In de wereld van vandaag beheren klanten enorme hoeveelheden gegevens in hun Amazon eenvoudige opslagservice (Amazon S3) datameren, waarvoor ingewikkelde datapijplijnen nodig zijn om voortdurend de veranderingen in de data-indeling te begrijpen en deze beschikbaar te maken voor consumerende systemen. AWS lijm crawlers bieden een eenvoudige manier om gegevens te catalogiseren in de AWS Glue Data Catalog, waardoor het zware werk als het gaat om schemabeheer en gegevensclassificatie wordt weggenomen. AWS Glue-crawlers extraheren het gegevensschema en de partities uit Amazon S3 om de gegevenscatalogus automatisch te vullen, waardoor de metagegevens actueel blijven.
Maar omdat de gegevens in de loop van de tijd exponentieel groeien, kan het aantal partities in een bepaalde tabel aanzienlijk toenemen. Omdat analysediensten zoals Amazone Athene Als u een tabel opvraagt die miljoenen partities bevat, neemt de tijd die nodig is om de partitie op te halen toe, waardoor de runtime van de query kan toenemen.
Tegenwoordig is de ondersteuning voor de AWS Glue-crawler uitgebreid om automatisch partitie-indexen toe te voegen voor nieuw ontdekte tabellen om de queryverwerking op de gepartitioneerde dataset te optimaliseren. Wanneer de crawler nu een nieuwe gegevenscatalogustabel maakt tijdens een crawlerrun, wordt er standaard ook een partitie-index gemaakt, met de grootste permutatie van alle partitiekolommen van numeriek en tekenreekstype als sleutels. De Data Catalog maakt vervolgens een doorzoekbare index op basis van deze sleutels, waardoor de tijd die nodig is voor het ophalen en filteren van partitie-metagegevens op tabellen met miljoenen partities wordt verkort. Het maken van partitie-indexen komt ten goede aan de analytische workloads die op Athena draaien, Amazon EMR, Amazon Roodverschuivingsspectrumen AWS-lijm.
In dit bericht beschrijven we hoe u partitie-indexen kunt maken met een AWS Glue-crawler en hoe u de verbetering van de queryprestaties kunt vergelijken bij toegang tot de gecrawlde gegevens met en zonder een partitie-index van Athena.
Overzicht oplossingen
We gebruiken een AWS CloudFormatie sjabloon om onze oplossingsbronnen te maken. In de volgende stappen laten we zien hoe u de AWS Glue-crawler configureert om een partitie-index te maken met behulp van de AWS Glue-console of de AWS-opdrachtregelinterface (AWS CLI). Vervolgens vergelijken we de verbeteringen in de queryprestaties met behulp van Athena.
Voorwaarden
Om dit bericht te kunnen volgen, moet je toegang hebben tot een AWS Identiteits- en toegangsbeheer (IAM) beheerdersrol om bronnen te creëren met behulp van AWS CloudFormation.
Stel uw oplossingsresources in
De CloudFormation-sjabloon genereert de volgende bronnen:
- IAM-rollen en -beleid
- Een AWS Glue-database om het schema te bewaren
- Een AWS Glue-crawler die verwijst naar een sterk gepartitioneerde dataset
- Een Athena-werkgroep en bucket om queryresultaten op te slaan
Voer de volgende stappen uit om de oplossingsbronnen in te stellen:
- Meld u aan bij de AWS-beheerconsole als IAM-beheerder.
