
Terwijl AI van de cloud naar de Edge migreert, zien we dat de technologie wordt gebruikt in een steeds groter wordende verscheidenheid aan gebruiksscenario’s – variërend van detectie van afwijkingen tot toepassingen zoals smart shopping, surveillance, robotica en fabrieksautomatisering. Er bestaat dus geen one-size-fits-all oplossing. Maar met de snelle groei van camera-compatibele apparaten is AI het meest toegepast voor het analyseren van realtime videogegevens om videomonitoring te automatiseren om de veiligheid te verbeteren, de operationele efficiëntie te verbeteren en betere klantervaringen te bieden, waardoor uiteindelijk een concurrentievoordeel in hun sector wordt verkregen. . Om videoanalyse beter te ondersteunen, moet u de strategieën begrijpen voor het optimaliseren van de systeemprestaties in edge AI-implementaties.
- Het selecteren van de juiste rekenmachines om aan de vereiste prestatieniveaus te voldoen of deze te overtreffen. Voor een AI-toepassing moeten deze rekenmachines de functies van de gehele visiepijplijn uitvoeren (dat wil zeggen videovoor- en naverwerking, neurale netwerkinferentie).
Mogelijk is een speciale AI-accelerator vereist, ongeacht of deze discreet is of geïntegreerd in een SoC (in plaats van de AI-inferentie op een CPU of GPU uit te voeren).
- Het verschil begrijpen tussen doorvoer en latentie; waarbij doorvoer de snelheid is waarmee gegevens in een systeem kunnen worden verwerkt, en latentie de vertraging bij de gegevensverwerking door het systeem meet en vaak wordt geassocieerd met realtime responsiviteit. Een systeem kan bijvoorbeeld beeldgegevens genereren met een snelheid van 100 frames per seconde (doorvoer), maar het duurt 100 ms (latentie) voordat een beeld door het systeem gaat.
- Gezien het vermogen om de AI-prestaties in de toekomst eenvoudig te schalen om tegemoet te komen aan de groeiende behoeften, veranderende vereisten en evoluerende technologieën (bijvoorbeeld geavanceerdere AI-modellen voor verhoogde functionaliteit en nauwkeurigheid). U kunt prestatieschaling realiseren met behulp van AI-accelerators in moduleformaat of met extra AI-acceleratorchips.
De daadwerkelijke prestatie-eisen zijn toepassingsafhankelijk. Normaal gesproken kan men verwachten dat het systeem voor videoanalyse de datastromen die van camera's binnenkomen, moet verwerken met 30-60 frames per seconde en met een resolutie van 1080p of 4k. Een AI-compatibele camera zou een enkele stream verwerken; een edge-apparaat zou meerdere stromen parallel verwerken. In beide gevallen moet het edge AI-systeem de voorverwerkingsfuncties ondersteunen om de sensorgegevens van de camera om te zetten in een formaat dat overeenkomt met de invoervereisten van het AI-inferentiegedeelte (Afbeelding 1).
Voorverwerkingsfuncties nemen de onbewerkte gegevens op en voeren taken uit zoals formaat wijzigen, normalisatie en kleurruimteconversie, voordat de invoer wordt ingevoerd in het model dat op de AI-versneller draait. Voorverwerking kan gebruik maken van efficiënte beeldverwerkingsbibliotheken zoals OpenCV om de voorverwerkingstijden te verkorten. Nabewerking omvat het analyseren van de uitvoer van de gevolgtrekking. Het maakt gebruik van taken zoals niet-maximale onderdrukking (NMS interpreteert de uitvoer van de meeste objectdetectiemodellen) en beeldweergave om bruikbare inzichten te genereren, zoals selectiekaders, klassenlabels of betrouwbaarheidsscores.

Figuur 1. Voor het infereren van AI-modellen worden de voor- en naverwerkingsfuncties doorgaans uitgevoerd op een applicatieprocessor.
