Apache Hudi is een open-tabelformaat dat database- en datawarehouse-mogelijkheden naar datameren brengt. Apache Hudi helpt data-ingenieurs bij het beheren van complexe uitdagingen, zoals het beheren van voortdurend evoluerende datasets met transacties terwijl de queryprestaties behouden blijven. Data-ingenieurs gebruiken Apache Hudi voor het streamen van werklasten en voor het creëren van efficiënte incrementele datapijplijnen. Hudi biedt tafels, transacties, efficiënte ups en verwijderingen, geavanceerde indexen, streaming opnameservices, data clustering en verdichting optimalisaties, en gelijktijdigheidscontrole, terwijl uw gegevens in open source-bestandsindelingen worden bewaard. De geavanceerde prestatie-optimalisaties van Hudi maken analytische workloads sneller met alle populaire query-engines, waaronder Apache Spark, Presto, Trino, Hive, enzovoort.
Veel AWS-klanten adopteerden Apache Hudi op hun datameren die bovenop Amazon S3 waren gebouwd AWS lijm, een serverloze data-integratieservice die het eenvoudiger maakt om gegevens uit meerdere bronnen te ontdekken, voor te bereiden, te verplaatsen en te integreren voor analyse, machine learning (ML) en applicatie-ontwikkeling. AWS lijmcrawler is een onderdeel van AWS Glue, waarmee u automatisch tabelmetagegevens van gegevensinhoud kunt maken zonder dat u de metagegevens handmatig hoeft te definiëren.
AWS Glue-crawlers ondersteunen nu Apache Hudi-tabellen, wat de adoptie van AWS-lijmgegevenscatalogus als catalogus voor Hudi-tafels. Een typisch gebruiksscenario is het registreren van Hudi-tabellen, die geen catalogustabeldefinitie hebben. Een ander typisch gebruiksscenario is migratie vanuit andere Hudi-catalogi, zoals Hive-metastore. Wanneer u migreert vanuit andere Hudi-catalogi, kunt u een AWS Glue-crawler maken en plannen en een of meer Amazon S3-paden opgeven waar de Hudi-tabelbestanden zich bevinden. U heeft de mogelijkheid om de maximale diepte op te geven van Amazon S3-paden die de AWS Glue-crawler kan doorlopen. Bij elke run extraheren AWS Glue-crawlers schema- en partitie-informatie en updaten ze de AWS Glue Data Catalog met de schema- en partitiewijzigingen. AWS Glue-crawlers updaten de nieuwste metadatabestandslocatie in de AWS Glue Data Catalog die AWS-analyse-engines rechtstreeks kunnen gebruiken.
Met deze lancering kunt u een AWS Glue-crawler maken en plannen om Hudi-tabellen te registreren in de AWS Glue Data Catalog. U kunt vervolgens een of meerdere Amazon S3-paden opgeven waar de Hudi-tabellen zich bevinden. Je hebt de mogelijkheid om de maximale diepte op te geven van Amazon S3-paden die crawlers kunnen doorkruisen. Bij elke crawler inspecteert de crawler elk van de S3-paden en catalogiseert de schema-informatie, zoals nieuwe tabellen, verwijderingen en updates van schema's in de AWS Glue Data Catalog. Crawlers inspecteren partitie-informatie en voegen nieuw toegevoegde partities toe aan AWS Glue Data Catalog. Crawlers updaten ook de nieuwste metadatabestandslocatie in de AWS Glue Data Catalog die AWS-analyse-engines rechtstreeks kunnen gebruiken.
Dit bericht laat zien hoe deze nieuwe mogelijkheid om Hudi-tabellen te crawlen werkt.
Hoe AWS Glue-crawler werkt met Hudi-tabellen
Hudi-tabellen hebben twee categorieën, met specifieke implicaties voor elk:
- Kopiëren bij schrijven (CoW) – Gegevens worden opgeslagen in een kolomvormig formaat (Parquet) en elke update creëert tijdens het schrijven een nieuwe versie van bestanden.
- Samenvoegen bij lezen (MoR) – Gegevens worden opgeslagen met behulp van een combinatie van kolomvormige (Parquet) en rijgebaseerde (Avro) formaten. Updates worden op rijbasis vastgelegd
deltabestanden en worden indien nodig gecomprimeerd om nieuwe versies van de kolombestanden te maken.
Met CoW-gegevenssets wordt elke keer dat een record wordt bijgewerkt, het bestand dat het record bevat, herschreven met de bijgewerkte waarden. Met een MoR-dataset schrijft Hudi elke keer dat er een update is, alleen de rij voor het gewijzigde record. MoR is beter geschikt voor werklasten met veel schrijf- of wijzigingsinspanningen en minder leesbewerkingen. CoW is beter geschikt voor zware leesbelastingen op gegevens die minder vaak veranderen.
Hudi biedt drie soorten zoekopdrachten voor toegang tot de gegevens:
- Snapshot-query's – Query's die de laatste momentopname van de tabel zien vanaf een bepaalde commit- of verdichtingsactie. Voor MoR-tabellen geven momentopnamequery's de meest recente status van de tabel weer door de basis- en deltabestanden van het nieuwste bestandssegment op het moment van de query samen te voegen.
- Incrementele zoekopdrachten – Query's zien alleen nieuwe gegevens die naar de tabel zijn geschreven, sinds een bepaalde commit of compactie. Dit zorgt effectief voor veranderingsstromen om incrementele datapijplijnen mogelijk te maken.
- Geoptimaliseerde zoekopdrachten lezen – Voor MoR-tabellen zien query's de nieuwste gegevens gecomprimeerd. Voor CoW-tabellen zien query's de meest recente vastgelegde gegevens.
Voor copy-on-write-tabellen maken crawlers een enkele tabel in de AWS Glue Data Catalog met de ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Voor merge-on-read-tabellen maken crawlers twee tabellen in AWS Glue Data Catalog voor dezelfde tabellocatie:
- Een tabel met achtervoegsel
_ro, dat gebruikmaakt van de ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Een tabel met achtervoegsel
_rt, die de RealTime Serde gebruikt, waardoor momentopnamequery's mogelijk zijn:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Tijdens elke crawl doen crawlers voor elk opgegeven Hudi-pad een Amazon S3-lijst API-aanroep, waarbij wordt gefilterd op basis van de .hoodie mappen en zoek het meest recente metadatabestand onder de metadatamap van de Hudi-tabel.
Kruip door een Hudi CoW-tafel met de AWS Glue-crawler
Laten we in dit gedeelte bekijken hoe u een Hudi CoW kunt crawlen met behulp van AWS Glue-crawlers.
Voorwaarden
Dit zijn de vereisten voor deze zelfstudie:
- Installeren en configureren AWS-opdrachtregelinterface (AWS CLI).
- Maak je S3-bucket als je die niet hebt.
- Creëer uw IAM-rol voor AWS Glue als je het niet hebt. Jij hebt nodig
s3:GetObjectFors3://your_s3_bucket/data/sample_hudi_cow_table/. - Voer de volgende opdracht uit om de voorbeeld-Hudi-tabel naar uw S3-bucket te kopiëren. (Vervangen
your_s3_bucketmet uw S3-bucketnaam.)
Deze instructie begeleidt u bij het kopiëren van voorbeeldgegevens, maar u kunt eenvoudig Hudi-tabellen maken met AWS Glue. Leer meer binnen Introductie van native ondersteuning voor Apache Hudi, Delta Lake en Apache Iceberg op AWS Glue voor Apache Spark, deel 2: AWS Glue Studio Visual Editor.
Maak een Hudi-crawler
In deze instructie maakt u de crawler via de console. Voer de volgende stappen uit om een Hudi-crawler te maken:
- Kies op de AWS Glue-console: crawlers.
