Gegevens zijn de levensader van alle online bedrijven en de manier waarop we met elkaar omgaan.
Elke dag creëren we ongeveer 2.5 biljoen bytes Van de gegevens. Dat is veel. Maar wat verrassend is, is dat 90% van die gegevens is ongestructureerd.
Het heeft geen specifieke structuur. Dus om de gegevens te begrijpen, moeten we echt begrijpen hoe we met ongestructureerde gegevens moeten omgaan.
Laten we zonder verder oponthoud diep in ongestructureerde gegevens duiken.
Wat is ongestructureerde data?
Alles in deze digitale wereld bestaat uit data. Gegevens kunnen van twee formaten zijn: ze kunnen een goede structuur volgen of niet.
Alle informatie die niet in een bepaalde volgorde of schema of in een specifieke structuur is gerangschikt waardoor deze gemakkelijk leesbaar is voor anderen, wordt ongestructureerde gegevens genoemd.
Ongestructureerde gegevens hebben geen structuur of formaat waardoor ze gemakkelijk herkenbaar zijn. Ongestructureerde gegevens zijn in hoge mate op tekst gebaseerd, zoals gegevens, feiten en antwoorden op open enquêtes, maar kunnen ook niet-tekstueel zijn, zoals afbeeldingen, audio of video.
Lees verder: Hoe gegevens uit PDF extraheren?
Wat zijn de voorbeelden van ongestructureerde data?
Als je aan data denkt, denk dan aan alle soorten data die geen herhalend of herkenbaar patroon hebben, en dat zijn ongestructureerde data. Het kan tekstueel, niet-tekstueel, door mensen of door een machine worden gegenereerd. Hier zijn enkele voorbeelden van ongestructureerde gegevens:
Tekstgegevens
De gegevens die in een e-mail of schriftelijke vorm beschikbaar zijn, worden tekstgegevens genoemd. Tekstberichten, geschreven documenten, Word, PDF's en andere bestanden hiervan zijn voorbeelden van ongestructureerde gegevens.
Multi-media berichten
Eén type ongestructureerde gegevens zijn multimediaberichten. Multimediagegevens omvatten afbeeldingen (JPEG, PNG, GIF), audio- of videoformaat. Multimediaberichten zijn een mix van complexe code die geen soortgelijk patroon kent.
Alle afbeeldingen, video's of audiobestanden kunnen gecodeerde binaire codes zijn die geen patroon volgen en daarom ongestructureerde gegevens zijn. Wat zie je hier?

Nou, het is eigenlijk een afbeelding van een rode auto.

De afbeeldingen en afbeeldingen hebben observatie nodig om te begrijpen en hun gegevens zijn niet volledig samengesteld, daarom worden dit de ongestructureerde gegevens genoemd.
Website inhoud
Alle websites staan vol met informatie die beschikbaar is in de vorm van lange paragrafen, verspreide en ongeorganiseerde formulieren. Dit is een soort data met waardevolle informatie, maar toch is het niet de moeite waard omdat de juiste samenstelling van data vereist is.
Sensor Data - IoT devices
Het Internet of Things is een fysiek apparaat dat informatie over de omgeving verzamelt en de gegevens terugstuurt naar de cloud. IoT-apparaten sturen gevoelige sensorgegevens terug die ongestructureerd kunnen zijn. Voorbeelden van IoT-apparaten die sensorgegevens verzenden, zijn apparaten voor verkeersmonitoring, muziekapparaten zoals Alexa, Google Home, enz.
E-mail wordt door bedrijven veel gebruikt als een van de belangrijkste communicatiekanalen. E-mails kunnen worden geclassificeerd als semi-gestructureerd of ongestructureerd. Er zijn veel parseertools beschikbaar die de e-mailinformatie schrapen om de details te begrijpen.
Zakelijke documenten
Bedrijven hebben te maken met verschillende soorten documenten, zoals pdf's, e-mails, facturen, bestellingen en meer. Alle documenten hebben verschillende structuren. Om zo te extraheer gegevens uit pdf's, en andere papieren documenten die bedrijven kunnen gebruiken intelligente documentverwerkingssoftware zoals Nanonets.
Meer dan 10,000 gebruikers gebruiken nanonetten om ongestructureerde gegevens om te zetten in gestructureerde gegevens met een nauwkeurigheid van meer dan 98%. Probeer het eens?
Wat is het verschil tussen gestructureerde en ongestructureerde data?
