De Amazon EMR-runtime voor Apache Spark is een prestatie-geoptimaliseerde runtime voor Apache Spark die 100% API-compatibel is met open-source Apache Spark. Met Amazon EMR versie 6.9.0 ondersteunt de EMR-runtime voor Apache Spark equivalente Spark-versie 3.3.0.
Met Amazon EMR 6.9.0 kunt u uw Apache Spark 3.x-applicaties nu sneller en tegen lagere kosten uitvoeren zonder dat er wijzigingen in uw applicaties nodig zijn. In onze prestatiebenchmarktests, afgeleid van TPC-DS-prestatietests op een schaal van 3 TB, ontdekten we dat de EMR-runtime voor Apache Spark 3.3.0 gemiddeld een 3.5 keer betere prestatie levert (bij gebruik van de totale runtime) dan open-source Apache Spark 3.3.0. XNUMX.
In dit bericht analyseren we de resultaten van onze benchmarktests met een TPC-DS-applicatie open source Apache Spark en vervolgens op Amazon EMR 6.9, dat wordt geleverd met een geoptimaliseerde Spark-runtime die compatibel is met open-source Spark. We doorlopen een gedetailleerde kostenanalyse en geven ten slotte stapsgewijze instructies om de benchmark uit te voeren.
Resultaten waargenomen
Om de prestatieverbeteringen te evalueren, hebben we een open-source Spark-hulpprogramma voor prestatietests gebruikt dat is afgeleid van de TPC-DS-toolkit voor prestatietests. We hebben de tests uitgevoerd op een c5d.9xlarge EMR-cluster met zeven knooppunten (zes kernknooppunten en één primair knooppunt) met de EMR-runtime voor Apache Spark, en een tweede zelfbeheerd cluster met zeven knooppunten op Amazon Elastic Compute-cloud (Amazon EC2) met de equivalente open-sourceversie van Spark. We hebben beide tests uitgevoerd met gegevens erin Amazon eenvoudige opslagservice (Amazone S3).
Dynamic Resource Allocation (DRA) is een geweldige functie om te gebruiken voor verschillende workloads. Voor een benchmarking-exercitie waarbij we twee platforms puur op prestatie vergelijken en testgegevensvolumes niet veranderen (3 TB in ons geval), denken we echter dat het het beste is om variabiliteit te vermijden om een vergelijking van appels met appels uit te voeren. In onze tests in zowel open-source Spark als Amazon EMR hebben we DRA uitgeschakeld tijdens het uitvoeren van de benchmarking-applicatie.
De volgende tabel toont de totale uitvoeringstijd van de taak voor alle query's (in seconden) in de querydataset van 3 TB tussen Amazon EMR versie 6.9.0 en open-source Spark versie 3.3.0. We hebben vastgesteld dat onze TPC-DS-tests een totale runtime van de taak op Amazon EMR op Amazon EC2 hadden die 3.5 keer sneller was dan die met een open-source Spark-cluster met dezelfde configuratie.
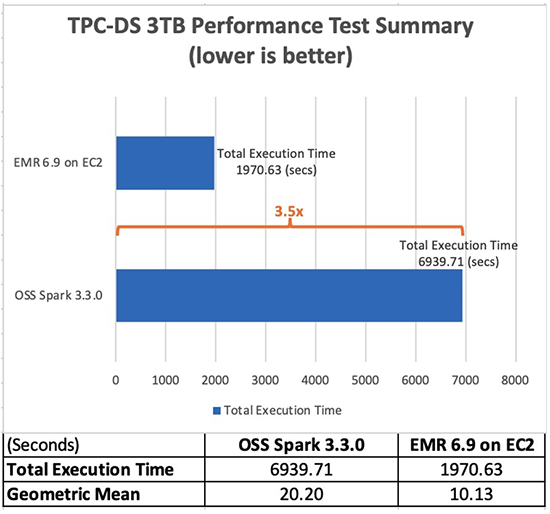
De versnelling per query op Amazon EMR 6.9 met en zonder de EMR-runtime voor Apache Spark wordt geïllustreerd in het volgende diagram. Op de horizontale as wordt elke query in de benchmark van 3 TB weergegeven. De verticale as toont de versnelling van elke query als gevolg van de EMR-runtime. Opmerkelijke prestatieverbeteringen zijn meer dan 10 keer sneller voor TPC-DS-query's 24b, 72, 95 en 96.

