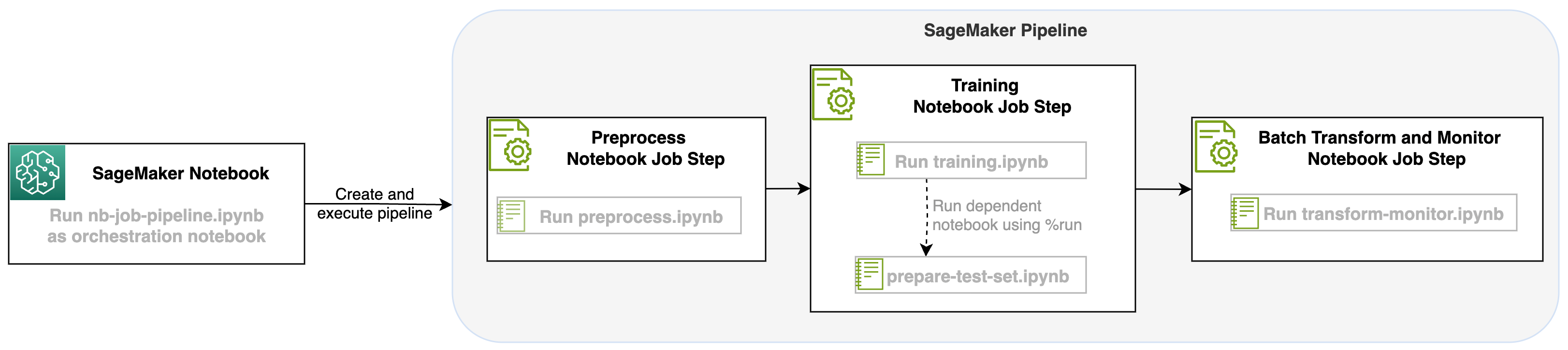
Het volgende diagram illustreert onze oplossingsarchitectuur. U kunt de SageMaker Python SDK gebruiken om één notebooktaak of een werkstroom uit te voeren. Met deze functie wordt een SageMaker-trainingstaak gemaakt om de notebook uit te voeren.
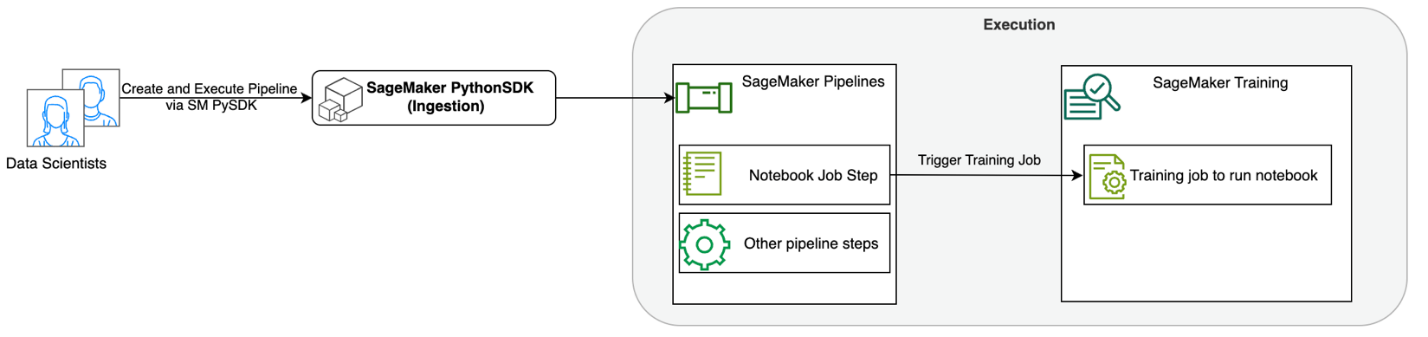
In de volgende secties doorlopen we een voorbeeld van een ML-gebruiksscenario en laten we de stappen zien om een workflow van notebooktaken te creëren, parameters door te geven tussen verschillende notebookstappen, uw workflow te plannen en deze te monitoren via SageMaker Studio.
Voor ons ML-probleem in dit voorbeeld bouwen we een sentimentanalysemodel, een soort tekstclassificatietaak. De meest voorkomende toepassingen van sentimentanalyse zijn onder meer het monitoren van sociale media, het beheer van klantenondersteuning en het analyseren van klantfeedback. De gegevensset die in dit voorbeeld wordt gebruikt, is de Stanford Sentiment Treebank (SST2)-gegevensset, die bestaat uit filmrecensies en een geheel getal (0 of 1) dat het positieve of negatieve sentiment van de recensie aangeeft.
