
Afbeelding van Adobe Firefly
“We waren met te veel. We hadden toegang tot te veel geld, te veel apparatuur, en beetje bij beetje werden we gek.”
Francis Ford Coppola maakte geen metafoor voor AI-bedrijven die te veel uitgeven en de weg kwijtraken, maar dat had hij wel kunnen zijn. Apocalyps Now was episch, maar ook een lang, moeilijk en duur project om te maken, net als GPT-4. Ik zou willen suggereren dat de ontwikkeling van LLM's heeft geleid tot te veel geld en te veel apparatuur. En een deel van de ‘we hebben zojuist algemene intelligentie uitgevonden’-hype is een beetje krankzinnig. Maar nu is het de beurt aan open source-gemeenschappen om te doen waar ze goed in zijn: het leveren van gratis concurrerende software met veel minder geld en apparatuur.
OpenAI heeft meer dan $11 miljard aan financiering overgenomen en naar schatting kost GPT-3.5 $5-$6 miljoen per training. We weten heel weinig over GPT-4 omdat OpenAI dat niet vertelt, maar ik denk dat het veilig is om aan te nemen dat het niet kleiner is dan GPT-3.5. Er is momenteel een wereldwijd GPU-tekort en – voor de verandering – niet vanwege de nieuwste cryptomunt. Start-ups op het gebied van generatieve AI krijgen $100 miljoen+ Series A-rondes tegen enorme waarderingen terwijl ze geen enkel IP-adres bezitten voor de LLM die ze gebruiken om hun product aan te drijven. De LLM-bandwagon staat in een hogere versnelling en het geld stroomt.
It had looked like the die was cast: only deep-pocketed companies like Microsoft/OpenAI, Amazon, and Google could afford to train hundred-billion parameter models. Bigger models were assumed to be better models. GPT-3 got something wrong? Just wait until there's a bigger version and it’ll all be fine! Smaller companies looking to compete had to raise far more capital or be left building commodity integrations in the ChatGPT marketplace. Academia, with even more constrained research budgets, was relegated to the sidelines.
Gelukkig beschouwden een stel slimme mensen en open source-projecten dit eerder als een uitdaging dan als een beperking. Onderzoekers van Stanford hebben Alpaca uitgebracht, een model met 7 miljard parameters waarvan de prestaties dicht in de buurt komen van het 3.5 miljard parametermodel van GPT-175. Bij gebrek aan de middelen om een trainingsset te bouwen van de omvang die door OpenAI wordt gebruikt, kozen ze er slim voor om een getrainde open source LLM, LLaMA, te nemen en deze in plaats daarvan te verfijnen op een reeks GPT-3.5-prompts en -uitvoer. In wezen heeft het model geleerd wat GPT-3.5 doet, wat een zeer effectieve strategie blijkt te zijn om het gedrag ervan te repliceren.
Alpaca heeft alleen een licentie voor niet-commercieel gebruik in zowel code als data, aangezien het gebruik maakt van het open source, niet-commerciële LLaMA-model, en OpenAI staat expliciet elk gebruik van zijn API's toe om concurrerende producten te creëren. Dat schept wel het verleidelijke vooruitzicht om een andere open source LLM te verfijnen op basis van de aanwijzingen en de output van Alpaca… waardoor een derde GPT-3.5-achtig model ontstaat met verschillende licentiemogelijkheden.
Er is hier nog een ironische laag, namelijk dat alle grote LLM's zijn opgeleid in auteursrechtelijk beschermde tekst en afbeeldingen die beschikbaar zijn op internet en dat ze geen cent hebben betaald aan de rechthebbenden. De bedrijven claimen de vrijstelling van ‘fair use’ onder de Amerikaanse auteursrechtwetgeving met het argument dat het gebruik ‘transformatief’ is. Maar als het gaat om de output van de modellen die ze bouwen met gratis data, willen ze echt niet dat iemand hetzelfde met hen doet. Ik verwacht dat dit zal veranderen naarmate de rechthebbenden verstandiger worden, en dat dit op een gegeven moment voor de rechtbank kan belanden.