Kostenanalyse
De prestatieverbeteringen van de EMR-runtime voor Apache Spark vertalen zich direct in lagere kosten. We hebben een kostenbesparing van 67% kunnen realiseren door de benchmark-applicatie op Amazon EMR te laten draaien in vergelijking met de kosten die zijn gemaakt om dezelfde applicatie op open-source Spark op Amazon EC2 te laten draaien met dezelfde clustergrootte als gevolg van minder uren van Amazon EMR en Amazon EC2-gebruik. Amazon EMR-prijzen zijn voor EMR-applicaties die worden uitgevoerd op EMR-clusters met EC2-instanties. De Amazon EMR-prijs wordt toegevoegd aan de onderliggende reken- en opslagprijzen, zoals de EC2-instantieprijs en Amazon elastische blokwinkel (Amazon EBS) kosten (indien EBS-volumes worden bijgevoegd). Over het algemeen zijn de geschatte benchmarkkosten in de regio US East (N. Virginia) $ 27.01 per run voor de open-source Spark op Amazon EC2 en $ 8.82 per run voor Amazon EMR.
| Benchmark-taak | Looptijd (uur) | Geschatte kosten | Totale EC2-instantie | Totale vCPU | Totaal geheugen (GiB) | Root-apparaat (Amazon EBS) |
|
Open-source Spark op Amazon EC2 (1 primaire en 6 kernknooppunten) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiBgp2 |
|
Amazon EMR op Amazon EC2 (1 primaire en 6 kernknooppunten) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiBgp2 |
Uitsplitsing van de kosten
Het volgende is de uitsplitsing van de kosten voor de open-source Spark op Amazon EC2-taak ($ 27.01):
- Totale Amazon EC2-kosten – (7 * $ 1.728 * 2.23) = (aantal instanties * c5d.9xgroot uurtarief * taakduur in uur) = $ 26.97
- Amazon EBS-kosten – ($ 0.1/730 * 20 * 7 * 2.23) = (Amazon EBS per GB-uurtarief * root EBS-grootte * aantal instanties * taaklooptijd in uur) = $ 0.042
Het volgende is de uitsplitsing van de kosten voor de Amazon EMR op Amazon EC2-taak ($ 8.82):
- Totale Amazon EMR-kosten – (7 * $ 0.27 * 0.63) = ((aantal kernknooppunten + aantal primaire knooppunten)* c5d.9xgrote Amazon EMR-prijs * taaklooptijd in uur) = $ 1.19
- Totale Amazon EC2-kosten – (7 * $ 1.728 * 0.63) = ((aantal kernknooppunten + aantal primaire knooppunten)* c5d.9xgrote instantieprijs * taaklooptijd in uur) = $ 7.62
- Amazon EBS-kosten – ($ 0.1/730 * 20 GiB * 7 * 0.63) = (Amazon EBS per GB-uurtarief * EBS-grootte * aantal instanties * looptijd van de taak in uur) = $ 0.012
Stel OSS Spark-benchmarking in
In de volgende paragrafen geven we een beknopt overzicht van de stappen die komen kijken bij het opzetten van de benchmarking. Raadpleeg voor gedetailleerde instructies met voorbeelden de GitHub repo.
Voor onze OSS Spark-benchmarking gebruiken we de open-sourcetool Vuursteen om onze op Amazon EC2 gebaseerde Apache Spark TROS. Flintrock biedt een snelle manier om een Apache Spark-cluster op Amazon EC2 te starten met behulp van de opdrachtregel.
Voorwaarden
Voer de volgende vereiste stappen uit:
- Heb Python 3.7.x of hoger.
- Heb Pip3 22.2.2 of hoger.
- Voeg de Python bin-directory toe aan uw omgevingspad. Het Flintrock-binaire bestand wordt in dit pad geïnstalleerd.
- lopen
aws configureom uw . te configureren AWS-opdrachtregelinterface (AWS CLI) shell om naar het benchmarking-account te verwijzen. Verwijzen naar Snelle configuratie met aws configure voor instructies. - Elke ochtend sleutelpaar met beperkende bestandsmachtigingen voor toegang tot het primaire OSS Spark-knooppunt.
- Maak indien nodig een nieuwe S3-bucket in uw testaccount.
- Kopieer de TPC-DS-brongegevens als invoer naar uw S3-bucket.