Het volgende is een voorbeeld van een data.csv bestand dat overeenkomt met de SST2-gegevensset en toont waarden in de eerste twee kolommen. Houd er rekening mee dat het bestand geen header mag hebben.
| Column 1 | Column 2 |
| 0 | verberg nieuwe secreties van de ouderunits |
| 0 | bevat geen humor, alleen moeizame grappen |
| 1 | die van zijn karakters houdt en iets heel moois communiceert over de menselijke natuur |
| 0 | blijft volkomen tevreden om overal hetzelfde te blijven |
| 0 | op de ergste wraak-van-de-nerds-clichés die de filmmakers konden uitbaggeren |
| 0 | dat is veel te tragisch om zo'n oppervlakkige behandeling te verdienen |
| 1 | laat zien dat de regisseur van Hollywood-kaskrakers als patriotgames toch een kleine, persoonlijke film met een emotionele klap kan maken. |
In dit ML-voorbeeld moeten we verschillende taken uitvoeren:
- Voer functie-engineering uit om deze dataset voor te bereiden in een formaat dat ons model kan begrijpen.
- Voer na de functie-engineering een trainingsstap uit waarbij gebruik wordt gemaakt van Transformers.
- Stel batchgewijze inferentie in met het verfijnde model om het sentiment voor nieuwe recensies die binnenkomen te helpen voorspellen.
- Stel een stap voor het monitoren van gegevens in, zodat we onze nieuwe gegevens regelmatig kunnen controleren op eventuele afwijkingen in de kwaliteit waarvoor we mogelijk de modelgewichten opnieuw moeten trainen.
Met deze lancering van een notebooktaak als stap in de SageMaker-pijplijnen kunnen we deze workflow, die uit drie afzonderlijke stappen bestaat, orkestreren. Elke stap van de workflow wordt ontwikkeld in een ander notebook, die vervolgens wordt omgezet in onafhankelijke stappen voor notebooktaken en als een pijplijn met elkaar wordt verbonden:
- Voorverwerking – Download de openbare SST2-dataset van Amazon eenvoudige opslagservice (Amazon S3) en maak in stap 2 een CSV-bestand zodat de notebook kan worden uitgevoerd. De SST2-gegevensset is een tekstclassificatiegegevensset met twee labels (0 en 1) en een kolom met tekst om te categoriseren.
- Trainingen – Neem het gevormde CSV-bestand en voer de verfijning uit met BERT voor tekstclassificatie met behulp van Transformers-bibliotheken. We gebruiken een notitieboekje voor het voorbereiden van testgegevens als onderdeel van deze stap, wat afhankelijk is van de stap voor het afstemmen en batch-inferentie. Wanneer de fijnafstelling is voltooid, wordt deze notebook uitgevoerd met behulp van run magic en wordt een testgegevensset voorbereid voor voorbeeldafleiding met het verfijnde model.
- Transformeren en monitoren – Voer batch-inferentie uit en stel de gegevenskwaliteit in met modelmonitoring om een suggestie voor een basisgegevensset te krijgen.
Voer de notitieboekjes uit
De voorbeeldcode voor deze oplossing is beschikbaar op GitHub.
Het maken van een SageMaker-notebooktaakstap is vergelijkbaar met het maken van andere SageMaker Pipeline-stappen. In dit notebookvoorbeeld gebruiken we de SageMaker Python SDK om de workflow te orkestreren. Om een notebookstap in SageMaker Pipelines te maken, kunt u de volgende parameters definiëren:
- Invoer notitieboekje – De naam van het notitieblok dat door deze notitieboekstap wordt georkestreerd. Hier kunt u het lokale pad naar het invoernotebook doorgeven. Als er op dit notebook andere notebooks worden gebruikt, kunt u deze eventueel doorgeven in de
AdditionalDependenciesparameter voor de notebooktaakstap. - Afbeeldings-URI – De Docker-afbeelding achter de notebooktaakstap. Dit kunnen de vooraf gedefinieerde afbeeldingen zijn die SageMaker al biedt, of een aangepaste afbeelding die u hebt gedefinieerd en waarnaar u hebt gepusht Amazon Elastic Container-register (Amazone ECR). Raadpleeg het gedeelte Overwegingen aan het einde van dit bericht voor ondersteunde afbeeldingen.