- Kies Creëren van crawler.
- Voor Naam, ga naar binnen
hudi_cow_crawler. Kiezen Volgende. - Onder Configuratie van gegevensbron, kiezen Gegevensbron toevoegen.
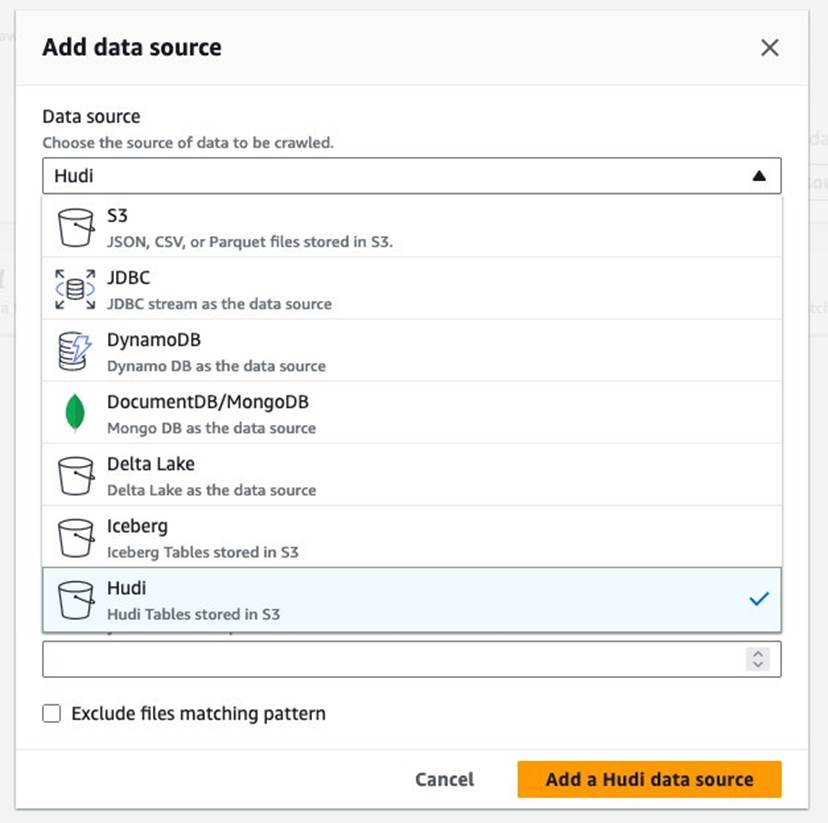
- Voor Databron, kiezen Hoed.
- Voor Voeg Hudi-tabelpaden toe, ga naar binnen
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Vervangenyour_s3_bucketmet uw S3-bucketnaam.) - Kies Hudi-gegevensbron toevoegen.
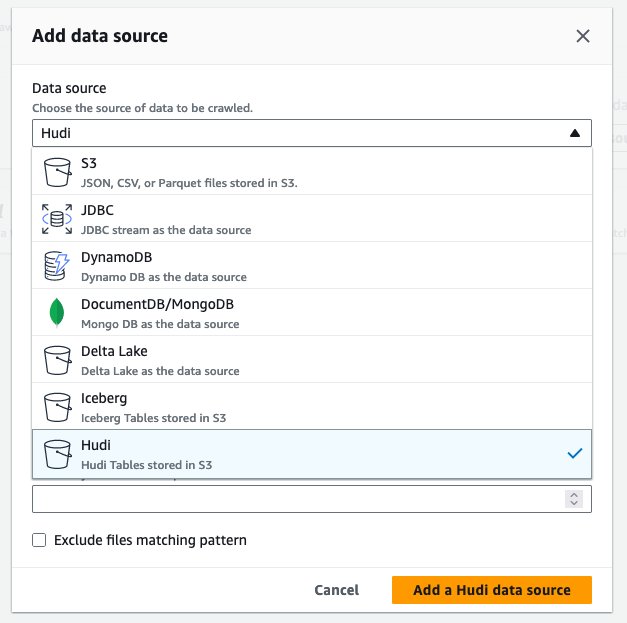
- Kies Volgende.
- Voor Bestaande IAM-rol, kies uw IAM-rol en kies vervolgens Volgende.
- Voor Doeldatabase, kiezen Voeg database toe, dan de Voeg database toe dialoogvenster verschijnt. Voor Database naam, ga naar binnen
hudi_crawler_blog, kies dan creëren. Kiezen Volgende. - Kies Creëren van crawler.
Nu is er met succes een nieuwe Hudi-crawler gemaakt. De crawler kan worden geactiveerd om via de console of via de SDK of AWS CLI te worden uitgevoerd met behulp van de StartCrawl API. Het kan ook via de console worden gepland om de crawlers op specifieke tijden te activeren. Voer in deze instructie de crawler door de console.
- Kies Voer de crawler uit.
- Wacht tot de crawler is voltooid.
Nadat de crawler is uitgevoerd, kunt u de Hudi-tabeldefinitie zien in de AWS Glue-console:
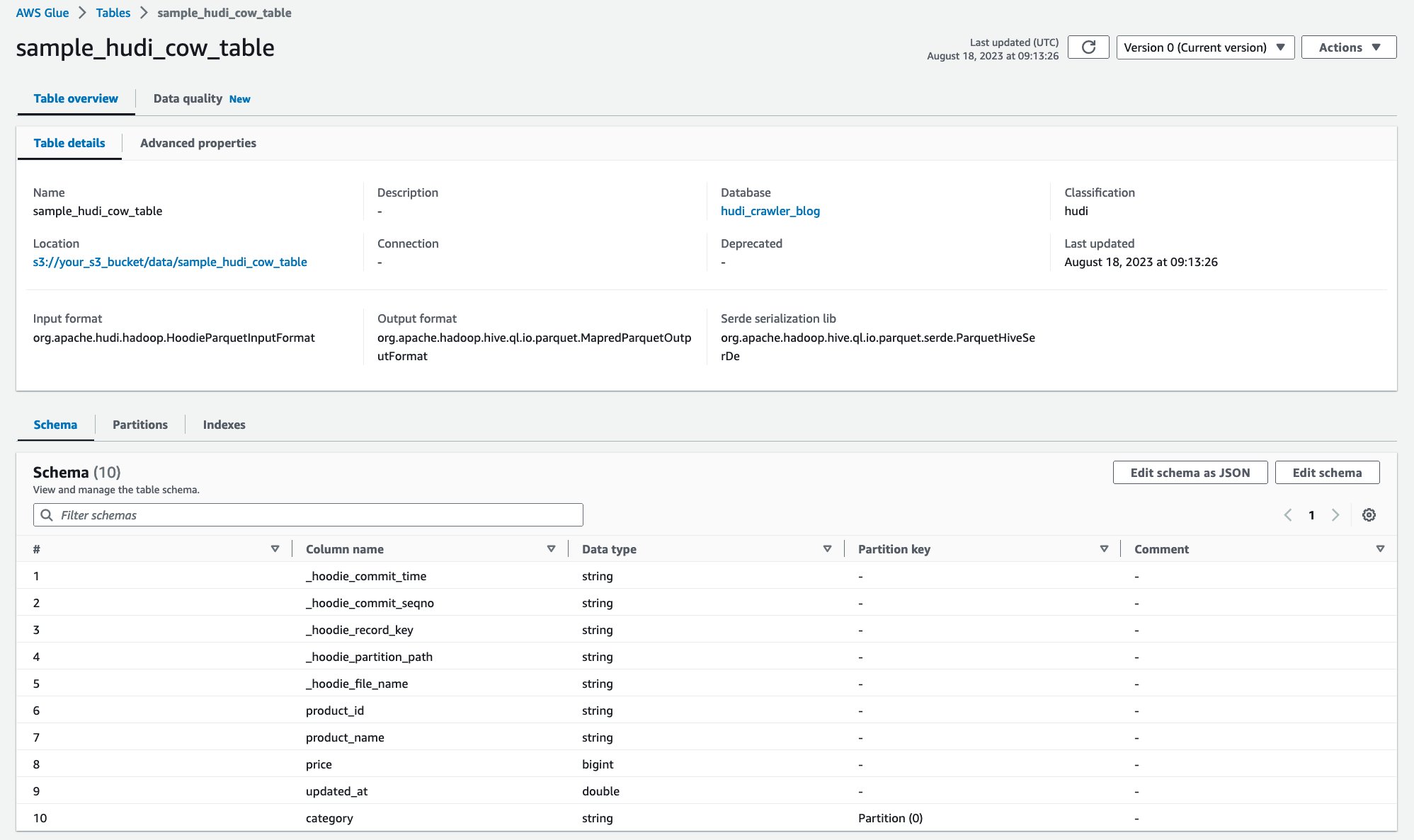
Je hebt met succes de Hudi CoR-tabel met gegevens op Amazon S3 gecrawld en een AWS Glue Data Catalog-tabel gemaakt waarin het schema is ingevuld. Nadat u de tabeldefinitie in AWS Glue Data Catalog hebt gemaakt, kunnen AWS-analyseservices zoals Amazon Athena de Hudi-tabel opvragen.