- Bouw de benchmarktoepassing volgens de stappen in Stappen om de spark-benchmark-assembly-toepassing te bouwen. U kunt ook een vooraf gebouwd spark-benchmark-assemblage-3.3.0.jar als u een op Spark 3.3.0 gebaseerde toepassing wilt.
Implementeer het Spark-cluster en voer de benchmarktaak uit
Voer de volgende stappen uit:
- Installeer de Flintrock-tool via pip zoals weergegeven in Stappen om OSS Spark Benchmarking in te stellen.
- Voer de opdracht flintrock configure uit, die een standaardconfiguratiebestand opent.
- Wijzig de standaard
config.yamlbestand op basis van uw behoeften. Of kopieer en plak het config.yaml-bestand inhoud naar het standaardconfiguratiebestand. Sla het bestand vervolgens op waar het was. - Start ten slotte het Spark-cluster met 7 knooppunten op Amazon EC2 via Flintrock.
Dit zou een Spark-cluster moeten maken met één primair knooppunt en zes werkknooppunten. Als u foutmeldingen ziet, controleer dan nogmaals de configuratiebestandswaarden, met name de Spark- en Hadoop-versies en de kenmerken van download-source en de AMI.
Het OSS Spark-cluster wordt niet geleverd met YARN resource manager. Om dit in te schakelen, moeten we het cluster configureren.
- Download de garen-site.xml en inschakelen-garen.sh bestanden uit de GitHub-repo.
- Vervangen met het IP-adres van het primaire knooppunt in uw Flintrock-cluster.
U kunt het IP-adres ophalen uit de Amazon EC2-console.
- Upload de bestanden naar alle knooppunten van het Spark-cluster.
- Voer het enable-yarn-script uit.
- Schakel Snappy-ondersteuning in Hadoop in (de benchmarktaak leest gecomprimeerde Snappy-gegevens).
- Download het JAR-bestand van de benchmark-hulpprogrammatoepassing spark-benchmark-assemblage-3.3.0.jar naar uw lokale machine.
- Kopieer dit bestand naar het cluster.
- Log in op het primaire knooppunt en start YARN.
- Dien de benchmarktaak in op het open-source Spark-cluster zoals weergegeven in Dien de benchmarktaak in.
Vat de resultaten samen
Download het testresultaatbestand van de output S3-bucket s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Vervangen $YOUR_S3_BUCKET met uw S3-bucketnaam.) U kunt de Amazon S3-console gebruiken en naar de output S3-locatie navigeren of de AWS CLI gebruiken.
De Spark-benchmarktoepassing maakt een tijdstempelmap en schrijft een samenvattingsbestand in een summary.csv-voorvoegsel. Uw tijdstempel en bestandsnaam verschillen van die in het voorgaande voorbeeld.
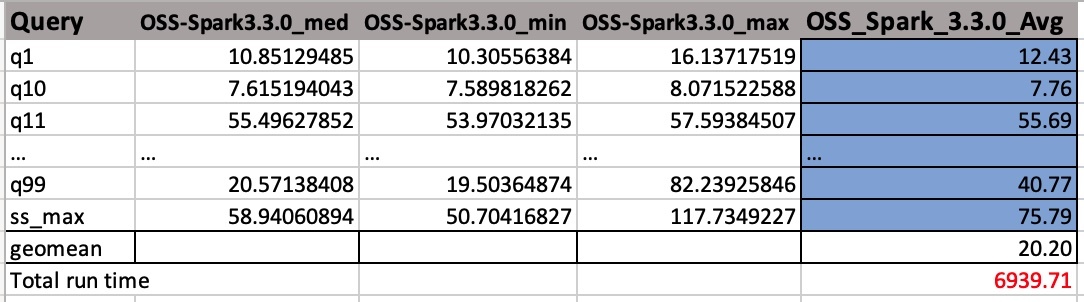
De CSV-uitvoerbestanden hebben vier kolommen zonder koptekstnamen. Zij zijn:
- Vraag naam
- Mediane tijd
- Minimale tijd
- Maximale tijd
De volgende schermafbeelding toont een voorbeelduitvoer. We hebben handmatig kolomnamen toegevoegd. De manier waarop we het geogemiddelde en de totale looptijd van de taak berekenen, is gebaseerd op rekenkundige gemiddelden. We nemen eerst het gemiddelde van de med-, min- en max-waarden met behulp van de formule GEMIDDELDE(B2:D2). Vervolgens nemen we een meetkundig gemiddelde van de kolom Gem met de formule GEOMEAN(E2:E105).
