Geautomatiseerde gegevensanalyse (ADA) op AWS is een AWS-oplossing waarmee u binnen enkele minuten betekenisvolle inzichten uit gegevens kunt halen via een eenvoudige en intuïtieve gebruikersinterface. ADA biedt een AWS-native data-analyseplatform dat kant-en-klaar door data-analisten kan worden gebruikt voor verschillende gebruiksscenario's. Met ADA kunnen teams diverse datasets uit een reeks gegevensbronnen opnemen, transformeren, beheren en opvragen zonder dat daarvoor specialistische technische vaardigheden nodig zijn. ADA biedt een reeks vooraf gebouwde connectoren om gegevens uit een breed scala aan bronnen op te nemen, waaronder Amazon eenvoudige opslagservice (Amazone S3), Amazon Kinesis-gegevensstromen, Amazon Cloud Watch, Amazon CloudTrail en Amazon DynamoDB evenals vele anderen.
ADA biedt een fundamenteel platform dat door data-analisten kan worden gebruikt in een breed scala aan gebruiksscenario's, waaronder IT, financiën, marketing, verkoop en beveiliging. De kant-en-klare CloudWatch-dataconnector van ADA maakt gegevensopname mogelijk vanuit CloudWatch-logboeken in hetzelfde AWS-account waarin ADA is geïmplementeerd, of vanuit een ander AWS-account.
In dit bericht laten we zien hoe een applicatieontwikkelaar of applicatietester ADA kan gebruiken om operationele inzichten te verkrijgen over applicaties die in AWS draaien. We laten ook zien hoe u de ADA-oplossing kunt gebruiken om verbinding te maken met verschillende gegevensbronnen in AWS. Wij eerst de ADA-oplossing implementeren in een AWS-account en de ADA-oplossing opzetten door te maken data producten gebruik van dataconnectoren. Vervolgens gebruiken we de ADA Query Workbench om de afzonderlijke datasets samen te voegen en de gecorreleerde gegevens te bevragen, met behulp van de bekende Structured Query Language (SQL), om inzichten te verkrijgen. Ook demonstreren we hoe ADA kan worden geïntegreerd met business intelligence (BI) tools zoals Tableau om de data te visualiseren en rapporten op te bouwen.
Overzicht oplossingen
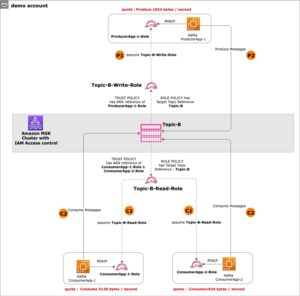
In deze sectie presenteren we de oplossingsarchitectuur voor de demo en leggen we de workflow uit. Voor demonstratiedoeleinden wordt de op maat gemaakte applicatie gesimuleerd met behulp van een AWS Lambda functie die aanmeldingen verzendt Apache Log-indeling met een vooraf ingesteld interval met behulp van Amazon EventBridge. Dit standaardformaat kan door veel verschillende webservers worden geproduceerd en door veel loganalyseprogramma's worden gelezen. De applicatielogboeken (Lambda-functie) worden verzonden naar een CloudWatch-loggroep. De historische applicatielogboeken worden ter referentie en voor bevragingsdoeleinden opgeslagen in een S3-bucket. Een opzoektabel met een lijst van HTTP-statuscodes samen met de beschrijvingen wordt opgeslagen in een DynamoDB-tabel. Deze drie dienen als bronnen van waaruit gegevens in ADA worden opgenomen voor correlatie, bevraging en analyse. Wij de ADA-oplossing implementeren in een AWS-account en ADA opzetten. Vervolgens maken wij de data producten binnen ADA voor de CloudWatch-logboekgroep, S3 emmer en DynamoDB. Terwijl de dataproducten worden geconfigureerd, voorziet ADA in datapijplijnen om de gegevens uit de bronnen op te nemen. Met de ADA Query Workbench kunt u de opgenomen gegevens opvragen met behulp van gewone SQL voor het oplossen van problemen met toepassingen of het diagnosticeren van problemen.
Het volgende diagram biedt een overzicht van de architectuur en workflow van het gebruik van ADA om inzicht te krijgen in applicatielogboeken.
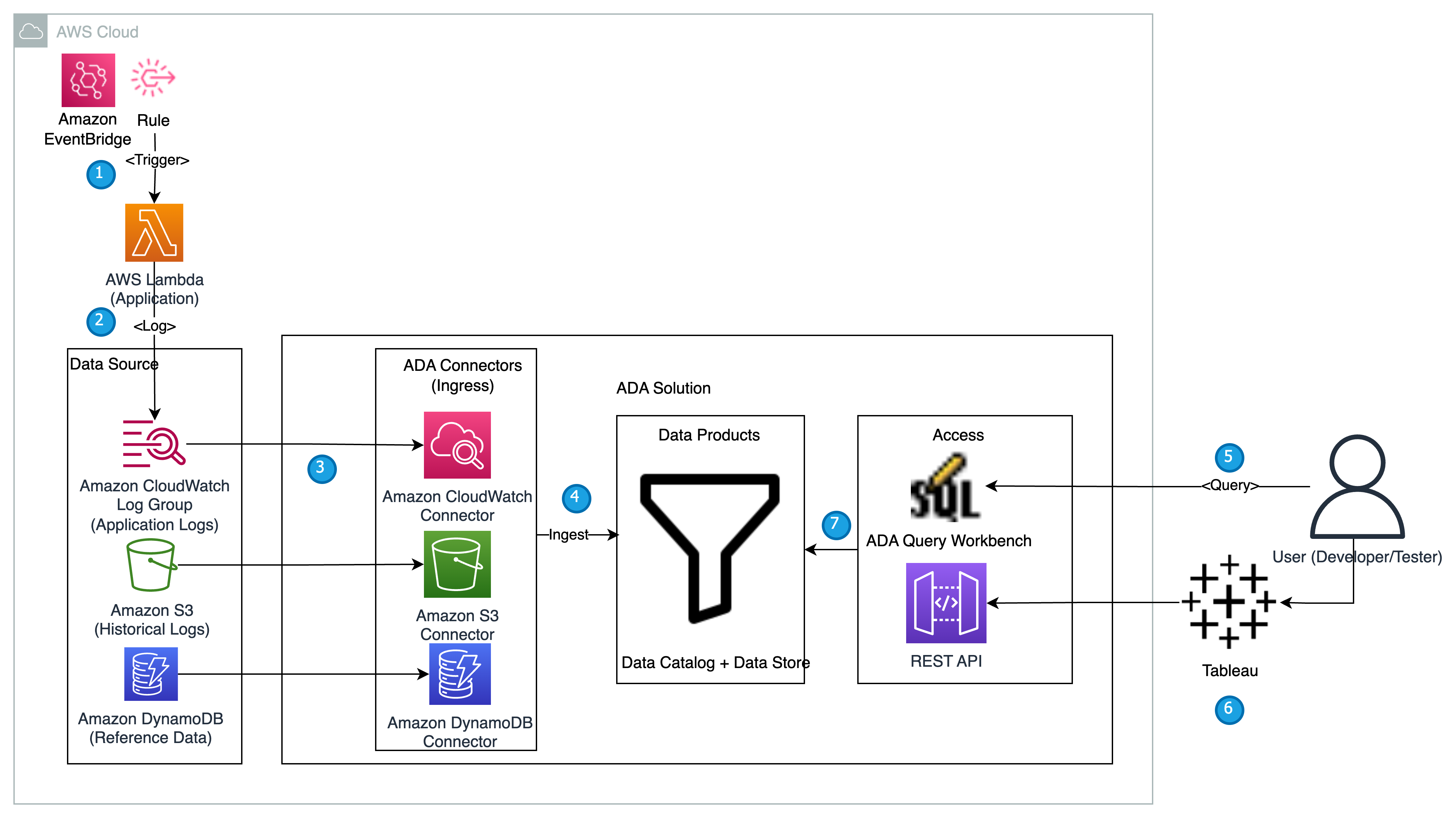
De workflow omvat de volgende stappen:
- Het is de bedoeling dat er met behulp van EventBridge met tussenpozen van 2 minuten een Lambda-functie wordt geactiveerd.
- De Lambda-functie verzendt logboeken die zijn opgeslagen in een opgegeven CloudWatch-logboekgroep onder
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. De applicatielogboeken worden gegenereerd met behulp van het Apache Log Format-schema, maar opgeslagen in de CloudWatch-logboekgroep in JSON-indeling. - De dataproducten voor CloudWatch, Amazon S3 en DynamoDB worden gemaakt in ADA. Het CloudWatch-dataproduct maakt verbinding met de CloudWatch-loggroep waar de applicatielogboeken (Lambda-functie) worden opgeslagen. De Amazon S3-connector maakt verbinding met een S3-bucketmap waarin de historische logs worden opgeslagen. De DynamoDB-connector maakt verbinding met een DynamoDB-tabel waarin de statuscodes waarnaar door de applicatie wordt verwezen, en historische logboeken worden opgeslagen.
- Voor elk van de dataproducten zet ADA de datapijplijninfrastructuur in om gegevens uit de bronnen op te nemen. Wanneer de gegevensopname is voltooid, kunt u via de ADA Query Workbench query's schrijven met behulp van SQL.
- U kunt inloggen op de ADA-portal en SQL-query's samenstellen vanuit de Query Workbench om inzicht te krijgen in de applicatielogboeken. U kunt de zoekopdracht optioneel opslaan en delen met andere ADA-gebruikers in hetzelfde domein. De ADA-queryfunctie wordt mogelijk gemaakt door Amazone Athene, een serverloze, interactieve analyseservice die een vereenvoudigde, flexibele manier biedt om petabytes aan gegevens te analyseren.
- Tableau is geconfigureerd voor toegang tot de ADA-dataproducten via uitgaande ADA-eindpunten. Vervolgens maakt u een dashboard met twee grafieken. Het eerste diagram is een heatmap die de prevalentie toont van HTTP-foutcodes die verband houden met de API-eindpunten van de applicatie. Het tweede diagram is een staafdiagram dat de top 10 applicatie-API's toont met een totaal aantal HTTP-foutcodes uit de historische gegevens.
Voorwaarden
Voor dit bericht moet je aan de volgende vereisten voldoen:
- Installeer de AWS-opdrachtregelinterface (AWS-CLI), AWS Cloud-ontwikkelingskit (AWS-CDK) vereisten, TypeScript-specifiek vereisten en git.
- Implementeren de ADA-oplossing in uw AWS-account in de
us-east-1Regio.- Geef een beheerders-e-mailadres op tijdens het starten van de ADA AWS CloudFormatie stapel. Dit is nodig zodat ADA het rootgebruikerswachtwoord kan verzenden. Er is een beheerderstelefoonnummer vereist om een eenmalig wachtwoordbericht te ontvangen als multi-factor authenticatie (MFA) is ingeschakeld. Voor deze demo is MFA niet ingeschakeld.
- Bouw en implementeer de voorbeeldtoepassing (beschikbaar op de GitHub repo) oplossing zodat de volgende bronnen kunnen worden ingericht in uw account in de
us-east-1Regio:- Een Lambda-functie die de logtoepassing simuleert en een EventBridge-regel die de toepassingsfunctie met tussenpozen van 2 minuten aanroept.
- Een S3-bucket met het relevante bucketbeleid en een CSV-bestand met de historische applicatielogboeken.
- Een DynamoDB-tabel met de opzoekgegevens.
- Relevant AWS Identiteits- en toegangsbeheer (IAM) rollen en machtigingen die vereist zijn voor de services.
- Optioneel installeren Tableau Desktop, een externe BI-provider. Voor dit bericht gebruiken we Tableau Desktop versie 2021.2. Er zijn kosten verbonden aan het gebruik van een gelicentieerde versie van de Tableau Desktop-applicatie. Voor meer details, zie de Tableau-licenties informatie.
ADA implementeren en instellen
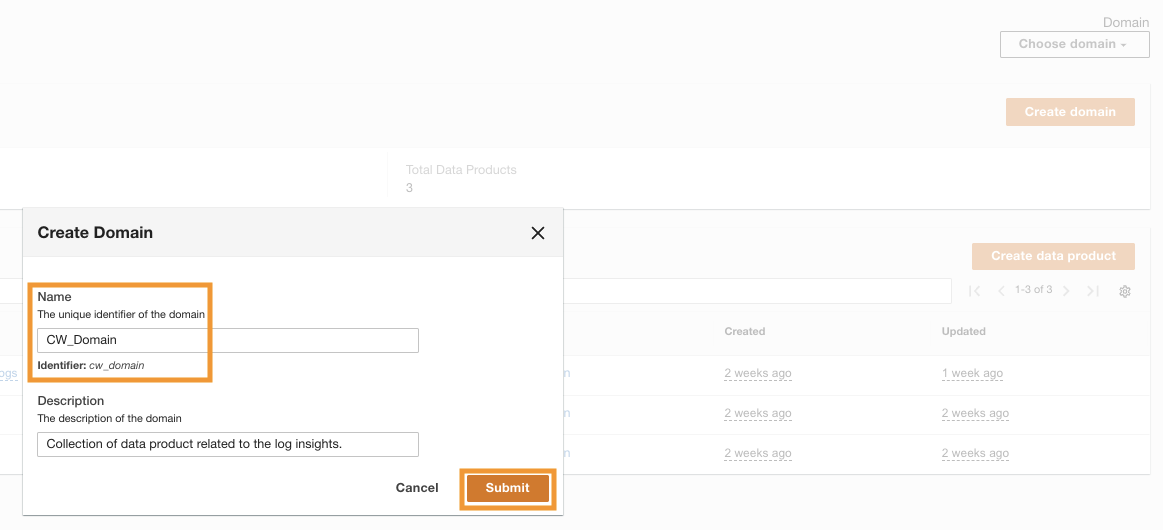
Nadat ADA met succes is geïmplementeerd, kunt u dat doen Log in met behulp van het beheerders-e-mailadres dat tijdens de installatie is verstrekt. Je maakt dan een domein genoemd CW_Domain. Een domein is een door de gebruiker gedefinieerde verzameling dataproducten. Een domein kan bijvoorbeeld een team of een project zijn. Domeinen bieden gebruikers een gestructureerde manier om hun dataproducten te organiseren en toegangsrechten te beheren.
- Kies op de ADA-console domeinen in het navigatievenster.
- Kies Domein aanmaken.
- Voer een naam in (
CW_Domain) en beschrijving en kies vervolgens Verzenden.
Zet de voorbeeldapplicatie-infrastructuur op met behulp van AWS CDK
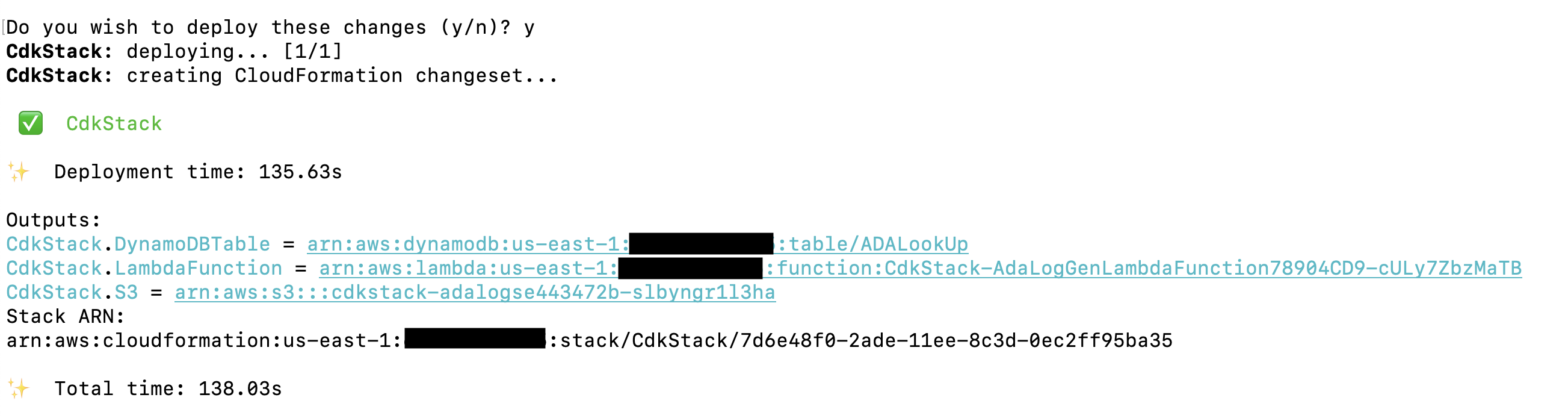
De AWS CDK-oplossing die de demo-applicatie implementeert, wordt gehost op GitHub. De stappen voor het klonen van de opslagplaats en het opzetten van het AWS CDK-project worden in deze sectie beschreven. Zorg ervoor dat u dit doet voordat u deze opdrachten uitvoert configureer uw AWS-inloggegevens. Maak een map, open de terminal en navigeer naar de map waarin de AWS CDK-oplossing moet worden geïnstalleerd. Voer de volgende code uit:
Met deze stappen worden de volgende acties uitgevoerd:
- Installeer de bibliotheekafhankelijkheden
- Bouw het project
- Genereer een geldige CloudFormation-sjabloon
- Implementeer de stack met AWS CloudFormation in uw AWS-account
De implementatie duurt ongeveer 1 à 2 minuten en creëert de DynamoDB-opzoektabel, de Lambda-functie en de S3-bucket met de historische logbestanden als uitvoer. Kopieer deze waarden naar een tekstbewerkingsprogramma, zoals Kladblok.