Het infereren van AI-modellen kan de extra uitdaging hebben om meerdere neurale netwerkmodellen per frame te verwerken, afhankelijk van de mogelijkheden van de applicatie. Computer vision-toepassingen omvatten doorgaans meerdere AI-taken waarvoor een pijplijn van meerdere modellen nodig is. Bovendien is de output van het ene model vaak de input van het volgende model. Met andere woorden: modellen in een applicatie zijn vaak van elkaar afhankelijk en moeten opeenvolgend worden uitgevoerd. De exacte set modellen die moet worden uitgevoerd, is mogelijk niet statisch en kan dynamisch variëren, zelfs per frame.
De uitdaging om meerdere modellen dynamisch uit te voeren vereist een externe AI-accelerator met speciaal en voldoende groot geheugen om de modellen op te slaan. Vaak is de geïntegreerde AI-versneller in een SoC niet in staat de werklast met meerdere modellen te beheren vanwege beperkingen die worden opgelegd door het gedeelde geheugensubsysteem en andere bronnen in de SoC.
Op bewegingsvoorspelling gebaseerde objecttracking is bijvoorbeeld afhankelijk van continue detecties om een vector te bepalen die wordt gebruikt om het gevolgde object op een toekomstige positie te identificeren. De effectiviteit van deze aanpak is beperkt omdat het echte heridentificatievermogen ontbeert. Met bewegingsvoorspelling kan het spoor van een object verloren gaan als gevolg van gemiste detecties, occlusies of als het object het gezichtsveld verlaat, zelfs maar tijdelijk. Eenmaal verloren, is er geen manier meer om het spoor van het object opnieuw te koppelen. Het toevoegen van heridentificatie lost deze beperking op, maar vereist een visuele inbedding (dwz een afbeeldingsvingerafdruk). Voor uiterlijke inbedding is een tweede netwerk nodig om een kenmerkvector te genereren door het beeld te verwerken dat zich in het begrenzende kader van het door het eerste netwerk gedetecteerde object bevindt. Deze inbedding kan worden gebruikt om het object opnieuw te identificeren, ongeacht tijd of ruimte. Omdat er inbeddingen moeten worden gegenereerd voor elk object dat in het gezichtsveld wordt gedetecteerd, nemen de verwerkingsvereisten toe naarmate de scène drukker wordt. Objecttracking met heridentificatie vereist een zorgvuldige afweging tussen het uitvoeren van detectie met hoge nauwkeurigheid / hoge resolutie / hoge framesnelheid en het reserveren van voldoende overhead voor schaalbaarheid van de inbedding. Eén manier om de verwerkingsbehoefte op te lossen is het gebruik van een speciale AI-accelerator. Zoals eerder vermeld kan de AI-engine van de SoC lijden onder het gebrek aan gedeelde geheugenbronnen. Modeloptimalisatie kan ook worden gebruikt om de verwerkingsvereisten te verlagen, maar dit kan de prestaties en/of nauwkeurigheid beïnvloeden.
In een slimme camera of edge-apparaat verkrijgt de geïntegreerde SoC (dwz de hostprocessor) de videoframes en voert de voorverwerkingsstappen uit die we eerder hebben beschreven. Deze functies kunnen worden uitgevoerd met de CPU-kernen of GPU van de SoC (indien beschikbaar), maar ze kunnen ook worden uitgevoerd door speciale hardwareversnellers in de SoC (bijvoorbeeld een beeldsignaalprocessor). Nadat deze voorverwerkingsstappen zijn voltooid, kan de AI-versneller die in de SoC is geïntegreerd, rechtstreeks toegang krijgen tot deze gekwantiseerde invoer vanuit het systeemgeheugen, of, in het geval van een discrete AI-versneller, wordt de invoer vervolgens ter gevolgtrekking afgeleverd, doorgaans via de USB- of PCIe-interface.
