Open AI Whisper is een geavanceerd model voor automatische spraakherkenning (ASR) met een MIT-licentie. ASR-technologie wordt toegepast in transcriptiediensten, stemassistenten en het verbeteren van de toegankelijkheid voor mensen met gehoorproblemen. Dit ultramoderne model is getraind op een enorme en diverse dataset van meertalige en multitask-gecontroleerde gegevens verzameld via internet. Dankzij de hoge nauwkeurigheid en het aanpassingsvermogen is het een waardevolle aanwinst voor een breed scala aan stemgerelateerde taken.
In het steeds evoluerende landschap van machinaal leren en kunstmatige intelligentie, Amazon Sage Maker biedt een alomvattend ecosysteem. SageMaker stelt datawetenschappers, ontwikkelaars en organisaties in staat om machine learning-modellen op schaal te ontwikkelen, trainen, implementeren en beheren. Het biedt een breed scala aan tools en mogelijkheden en vereenvoudigt de gehele machine learning-workflow, van gegevensvoorverwerking en modelontwikkeling tot moeiteloze implementatie en monitoring. De gebruiksvriendelijke interface van SageMaker maakt het tot een cruciaal platform voor het ontsluiten van het volledige potentieel van AI, waardoor het een baanbrekende oplossing wordt op het gebied van kunstmatige intelligentie.
In dit bericht beginnen we aan een verkenning van de mogelijkheden van SageMaker, waarbij we ons specifiek richten op het hosten van Whisper-modellen. We zullen diep ingaan op twee methoden om dit te doen: de ene gebruikt het Whisper PyTorch-model en de andere gebruikt de Hugging Face-implementatie van het Whisper-model. Daarnaast zullen we een diepgaand onderzoek doen naar de inferentieopties van SageMaker, waarbij we ze vergelijken op basis van parameters zoals snelheid, kosten, payloadgrootte en schaalbaarheid. Deze analyse stelt gebruikers in staat weloverwogen beslissingen te nemen bij het integreren van Whisper-modellen in hun specifieke gebruiksscenario's en systemen.
Overzicht oplossingen
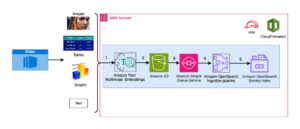
Het volgende diagram toont de belangrijkste componenten van deze oplossing.
- Om het model op Amazon SageMaker te hosten, is de eerste stap het opslaan van de modelartefacten. Deze artefacten verwijzen naar de essentiële componenten van een machine learning-model die nodig zijn voor verschillende toepassingen, inclusief implementatie en hertraining. Ze kunnen modelparameters, configuratiebestanden, voorbewerkingscomponenten en metagegevens bevatten, zoals versiedetails, auteurschap en eventuele opmerkingen met betrekking tot de prestaties ervan. Het is belangrijk op te merken dat Whisper-modellen voor PyTorch- en Hugging Face-implementaties uit verschillende modelartefacten bestaan.
- Vervolgens maken we aangepaste inferentiescripts. Binnen deze scripts definiëren we hoe het model moet worden geladen en specificeren we het inferentieproces. Dit is ook waar we indien nodig aangepaste parameters kunnen opnemen. Bovendien kunt u de vereiste Python-pakketten vermelden in een
requirements.txtbestand. Tijdens de implementatie van het model worden deze Python-pakketten automatisch geïnstalleerd in de initialisatiefase. - Vervolgens selecteren we de deep learning containers (DLC) van PyTorch of Hugging Face die worden geleverd en onderhouden door AWS. Deze containers zijn vooraf gebouwde Docker-images met deep learning-frameworks en andere noodzakelijke Python-pakketten. Voor meer informatie kunt u dit controleren link.
- Met de modelartefacten, aangepaste inferentiescripts en geselecteerde DLC's zullen we Amazon SageMaker-modellen maken voor respectievelijk PyTorch en Hugging Face.
- Ten slotte kunnen de modellen worden geïmplementeerd op SageMaker en worden gebruikt met de volgende opties: realtime inferentie-eindpunten, batchtransformatietaken en asynchrone inferentie-eindpunten. We zullen later in dit bericht dieper op deze opties ingaan.