- Kies Start Stack om de CloudFormation-sjabloon te implementeren:

- Voor Database naam, behoud de standaard
blog_partition_index_crawlerdb.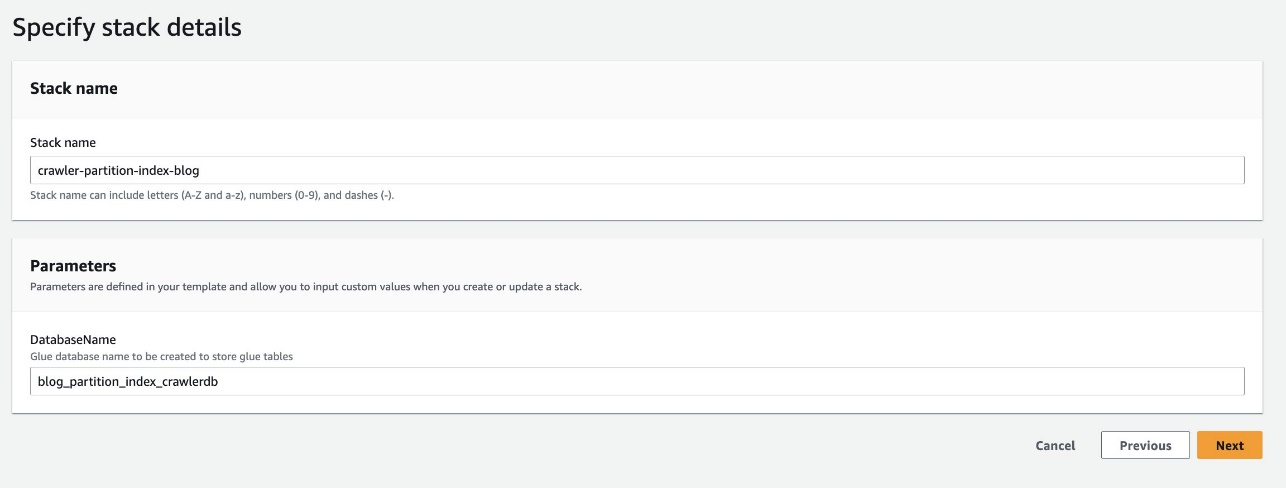
- Kies Volgende.
- Bekijk de details op de laatste pagina en selecteer Ik erken dat AWS CloudFormation IAM-bronnen kan creëren.
- Kies Maak een stapel.
- Wanneer de stapel compleet is, navigeert u op de AWS CloudFormation-console naar de Uitgangen tabblad van de stapel.
- Noteer de waarden van
DatabaseNameenGlueCrawlerName.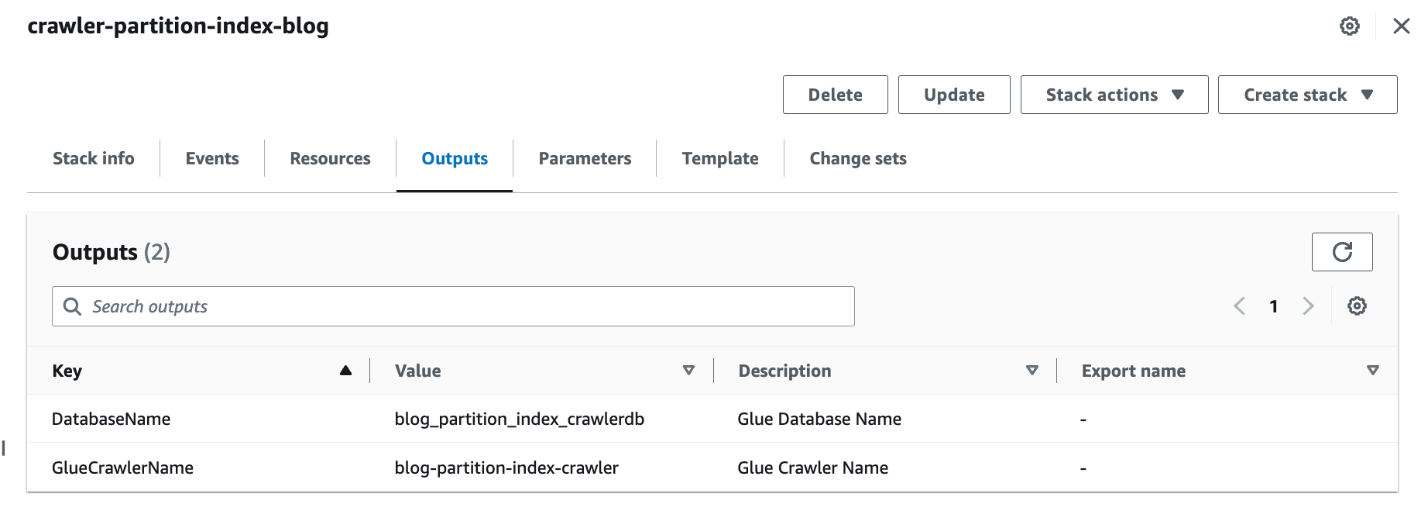
Sommige van de bronnen die door deze stapel worden ingezet, brengen kosten met zich mee wanneer ze worden gebruikt.