Een geïntegreerde SoC kan een reeks rekeneenheden bevatten, waaronder CPU's, GPU's, AI-accelerator, vision-processors, video-encoders/decoders, beeldsignaalprocessor (ISP) en meer. Deze rekeneenheden delen allemaal dezelfde geheugenbus en hebben bijgevolg toegang tot hetzelfde geheugen. Bovendien moeten de CPU en GPU mogelijk ook een rol spelen bij de gevolgtrekking en zullen deze eenheden bezig zijn met het uitvoeren van andere taken in een ingezet systeem. Dit is wat we bedoelen met overhead op systeemniveau (Figuur 2).
Veel ontwikkelaars evalueren ten onrechte de prestaties van de ingebouwde AI-versneller in de SoC zonder rekening te houden met het effect van overhead op systeemniveau op de totale prestaties. Overweeg bijvoorbeeld om een YOLO-benchmark uit te voeren op een 50 TOPS AI-accelerator geïntegreerd in een SoC, die een benchmarkresultaat van 100 gevolgtrekkingen/seconde (IPS) zou kunnen opleveren. Maar in een geïmplementeerd systeem met alle andere rekeneenheden actief, zouden die 50 TOPS kunnen worden teruggebracht tot ongeveer 12 TOPS en zouden de algehele prestaties slechts 25 IPS opleveren, uitgaande van een royale benuttingsfactor van 25%. Systeemoverhead is altijd een factor als het platform continu videostreams verwerkt. Als alternatief zou met een discrete AI-versneller (bijv. Kinara Ara-1, Hailo-8, Intel Myriad X) het gebruik op systeemniveau groter kunnen zijn dan 90%, omdat zodra de host-SoC de inferentiefunctie initieert en de invoer van het AI-model overdraagt gegevens, werkt de versneller autonoom en maakt gebruik van het speciale geheugen voor toegang tot modelgewichten en parameters.
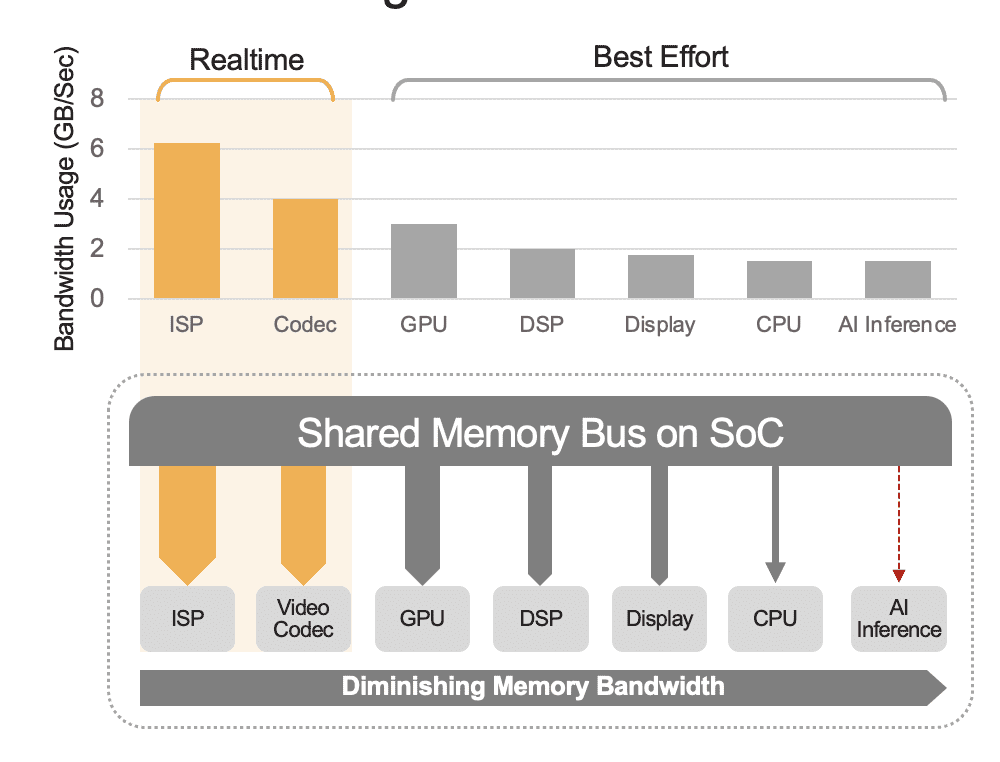
Figuur 2. De gedeelde geheugenbus regelt de prestaties op systeemniveau, hier weergegeven met geschatte waarden. De werkelijke waarden variëren afhankelijk van het gebruiksmodel van uw applicatie en de configuratie van de rekeneenheid van de SoC.