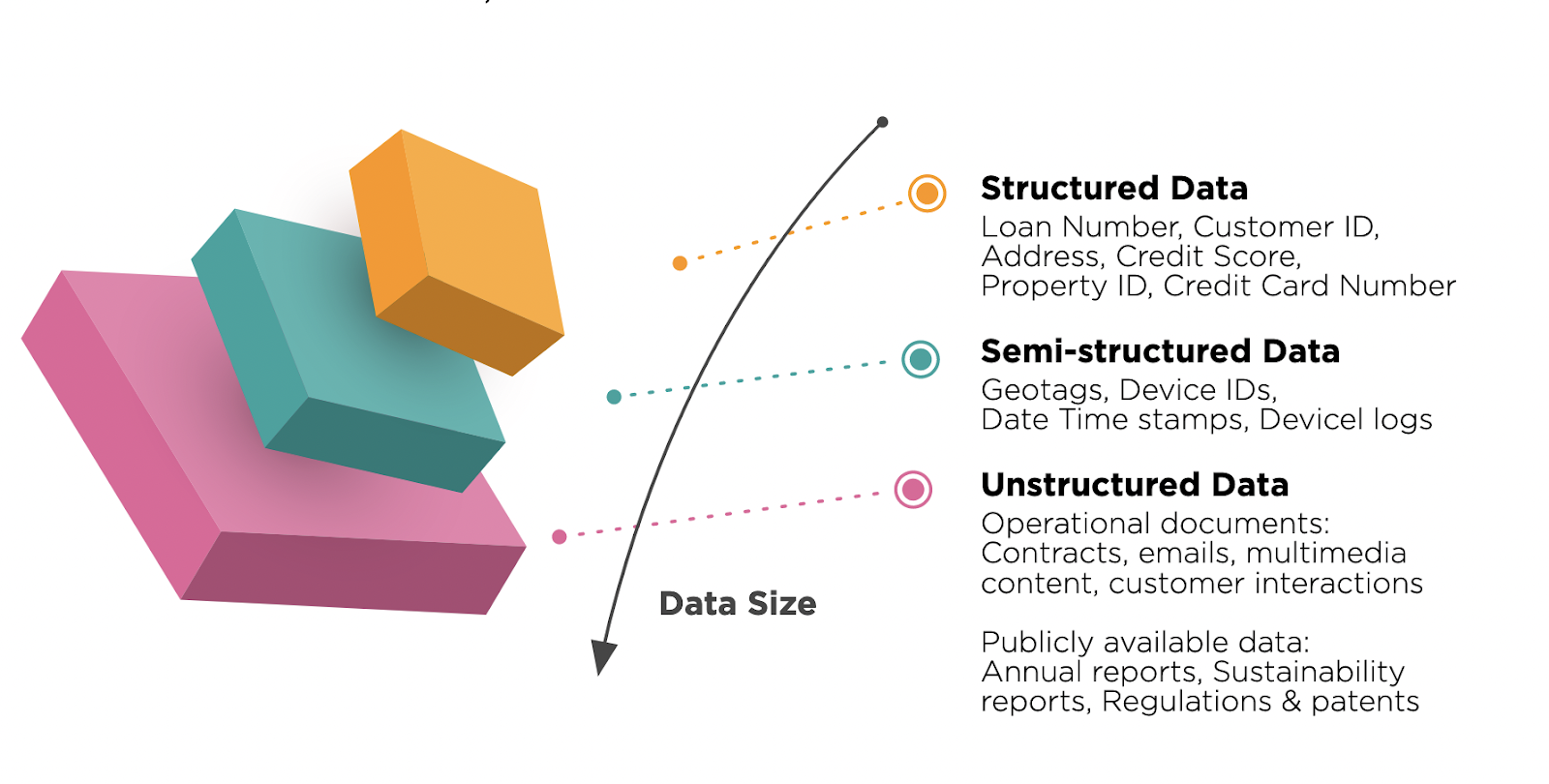
Big data omvat gestructureerde, semi-gestructureerde en ongestructureerde data. Al dit soort data hebben veel te bieden. Laten we hun verschillen in detail bekijken.
Gestructureerde gegevens zijn een ander soort gegevens die een bepaald patroon volgen en gemakkelijk te herkennen zijn. Deze vorm van data is beschikbaar in RDBMS en kent vele toepassingen. Er is een korte tabel met beschrijvingen tussen zowel gestructureerde als ongestructureerde gegevens:
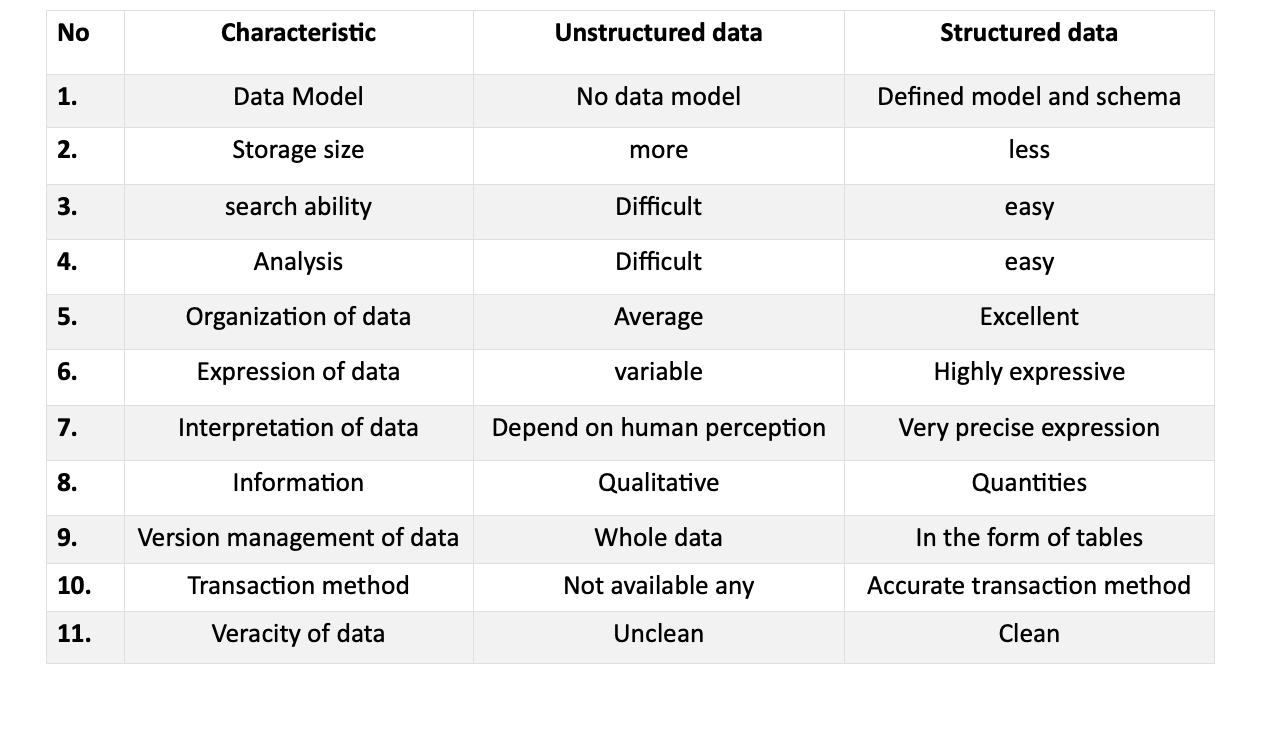
Gegevensmodel
- Ongestructureerde gegevens komen vaak in de vorm van grote pdf's, tekst- of multimediabestanden, terwijl gestructureerde gegevens nauwkeurig en georganiseerd zijn.
- Het gedefinieerde model van gestructureerde gegevens maakt het gemakkelijk en betrouwbaar om te bestuderen en te raadplegen.
- Grote bestanden vereisen een aanzienlijke opslagcapaciteit, waardoor gestructureerde gegevens wenselijker worden vanwege de aanpasbare bestandsgrootte, vaak in tabelvorm.
Data-analyse
- De analyse bepaalt de relevantie en nauwkeurigheid van de gegevens.
- Ongestructureerde data kunnen onbetrouwbare of dubbelzinnige kennis bevatten, in tegenstelling tot gestructureerde data die georganiseerd en aangepast zijn.
- Gestructureerde gegevens hebben de voorkeur vanwege het gemak van analyse in vergelijking met ongestructureerde gegevens.
Doorzoekbaarheid
- Ongestructureerde data-extractie kan chaotisch zijn, waardoor het zoeken naar belangrijke punten tijdrovend is.
- Gestructureerde gegevens zijn dankzij de organisatie ervan gemakkelijk doorzoekbaar.