Dit staat los van het punt dat wordt aangehaald door auteurs van open source met restrictieve licenties die, voor generatieve AI for Code-producten zoals CoPilot, bezwaar maken tegen het gebruik van hun code voor training, op grond van het feit dat de licentie niet wordt gevolgd. Het probleem voor individuele open-sourceauteurs is dat zij hun reputatie moeten aantonen – inhoudelijk kopiëren – en dat zij schade hebben geleden. En omdat de modellen het moeilijk maken om de uitvoercode aan de invoer te koppelen (de regels broncode van de auteur) en er geen economisch verlies is (het zou gratis moeten zijn), is het veel moeilijker om iets te beargumenteren. Dit in tegenstelling tot makers met winstoogmerk (bijvoorbeeld fotografen) wier hele bedrijfsmodel bestaat uit het licentiëren/verkopen van hun werk, en die worden vertegenwoordigd door aggregators als Getty Images die inhoudelijke kopieën kunnen laten zien.
Een ander interessant aspect van LLaMA is dat het uit Meta komt. Het werd oorspronkelijk alleen vrijgegeven aan onderzoekers en vervolgens via BitTorrent naar de wereld gelekt. Meta bevindt zich in een fundamenteel andere branche dan OpenAI, Microsoft, Google en Amazon, omdat het niet probeert u clouddiensten of software te verkopen, en dus heel andere prikkels heeft. Het bedrijf heeft zijn computerontwerpen in het verleden open source gemaakt (OpenCompute) en heeft de gemeenschap daarin zien verbeteren; het begrijpt de waarde van open source.
Meta zou een van de belangrijkste open-source AI-bijdragers kunnen zijn. Het beschikt niet alleen over enorme middelen, maar het heeft er ook baat bij als er sprake is van een proliferatie van geweldige generatieve AI-technologie: er zal meer inhoud zijn waarmee geld kan worden verdiend op sociale media. Meta heeft drie andere open-source AI-modellen uitgebracht: ImageBind (multidimensionale gegevensindexering), DINOv2 (computervisie) en Segment Anything. Deze laatste identificeert unieke objecten in afbeeldingen en wordt vrijgegeven onder de zeer tolerante Apache-licentie.
Ten slotte hadden we ook het vermeende lekken van een intern Google-document “We Have No Moat, and Noch Does OpenAI”, waarin een vaag beeld wordt gegeven van gesloten modellen versus de innovatie van gemeenschappen die veel kleinere, goedkopere modellen produceren die bijna of beter presteren dan hun closed source-tegenhangers. Ik zeg naar verluidt omdat er geen manier is om de bron van het artikel te verifiëren als intern van Google. Het bevat echter wel deze overtuigende grafiek:
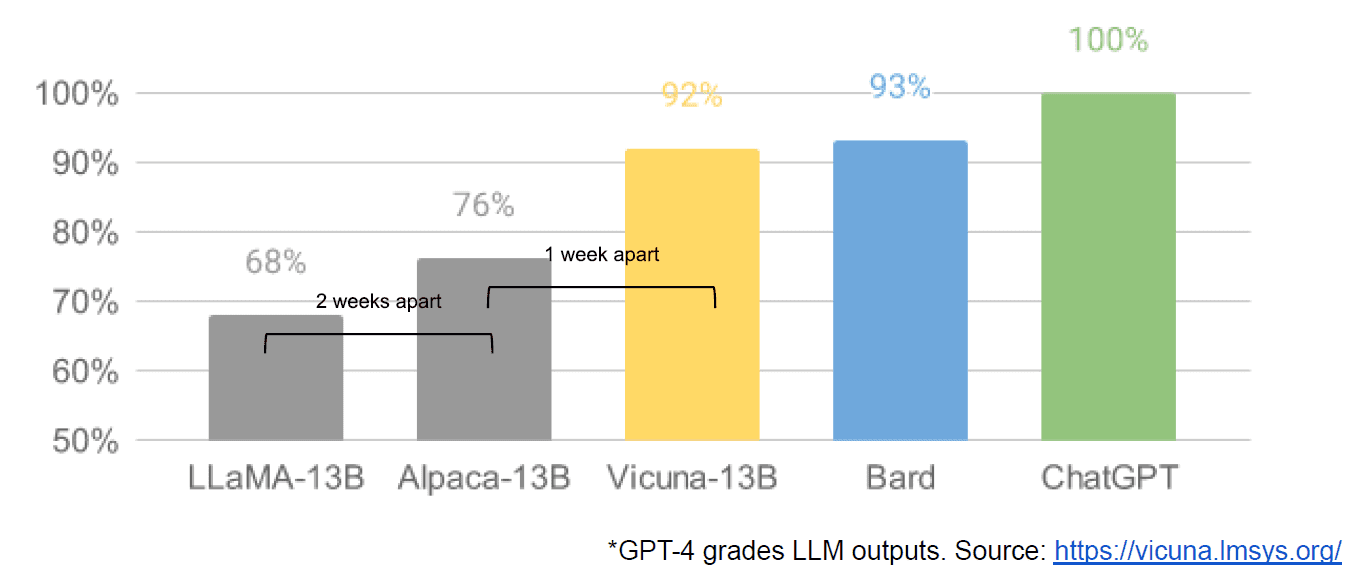
Voor alle duidelijkheid: de verticale as is de beoordeling van de LLM-uitvoer door GPT-4.