Tot nu toe hebben we de AI-prestaties besproken in termen van frames per seconde en TOPS. Maar een lage latentie is een andere belangrijke vereiste om de real-time responsiviteit van een systeem te garanderen. Bij gaming is een lage latentie bijvoorbeeld van cruciaal belang voor een naadloze en responsieve game-ervaring, vooral bij bewegingsgestuurde games en virtual reality (VR)-systemen. In autonome rijsystemen is een lage latentie essentieel voor real-time objectdetectie, voetgangersherkenning, rijstrookdetectie en verkeersbordherkenning om te voorkomen dat de veiligheid in gevaar komt. Autonome aandrijfsystemen vereisen doorgaans een end-to-end latentie van minder dan 150 ms vanaf detectie tot daadwerkelijke actie. Op dezelfde manier is in de productie een lage latentie essentieel voor realtime detectie van defecten. Anomalieherkenning en robotbegeleiding zijn afhankelijk van videoanalyses met lage latentie om een efficiënte werking te garanderen en productie-uitval te minimaliseren.
Over het algemeen zijn er drie componenten van latentie in een video-analysetoepassing (Afbeelding 3):
- De latentie bij het vastleggen van gegevens is de tijd vanaf het moment dat de camerasensor een videoframe vastlegt, totdat het frame beschikbaar is voor verwerking door het analysesysteem. U kunt deze latentie optimaliseren door een camera te kiezen met een snelle sensor en een processor met lage latentie, optimale framesnelheden te selecteren en efficiënte videocompressieformaten te gebruiken.
- De latentie bij gegevensoverdracht is de tijd die vastgelegde en gecomprimeerde videogegevens nodig hebben om van de camera naar de edge-apparaten of lokale servers te reizen. Dit omvat vertragingen bij de netwerkverwerking die op elk eindpunt optreden.
- De latentie bij gegevensverwerking heeft betrekking op de tijd die de edge-apparaten nodig hebben om videoverwerkingstaken uit te voeren, zoals framedecompressie en analyse-algoritmen (bijvoorbeeld op bewegingsvoorspelling gebaseerde objecttracking, gezichtsherkenning). Zoals eerder opgemerkt is de verwerkingslatentie nog belangrijker voor toepassingen die voor elk videoframe meerdere AI-modellen moeten uitvoeren.
