Sponsored Bericht

De uitdagingen van het helemaal opnieuw bouwen van multimodale modellen
Voor veel gebruiksscenario's voor machine learning vertrouwen organisaties uitsluitend op gegevens in tabelvorm en op bomen gebaseerde modellen zoals XGBoost en LightGBM. Dit komt omdat diep leren gewoon te moeilijk is voor de meeste ML-teams. Veelvoorkomende uitdagingen zijn onder meer:
- Gebrek aan vakkennis die nodig is om complexe deep learning-modellen te ontwikkelen
- Frameworks zoals PyTorch en Tensorflow vereisen dat teams duizenden regels code schrijven die vatbaar zijn voor menselijke fouten
- Het trainen van gedistribueerde DL-pijplijnen vereist diepgaande kennis van de infrastructuur en het kan weken duren om modellen te trainen
Hierdoor lopen teams waardevolle signalen mis die verborgen zitten in ongestructureerde data zoals tekst en afbeeldingen.
Snelle modelontwikkeling met declaratieve systemen
Nieuwe declaratieve machine learning-systemen, zoals open-source die Ludwig bij Uber begon, bieden een low-code benadering voor het automatiseren van ML waarmee datateams sneller state-of-the-art modellen kunnen bouwen en implementeren met een eenvoudig configuratiebestand. Met name Predibase, het toonaangevende low-code declaratieve ML-platform, maakt het samen met Ludwig eenvoudig om multimodale deep learning-modellen te bouwen in <15 regels code.
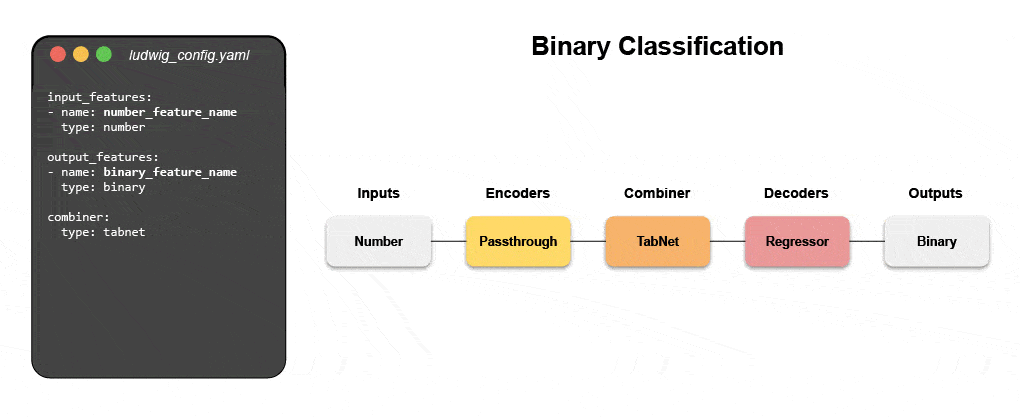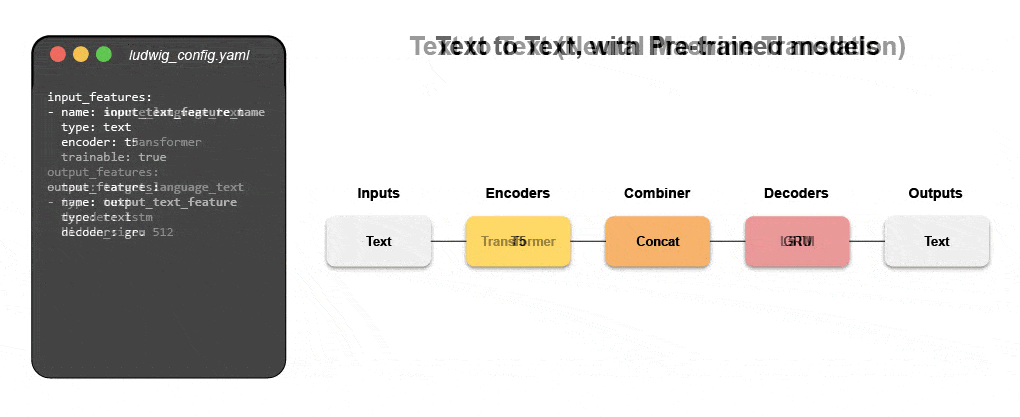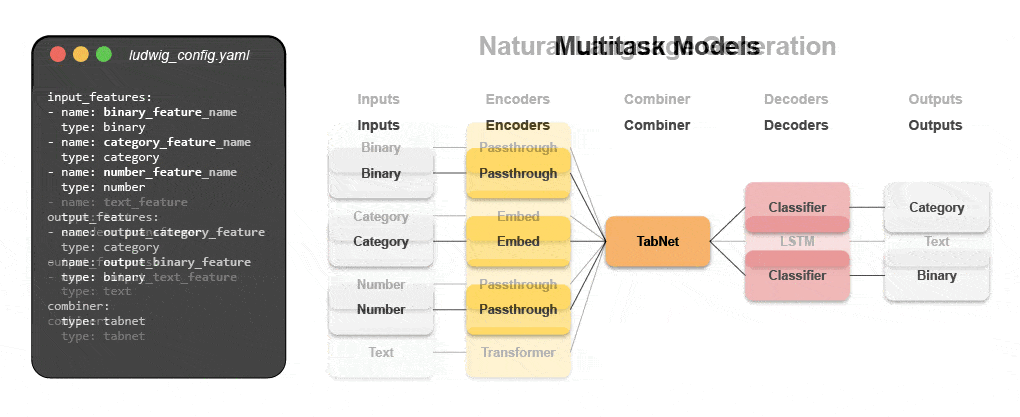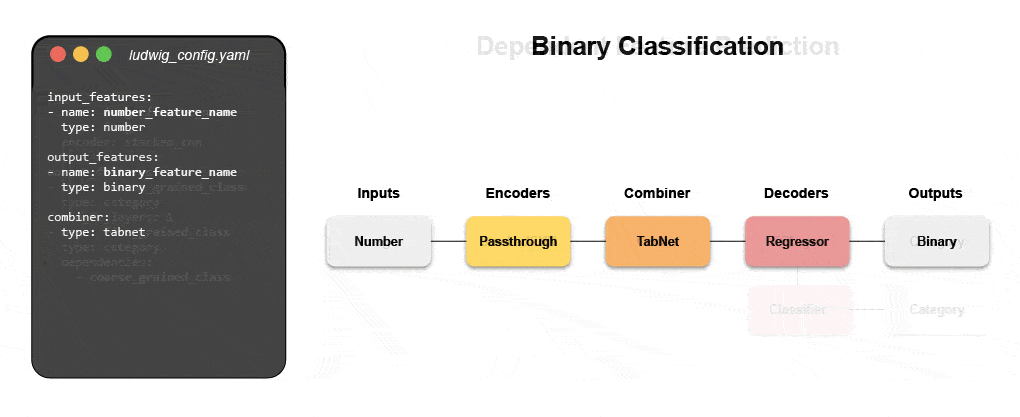
Leer hoe u een multimodaal model bouwt met declaratieve ML
Doe mee aan ons komende webinar en live tutorial om meer te weten te komen over declaratieve systemen zoals Ludwig en volg stapsgewijze instructies voor het bouwen van een multimodaal voorspellingsmodel voor klantrecensies dat gebruikmaakt van tekst en tabelgegevens.