Voer de volgende stappen uit om zoekopdrachten op Athena te starten:
- Open de Amazon Athena-console.
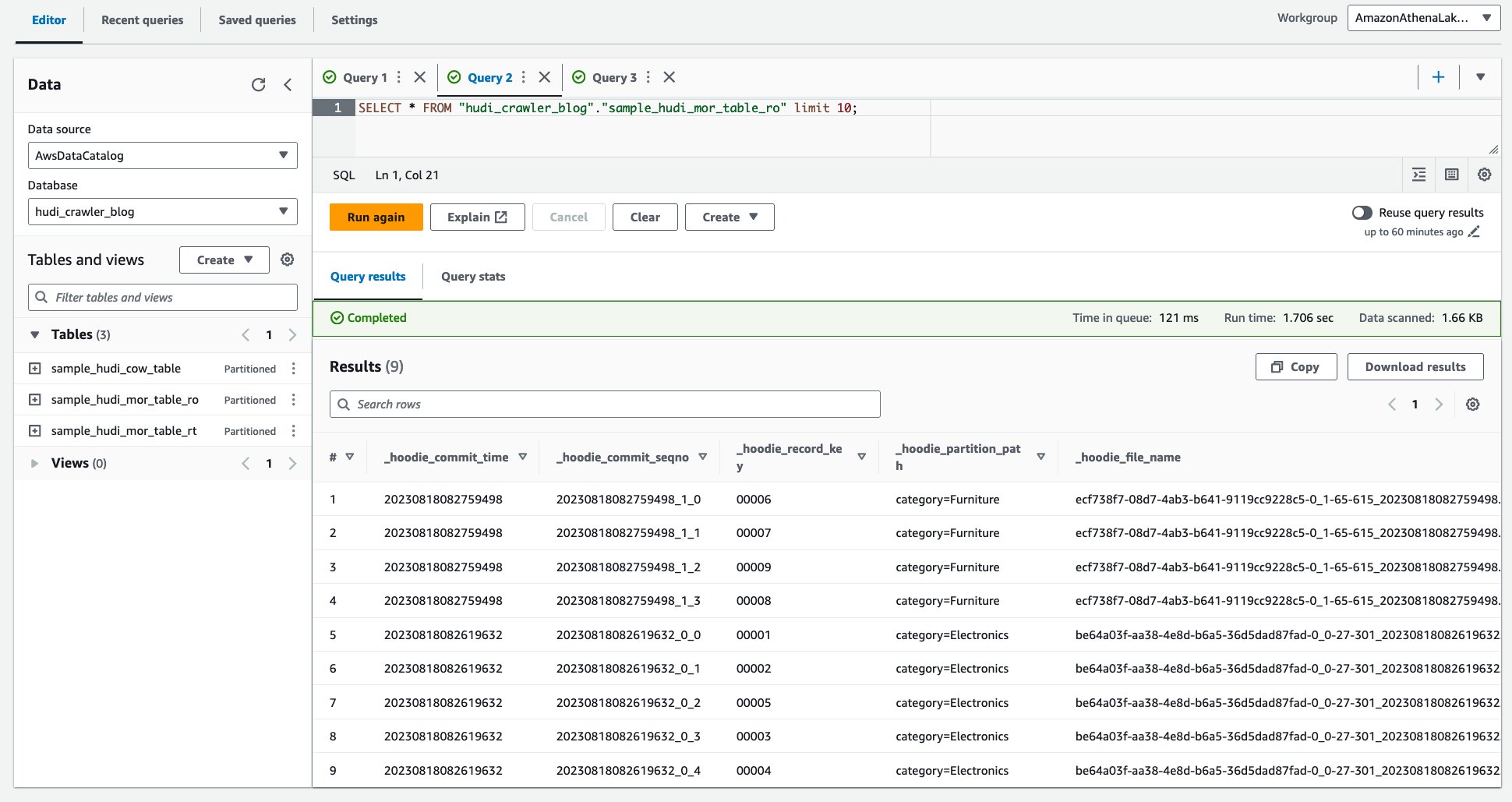
- Voer de volgende query uit.
De volgende schermafbeelding toont onze uitvoer:
Crawl een Hudi MoR-tabel met behulp van de AWS Glue-crawler met AWS Lake Formation-gegevensrechten
Laten we in dit gedeelte bekijken hoe u een Hudi MoR-tabel kunt crawlen met AWS Glue. Deze keer gebruikt u de gegevenstoestemming van AWS Lake Formation voor het crawlen van Amazon S3-gegevensbronnen in plaats van de IAM- en Amazon S3-toestemming. Dit is optioneel, maar het vereenvoudigt de machtigingsconfiguraties wanneer uw datameer wordt beheerd door AWS Lake Formation-machtigingen.
Voorwaarden
Dit zijn de vereisten voor deze zelfstudie:
- Installeren en configureren AWS-opdrachtregelinterface (AWS CLI).
- Maak je S3-bucket als je die niet hebt.
- Creëer uw IAM-rol voor AWS Glue als je het niet hebt. Jij hebt nodig
lakeformation:GetDataAccess. Maar dat is niet nodigs3:GetObjectFors3://your_s3_bucket/data/sample_hudi_mor_table/omdat we de gegevenstoestemming van Lake Formation gebruiken om toegang te krijgen tot de bestanden. - Voer de volgende opdracht uit om de voorbeeld-Hudi-tabel naar uw S3-bucket te kopiëren. (Vervangen
your_s3_bucketmet uw S3-bucketnaam.)
Voer naast de verwerkingsstappen de volgende stappen uit om de AWS Glue Data Catalog-instellingen bij te werken om Lake Formation-machtigingen te gebruiken om catalogusbronnen te beheren in plaats van op IAM gebaseerde toegangscontrole:
- Meld u aan bij de Lake Formation-console als data lake-beheerder.
- Als dit de eerste keer is dat u toegang krijgt tot de Lake Formation-console, voeg uzelf toe als data lake-beheerder.
- Onder Administratie, kiezen Instellingen voor gegevenscatalogus.
- Voor Standaardmachtigingen voor nieuw gemaakte databases en tabellen, deselecteren Gebruik alleen IAM-toegangscontrole voor nieuwe databases en Gebruik alleen IAM-toegangscontrole voor nieuwe tabellen in nieuwe databases.