Bewerk en voer de AWS Glue-crawler uit
Voer de volgende stappen uit om de AWS Glue-crawler te configureren en uit te voeren:
- Kies op de AWS Glue-console: crawlers in het navigatievenster.
- Zoek de
crawler blog-partition-index-crawlerEn kies Edit.
- In het Uitvoer en planning instellen sectie, onder geavanceerde optiesselecteer Maak automatisch partitie-indexen.
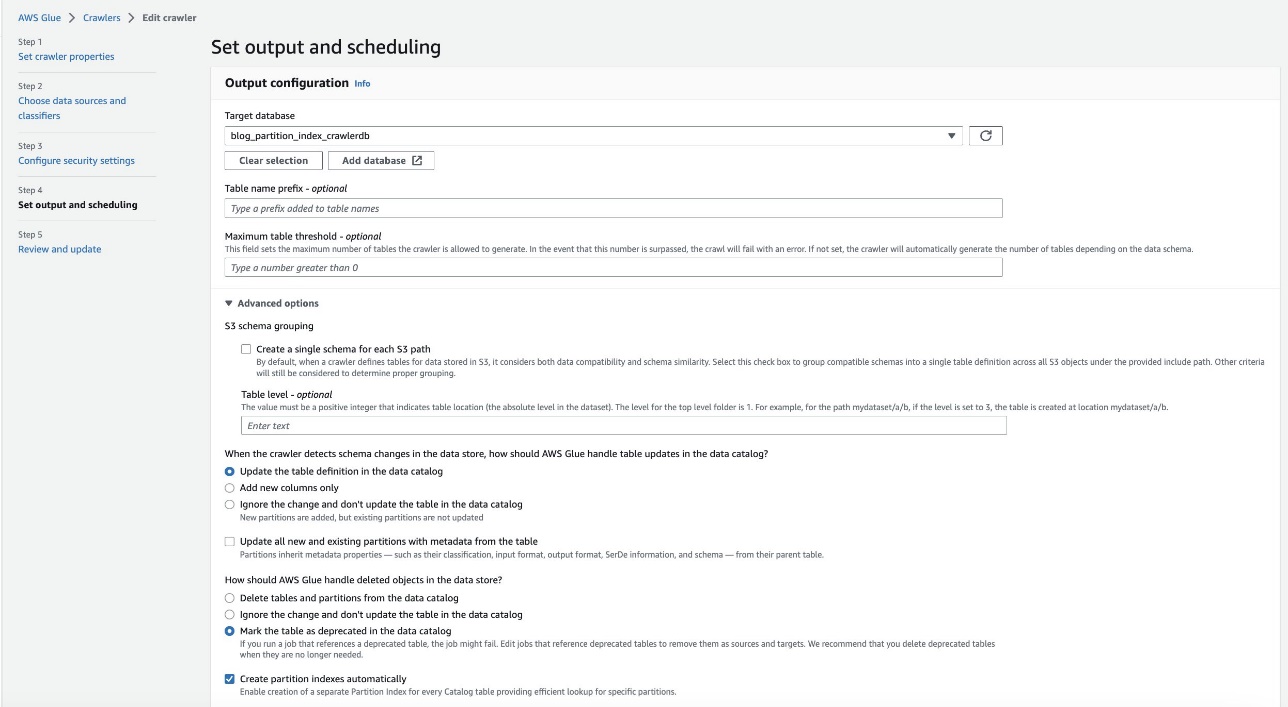
- Controleer en update de crawlerinstellingen.