Maak ADA-dataproducten
We maken voor deze demo drie verschillende dataproducten, één voor elke gegevensbron die u gaat bevragen om operationele inzichten te verkrijgen. Een dataproduct is een dataset (een verzameling gegevens zoals een tabel of een CSV-bestand) die met succes in ADA is geïmporteerd en die kan worden opgevraagd.
Maak een CloudWatch-dataproduct
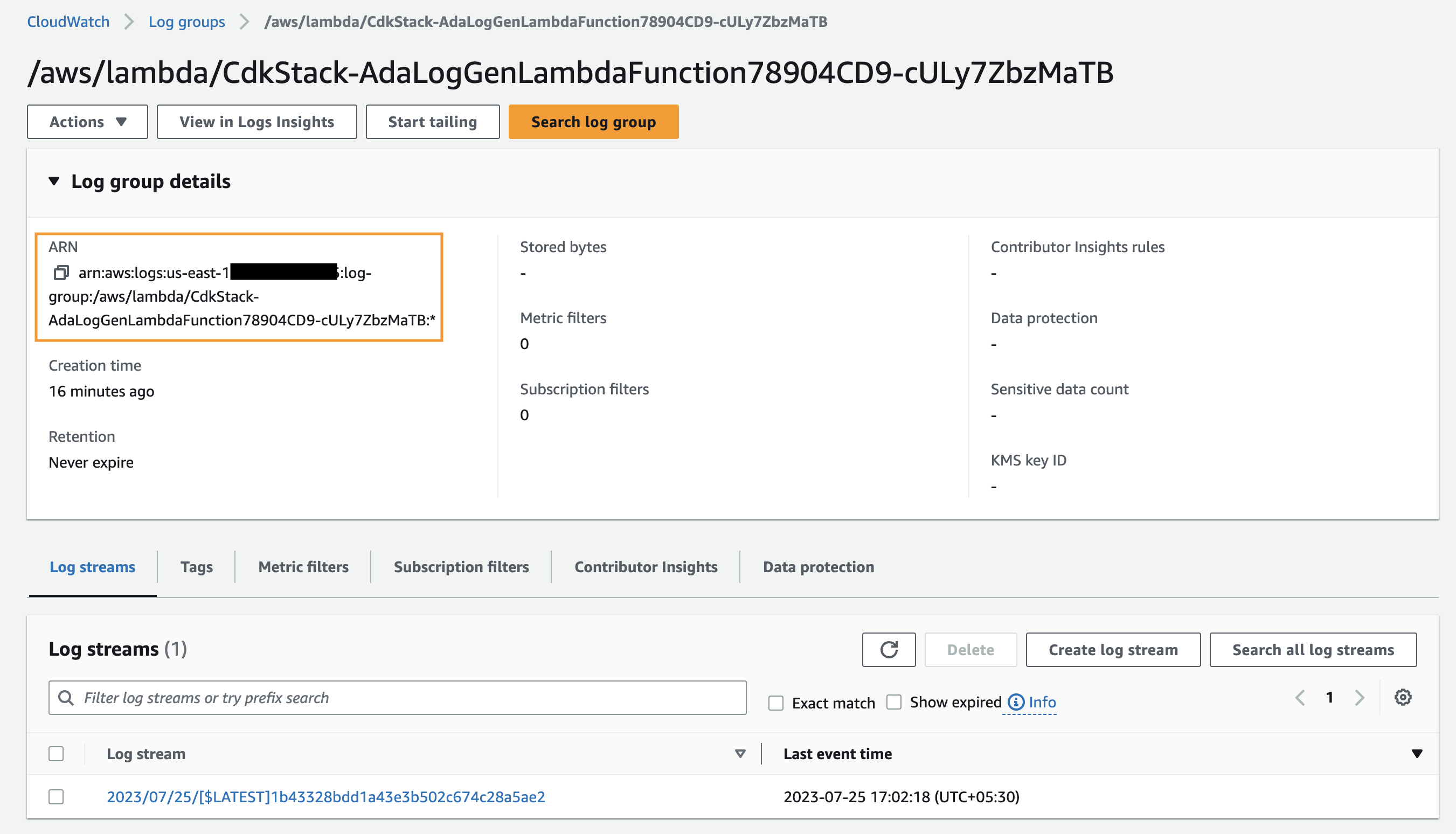
Eerst maken we een gegevensproduct voor de applicatielogboeken door ADA in te stellen om de CloudWatch-logboekgroep voor de voorbeeldapplicatie (Lambda-functie) op te nemen. Gebruik de CdkStack.LambdaFunction uitvoer om de Lambda-functie ARN op te halen en de corresponderende CloudWatch-loggroep ARN op de CloudWatch-console te lokaliseren.
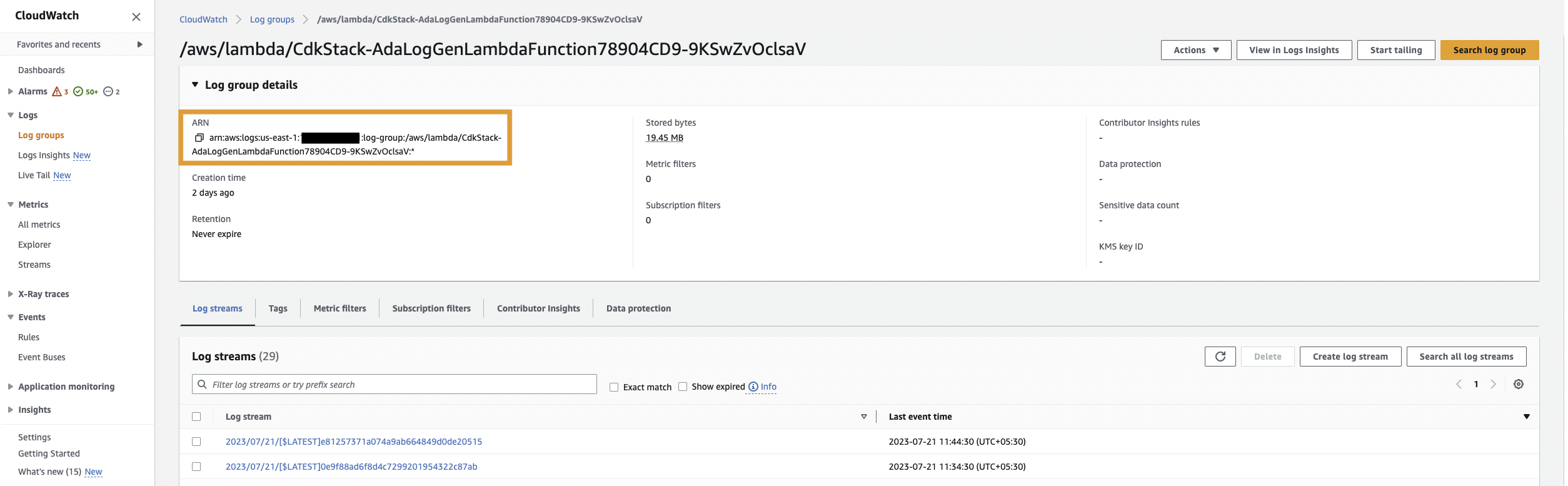
Voer daarna de volgende stappen uit:
- Navigeer op de ADA-console naar het ADA-domein en maak een CloudWatch-dataproduct.
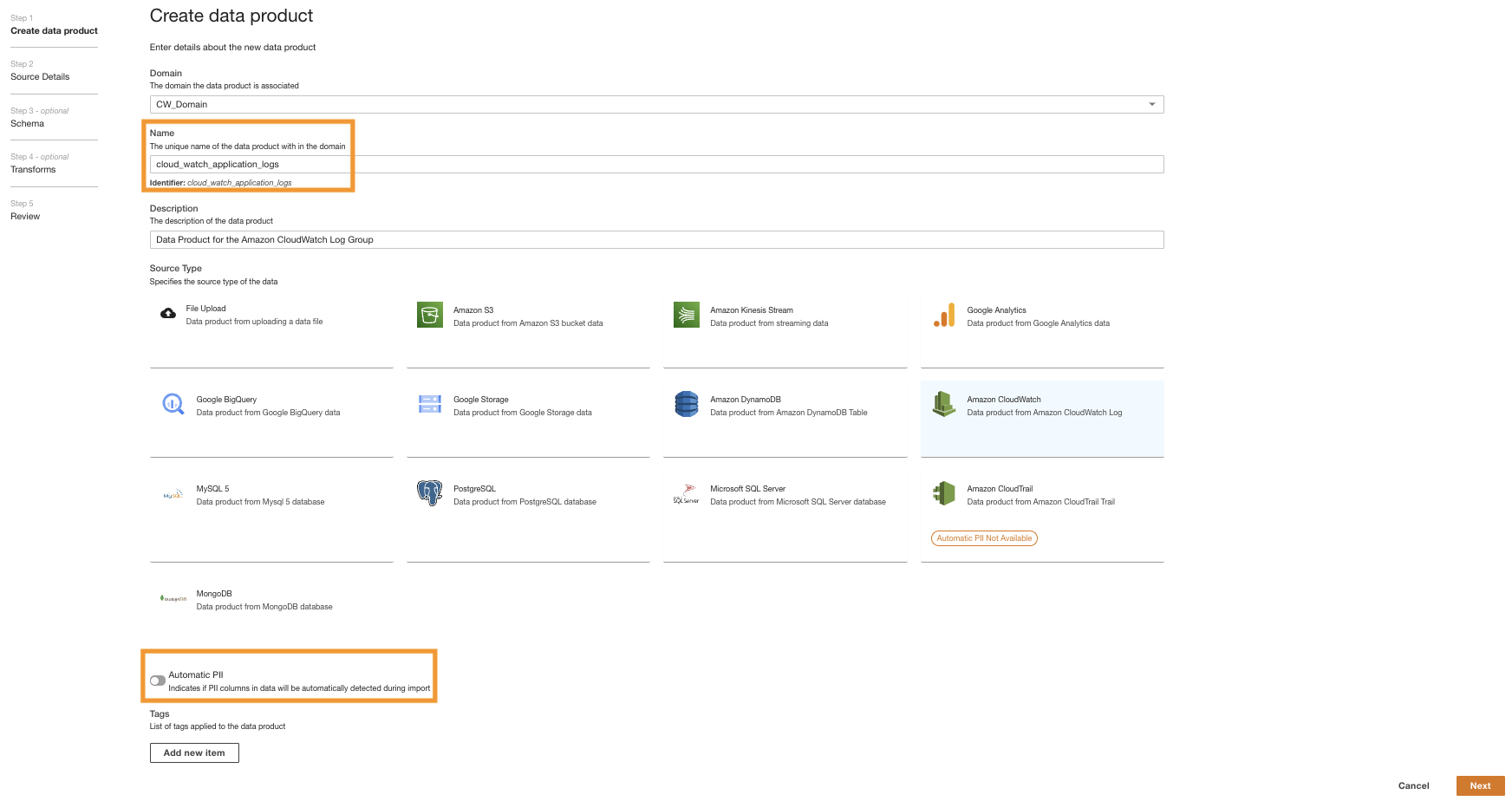
- Voor Naamvoer een naam in.
- Voor Bron Type, kiezen Amazon Cloud Watch.
- onbruikbaar maken Automatische PII.
ADA heeft een functie die automatisch persoonlijk identificeerbare informatie (PII)-gegevens detecteert tijdens het importeren, die standaard is ingeschakeld. Voor deze demo schakelen we deze optie uit voor het dataproduct omdat het ontdekken van PII-gegevens niet binnen de reikwijdte van deze demo valt.
- Kies Volgende.
- Zoek en kies de CloudWatch-loggroep ARN die u uit de vorige stap heeft gekopieerd.

- Kopieer de loggroep ARN.
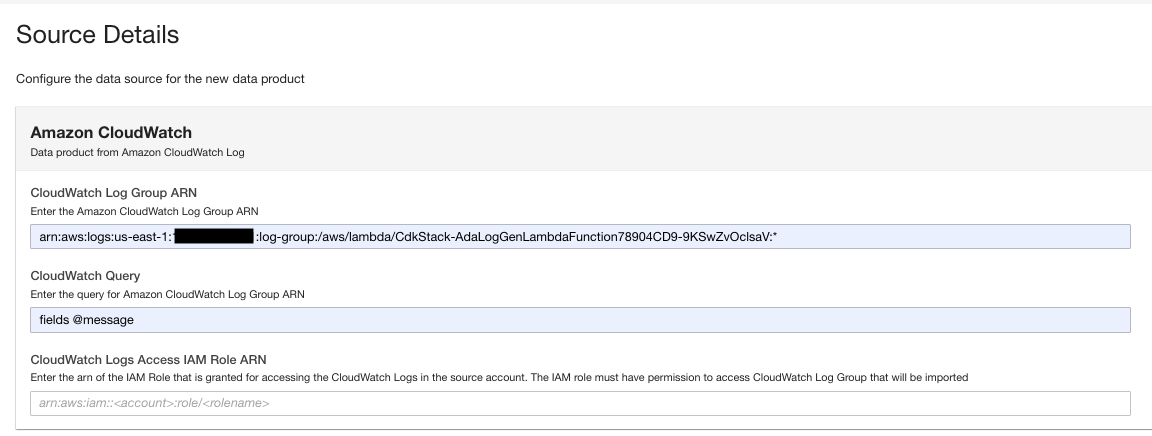
- Voer op de dataproductpagina de loggroep ARN in.
- Voor CloudWatch-queryVoer een query in die u wilt dat ADA ophaalt uit de loggroep.
In deze demo voeren we een query uit op het @message-veld omdat we geïnteresseerd zijn in het ophalen van de applicatielogboeken uit de loggroep.
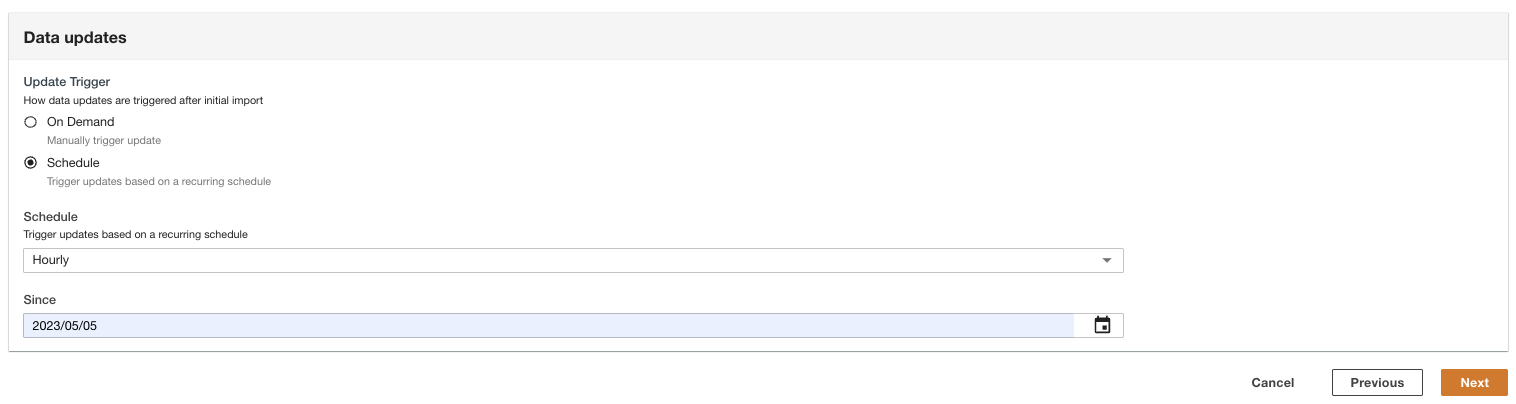
- Selecteer hoe de gegevensupdates worden geactiveerd na de eerste import.
ADA kan worden geconfigureerd om de gegevens uit de bron op flexibele intervallen (tot 15 minuten of later) of op aanvraag op te nemen. Voor de demo hebben we ingesteld dat de gegevensupdates elk uur worden uitgevoerd.
- Kies Volgende.
Vervolgens maakt ADA verbinding met de loggroep en vraagt het schema op. Omdat de logs in Apache Log Format zijn, transformeren we de logs in aparte velden, zodat we queries kunnen uitvoeren op de specifieke logvelden. ADA biedt er vier verzuim transformaties en ondersteunt aangepaste transformatie via een Python-script. In deze demo voeren we een aangepast Python-script uit om het JSON-berichtveld om te zetten in Apache Log Format-velden.