- Voor Versie-instelling voor meerdere accounts, kiezen versie 3.
- Kies Bespaar.
De volgende stap is het registreren van uw S3-bucket op de data lake-locaties van Lake Formation:
- Kies op de Lake Formation-console Data Lake-locatiesen kies Registreer locatie.
- Voor Amazon S3-pad, ga naar binnen
s3://your_s3_bucket/. (Vervangenyour_s3_bucketmet uw S3-bucketnaam.) - Kies Registreer locatie.
Verleen vervolgens Glue-crawlerroltoegang tot de gegevenslocatie, zodat de crawler Lake Formation-toestemming kan gebruiken om toegang te krijgen tot de gegevens en tabellen op de locatie te maken:
- Kies op de Lake Formation-console Gegevenslocaties En kies Grant.
- Voor IAM-gebruikers en -rollen, selecteert u de IAM-rol die u voor de crawler heeft gebruikt.
- Voor Opslaglocatie, ga naar binnen
s3://your_s3_bucket/data/. (Vervangenyour_s3_bucketmet uw S3-bucketnaam.) - Kies Grant.
Verleen vervolgens de crawlerrol om tabellen onder de database te maken hudi_crawler_blog:
- Kies op de Lake Formation-console Data lake-machtigingen.
- Kies Grant.
- Voor opdrachtgevers, kiezen IAM-gebruikers en -rollenen kies de crawlerrol.
- Voor LF-tags of catalogusbronnen, kiezen Benoemde gegevenscatalogusbronnen.
- Voor Database, kies de database
hudi_crawler_blog. - Onder Databasemachtigingenselecteer Maak een tabel.
- Kies Grant.
Maak een Hudi-crawler met Lake Formation-gegevensmachtigingen
Voer de volgende stappen uit om een Hudi-crawler te maken:
- Kies op de AWS Glue-console: crawlers.
- Kies Creëren van crawler.
- Voor Naam, ga naar binnen
hudi_mor_crawler. Kiezen Volgende. - Onder Configuratie van gegevensbron, kiezen Gegevensbron toevoegen.
- Voor Databron, kiezen Hoed.
- Voor Voeg Hudi-tabelpaden toe, ga naar binnen
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Vervangenyour_s3_bucketmet uw S3-bucketnaam.) - Kies Hudi-gegevensbron toevoegen.
- Kies Volgende.
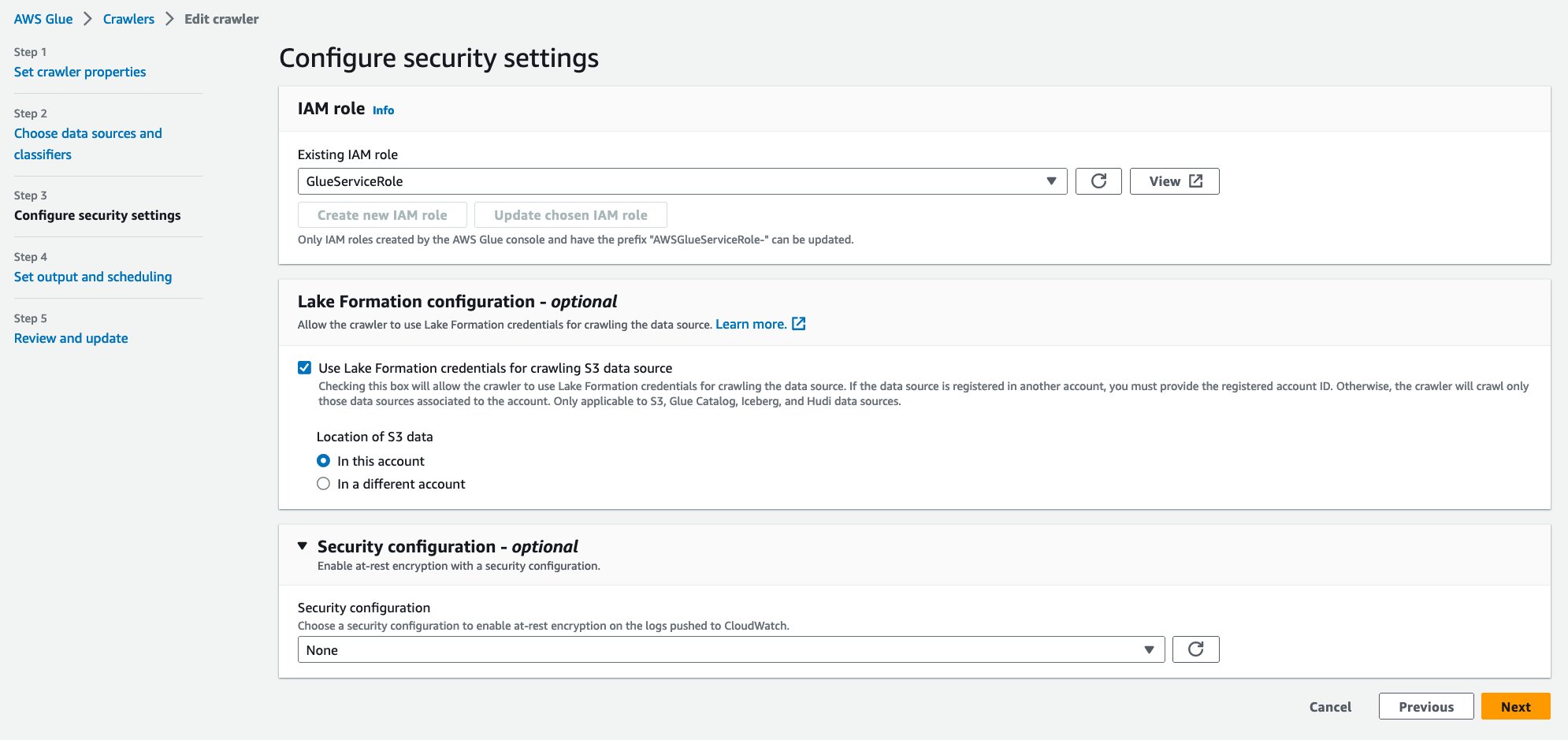
- Voor Bestaande IAM-rol, kies uw IAM-rol.
- Onder Lake Formation-configuratie – optioneelselecteer Gebruik Lake Formation-referenties voor het crawlen van de S3-gegevensbron.
- Kies Volgende.
- Voor Doeldatabase, kiezen
hudi_crawler_blog. Kiezen Volgende. - Kies Creëren van crawler.
Nu is er met succes een nieuwe Hudi-crawler gemaakt. De crawler gebruikt Lake Formation-inloggegevens voor het crawlen van Amazon S3-bestanden. Laten we de nieuwe crawler uitvoeren:
- Kies Voer de crawler uit.
- Wacht tot de crawler is voltooid.