Het voorbeeldnotebook en de code voor deze oplossing zijn hier beschikbaar GitHub-repository.
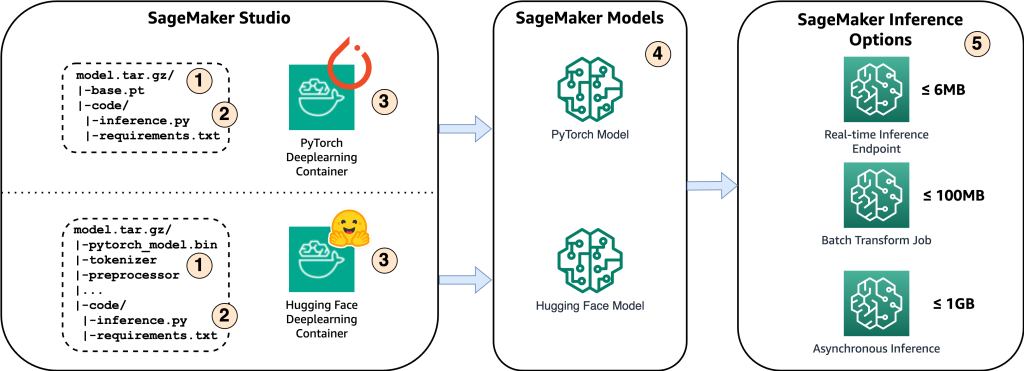
Figuur 1. Overzicht van de belangrijkste oplossingscomponenten
walkthrough
Hosting van het Whisper-model op Amazon SageMaker
In deze sectie leggen we de stappen uit om het Whisper-model op Amazon SageMaker te hosten, met respectievelijk PyTorch en Hugging Face Frameworks. Om met deze oplossing te experimenteren, heb je een AWS-account en toegang tot de Amazon SageMaker-service nodig.
PyTorch-framework
- Bewaar modelartefacten
De eerste optie om het model te hosten is door het Whisper officieel Python-pakket, die kan worden geïnstalleerd met behulp van pip install openai-whisper. Dit pakket biedt een PyTorch-model. Bij het opslaan van modelartefacten in de lokale repository is de eerste stap het opslaan van de leerbare parameters van het model, zoals modelgewichten en biases van elke laag in het neurale netwerk, als een ‘pt’-bestand. U kunt kiezen uit verschillende modelgroottes, waaronder 'tiny', 'base', 'small', 'medium' en 'large'. Grotere modelgroottes bieden hogere nauwkeurigheidsprestaties, maar gaan ten koste van een langere inferentielatentie. Bovendien moet u het modelstatuswoordenboek en het dimensiewoordenboek opslaan, die een Python-woordenboek bevatten dat elke laag of parameter van het PyTorch-model toewijst aan de overeenkomstige leerbare parameters, samen met andere metagegevens en aangepaste configuraties. De onderstaande code laat zien hoe u de Whisper PyTorch-artefacten kunt opslaan.
- Selecteer DLC
De volgende stap is om hieruit de vooraf gebouwde DLC te selecteren link. Wees voorzichtig bij het kiezen van de juiste afbeelding door rekening te houden met de volgende instellingen: raamwerk (PyTorch), raamwerkversie, taak (gevolgtrekking), Python-versie en hardware (d.w.z. GPU). Het wordt aanbevolen om waar mogelijk de nieuwste versies van het framework en Python te gebruiken, omdat dit resulteert in betere prestaties en bekende problemen en bugs uit eerdere releases worden aangepakt.
- Maak Amazon SageMaker-modellen
Vervolgens maken we gebruik van de SageMaker Python-SDK om PyTorch-modellen te maken. Het is belangrijk om te onthouden dat u omgevingsvariabelen moet toevoegen bij het maken van een PyTorch-model. Standaard kan TorchServe alleen bestandsgroottes tot 6 MB verwerken, ongeacht het gebruikte inferentietype.