- Ongestructureerde gegevens kunnen vanwege de omvang en het formaat moeilijk te begrijpen en te doorzoeken zijn.
Visionaire analyse
- De gerichte analyse van ongestructureerde data kan waardevolle inzichten opleveren.
- Gegevens in een kort, actueel formaat trekken meer belangstelling dan lange paragrafen.
- Gestructureerde gegevens zorgen voor een snellere authenticatie van informatie, waardoor gebruikers tijd besparen.
Wat zijn de uitdagingen bij het werken met ongestructureerde data?
De ongestructureerde gegevens hebben een zeer lange vorm en daarom is ongestructureerde gegevensextractie noodzakelijk. Het werkende personeel wordt geconfronteerd met veel uitdagingen bij het werken met ongestructureerde gegevens. Allereerst zijn dit soort gegevens beschikbaar in een bulktekst van een andere vorm, daarom duurt het te lang om met deze gegevens te werken. Ten tweede, als de gegevens beschikbaar zijn in grote bestanden, zoals hoogstwaarschijnlijk ongestructureerde gegevens, neemt dit te veel opslagruimte in beslag. De kwaliteit van de gestructureerde gegevens is dat ze in zeer nauwkeurige en tabelvorm worden weergegeven, daarom is het extraheren van de gegevens erg eenvoudig.
Gecompromitteerde relevantie
Het blijkt dat ongestructureerde gegevens veel informatie bevatten die niet waardevol en hoogst onnauwkeurig en irrelevant is. De nauwkeurigheid van de gegevens moet op de best mogelijke manier worden gehandhaafd. Daarom is de grootste uitdaging bij ongestructureerde gegevensextractie om de kwaliteit van relevante en nauwkeurige gegevens intact te houden.