Als alternatief kunt u uw crawler configureren met behulp van de AWS CLI (geef uw IAM-rol en regio op):
- Voer nu de crawler uit en controleer of de crawlerrun is voltooid.
Dit is een sterk gepartitioneerde dataset en het duurt ongeveer 90 minuten om deze te voltooien.
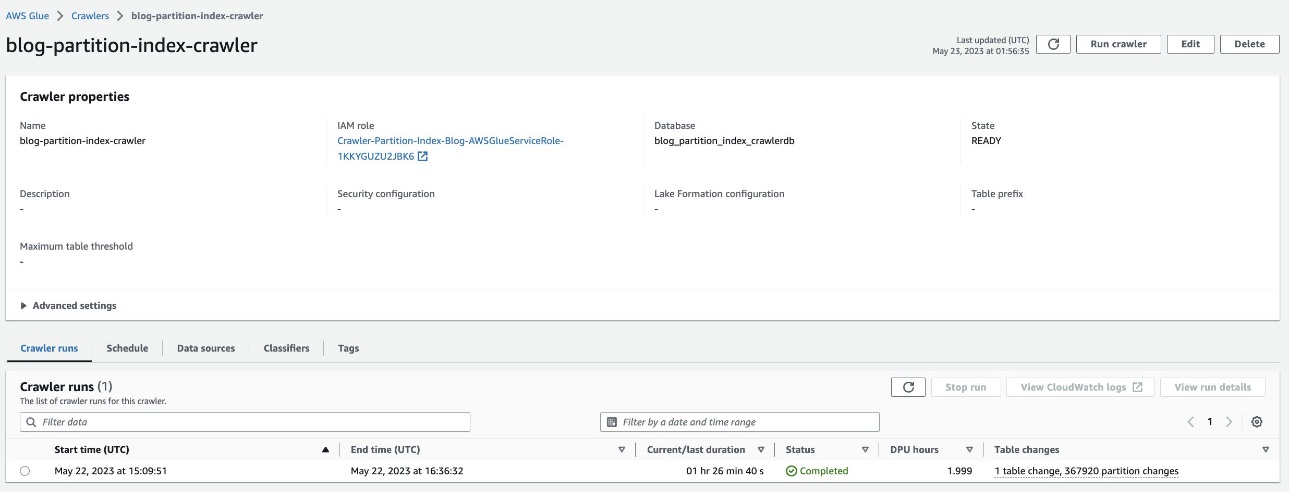
Controleer de gepartitioneerde tabel
In de AWS Glue-database blog_partition_index_crawlerdb, controleer of de tabel highly_partitioned_table is gecreëerd.
Standaard bepaalt de crawler een index op basis van de grootste permutatie van partitiekolommen van geldige kolomtypen in dezelfde volgorde van partitiekolommen, die numeriek of tekenreeks zijn. Voor de tabel die door de crawler is gemaakt (highly_partitioned_table), hebben we partitiekolommen year (draad), month (draad), day (tekenreeks), en hour (snaar).