De volgende tabel toont de instellingen voor verschillende PyTorch-versies:
| Achtergrond | Omgevingsvariabelen |
| PyTorch 1.8 (gebaseerd op TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (gebaseerd op MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definieer de modellaadmethode in inference.py
In de gewoonte inference.py script, controleren we eerst of er een CUDA-compatibele GPU beschikbaar is. Als een dergelijke GPU beschikbaar is, wijzen we de 'cuda' apparaat naar de DEVICE variabel; anders wijzen we de 'cpu' apparaat. Deze stap zorgt ervoor dat het model op de beschikbare hardware wordt geplaatst voor efficiënte berekeningen. We laden het PyTorch-model met behulp van het Whisper Python-pakket.
Kader voor knuffelend gezicht
- Bewaar modelartefacten
De tweede optie is om te gebruiken Het gefluister van een knuffelend gezicht implementatie. Het model kan worden geladen met behulp van de AutoModelForSpeechSeq2Seq transformatoren klasse. De leerbare parameters worden opgeslagen in een binair (bin) bestand met behulp van de save_pretrained methode. De tokenizer en preprocessor moeten ook afzonderlijk worden opgeslagen om ervoor te zorgen dat het Hugging Face-model goed werkt. Als alternatief kunt u een model rechtstreeks vanuit de Hugging Face Hub op Amazon SageMaker implementeren door twee omgevingsvariabelen in te stellen: HF_MODEL_ID en HF_TASK. Voor meer informatie verwijzen wij u naar deze webpagina.
- Selecteer DLC
Net als bij het PyTorch-framework kun je daaruit een vooraf gebouwde Hugging Face DLC kiezen link. Zorg ervoor dat je een DLC selecteert die de nieuwste Hugging Face-transformatoren ondersteunt en GPU-ondersteuning biedt.
- Maak Amazon SageMaker-modellen
Op dezelfde manier gebruiken we de SageMaker Python-SDK om knuffelgezichtsmodellen te maken. Het Hugging Face Whisper-model heeft een standaardlimiet waarbij het alleen audiosegmenten van maximaal 30 seconden kan verwerken. Om deze beperking aan te pakken, kunt u de chunk_length_s parameter in de omgevingsvariabele bij het maken van het Hugging Face-model, en geef deze parameter later door aan het aangepaste inferentiescript bij het laden van het model. Stel ten slotte de omgevingsvariabelen in om de payloadgrootte en de responstime-out voor de Hugging Face-container te vergroten.
| Achtergrond | Omgevingsvariabelen |
|
HuggingFace-inferentiecontainer (gebaseerd op mms) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definieer de modellaadmethode in inference.py
Bij het maken van een aangepast inferentiescript voor het Hugging Face-model gebruiken we een pijplijn, waardoor we de chunk_length_s als parameter. Met deze parameter kan het model lange audiobestanden efficiënt verwerken tijdens inferentie.
Verschillende gevolgtrekkingsopties verkennen op Amazon SageMaker
De stappen voor het selecteren van gevolgtrekkingsopties zijn hetzelfde voor zowel PyTorch- als Hugging Face-modellen, dus we zullen er hieronder geen onderscheid tussen maken. Het is echter vermeldenswaard dat op het moment dat dit bericht werd geschreven, de serverloze gevolgtrekking optie van SageMaker ondersteunt geen GPU's en daarom sluiten we deze optie uit voor dit gebruik.
We kunnen het model inzetten als een realtime eindpunt, dat antwoorden in milliseconden levert. Het is echter belangrijk op te merken dat deze optie beperkt is tot het verwerken van invoer van minder dan 6 MB. We definiëren de serializer als een audio-serializer, die verantwoordelijk is voor het converteren van de invoergegevens naar een geschikt formaat voor het geïmplementeerde model. We gebruiken een GPU-instantie voor gevolgtrekking, waardoor een versnelde verwerking van audiobestanden mogelijk is. De inferentie-invoer is een audiobestand dat afkomstig is uit de lokale opslagplaats.
De tweede gevolgtrekkingsoptie is de batchtransformatietaak, die invoerladingen tot 100 MB kan verwerken. Deze methode kan echter enkele minuten latentie in beslag nemen. Elke instantie kan slechts één batchverzoek tegelijk afhandelen, en het starten en afsluiten van de instantie duurt ook enkele minuten. De gevolgtrekkingsresultaten worden opgeslagen in een Amazon Simple Storage Service (Amazon S3) bucket na voltooiing van de batchtransformatietaak.