Opbergen
Sinds de tijd van digitalisering van de wereld in de 20e eeuw, komt datasucces met het innemen van minder opslagruimte en meer informatie. Vroeger werden gegevens opgeslagen in veel grote bestanden, de ongestructureerde gegevens nemen te veel opslagruimte in beslag dat het nu een uitdaging is om met al deze veranderingen om te gaan.
Omgaan met ongestructureerde data kost veel tijd. Het duurde te lang om informatie uit ongestructureerde data te halen als het gaat om de urgentie van de data. Daarom duurden de data te lang en is het in de urgentie erg moeilijk om alle kennis uit de data te halen.
Sinds het begin van de digitalisering zijn er veel tools ontstaan om de uitdagingen van ongestructureerde data-extractie aan te pakken. Om tijd te besparen is de ongestructureerde data-extractie via AI verbeterd tools voor gegevensextractie zoals Nanonets is zeer betrouwbaar omdat het grondige en totaal relevante informatie voor gegevens biedt. De relevantie van de gegevens is erg belangrijk omdat het een belangrijk tijdbesparend hulpmiddel is voor het personeel en de analisten. Met deze datastrategieën kan men op eenvoudige wijze waardevolle informatie uit de data interpreteren.
Hoe kun je Nanonetten gebruiken om ongestructureerde data om te zetten in inzichten?
Nanonets is a platform that employs AI, ML & NLP techniques to help users derive insights from unstructured data. Here's a simplified step-by-step guide on how to achieve this:
- Data Collection: Verzamel uw ongestructureerde gegevens. Dit kan de vorm hebben van afbeeldingen, tekstbestanden, pdf's, video's of audiobestanden.
- Uploaden naar Nanonetten: Upload uw ongestructureerde gegevens naar het Nanonets-platform met behulp van uw account. Jij kan maak de jouwe hier. Dit kan rechtstreeks worden gedaan of via API's die in de app aanwezig zijn.
- Kies of train een model: Now, based on the document that you're uploading, select an OCR model. Nanonets provides pre-trained models for many document types. . Choose a model that fits your data type and objective. If none of the pre-trained models suit your needs, you can train a custom OCR model using your data.
- Model toepassen op gegevens: Zodra uw model klaar is, past u het toe op uw documenten. Het model haalt gegevens uit uw documenten en converteert deze naar een gestructureerd formaat zoals tabel, excel, csv, wat gemakkelijker te lezen is.
- Herzien en aanpassen: Check the results from the model's analysis. If they aren't accurate enough, you can fine-tune the model by using Nanonets' drag and drop platform until the results meet your needs.
- Inzichten extraheren: Gebruik ten slotte de gestructureerde gegevens om inzichten te verkrijgen. U kunt de gegevens exporteren en gegevensanalyses uitvoeren om inzichten te verkrijgen.
Houd er rekening mee dat de specifieke stappen kunnen variëren, afhankelijk van het specifieke type ongestructureerde gegevens en de inzichten die u wilt verkrijgen. Nanonetten kunnen het proces automatiseren met geautomatiseerde workflows, krachtige OCR-software en een gebruikersinterface zonder code.
We're living in a transformative era where digitalization simplifies business growth and decision-making. Unstructured data extraction has streamlined various processes due to its time-saving and fast operation.
Ongestructureerde gegevens, in wezen grondstoffen, worden verwerkt om waardevolle informatie te extraheren voor eenvoudige opslag. De tabelvorm verbetert de toegankelijkheid. Gegevensquery's zijn georganiseerd in gebruiksvriendelijke, goed gestructureerde vormen, zonder dubbelzinnigheid, waardoor ze gemakkelijk te lezen zijn. Van de verschillende beschikbare data-extractietools draagt elk bij aan de efficiëntie van het systeem en de verbetering van het milieu.
Ongestructureerde gegevensextractie is van cruciaal belang in alle sectoren, waarbij de authenticiteit van gegevens behouden blijft. De banksector gebruikt deze instrumenten bijvoorbeeld voor bedrijfsgroei.
In scientific research, unstructured data extraction tools condense data into a more precise form, irrespective of whether it's human or machine-generated, providing valuable insights.
Bedrijven in alle sectoren gebruiken ongestructureerde data-extractietechnieken om hun bedrijfsdocumenten te begrijpen en een extra laag van intelligentie toe te voegen aan hun analyses. Onderstaande figuur laat de opkomst van het gebruik van ongestructureerde data in verschillende industrieën zien.