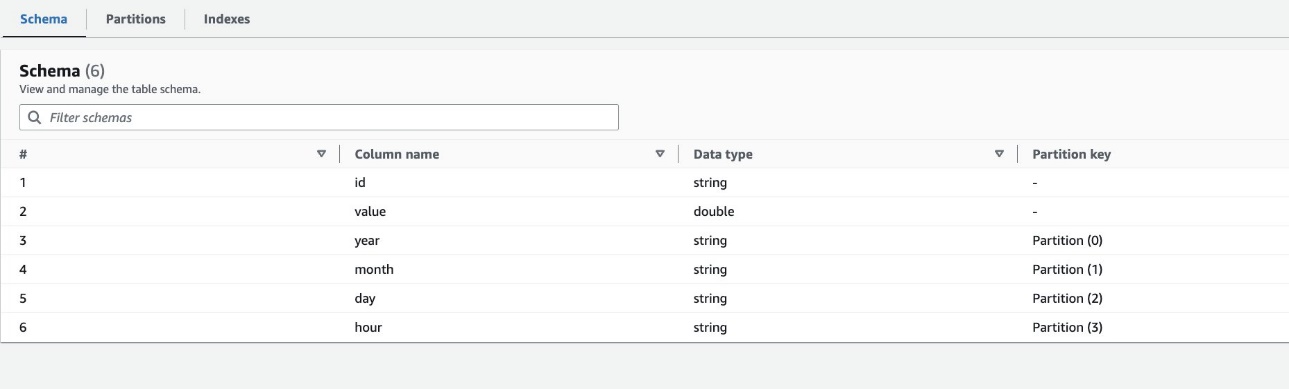
Op basis van deze definitie heeft de crawler een index gemaakt over de permutatie van jaar, maand, dag en uur. De crawler heeft de indexen gemaakt met het voorvoegsel crawler_ op elke partitie-index die standaard is gemaakt.
Controleer hetzelfde door naar de tabel te navigeren highly_partitioned_table op de AWS Glue-console en kies de Indexen Tab.
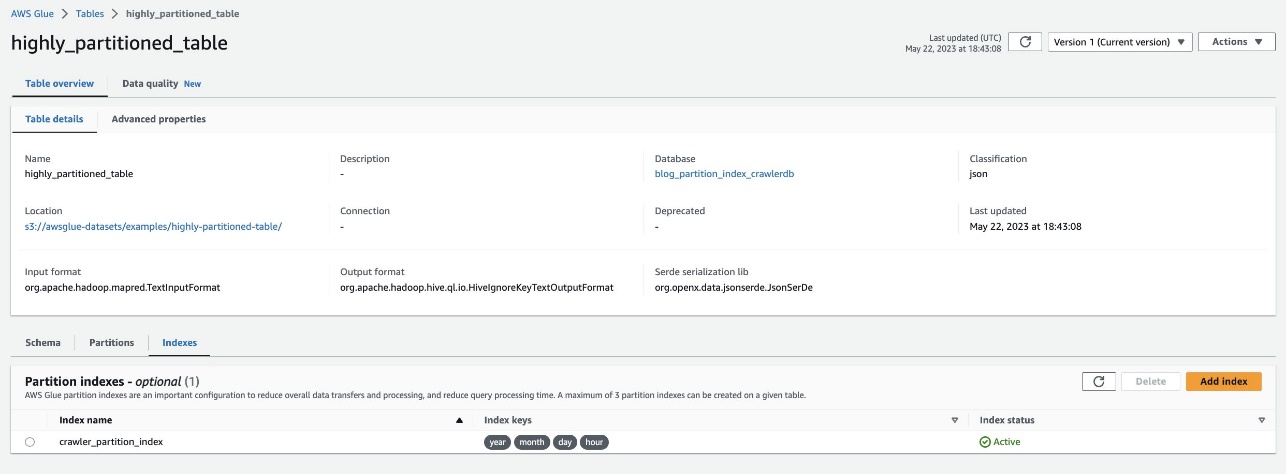
De crawler kon de S3-gegevensbron crawlen en de partitie-indexen voor de tabel invullen.
Vergelijk de verbeteringen in de queryprestaties met Athena
Eerst doorzoeken we de tabel in Athena zonder de partitie-index te gebruiken. Voer de volgende stappen uit om de tabellen te verifiëren met Athena:
- Kies op de Athena-console
crawler-primary-workgroupzoals de Athena-werkgroep en kies Erkennen.
- Voer de volgende query uit:
In de volgende schermafbeelding ziet u dat de query ongeveer 32 seconden duurde zonder dat filteren was ingeschakeld met behulp van de partitie-index.