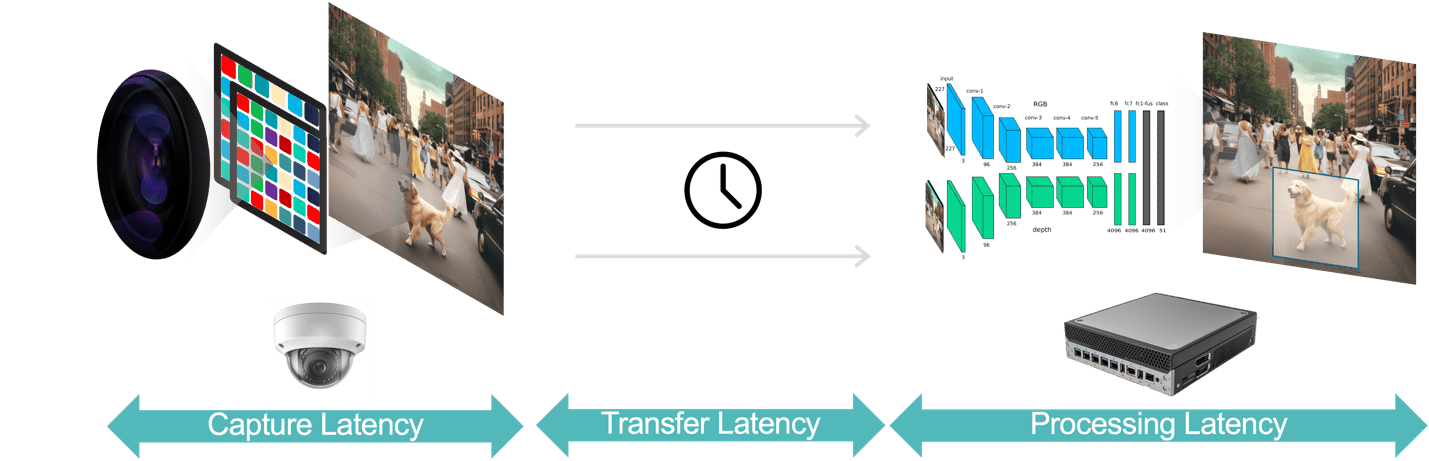
Figuur 3. De pijplijn voor video-analyse bestaat uit het vastleggen, overdragen en verwerken van gegevens.
De latentie bij gegevensverwerking kan worden geoptimaliseerd met behulp van een AI-versneller met een architectuur die is ontworpen om de gegevensbeweging over de chip en tussen rekenkracht en verschillende niveaus van de geheugenhiërarchie te minimaliseren. Om de latentie en de efficiëntie op systeemniveau te verbeteren, moet de architectuur bovendien nul (of bijna nul) schakeltijd tussen modellen ondersteunen, om de multi-modelapplicaties die we eerder hebben besproken beter te ondersteunen. Een andere factor voor zowel verbeterde prestaties als latentie heeft betrekking op algoritmische flexibiliteit. Met andere woorden: sommige architecturen zijn alleen ontworpen voor optimaal gedrag op specifieke AI-modellen, maar met de snel veranderende AI-omgeving verschijnen er, wat elke dag lijkt, nieuwe modellen voor hogere prestaties en betere nauwkeurigheid. Selecteer daarom een edge AI-processor zonder praktische beperkingen op het gebied van modeltopologie, operators en grootte.
Er zijn veel factoren waarmee rekening moet worden gehouden bij het maximaliseren van de prestaties in een edge AI-apparaat, inclusief prestatie- en latentievereisten en systeemoverhead. Een succesvolle strategie zou een externe AI-versneller moeten overwegen om de geheugen- en prestatiebeperkingen in de AI-engine van de SoC te overwinnen.