- Kies Transformatieschema.
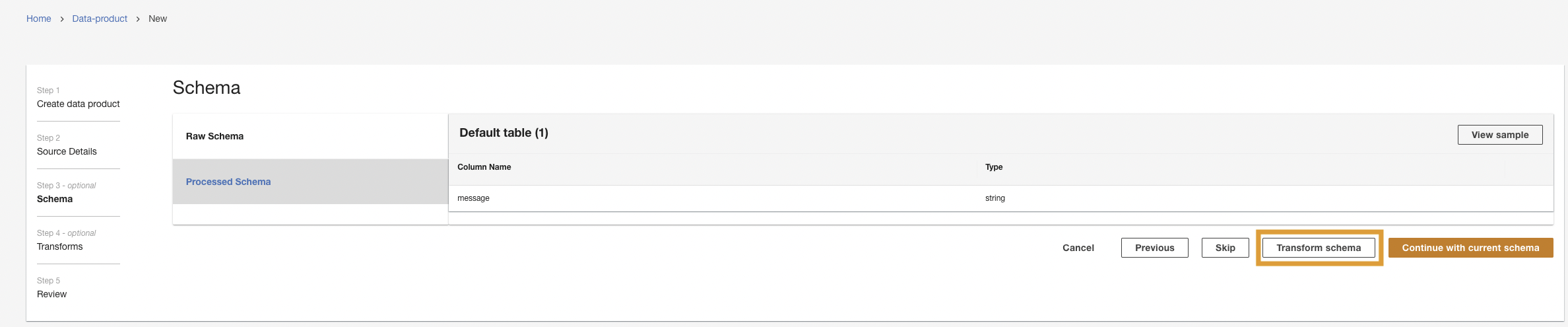
- Kies Creëer een nieuwe transformatie.
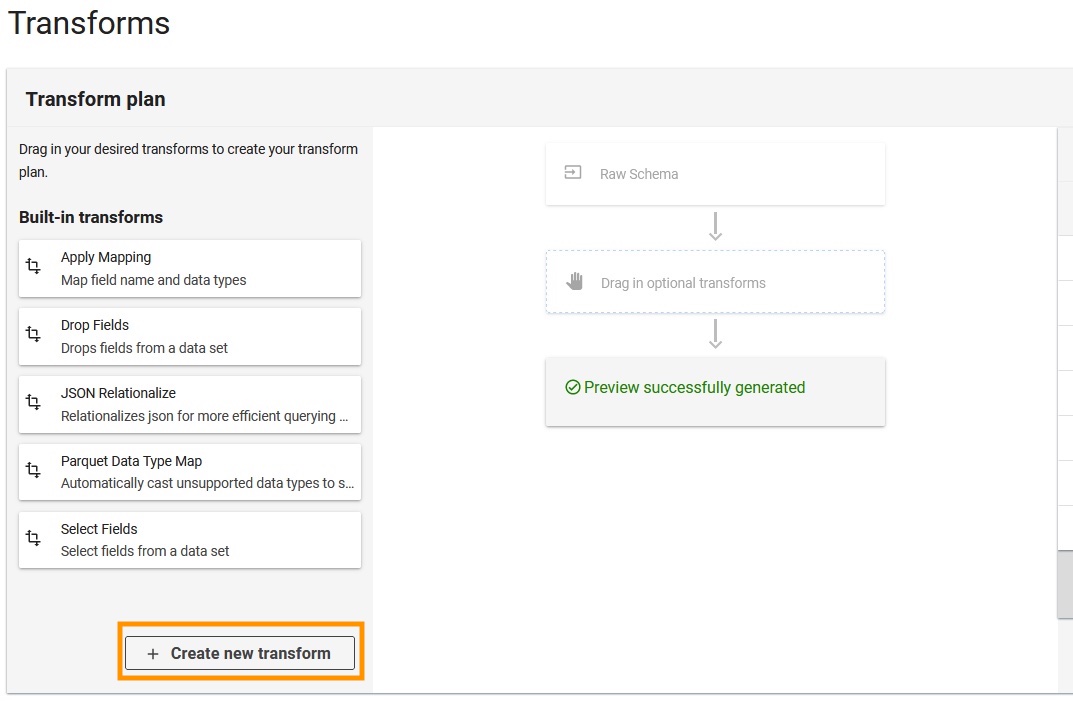
- Upload de
apache-log-extractor-transform.pyscript van de/asset/transform_logs/map. - Kies Verzenden.
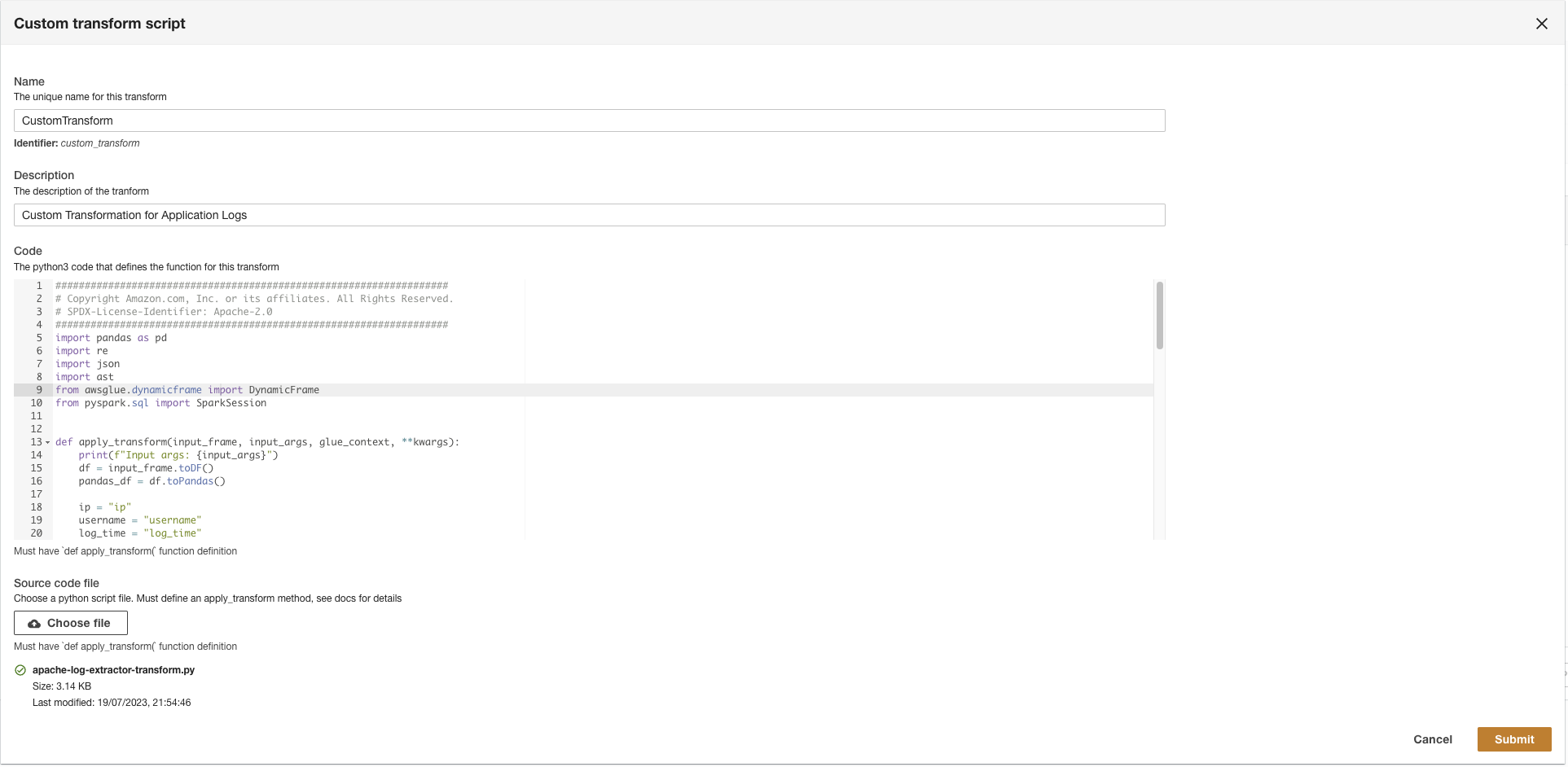
ADA transformeert de CloudWatch-logboeken met behulp van het script en presenteert het verwerkte schema.
- Kies Volgende.
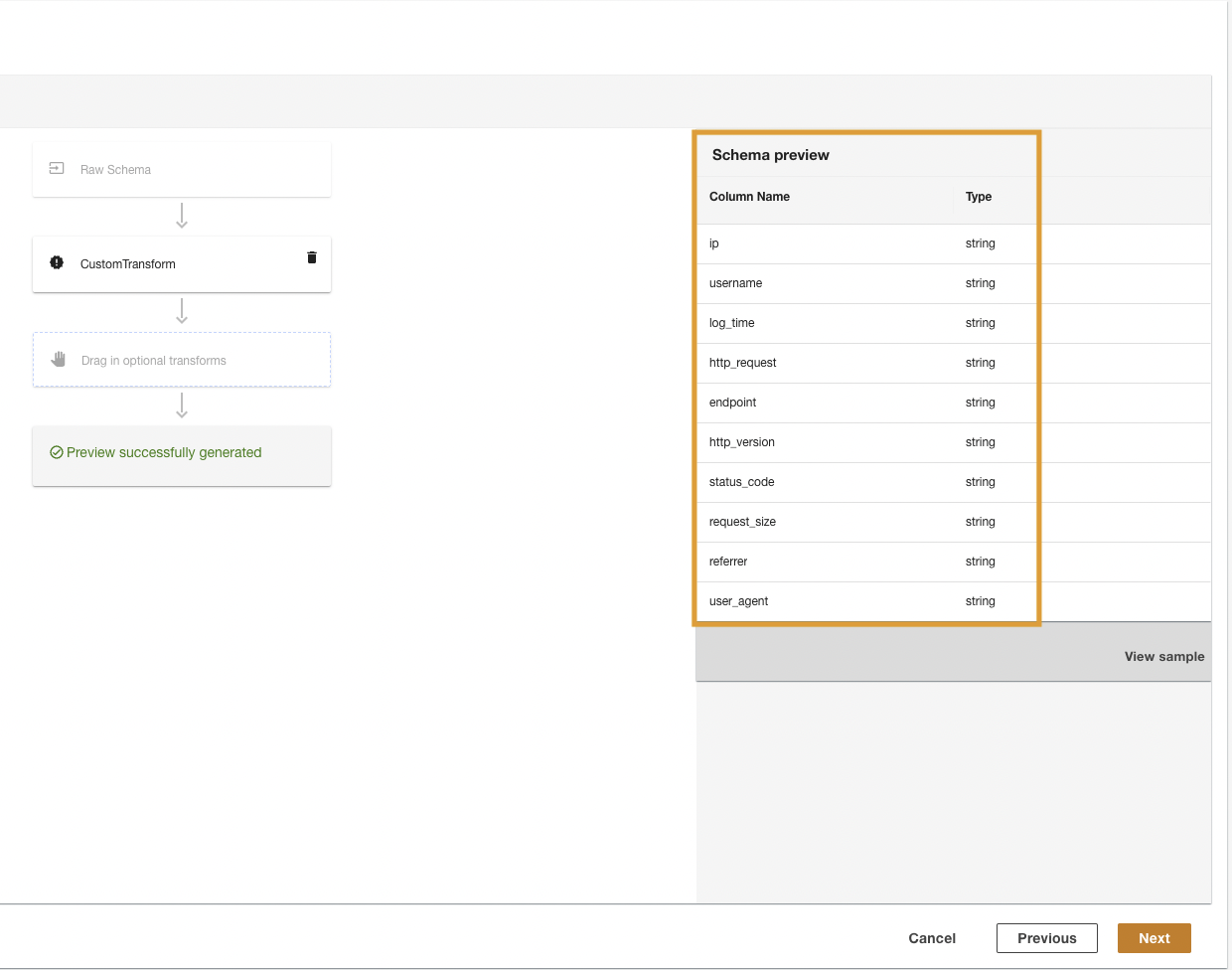
- In de laatste stap bekijkt u de stappen en maakt u een keuze Verzenden.
ADA start de gegevensverwerking, creëert de gegevenspijplijnen en bereidt de CloudWatch-logboekgroepen voor op query's vanuit de Query Workbench. Dit proces duurt een paar minuten en wordt weergegeven op de ADA-console hieronder Gegevensproducten.
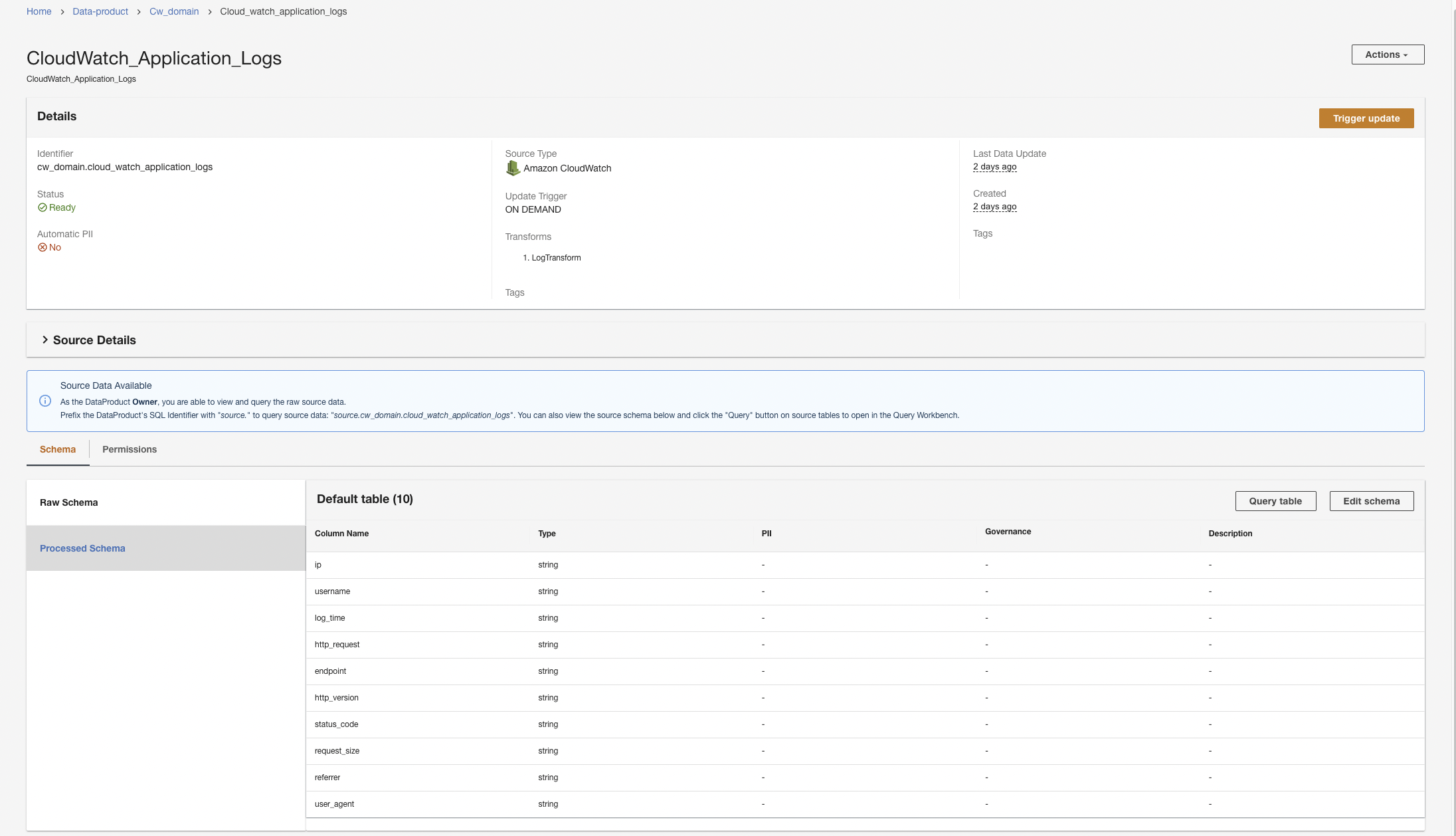
Maak een Amazon S3-dataproduct
We herhalen de stappen om de historische logboeken uit de Amazon S3-gegevensbron toe te voegen en referentiegegevens op te zoeken uit de DynamoDB-tabel. Voor deze twee gegevensbronnen maken we geen aangepaste transformaties omdat de gegevensindelingen in CSV (voor historische logboeken) en sleutelkenmerken (voor referentie-opzoekgegevens) zijn.
- Maak op de ADA-console een nieuw dataproduct.