Stel Amazon EMR-benchmarking in
Voor gedetailleerde instructies, zie Stappen om EMR-benchmarking in te stellen.
Voorwaarden
Voer de volgende vereiste stappen uit:
- lopen
aws configureom uw AWS CLI-shell te configureren om naar het benchmarking-account te verwijzen. Verwijzen naar Snelle configuratie met aws configure voor instructies. - Upload de benchmark-applicatie naar Amazon S3.
Implementeer het EMR-cluster en voer de benchmarktaak uit
Voer de volgende stappen uit:
- Draai Amazon EMR in uw AWS CLI-shell met behulp van de opdrachtregel zoals weergegeven in Implementeer EMR Cluster en voer een benchmarktaak uit.
- Configureer Amazon EMR met één primaire (c5d.9xlarge) en zes kernknooppunten (c5d.9xlarge). Verwijzen naar maak-cluster voor een gedetailleerde beschrijving van AWS CLI-opties.
- Sla de cluster-ID van het antwoord op. Deze heb je nodig in de volgende stap.
- Dien de benchmarktaak in Amazon EMR in met behulp van add-steps in de AWS CLI.
Vat de resultaten samen
Vat de resultaten van de uitvoerbucket samen s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT op dezelfde manier als we deden voor de OSS-resultaten en vergelijk.
Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de bronnen die u hebt gemaakt met behulp van de instructies in de Cleanup-gedeelte van de GitHub-opslagplaats.
- Stop de EMR- en OSS Spark-clusters. U kunt ze ook verwijderen als u de inhoud niet wilt behouden. U kunt deze resources verwijderen door het script uit te voeren cleanup-benchmark-env.sh vanaf een terminal in uw benchmarkomgeving.
- Als je gebruikt AWS-Cloud9 als uw IDE voor het bouwen van het JAR-bestand van de benchmarktoepassing met behulp van Stappen om de spark-benchmark-assembly-toepassing te bouwen, wilt u misschien ook de omgeving verwijderen.
Conclusie
U kunt uw Apache Spark-workloads 3.5 keer (op basis van de totale runtime) sneller en tegen lagere kosten uitvoeren zonder wijzigingen in uw applicaties aan te brengen door Amazon EMR 6.9.0 te gebruiken.
Abonneer u op de Big Data Blog's om op de hoogte te blijven RSS-feed voor meer informatie over de EMR-runtime voor Apache Spark, best practices voor configuratie en afstemmingsadvies.
Zie voor eerdere benchmarktests Voer Apache Spark 3.0-workloads 1.7 keer sneller uit met Amazon EMR-runtime voor Apache Spark. Merk op dat het eerdere benchmarkresultaat van 1.7 keer de prestatie gebaseerd was op geometrisch gemiddelde. Op basis van geometrisch gemiddelde waren de prestaties in Amazon EMR 6.9 twee keer sneller.
Over de auteurs
 Sekar Srinivasan is Sr. Specialist Solutions Architect bij AWS gericht op Big Data en Analytics. Sekar heeft meer dan 20 jaar ervaring in het werken met data. Hij heeft een passie voor het helpen van klanten bij het bouwen van schaalbare oplossingen die hun architectuur moderniseren en inzichten uit hun gegevens genereren. In zijn vrije tijd werkt hij graag aan non-profit projecten, met name projecten gericht op kansarme kindereducatie.
Sekar Srinivasan is Sr. Specialist Solutions Architect bij AWS gericht op Big Data en Analytics. Sekar heeft meer dan 20 jaar ervaring in het werken met data. Hij heeft een passie voor het helpen van klanten bij het bouwen van schaalbare oplossingen die hun architectuur moderniseren en inzichten uit hun gegevens genereren. In zijn vrije tijd werkt hij graag aan non-profit projecten, met name projecten gericht op kansarme kindereducatie.
 Prabu Ravichandran is een Senior Data Architect bij Amazon Web Services, gericht op Analytics, data Lake architectuur en implementatie. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare en robuuste oplossingen met behulp van AWS-services. In zijn vrije tijd houdt Prabu van reizen en tijd doorbrengen met familie.