CH Chee Chee is een ervaren productmarketing- en managementmanager en heeft uitgebreide ervaring in het promoten van producten en oplossingen in de halfgeleiderindustrie, met de nadruk op op visie gebaseerde AI, connectiviteit en video-interfaces voor meerdere markten, waaronder ondernemingen en consumenten. Als ondernemer was Chee medeoprichter van twee start-ups op het gebied van videohalfgeleiders, die werden overgenomen door een openbaar halfgeleiderbedrijf. Chee gaf leiding aan productmarketingteams en werkt graag samen met een klein team dat zich richt op het behalen van geweldige resultaten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- : heeft
- :is
- :niet
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- vermogen
- versneller
- versnellers
- toegang
- toegang
- accommoderen
- bereiken
- nauwkeurigheid
- het bereiken van
- verworven
- Koopt
- over
- Actie
- actieve
- daadwerkelijk
- toe te voegen
- Extra
- aangenomen
- vergevorderd
- Na
- weer
- AI
- AI-motor
- AI-modellen
- algoritmische
- algoritmen
- Alles
- ook
- altijd
- an
- analyse
- analytics
- het analyseren van
- en
- onregelmatigheidsdetectie
- Nog een
- Aanvraag
- toepassingen
- nadering
- architectuur
- ZIJN
- AS
- geassocieerd
- At
- automatiseren
- Automatisering
- autonoom
- autonoom
- beschikbaarheid
- Beschikbaar
- vermijd
- gebaseerde
- basis
- BE
- omdat
- wordt
- geweest
- vaardigheden
- wezen
- criterium
- Betere
- tussen
- zowel
- Box camera's
- dozen
- ingebouwd
- bus
- druk
- maar
- by
- camera
- camera's
- CAN
- mogelijkheden
- bekwaamheid
- vangen
- gevangen
- Het vastleggen
- voorzichtig
- geval
- gevallen
- uitdagen
- veranderende
- spaander
- chips
- het kiezen van
- klasse
- Cloud
- kleur
- komst
- afstand
- concurrerend
- Voltooid
- componenten
- afbreuk te doen aan
- berekening
- computationeel
- Berekenen
- computer
- Computer visie
- Computer Vision-toepassingen
- vertrouwen
- Configuratie
- Connectiviteit
- bijgevolg
- Overwegen
- overweging
- beschouwd
- aangezien
- bestaat uit
- beperkingen
- consument
- bevatten
- bevatte
- doorlopend
- doorlopend
- Camper ombouw
- kon
- CPU
- kritisch
- klant
- gegevens
- gegevensverwerking
- dag
- toegewijd aan
- vertraging
- vertragingen
- leveren
- geleverd
- afhankelijk
- Afhankelijk
- ingezet
- implementaties
- beschreven
- ontworpen
- gedetecteerd
- Opsporing
- Bepalen
- ontwikkelaars
- systemen
- verschil
- direct
- besproken
- Display
- uitvaltijd
- aandrijving
- twee
- dynamisch
- e
- elk
- Vroeger
- gemakkelijk
- rand
- effect
- effectiviteit
- efficiëntie
- doeltreffendheid
- doeltreffend
- beide
- inbedding
- einde
- eind tot eind
- Motor
- Motoren
- verhogen
- verzekeren
- Enterprise
- Geheel
- Ondernemer
- Milieu
- essentieel
- geschat
- schatten
- Zelfs
- Alle
- evoluerende
- voorbeeld
- overtreffen
- uitvoeren
- uitgevoerd
- uitvoerend
- verwachten
- ervaring
- Ervaringen
- uitgebreid
- Uitgebreide ervaring
- extern
- Gezicht
- gezichtsherkenning
- factor
- factoren
- fabriek
- SNELLE
- Kenmerk
- voeden
- veld-
- Figuur
- vingerafdruk
- Voornaam*
- Flexibiliteit
- richt
- gericht
- Voor
- formaat
- FRAME
- oppompen van
- functie
- functionaliteit
- functies
- Bovendien
- toekomst
- met het verkrijgen van
- Spellen
- gaming
- game-ervaring
- Algemeen
- voortbrengen
- gegenereerde
- genereus
- Go
- GPU
- GPU's
- groot
- meer
- Groeiend
- leiding
- Hardware
- Hebben
- Vandaar
- hier
- hiërarchie
- Hoge
- hoger
- gastheer
- HTTPS
- i
- identificeren
- if
- beeld
- Impact
- belangrijk
- opgelegd
- verbeteren
- verbeterd
- in
- Anders
- omvat
- Inclusief
- Laat uw omzet
- meer
- industrieën
- -industrie
- ingewijden
- invoer
- binnen
- inzichten
- geïntegreerde
- Intel
- Interface
- interfaces
- in
- betrekken
- gaat
- ongeacht
- ISP
- IT
- HAAR
- KDnuggets
- labels
- Gebrek
- Rijstrook
- Groot
- Wachttijd
- verlaten
- LED
- minder
- niveaus
- bibliotheken
- als
- beperking
- beperkingen
- Beperkt
- lokaal
- verloren
- Laag
- te verlagen
- beheer
- management
- productie
- veel
- Marketing
- Markten
- Maximaliseren
- maximaliseren
- Mei..