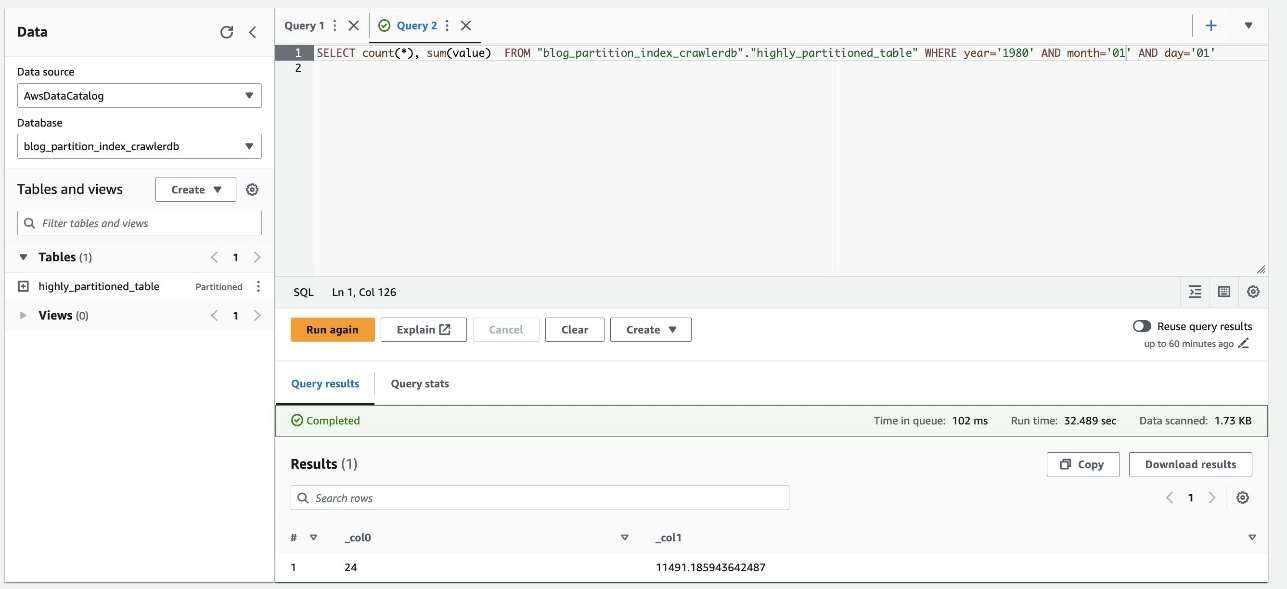
- Nu schakelen we de partitie-index in voor de Athena-query:
- Voer de volgende query opnieuw uit en noteer de runtime:
De volgende schermafbeelding laat zien dat de query slechts 700 milliseconden duurde, wat veel sneller is als filteren is ingeschakeld met behulp van de partitie-index.
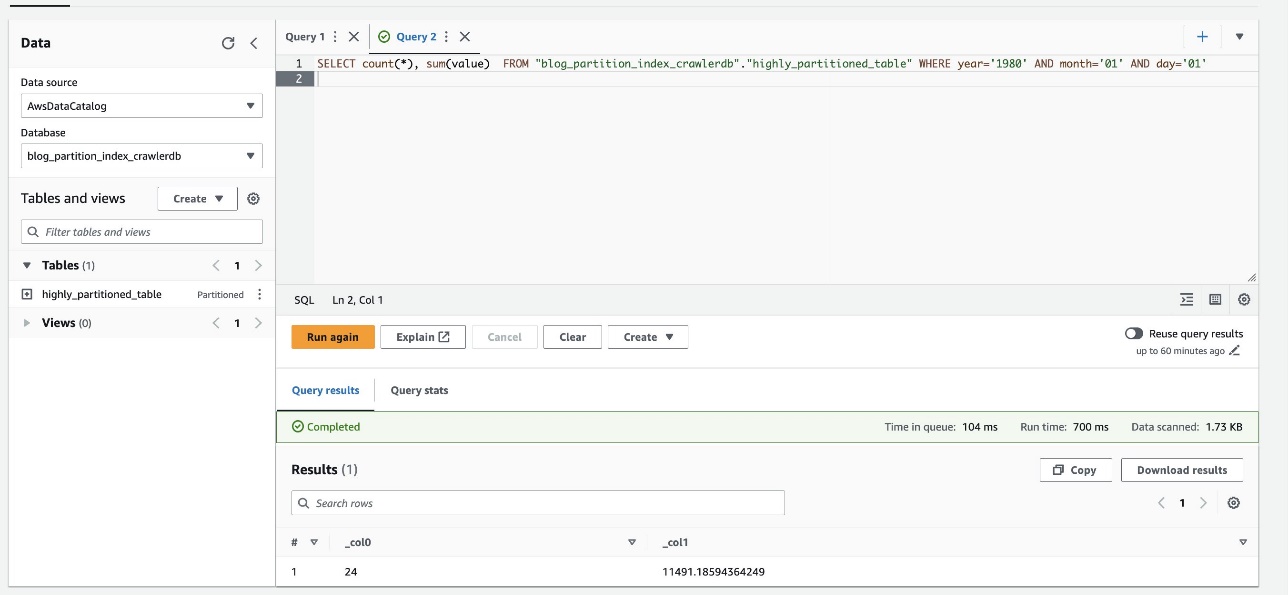
Opruimen
Om ongewenste afschrijvingen op uw AWS-account te voorkomen, kunt u de AWS-bronnen verwijderen:
- Meld u aan bij de CloudFormation-console als de IAM-beheerder die is gebruikt voor het maken van de CloudFormation-stack.
- Verwijder de CloudFormation-stack die u hebt gemaakt.
Conclusie
In dit bericht hebben we uitgelegd hoe je een AWS-crawler configureert om partitie-indexen te maken en de queryprestaties te vergelijken bij toegang tot de gegevens met indexen van Athena.
Als er geen partitie-indexen op de tafel aanwezig zijn, laadt AWS Glue alle partities van de tabel en filtert vervolgens de geladen partities, wat resulteert in het inefficiënt ophalen van metagegevens. Analyseservices zoals Redshift Spectrum, Amazon EMR en AWS Glue ETL Spark DataFrames kunnen nu indexen gebruiken voor het ophalen van partities, wat resulteert in aanzienlijke queryprestaties.
Raadpleeg voor meer informatie over partitie-indexen en queryprestaties voor verschillende analytische motoren Verbeter de queryprestaties van Amazon Athena met behulp van AWS Glue Data Catalog-partitie-indexen en Verbeter de queryprestaties met behulp van AWS Glue-partitie-indexen.