Stable Diffusion, dat afbeeldingen uit tekst synthetiseert, is een ander voorbeeld van waar open source generatieve AI sneller vooruitgang heeft kunnen boeken dan propriëtaire modellen. Een recente versie van dat project (ControlNet) heeft het zodanig verbeterd dat het de mogelijkheden van Dall-E2 heeft overtroffen. Dit is het resultaat van heel veel sleutelen over de hele wereld, wat heeft geresulteerd in een tempo van vooruitgang dat voor geen enkele instelling te evenaren is. Sommige van die knutselaars hebben ontdekt hoe ze Stable Diffusion sneller kunnen trainen en laten draaien op goedkopere hardware, waardoor kortere iteratiecycli voor meer mensen mogelijk worden.
En zo zijn we rond. Het feit dat we niet te veel geld en te veel apparatuur hebben, heeft een hele gemeenschap van gewone mensen tot een sluw niveau van innovatie geïnspireerd. Wat een tijd om AI-ontwikkelaar te zijn.
Mathew Loge is CEO van Diffblue, een AI For Code-startup. Hij heeft meer dan 25 jaar uiteenlopende ervaring in productleiderschap bij bedrijven als Anaconda en VMware. Lodge is momenteel lid van het bestuur van het Good Law Project en is vice-voorzitter van de Board of Trustees van de Royal Photographic Society.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- : heeft
- :is
- :niet
- :waar
- $UP
- 9
- a
- in staat
- Over
- Academie
- toegang
- adobe
- bevorderen
- aggregators
- AI
- Alles
- vermeende
- naar verluidt
- ook
- Amazone
- an
- en
- Nog een
- elke
- iedereen
- iets
- apache
- APIs
- ZIJN
- argument
- dit artikel
- AS
- uitgegaan van
- At
- auteur
- auteurs
- Beschikbaar
- As
- BE
- omdat
- geweest
- wezen
- betekent
- BEST
- Betere
- groter
- BitTorrent
- boord
- zowel
- Begrotingen
- bouw
- Gebouw
- Bos
- bedrijfsdeskundigen
- bedrijfsmodel
- maar
- by
- kwam
- CAN
- mogelijkheden
- hoofdstad
- geval
- ceo
- Voorzitter
- uitdagen
- verandering
- ChatGPT
- goedkoper
- koos
- Circle
- aanspraak maken op
- duidelijk
- Sluiten
- CLOSED
- Cloud
- cloud-diensten
- code
- hoe
- komt
- koopwaar
- Gemeenschappen
- gemeenschap
- Bedrijven
- dwingende
- concurreren
- concurrerende
- Berekenen
- computer
- Computer visie
- content
- bijdragers
- kopiëren
- auteursrecht
- Kosten
- kon
- Rechtbank
- en je merk te creëren
- Wij creëren
- scheppers
- cryptomunt
- Op dit moment
- cycli
- gegevens
- het leveren van
- plaatsvervanger
- ontwerpen
- Ontwikkelaar
- Ontwikkeling
- De
- anders
- moeilijk
- Verspreiding
- onderscheiden
- diversen
- do
- document
- doet
- Dont
- e
- Economisch
- effectief
- waardoor
- einde
- Geheel
- EPIC
- uitrusting
- in wezen
- geschat
- Zelfs
- voorbeeld
- verwachten
- duur
- ervaring
- ver
- sneller
- bedacht
- vloeiende
- gevolgd
- Voor
