Een nieuw gecreëerd kunstmatige-intelligentie (AI)-systeem op basis van Deep Reinforcement Learning (DRL) kan reageren op aanvallers in een gesimuleerde omgeving en 95% van de cyberaanvallen blokkeren voordat ze escaleren.
Dat is volgens de onderzoekers van het Pacific Northwest National Laboratory van het Department of Energy, die een abstracte simulatie van het digitale conflict tussen aanvallers en verdedigers in een netwerk hebben gebouwd en vier verschillende DRL-neurale netwerken hebben getraind om beloningen te maximaliseren op basis van het voorkomen van compromissen en het minimaliseren van netwerkverstoring.
De gesimuleerde aanvallers gebruikten een reeks tactieken op basis van de MITRE ATT & CK classificatie van het framework om van de initiële toegangs- en verkenningsfase naar andere aanvalsfasen te gaan totdat ze hun doel bereikten: de impact- en exfiltratiefase.
De succesvolle training van het AI-systeem in de vereenvoudigde aanvalsomgeving toont aan dat defensieve reacties op aanvallen in realtime kunnen worden afgehandeld door een AI-model, zegt Samrat Chatterjee, een datawetenschapper die het werk van het team presenteerde op de jaarlijkse bijeenkomst van de Association for the Vooruitgang van kunstmatige intelligentie in Washington, DC op 14 februari.
"Je wilt niet naar complexere architecturen gaan als je niet eens de belofte van deze technieken kunt laten zien", zegt hij. "We wilden eerst aantonen dat we een DRL daadwerkelijk met succes kunnen trainen en een aantal goede testresultaten kunnen laten zien, voordat we verder gaan."
De toepassing van machine learning en kunstmatige intelligentietechnieken op verschillende gebieden binnen cyberbeveiliging is het afgelopen decennium een hete trend geworden, van de vroege integratie van machine learning in gateways voor e-mailbeveiliging in de vroege 2010s naar meer recente pogingen om gebruik ChatGPT om code te analyseren of forensische analyses uitvoeren. Nu, de meeste beveiligingsproducten hebben - of beweren te hebben - een paar functies die worden aangedreven door algoritmen voor machine learning die zijn getraind op grote datasets.
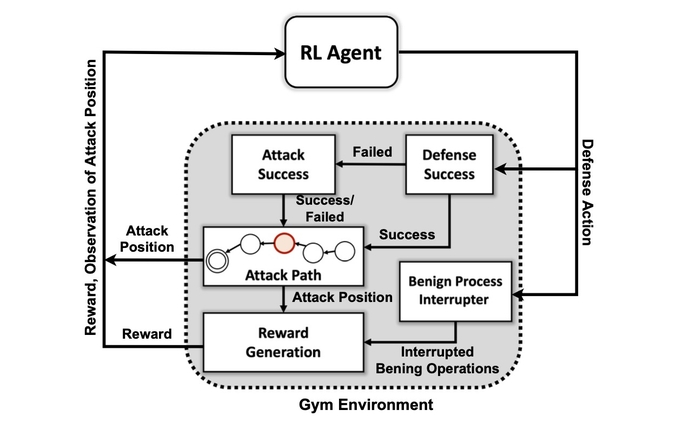
Toch blijft het creëren van een AI-systeem dat in staat is tot proactieve verdediging eerder ambitieus dan praktisch. Hoewel er nog verschillende hindernissen zijn voor onderzoekers, toont het PNNL-onderzoek aan dat een AI-verdediger in de toekomst mogelijk zou kunnen zijn.
"Het evalueren van meerdere DRL-algoritmen die zijn getraind in verschillende vijandige omgevingen, is een belangrijke stap in de richting van praktische autonome cyberdefensieoplossingen", aldus het PNNL-onderzoeksteam vermeld in hun krant. "Onze experimenten suggereren dat modelvrije DRL-algoritmen effectief kunnen worden getraind onder meertraps aanvalsprofielen met verschillende vaardigheids- en persistentieniveaus, wat gunstige verdedigingsresultaten oplevert in betwiste omgevingen."