- Kernelnaam – De naam van de kernel die u gebruikt in SageMaker Studio. Deze kernelspecificatie is geregistreerd in de afbeelding die u hebt opgegeven.
- Instantietype (optioneel) - The Amazon Elastic Compute-cloud (Amazon EC2) exemplaartype achter de notebooktaak die u hebt gedefinieerd en die u gaat uitvoeren.
- Parameters (optioneel) – Parameters die u kunt doorgeven en die toegankelijk zijn voor uw notebook. Deze kunnen worden gedefinieerd in sleutel-waardeparen. Bovendien kunnen deze parameters worden gewijzigd tussen verschillende notebooktaakuitvoeringen of pijplijnuitvoeringen.
Ons voorbeeld heeft in totaal vijf notitieboekjes:
- nb-job-pipeline.ipynb – Dit is ons hoofdnotitieboekje waarin we onze pijplijn en workflow definiëren.
- preprocess.ipynb – Dit notitieboekje is de eerste stap in onze workflow en bevat de code die de openbare AWS-dataset ophaalt en er een CSV-bestand van maakt.
- training.ipynb – Dit notitieboekje is de tweede stap in onze workflow en bevat code om de CSV uit de vorige stap te gebruiken en lokale training en afstemming uit te voeren. Deze stap is ook afhankelijk van de
prepare-test-set.ipynbnotebook om een testgegevensset op te halen voor voorbeeldconclusie met het verfijnde model. - prepare-test-set.ipynb – Met dit notebook wordt een testgegevensset gemaakt die ons trainingsnotebook zal gebruiken in de tweede pijplijnstap en zal gebruiken voor voorbeeldafleiding met het verfijnde model.
- transform-monitor.ipynb – Deze notebook is de derde stap in onze workflow en neemt het basis-BERT-model en voert een batchtransformatietaak van SageMaker uit, terwijl ook de gegevenskwaliteit wordt ingesteld met modelmonitoring.
Vervolgens lopen we door het hoofdnotitieboekje nb-job-pipeline.ipynb, dat alle subnotebooks in één pijplijn combineert en de end-to-end workflow uitvoert. Houd er rekening mee dat, hoewel het volgende voorbeeld de notebook slechts één keer uitvoert, u de pijplijn ook kunt plannen om de notebook herhaaldelijk uit te voeren. Verwijzen naar SageMaker-documentatie voor gedetailleerde instructies.
Voor onze eerste stap in de notebooktaak geven we een parameter door met een standaard S3-bucket. We kunnen deze bucket gebruiken om alle artefacten te dumpen die we beschikbaar willen hebben voor onze andere pijplijnstappen. Voor het eerste notitieboekje (preprocess.ipynb), halen we de openbare SST2-treindataset van AWS tevoorschijn en maken er een CSV-trainingsbestand van dat we naar deze S3-bucket pushen. Zie de volgende code:
We kunnen dit notitieboekje vervolgens omzetten in een NotebookJobStep met de volgende code in ons hoofdnotebook:
Nu we een voorbeeld-CSV-bestand hebben, kunnen we beginnen met het trainen van ons model in ons trainingsnotebook. Ons trainingsnotebook neemt dezelfde parameter over met de S3-bucket en haalt de trainingsgegevensset vanaf die locatie op. Vervolgens voeren we de verfijning uit door het Transformers trainer-object te gebruiken met het volgende codefragment:
Na het verfijnen willen we een batch-gevolgtrekking uitvoeren om te zien hoe het model presteert. Dit gebeurt met behulp van een apart notitieboekje (prepare-test-set.ipynb) in hetzelfde lokale pad dat een testgegevensset maakt om gevolgtrekkingen uit te voeren over het gebruik van ons getrainde model. We kunnen het extra notitieboekje in ons trainingsnotitieboekje gebruiken met de volgende magische cel:
We definiëren deze extra notebookafhankelijkheid in de AdditionalDependencies parameter in onze tweede notebook-taakstap:
We moeten ook opgeven dat de taakstap voor het trainen van notebooks (stap 2) afhankelijk is van de taakstap voor het voorbewerken van notebooks (stap 1) met behulp van de add_depends_on API-aanroep als volgt:
Onze laatste stap is dat het BERT-model een SageMaker Batch Transform uitvoert, terwijl ook Data Capture en Quality worden ingesteld via SageMaker Model Monitor. Merk op dat dit anders is dan het gebruik van de ingebouwde Transformeren or vangen stappen via pijpleidingen. Onze notebook voor deze stap voert dezelfde API's uit, maar wordt bijgehouden als een Notebook-taakstap. Deze stap is afhankelijk van de trainingstaakstap die we eerder hebben gedefinieerd, dus we leggen die ook vast met de vlag depend_on.
