Amazon roodverschuiving, een veelgebruikt datawarehouse in de cloud, is aanzienlijk geëvolueerd om te voldoen aan de prestatie-eisen van de meest veeleisende workloads. Dit bericht behandelt zo'n nieuwe functie: de sorteersleutel voor de multidimensionale gegevensindeling.
Amazon Redshift verbetert nu uw queryprestaties door multidimensionale sorteersleutels voor gegevensindeling te ondersteunen, wat een nieuw type sorteersleutel is die de gegevens van een tabel sorteert op filterpredikaten in plaats van op fysieke kolommen van de tabel. Multidimensionale sorteersleutels voor de gegevensindeling zullen de prestaties van tabelscans aanzienlijk verbeteren, vooral wanneer uw querywerklast repetitieve scanfilters bevat.
Amazon Redshift biedt al de mogelijkheid om automatische tafeloptimalisatie (ATO), dat het ontwerp van tabellen automatisch optimaliseert door sorteer- en distributiesleutels toe te passen zonder tussenkomst van de beheerder. In dit bericht introduceren we sorteersleutels voor multidimensionale gegevensindeling als een extra mogelijkheid die wordt aangeboden door ATO en wordt versterkt door het sorteersleuteladviseur-algoritme van Amazon Redshift.
Sorteersleutels voor multidimensionale gegevensindeling
Wanneer u een tabel definieert met de AUTO-sorteersleutel, analyseert Amazon Redshift ATO uw zoekgeschiedenis en selecteert automatisch een sorteersleutel met één kolom of een multidimensionale sorteersleutel voor de gegevensindeling voor uw tabel, op basis van welke optie het beste is voor uw werklast. Wanneer de multidimensionale gegevensindeling is geselecteerd, zal Amazon Redshift een multidimensionale sorteerfunctie construeren die rijen co-loceert die doorgaans door dezelfde zoekopdrachten worden benaderd, en de sorteerfunctie wordt vervolgens gebruikt tijdens het uitvoeren van query's om datablokken over te slaan en zelfs het scannen van het individuele predikaat over te slaan. kolommen.
Beschouw de volgende gebruikersquery, een dominant querypatroon in de werklast van de gebruiker:
Amazon Redshift slaat gegevens voor elke kolom op in schijfblokken van 1 MB en slaat de minimum- en maximumwaarden in elk blok op als onderdeel van de metagegevens van de tabel. Als een query gebruikmaakt van een bereik-beperkt predikaat, kan Amazon Redshift de minimum- en maximumwaarden gebruiken om snel grote aantallen blokken over te slaan tijdens tabelscans. Het filter van deze query op de subregiokolom kan echter niet worden gebruikt om te bepalen welke blokken moeten worden overgeslagen op basis van minimum- en maximumwaarden, en als resultaat scant Amazon Redshift alle rijen uit de titeltabel:
Wanneer de query van de gebruiker werd uitgevoerd met titles met behulp van een sorteersleutel met één kolom subregion, is het resultaat van de voorgaande query als volgt:
Hieruit blijkt dat de tabelscan 2,164,081,640 rijen bevatte.
Om scans op de titles tabel, zou Amazon Redshift automatisch kunnen besluiten om een sorteersleutel voor de multidimensionale gegevensindeling te gebruiken. Alle rijen die voldoen aan de lower(subregion) like '%United States%' predikaat zou zich in een speciaal gebied van de tabel bevinden, en daarom zal Amazon Redshift alleen datablokken scannen die aan het predikaat voldoen.
Wanneer de query van de gebruiker wordt uitgevoerd met titles met behulp van een multidimensionale sorteersleutel voor de gegevensindeling die omvat lower(subregion) like '%United States%' als predikaat het resultaat van de sys_query_detail vraag luidt als volgt:
Hieruit blijkt dat de tabelscan 152,324,046 rijen las, wat slechts 7% van het origineel is, en dat de sorteersleutel voor de multidimensionale gegevensindeling werd gebruikt.
Houd er rekening mee dat dit voorbeeld één enkele query gebruikt om de multidimensionale gegevenslay-outfunctie te demonstreren, maar Amazon Redshift houdt rekening met alle query's die tegen de tabel worden uitgevoerd en kan meerdere regio's maken om aan de meest voorkomende predicaten te voldoen.
Laten we nog een voorbeeld nemen, met deze keer complexere predikaten en meerdere query's.