Prabu Ravichandran is een Senior Data Architect bij Amazon Web Services, gericht op Analytics, data Lake architectuur en implementatie. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare en robuuste oplossingen met behulp van AWS-services. In zijn vrije tijd houdt Prabu van reizen en tijd doorbrengen met familie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 jaar
- 7
- 9
- a
- in staat
- Over
- boven
- toegang
- Account
- toegevoegd
- adres
- advies
- Alles
- toewijzing
- Amazone
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analyse
- analytics
- analyseren
- en
- apache
- Apache Spark
- api
- Aanvraag
- toepassingen
- architectuur
- attributen
- gemiddelde
- AVG
- AWS
- As
- gebaseerde
- geloofd wie en wat je bent
- criterium
- BEST
- 'best practices'
- tussen
- Groot
- Big data
- Blok
- Storing
- bouw
- Gebouw
- geval
- verandering
- Wijzigingen
- lasten
- tabel
- TROS
- Kolom
- columns
- hoe
- vergelijken
- vergelijking
- verenigbaar
- Berekenen
- Configuratie
- troosten
- content
- Kern
- Kosten
- kostenbesparingen
- Kosten
- en je merk te creëren
- aangemaakt
- creëert
- Klanten
- gegevens
- Datameer
- Datum
- Standaard
- Afgeleid
- beschrijving
- gedetailleerd
- apparaat
- DEED
- anders
- direct
- invalide
- Nee
- Dont
- Download
- elk
- oosten
- ebs
- Onderwijs
- in staat stellen
- Milieu
- Gelijkwaardig
- fout
- vooral
- geschat
- Ether (ETH)
- schatten
- voorbeeld
- voorbeelden
- Oefening
- ervaring
- familie
- sneller
- Kenmerk
- Dien in
- Bestanden
- Tot slot
- Voornaam*
- gericht
- gefocust
- volgend
- formule
- gevonden
- Gratis
- oppompen van
- toekomst
- verdiensten
- het genereren van
- GitHub
- groot
- Hadoop
- het helpen van
- helpt
- Horizontaal
- HOURS
- Echter
- HTML
- HTTPS
- uitvoering
- verbetering
- verbeteringen
- in
- invoer
- inzichten
- instantie
- instructies
- betrokken zijn
- IP
- IP-adres
- IT
- Jobomschrijving:
- Houden
- meer
- lancering
- LEARN
- Lijn
- lokaal
- plaats
- machine
- maken
- manager
- manier
- handmatig
- max
- middel
- Geheugen
- berichten
- meer
- naam
- namen
- OP DEZE WEBSITE VIND JE
- Noodzaak
- nodig
- behoeften
- New
- volgende
- knooppunt
- knooppunten
- non-profit
- opvallend
- aantal
- EEN
- open source
- geoptimaliseerde
- Opties
- bestellen
- Ons
- schets
- totaal
- hartstochtelijk
- verleden
- pad
- prestatie
- permissies
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- Pops
- Post
- praktijken
- prijs
- Prijzen
- prijsstelling
- primair
- privaat
- projecten
- zorgen voor
- mits
- biedt
- puur
- Python
- Quick
- tarief
- realiseren
- Gereduceerd
- regio
- los
- vervangen
- hulpbron
- Resources
- antwoord
- beperkend
- resultaat
- Resultaten
- robuust
- wortel
- lopen
- lopend
- dezelfde
- Bespaar
- Bespaar geld
- schaalbare
- Scale
- Tweede
- seconden
- sectie
- secties
- senior
- Diensten
- het instellen van
- setup
- Shell
- moet
- getoond
- Shows
- Eenvoudig
- ZES
- Maat
- Oplossingen
- bron
- Vonk
- specialist
- Uitgaven
- begin
- Stap voor
- Stappen
- mediaopslag
- abonneren
- dergelijk
- OVERZICHT
- ondersteuning
- steunen
- tafel
- Nemen
- terminal
- proef
- testen
- De
- hun
- Door
- niet de tijd of
- keer
- tijdstempel
- naar
- tools
- toolkit
- Totaal
- vertalen
- Reizend
- die ten grondslag liggen
- moeilijk hebben
- us
- Gebruik
- .
- utility
- Values
- versie
- via
- Virginia
- volumes
- web
- webservices
- welke
- en
- wil
- zonder
- Mijn werk
- werker
- werkzaam
- X
- XML
- YAML
- jaar
- Your
- zephyrnet