Nadat de verschillende stappen van onze workflow zijn gedefinieerd, kunnen we de end-to-end pipeline creëren en uitvoeren:
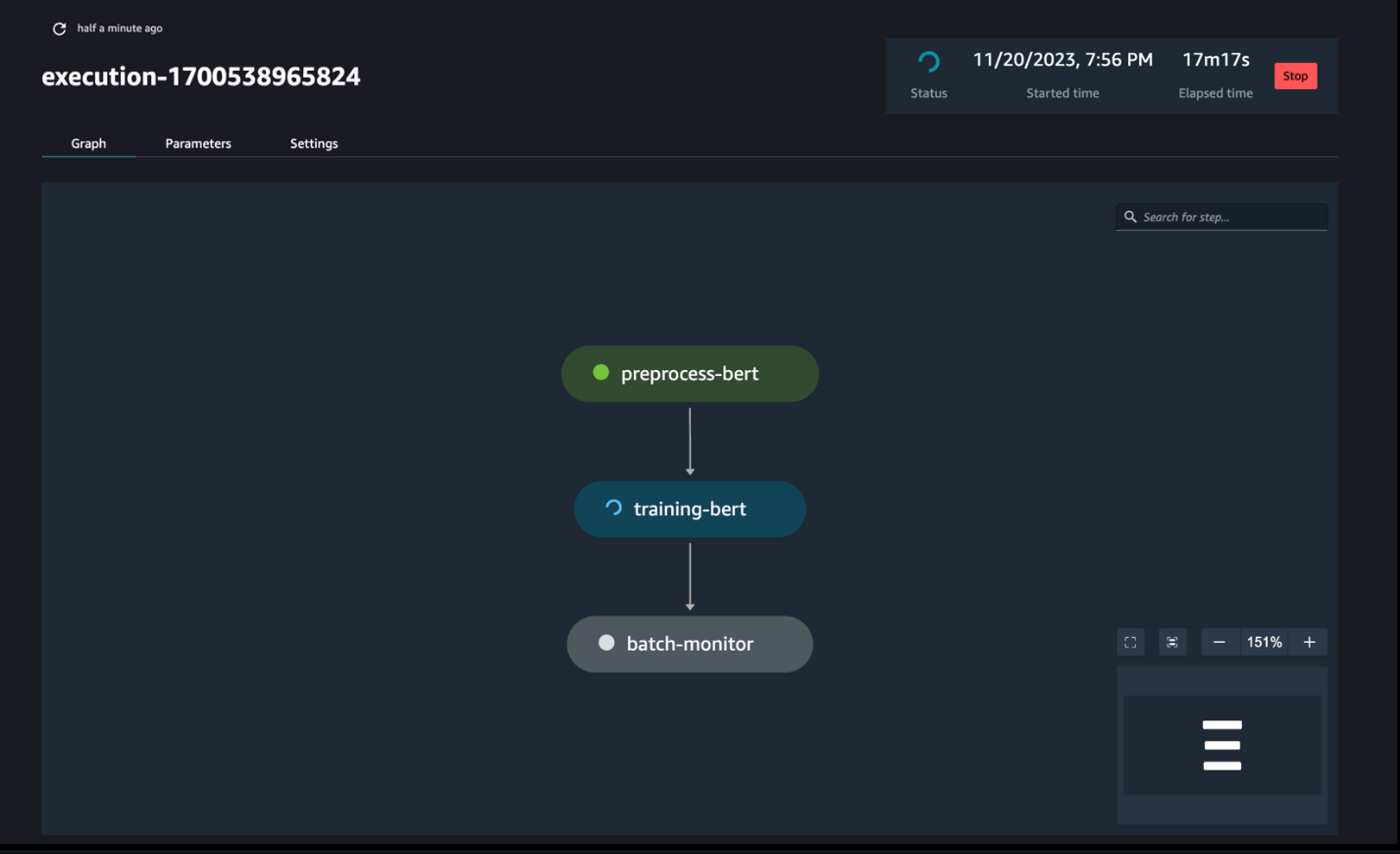
Bewaak de pijplijntrajecten
U kunt de stapuitvoeringen van de notebook volgen en bewaken via de SageMaker Pipelines DAG, zoals te zien in de volgende schermafbeelding.