- Voer een naam in (
hist_logs) en kies Amazon S3.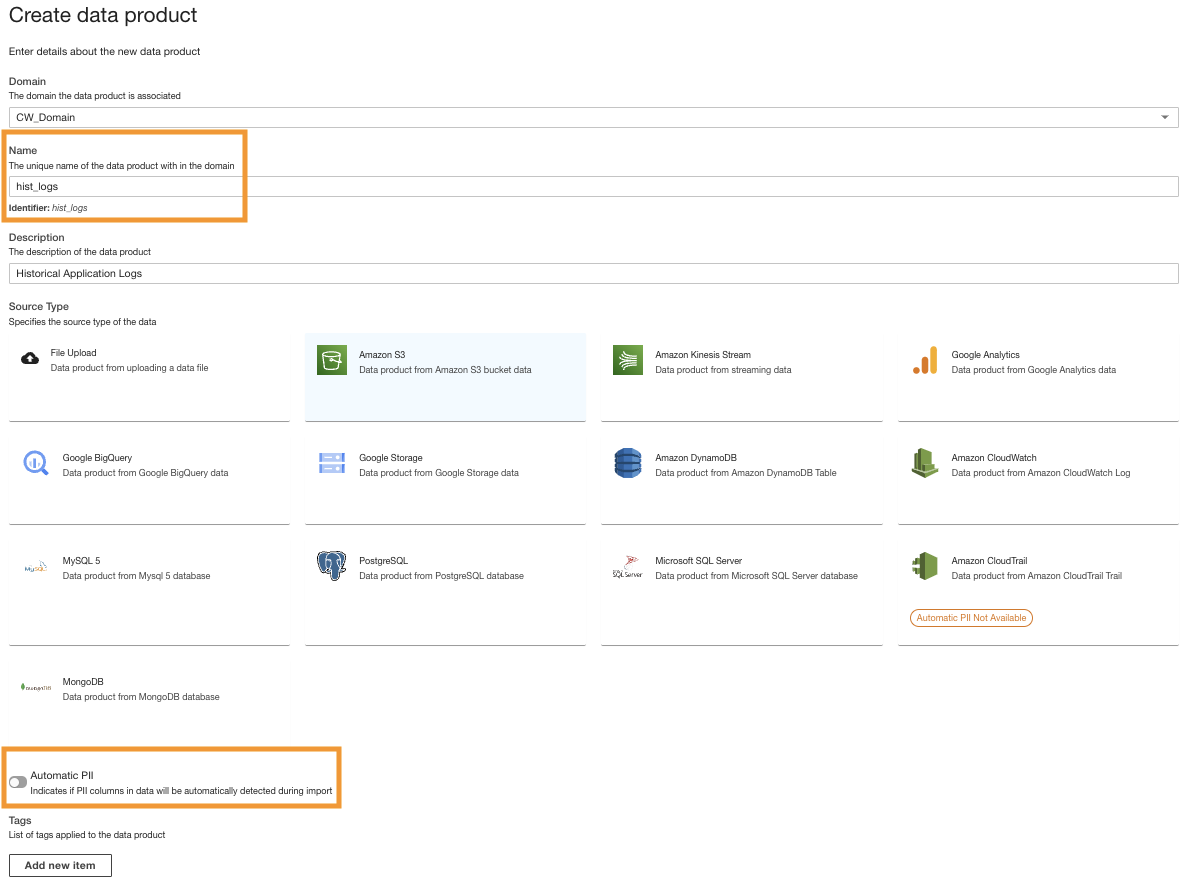
- Kopieer de Amazon S3 URI (de tekst erna
arn:aws:s3:::) Van deCdkStack.S3uitvoervariabele en navigeer naar de Amazon S3-console. - Voer in het zoekvak de gekopieerde tekst in, open de S3-bucket, selecteer de
/logsmap en kies S3-URI kopiëren.
In dit pad worden de historische logs opgeslagen.
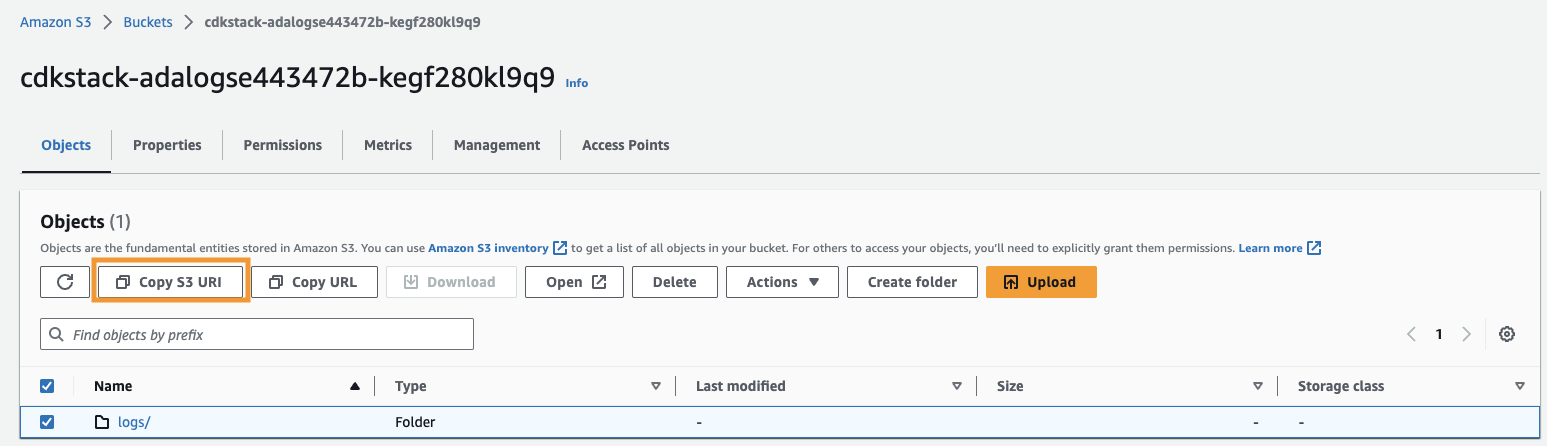
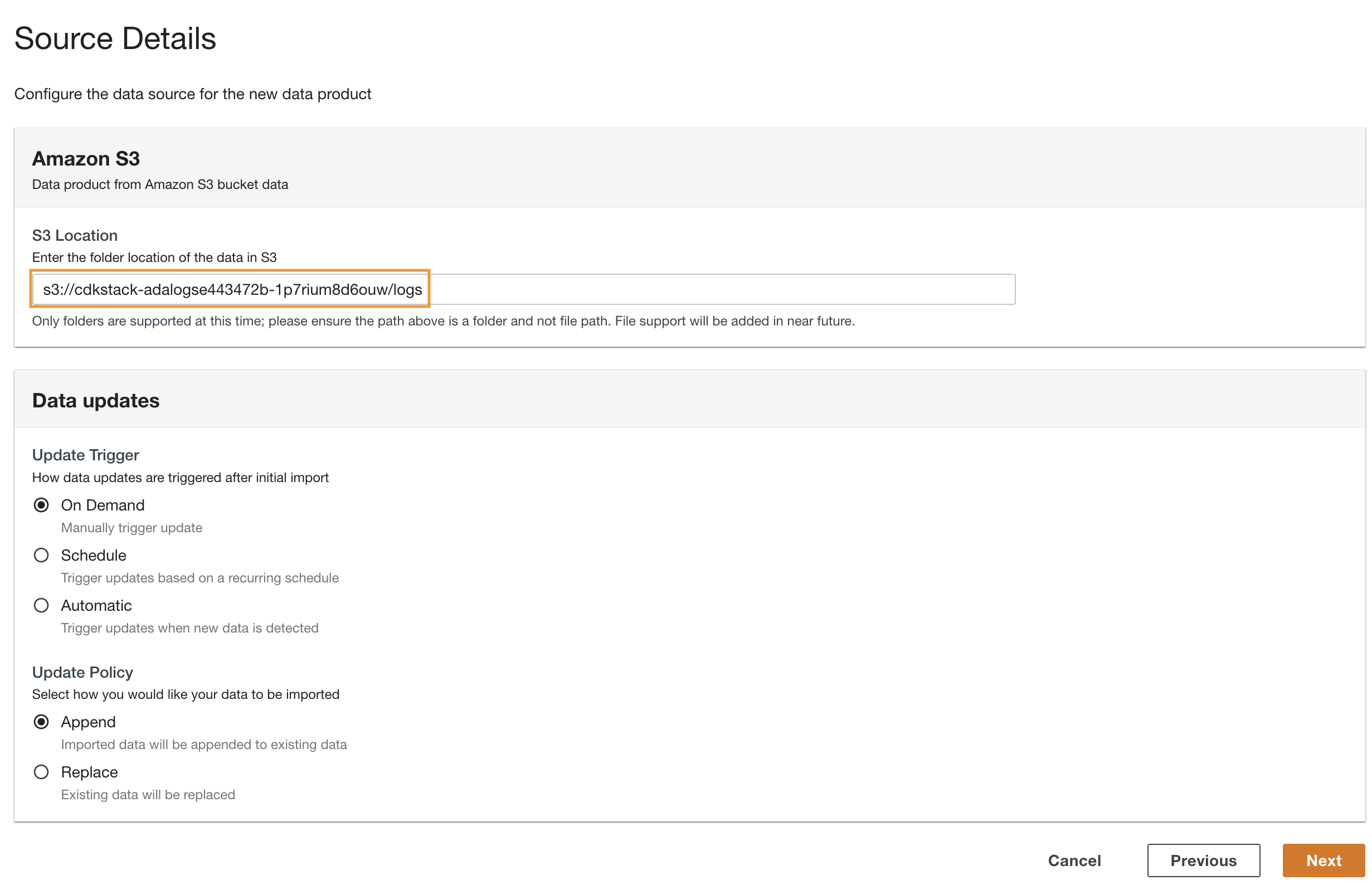
- Navigeer terug naar de ADA-console en voer de gekopieerde S3-URI in voor S3 locatie.
- Voor Trigger bijwerkenselecteer Op aanvraag omdat de historische logboeken met een niet-gespecificeerde frequentie worden bijgewerkt.
- Voor Beleid bijwerkenselecteer toevoegen om nieuw geïmporteerde gegevens aan de bestaande gegevens toe te voegen.
- Kies Volgende.
ADA verwerkt het schema voor de bestanden in het geselecteerde mappad. Omdat de logbestanden in CSV-formaat zijn, kan ADA de kolomnamen lezen zonder dat aanvullende transformaties nodig zijn. Echter, de kolommen status_code en request_size worden door ADA afgeleid als lang type. We willen de kolomgegevenstypen consistent houden tussen de gegevensproducten, zodat we de gegevenstabellen kunnen samenvoegen en de gegevens kunnen opvragen. De kolom status_code wordt gebruikt om joins tussen de gegevenstabellen te maken.
- Kies Transformatieschema om de gegevenstypen van de twee kolommen te wijzigen in een tekenreeksgegevenstype.
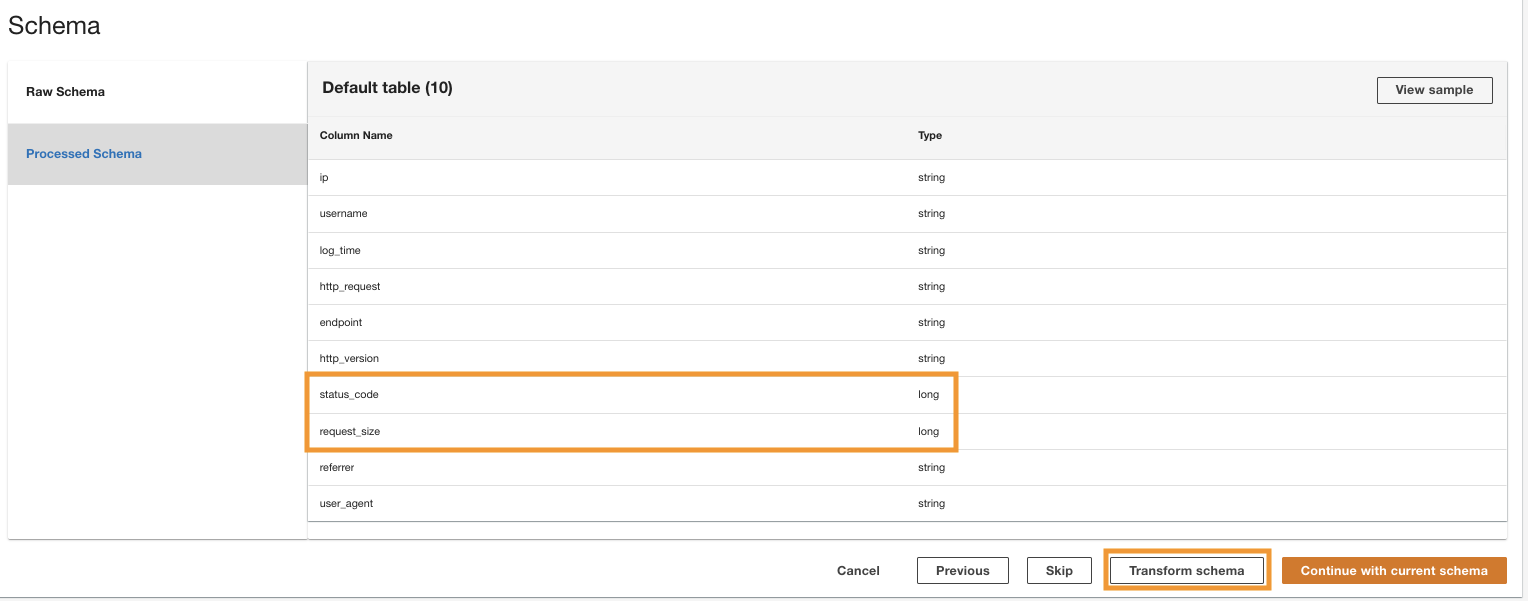
Let op de gemarkeerde kolomnamen in het Schemavoorbeeld voordat de transformaties van het gegevenstype worden toegepast.
- In het Transformatieplan deelvenster, onder Ingebouwde transformaties, kiezen Mapping toepassen.
Met deze optie kunt u het gegevenstype van het ene type naar het andere wijzigen.
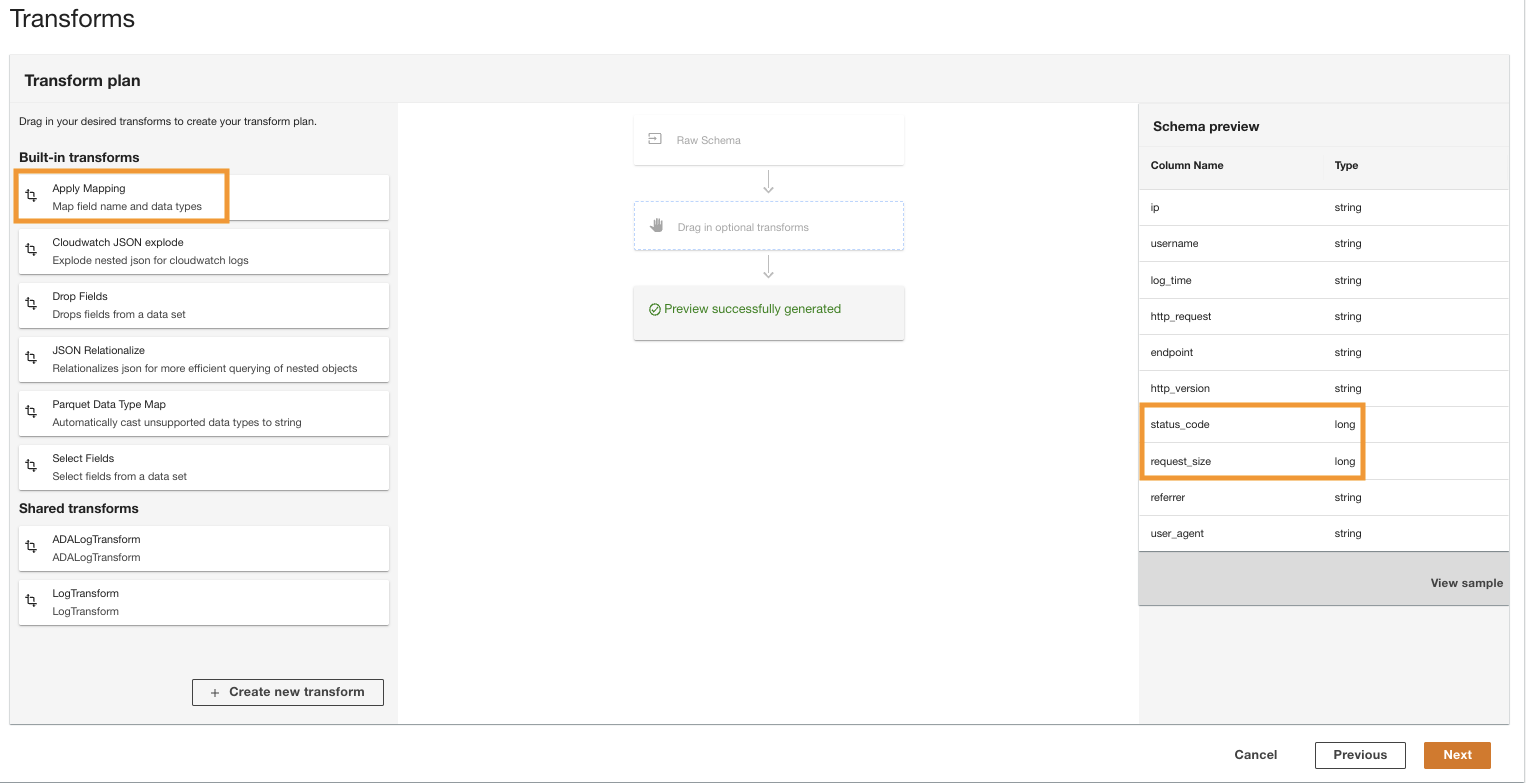
- In het Mapping toepassen sectie, deselecteren Laat andere velden vallen.