Stel je voor dat je een tafel hebt items (cost int, available int, demand int) met vier rijen, zoals weergegeven in het volgende voorbeeld.
| #ID kaart | kosten | Beschikbaar | vraag |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Uw dominante werklast bestaat uit twee query's:
- 70% querypatroon:
- 20% querypatroon:
Bij traditionele sorteertechnieken kunt u ervoor kiezen om de tabel op de kostenkolom te sorteren, zodat de evaluatie van de tabel plaatsvindt cost > 3 zullen profiteren van de soort. Dus de itemstabel na het sorteren met behulp van een enkele cost kolom ziet er als volgt uit.
| #ID kaart | kosten | Beschikbaar | vraag |
| Regio #1, met kosten <= 3 | |||
| Regio #2, met kosten > 3 | |||
| #ID kaart | kosten | Beschikbaar | vraag |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Door deze traditionele sortering te gebruiken, kunnen we de bovenste twee (blauwe) rijen met ID 4 en ID 2 onmiddellijk uitsluiten, omdat ze niet voldoen aan cost > 3.
Aan de andere kant wordt de tabel met een multidimensionale sorteersleutel voor de gegevensindeling gesorteerd op basis van een combinatie van de twee vaak voorkomende predikaten in de werklast van de gebruiker, namelijk cost > 3 en available < demand. Als gevolg hiervan worden de rijen van de tabel in vier regio's gesorteerd.
| #ID kaart | kosten | Beschikbaar | vraag |
| Regio #1, met kosten <= 3 en beschikbaar < vraag | |||
| Regio #2, met kosten <= 3 en beschikbaar >= vraag | |||
| Regio #3, met kosten > 3 en beschikbaar < vraag | |||
| Regio #4, met kosten > 3 en beschikbaar >= vraag | |||
| #ID kaart | kosten | Beschikbaar | vraag |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Dit concept is zelfs nog krachtiger wanneer het wordt toegepast op hele blokken in plaats van op enkele rijen, wanneer het wordt toegepast op complexe predikaten die operatoren gebruiken die niet geschikt zijn voor traditionele sorteertechnieken (zoals like), en wanneer toegepast op meer dan twee predikaten.
Systeemtabellen
De volgende Amazon Redshift-systeemtabellen laten gebruikers zien of multidimensionale gegevenslay-outs worden gebruikt in hun tabellen en zoekopdrachten:
- Om te bepalen of een bepaalde tabel een multidimensionale sorteersleutel voor de gegevensindeling gebruikt, kunt u controleren of dit het geval is
sortkey1in svv_table_info is gelijk aanAUTO(SORTKEY(padb_internal_mddl_key_col)). - Als u wilt bepalen of een bepaalde query een multidimensionale gegevensindeling gebruikt om tabelscans te versnellen, kunt u dit controleren
step_attributein de sys_query_detail weergave. De waarde zal gelijk zijn aanmulti-dimensionalof de sorteersleutel voor de multidimensionale gegevensindeling van de tabel is gebruikt tijdens de scan.