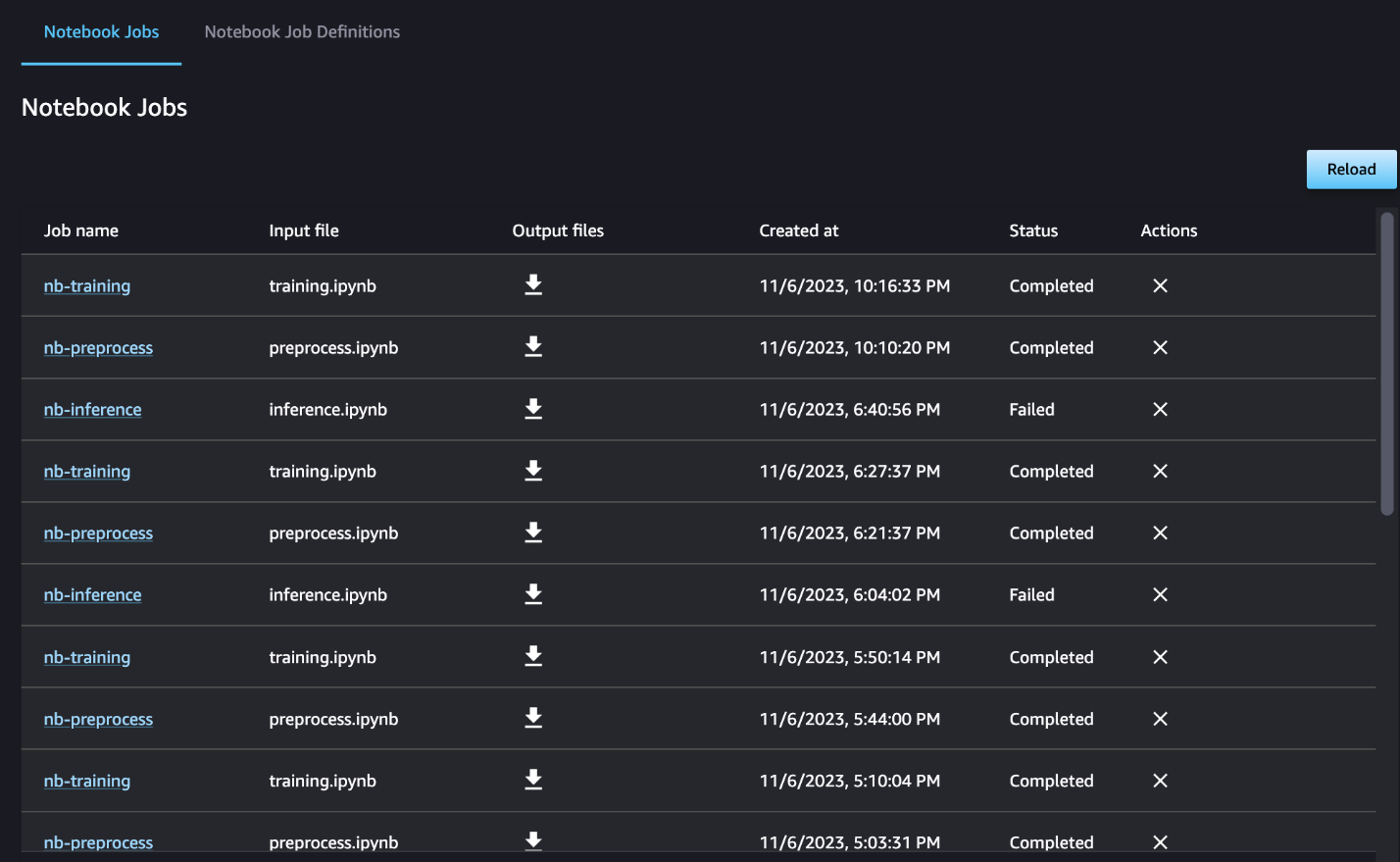
U kunt optioneel ook de individuele notebookruns monitoren op het notebooktaakdashboard en schakelen tussen de uitvoerbestanden die zijn gemaakt via de gebruikersinterface van SageMaker Studio. Wanneer u deze functionaliteit buiten SageMaker Studio gebruikt, kunt u de gebruikers definiëren die de uitvoeringsstatus op het notebooktaakdashboard kunnen volgen met behulp van tags. Zie voor meer informatie over tags die u moet opnemen Bekijk uw notebooktaken en download uitvoer in het Studio UI-dashboard.