Als deze optie niet is uitgeschakeld, blijven alleen de getransformeerde kolommen behouden en worden alle andere kolommen verwijderd. Omdat we alle kolommen willen behouden, schakelen we deze optie uit.
- Onder Veldtoewijzingenvoor Oude naam en Nieuwe naam, ga naar binnen
status_codeen voor Nieuw type, ga naar binnenstring.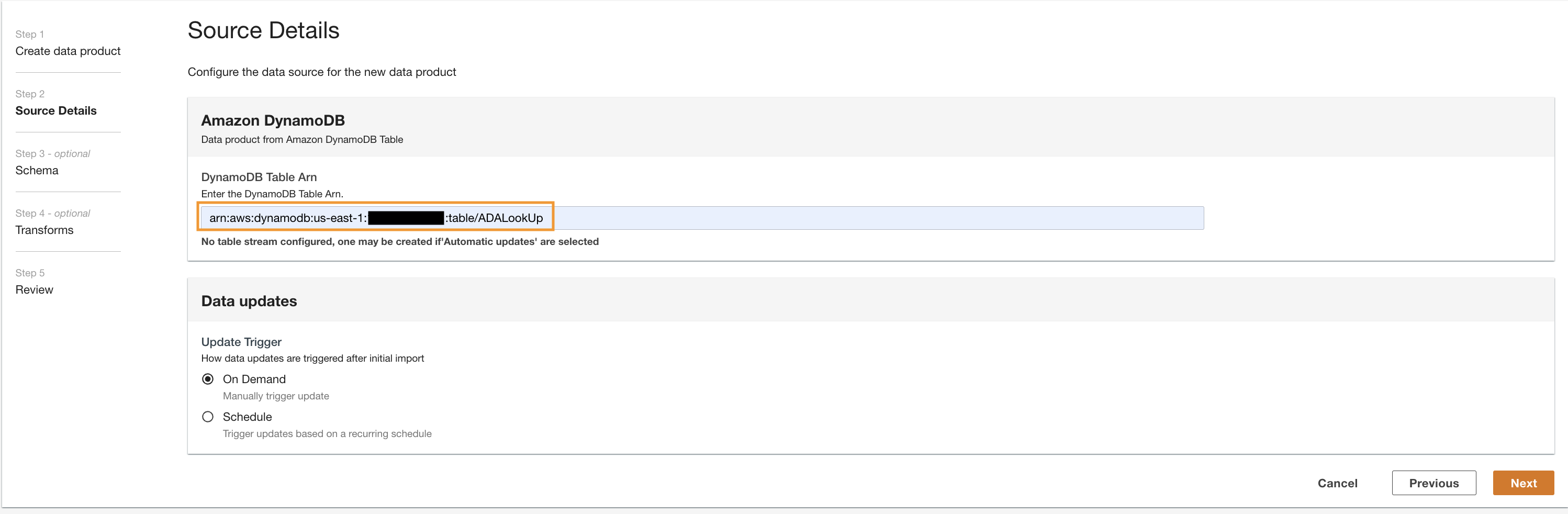
- Kies Voeg item toe.
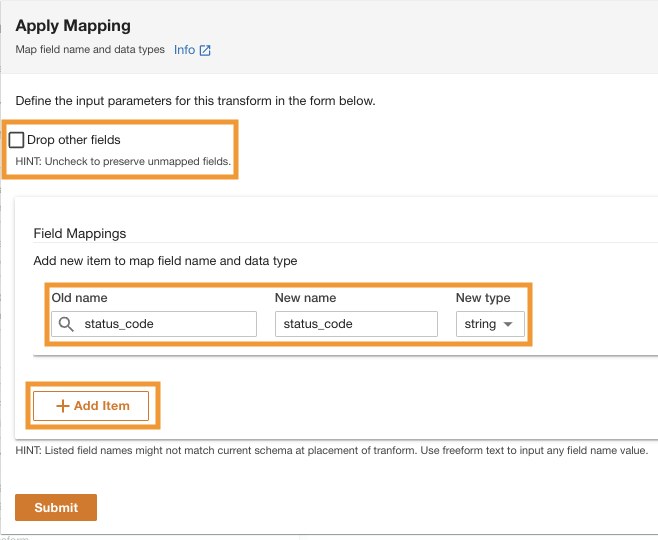
- Voor Oude naam en Nieuwe naam¸ voer request_size en for in Nieuw gegevenstype, voer een tekenreeks in.
- Kies Verzenden.
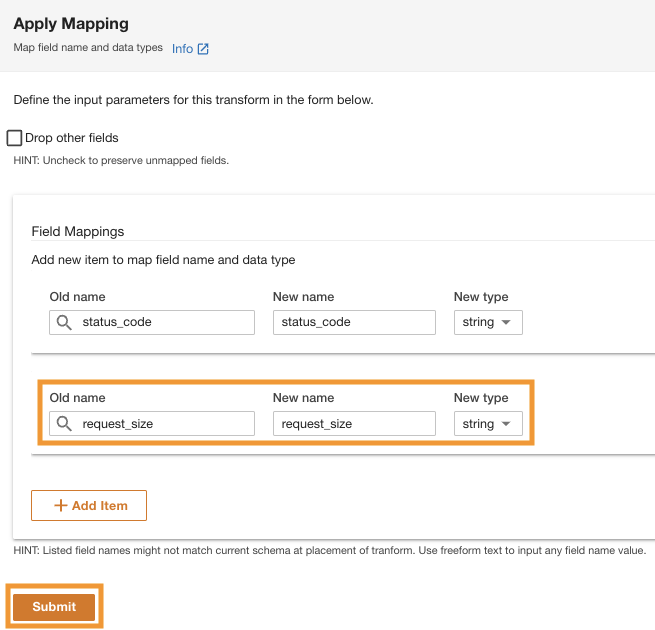
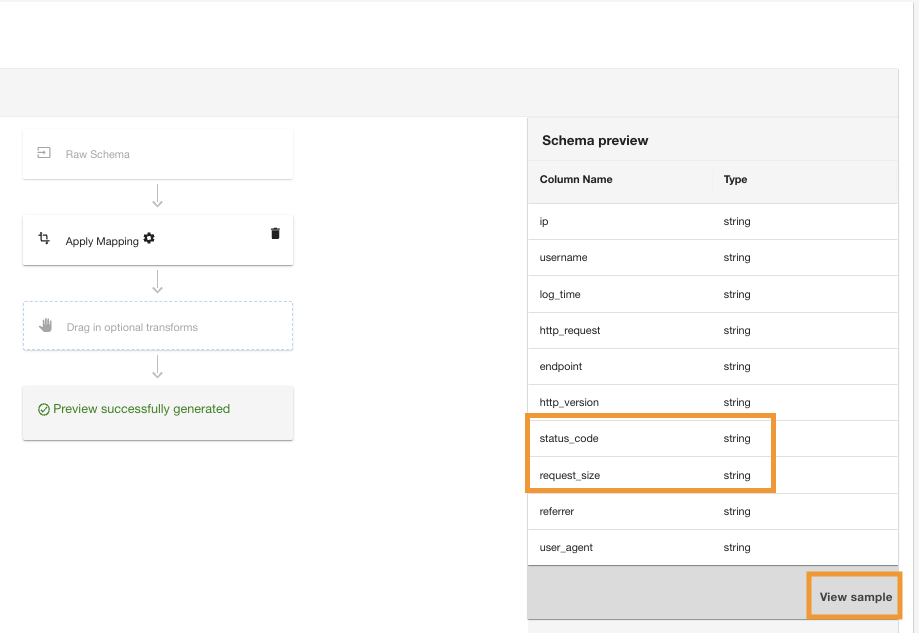
ADA zal de kaarttransformatie toepassen op de Amazon S3-gegevensbron. Let op de kolomtypen in het Schemavoorbeeld brood.
- Kies Bekijk voorbeeld om een voorbeeld van de gegevens te bekijken terwijl de transformatie is toegepast.
ADA geeft de PII-gegevensbevestiging weer om ervoor te zorgen dat alleen geautoriseerde gebruikers de gegevens kunnen bekijken of dat de dataset geen PII-gegevens bevat.
- Kies Instemmen om door te gaan met het bekijken van de voorbeeldgegevens.
Houd er rekening mee dat het schema identiek is aan het CloudWatch-logboekgroepschema, omdat zowel de huidige applicatie- als historische applicatielogboeken de Apache-logboekindeling hebben.
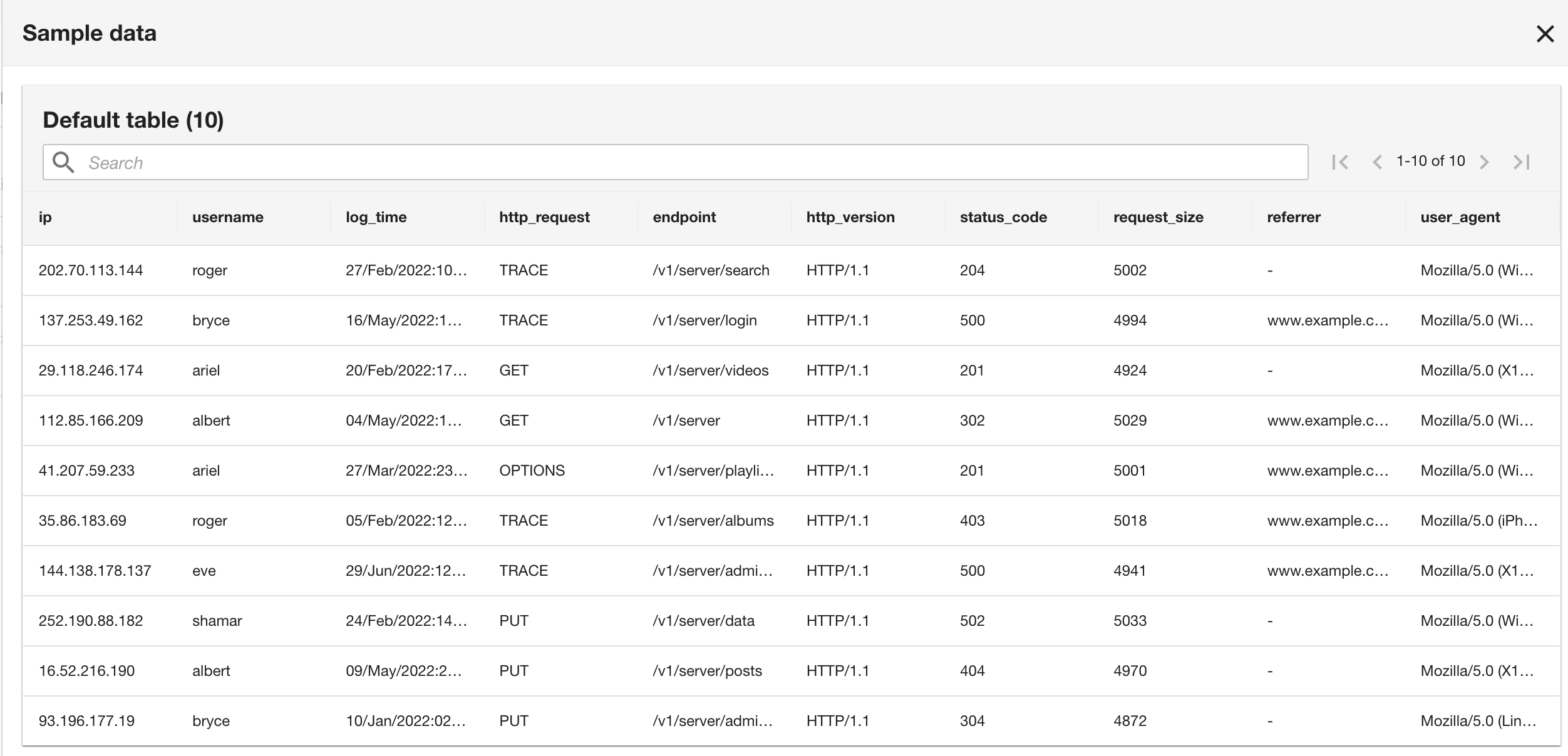
- In de laatste stap bekijkt u de configuratie en maakt u een keuze Verzenden.
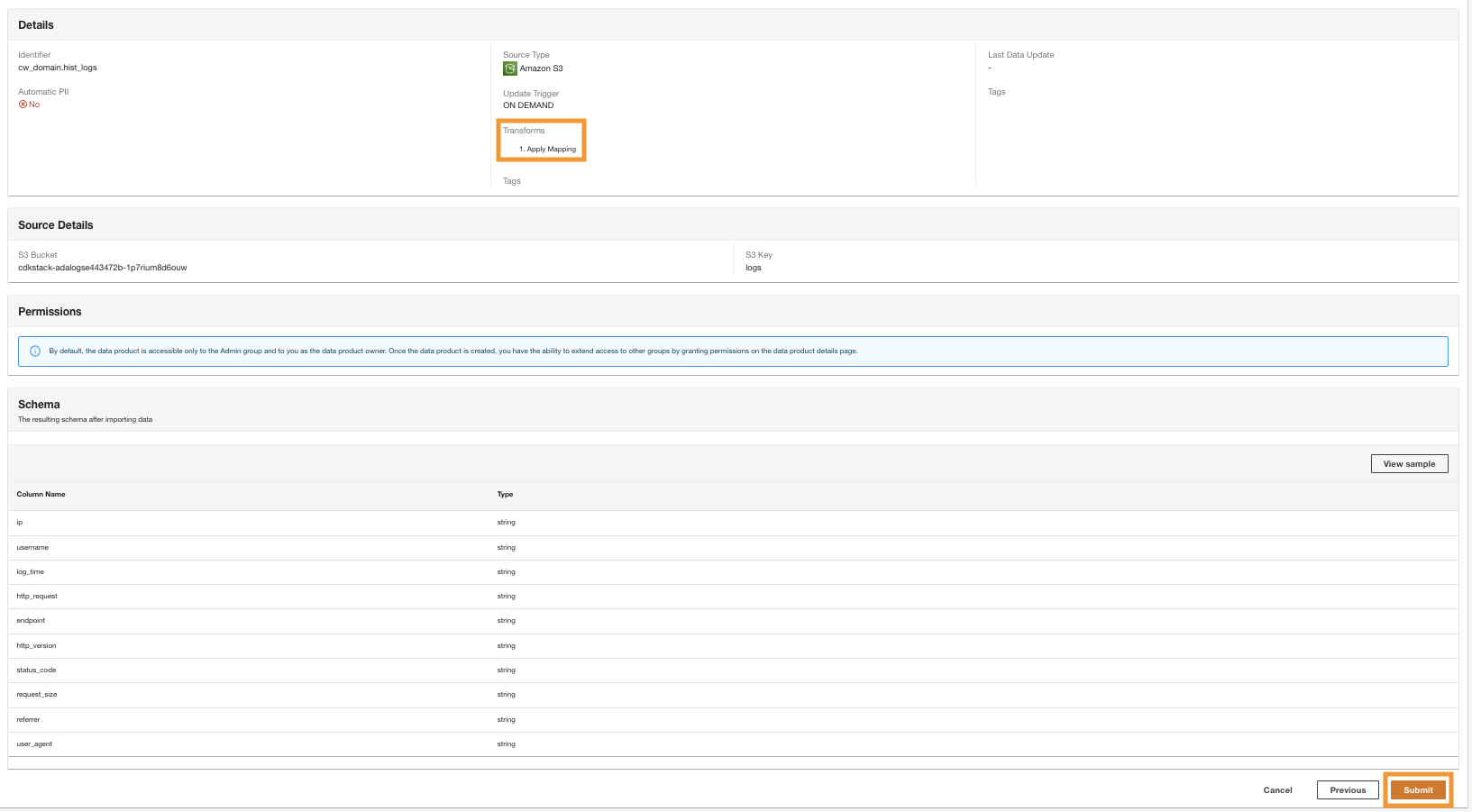
ADA begint met het verwerken van de gegevens uit de Amazon S3-bron, creëert de backend-infrastructuur en bereidt het dataproduct voor. Dit proces duurt enkele minuten, afhankelijk van de grootte van de gegevens.