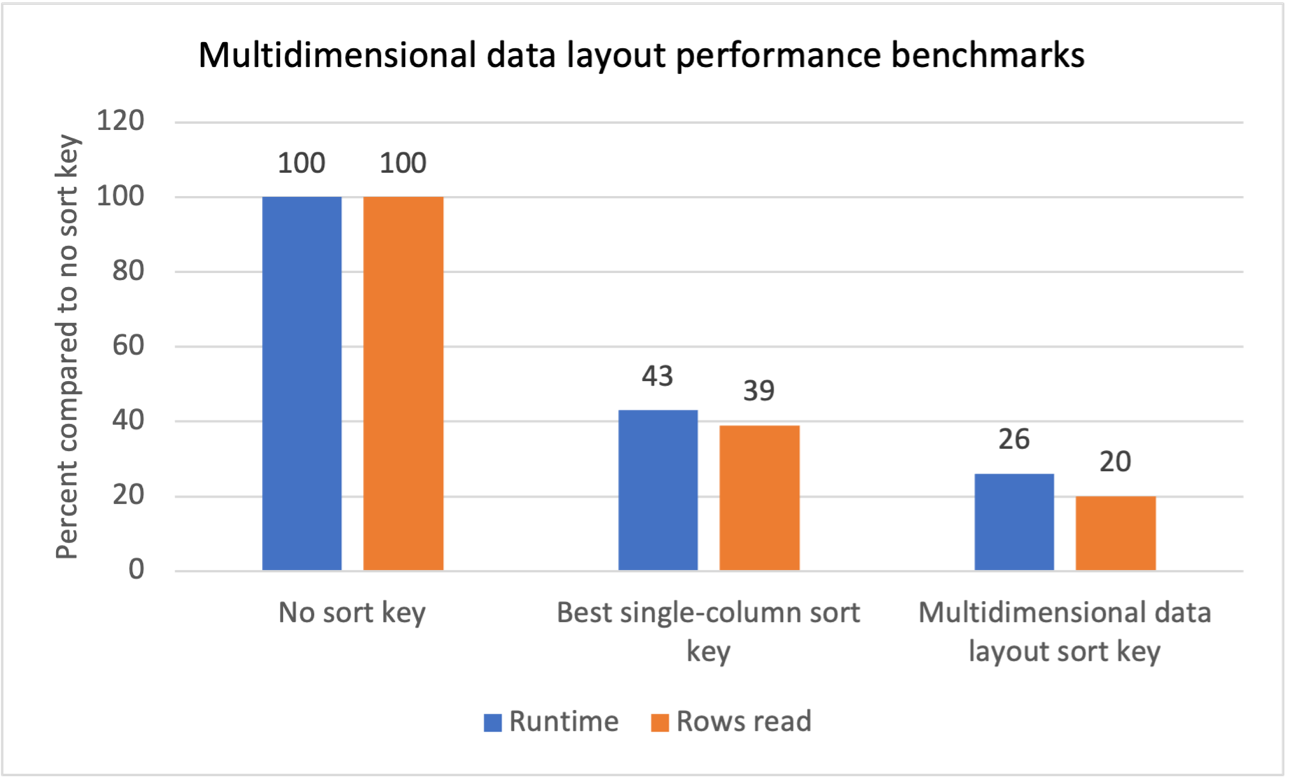
Prestatiebenchmarks
We hebben interne benchmarktests uitgevoerd voor meerdere werkbelastingen met repetitieve scanfilters en hebben vastgesteld dat de introductie van multidimensionale sorteersleutels voor de gegevensindeling de volgende resultaten opleverde:
- Een totale runtimereductie van 74% vergeleken met het ontbreken van een sorteersleutel.
- Een totale runtimereductie van 40% vergeleken met de beste sorteersleutel met één kolom in elke tabel.
- Een vermindering van 80% in het totaal aantal rijen dat uit tabellen wordt gelezen, vergeleken met het ontbreken van een sorteersleutel.
- Een vermindering van 47% in het totaal aantal rijen dat uit tabellen wordt gelezen, vergeleken met de beste sorteersleutel met één kolom voor elke tabel.
Functievergelijking
Met de introductie van multidimensionale sorteersleutels voor de gegevensindeling kunnen uw tabellen nu worden gesorteerd op expressies op basis van de vaak voorkomende filterpredikaten in uw werklast. De volgende tabel biedt een functievergelijking voor Amazon Redshift met twee concurrenten.
| Kenmerk | Amazon roodverschuiving | Concurrent A | Concurrent B |
| Ondersteuning voor sorteren op kolommen | Ja | Ja | Ja |
| Ondersteuning voor sorteren op expressie | Ja | Ja | Nee |
| Automatische kolomselectie voor sorteren | Ja | Nee | Ja |
| Automatische expressieselectie voor sorteren | Ja | Nee | Nee |
| Automatische selectie tussen sorteren van kolommen of sorteren van expressies | Ja | Nee | Nee |
| Automatisch gebruik van sorteereigenschappen voor expressies tijdens scans | Ja | Nee | Nee |
Overwegingen
Houd rekening met het volgende wanneer u een multidimensionale gegevensindeling gebruikt:
- Multidimensionale gegevensindeling wordt ingeschakeld wanneer u uw tabel instelt als SORTKEY AUTO.
- Amazon Redshift Advisor kiest automatisch een sorteersleutel met één kolom of een multidimensionale gegevensindeling voor de tabel door uw historische werklast te analyseren.
- Amazon Redshift ATO past de sorteerresultaten van de multidimensionale gegevensindeling aan op basis van de manier waarop doorlopende zoekopdrachten omgaan met de werklast.