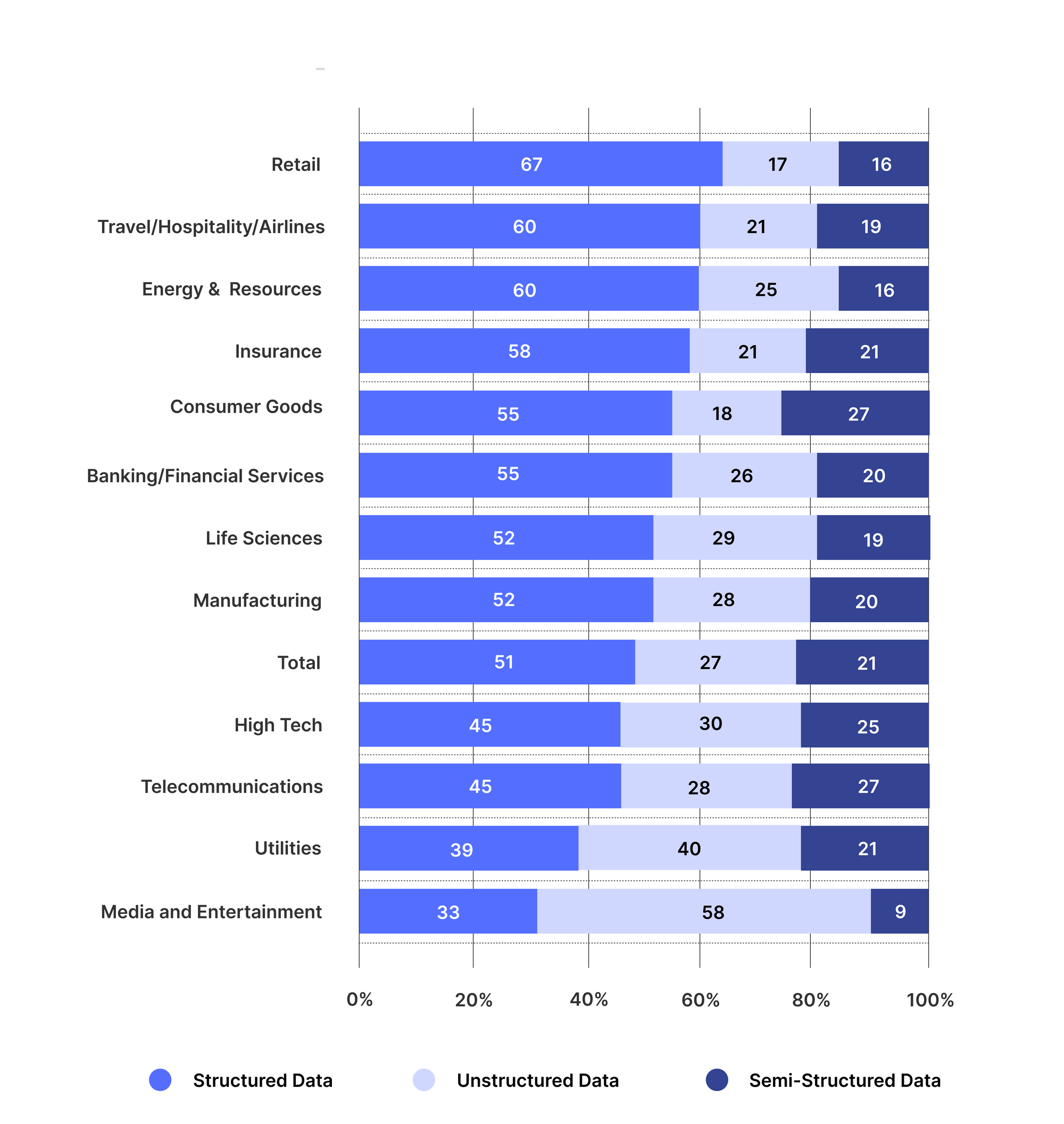
[Bron: TCS-onderzoek]
Hier zijn enkele voorbeelden van hoe verschillende industrieën intelligente documentverwerkingsplatforms zoals Nanonets gebruiken voor ongestructureerde gegevensextractie en het verhogen van hun productiviteit.
Banken
Banken gebruiken IDP-platforms om inzichten te extraheren uit ongestructureerde gegevensbronnen zoals claims, klantformulieren, KYC-documenten, oproeprecords, financiële rapporten en meer.
Lees verder: RPA in het bankwezen en Bankautomatisering
Verzekering
Verzekeringen zijn een sterk gereguleerde sector. Het moet documentverificatie en identiteitsverificatie uitvoeren bij elke stap van de verzekeringsclaimprocedures. Verzekeringsmaatschappijen gebruiken geautomatiseerde documentverwerkingsplatforms om claimprocessen, risicobeheer en andere op regels gebaseerde functies te automatiseren. Het verzekeringsclaimproces bevat veel ongestructureerde gegevens. Ongestructureerde gegevensextractie Door het gebruik van AI-verbeterde platforms zoals Nanonets wordt het proces van verzekeringsclaims eenvoudig omdat het selectieve gegevensextractie uit afbeeldingen, pdf's, video's, audio, enz. mogelijk maakt.
Lees verder: Verzekeringsautomatisering, Verzekering OCR en RPA in verzekeringen
Gezondheid
Het bieden van een uitzonderlijke patiëntervaring draait om het bieden van betere service, het verkorten van de wachttijden voor de patiënt en ervoor zorgen dat het personeel niet overwerkt raakt. Gebruik makend van IDP-platform om inzichten te extraheren uit ongestructureerde gegevensbronnen zoals de stem van klantgegevens, patiëntenonderzoeken, EPD's, klachten van klanten, regelgevende websites en literatuuronderzoek helpt de gezondheidszorg om een betere patiëntervaring te garanderen.