Hoe het systeem MITRE ATT&CK gebruikt
Het eerste doel van het onderzoeksteam was om een aangepaste simulatieomgeving te creëren op basis van een open source toolkit die bekend staat als AI-sportschool openen. Met behulp van die omgeving creëerden de onderzoekers aanvallerentiteiten met verschillende vaardigheids- en persistentieniveaus met de mogelijkheid om een subset van 7 tactieken en 15 technieken uit het MITRE ATT&CK-framework te gebruiken.
Het doel van de aanvallers is om de zeven stappen van de aanvalsketen te doorlopen, van initiële toegang tot uitvoering, van persistentie tot commando en controle, en van verzameling tot impact.
Voor de aanvaller kan het ingewikkeld zijn om hun tactiek aan te passen aan de toestand van de omgeving en de huidige acties van de verdediger, zegt Chatterjee van PNNL.
"De tegenstander moet zijn weg vinden van een aanvankelijke verkenningsstaat helemaal naar een exfiltratie- of impactstaat", zegt hij. "We proberen niet een soort model te maken om een tegenstander te stoppen voordat ze de omgeving binnendringen - we gaan ervan uit dat het systeem al is gecompromitteerd."
De onderzoekers gebruikten vier benaderingen van neurale netwerken op basis van versterkend leren. Reinforcement learning (RL) is een machine learning-benadering die het beloningssysteem van het menselijk brein nabootst. Een neuraal netwerk leert door bepaalde parameters voor individuele neuronen te versterken of te verzwakken om betere oplossingen te belonen, zoals gemeten door een score die aangeeft hoe goed het systeem presteert.
Versterkend leren stelt de computer in wezen in staat om een goede, maar niet perfecte benadering van het probleem te creëren, zegt Mahantesh Halappanavar, een PNNL-onderzoeker en een auteur van het artikel.
"Zonder versterkend leren te gebruiken, zouden we het nog steeds kunnen doen, maar het zou een heel groot probleem zijn dat niet genoeg tijd zal hebben om daadwerkelijk een goed mechanisme te bedenken", zegt hij. "Ons onderzoek ... geeft ons dit mechanisme waarbij diep versterkend leren tot op zekere hoogte een deel van het menselijk gedrag zelf nabootst, en het kan deze zeer uitgestrekte ruimte zeer efficiënt verkennen."
Niet klaar voor primetime
Uit de experimenten bleek dat een specifieke leermethode voor versterking, bekend als een Deep Q Network, een sterke oplossing creëerde voor het defensieve probleem, het vangen van 97% van de aanvallers in de testdataset. Toch is het onderzoek nog maar het begin. Beveiligingsprofessionals moeten niet snel op zoek gaan naar een AI-partner om hen te helpen bij incidentrespons en forensisch onderzoek.
Een van de vele problemen die nog moeten worden opgelost, is het verkrijgen van versterkend leren en diepe neurale netwerken om de factoren te verklaren die hun beslissingen hebben beïnvloed, een onderzoeksgebied dat verklaarbaar versterkend leren (XRL) wordt genoemd.
Bovendien zijn de robuustheid van de AI-algoritmen en het vinden van efficiënte manieren om de neurale netwerken te trainen beide problemen die moeten worden opgelost, zegt Chatterjee van PNNL.
"Een product maken - dat was niet de belangrijkste motivatie voor dit onderzoek", zegt hij. "Dit ging meer over wetenschappelijke experimenten en algoritmische ontdekkingen."