Maak een DynamoDB-gegevensproduct
Ten slotte creëren we een DynamoDB-dataproduct. Voer de volgende stappen uit:
- Maak op de ADA-console een nieuw dataproduct.
- Voer een naam in (
lookup) en kies Amazon DynamoDB.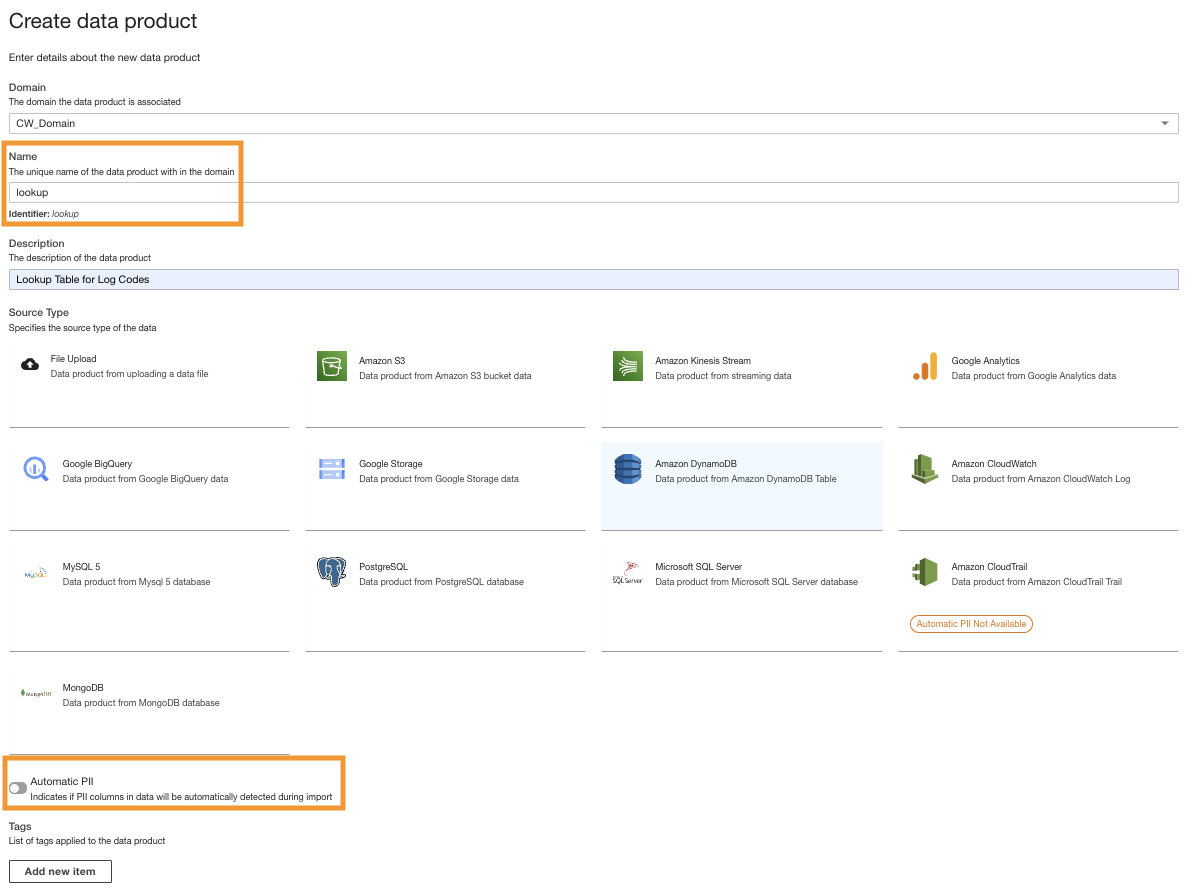
- Voer de
Cdk.DynamoDBTableuitvoervariabele voor DynamoDB-tabel ARN.
Deze tabel bevat sleutelkenmerken die in deze demo als opzoektabel zullen worden gebruikt. Voor de opzoekgegevens gebruiken we de HTTP-codes en lange en korte beschrijvingen van de codes. U kunt als alternatief ook PostgreSQL, MySQL of een CSV-bestandsbron gebruiken.
- Voor Trigger bijwerkenselecteer On-Demand.
De updates zullen op aanvraag plaatsvinden, omdat de zoekopdracht voornamelijk ter referentie dient tijdens het uitvoeren van query's. Eventuele updates van de opzoekgegevens kunnen in ADA worden bijgewerkt met behulp van triggers op aanvraag.
- Kies Volgende.
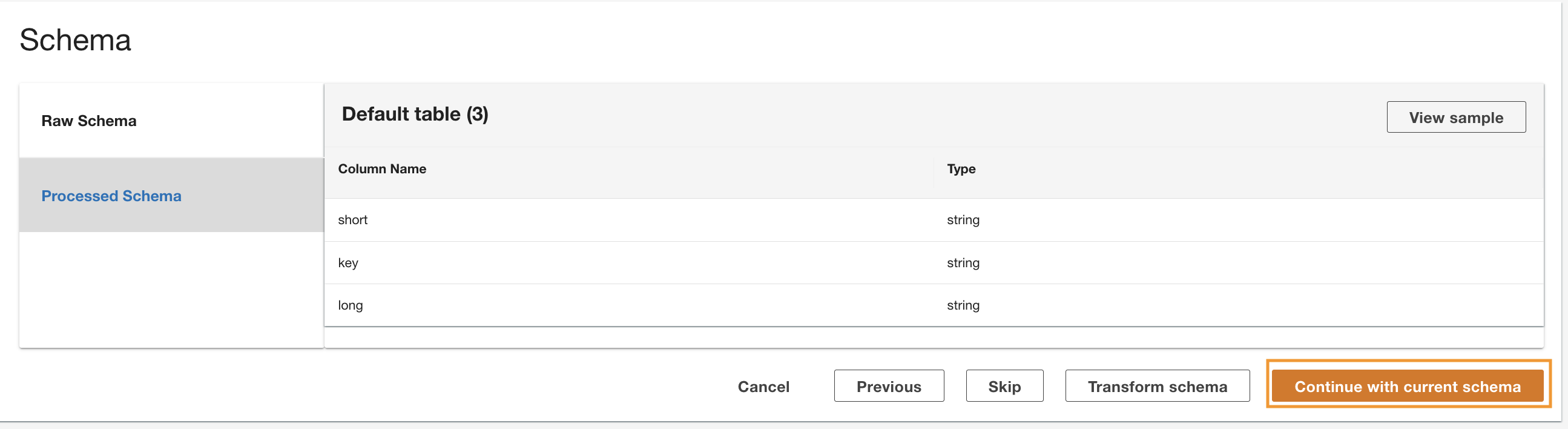
ADA leest het schema uit het onderliggende DynamoDB-schema en presenteert de kolomnaam en het type voor optionele transformatie. We gaan verder met de standaardschemaselectie omdat de kolomtypen consistent zijn met de typen uit de CloudWatch-loggroep en de Amazon S3 CSV-gegevensbron. Als we gegevenstypen hebben die consistent zijn in alle gegevensbronnen, kunnen we query's schrijven om records op te halen door de tabellen samen te voegen met behulp van de kolomvelden. De kolom bijvoorbeeld key in het DynamoDB-schema komt overeen met de status_code in de dataproducten Amazon S3 en CloudWatch. We kunnen query's schrijven die de drie tabellen kunnen samenvoegen met behulp van de kolomnaam key. Een voorbeeld wordt getoond in de volgende sectie.
- Kies Ga verder met het huidige schema.
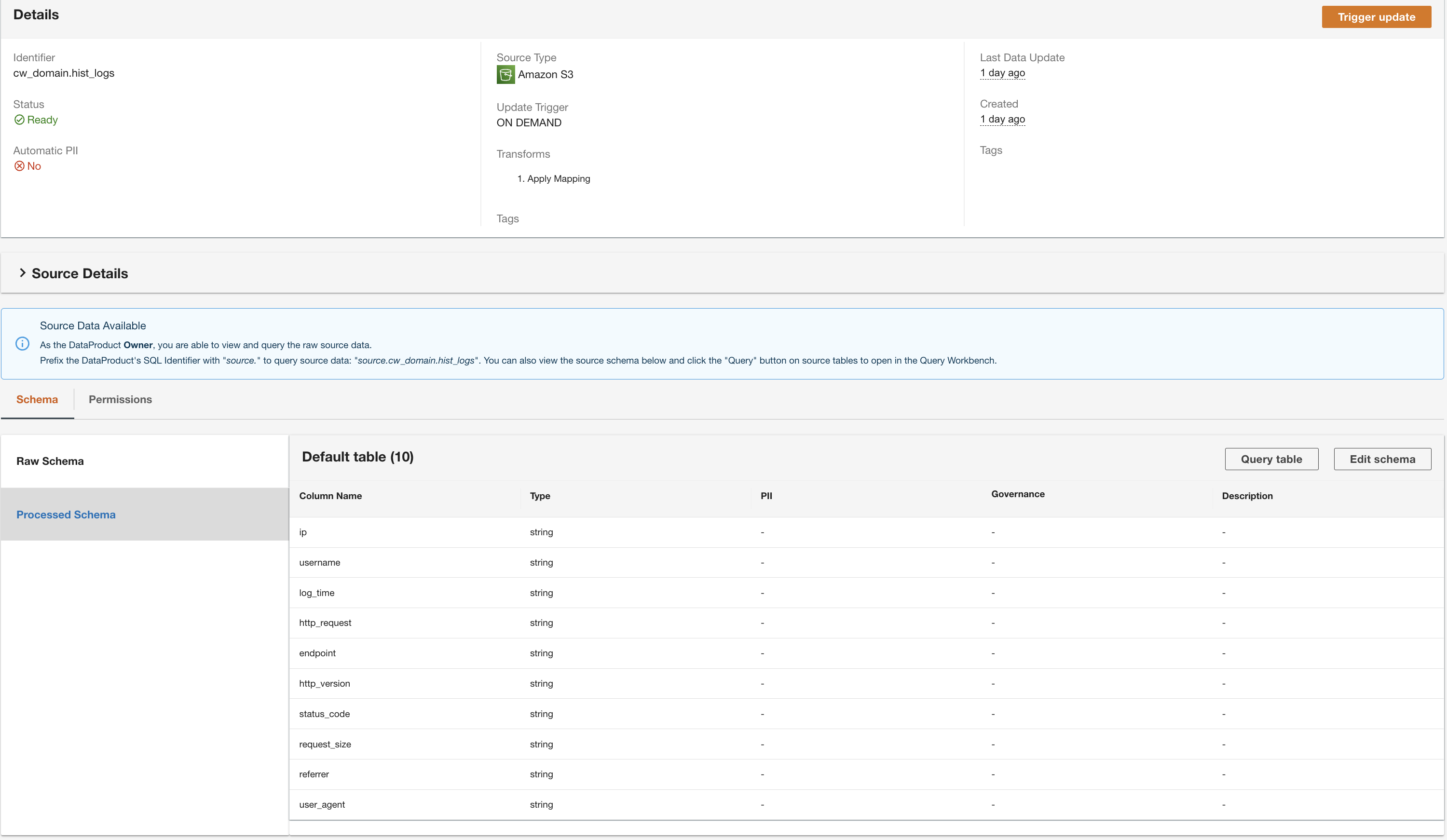
- Bekijk de configuratie en kies Verzenden.
ADA verwerkt de gegevens uit de DynamoDB-tabelgegevensbron en bereidt het gegevensproduct voor. Afhankelijk van de grootte van de gegevens duurt dit proces enkele minuten.
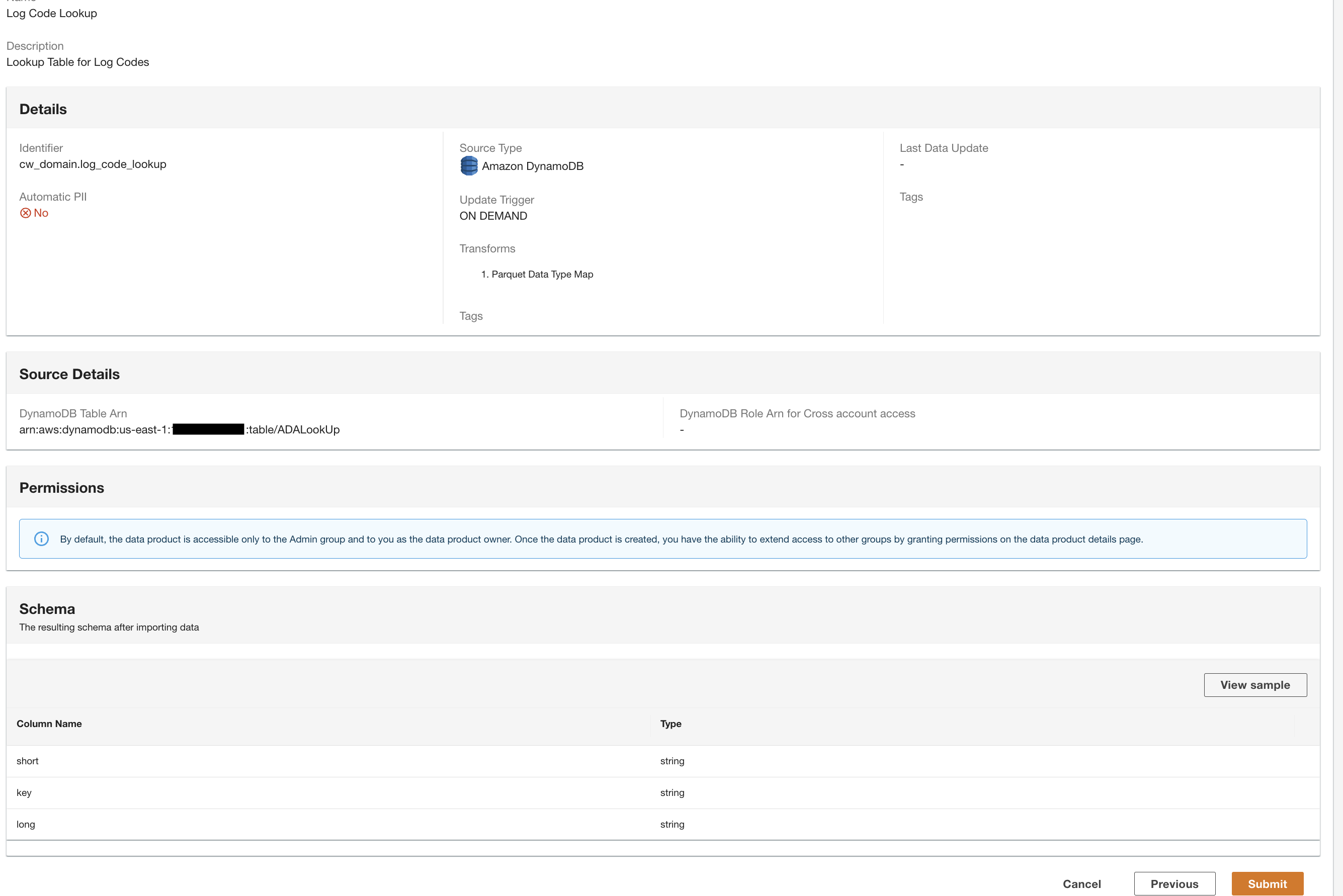
Nu hebben we alle drie de gegevensproducten verwerkt door ADA en beschikbaar voor u om zoekopdrachten uit te voeren.