Nadat de crawler is uitgevoerd, kunt u twee tabellen met de Hudi-tabeldefinitie zien in de AWS Glue-console:
sample_hudi_mor_table_ro(lees geoptimaliseerde tabel)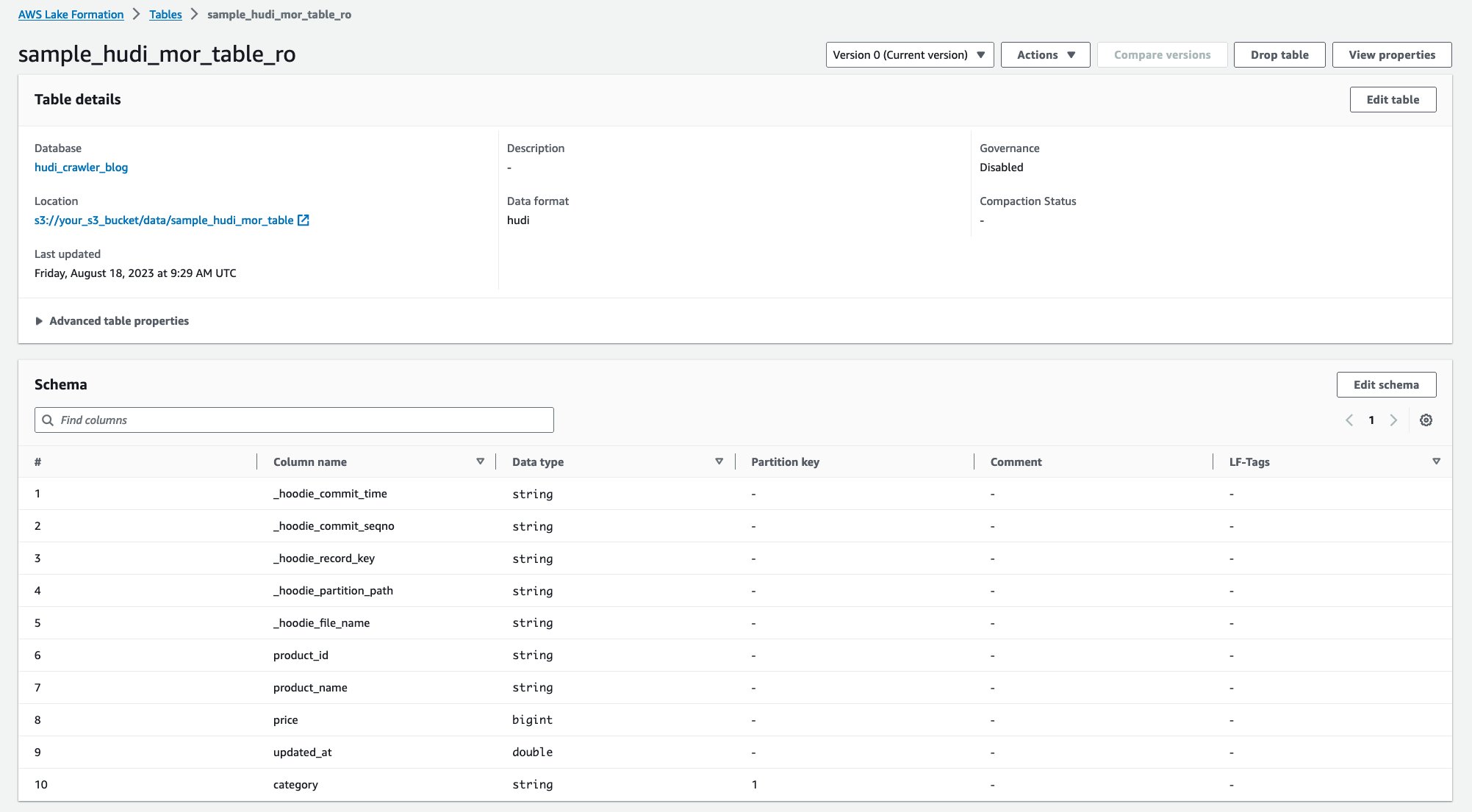
sample_hudi_mor_table_rt(real-time tabel)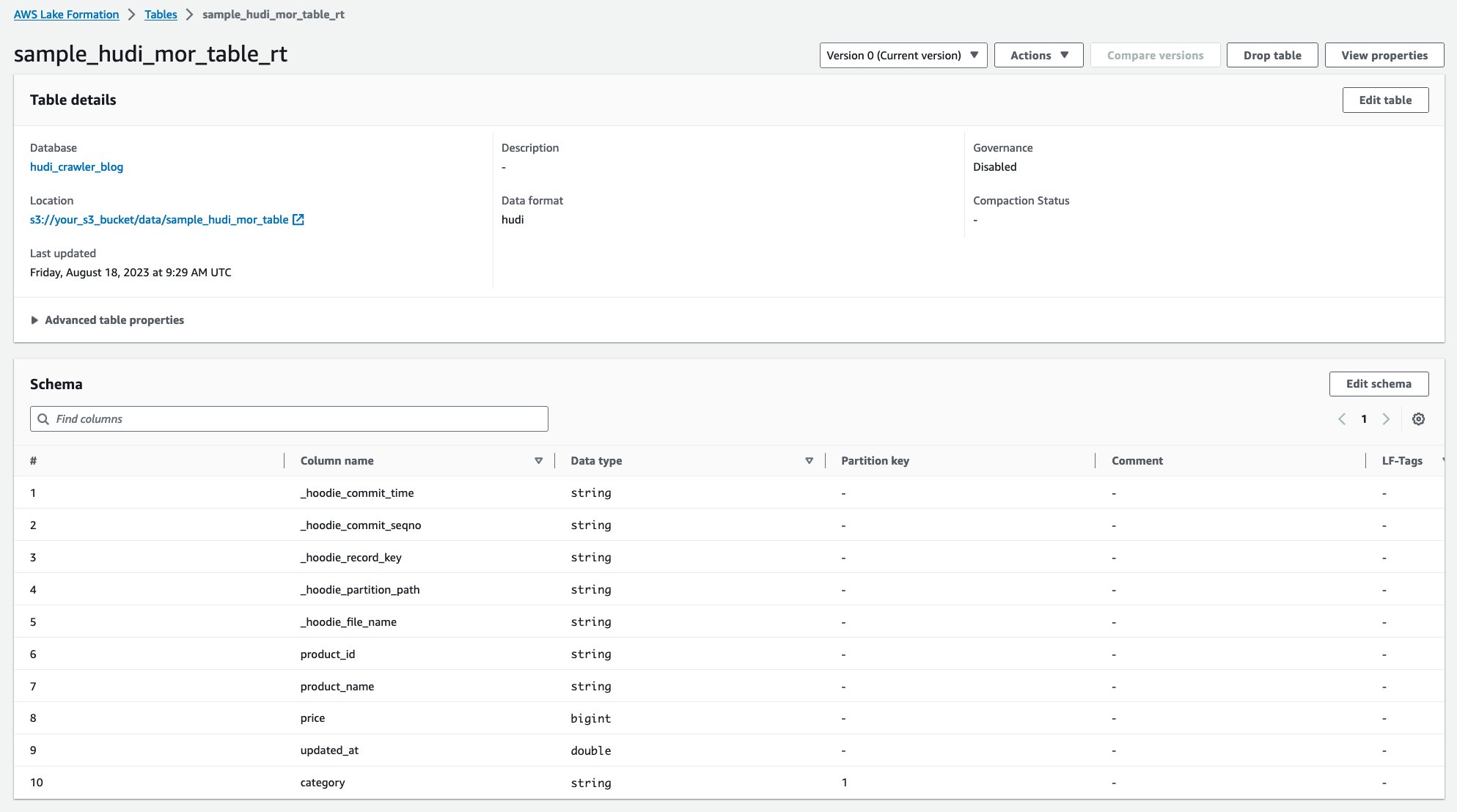
U hebt de data lake-bucket geregistreerd bij Lake Formation en crawltoegang tot het data lake ingeschakeld met behulp van Lake Formation-machtigingen. Je hebt met succes de Hudi MoR-tabel met gegevens op Amazon S3 gecrawld en een AWS Glue Data Catalog-tabel gemaakt waarin het schema is ingevuld. Nadat u de tabeldefinities in AWS Glue Data Catalog hebt gemaakt, kunnen AWS-analyseservices zoals Amazon Athena de Hudi-tabel opvragen.
Voer de volgende stappen uit om zoekopdrachten op Athena te starten:
- Open de Amazon Athena-console.
- Voer de volgende query uit.