Lees verder: Automatisering van de gezondheidszorg en AI in de gezondheidszorg
Vastgoedbedrijven werken met meerdere mensen tegelijk, zoals klanten, bouwers, huurders, verkopers, concurrenten en eigenaren van onroerend goed. Het gebruik van geautomatiseerde documentverwerkingssoftware kan vastgoedinstellingen helpen om rijke profielen van genoemde belanghebbenden te creëren en de gegevensextractie uit ongestructureerde gegevensbronnen zoals huurcontracten, contracten, taxatiepapieren van onroerend goed, enz. te stroomlijnen.
Conclusie
Data is de nieuwe olie. Het bedrijf dat ongestructureerde gegevensextractie beheerst, kan het volledige potentieel van bedrijfsgegevens ontsluiten. Nanonetten stellen ondernemingen in staat hun documentverwerking te automatiseren en kunnen op slimme wijze gegevens uit elk soort document extraheren.
Nanonetten online OCR & OCR API hebben veel interessante use cases that kan uw bedrijfsprestaties optimaliseren, kosten besparen en de groei stimuleren. Ontdek hoe de use cases van Nanonets van toepassing kunnen zijn op uw product.
FAQ
Wat zijn de voordelen van het gebruik van ongestructureerde data?
Ongestructureerde data zijn moeilijk te begrijpen, interpreteren en direct te gebruiken, maar dat is niet het enige. Er zijn veel voordelen aan het gebruik van ongestructureerde gegevens, zoals hieronder vermeld:
Geen vast formaat
Ongestructureerde gegevens ondersteunen gegevens van alle formaten en formaten. Alle soorten gegevens die geen juiste volgorde hebben, kunnen worden geclassificeerd als ongestructureerde gegevens. Het kan handig zijn om de horizon van soorten gegevens te verbreden.
Geen schema
Zoals hierboven besproken, hebben ongestructureerde gegevens geen vaste volgorde en ook geen vast schema. Dit is wat ongestructureerde gegevensextractie voor de meeste onderdelen moeilijk maakt.
Flexibiliteit
Aangezien ongestructureerde gegevens geen structuur hebben, kunnen ze elk formaat hebben. Hierdoor is het qua structuur vloeibaar.
Draagbaar en schaalbaar
Ongestructureerde gegevens zijn beter overdraagbaar en schaalbaarder in vergelijking met semi-gestructureerde en gestructureerde gegevens.
Veel zakelijke toepassingen
Aangezien 80% van de enterprise bedrijfsdata ongestructureerd is, zijn er veel toepassingen voor deze data. Ongestructureerde bedrijfsgegevens worden gebruikt voor verschillende gebruiksscenario's voor bedrijfsanalyses. Bijvoorbeeld presentaties, bedrijfsvideo's, inzicht in klantprofielen, etc.
Hoe zet u ongestructureerde data om in gestructureerde data?
Terwijl het werken met grote en omvangrijke gegevens een hectische taak kan zijn. Om tijd te besparen en de originaliteit en nauwkeurigheid van de gegevens te behouden, moet deze zodanig worden ingekort dat alleen de noodzakelijke informatie overblijft. De ongestructureerde gegevensextractie heeft verschillende methoden en het belang ervan wordt duidelijk aangetoond door alle hierboven verstrekte informatie. Het verschil tussen gestructureerd en ongestructureerd geeft belangrijke aanwijzingen over de gegevens. U kunt de volgende stappen gebruiken om ongestructureerde gegevens om te zetten in gestructureerde gegevens.
Stap 1: Heb een duidelijk doel voor ogen
Geen enkel project mag ooit beginnen zonder een reeks meetbare doelen te hebben. Met een duidelijk beeld van het einddoel van welke inzichten je wilt verkrijgen, wordt het makkelijker om de volgende stappen af te ronden.
Stap 2: Voltooi de gegevensbronnen
Gegevens zijn overal. Maar om met de conversie te beginnen, moet u de gegevensbronnen identificeren om uw ongestructureerde gegevens te tekenen. Strategieën voor gegevensextractie zouden voor verschillende gegevensbronnen anders zijn. Met Nanonetten kunnen gebruikers gegevens verzamelen uit meerdere bronnen zoals Gmail, dropbox, Outlook, desktop, enz.
De gegevens kunnen worden geëxtraheerd uit de grote pdf-bestanden, afbeeldingen en andere tekstvormen.
Stap 3: Standaardisatie van gegevens
De derde stap is om te weten wat u moet doen met ongestructureerde gegevensextractie. De analist moet een idee hebben over het uiteindelijke resultaat van de ongestructureerde data.
Als u de gegevens hebt geselecteerd, is de volgende stap het definitief maken van de uitkomst van de gegevens. Als de gegevens een variabele vorm hebben, moet de analist deze standaardiseren voordat er een analyse kan worden uitgevoerd. Deze specifieke stap omvat het opschonen en standaardiseren van de gegevensformaten voor de volgende stappen.