Speciale dank aan iedereen die heeft bijgedragen aan de lancering van deze crawlerfunctie: Yuhang Chen, Kyle Duong en Mita Gavade.
Over de auteurs
 Srividya Parthasarathy is een Senior Big Data Architect in het AWS Lake Formation-team. Ze vindt het leuk om data mesh-oplossingen te bouwen en deze te delen met de community.
Srividya Parthasarathy is een Senior Big Data Architect in het AWS Lake Formation-team. Ze vindt het leuk om data mesh-oplossingen te bouwen en deze te delen met de community.
 Sandeep Adwankar is Senior Technisch Product Manager bij AWS. Hij is gevestigd in de California Bay Area en werkt samen met klanten over de hele wereld om zakelijke en technische vereisten om te zetten in producten waarmee klanten de manier waarop ze gegevens beheren, beveiligen en openen, kunnen verbeteren.
Sandeep Adwankar is Senior Technisch Product Manager bij AWS. Hij is gevestigd in de California Bay Area en werkt samen met klanten over de hele wereld om zakelijke en technische vereisten om te zetten in producten waarmee klanten de manier waarop ze gegevens beheren, beveiligen en openen, kunnen verbeteren.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- : heeft
- :is
- :waar
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- in staat
- toegang
- toegang
- Account
- erkennen
- over
- toevoegen
- beheerder
- weer
- Alles
- langs
- ook
- Amazone
- Amazone Athene
- Amazon EMR
- Amazon Web Services
- hoeveelheden
- an
- Analytisch
- analytics
- en
- elke
- ongeveer
- ZIJN
- GEBIED
- rond
- AS
- At
- webmaster.