- Amazon Redshift ATO onderhoudt sorteersleutels met multidimensionale gegevensindeling op dezelfde manier als momenteel voor bestaande sorteersleutels. Verwijzen naar Werken met automatische tabeloptimalisatie voor meer informatie over ATO.
- Multidimensionale sorteersleutels voor de gegevensindeling werken met zowel ingerichte clusters als serverloze werkgroepen.
- Sorteersleutels voor de multidimensionale gegevensindeling werken met uw bestaande gegevens zolang de AUTO SORTKEY op uw table is ingeschakeld en er een werklast met repetitieve scanfilters wordt gedetecteerd. De tabel wordt gereorganiseerd op basis van de resultaten van de multidimensionale sorteerfunctie.
- Om de sorteersleutels voor de multidimensionale gegevensindeling voor een tabel uit te schakelen, gebruikt u alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Hierdoor wordt de AUTO-sorteersleutelfunctie op de tafel uitgeschakeld. - Sorteersleutels voor de multidimensionale gegevensindeling blijven behouden wanneer u uw ingerichte cluster herstelt of migreert naar een serverloos cluster, of omgekeerd.
Conclusie
In dit bericht hebben we laten zien dat sorteersleutels voor de multidimensionale gegevensindeling de runtimeprestaties van query's aanzienlijk kunnen verbeteren voor werkbelastingen waarbij dominante query's repetitieve scanfilters hebben.
Als u een voorbeeldcluster wilt maken vanuit de Amazon Redshift-console, navigeert u naar de Clusters pagina en kies Maak een voorbeeldcluster. U kunt een cluster maken in de regio's VS-Oost (Ohio), VS-Oost (N. Virginia), VS-West (Oregon), Azië-Pacific (Tokio), Europa (Ierland) en Europa (Stockholm) en uw werklasten testen.
We horen graag uw feedback over deze nieuwe functie en kijken uit naar uw opmerkingen over dit bericht.
Over de auteurs
 Milde oke is een Data Warehouse Specialist Solutions Architect gevestigd in New York. Hij bouwt al meer dan 15 jaar datawarehouse-oplossingen en is gespecialiseerd in Amazon Redshift.
Milde oke is een Data Warehouse Specialist Solutions Architect gevestigd in New York. Hij bouwt al meer dan 15 jaar datawarehouse-oplossingen en is gespecialiseerd in Amazon Redshift.
 Jialin Ding is een Applied Scientist in de Learned Systems Group, gespecialiseerd in het toepassen van machine learning en optimalisatietechnieken om de prestaties van datasystemen zoals Amazon Redshift te verbeteren.
Jialin Ding is een Applied Scientist in de Learned Systems Group, gespecialiseerd in het toepassen van machine learning en optimalisatietechnieken om de prestaties van datasystemen zoals Amazon Redshift te verbeteren.
 Yanzhu Ji is een productmanager in het Amazon Redshift-team. Ze heeft ervaring in productvisie en -strategie in toonaangevende dataproducten en -platforms. Ze heeft een uitstekende vaardigheid in het bouwen van substantiële softwareproducten met behulp van webontwikkeling, systeemontwerp, database en gedistribueerde programmeertechnieken. In haar persoonlijke leven houdt Yanzhu van schilderen, fotografie en tennissen.
Yanzhu Ji is een productmanager in het Amazon Redshift-team. Ze heeft ervaring in productvisie en -strategie in toonaangevende dataproducten en -platforms. Ze heeft een uitstekende vaardigheid in het bouwen van substantiële softwareproducten met behulp van webontwikkeling, systeemontwerp, database en gedistribueerde programmeertechnieken. In haar persoonlijke leven houdt Yanzhu van schilderen, fotografie en tennissen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- : heeft
- :is
- :niet
- :waar
- 1
- 100
- 15 jaar
- 15%
- 152
- 7
- 8
- 9
- a
- versnellen
- geraadpleegde
- Extra
- adviseur
- Na
- tegen
- algoritme
- Alles
- al
- Amazone
- Amazon Web Services
- an
- analyseren
- het analyseren van
- en
- Nog een
- toegepast
- Het toepassen van
- ZIJN
- AS
- Azië
- Asia Pacific
- auto
- Automatisch
- webmaster.