- doorwaadbare plaats
- Gratis
- oppompen van
- vol
- fundamenteel
- financiering
- Kookgerei
- Algemeen
- generatief
- generatieve AI
- goed
- Kopen Google Reviews
- GPU
- diagram
- groot
- HAD
- Hard
- Hardware
- Hebben
- met
- he
- hier
- Hoge
- zeer
- houders
- Hoe
- How To
- Echter
- HTTPS
- reusachtig
- Hype
- i
- identificeert
- if
- afbeeldingen
- belangrijk
- verbeteren
- verbeterd
- in
- Incentives
- individueel
- Innovatie
- invoer
- KRANKZINNIG
- geinspireerd
- verkrijgen in plaats daarvan
- Instelling
- integraties
- interessant
- intern
- Internet
- Uitgevonden
- IP
- ironie
- IT
- herhaling
- HAAR
- voor slechts
- KDnuggets
- blijven
- landing
- laatste
- Wet
- lagen
- Leadership
- geleerd
- links
- minder
- Niveau
- Vergunning
- Erkend
- Licenties
- als
- lijnen
- LINK
- Elke kleine stap levert grote resultaten op!
- Lama
- lang
- keek
- op zoek
- verliezen
- uit
- lot
- groot
- maken
- maken
- veel
- markt
- massief
- Match
- Mei..
- Media
- meta
- Microsoft
- model
- modellen
- gelde
- geld
- meer
- meest
- veel
- Noodzaak
- Noch
- geen
- niet commercieel
- nu
- object
- objecten
- of
- on
- EEN
- Slechts
- open
- open source
- open source projecten
- OpenAI
- or
- gewoon
- oorspronkelijk
- Overige
- uit
- uitgang
- over
- het te bezitten.
- Tempo
- parameter
- verleden
- Betaal
- Mensen
- uitvoeren
- prestatie
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- mogelijkheden
- energie
- probleem
- Product
- Producten
- project
- projecten
- gepatenteerd
- vooruitzicht
- verhogen
- opgebracht
- liever
- werkelijk
- recent
- uitgebracht
- vertegenwoordigd
- onderzoek
- onderzoekers
- Resources
- beperking
- verkregen
- rechten
- rondes
- koninklijk
- lopen
- s
- veilig
- dezelfde
- ervaren
- gezien
- segment
- verkopen
- apart
- -Series
- Serie A
- bedient
- Diensten
- reeks
- schaarste
- tonen
- sinds
- single
- Maat
- kleinere
- slim
- So
- Social
- social media
- Maatschappij
- Software
- sommige
- iets
- bron
- broncode
- besteden
- stabiel
- stanford
- start-ups
- startup
- Strategie
- dergelijk
- stel
- vermeend
- overtroffen
- Nemen
- ingenomen
- neemt
- Technologie
- neem contact
- dat
- De
- De Bron
- de wereld
- hun
- Ze
- harte
- Er.
- ze
- ding
- denken
- Derde
- dit
- die
- drie
- niet de tijd of
- naar
- ook
- nam
- Trainen
- getraind
- Trainingen
- BEURT
- wordt
- voor
- begrijpt
- unieke
- anders
- tot
- us
- .
- gebruikt
- toepassingen
- gebruik
- taxaties
- waarde
- controleren
- versie
- verticaal
- zeer
- via
- Bekijk
- visie
- vmware
- vs
- wachten
- willen
- was
- Manier..
- we
- gegaan
- waren
- Wat
- wanneer
- welke
- WIE
- geheel
- waarvan
- wil
- WISE
- Met
- Mijn werk
- wereld
- Verkeerd
- u
- zephyrnet