De volgende schermafbeelding toont onze uitvoer:
- Voer de volgende query uit.
De volgende schermafbeelding toont onze uitvoer:
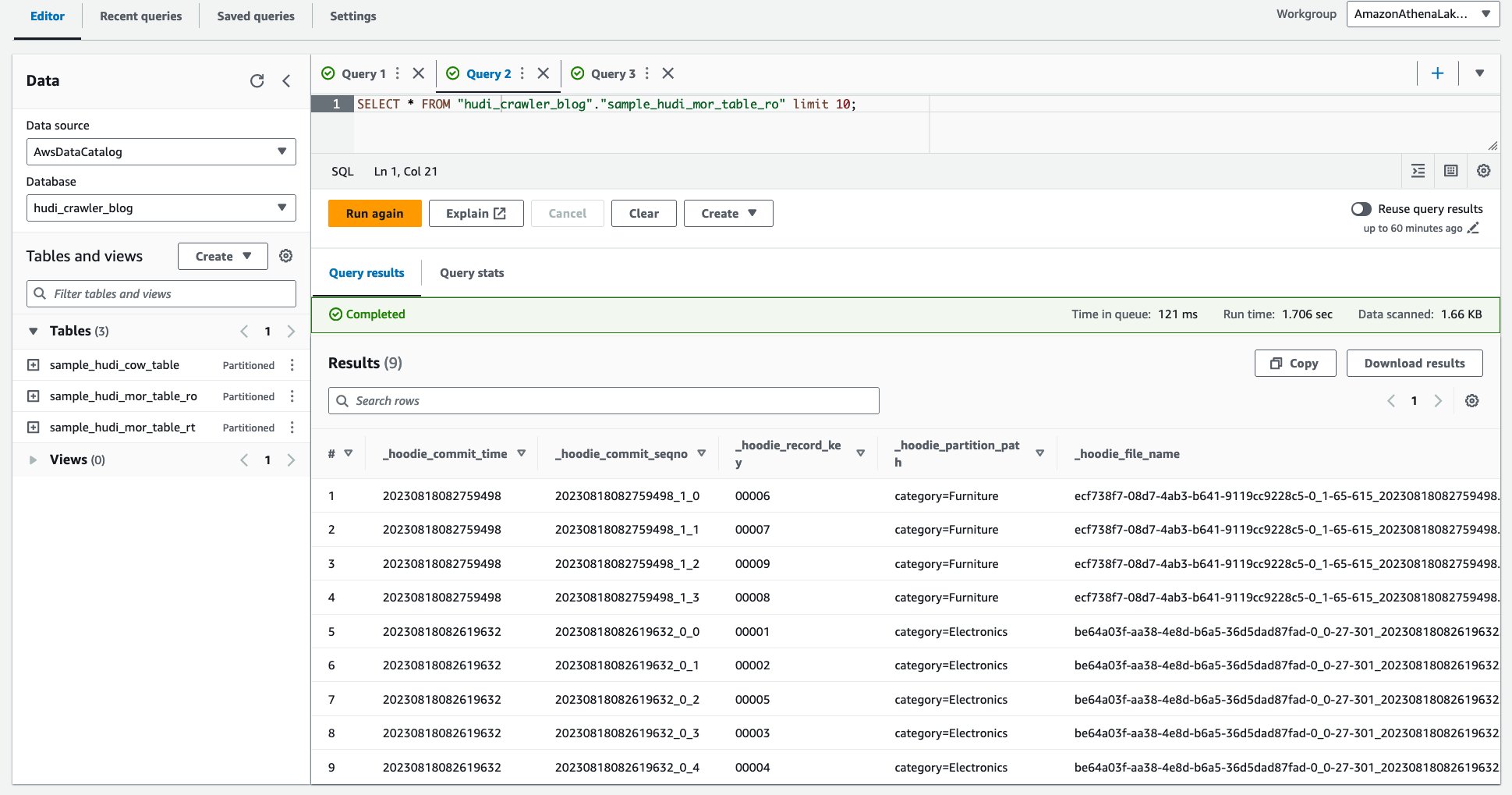
Fijnmazige toegangscontrole met behulp van AWS Lake Formation-machtigingen
Om fijnmazige toegangscontrole op de Hudi-tabel toe te passen, kunt u profiteren van AWS Lake Formation-machtigingen. Met Lake Formation-machtigingen kunt u de toegang tot specifieke tabellen, kolommen of rijen beperken en vervolgens de Hudi-tabellen opvragen via Amazon Athena met fijnmazige toegangscontrole. Laten we de toestemming voor Lake Formation configureren voor de Hudi MoR-tabel.
Voorwaarden
Dit zijn de vereisten voor deze zelfstudie:
- Vul het vorige gedeelte in Crawl een Hudi MoR-tabel met behulp van de AWS Glue-crawler met AWS Lake Formation-gegevensrechten.
- Maak een IAM-gebruiker DataAnalyst, die AWS-beheerd beleid heeft AmazonAthenaVolledige Toegang.
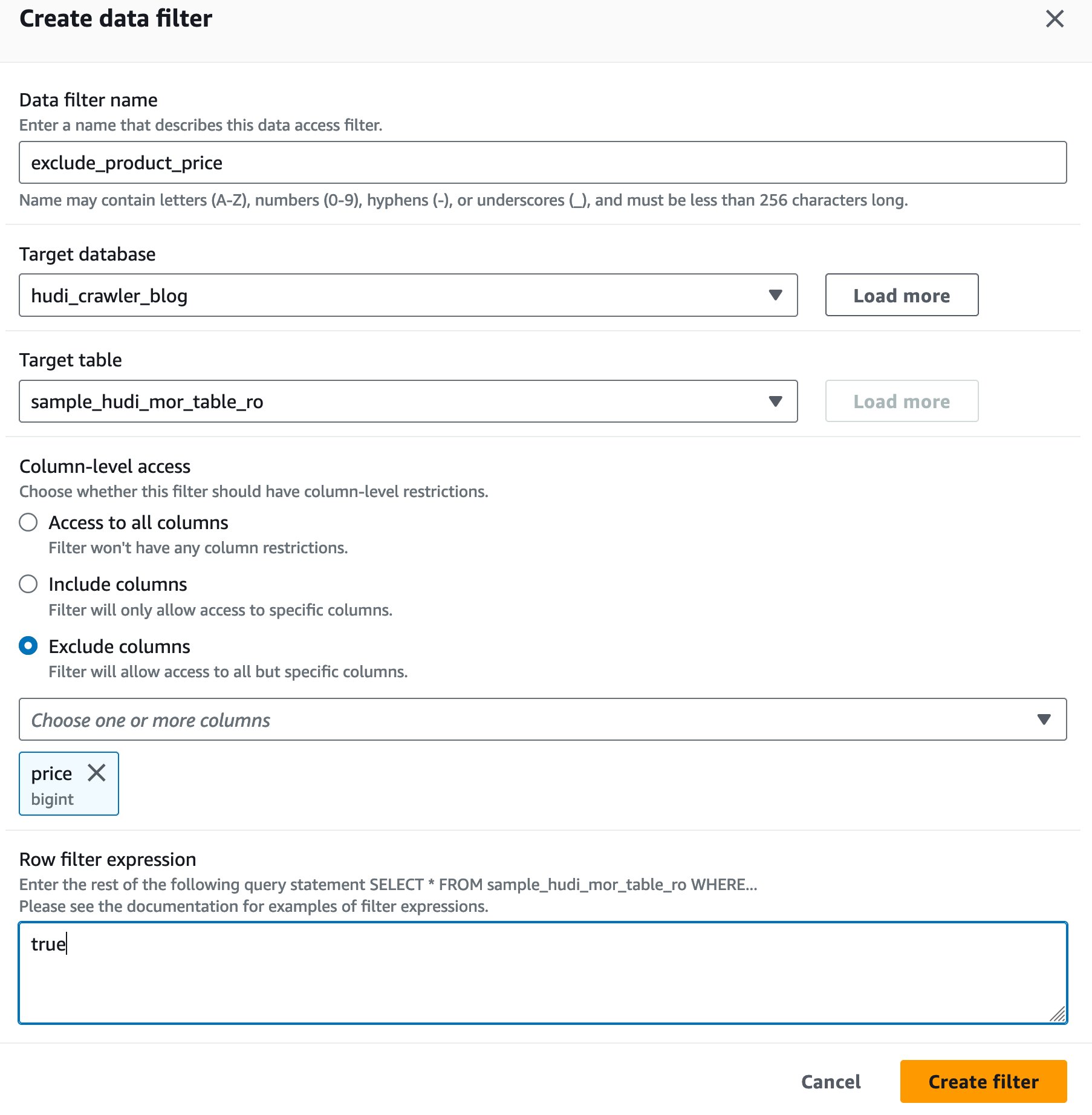
Maak een Lake Formation-gegevenscelfilter
Laten we eerst een filter instellen voor de voor MoR-lezen geoptimaliseerde tabel.