Zorg ervoor dat u dit bij het configureren van de batchtransformator meeneemt max_payload = 100 om grotere ladingen effectief te kunnen verwerken. De inferentie-invoer moet het Amazon S3-pad zijn naar een audiobestand of een Amazon S3 Bucket-map met een lijst met audiobestanden, elk met een grootte kleiner dan 100 MB.
Batch Transform verdeelt de Amazon S3-objecten in de invoer per sleutel en wijst Amazon S3-objecten toe aan instanties. Als u bijvoorbeeld meerdere audiobestanden hebt, kan één exemplaar input1.wav verwerken, en een ander exemplaar kan het bestand met de naam input2.wav verwerken om de schaalbaarheid te verbeteren. Met Batch Transform kunt u configureren max_concurrent_transforms om het aantal HTTP-verzoeken aan elke individuele transformatorcontainer te vergroten. Het is echter belangrijk op te merken dat de waarde van (max_concurrent_transforms* max_payload) mag niet groter zijn dan 100 MB.
Ten slotte is Amazon SageMaker Asynchronous Inference ideaal voor het gelijktijdig verwerken van meerdere verzoeken, biedt het een gematigde latentie en ondersteunt het invoerladingen tot 1 GB. Deze optie biedt uitstekende schaalbaarheid, waardoor de configuratie van een automatische schalingsgroep voor het eindpunt mogelijk wordt. Wanneer er een golf van verzoeken optreedt, wordt het automatisch opgeschaald om het verkeer af te handelen. Zodra alle verzoeken zijn verwerkt, wordt het eindpunt teruggeschaald naar 0 om kosten te besparen.
Met behulp van asynchrone inferentie worden de resultaten automatisch opgeslagen in een Amazon S3-bucket. In de AsyncInferenceConfig, kunt u meldingen configureren voor succesvolle of mislukte voltooiingen. Het invoerpad verwijst naar een Amazon S3-locatie van het audiobestand. Voor meer details verwijzen wij u naar de code op GitHub.
Optioneel: Zoals eerder vermeld, hebben we de mogelijkheid om een autoscaling-groep te configureren voor het asynchrone inferentie-eindpunt, waardoor het een plotselinge toename van het aantal inferentieverzoeken kan afhandelen. Hierin wordt een codevoorbeeld gegeven GitHub-repository. In het volgende diagram ziet u een lijndiagram met twee metrieken uit Amazon Cloud Watch: ApproximateBacklogSize en ApproximateBacklogSizePerInstance. Toen er aanvankelijk duizend verzoeken werden geactiveerd, was er slechts één exemplaar beschikbaar om de gevolgtrekking af te handelen. Drie minuten lang overschreed de backlog-grootte consequent de drie (houd er rekening mee dat deze aantallen kunnen worden geconfigureerd) en de autoscaling-groep reageerde door extra instanties op te starten om de backlog efficiënt weg te werken. Dit heeft geleid tot een aanzienlijke daling van het aantal ApproximateBacklogSizePerInstance, waardoor achterstandsaanvragen veel sneller kunnen worden verwerkt dan tijdens de beginfase.

Figuur 2. Lijndiagram dat de tijdelijke veranderingen in de Amazon CloudWatch-statistieken illustreert
Vergelijkende analyse voor de gevolgtrekkingsopties
De vergelijkingen voor verschillende gevolgtrekkingsopties zijn gebaseerd op algemene gebruiksscenario's voor audioverwerking. Realtime inferentie biedt de hoogste inferentiesnelheid, maar beperkt de payloadgrootte tot 6 MB. Dit gevolgtrekkingstype is geschikt voor audiocommandosystemen, waarbij gebruikers apparaten of software besturen of ermee communiceren met behulp van spraakopdrachten of gesproken instructies. Spraakopdrachten zijn doorgaans klein van formaat en een lage inferentielatentie is van cruciaal belang om ervoor te zorgen dat getranscribeerde opdrachten onmiddellijk daaropvolgende acties kunnen activeren. Batchtransformatie is ideaal voor geplande offline taken, waarbij de grootte van elk audiobestand minder dan 100 MB bedraagt en er geen specifieke vereiste is voor snelle responstijden voor gevolgtrekkingen. Asynchrone inferentie maakt uploads van maximaal 1 GB mogelijk en biedt een gematigde inferentielatentie. Dit gevolgtrekkingstype is zeer geschikt voor het transcriberen van films, tv-series en opgenomen conferenties waarbij grotere audiobestanden moeten worden verwerkt.