Stap 4: Selectie van de data-extractietechnologie:
Na het begrijpen van de gegevensbronnen en de methode om de gegevens te standaardiseren, is het belangrijk om de software te finaliseren die u wilt gebruiken voor het implementeren van deze stappen. IDP-platforms zoals Nanonets helpen organisaties om verbinding te maken, gegevens te extraheren en te standaardiseren voor verdere analyse.
De gegevens worden door verschillende software verzameld, de volgende stap is het vinden van de technologie waarmee de gegevens naar de software worden overgedragen. Hiervoor wordt een rationeel databasebeheersysteem (RDBMS) gebruikt. Deze software en technologie helpen om eenvoudig technologiegebruik te krijgen.
Stap 5: Het gegevensopslagsysteem selecteren
Het gegevensopslagsysteem wordt geselecteerd op basis van het type technologie dat u zoekt. Het moet een hoge beschikbaarheid, hoge snelheid en andere functies hebben. Al deze functies, samen met de realtime opslagcapaciteit, zorgen voor een hoog opslagsysteem.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://nanonets.com/blog/unstructured-data-extraction/
- : heeft
- :is
- :niet
- :waar
- 1
- 12
- 24
- 50
- 7
- a
- Over
- over het
- boven
- toegang
- de toegankelijkheid
- Account
- nauwkeurigheid
- accuraat
- Bereiken
- over
- werkelijk
- toevoegen
- verstelbaar
- gecorrigeerd
- voordelen
- komst
- AI
- Alexa
- Alles
- toelaten
- toestaat
- langs
- ook
- allemaal samen
- Dubbelzinnigheid
- onder
- an
- analyse
- analist
- analisten
- analytics
- en
- Nog een
- elke
- APIs
- gebruiken
- toepassingen
- Solliciteer
- ZIJN
- rond
- geregeld
- AS
- At
- Trekt aan
- audio
- authenticatie
- echtheid
- automatiseren
- geautomatiseerde
- beschikbaarheid
- Beschikbaar
- terug
- Bankieren
- banken sector
- Banken
- gebaseerde
- BE
- omdat
- worden
- wordt
- vaardigheden
- wezen
- onder
- BEST
- Betere
- tussen
- Groot
- Grootste
- boost
- zowel
- Box camera's
- bouwers
- bedrijfsdeskundigen
- zakelijke prestaties
- ondernemingen
- maar
- by
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- CAN
- Inhoud
- auto
- gevallen
- Eeuw
- uitdagen
- uitdagingen
- Wijzigingen
- kanalen
- controle
- Kies
- vorderingen
- geklasseerd
- Schoonmaak
- duidelijk
- Sluiten
- Cloud
- code
- verzamelen
- verzamelt
- COM
- hoe
- komt
- communiceren
- Bedrijven
- afstand
- vergeleken
- concurrenten
- klachten
- compleet
- complex
- samengesteld
- omvat
- conclusie
- Verbinden
- bevat
- contracten
- Camper ombouw
- converteren
- Kosten
- kon
- en je merk te creëren
- cruciaal
- gewoonte
- klant
- klantgegevens
- Klanten
- gegevens
- gegevens Analytics
- gegevensopslag
- Database
- dag
- transactie
- Besluitvorming
- deep
- diepe duik
- gedefinieerd
- desktop
- detail
- gegevens
- bepaalt
- apparaat
- systemen
- verschil
- verschillen
- anders
- moeilijk
- digitaal
- digitale wereld
- digitalisering
- direct
- besproken
- do
- document
- documenten
- doet
- gedaan
- trekken
- Val
- twee
- elk
- gemak
- gemakkelijker
- gemakkelijk
- En het is heel gemakkelijk
- doeltreffendheid
- beide
- e-mails
- telt
- versleutelde
- einde
- Verbetert
- verbeteren
- genoeg
- verzekeren
- zorgen
- Enterprise
- bedrijven
- milieu
- Tijdperk
- in wezen
- vastgoed
- etc
- Ether (ETH)
- OOIT
- Alle
- voorbeeld
- voorbeelden
- Excel
- uitzonderlijk
- Uitvouwen
- ervaring
- exporteren
- extra
- extract
- extractie
- geconfronteerd
- feiten
- SNELLE
- Voordelen
- Figuur
- Dien in
- Bestanden
- gevuld
- finale
- afronden
- Tot slot
- financieel
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- bedrijven
- Voornaam*
- vast
- vloeistof
- gericht
- volgen
- volgend
- volgt
- Voor
- Forbes
- formulier
- formaat
- formulieren
- oppompen van
- vol
- functies
- verder
- verzamelen
- voortbrengen
- krijgen
- gif
- Geven
- gmail
- doel
- Doelen
- Kopen Google Reviews
- Google Startpagina
- gids
- Hard
- Hebben
- met
- Gezondheid
- gezondheidszorg
- hard
- hulp
- helpt
- hier
- Hoge
- zeer
- Home
- horizont
- Hoe
- How To
- http
- HTTPS
- menselijk
- idee
- identificeren
- Identiteit
- identiteit verificatie
- if
- beeld
- afbeeldingen
- uitvoering
- belangrijk
- verbetering
- in
- onnauwkeurig
- industrieën
- -industrie
- informatie
- inzichten
- instantie
- instellingen
- verzekering
- Intelligentie
- Intelligent
- Intelligente documentverwerking
- interactie
- belang
- interessant
- Interface
- Internet
- internet van dingen
- in
- iot
- iot apparaten
- ongeacht
- IT
- HAAR
- Soort
- blijven
- kennis
- KYC
- Groot
- lagen
- links
- minder
- als
- literatuur
- leven
- lang
- Kijk
- op zoek
- lot
- onderhouden
- groot
- maken
- MERKEN
- maken
- management
- beheersysteem
- veel
- materiaal
- Maak kennis met
- vermeld
- berichten
- methode
- methoden
- macht
- ML
- model
- modellen
- Grensverkeer
- meer
- meest
- veel
- Multimedia
- meervoudig
- Muziek
- noodzakelijk
- Noodzaak
- behoeften
- New
- volgende
- nlp
- geen
- nu
- doel van de persoon
- verkrijgen
- OCR
- OCR-software
- of
- bieden
- vaak
- Olie
- on
- eens
- EEN
- online.