- Beschikbaar
- AWS
- gebaseerde
- BE
- omdat
- geweest
- criterium
- voordeel
- BEST
- Betere
- tussen
- Blok
- Blokken
- Blauw
- zowel
- Gebouw
- maar
- by
- CAN
- bekwaamheid
- controle
- Kies
- Cloud
- TROS
- Kolom
- columns
- combinatie van
- opmerkingen
- algemeen
- vergeleken
- vergelijking
- concurrenten
- complex
- concept
- Overwegen
- bestaat uit
- troosten
- bouwen
- bevat
- Kosten
- heeft betrekking op
- en je merk te creëren
- Op dit moment
- gegevens
- datawarehouse
- Database
- beslissen
- toegewijd aan
- bepalen
- Vraag
- veeleisende
- Design
- gegevens
- gedetecteerd
- Bepalen
- Ontwikkeling
- verdeeld
- distributie
- doet
- dominant
- Dont
- gedurende
- elk
- oosten
- beide
- ingeschakeld
- Geheel
- gelijk
- vooral
- Ether (ETH)
- Europa
- evaluatie
- Zelfs
- evolueerde
- voorbeeld
- bestaand
- ervaring
- uitdrukkingen
- Kenmerk
- feedback
- filter
- filters
- volgend
- volgt
- Voor
- Naar voren
- vier
- oppompen van
- functie
- Groep
- hand
- Hebben
- met
- he
- horen
- haar
- historisch
- geschiedenis
- Echter
- HTML
- HTTPS
- ID
- if
- per direct
- verbeteren
- verbetert
- in
- omvat
- individueel
- toonaangevende
- verkrijgen in plaats daarvan
- interactie
- intern
- tussenkomst
- in
- voorstellen
- de invoering
- Introductie
- Ierland
- IT
- artikelen
- sleutel
- toetsen
- Groot
- Layout
- geleerd
- leren
- Life
- als
- sympathieën
- lang
- Kijk
- ziet eruit als
- liefde
- machine
- machine learning
- onderhoudt
- manager
- manier
- maximaal
- Maak kennis met
- Metadata
- macht
- migreren
- denken
- minimum
- meer
- meest
- meervoudig
- OP DEZE WEBSITE VIND JE
- Noodzaak
- New
- nieuwe functie
- New York
- geen
- nu
- nummers
- voorkomend
- of
- korting
- aangeboden
- Ohio
- on
- EEN
- lopend
- Slechts
- exploitanten
- optimalisatie
- Optimaliseert
- Keuze
- or
- bestellen
- Oregon
- origineel
- Overige
- uit
- uitstekend
- over
- Pacific
- schilderij
- deel
- bijzonder
- Patronen
- prestatie
- uitgevoerd
- persoonlijk
- fotografie
- Fysiek
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- Post
- krachtige
- bewaard
- Voorbeschouwing
- geproduceerd
- Product
- product manager
- Producten
- Programming
- vastgoed
- biedt
- queries
- snel
- Lees
- reductie
- verwijzen
- regio
- regio
- herhalende
- Voorwaarden
- het herstellen van
- resultaat
- Resultaten
- lopen
- lopend
- loopt
- dezelfde
- aftasten
- het scannen
- scant
- Wetenschapper
- Seizoen
- zien
- kiezen
- gekozen
- selectie
- Serverless
- Diensten
- reeks
- ze
- tonen
- showcase
- vertoonde
- getoond
- Shows
- aanzienlijk
- single
- bekwaamheid
- So
- Software
- Oplossingen
- specialist
- specialiseert
- gespecialiseerd
- winkels
- Strategie
- Hierop volgend
- wezenlijk
- dergelijk
- geschikt
- Ondersteuning
- system
- Systems
- tafel
- Nemen
- team
- technieken
- tennis
- proef
- Testen
- neem contact
- dat
- De
- hun
- daarom
- ze
- dit
- niet de tijd of
- titels
- naar
- tokyo
- top
- Totaal
- traditioneel
- twee
- type dan:
- typisch
- us
- .
- gebruikt
- Gebruiker
- gebruikers
- toepassingen
- gebruik
- waarde
- Values
- vice
- Bekijk
- Virginia
- visie
- Magazijn
- was
- Manier..
- we
- web
- Webontwikkeling
- webservices
- West
- wanneer
- of
- welke
- wijd
- wil
- Met
- zonder
- Mijn werk
- zou
- jaar
- york
- u
- Your
- zephyrnet