Zowel realtime als asynchrone inferentieopties bieden automatische schalingsmogelijkheden, waardoor de eindpuntinstanties automatisch omhoog of omlaag kunnen schalen op basis van het aantal verzoeken. In gevallen zonder verzoeken verwijdert automatisch schalen onnodige exemplaren, waardoor u de kosten kunt vermijden die verband houden met ingerichte exemplaren die niet actief in gebruik zijn. Voor realtime gevolgtrekking moet echter ten minste één persistent exemplaar worden behouden, wat tot hogere kosten kan leiden als het eindpunt continu werkt. Met asynchrone inferentie kan het exemplaarvolume daarentegen worden teruggebracht tot 0 wanneer het niet in gebruik is. Bij het configureren van een batchtransformatietaak is het mogelijk om meerdere instanties te gebruiken om de taak te verwerken en max_concurrent_transforms aan te passen zodat één instantie meerdere verzoeken kan afhandelen. Daarom bieden alle drie de gevolgtrekkingsopties een grote schaalbaarheid.
Schoonmaken
Zodra u klaar bent met het gebruik van de oplossing, moet u ervoor zorgen dat u de SageMaker-eindpunten verwijdert om extra kosten te voorkomen. U kunt de meegeleverde code gebruiken om respectievelijk realtime- en asynchrone inferentie-eindpunten te verwijderen.
Conclusie
In dit bericht hebben we u laten zien hoe het inzetten van machine learning-modellen voor audioverwerking steeds belangrijker is geworden in verschillende industrieën. Met het Whisper-model als voorbeeld hebben we gedemonstreerd hoe open-source ASR-modellen op Amazon SageMaker kunnen worden gehost met behulp van PyTorch- of Hugging Face-benaderingen. De verkenning omvatte verschillende gevolgtrekkingsopties op Amazon SageMaker, die inzicht boden in het efficiënt verwerken van audiogegevens, het maken van voorspellingen en het effectief beheren van de kosten. Dit bericht is bedoeld om kennis te verschaffen aan onderzoekers, ontwikkelaars en datawetenschappers die geïnteresseerd zijn in het gebruik van het Whisper-model voor audiogerelateerde taken en het nemen van weloverwogen beslissingen over inferentiestrategieën.
Raadpleeg dit voor meer gedetailleerde informatie over het implementeren van modellen op SageMaker Handleiding voor ontwikkelaars. Bovendien kan het Whisper-model worden geïmplementeerd met behulp van SageMaker JumpStart. Voor meer details kunt u de Fluistermodellen voor automatische spraakherkenning nu beschikbaar in Amazon SageMaker JumpStart post.
Bekijk gerust het notitieboekje en de code voor dit project op GitHub en deel uw reactie met ons.
Over de auteur
 Ying Hou, PhD, is een Machine Learning Prototyping Architect bij AWS. Haar voornaamste interessegebieden omvatten Deep Learning, met een focus op GenAI, Computer Vision, NLP en tijdreeksgegevensvoorspelling. In haar vrije tijd brengt ze graag kwaliteitsmomenten door met haar familie, verdiept ze zich in romans en wandelt ze in de nationale parken van Groot-Brittannië.
Ying Hou, PhD, is een Machine Learning Prototyping Architect bij AWS. Haar voornaamste interessegebieden omvatten Deep Learning, met een focus op GenAI, Computer Vision, NLP en tijdreeksgegevensvoorspelling. In haar vrije tijd brengt ze graag kwaliteitsmomenten door met haar familie, verdiept ze zich in romans en wandelt ze in de nationale parken van Groot-Brittannië.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- versneld
- toegang
- de toegankelijkheid
- Account
- nauwkeurigheid
- over
- acties
- actief
- toevoegen
- Extra
- Daarnaast
- adres
- aanpassen
- vergevorderd
- AI
- wil
- Alles
- Het toestaan
- toestaat
- langs
- ook
- Amazone
- Amazon Sage Maker
- Amazon Web Services
- an
- analyse
- en
- Nog een
- elke
- toepassingen
- benaderingen
- ZIJN
- gebieden
- reeks
- kunstmatig
- kunstmatige intelligentie
- AS
- aanwinst
- assistenten
- geassocieerd
- At
- audio
- Auteurschap
- Automatisch
- webmaster.