- Beschikbaar
- vermijd
- AWS
- AWS CloudFormatie
- AWS lijm
- AWS Lake-formatie
- gebaseerde
- Baai
- omdat
- geweest
- betekent
- Groot
- Big data
- Gebouw
- bedrijfsdeskundigen
- by
- Californië
- CAN
- catalogus
- Veroorzaken
- Wijzigingen
- lasten
- chen
- Kies
- het kiezen van
- classificatie
- Kolom
- columns
- komt
- gemeenschap
- vergelijken
- vergeleken
- compleet
- troosten
- doorlopend
- bijgedragen
- Kosten
- crawler
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- het aanmaken
- Actueel
- Klanten
- gegevens
- toegang tot data
- Datameer
- Database
- dag
- Standaard
- tonen
- implementeren
- ontplooit
- beschrijven
- gegevens
- bepaalt
- ontdekt
- beneden
- gedurende
- efficiënt
- beide
- in staat stellen
- ingeschakeld
- Motoren
- Ether (ETH)
- iedereen
- uitgebreid
- uitgelegd
- exponentieel
- extract
- extraheer de gegevens
- sneller
- Kenmerk
- filter
- filtering
- filters
- finale
- volgen
- volgend
- Voor
- vorming
- oppompen van
- genereert
- gegeven
- wereldbol
- Groeien
- Groeiend
- Hebben
- he
- zwaar
- zwaar tillen
- zeer
- houden
- uur
- Hoe
- How To
- HTML
- http
- HTTPS
- IAM
- Identiteit
- verbeteren
- verbetering
- verbeteringen
- in
- Laat uw omzet
- Verhoogt
- index
- indexen
- ondoeltreffend
- informatie
- in
- IT
- jpg
- Houden
- houden
- toetsen
- meer
- grootste
- lancering
- Layout
- facelift
- als
- Lijn
- ladingen
- maken
- beheer
- management
- manager
- mesh
- Metadata
- macht
- miljoenen
- minuten
- Maand
- meer
- veel
- Dan moet je
- OP DEZE WEBSITE VIND JE
- navigeren
- Navigatie
- nodig
- New
- onlangs
- geen
- nu
- aantal
- of
- on
- Slechts
- Optimaliseer
- or
- bestellen
- onze
- uitgang
- over
- pagina
- brood
- pad
- prestatie
- Plato
- Plato gegevensintelligentie
- PlatoData
- Post
- presenteren
- verwerking
- Product
- product manager
- Producten
- zorgen voor
- vermindering
- regio
- nodig
- Voorwaarden
- vereist
- Resources
- verkregen
- Resultaten
- Rol
- rollen
- lopen
- lopend
- dezelfde
- seconden
- sectie
- beveiligen
- senior
- Diensten
- reeks
- settings
- delen
- ze
- Shows
- aanzienlijke
- aanzienlijk
- Eenvoudig
- oplossing
- Oplossingen
- bron
- Vonk
- Spectrum
- stack
- Stappen
- mediaopslag
- shop
- eenvoudig
- Draad
- Met goed gevolg
- ondersteuning
- Systems
- tafel
- Nemen
- team
- Technisch
- sjabloon
- bedankt
- dat
- De
- hun
- Ze
- harte
- Deze
- ze
- dit
- niet de tijd of
- naar
- vandaag
- nam
- vertalen
- waar
- type dan:
- types
- voor
- begrijpen
- ongewenste
- bijwerken
- .
- gebruikt
- gebruik
- gebruik maken van
- waarde
- Values
- divers
- groot
- controleren
- versie
- was
- Manier..
- we
- web
- webservices
- wanneer
- welke
- WIE
- wil
- Met
- zonder
- Werkgroep
- Bedrijven
- wereld
- YAML
- jaar
- u
- Your
- zephyrnet