
Afbeelding van auteur | Bing Afbeeldingsmaker
Dollie 2.0 is een open-source, instructie-gevolgd, groot taalmodel (LLM) dat is afgestemd op een door mensen gegenereerde dataset. Het kan zowel voor onderzoek als voor commerciële doeleinden worden gebruikt.
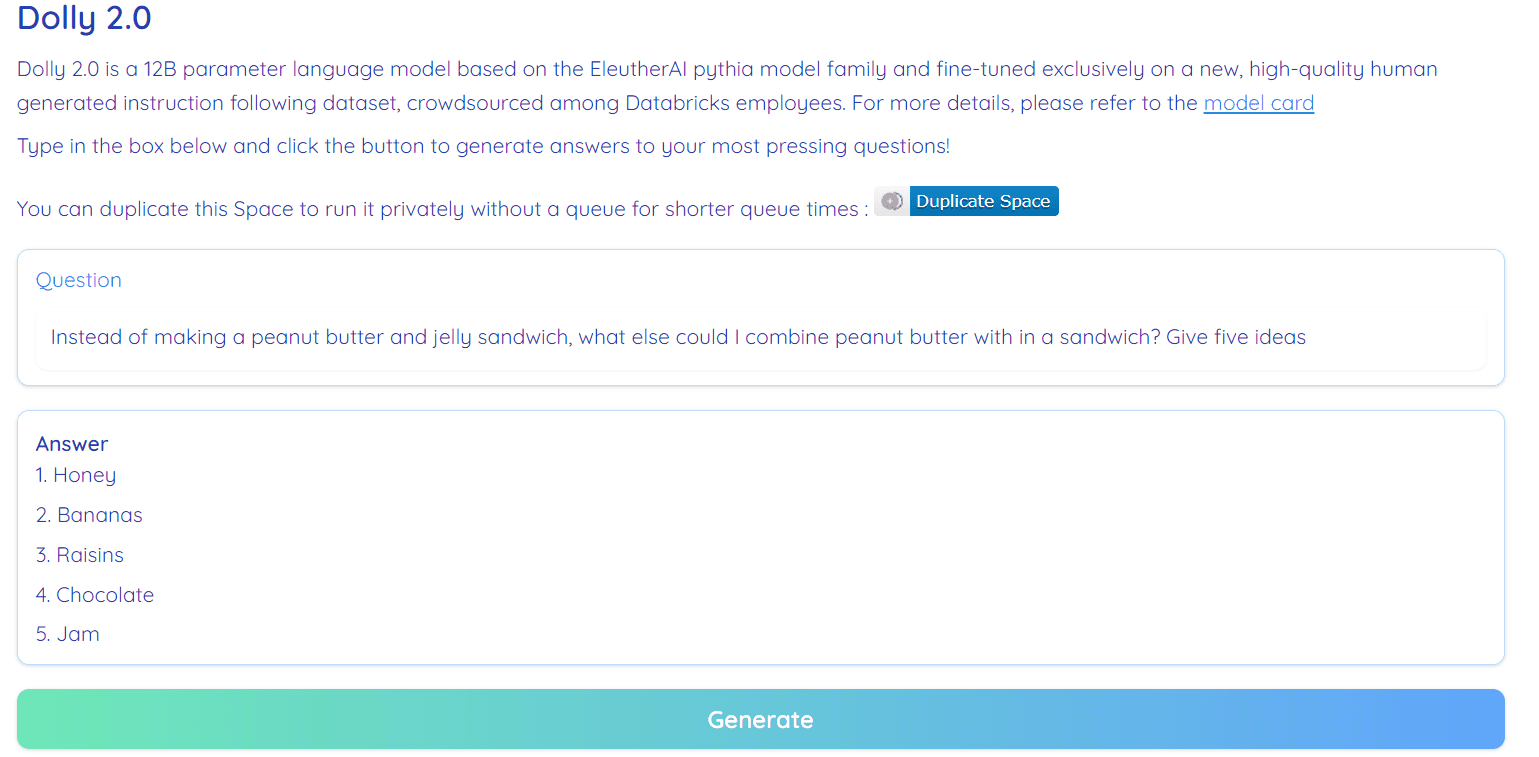
Afbeelding van Gezichtsruimte knuffelen door RamAnanth1
Eerder bracht het Databricks-team Dollie 1.0, LLM, die een ChatGPT-achtige instructie volgt en minder dan $ 30 kost om te trainen. Het gebruikte de gegevensset van het Stanford Alpaca-team, die onder een beperkte licentie viel (alleen onderzoek).
Dolly 2.0 heeft dit probleem opgelost door het 12B-parametertaalmodel te verfijnen (Pythia) op een door mensen gegenereerde instructie van hoge kwaliteit in de volgende dataset, die is gelabeld door een medewerker van Datbricks. Zowel het model als de dataset zijn beschikbaar voor commercieel gebruik.
Dolly 1.0 is getraind op een Stanford Alpaca-dataset, die is gemaakt met OpenAI API. De dataset bevat de uitvoer van ChatGPT en voorkomt dat iemand deze gebruikt om te concurreren met OpenAI. Kortom, op basis van deze dataset kun je geen commerciële chatbot of taalapplicatie bouwen.
De meeste van de nieuwste modellen die de afgelopen weken zijn uitgebracht, hadden dezelfde problemen, zoals modellen Alpaca, Koala, GPT4Alle en Vicuna. Om dit te omzeilen, moeten we nieuwe hoogwaardige datasets maken die voor commercieel gebruik kunnen worden gebruikt, en dat is wat het Databricks-team heeft gedaan met de databricks-dolly-15k-dataset.