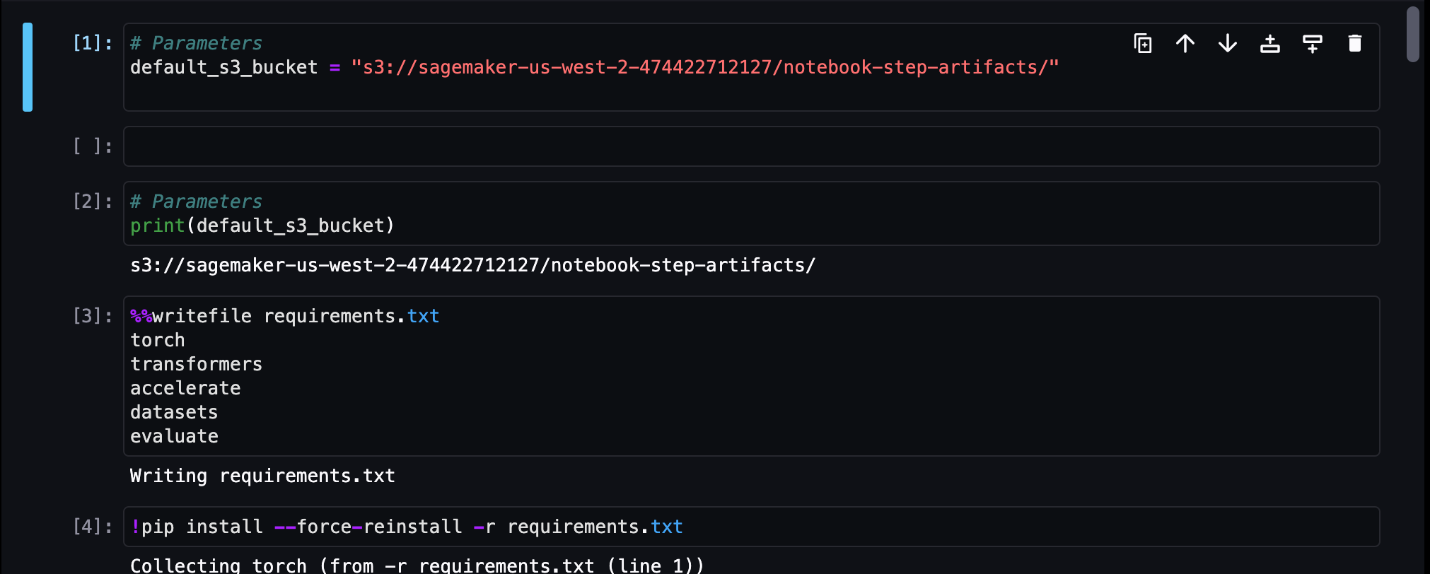
Voor dit voorbeeld voeren we de resulterende notebooktaken uit naar een map genaamd outputs in uw lokale pad met uw pijplijnuitvoeringscode. Zoals u in de volgende schermafbeelding kunt zien, ziet u hier de uitvoer van uw invoernotebook en ook alle parameters die u voor die stap hebt gedefinieerd.
Opruimen
Als u ons voorbeeld hebt gevolgd, zorg er dan voor dat u de gemaakte pijplijn, notebooktaken en de s3-gegevens verwijdert die door de voorbeeldnotebooks zijn gedownload.
Overwegingen
Hier volgen enkele belangrijke overwegingen voor deze functie:
- SDK-beperkingen – De notebooktaakstap kan alleen worden gemaakt via de SageMaker Python SDK.
- Beeldbeperkingen –De notebooktaakstap ondersteunt de volgende afbeeldingen:
Conclusie
Met deze lancering kunnen datawerkers hun notebooks nu programmatisch uitvoeren met een paar regels code met behulp van de SageMaker Python-SDK. Bovendien kunt u met uw notebooks complexe, uit meerdere stappen bestaande workflows creëren, waardoor de tijd die nodig is om van een notebook naar een CI/CD-pijplijn te gaan, aanzienlijk wordt verkort. Nadat u de pijplijn hebt gemaakt, kunt u SageMaker Studio gebruiken om DAG's voor uw pijplijnen te bekijken en uit te voeren en de runs te beheren en te vergelijken. Of u nu end-to-end ML-workflows of een deel ervan plant, we raden u aan het te proberen op notebooks gebaseerde workflows.