- Meld u aan bij de Lake Formation-console als data lake-beheerder.
- Kies Gegevensfilters.
- Kies Nieuw filter maken.
- Voor Naam gegevensfilter, ga naar binnen
exclude_product_price. - Voor Doeldatabase, kies de database
hudi_crawler_blog. - Voor Doeltabel, kies de tafel
sample_hudi_mor_table_ro. - Voor Kolomniveau toegang, selecteren Kolommen uitsluitenen kies de kolomprijs.
- Voor Uitdrukking rijfilter, ga naar binnen
true. - Kies Maak een filter.
Verleen Lake Formation-machtigingen aan de DataAnalyst-gebruiker
Voer de volgende stappen uit om toestemming voor Lake Formation te verlenen aan de DataAnalyst gebruiker
- Kies op de Lake Formation-console Data lake-machtigingen.
- Kies Grant.
- Voor opdrachtgevers, kiezen IAM-gebruikers en -rollenen kies de gebruiker
DataAnalyst. - Voor LF-tags of catalogusbronnen, kiezen Benoemde gegevenscatalogusbronnen.
- Voor Database, kies de database
hudi_crawler_blog. - Voor Tafel – optioneel, kies de tafel
sample_hudi_mor_table_ro. - Voor Gegevensfilters – optioneel, selecteer
exclude_product_price. - Voor Gegevensfiltermachtigingenselecteer kies.
- Kies Grant.
U hebt toestemming verleend voor Lake Formation voor de database hudi_crawler_blog en de tafel sample_hudi_mor_table_ro, exclusief de kolom price aan de DataAnalyst-gebruiker. Laten we nu de gebruikerstoegang tot de gegevens valideren met behulp van Athena.
- Meld u aan bij de Athena-console als DataAnalyst-gebruiker.
- Voer in de query-editor de volgende query uit:
De volgende schermafbeelding toont onze uitvoer:
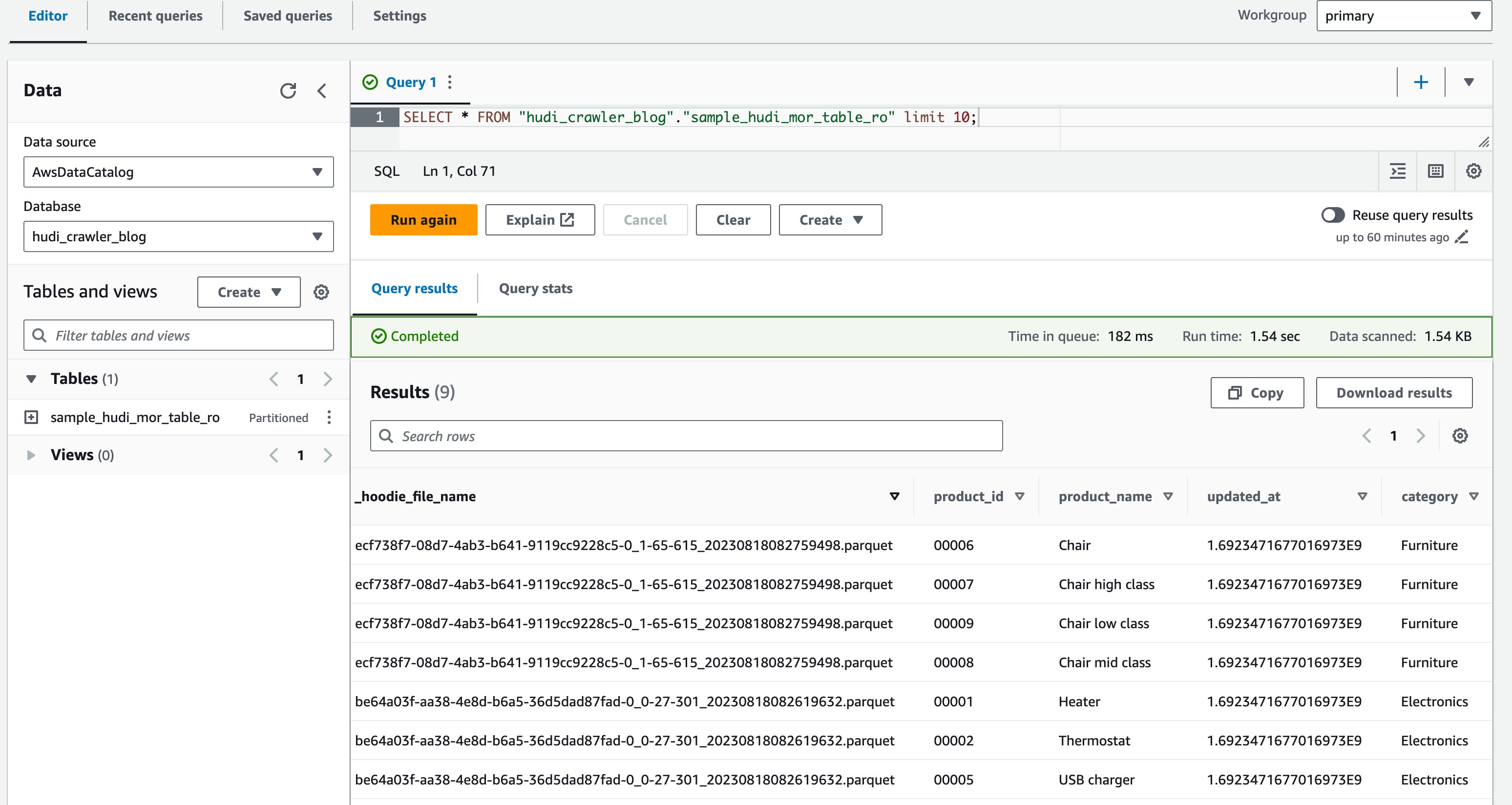
Nu hebt u de kolom gevalideerd price wordt niet getoond, maar wel de andere kolommen product_id, product_name, update_at en category zijn getoond.
Opruimen
Om ongewenste kosten voor uw AWS-account te voorkomen, verwijdert u de volgende AWS-bronnen:
- Verwijder de AWS Glue-database
hudi_crawler_blog. - Verwijder AWS Glue-crawlers
hudi_cow_crawlerenhudi_mor_crawler. - Verwijder Amazon S3-bestanden onder
s3://your_s3_bucket/data/sample_hudi_cow_table/ens3://your_s3_bucket/data/sample_hudi_mor_table/.