- Online bedrijven
- Slechts
- operatie
- Optimaliseer
- or
- bestellen
- orders
- organisatie
- organisaties
- Georganiseerd
- oorspronkelijkheid
- Overige
- Overig
- Resultaat
- Outlook
- eigenaren
- op papier gebaseerd
- papieren
- bijzonder
- onderdelen
- verleden
- patiënt
- Patronen
- Mensen
- uitvoeren
- prestatie
- Fysiek
- Foto's
- platform
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- punten
- mogelijk
- potentieel
- krachtige
- nauwkeurig
- bij voorkeur
- presenteren
- Presentaties
- cadeautjes
- primair
- waarschijnlijk
- processen
- verwerking
- Product
- produktiviteit
- Profielen
- project
- gepast
- eigendom
- mits
- biedt
- het verstrekken van
- doel
- kwaliteit
- queries
- sneller
- quintillion
- Rationeel
- Rauw
- RE
- Lees
- klaar
- vast
- vastgoed
- real-time
- werkelijk
- herkennen
- archief
- Rood
- vermindering
- regelmatig
- gereguleerd
- regelgevers
- relevantie
- relevante
- betrouwbaar
- stoffelijk overschot
- Verhuur
- Rapporten
- vereisen
- nodig
- onderzoek
- reacties
- resultaat
- Resultaten
- onthullen
- beoordelen
- Rijk
- Risico
- risicobeheer
- ruw
- s
- dezelfde
- Bespaar
- besparing
- schaalbare
- verspreid
- schema
- Wetenschappelijk onderzoek
- Ontdek
- Tweede
- sector
- zien
- gezien
- gekozen
- selecteren
- selectief
- sturen
- verzending
- verzendt
- zin
- gevoelig
- Volgorde
- service
- reeks
- Bermuda's
- verkort
- moet
- getoond
- Shows
- betekenis
- aanzienlijke
- gelijk
- vereenvoudigd
- Maat
- maten
- So
- Software
- sommige
- bron
- bronnen
- specifiek
- Medewerkers
- stakeholders
- standaardiseren
- begin
- Stap voor
- Stappen
- Still
- mediaopslag
- eenvoudig
- strategieën
- gestroomlijnd
- gestroomlijnd
- structuur
- gestructureerde
- gestructureerde en ongestructureerde data
- Studie
- succes
- dergelijk
- Pak
- steunen
- verrassend
- nabijgelegen
- Enquête
- system
- tafel
- Nemen
- neemt
- het nemen
- Taak
- technieken
- Technologie
- termen
- neem contact
- dat
- De
- de informatie
- de wereld
- hun
- Ze
- Er.
- daarom
- Deze
- ze
- ding
- spullen
- denken
- Derde
- dit
- overal
- niet de tijd of
- tijdrovend
- keer
- naar
- ook
- nam
- tools
- tools
- verkeer
- Trainen
- overgedragen
- transformatieve
- proberen
- twee
- type dan:
- types
- begrijpen
- begrip
- anders
- openen
- tot
- up-to-date
- Uploaden
- urgentie
- .
- gebruikt
- Gebruiker
- User Interface
- gebruiksvriendelijke
- gebruikers
- gebruik
- maakt gebruik van
- waardevol
- Waardevolle informatie
- Taxatie
- variëteit
- divers
- vendors
- Verificatie
- zeer
- via
- Video
- Video's
- Stem
- wachten
- willen
- was
- Manier..
- we
- websites
- Wat
- Wat is
- wanneer
- of
- welke
- en
- Waarom
- wijd
- wil
- Met
- zonder
- Woord
- workflows
- werkzaam
- wereld
- zou
- geschreven
- u
- Your
- zephyrnet