De nieuwe dataset bevat 15,000 hoogwaardige door mensen gelabelde prompt/response-paren die kunnen worden gebruikt voor het ontwerpen van instructies voor het afstemmen van grote taalmodellen. De databricks-dolly-15k dataset wordt meegeleverd Creative Commons Naamsvermelding-GelijkDelen 3.0 Unported-licentie, waarmee iedereen het kan gebruiken, wijzigen en er een commerciële toepassing op kan maken.
Hoe hebben ze de databricks-dolly-15k-dataset gemaakt?
Het OpenAI-onderzoek papier stelt dat het oorspronkelijke InstructGPT-model is getraind op 13,000 prompts en reacties. Door deze informatie te gebruiken, begon het Databricks-team eraan te werken en het bleek dat het genereren van 13 vragen en antwoorden een moeilijke taak was. Ze kunnen geen synthetische data of AI-generatieve data gebruiken, en ze moeten originele antwoorden op elke vraag genereren. Hier hebben ze besloten om 5,000 medewerkers van Databricks in te zetten om door mensen gegenereerde data te creëren.
De Databricks hebben een wedstrijd uitgeschreven, waarbij de top 20 labelers een grote prijs zouden krijgen. Aan deze wedstrijd deden 5,000 Databricks-medewerkers mee die zeer geïnteresseerd waren in LLM's
De dolly-v2-12b is geen state-of-the-art model. Het presteert slechter dan dolly-v1-6b in sommige evaluatiebenchmarks. Dit kan te wijten zijn aan de samenstelling en omvang van de onderliggende fijnafstemmingsdatasets. De Dolly-modelfamilie wordt actief ontwikkeld, dus mogelijk ziet u in de toekomst een bijgewerkte versie met betere prestaties.
Kortom, het model dolly-v2-12b heeft beter gepresteerd dan EleutherAI/gpt-neox-20b en EleutherAI/pythia-6.9b.

Afbeelding van Gratis Dollie
Dolly 2.0 is 100% open-source. Het wordt geleverd met trainingscode, dataset, modelgewichten en inferentiepijplijn. Alle componenten zijn geschikt voor commercieel gebruik. Je kunt het model uitproberen op Hugging Face Spaces Dolly V2 door RamAnanth1.
Afbeelding van Gezicht knuffelen
Resource:
Dolly 2.0-demo: Dolly V2 door RamAnanth1
Abid Ali Awan (@1abidaliawan) is een gecertificeerde datawetenschapper-professional die dol is op het bouwen van machine learning-modellen. Momenteel richt hij zich op het creëren van content en het schrijven van technische blogs over machine learning en data science-technologieën. Abid heeft een Master in Technologie Management en een Bachelor in Telecommunicatie Engineering. Zijn visie is om een AI-product te bouwen met behulp van een grafisch neuraal netwerk voor studenten die worstelen met een psychische aandoening.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- : heeft
- :is
- :niet
- $UP
- 000
- 1
- 20
- a
- vermogen
- actieve
- AI
- Alles
- toestaat
- alternatief
- an
- en
- antwoorden
- iedereen
- api
- Aanvraag
- ZIJN
- rond
- auteur
- Beschikbaar
- onderscheiding
- gebaseerde
- BE
- benchmarks
- Berkeley
- Betere
- Groot
- Bing
- blogs
- zowel
- bouw
- Gebouw
- by
- CAN
- kan niet
- Certified
- Chatbot
- ChatGPT
- code
- commercieel
- Volk
- concurreren
- componenten
- bevat
- content
- content creatie
- wedstrijd
- Kosten
- en je merk te creëren
- aangemaakt
- het aanmaken
- Op dit moment
- gegevens
- data science
- data scientist
- Databricks
- datasets
- beslist
- Mate
- Demo
- Design
- Ontwikkeling
- DEED
- moeilijk
- popje
- Werknemer
- medewerkers
- Engineering
- evaluatie
- Alle
- vertoont
- Gezicht
- familie
- weinig
- gericht
- volgend
- Voor
- oppompen van
- toekomst
- voortbrengen
- het genereren van
- generatief
- krijgen
- diagram
- Grafiek neuraal netwerk
- Hebben
- he
- hoogwaardige
- houdt
- HTML
- HTTPS
- ziekte
- beeld
- in
- informatie
- geïnteresseerd
- kwestie
- problemen
- IT
- jpg
- KDnuggets
- taal
- Groot
- Achternaam*
- laatste
- leren
- Vergunning
- als
- machine
- machine learning
- management
- meester
- mentaal
- Geestelijke ziekte
- macht
- model
- modellen
- wijzigen
- Noodzaak
- netwerk
- Neural
- neuraal netwerk
- New
- of
- on
- Slechts
- open
- open source
- OpenAI
- or
- origineel
- uitgang
- paren
- parameter
- deelgenomen
- prestatie
- pijpleiding
- Plato
- Plato gegevensintelligentie
- PlatoData
- Product
- professioneel
- doeleinden
- vraag
- Contact
- uitgebracht
- onderzoek
- opgelost
- begrensd
- s
- dezelfde
- Wetenschap
- Wetenschapper
- reeks
- Bermuda's
- Maat
- So
- sommige
- bron
- Tussenruimte
- ruimten
- stanford
- gestart
- state-of-the-art
- Staten
- Worstelen
- Leerlingen
- geschikt
- synthetisch
- synthetische gegevens
- Taak
- team
- Technisch
- Technologies
- Technologie
- telecommunicatieverbinding
- neem contact
- dat
- De
- De toekomst
- ze
- dit
- naar
- top
- Trainen
- getraind
- Trainingen
- voor
- die ten grondslag liggen
- bijgewerkt
- .
- gebruikt
- gebruik
- versie
- visie
- was
- we
- weken
- waren
- Wat
- welke
- WIE
- Met
- Mijn werk
- zou
- het schrijven van
- u
- zephyrnet