- beschikbaarheid
- Beschikbaar
- vermijd
- AWS
- baseren
- gebaseerde
- BE
- worden
- onder
- Betere
- tussen
- vooroordelen
- BIN
- zowel
- bugs
- maar
- by
- CAN
- mogelijkheden
- in staat
- voorzichtig
- gevallen
- Wijzigingen
- tabel
- controle
- Kies
- het kiezen van
- klasse
- duidelijk
- code
- hoe
- commentaar
- Gemeen
- vergelijken
- vergelijkingen
- Voltooid
- voltooiing
- componenten
- uitgebreid
- berekening
- computer
- Computer visie
- Gedrag
- conferenties
- Configuratie
- geconfigureerd
- configureren
- aangezien
- consistent
- bevatten
- Containers
- containers
- doorlopend
- contrast
- onder controle te houden
- het omzetten van
- te corrigeren
- Overeenkomend
- Kosten
- Kosten
- kon
- CPU
- en je merk te creëren
- Wij creëren
- cruciaal
- gewoonte
- gegevens
- beslissingen
- verlagen
- deep
- diepgaand leren
- Standaard
- bepalen
- gedemonstreerd
- implementeren
- ingezet
- het inzetten
- inzet
- detail
- gedetailleerd
- gegevens
- ontwikkelen
- ontwikkelaars
- Ontwikkeling
- apparaat
- systemen
- anders
- onderscheiden
- Afmeting
- direct
- weergeven
- duiken
- diversen
- havenarbeider
- Nee
- doen
- beneden
- gedurende
- e
- elk
- Vroeger
- ecosysteem
- effectief
- doeltreffend
- efficiënt
- zonder inspanning
- beide
- anders
- inschepen
- machtigt
- in staat stellen
- maakt
- waardoor
- omvatten
- Endpoint
- eindpunten
- verhogen
- verbeteren
- verzekeren
- waarborgt
- Geheel
- Milieu
- essentieel
- oprichting
- Ether (ETH)
- onderzoek
- voorbeeld
- overtreffen
- overschreden
- uitstekend
- experiment
- Verklaren
- exploratie
- Verkennen
- Gezicht
- Mislukt
- vals
- familie
- SNELLE
- sneller
- snelste
- weinig
- Dien in
- Bestanden
- vondsten
- Voornaam*
- Focus
- gericht
- volgend
- Voor
- formaat
- Achtergrond
- frameworks
- Gratis
- oppompen van
- vol
- GPU
- GPU's
- groot
- Groep
- handvat
- Behandeling
- Hardware
- Hebben
- gehoor
- het helpen van
- haar
- Hoge
- hoger
- wandelen
- gastheer
- Hosting
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- Naaf
- KnuffelenGezicht
- i
- ideaal
- if
- illustreren
- beeld
- afbeeldingen
- uitvoering
- implementaties
- importeren
- belangrijk
- in
- diepgaande
- omvatten
- omvat
- Inclusief
- nemen
- Laat uw omzet
- in toenemende mate
- individueel
- individuen
- industrieën
- informatie
- op de hoogte
- eerste
- eerste
- inwijding
- invoer
- ingangen
- inzichten
- installeren
- instantie
- gevallen
- instructies
- Integreren
- Intelligentie
- interactie
- belang
- geïnteresseerd
- Interface
- in
- problemen
- IT
- HAAR
- Jobomschrijving:
- Vacatures
- jpg
- sleutel
- kennis
- bekend
- Landschap
- groter
- tot slot
- Wachttijd
- later
- laatste
- lagen
- leiden
- leren
- minst
- leveraging
- Vergunning
- beperking
- Beperkt
- Lijn
- Lijst
- laden
- het laden
- lokaal
- plaats
- lang
- langer
- Laag
- machine
- machine learning
- gemaakt
- Hoofd
- maken
- MERKEN
- maken
- beheer
- beheren
- Maps
- Mei..