Gebruik de Query Workbench om de gegevens op te vragen
Met ADA kunt u query's uitvoeren op de dataproducten, terwijl u de gegevensbron abstraheert en deze toegankelijk maakt met behulp van SQL (Structured Query Language). U kunt query's schrijven en de tabellen samenvoegen, net zoals u query's zou uitvoeren op tabellen in een relationele database. We demonstreren de querymogelijkheden van ADA via twee gebruikersscenario's. In beide scenario's voegen we een toepassingslogboekgegevensset toe aan de opzoektabel voor foutcodes. In het eerste gebruiksscenario doorzoeken we de huidige applicatielogboeken om de top 10 van meest gebruikte applicatie-eindpunten te identificeren, samen met de bijbehorende HTTP-statuscodes:
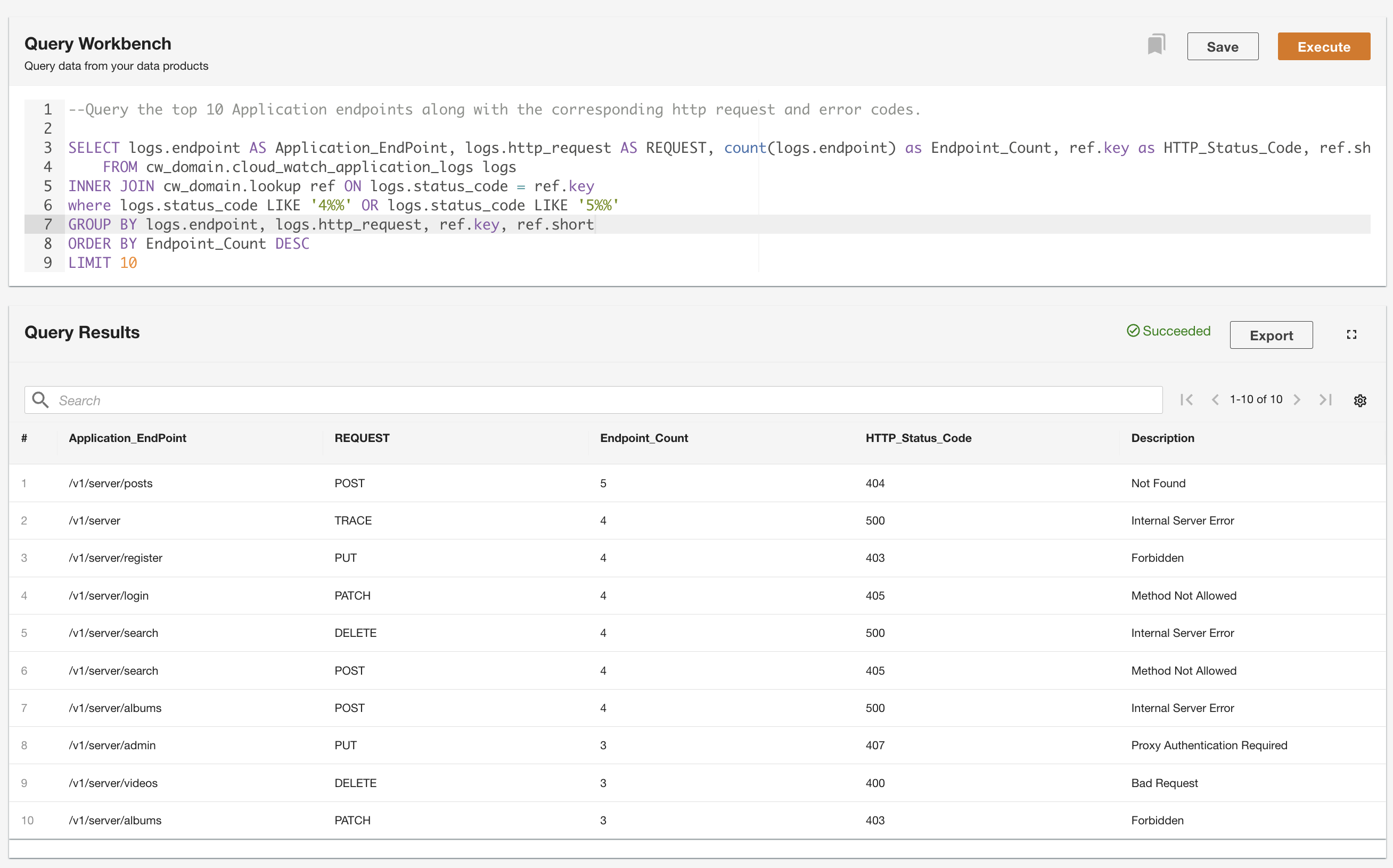
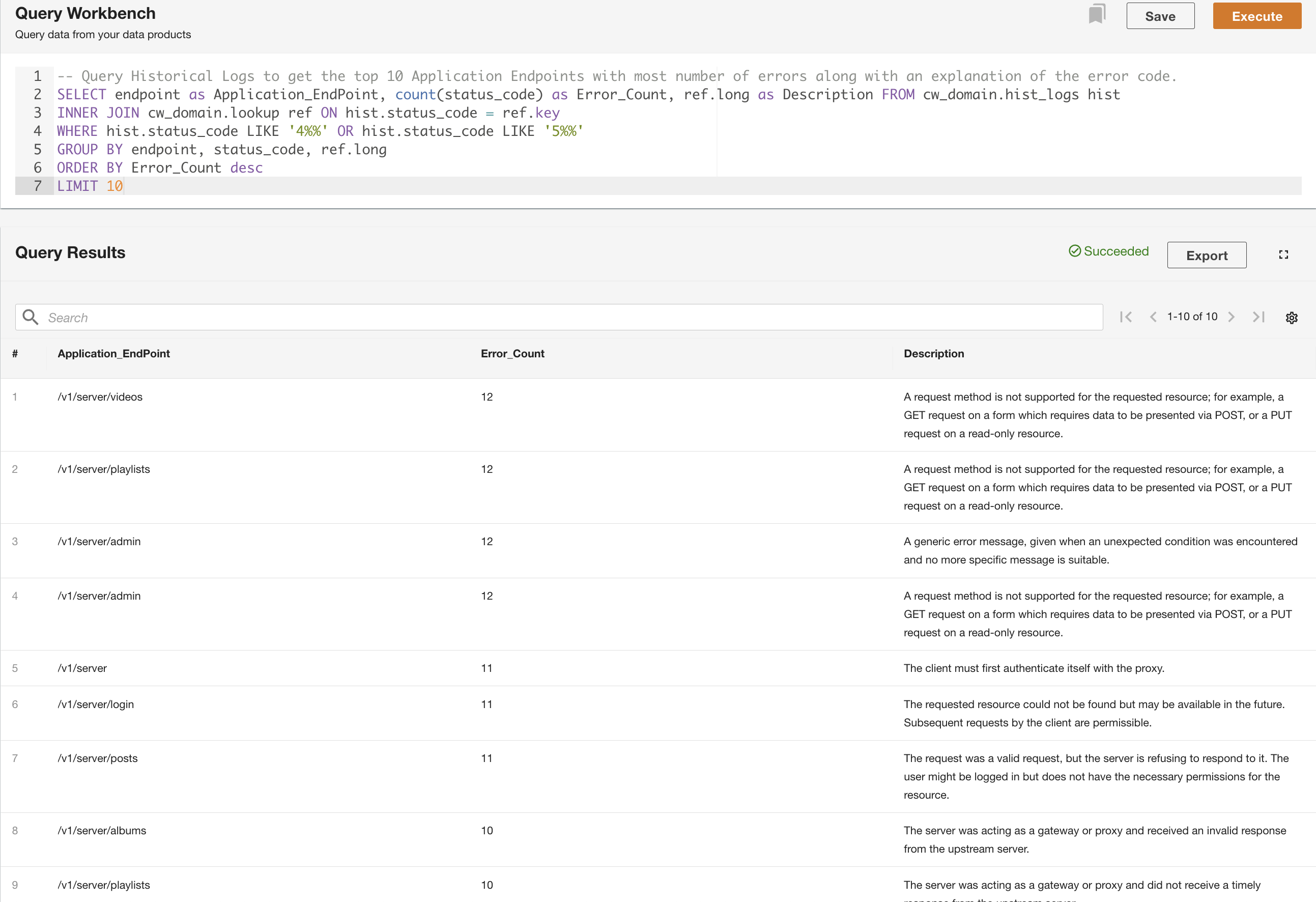
In het tweede voorbeeld doorzoeken we de tabel met historische logboeken om de top 10 van applicatie-eindpunten met de meeste fouten te achterhalen, zodat we het aanroeppatroon van het eindpunt kunnen begrijpen:
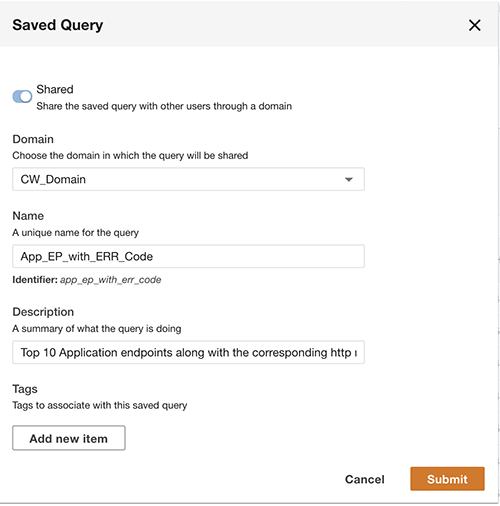
Naast het uitvoeren van query's kunt u de query optioneel opslaan en de opgeslagen query delen met andere gebruikers in hetzelfde domein. De gedeelde query's zijn rechtstreeks toegankelijk vanuit de Query Workbench. De zoekopdrachtresultaten kunnen ook naar CSV-formaat worden geëxporteerd.
Visualiseer ADA-dataproducten in Tableau
ADA biedt de mogelijkheid om connect naar BI-tools van derden om gegevens te visualiseren en rapporten te maken op basis van de ADA-dataproducten. In deze demo gebruiken we de native integratie van ADA met Tableau om de gegevens van de drie dataproducten die we eerder hebben geconfigureerd te visualiseren. Gebruik de Athena-connector van Tableau en volg de stappen in Tableau-configuratie, kun je ADA configureren als gegevensbron in Tableau. Nadat er een succesvolle verbinding tot stand is gebracht tussen Tableau en ADA, zal Tableau de drie dataproducten onder de Tableau-catalogus vullen cw_domain.
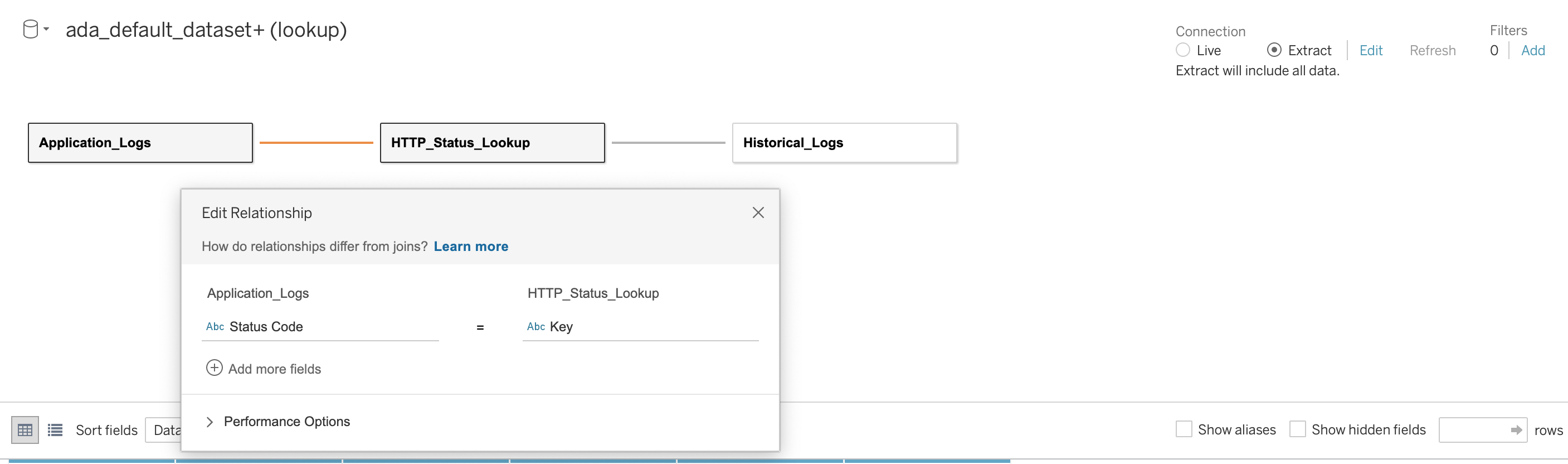
Vervolgens brengen we een relatie tot stand tussen de drie databases met behulp van de HTTP-statuscode als de verbindingskolom, zoals weergegeven in de volgende schermafbeelding. Met Tableau kunnen we zowel online als offline met de databronnen werken. In de onlinemodus maakt Tableau verbinding met ADA en bevraagt de dataproducten live. In de offline modus kunnen we de Extract optie om de gegevens uit ADA te extraheren en de gegevens in Tableau te importeren. In deze demo importeren we de gegevens in Tableau om de zoekopdrachten responsiever te maken. Vervolgens slaan we de Tableau-werkmap op. We kunnen de gegevens uit de gegevensbronnen inspecteren door de database en te kiezen Update nu.
Met de gegevensbronconfiguraties in Tableau kunnen we aangepaste rapporten, grafieken en visualisaties maken voor de ADA-gegevensproducten. Laten we twee gebruiksscenario's voor visualisaties bekijken.
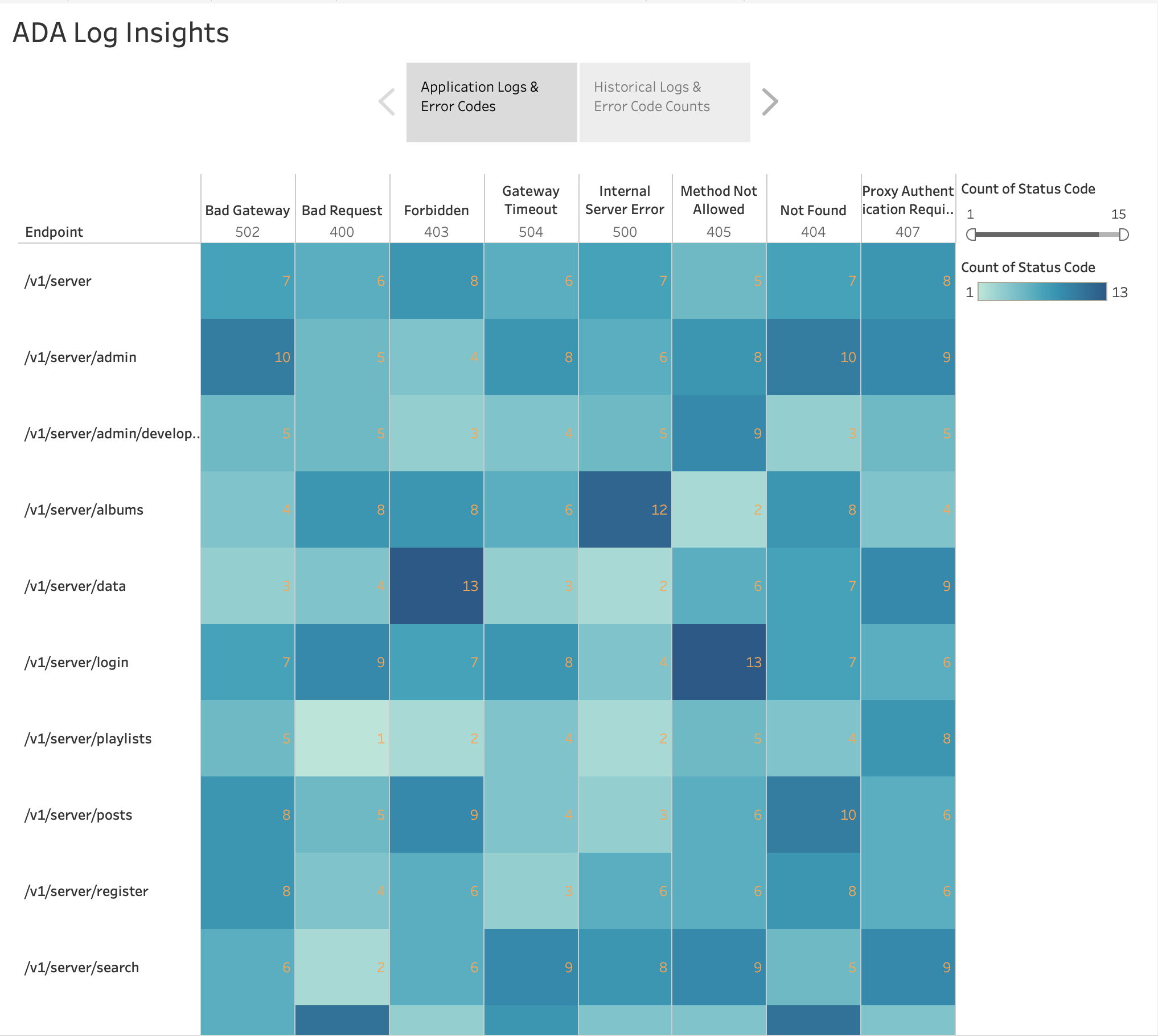
Zoals weergegeven in de volgende afbeelding hebben we de frequentie van de HTTP-fouten per applicatie-eindpunten gevisualiseerd met behulp van de ingebouwde Tableau-functie hittekaart grafiek. We hebben de HTTP-statuscodes eruit gefilterd om alleen foutcodes in het 4xx- en 5xx-bereik op te nemen.