- gemiddelde
- maatregelen
- Maak kennis met
- Geheugen
- vermeld
- macht
- gemiste
- model
- modellen
- module
- Grensverkeer
- meer
- meest
- beweging
- beweging
- meervoudig
- Dan moet je
- veelvoud
- Nabij
- behoeften
- netwerk
- Neural
- neuraal netwerk
- New
- volgende
- geen
- object
- Objectdetectie
- zich voordoen
- of
- vaak
- on
- eens
- EEN
- Slechts
- OpenCV
- operatie
- operationele
- exploitanten
- gekant tegen
- optimale
- optimalisatie
- Optimaliseer
- geoptimaliseerde
- optimaliseren
- or
- Overige
- uit
- uitgang
- over
- totaal
- Overwinnen
- Parallel
- parameters
- vooral
- voor
- uitvoeren
- prestatie
- uitgevoerd
- uitvoerend
- presteert
- pijpleiding
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- punt
- positie
- nabewerking
- PRAKTISCH
- voorspelling
- verwerkt
- verwerking
- Gegevensverwerker
- processors
- Product
- productie
- Producten
- Het bevorderen van
- zorgen voor
- publiek
- reeks
- variërend
- snel
- snel
- tarief
- Tarieven
- Rauw
- ruwe data
- vast
- real-time
- Realiteit
- erkenning
- verminderen
- verwijst
- vereisen
- nodig
- vereiste
- Voorwaarden
- vereist
- Resolutie
- Resources
- responsive
- beperkingen
- resultaat
- Resultaten
- robotica
- Rol
- lopen
- lopend
- loopt
- Veiligheid
- dezelfde
- Schaalbaarheid
- Scale
- schaal ai
- scaling
- scène
- scores
- naadloos
- Tweede
- sectie
- zien
- lijkt
- selecteren
- halfgeleider
- reeks
- Delen
- gedeeld
- Winkelen
- moet
- getoond
- teken
- Signaal
- evenzo
- sinds
- single
- Maat
- Klein
- slim
- oplossing
- Oplossingen
- OPLOSSEN
- Lost op
- sommige
- iets
- Tussenruimte
- specifiek
- start-ups
- Stappen
- shop
- strategieën
- Strategie
- stream
- streams
- geslaagd
- dergelijk
- voldoende
- ondersteuning
- onderdrukking
- toezicht
- system
- Systems
- Nemen
- neemt
- taken
- team
- teams
- Technologies
- Technologie
- termen
- neem contact
- dat
- De
- De toekomst
- hun
- harte
- Er.
- daarom
- Deze
- ze
- dit
- die
- drie
- Door
- doorvoer
- niet de tijd of
- keer
- naar
- Tops
- Totaal
- spoor
- Tracking
- verkeer
- overdracht
- transfers
- Transformeren
- reizen
- waar
- twee
- typisch
- Tenslotte
- niet in staat
- begrijpen
- eenheid
- eenheden
- Gebruik
- usb
- .
- gebruikt
- toepassingen
- gebruik
- doorgaans
- Gebruik makend
- Values
- variëteit
- divers
- Video
- Bekijk
- Virtueel
- Virtuele realiteit
- visie
- vitaal
- vr
- Manier..
- we
- waren
- Wat
- of
- welke
- wijd
- wil
- Met
- zonder
- woorden
- werkzaam
- zou
- X
- Opbrengst
- Yolo
- u
- Your
- zephyrnet
- nul