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- vermogen
- Over
- SAMENVATTING
- toegang
- Volgens
- acties
- werkelijk
- toevoeging
- vordering
- tegenstander
- agenten
- AI
- AI-powered
- algoritmische
- algoritmen
- Alles
- toestaat
- al
- analyse
- analyseren
- en
- jaar-
- Aanvraag
- nadering
- benaderingen
- GEBIED
- kunstmatig
- kunstmatige intelligentie
- Kunstmatige intelligentie (AI)
- Vereniging
- aanvallen
- Aanvallen
- auteur
- autonoom
- gebaseerde
- worden
- vaardigheden
- Betere
- tussen
- Groot
- Blok
- Hersenen
- bebouwd
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- kan niet
- in staat
- zeker
- keten
- ChatGPT
- aanspraak maken op
- classificatie
- Collectie
- hoe
- complex
- Aangetast
- computer
- Gedrag
- conflict
- blijft
- onder controle te houden
- kon
- en je merk te creëren
- aangemaakt
- Wij creëren
- Actueel
- gewoonte
- cyber
- cyberaanvallen
- Cybersecurity
- gegevens
- data scientist
- gegevensset
- datasets
- dc
- decennium
- beslissing
- beslissingen
- deep
- diepe neurale netwerken
- verdedigers
- Verdediging
- defensief
- tonen
- demonstreert
- afdeling
- Ministerie van Energie
- anders
- digitaal
- ontdekking
- Ontwrichting
- diversen
- DOE
- Vroeg
- effectief
- doeltreffend
- efficiënt
- inspanningen
- e-mail beveiliging
- energie-niveau
- genoeg
- entiteiten
- Milieu
- in wezen
- Ether (ETH)
- evalueren
- Zelfs
- uitvoering
- exfiltratie
- Verklaren
- Verken
- factoren
- Voordelen
- weinig
- Velden
- het vinden van
- Voornaam*
- stroom
- gerechtelijk
- forensisch onderzoek
- Naar voren
- gevonden
- Achtergrond
- oppompen van
- toekomst
- krijgen
- het krijgen van
- geeft
- doel
- Doelen
- goed
- hand
- hulp
- Populair
- Hoe
- HTTPS
- menselijk
- Horden
- Impact
- belangrijk
- in
- incident
- incident reactie
- wat aangeeft
- individueel
- beïnvloed
- eerste
- integratie
- Intelligentie
- IT
- zelf
- Soort
- bekend
- laboratorium
- Groot
- leren
- niveaus
- Kijk
- machine
- machine learning
- Hoofd
- veel
- max-width
- Maximaliseren
- mechanisme
- vergadering
- methode
- minimaliseren
- model
- meer
- Motivatie
- beweging
- bewegend
- meervoudig
- nationaal
- OP DEZE WEBSITE VIND JE
- Noodzaak
- netwerk
- netwerken
- Neural
- neuraal netwerk
- neurale netwerken
- neuronen
- open
- open source
- Overige
- Pacific
- Papier
- parameters
- verleden
- presteert
- volharding
- fase
- Plato
- Plato gegevensintelligentie
- PlatoData
- mogelijk
- aangedreven
- PRAKTISCH
- gepresenteerd
- het voorkomen van
- Prime
- Proactieve
- probleem
- problemen
- Producten
- professionals
- Profielen
- belofte
- RE
- bereikt
- Reageren
- reageert
- klaar
- vast
- real-time
- recent
- versterking van leren
- blijven
- onderzoek
- onderzoeker
- onderzoekers
- antwoord
- Belonen
- Beloningen
- robuustheid
- zegt
- Wetenschapper
- veiligheid
- -Series
- reeks
- settings
- zeven
- moet
- tonen
- Shows
- vereenvoudigd
- simulatie
- bekwaamheid
- oplossing
- Oplossingen
- sommige
- Spoedig
- bron
- Tussenruimte
- specifiek
- begin
- Land
- Stap voor
- Stappen
- Still
- stop
- versterking
- sterke
- geslaagd
- Met goed gevolg
- system
- tactiek
- team
- technieken
- Testen
- De
- De toekomst
- De Staat
- hun
- Door
- niet de tijd of
- naar
- toolkit
- in de richting van
- Trainen
- getraind
- Trainingen
- trend
- voor
- us
- .
- variëteit
- groot
- gezocht
- Washington
- manieren
- en
- WIE
- wil
- binnen
- zonder
- Mijn werk
- zou
- waardoor
- zephyrnet