Over de auteurs
 Anchit Gupta is een Senior Product Manager voor Amazon SageMaker Studio. Ze richt zich op het mogelijk maken van interactieve data science en data engineering workflows vanuit de SageMaker Studio IDE. In haar vrije tijd houdt ze van koken, bord-/kaartspellen spelen en lezen.
Anchit Gupta is een Senior Product Manager voor Amazon SageMaker Studio. Ze richt zich op het mogelijk maken van interactieve data science en data engineering workflows vanuit de SageMaker Studio IDE. In haar vrije tijd houdt ze van koken, bord-/kaartspellen spelen en lezen.
 Ram Vegiraju is een ML Architect bij het SageMaker Service-team. Hij richt zich op het helpen van klanten bij het bouwen en optimaliseren van hun AI/ML-oplossingen op Amazon SageMaker. In zijn vrije tijd houdt hij van reizen en schrijven.
Ram Vegiraju is een ML Architect bij het SageMaker Service-team. Hij richt zich op het helpen van klanten bij het bouwen en optimaliseren van hun AI/ML-oplossingen op Amazon SageMaker. In zijn vrije tijd houdt hij van reizen en schrijven.
 Eduard Zon is een Senior SDE die werkt voor SageMaker Studio bij Amazon Web Services. Hij richt zich op het bouwen van een interactieve ML-oplossing en het vereenvoudigen van de klantervaring om SageMaker Studio te integreren met populaire technologieën in data-engineering en het ML-ecosysteem. In zijn vrije tijd is Edward een grote fan van kamperen, wandelen en vissen en brengt hij graag tijd door met zijn gezin.
Eduard Zon is een Senior SDE die werkt voor SageMaker Studio bij Amazon Web Services. Hij richt zich op het bouwen van een interactieve ML-oplossing en het vereenvoudigen van de klantervaring om SageMaker Studio te integreren met populaire technologieën in data-engineering en het ML-ecosysteem. In zijn vrije tijd is Edward een grote fan van kamperen, wandelen en vissen en brengt hij graag tijd door met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- : heeft
- :is
- :waar
- $UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Over
- beschikbaar
- acyclische
- Extra
- Daarnaast
- Voordeel
- Na
- AI / ML
- Alles
- toestaat
- langs
- al
- ook
- Hoewel
- Amazone
- Amazon EC2
- Amazon Sage Maker
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analyse
- het analyseren van
- en
- elke
- api
- APIs
- toepassingen
- architectuur
- ZIJN
- AS
- At
- automatiseren
- Beschikbaar
- AWS
- baseren
- gebaseerde
- Baseline
- BE
- prachtige
- geweest
- achter
- wezen
- Betere
- tussen
- Groot
- bouw
- Gebouw
- ingebouwd
- maar
- by
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- camping
- CAN
- vangen
- geval
- gevallen
- cel
- tekens
- classificatie
- code
- Kolom
- columns
- combines
- hoe
- Gemeen
- vergelijken
- compleet
- complex
- samengesteld
- bestaat uit
- Berekenen
- Gedrag
- gekoppeld blijven
- overwegingen
- bestaat uit
- Containers
- bevat
- doorlopend
- converteren
- geconverteerd
- koken
- Overeenkomend
- kon
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- Op dit moment
- gewoonte
- klant
- klantervaring
- Klantenservice
- Klanten
- DAG
- dashboards
- gegevens
- gegevensbewaking
- Data voorbereiding
- gegevensverwerking
- data kwaliteit
- data science
- datasets
- Standaard
- bepalen
- gedefinieerd
- levering
- Vraag
- afhankelijkheden
- Afhankelijkheid
- afhankelijk
- afhankelijk
- implementeren
- het inzetten
- gedetailleerd
- gegevens
- ontwikkelen
- ontwikkelde
- anders
- directe
- gerichte
- Director
- onderscheiden
- havenarbeider
- doen
- gedaan
- beneden
- Download
- storten
- elk
- gemakkelijk
- ecosysteem
- Edward
- in staat stellen
- waardoor
- aanmoedigen
- einde