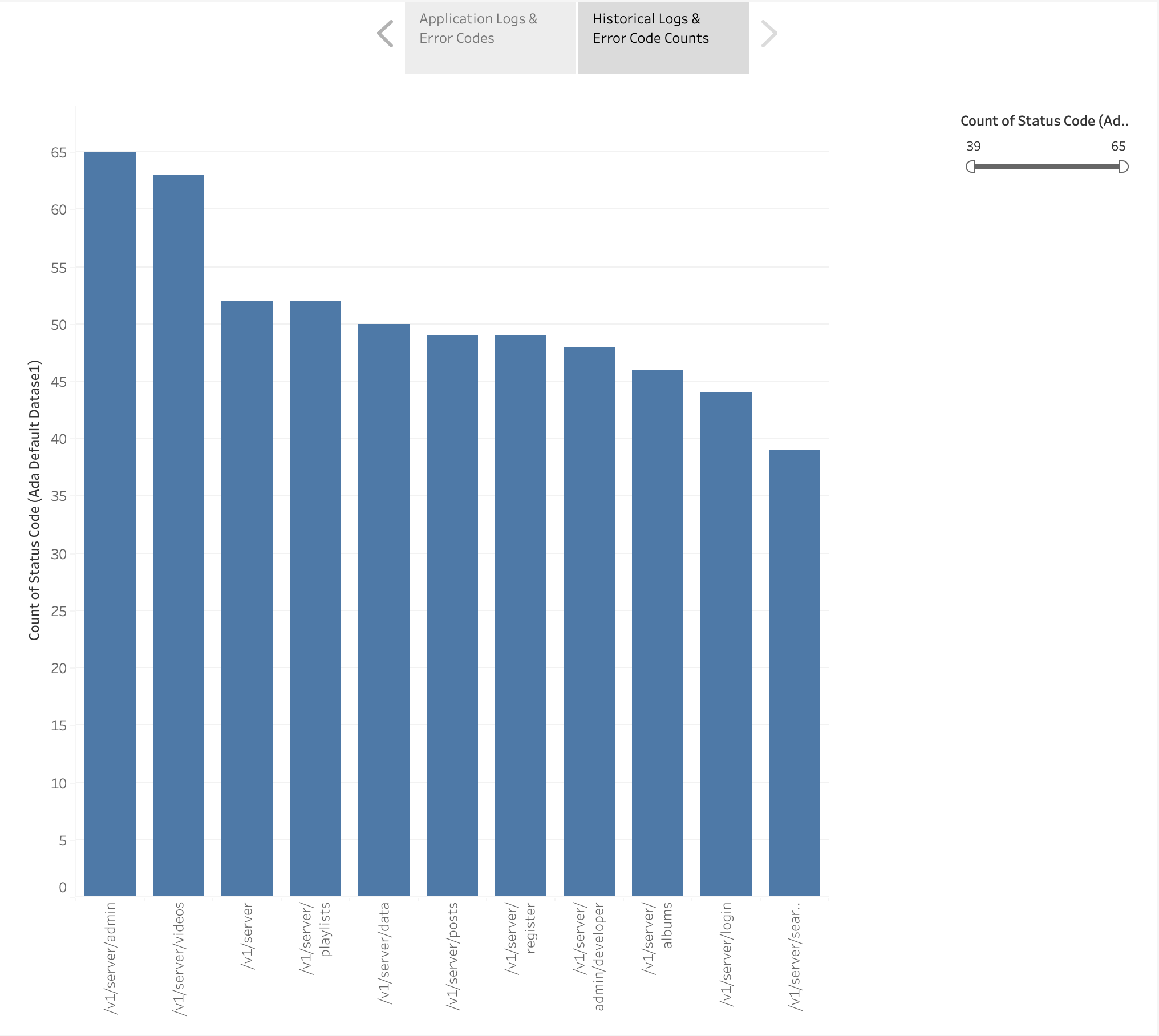
We hebben ook een staafdiagram gemaakt om de applicatie-eindpunten weer te geven op basis van de historische logboeken, gerangschikt op basis van het aantal HTTP-foutcodes. In deze grafiek kunnen we zien dat de /v1/server/admin eindpunt heeft de meeste HTTP-foutstatuscodes gegenereerd.
Opruimen
Het opschonen van de voorbeeldtoepassingsinfrastructuur bestaat uit twee stappen. Om eerst de infrastructuur te verwijderen die voor deze demo is ingericht, voert u de volgende opdracht uit in de terminal:
Voer voor de volgende vraag y in en AWS CDK verwijdert de bronnen die voor de demo zijn ingezet:
Als alternatief kunt u de bronnen verwijderen via de AWS CloudFormation-console door naar de CdkStack-stack te navigeren en te kiezen Verwijder.
De tweede stap is het verwijderen van ADA. Voor instructies, zie Verwijder de oplossing.
Conclusie
In dit bericht hebben we gedemonstreerd hoe u de ADA-oplossing kunt gebruiken om inzichten te verkrijgen uit applicatielogboeken die zijn opgeslagen in twee verschillende gegevensbronnen. We hebben gedemonstreerd hoe u ADA op een AWS-account installeert en de democomponenten implementeert met behulp van AWS CDK. We hebben dataproducten gemaakt in ADA en de dataproducten geconfigureerd met de respectievelijke databronnen met behulp van de ingebouwde dataconnectoren van ADA. We hebben gedemonstreerd hoe u de dataproducten kunt bevragen met behulp van standaard SQL-query's en hoe u inzichten kunt genereren over de loggegevens. We hebben ook de Tableau Desktop-client, een BI-product van derden, met ADA verbonden en gedemonstreerd hoe visualisaties voor de dataproducten kunnen worden gebouwd.
ADA automatiseert het proces van het opnemen, transformeren, beheren en bevragen van diverse datasets en vereenvoudigt het levenscyclusbeheer van gegevens. Met de vooraf gebouwde connectoren van ADA kunt u gegevens uit diverse gegevensbronnen opnemen. Softwareteams met basiskennis van AWS-producten en -diensten kunnen binnen een paar uur een operationeel data-analyseplatform opzetten en veilige toegang tot de data bieden. De gegevens kunnen vervolgens eenvoudig en snel worden opgevraagd via een intuïtieve en zelfstandige webgebruikersinterface.
Probeer ADA vandaag nog uit om eenvoudig gegevens te beheren en er inzichten uit te halen.
Over de auteurs
 Aparajithan Vaidyanathan is Principal Enterprise Solutions Architect bij AWS. Hij ondersteunt zakelijke klanten bij het migreren en moderniseren van hun workloads naar de AWS-cloud. Hij is een Cloud Architect met meer dan 23 jaar ervaring in het ontwerpen en ontwikkelen van enterprise, grootschalige en gedistribueerde softwaresystemen. Hij is gespecialiseerd in Machine Learning & Data Analytics met een focus op het domein Data en Feature Engineering. Hij is een aspirant-marathonloper en zijn hobby's zijn wandelen, fietsen en tijd doorbrengen met zijn vrouw en twee jongens.
Aparajithan Vaidyanathan is Principal Enterprise Solutions Architect bij AWS. Hij ondersteunt zakelijke klanten bij het migreren en moderniseren van hun workloads naar de AWS-cloud. Hij is een Cloud Architect met meer dan 23 jaar ervaring in het ontwerpen en ontwikkelen van enterprise, grootschalige en gedistribueerde softwaresystemen. Hij is gespecialiseerd in Machine Learning & Data Analytics met een focus op het domein Data en Feature Engineering. Hij is een aspirant-marathonloper en zijn hobby's zijn wandelen, fietsen en tijd doorbrengen met zijn vrouw en twee jongens.
 Rashim Rahman is een softwareontwikkelaar gevestigd in Sydney, Australië met meer dan 10 jaar ervaring in softwareontwikkeling en architectuur. Hij werkt voornamelijk aan het bouwen van grootschalige open-source AWS-oplossingen voor veelvoorkomende klantgebruiksscenario's en zakelijke problemen. In zijn vrije tijd houdt hij van sporten en brengt hij tijd door met vrienden en familie.
Rashim Rahman is een softwareontwikkelaar gevestigd in Sydney, Australië met meer dan 10 jaar ervaring in softwareontwikkeling en architectuur. Hij werkt voornamelijk aan het bouwen van grootschalige open-source AWS-oplossingen voor veelvoorkomende klantgebruiksscenario's en zakelijke problemen. In zijn vrije tijd houdt hij van sporten en brengt hij tijd door met vrienden en familie.
 Hafiz Saadullah is hoofdtechnisch productmanager bij Amazon Web Services. Hafiz richt zich op AWS-oplossingen, ontworpen om klanten te helpen door veelvoorkomende zakelijke problemen en gebruiksscenario's aan te pakken.
Hafiz Saadullah is hoofdtechnisch productmanager bij Amazon Web Services. Hafiz richt zich op AWS-oplossingen, ontworpen om klanten te helpen door veelvoorkomende zakelijke problemen en gebruiksscenario's aan te pakken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- : heeft
- :is
- :niet
- :waar
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- vermogen
- in staat
- Over
- toegang
- geraadpleegde
- beschikbaar
- Account
- over
- acties
- ADA
- toevoegen
- toevoeging
- Extra
- aanpakken
- beheerder
- Na
- tegen
- Alles
- toelaten
- toestaat
- langs
- ook
- alternatief
- Amazone
- Amazon Web Services
- onder
- an
- analyse
- analisten
- analytics
- analyseren
- en
- Nog een
- elke
- apache
- api
- APIs
- Aanvraag
- toepassingen
- toegepast
- Solliciteer
- Het toepassen van
- architectuur
- ZIJN
- AS
- eerzuchtig
- At
- attributen
- Australië
- authenticatie
- bevoegd
- geautomatiseerde
- automaten
- webmaster.
- Beschikbaar
- AWS
- AWS CloudFormatie
- terug
- backend
- bars
- gebaseerde
- basis-
- BE
- omdat
- geweest
- vaardigheden
- op maat
- tussen
- zowel
- Box camera's
- bouw
- Gebouw
- ingebouwd
- bedrijfsdeskundigen
- business intelligence
- maar
- by
- Bellen
- CAN
- bekwaamheid
- geval
- gevallen
- catalogus
- CD
- verandering
- tabel
- Grafieken
- Kies
- het kiezen van
- klant
- Cloud
- code
- codes
- Collectie
- Kolom
- columns
- Gemeen
- compleet
- componenten
- Configuratie
- geconfigureerd
- Verbinden
- gekoppeld blijven
- versterken
- verbindt
- Overwegen
- consequent
- troosten
- bevat
- voortzetten
- gecorreleerd
- Correlatie
- Overeenkomend
- komt overeen
- Kosten
- en je merk te creëren
- aangemaakt
- creëert
- Wij creëren
- Geloofsbrieven
- Actueel
- gewoonte
- klant
- Klanten
- dashboards
- gegevens
- gegevens Analytics
- gegevensverwerking
- Database
- databanken
- datasets
- Standaard
- Vraag
- Demo
- tonen
- gedemonstreerd
- Afhankelijk
- implementeren
- ingezet
- inzet
- ontplooit
- beschrijving
- ontworpen
- ontwerpen
- desktop
- gedetailleerd
- gegevens
- Ontwikkelaar
- het ontwikkelen van
- Ontwikkeling
- diagnose
- anders
- direct
- invalide
- ontdekking
- Display
- verdeeld
- diversen
- Nee
- domein
- domeinen
- Dont
- liet vallen
- gedurende
- elk
- Vroeger
- gemakkelijk
- editing
- beide
- ingeschakeld
- maakt
- Endpoint
- eindpunten
- Engineering
- verzekeren
- Enter
- Enterprise
- zakelijke klanten
- Ondernemingsoplossingen
- fout
- fouten
- oprichten
- gevestigd
- Ether (ETH)
- voorbeeld
- bestaand
- ervaring
- Verklaren
- uitleg
- extract
- extraheer de gegevens
- vertrouwd
- familie
- Kenmerk
- weinig
- veld-
- Velden
- Figuur
- Dien in
- Bestanden
- finale
- financiën
- Voornaam*
- flexibel
- Focus
- richt
- volgend
- Voor
- formaat
- vier
- Frequentie
- vrienden
- oppompen van
- functie
- Krijgen
- voortbrengen
- gegenereerde
- krijgen
- het krijgen van
- regerend
- Groep
- Groep
- Hebben
- met
- he
- hulp
- Gemarkeerd
- wandelen
- zijn
- historisch
- Hobby's
- gehost
- HOURS
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- IAM
- identiek
- identificeren
- Identiteit
- if
- importeren
- in
- omvatten
- omvat
- Inclusief
- informatie
- Infrastructuur
- eerste
- inzichten
- installeren
- installatie
- instructies
- geïntegreerde
- integratie
- Intelligentie
- interactieve
- geïnteresseerd
- Interface
- in
- intuïtief
- oproept
- betrokken zijn
- kwestie
- IT
- mee
- aansluiting
- Sluit zich aan bij
- jpg
- json
- voor slechts
- Houden
- sleutel
- kennis
- taal
- Groot
- grootschalig
- Achternaam*
- later
- lancering
- leren
- Bibliotheek
- Erkend
- levenscyclus van uw product
- als
- LIMIT
- Lijn
- Lijst
- leven
- inloggen
- logging
- lang
- Kijk
- lookup
- machine
- machine learning
- maken
- maken
- beheer
- management
- manager
- veel
- kaart
- in kaart brengen
- Marathon
- Marketing
- Materie
- zinvolle
- Bericht
- MFA
- macht
- trekken
- minuten
- Mode
- moderniseren
- meer
- meest
- meestal
- mozilla
- multi-factor authenticatie
- MySQL
- naam
- Genoemd
- namen
- inheemse
- OP DEZE WEBSITE VIND JE
- navigeren
- Navigatie
- Noodzaak
- nodig
- behoeften
- New
- onlangs
- volgende
- aantal
- of
- Aanbod
- offline
- Oud
- on
- On-Demand
- EEN
- online.
- Slechts
- open
- open source
- operationele
- Keuze
- or
- bestellen
- Overige
- Overig
- uit
- uitgang
- overzicht
- pagina
- brood
- Wachtwoord
- pad
- Patronen
- uitvoeren
- permissies
- Persoonlijk
- phone
- pii
- pijpleiding
- plaats
- Eenvoudig
- plan
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- beleidsmaatregelen door te lezen.
- Portaal
- Post
- postgresql
- aangedreven
- Voorbereiden
- Bereidt zich voor
- vereisten
- presenteren
- cadeautjes
- Voorbeschouwing
- vorig
- in de eerste plaats
- Principal
- Voorafgaand
- problemen
- gaan
- verwerkt
- processen
- verwerking
- geproduceerd
- Product
- product manager
- Producten
- Producten en Diensten
- Programma's
- project
- zorgen voor
- mits
- leverancier
- biedt
- doel
- doeleinden
- Python
- queries
- vraag
- snel
- reeks
- Lees
- klaar
- ontvangen
- archief
- verwezen
- regio
- verwantschap
- relevante
- verwijderen
- herhaling
- Rapporten
- te vragen
- nodig
- Resources
- degenen
- responsive
- Resultaten
- behouden
- beoordelen
- paardrijden
- rollen
- wortel
- Regel
- lopen
- loper
- lopend
- verkoop
- dezelfde
- Bespaar
- Scale
- scenario's
- gepland
- omvang
- Ontdek
- Tweede
- sectie
- beveiligen
- veiligheid
- zien
- gekozen
- selectie
- sturen
- verzonden
- apart
- dienen
- Serverless
- service
- Diensten
- reeks
- het instellen van
- Delen
- gedeeld
- Bermuda's
- getoond
- Shows
- Eenvoudig
- vereenvoudigd
- vereenvoudigen
- Maat
- vaardigheden
- So
- Software
- software development
- oplossing
- Oplossingen
- bron
- bronnen
- specialist
- specialiseert
- specifiek
- gespecificeerd
- Uitgaven
- Sport
- SQL
- stack
- standalone
- standaard
- begin
- starts
- Status
- Stap voor
- Stappen
- mediaopslag
- opgeslagen
- Draad
- gestructureerde
- geslaagd
- Met goed gevolg
- dergelijk
- steunen
- zeker
- sydney
- Systems
- tafel
- Tableau
- Nemen
- neemt
- team
- teams
- Technisch
- technische vaardigheden
- terminal
- dat
- De
- De Bron
- hun
- harte
- Er.
- Deze
- van derden
- dit
- drie
- Door
- niet de tijd of
- naar
- vandaag
- tools
- top
- Top 10
- Totaal
- Transformeren
- Transformatie
- transformaties
- getransformeerd
- transformeren
- transformaties
- veroorzaakt
- twee
- type dan:
- types
- voor
- die ten grondslag liggen
- begrijpen
- bijgewerkt
- updates
- op
- URI
- us
- .
- use case
- gebruikt
- Gebruiker
- User Interface
- gebruikers
- gebruik
- Values
- variabele
- variëteit
- versie
- via
- Bekijk
- willen
- Manier..
- we
- web
- webservices
- GOED
- wanneer
- welke
- en
- breed
- Grote range
- vrouw
- wil
- Met
- binnen
- zonder
- Mijn werk
- workflow
- Bedrijven
- zou
- schrijven
- jaar
- u
- Your
- zephyrnet