In deze sessie leer je hoe je:
- Train, herhaal en implementeer snel een multimodaal model voor voorspellingen van klantrecensies,
- Gebruik low-code declaratieve ML-tools om de tijd die nodig is om meerdere ML-modellen te bouwen drastisch te verminderen,
- Gebruik ongestructureerde gegevens net zo gemakkelijk als gestructureerde gegevens met open-source Ludwig en Predibase
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- Over
- en
- nadering
- automatiseren
- omdat
- bouw
- Gebouw
- uitdagingen
- code
- Gemeen
- complex
- Configuratie
- klant
- gegevens
- deep
- diepgaand leren
- implementeren
- ontwikkelen
- Ontwikkeling
- verdeeld
- dramatisch
- gemakkelijk
- maakt
- fout
- expert
- sneller
- Dien in
- volgen
- oppompen van
- gif
- Hard
- verborgen
- Hoe
- How To
- HTML
- HTTPS
- menselijk
- afbeeldingen
- in
- omvatten
- Infrastructuur
- instructies
- IT
- KDnuggets
- kennis
- leidend
- LEARN
- leren
- leveraging
- lijnen
- leven
- machine
- machine learning
- maken
- veel
- ML
- model
- modellen
- meest
- meervoudig
- nodig
- open source
- organisaties
- Plato
- Plato gegevensintelligentie
- PlatoData
- voorspelling
- Voorspellingen
- pytorch
- verminderen
- vereisen
- vereist
- resultaat
- beoordelen
- Sessie
- signalen
- Eenvoudig
- eenvoudigweg
- specifiek
- gestart
- state-of-the-art
- Stap voor
- gestructureerde
- Systems
- Nemen
- neemt
- teams
- tensorflow
- De
- duizenden kosten
- niet de tijd of
- naar
- ook
- tools
- Trainen
- zelfstudie
- komende
- gebruiksgevallen
- waardevol
- weken
- wil
- binnen
- schrijven
- XGBoost
- Your
- zephyrnet