- eind tot eind
- Engineering
- Geheel
- tijdperk
- Ether (ETH)
- voorbeeld
- uitvoeren
- uitvoering
- ervaring
- extra
- extract
- familie
- ventilator
- ver
- Kenmerk
- feedback
- weinig
- Dien in
- Bestanden
- Film
- filmmakers
- Voornaam*
- Vissen
- vijf
- gericht
- richt
- gevolgd
- volgend
- volgt
- Voor
- formulier
- formaat
- oppompen van
- geheel
- functionaliteit
- Bovendien
- Spellen
- voortbrengen
- grafieken
- Hebben
- he
- hulp
- het helpen van
- haar
- hier
- wandelen
- zijn
- Hollywood
- Hoe
- HTML
- http
- HTTPS
- menselijk
- if
- illustreert
- beeld
- afbeeldingen
- per direct
- importeren
- belangrijk
- in
- omvatten
- onafhankelijk
- geeft aan
- individueel
- invoer
- instantie
- instructies
- integreren
- integratie
- interactieve
- in
- IT
- HAAR
- Jobomschrijving:
- Vacatures
- jpg
- voor slechts
- label
- labels
- Achternaam*
- lancering
- leren
- bibliotheken
- Lijn
- lijnen
- laden
- lokaal
- plaats
- lang
- houdt
- machine
- machine learning
- magie
- Hoofd
- MERKEN
- beheer
- beheerd
- management
- manager
- Media
- Verdienste
- macht
- ML
- model
- modellen
- gewijzigd
- Modules
- monitor
- Grensverkeer
- monitors
- meer
- meest
- beweging
- filmpje
- meervoudig
- Dan moet je
- naam
- inheemse
- Noodzaak
- nodig
- negatief
- New
- geen
- nota
- notitieboekje
- laptops
- nu
- object
- of
- vaak
- on
- EEN
- Slechts
- Optimaliseer
- or
- orkestratie
- Overige
- onze
- uit
- uitgang
- uitgangen
- buiten
- paren
- parameter
- parameters
- deel
- passeren
- Voorbijgaand
- pad
- uitvoeren
- uitvoerend
- persoonlijk
- pijpleiding
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- Populair
- positief
- Post
- voorspellen
- voorbereiding
- Voorbereiden
- Bereidt zich voor
- voorbereiding
- vorig
- die eerder
- probleem
- verwerking
- Product
- product manager
- zorgen voor
- mits
- biedt
- publiek
- Truien
- doeleinden
- Duwen
- geduwd
- Python
- kwaliteit
- sneller
- R
- liever
- Lees
- lezing
- terugkerend
- vermindering
- Refactoren
- verwijzen
- geregistreerd
- regelmatig
- blijven
- HERHAALDELIJK
- vereisen
- verkregen
- beoordelen
- Recensies
- lopen
- lopend
- loopt
- sagemaker
- SageMaker-pijpleidingen
- dezelfde
- tevreden
- rooster
- gepland
- Geplande banen
- scheduling
- Wetenschap
- wetenschappers
- sdk
- Tweede
- sectie
- secties
- zien
- gezien
- senior
- sentiment
- apart
- service
- Diensten
- Sessie
- reeks
- het instellen van
- verscheidene
- gevormd
- ze
- moet
- tonen
- showcase
- getoond
- Shows
- aanzienlijke
- aanzienlijk
- gelijk
- Eenvoudig
- vereenvoudigen
- single
- Klein
- kleinere
- snipper
- So
- Social
- social media
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- iets
- Tussenruimte
- specifiek
- Uitgaven
- standalone
- stanford
- begin
- Status
- Stap voor
- Stappen
- Still
- mediaopslag
- eenvoudig
- studio
- dergelijk
- Zon
- ondersteuning
- ondersteunde
- steunen
- zeker
- Nemen
- neemt
- Taak
- taken
- team
- Technologies
- proef
- tekst
- Tekstclassificatie
- dat
- De
- hun
- Ze
- harte
- Deze
- Derde
- dit
- die
- drie
- Door
- niet de tijd of
- naar
- samen
- ook
- tools
- Totaal
- spoor
- Trainen
- getraind
- Trainingen
- Transformeren
- transformers
- Reizend
- leiden
- BEURT
- twee
- type dan:
- ui
- begrijpen
- bijwerken
- us
- .
- use case
- gebruikt
- gebruikers
- toepassingen
- gebruik
- Gebruik makend
- Values
- divers
- via
- Bekijk
- visualiseren
- lopen
- willen
- we
- web
- webservices
- wanneer
- of
- welke
- en
- WIE
- wil
- Met
- binnen
- zonder
- werknemers
- workflow
- workflows
- werkzaam
- Slechtst
- het schrijven van
- u
- Your
- zephyrnet