Conclusie
Dit bericht liet zien hoe AWS Glue-crawlers werken voor Hudi-tabellen. Met de ondersteuning voor de Hudi-crawler kunt u snel overstappen op het gebruik van AWS Glue Data Catalog als uw primaire Hudi-tabelcatalogus. U kunt beginnen met het bouwen van uw serverloze transactionele data lake met behulp van Hudi op AWS met behulp van AWS Glue, AWS Glue Data Catalog en Lake Formation fijnmazige toegangscontroles voor tabellen en formaten die worden ondersteund door AWS-analyse-engines.
Over de auteurs
 Noritaka Sekiyama is een Principal Big Data Architect in het AWS Glue-team. Hij werkt vanuit Tokyo, Japan. Hij is verantwoordelijk voor het bouwen van software-artefacten om klanten te helpen. In zijn vrije tijd fietst hij graag met zijn racefiets.
Noritaka Sekiyama is een Principal Big Data Architect in het AWS Glue-team. Hij werkt vanuit Tokyo, Japan. Hij is verantwoordelijk voor het bouwen van software-artefacten om klanten te helpen. In zijn vrije tijd fietst hij graag met zijn racefiets.
 Kyle Duong is een Software Development Engineer bij het AWS Glue and Lake Formation-team. Hij heeft een passie voor het bouwen van big data-technologieën en gedistribueerde systemen.
Kyle Duong is een Software Development Engineer bij het AWS Glue and Lake Formation-team. Hij heeft een passie voor het bouwen van big data-technologieën en gedistribueerde systemen.
 Sandeep Adwankar is Senior Technisch Product Manager bij AWS. Hij is gevestigd in de California Bay Area en werkt samen met klanten over de hele wereld om zakelijke en technische vereisten om te zetten in producten waarmee klanten de manier waarop ze gegevens beheren, beveiligen en openen, kunnen verbeteren.
Sandeep Adwankar is Senior Technisch Product Manager bij AWS. Hij is gevestigd in de California Bay Area en werkt samen met klanten over de hele wereld om zakelijke en technische vereisten om te zetten in producten waarmee klanten de manier waarop ze gegevens beheren, beveiligen en openen, kunnen verbeteren.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- : heeft
- :is
- :niet
- :waar
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- in staat
- Over
- toegang
- Toegang tot gegevens
- toegang
- Account
- Actie
- toevoegen
- toegevoegd
- toevoeging
- aangenomen
- Adoptie
- vergevorderd
- Na
- Alles
- toelaten
- Het toestaan
- toestaat
- ook
- Amazone
- Amazone Athene
- Amazon Web Services
- an
- Analytisch
- analytics
- en
- Nog een
- elke
- apache
- Apache Spark
- api
- komt naar voren
- Aanvraag
- Application Development
- Solliciteer
- ZIJN
- GEBIED
- rond
- AS
- At
- webmaster.
- vermijd
- AWS
- AWS lijm
- AWS Lake-formatie
- baseren
- gebaseerde
- Baai
- BE
- omdat
- geweest
- voordeel
- Betere
- Groot
- Big data
- Brengt
- Gebouw
- bebouwd
- bedrijfsdeskundigen
- maar
- by
- Californië
- Bellen
- CAN
- mogelijkheden
- bekwaamheid
- geval
- catalogus
- catalogi
- categorieën
- cel
- uitdagingen
- verandering
- veranderd
- Wijzigingen
- lasten
- Kies
- Kolom
- columns
- combinatie van
- plegen
- toegewijd
- compleet
- complex
- bestanddeel
- Configuratie
- troosten
- bevat
- content
- doorlopend
- onder controle te houden
- controles
- kon
- crawler
- en je merk te creëren
- aangemaakt
- creëert
- Geloofsbrieven
- Klanten
- gegevens
- gegevens integratie
- Datameer
- datawarehouse
- Database
- databanken
- datasets
- definitie
- definities
- Delta
- gedemonstreerd
- demonstreert
- diepte
- Ontwikkeling
- direct
- Onthul Nu
- verdeeld
- gedistribueerde systemen
- do
- doet
- gedurende
- elk
- gemakkelijker
- gemakkelijk
- editor
- effectief
- doeltreffend
- in staat stellen
- ingeschakeld
- ingenieur
- Ingenieurs
- Motoren
- Enter
- Ether (ETH)
- evoluerende
- Exclusief
- extract
- sneller
- minder
- Dien in
- Bestanden
- filter
- filters
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- eerste keer
- volgend
- Voor
- formaat
- vorming
- vaak
- oppompen van
- gegeven
- wereldbol
- Go
- toe te kennen
- verleend
- Guides
- Hadoop
- Hebben
- he
- hulp
- helpt
- zijn
- Bijenkorf
- Hoe
- How To
- HTML
- HTTPS
- IAM
- if
- implicaties
- verbeteren
- in
- Inclusief
- incrementele
- informatie
- verkrijgen in plaats daarvan
- integreren
- integratie
- Interface
- in
- de invoering
- IT
- Japan
- jpg
- houden
- meer
- meren
- laatste
- lancering
- LEARN
- leren
- minder
- LIMIT
- Lijn
- Lijst
- gelegen
- plaats
- locaties
- ingelogd
- machine
- machine learning
- behoud van
- maken
- MERKEN
- beheer
- beheerd
- manager
- beheren
- handboek
- maximaal
- samen te voegen
- Metadata
- migreren
- migratie
- ML
- meer
- meest
- beweging
- meervoudig
- naam
- inheemse
- Noodzaak
- nodig
- New
- onlangs
- volgende
- nu
- of
- on
- EEN
- Slechts
- open
- open source
- geoptimaliseerde
- Keuze
- or
- Overige
- onze
- uitgang
- deel
- hartstochtelijk
- pad
- paden
- prestatie
- toestemming
- permissies
- Plato
- Plato gegevensintelligentie
- PlatoData
- Populair
- bevolkte
- Post
- Voorbereiden
- vereisten
- vorig
- prijs
- primair
- Principal
- verwerking
- Product
- product manager
- Producten
- zorgen voor
- mits
- biedt
- queries
- snel
- Lees
- vast
- real-time
- realtime
- recent
- record
- registreren
- geregistreerd
- vervangen
- Voorwaarden
- Resources
- verantwoordelijk
- beperken
- weg
- Rol
- RIJ
- lopen
- dezelfde
- rooster
- gepland
- sdk
- sectie
- beveiligen
- zien
- kiezen
- senior
- Serverless
- service
- Diensten
- reeks
- settings
- getoond
- Shows
- vereenvoudigt
- sinds
- single
- Plak
- Momentopname
- So
- Software
- software development
- bron
- bronnen
- Vonk
- specifiek
- begin
- Land
- Stap voor
- Stappen
- opgeslagen
- streaming
- streams
- studio
- Met goed gevolg
- dergelijk
- ondersteuning
- ondersteunde
- synchroniseren.
- Systems
- tafel
- team
- Technisch
- Technologies
- dat
- De
- hun
- harte
- Er.
- ze
- dit
- drie
- Door
- niet de tijd of
- keer
- naar
- tokyo
- top
- transactionele
- Transacties
- vertalen
- traverse
- leiden
- veroorzaakt
- zelfstudie
- twee
- types
- typisch
- voor
- ongewenste
- bijwerken
- bijgewerkt
- updates
- .
- use case
- gebruikt
- Gebruiker
- gebruikers
- toepassingen
- gebruik
- BEVESTIG
- gevalideerd
- Values
- versie
- visuele
- Magazijn
- we
- web
- webservices
- GOED
- wanneer
- welke
- en
- WIE
- wil
- Met
- zonder
- Mijn werk
- Bedrijven
- schrijven
- geschreven
- u
- Your
- jezelf
- zephyrnet