- vermeld
- Metadata
- methode
- methoden
- Metriek
- macht
- milliseconden
- minuten
- MIT
- ML
- model
- modellen
- matig
- Moments
- Grensverkeer
- meer
- Films
- veel
- meervoudig
- Dan moet je
- Genoemd
- nationaal
- nationale parken
- noodzakelijk
- Noodzaak
- nodig
- netwerk
- Neural
- neuraal netwerk
- volgende
- nlp
- geen
- nota
- notitieboekje
- Opmerkingen
- notificatie
- meldingen
- opmerkend
- nu
- aantal
- nummers
- object
- objecten
- waarnemen
- of
- bieden
- het aanbieden van
- Aanbod
- officieel
- offline
- on
- eens
- EEN
- Slechts
- open source
- exploiteert
- Keuze
- Opties
- or
- bestellen
- organisaties
- OS
- Overige
- anders-
- uit
- overzicht
- pakket
- Paketten
- parameter
- parameters
- parken
- passeren
- pad
- uitvoeren
- prestatie
- fase
- pijpleiding
- centraal
- geplaatst
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- dan
- punten
- mogelijk
- Post
- potentieel
- voorspelling
- Voorspellingen
- voorkomen
- vorig
- primair
- verwerkt
- verwerking
- Gegevensverwerker
- project
- naar behoren
- prototyping
- zorgen voor
- mits
- biedt
- het verstrekken van
- Python
- pytorch
- kwaliteit
- reeks
- real-time
- rijk
- erkenning
- aanbevolen
- opgenomen
- Gereduceerd
- verwijzen
- achteloos
- verwant
- Releases
- niet vergeten
- verwijderen
- verwijdert
- bewaarplaats
- te vragen
- verzoeken
- vereisen
- nodig
- vereiste
- onderzoekers
- respectievelijk
- antwoord
- reacties
- verantwoordelijk
- resultaat
- resulteerde
- Resultaten
- behouden
- heropleiding
- terugkeer
- sagemaker
- dezelfde
- Bespaar
- gered
- besparing
- Schaalbaarheid
- Scale
- balans
- gepland
- wetenschappers
- script
- scripts
- Tweede
- seconden
- sectie
- segmenten
- kiezen
- gekozen
- selecteren
- -Series
- service
- Diensten
- reeks
- het instellen van
- settings
- Delen
- ze
- moet
- vertoonde
- Shows
- stillegging
- aanzienlijke
- Eenvoudig
- vereenvoudigt
- Maat
- maten
- Klein
- kleinere
- So
- Software
- oplossing
- specifiek
- specifiek
- gespecificeerd
- toespraak
- Spraakherkenning
- snelheid
- Uitgaven
- gesproken
- begin
- Land
- state-of-the-art
- Stap voor
- Stappen
- mediaopslag
- strategieën
- volgend
- geslaagd
- dergelijk
- plotseling
- geschikt
- ondersteuning
- Ondersteuning
- steunen
- zeker
- ontstaat
- Systems
- tafel
- Nemen
- het nemen
- Taak
- taken
- Technologie
- neem contact
- dat
- De
- Brittannië
- hun
- Ze
- harte
- Er.
- daarom
- Deze
- ze
- dit
- drie
- niet de tijd of
- Tijdreeksen
- keer
- naar
- tools
- fakkel
- verkeer
- Trainen
- getraind
- Transformeren
- transformator
- transformers
- leiden
- veroorzaakt
- tv
- TV Series
- twee
- type dan:
- typisch
- Uk
- voor
- ontgrendelen
- op
- us
- .
- gebruikt
- gebruiksvriendelijke
- gebruikers
- gebruik
- utility
- gebruik maken van
- Gebruik makend
- waardevol
- waarde
- variabele
- divers
- groot
- versie
- visie
- Stem
- spraakopdrachten
- volume
- wachten
- willen
- was
- we
- web
- webservices
- GOED
- waren
- wanneer
- telkens als
- welke
- Fluisteren
- breed
- Grote range
- Met
- binnen
- workflow
- Bedrijven
- waard
- het schrijven van
- u
- Your
- zephyrnet